面向决策分析的海量气象数值预报数据快速提取①
2022-09-20李永生张金标陈冰怀
李永生, 张金标, 张 敏, 陈冰怀
(广东省气象探测数据中心, 广州 510080)
1 引言
GRIB 码是世界气象组织(WMO)推荐使用的与计算机操作系统无关的压缩的二进制编码, 是一种用于交换和存储规则分布数据的二进制文件格式, 现行的GRIB 码版本有GRIB1和GRIB2两种格式, 具有多维数据存储方便、压缩比高、支持多种压缩方式、扩展性强等特点, 尤其擅长大容量多维度的非结构化数据的交换, 广泛应用于数值天气预报产品、海洋水文等数据的存储和交换. 针对GRIB码进行解码工具有两种, 第一种是wgrib命令行工具, 可以通过命令行的方式通过不同的参数组合对GRIB数据进行读取操作.第2种方法是利用业界Unidata发布的NetCDF-java的网格数据操作API (支持Bufr、Grib、NetCDF3/4、HDF等网格数据), 具有按照Shape形状提取指定范围内网格数据的方法, 可以通过编程使用get和set键值操作读取数据, 其中第一种方法在国内应用比较广泛.使用上述方法基本能够满足获取特定维度的部分数据的业务应用需求[1], 但在面向决策分析领域气象预测的应用中, 通常以融合分析应用为主, 需要对海量的数值预报产品的一次性批量数据快速读取和分析, 传统的数据读物方法存在数据读取时间效率不高, 空间资源消耗大等问题[2]. 本文即针对上述业务痛点, 面向气象预警、预报和预测业务实际需求, 以GRIB码存储的数值预报数据产品为研究对象, 设计一种基于精准定位, 数据提取的维度、读取经纬度的范围可按需定制的, 多进程处理的快速数据提取方法.
2 研究对象数学模型
本文的研究对象是以GRIB格式存储的半结构化气象数值预报产品, 现行的GRIB 码版本有GRIB1和GRIB2两种格式, 每个 GRIB1记录单元通常存储某个要素在某个层次的连续网格序列点的数据值. 逻辑上将记录单元划分为“段”, 每个GRIB1记录单元可以包含六段, 其中两个段是可选的, 具体如表1所示.

表1 GRIB1格式说明
GRIB文件每一个“段”对应到数值预报产品中就是一个平面数据, 该平面数据是一个非结构化的网格数据, 网格点数由产品的空间分辨率决定, 平面数据Data[v]由产品的要素种类(VarName)、产品的生成时间(DataTime)、层次高度(LevelName)、预报时效(ForcastName)、成员变量(MemberName)等维度信息唯一确定, 用数学表达为:
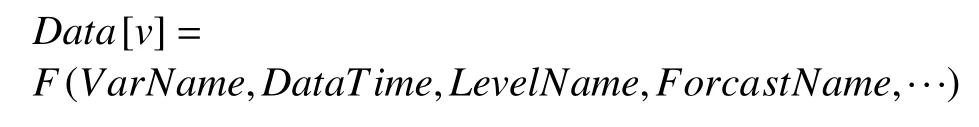
上述维度信息确定的平面数据D ata[v]是网格点类的半结构化数据, 其属性信息包括经度范围、纬度范围、空间分辨率以及数据维度上的南北走向, 1代表维度上从南到北依次排列, 0表示维度从北到南依次排列, 其属性函数可以描述为:
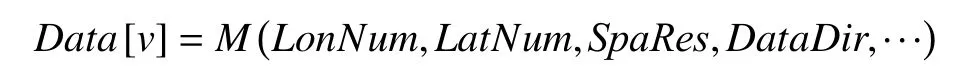
3 数据快速精准定位算法的设计与实现
分析传统数据读取算法的技术原理可知, 数据解码效率方面存在主要制约因素[3]是需要一定范围内遍历查找所需提取特定维度数据所在的位置, 即数据块的定位[4]; 这在一次性批量处理大量数值预报产品时产生了一定的时间损耗; 但上述因素存在较大的提升空间, 相关的方法的创新研究也基本围绕上述制约因素展开. 针对上述问题, 本文基于精准数据定位获取数据的算法[5], 节省了传统方法中数据块查找所消耗的时间;进而明显提高了数据的读取速度, 算法具体流程如下.
(2)可根据数值预报产品的要素种类、产品的生成时间、层次高度、预报时效等信息, 定制筛选业务所需的平面数据[11,12].
该品种由福建省泉州市农业科学研究所(福建省泉州市晋江市池店镇泉安北路,邮编:362212)和云南省农业科学院经济作物研究所培育。
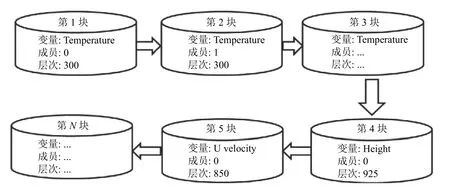
图1 数据文件结构图
算法根据实际业务确定的空间经纬度范围信息,对数值预报产品平面数据进行逐行剪裁, 形成业务所需空间范围的平面数据, 数据截取从低纬度到高维的方向具体的算法流程如下.
计算读取圈数:
(2)再确定读取圈数:
4 数据按需定制截取算法的设计与实现
获取特定数据块的精确位置后, 为了不产生计算和存储资源的浪费以及处理时间的增加. 需要对一定空间范围的数据进行按需截取, 避免总是进行整个平面数据的读取和流转处理, 从而可以按照业务需求, 根据其属性函数在空间范围内进行裁剪以获取业务所需空间范围的数据, 这样可以减少数据的传输量, 提高数据业务应用效率[6-9].
染料的广泛使用导致染料废水造成的环境污染日益严重[1,2]。染料废水污染组分复杂、毒性强,是一种难处理的工业废水[3,4]。亚甲基蓝就是一种使用最为广泛的染料。常用的染料废水的处理方法主要有沉淀法[5]、氧化法[6]、膜分离法[7]及吸附法[8]等。吸附法因其易操作、高效等优点而受到重视。
老太医娓娓道来:火药量适中即可,专门灼烧对手最柔弱之处,比如说两腋、男根、肚脐和喉囊。剧痛之下,肾火陡升,伤者会心跳骤停,引发猝死。此外,为了增加火势,也为了掩盖火药味,掩人耳目,表象应以大火焚烧为主。这也不难办到:以奇特的香料掺入燃油之中,作为助燃之物。以火药来点燃油料,烧起来迅猛异常,根本无法扑救。
运用拟人手法编出这一段菊花与主人公的对话,这是菊花对主人公的提问,因为菊花不能从大地吸收养分而衰弱下去,这是表现菊花对大地的渴望。这话也是主人公即作者中野重治的自白。被带到监狱里来,被和人民大众隔离,监狱的生活又很艰苦,可以理解为作者也不能从大地吸收养分的比喻。巧妙地借菊花的口把这话说出来表达自己的思念劳苦大众的内心。
4.1 按需可定制的内容
根据数值预报产品原始空间经度范围信息确定,整个经度范围:
每个GRIB实体文件是若干平面数据 D ata[v]的组合, 每个平面数据对应一个数据块, 文件结构示意如图1所示.
4.2 空间范围截取算法
(1)获取元信息体: 获取整个GRIB文件的所有数据块的元信息, 包括每个“数据块”的起始位置, 结束位置等, 所获取的信息均是轻量的元信息, 形成元信息体.整个过程的耗时在毫秒级别.
(1)每圈读取长度的确定
(1)可对平面数据进行空间范围内的按需裁剪, 允许业务用户根据所需数据的空间经纬度信息对数据块进行按需截取[10].
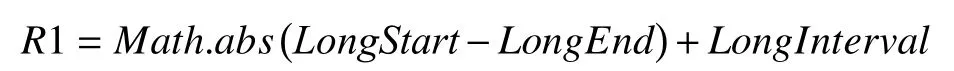
整体经度差:
在与梁兆贤的近距离交谈中,我们感受到了印刷业以及市场对于人才技术和创新的迫切需要,以及具备学习能力的重要性。在他看来,要通过人才队伍的建设,提高企业管理水平,使印刷行业加快转型升级,推动中国制造2025在印刷领域的前进。
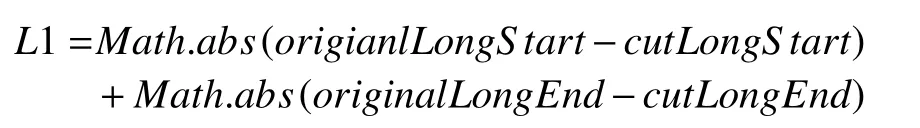
计算单圈读取的数据长度:
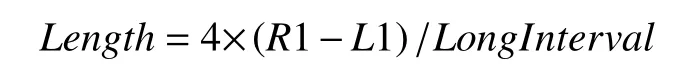
(3)目标数据块的位置: 根据元数据体和实体数据体的对应关系, 首先对元数据体进行整理, 通过数据整理函数, 将元数据信息进行分类, 重点确定数据块的实际位置, 位置确定后, 根据属性信息计算数据的偏移量进而定位数据并对数据块进行循环读取.
整个纬度范围:
煤炭资源是非常宝贵的不可再生资源。由于煤炭的不可再生性和重要性,对煤炭资源的开采和保护广受社会的关注。在煤炭综采工作面上进行系统的开发和创新,是当前研究的热点。例如工作面支架液压系统的管控,需分析支架液压系统发生污染的情况,找到有效改善措施来控制污染,避免影响到综采工作面支架液压系统的安全运行。
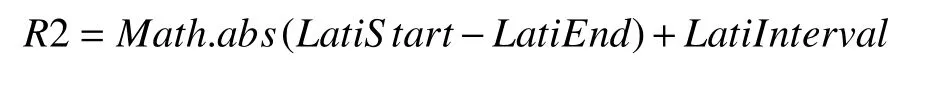
整体纬度差:
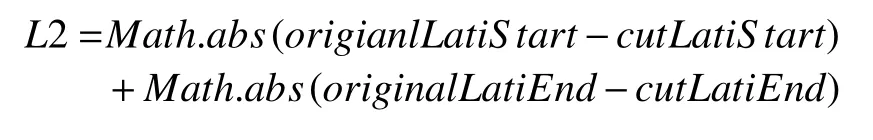
(2)获取实体信息体: 算法过滤去掉每个数据块的元数据信息, 并一次性将所有GRIB数据解码为二进制数据, 包括数据的解压缩、解码, 一次性将所有GRIB数据解码为二进制数据, 称为实体数据体. 实体数据体存储的顺序和步骤(1)中元数据的顺序是一一对应的.
Number=4×(R2-L2)/LatiInterval
采用for循环依次读取每圈数据:
应用SPSS 17.0统计软件对数据进行统计分析。计量资料以均数±标准差(±s)表示,组间比较采用重复测量的方差分析,P<0.05为差异有统计学意义。
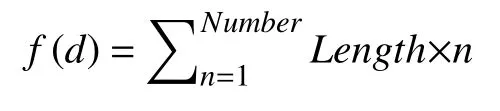
算法的实现过程如算法1.

算法1. 格点数据按需截取算法输入: 模型 model包括分辨率值, 原始经纬度范围, 裁剪经纬度范围:{[(longitudeInterval, latitudeInterval)], [(orignalLongitudeStart,orignalLatitudeStart), (orignalLongitudeEnd, orignalLatitudeEnd)],[(cutLongitudeStart, orignalLatitudeStart), (orignalLongitudeEnd,orignalLatitudeEnd)]}输出: 字节数组data 1. 计算经纬度范围2. double longitudeRange=|orignalLongitudeStart-orignalLongitudeEnd|+longitudeInterval 3. double latitudeRange=|orignalLatitudeStart-orignalLatitudeEnd|+latitudeInterval 4. 计算经度差值double longitudeSub1=|orignalLongitudeStart-cutLongitudeStart|double longitudeSub2=|orignalLongitudeEnd-cutLongitudeEnd|5. 计算纬度差值double latitudeSub1=|orignalLatitudeStart-cutLatitudeStart|double latitudeSub2=|orignalLatitudeEnd-cutLatitudeEnd|6. 计算整体的经度差值和纬度差值double longitudeFinal=longitudeSub1+longitudeSub2 double latitudeFinal=latitudeSub1+latitudeSub2 7. 确定数据存储方向, 1表示从南到北, 0表示从北到南String sNDirection = model.getGridInfoXml().getsNDirection();String wEDirection = model.getGridInfoXml().getwEDirection();

8. 根据缠绕方向确定纬度裁剪大小double latitudeSub = 0d;switch (sNDirection) do case “1”:latitudeSub = latitudeSub2;break;case “0”:latitudeSub = latitudeSub1;break;default:decodeLogger.error (“---------数据南北缠绕方向定义错误, 只能为1或者0!”);break;}end switch 9. 根据缠绕方向确定经度裁剪大小double longitudeSub = 0d;switch (wEDirection) do case “1”:longitudeSub = longitudeSub1;break;case “0”:longitudeSub = longitudeSub2;break;default:decodeLogger.error(“---------数据东西缠绕方向定义错误,只能为1或者0!”);break;}End switch 10. 计算纬度遍历个数int latiLengthValue = (int)((latitudeRange-latitudeFinal)/latitudeInterval);11. 计算纬线长度double latiLength = latitudeSub/latitudeInterval;12. 计算纬度取值长度double longitudePosi = 4 × (longitudeRange/longitudeInterval) ×latiLength;13. 计算沿经度纬度移动值int latitudePosi = 4 × (int)(longitudeSub/longitudeInterval);14. 计算开始整体移动的个数long finalPosi = (long)(planeStartPos + longitudePosi + latitudePosi);15. 计算单圈读取长度double length = 4 × (longitudeRange-longitudeFinal)/longitudeInterval;16. 输出data for int i = 0; i < latiLengthValue; i++ do byte[] oneCircleByte = gribUtil.readFileByPosiBytes(bodyPath,finalPosi, (int) length);data = byteJoin(data, oneCircleByte);finalPosi += 4 × longitudeRange/longitudeInterval;}end for 17. return data
5 实例测试与结果分析
本文选取一类数值预报产品进行实际测试, 该产品每时次需处理的数据文件为66个, 每个文件数据量约600 M, 每个文件约200个平面数据. 以数据解码耗时为主要考核指标, 分别对不同的文件数均采用单个进程解码测试. 结果表明随着文件数量的增长耗时基本呈线性增长趋势, 如图2所示, 且66个文件的总耗时由传统方法的2 h提高到约40 min, 解码效率大幅提升.
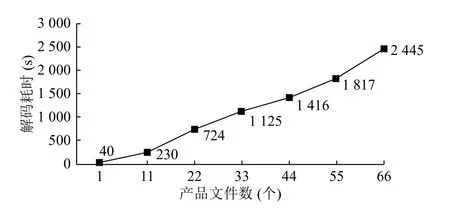
图2 单进程多文件解码耗时统计图
另外以单平面耗时为主要考核指标, 分别采用1进程, 4进程、8进程以及16进程进行数据处理, 实际测试结果表明, 采用16进程处理的速度由单个进程的257 ms提高到37 ms. 实际测试结果显示多进程技术的引入对数据处理速度提升明显. 如图3所示.
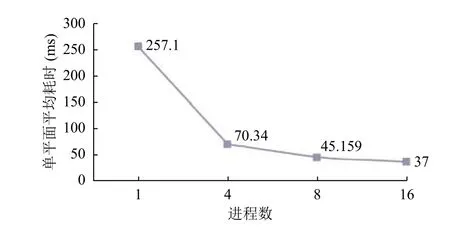
图3 多进程单平面解码耗时统计图
本文实现的批量数据数据处理方法已经为广东省气象行业的市县版的Gift系统提供数据快速处理服务, 同时在广东省气象行业的预报预测和决策分析业务系统提供可视化数据服务支撑, 如图4所示.
图4 预报决策可视化业务化数据支撑图
6 结论
本文针对传统数据抽取方法效率不高的问题, 基于多进程处理技术, 设计了一种基于精准位置寻址的快速数据块定位算法, 实现了数据块的精准定位; 设计了可按需在空间范围内进行裁剪的截取算法, 可按需根据数据的属性维度、经纬度范围等信息实现数据按需抽取; 基于上述算法实现了全流程统一控制的多进程数据读取的业务流程. 实际测试结果表明利用本方法来解码GRIB格式的数值预报产品, 可以大大提升非结构气象数值预报产品数据的抽取效率, 提高资源利用率. 为海量半结构化的气象数值预报数据产品的快速处理提供了方法参考, 具有很好的业务应用价值.
