GM-FastText多通道词向量短文本分类模型①
2022-09-20白子诚周艳玲
白子诚, 周艳玲, 张 龑
(湖北大学 计算机与信息工程学院, 武汉 430062)
1 引言
随着互联网的普及, 中国大数据产业领跑全球, 每时每刻都产生大量的短文本数据信息, 如新闻标题、应用评论、短信息等[1]. 在大数据时代背景下, 大量短文本信息的筛选与管理成为人们亟待解决的需求. 文本分类作为自然语言处理(natural language processing, NLP)的一个子任务, 是将指定文本归纳到预定义标签的过程, 广泛应用于新闻标题分类、情感分析、主题标签和对话系统等, 对于特定的信息筛选, 有着极大的便利. 与长文本分类相比, 短文本分类数据具有特征稀疏, 用词不规范, 数据海量等问题[2].
目前处理短文本分类思路主要有两个方向[3]: 一是通过大规模的预训练语言模型, 生成“动态”的嵌入词向量, 通过引入大量的外部信息提高分类效果; 二是通过构建优良的模型结构, 更深层次的挖掘信息从而提高分类准确度. 本文同时考虑这两个角度改进提高文本分类效果. 为了获取更多短文本的特征, 采用FastText方法[4]代替传统Word2Vec方法产生嵌入词向量, 这种方式不单单只是利用字向量级别的嵌入词向量, 同时产生含有N-gram级别的嵌入词向量, 形成多通道的嵌入词向量输入; 另外在多通道的嵌入词输入下, 采取了GRU (gate recurrent unit)和多层感知机(multi-layer perceptron, MLP)混合网络结构(GRU-MLP hybrid network architecture, GM)提取并结合各通道词向量特征. 提出新的文本分类结构GM-FastText, 并在多个数据集上通过对比分析其性能.
2 相关工作
在数据较小情况下, 可以采用传统的机器学习方式, 如朴素贝叶斯、K-近邻、支持向量机等, 这些方法通过对数据集的预定义学习从而预测结果. 然而, 特征工程的建立往往需要大量工作量. 随着数据量的增长,传统机器学习方式已不再适用, 卷积神经网络(convolutional neural networks, CNN)、循环神经网络(recurrent neural networks, RNN)等基于神经网络可以自主提取文本的特征, 减少大量人工标注, Kim[5]提出TextCNN模型, 应用了多个不同卷积核提取文本特征实现文本分类.
实现自主提取特征的关键是字词向量化. 在NLP中广泛应用的独热编码(one-hot)将词表示为长度为词表大小的长维度向量, 其中仅一个纬度值为1及表示这个词. 这样的编码方式易于理解, 但是难以联系上下文关系, 在实际应用过程中易造成维数灾难等问题. 然而, 分布式词向量表示则在很大程度上解决了以上问题, 训练良好的分布式词向量可以通过计算向量之间欧几里得距离衡量相似度. 现阶段主流的分布式词向量训练模型有Mikolov[6]在2013年提出的Word2Vec模型, 其训练方式有两种模式: CBOW和Skip-gram, 并通过层次Softmax和负采样两种优化方式训练, 可以得到较为准确的词向量表示. Facebook研究团队提出的FastText模型是一个开源词向量计算和文本分类工具, 其效果可以媲美深度神经网络, 运行速度快并且在CPU上一分钟能实现10万数据级别的分类任务, 同样是在Word2Vec的基础上进行了改进, 可以得到除了词向量以外的N-gram向量信息. 张焱博等人[7]将预训练词向量分别通过CNN-Bi-LSTM和FastText提取浅层语义并做拼接然后直接映射到分类, 得到了较好的结果并加速了训练过程. 汪家成等人[8]为解决FastText准确率低问题, 在输入阶段使用TextRank和TF-IDF技术使输入特征表示信息量更高. 范昊等人[9]则利用Bi-GRU直接处理FastText词向量. 但是这些操作仅是对FastText不同N-gram词向量简单的叠加操作, 而丢失了各个N-gram词向量独立特征. 不同N-gram词向量这一特性对于短文本分类处理可以一定程度上解决“简写”导致超出词表问题. 然而FastText产生的向量组比主流的词向量多了很多数据参数, 如何建立高效网络结构成为一个挑战, 针对此问题采取了GRU和MLP混合网络结构.
3 GM-FastText模型
为了解决短文本分类中存在的特征稀疏、用词不规范等问题, 本文根据FastText模型能产生多通道的词向量等特点, 结合GRU和MLP等模型在特征提取上的优势提出了GM-FastText模型. GM-FastText模型流程图如图1所示, 利用FastText模型产生3种不同的嵌入词向量编码, One-Emb、Two-Emb、Thr-Emb分别代表由1、2、3个字表示的向量. 将One-Emb输入到GRU网络提取One-Emb信息, 然后再输入到MLP-Layer层. Two-Emb和Thr-Emb则直接输入到MLP-Layer层. 通过MLP层联系3组嵌入词向量, 平均池化后连接全连接层得到分类结果.
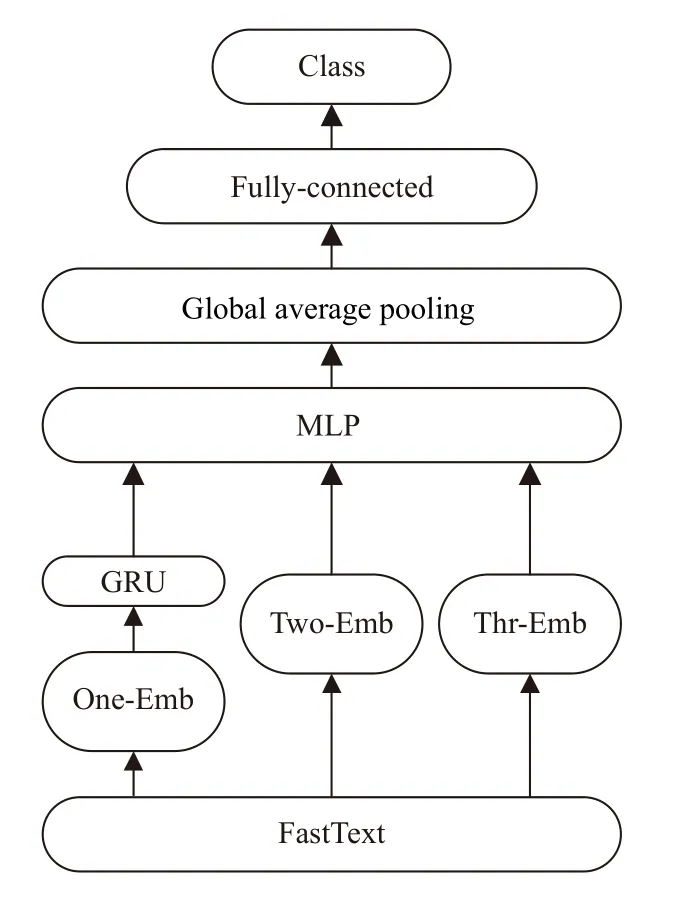
图1 GM-FastText模型结构图
3.1 FastText
FastText模型架构如图2所示, 只有输入层、隐藏层、输出层3层构成. 虽然其结构与Word2Vec模型的CBOW类似, 但是模型任务不同. 前者通过上下文预测中间词, 后者通过全部特征预测文本标签.
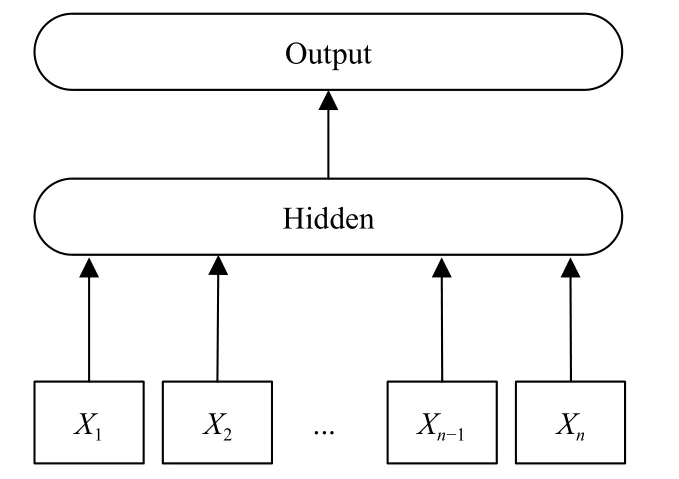
图2 FastText模型结构
模型中{X1, X2, …, Xn-1, Xn}表示文本中的特征词向量, 通过隐藏层将多个词向量叠加经过激活函数得到输出层的输入:
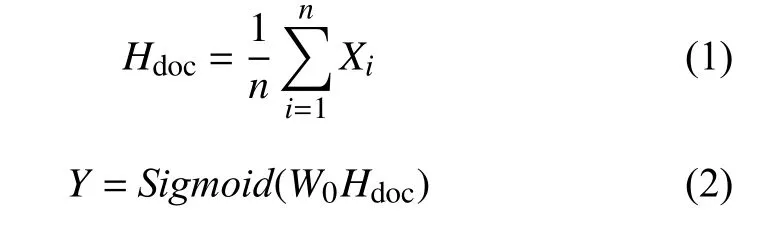
其中, Hdoc表示平均文本特征, W0表示隐藏层权重矩阵, Y表示输出层输入.
对于大量类别的数据集, 在做类别概率归一化时会占用非常长的时间, 因此在模型输入层中引入了分层Softmax[10], 其思想是根据类别的频率构造哈夫曼树来代替标准Softmax, 只需要计算一条路径上所有节点的概率值, 不需要在意其他节点, 可以将计算时间复杂度从O(N)降低到O(logN).
FastText通过词袋模型获取文本特征的同时, 还融入了N-gram信息. 其基本思想是按指定的步长进行大小为N的窗口滑动, 最终得到片段长度N的序列. 这样对于一些罕见单词可以提供更好的词向量, 对于一些超出词表的单词可以通过字符级N-gram进行组合,同时也面临着内存压力. FastText模型随着语料库增加, 使用Hash的方式被分配到不同的桶中缓解内存压力.
3.2 GUR
为采用GRU模型处理字符集别的嵌入词向量, 这个模型由Chung[11]提出, 是RNN的变种与LSTM (long short-term memory)结构相似. 然而GUR只有两个门控, 分别是更新门和重置门, 简化了模型结构计算效率更高, 同时也能解决梯度消失和梯度爆炸等文本信息丢失问题.
GRU模型结构由图3所示, Zt为更新门, 是由隐藏状态Ht-1和当前输入Xt控制, 其计算过程如式(3)所示, Wz表示为权重, 通过激活函数Sigmoid将结果映射到0-1之间, 结果越大表示存储下来的信息多, 反之越少, 有助于获取长序列依赖关系. Rt为重置门决定了对上一时刻的信息的获取程度, 如式(4)所示, 有助于获取短序列的依赖关系. H~t表示当前序列的隐藏状态,是由重置门和当前输入控制, 使用tanh激活函数结果映射在-1~1之间如式(5)所示. Ht表示传递到下个序列信息, 通过更新门实现记忆更新, 其计算如式(6).
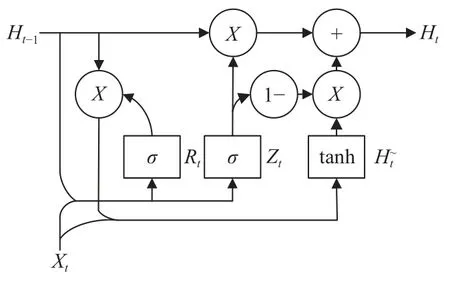
图3 GRU模型结构图
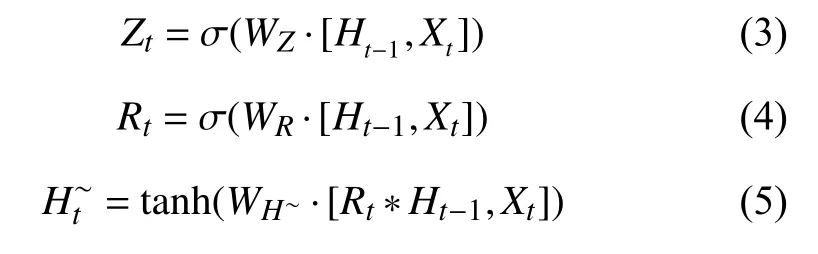
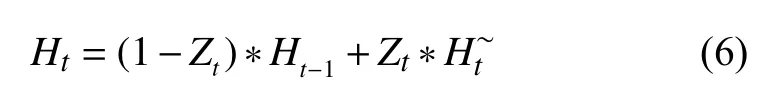
3.3 MLP-Layer
为了使3种不同特征通道之间参数能有交互, 设计了MLP-Layer层[12], 是由层归一化层(LayerNorm)、全联接层和一个激活层构成, 其结构如图4所示. 层归一化是为了突出特征同时保持特征稳定的分布结构,然后再通过全联接层和激活层输入到下一层. 其计算流程可以如式(7), 其中X表示输入, Y表示输出, W表示训练权重, b表示偏置, σ表示激活函数.
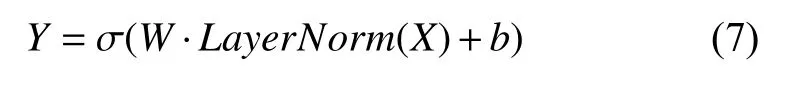
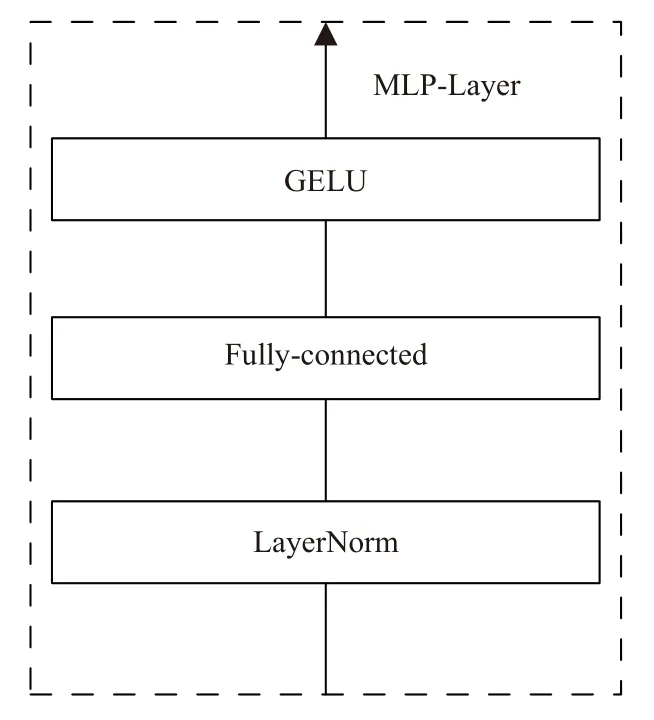
图4 MLP-Layer结构
4 实验结果分析
该实验将采取多个数据集与传统的基线模型做对比, 分析模型的性能, 实验使用Python 3.8版本, 采用NVIDIA 1070显卡作为计算平台.
4.1 数据集
该实验采用短新闻标题去验证模型的效果, 由于数据库过大, 限于计算资源, 分别从THUCNews、Sogo新闻库中选取10个类别按每个类别2万条, 然后每个类别抽取2 000条以1:1分为测试集和验证集. 由于头条新闻库单个类别数量少, 选取了10个类别每个类别只抽取12 000条再分别抽取出2 000条以1:1分为测试集和验证集. 数据集的详细情况如表1所示.
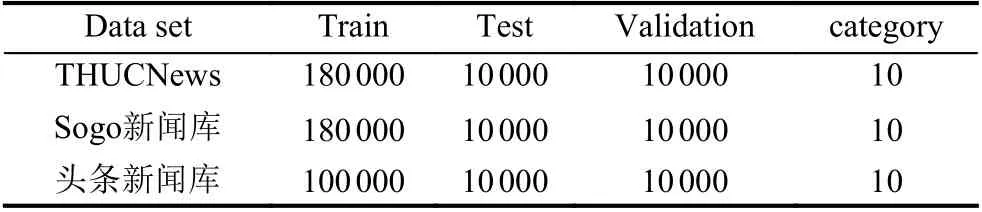
表1 数据集信息表
4.2 实验评估指标
实验将词向量维度设置为300, 采用Adam优化器进行参数更新, 学习率设置为0.001, 批处理设置为128, 为防止过拟合随机失活率设置为0.5. 文本分类常用指标包括精确率P、召回率R、F1以及准确率Accuracy, 由于F1指标中已经包含了精确率P和召回R, 所以选择F1和Accuracy作为评估指标.
为了验证GM-FastText模型的有效性, 主要从两个角度进行了对比. 首先使用相同的运行参数, 且都使用随机初始化嵌入词向量对比分析了TextCNN、TextRNN、DPCNN[13]、RCNN[14]、Transformer、FastText 模型的文本分类性能. 同时为了分析GM结构的特征提取优势, 将FastText分别与RNN、CNN拼接后的模型FastText-CNN、FastText-RNN与GMFastText模型也进行对比实验分析.
4.3 实验结果分析
各模型在3个数据集上的F1值如表2-表4所示.从表2可以看出, GM-FastText模型在THUCNews数据集中各分类的F1值最好. 与传统文本分类模型TextCNN、TextRNN相比, GM-FastText在该数据集上F1值提升最大类别为Sport和Stock分别为0.04和0.05, 10个类别F1值分别平均提升0.02和0.019;采用FastText词向量, GM-FastText与FastText,FastText-CNN和FastText-RNN相比在该数据集上F1值提升最大类别为Stock、Entertainment和Stock分别为0.02、0.03和0.03, 10个类别F1值平均提升0.005, 0.015, 0.011.
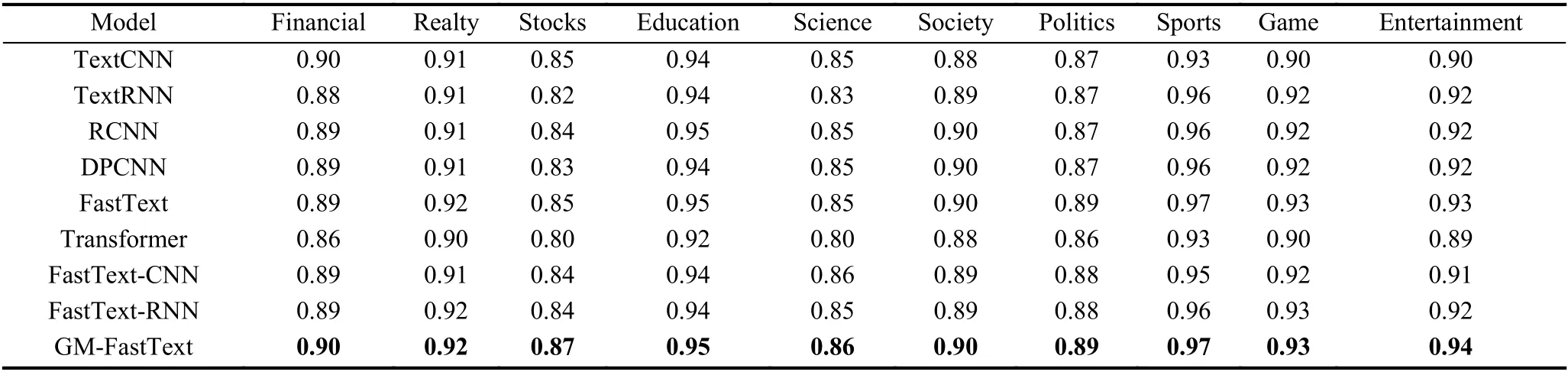
表2 THUCNews数据集10类别F1值
从表3中可以看出, 在头条新闻库数据集中除Entertainment、Education和Travel这3个类别外有7个类别达到最优值. 与传统文本分类模型TextCNN、TextRNN相比, GM-FastText在该数据集上F1值提升最大类别为Science和Word分别为0.03和0.04,10个类别F1值分别平均提升0.013和0.015; 采用FastText词向量, GM-FastText与FastText, FastText-CNN和FastText-RNN相比在该数据集上F1值提升最大类别为Financial、Science和Word分别为0.03、0.03和0.03, 10个类别F1值平均提升0.008, 0.008,0.013.
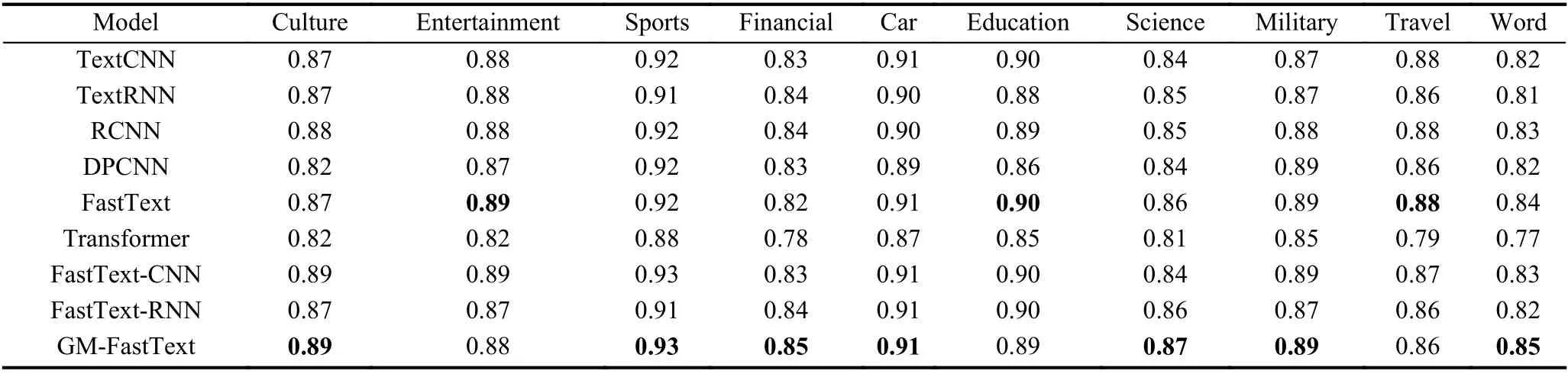
表3 头条新闻库数据集10个类别F1值
从表4可以看出, 在Sogo新闻库数据中除Travel类别外其他9个分类能达到最好的效果. 与传统文本分类模型TextCNN、TextRNN相比, GM-FastText在该数据集上F1值提升最大类别都为Culture分别为0.07和0.06, 10个类别F1值分别平均提升0.032和0.035 ; 采用FastText词向量, GM-FastText与FastText,FastText-CNN和FastText-RNN相比, 在该数据集上F1值提升最大类别为Culture、Education和Science分别为0.02、0.05和0.05, 10个类别F1值平均提升0.005, 0.019, 0.025.
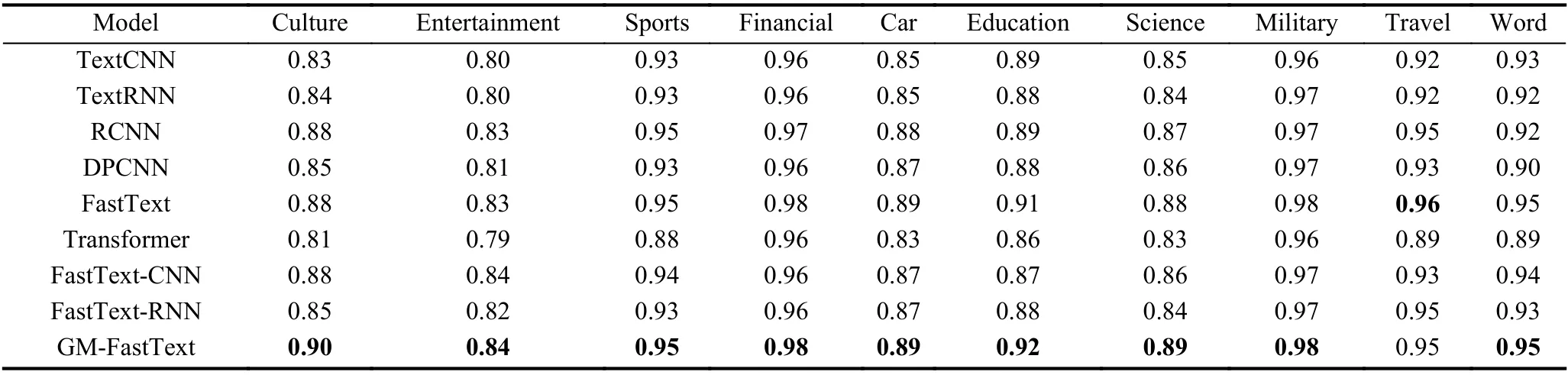
表4 Sogo新闻库数据集10个类别F1值
根据以上分析, GM-FastText与传统文本分类模型TextCNN、TextRNN相比, 在3个数据集上F1平均提升0.021和0.023; GM-FastText相比于FastText,FastText-CNN和FastText-RNN在3个数据集上10个类别F1平均提升0.006, 0.014和0.016.
各模型在3个数据集上的准确率值如表5所示.从表5中可以看出, GM-FastText在不同的数据集上都达到了最高的值. 与传统文本分类模型TextCNN、TextRNN相比, GM-FastText分别在3种数据集上准确率提升了1.74、0.95、3.2和1.64、1.58、3.03个百分点; 采用FastText词向量, GM-FastText与FastText、FastText-CNN、FastText-RNN相比在3个不同的数据集上的准确率分别提升, 0.56、0.28、0.43,1.15、0.41、1.62和1.01、1.09、2.21个百分点.
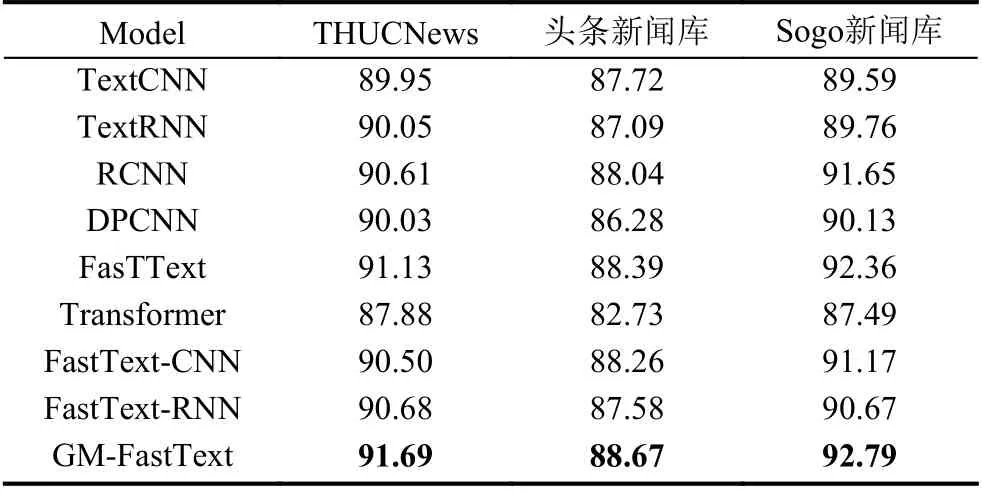
表5 各模型在不同数据集的准确率(%)
由以上数据可得, GM-FastText与传统文本分类模型TextCNN、TextRNN相比在3个数据集上准确率平均提升1.96、2.08个百分点; GM-FastText相比于FastText, FastText-CNN和FastText-RNN在3个数据集上准确率平均提升0.42、1.06、1.41个百分点.
同时从表2-表5可以看出DPCNN和Transformer两个深度神经网络模型, 相比其他网络模型准确率上缺乏优势, 说明仅依靠增加网络深度对于短文本处理没有明显的提升效果.
总之, 针对3个数据集表2-表5中的F1值和准确率的性能改善可知, FastText多通道词向量在短文本分类中有更好的词向量表达和更加准确的特征表示;且GM网络结构相对于传统的CNN、RNN模型在应对多通道大量数据时有更好的特征提取和整合能力.
5 结论与展望
通过词向量表征和模型结构两个切入点, 构建了一个多通道嵌入词的简易网络短文本分类模型GMFastText. 通过FastText生成3种不同N-gram嵌入词向量, 以多通道的形式输入到GM结构中, 突出文本特征然后通过全联接层得到结果. GM-FastText模型利用N-gram特殊的滑窗结构构建特殊的字词向量, 对于短新闻中一些极简词也有对应向量解决大多数的OOV问题, 提高了部分类别新闻分类准确率. 尽管MLP提取整合多特征向量有着良好性能, 但是特征向量经过1次MLP-Layer层特征识别有限, 在接下来的工作中应着重优化MLP-Layer尝试多次经过MLP-Layver层多次提取词向量特征.
