基于暗通道和改进YOLOv3的雾天车辆检测算法
2022-09-19王艺钢
华 丹,杨 硕,2,王艺钢
(1.沈阳化工大学 计算机科学与技术学院,辽宁 沈阳 110142;2.辽宁省化工工程工业智能化技术重点实验室,辽宁 沈阳 110142)
0 引 言
车辆检测是计算机视觉中的重要任务之一,在智能交通和自动驾驶等领域涉及较广泛。在雾天环境下,图像的对比度下降、可辨识度较低,严重影响车辆的检测效果,因此提高雾天车辆检测的准确性具有重要意义。
雾天环境下车辆检测分为两个阶段:去雾阶段和车辆检测阶段。针对去雾阶段,文献[4]提出了一种使用半全局加权最小二乘优化局部大气光去雾的算法,提高了去雾图像的亮度,但该算法在去雾的效果方面仍不理想。文献[5]通过级联直方图均衡化和NBPC+PA模型提高了去雾后图像的能见度,但该算法鲁棒性较差。文献[6]提出了一种融合亮度模型和梯度域滤波的算法,一定程度上提升了去雾的效果,但该算法模型较复杂,鲁棒性不够。
在车辆检测阶段,得益于深度学习强大的特征检测能力,基于深度学习的车辆检测算法发挥着越来越重要的作用。文献[8]提出了一种基于Faster RCNN和增量学习的车辆目标检测算法,改善了漏检错检的问题,但该算法检测精度较差。文献[9]提出了一种基于改进SSD的车辆检测算法,该算法通过网络剪枝与参数量化融合减少了模型的冗余参数,提升了检测速度,但检测精度有所欠缺。文献[10]提出了一种改进的YOLOv3算法,该算法通过增加网络输出层数在一定程度上提高了车辆检测的精度,但检测性能仍有所不足。
针对上述去雾算法效果较差、检测算法精度较低的问题,本文提出一种基于暗通道去雾算法和改进YOLOv3模型的雾天车辆检测算法。首先,在去雾阶段通过暗通道去雾算法降低雾气对图像检测的影响;其次,在车辆检测阶段使用K-means聚类算法计算出适用于车辆检测的先验框。YOLOv3算法的先验框由COCO数据集的图片进行预设,并不能完全适用于车辆检测,针对雾天车辆数据集计算先验框可以提高算法的精确度;最后,在YOLOv3算法的特征金字塔模块中引入注意力机制,注意力机制可以加强算法对特征的挖掘能力,提高算法的检测效果。
1 去雾算法
由于大气中的微粒会对光产生大量的散射,雾天图像质量会被不同程度地降低。基于上述原理,Narasimhan等人提出了解释雾天图像成像过程的大气散射模型,该模型的数学描述如式(1)所示。
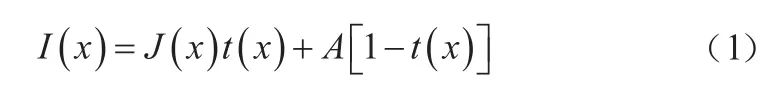
上述模型的适用条件是场景中的雾分布均匀。式中:表示像素点位置;()和()分别表示待恢复的无雾图像和原始雾图;()为场景透射率;表示大气光值。
暗通道先验理论(DCP)是对无雾图像属性的一种经验性观察,该理论认为在非天空的图像区域,总有一些像素点至少有一个颜色通道具有接近零的像素值。暗通道先验理论的数学描述如式(2)所示。

式中:()为像素点的邻域;{,,}表示每个像素的三个颜色通道;是图像的暗通道。
结合式(1)和式(2),可以得到图像的粗估计透射率()为:
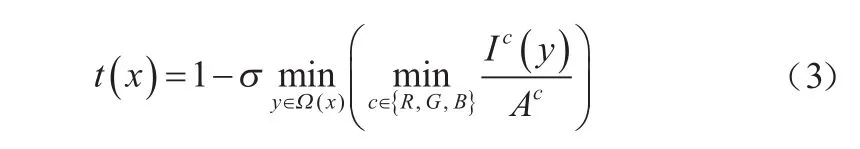
式中引入一个在[0,1]之间取值的修正参数,从而保留图像中远处的雾,使图像更自然。仿真结果表明,取0.95时复原效果最好。
将得到的透射率和大气光值代入大气散射模型中获得去雾图像,再对该图像做Gamma校正调整对比度,最终得到复原的去雾图像。
暗通道去雾算法的效果如图1所示。相较于原图,暗通道去雾后的图像更为清晰,车辆目标的轮廓更明显,对比度更强,有利于提高检测算法的精度。

图1 暗通道去雾算法效果
2 改进的YOLOv3
2.1 YOLOv3原理
YOLOv3算法由主干提取网络、特征金字塔网络(Feature Pyramid Network, FPN)和检测网络三部分组成,网络结构如图2所示。
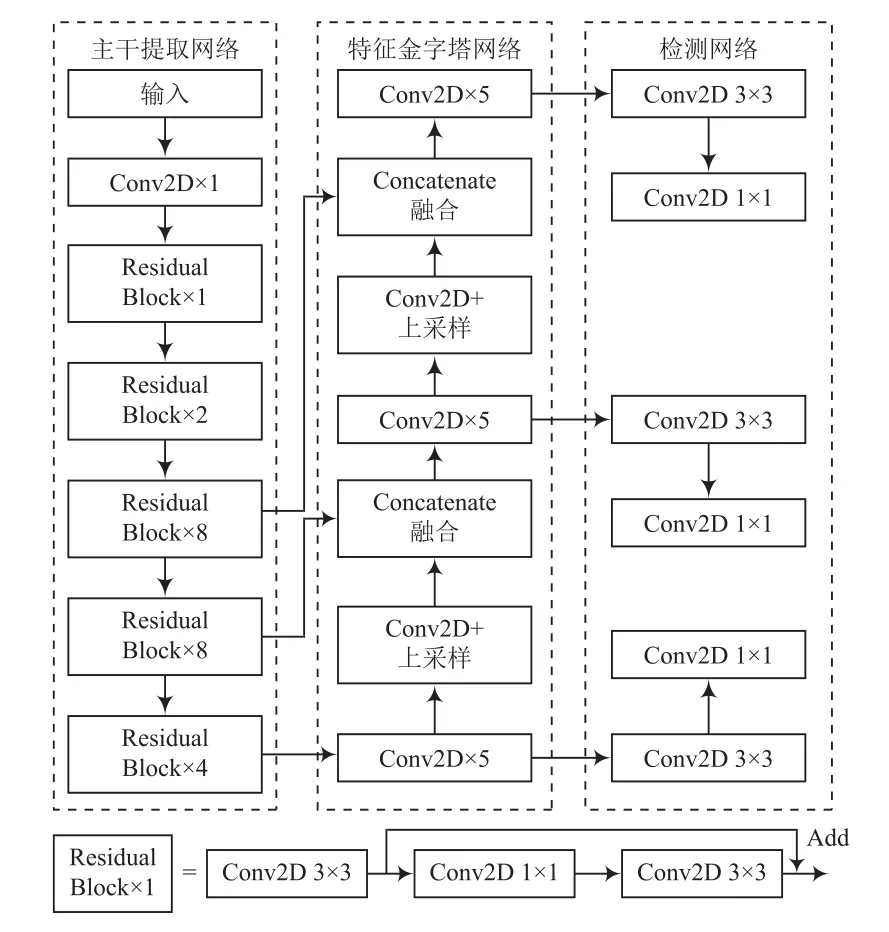
图2 YOLOv3算法网络结构
YOLOv3算法以DarkNet-53为主干特征提取网络。DarkNet-53通 过 3×3和 1×1的卷积层(Convolution Layers)跳跃连接,利用L2正则化、激活函数(Leaky ReLu)和批标准化(BatchNormalization, BN)提高模型泛化能力;同时引入了残差网络(Residual Network),减少了多层网络的训练难度,提升了检测的精度。
在特征金字塔模块,为了获取细粒度特征,YOLOv3对深层特征图进行上采样(UpSampling),再与浅层特征图进行Concatenate拼接。拼接后的特征图融合了深层和浅层的特征信息,提升了算法的检测性能。
为了使算法针对不同尺度的目标具有相同的检测效果,YOLOv3算法采用多尺度检测网络。从DarkNet-53中选取3种不同尺度特征图(13×13,26×26,52×52),对这三个特征图分别做3×3和1×1的卷积运算,并进行特征整合和通道调整,计算后的结果合并转移给损失函数。
YOLOv3算法的损失函数为回归损失、置信度损失和分类损失的加权和。在回归损失中采用误差平方和,在置信度损失和分类损失中采用交叉熵损失,各损失计算的数学描述如式(4)所示。
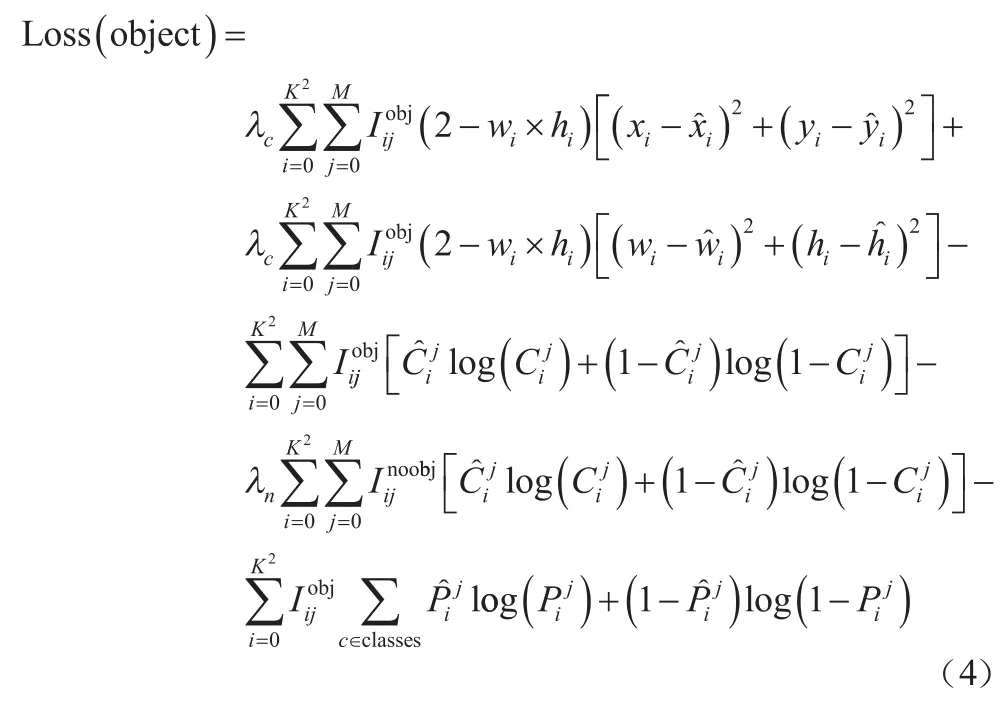

YOLOv3算法在目标检测方面具有较好的性能,但在应用于雾天车辆检测时存在以下问题:(1)YOLOv3算法的框不能完全适用于车辆检测;(2)多尺度检测网络虽然对特征进行了整合,但是并没有加强对特征的提取,还存在对特征挖掘不足的问题。针对以上问题,本文对YOLOv3进行了相应的改进。
2.2 K-means计算先验框
YOLOv3算法的先验框是根据COCO数据集预设的,不能很好地适用于本文的雾天车辆检测数据集。为了使算法能够更加准确和快速地对车辆进行检测,通过K-means聚类算法对本文数据集中的真实框(Ground TrueBox)进行分析。
传统的K-means聚类算法多以欧氏距离来计算对象间的距离,但是对先验框使用欧氏距离计算时,大先验框的误差更大,因此使用改进的交并比(IOU)公式进行计算,如式(5)所示。

式中,IOU表示聚类中心与真实框的重合程度,其数学描述如式(6)所示。
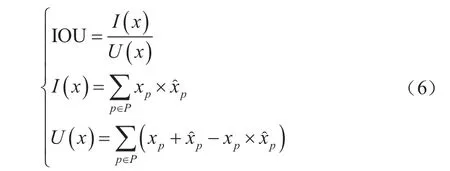
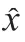
2.3 注意力机制的引入
CA(Coordinate Attention)模块是一种融合位置信息和通道信息的注意力机制,在空间和通道维度上加强了特征挖掘能力,其网络结构如图3所示。

图3 注意力机制网络结构
全局池化可以在通道注意力中采集空间信息,但是难以保留位置信息。为了将位置信息嵌入到空间信息中,将全局池化分解为两组一维的池化。对尺寸为××的输入,分别使用尺寸为(,1)和(1,)的池化核沿着水平和竖直方向对每个通道进行编码。高度为和宽度为的第个通道的输出分别为:
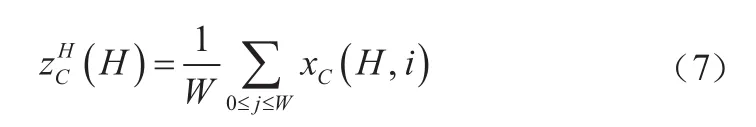

将这一对输出的池化结果进行Concatenate级联,然后使用一个共享的1×1卷积对其做变换,如式(9)所示。

其中,表示下采样比例。沿着空间维度将划分为两个单独的张量f∈ R和f∈ R。使用两个 1×1 卷积F和F将特征图f和f变换到与输入同样的通道数,如式(10)和式(11)所示。
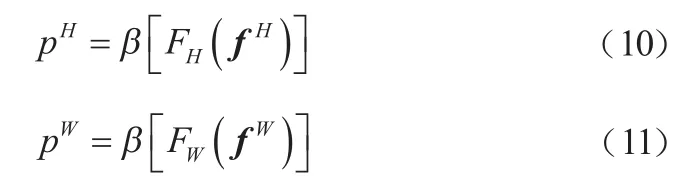
对p和p进行拓展,作为注意力权重,添加到输入中。CA模块的最终输出如式(12)所示。

最终通过CA模块,对输入完成了水平和竖直方向的特征挖掘。
3 实验分析
3.1 实验环境与参数
本文实验环境为:11th GenIntel Corei5-1135G7@2.4 GHz,8 GB内存,NVIDIA Geforce MX450 2 GB,64位Windows10操作系统。编程语言为Python,框架为Pytorch1.8.1,GPU加速库为CUDA11.1和cuDNN7.65。
在本文的实验中,将数据集图片的尺寸统一缩放到416×416,设置参数Batchsize为4,学习率为0.001,使用Adam优化器调整网络的学习率。实验的训练周期为100个Epoch,直到Loss不再变化,自动终止训练。
3.2 数据集
本文使用的数据集为自制的雾天车辆检测数据集,包含13 526张图片,按照7∶2∶1的比例划分为训练集、验证集和测试集。由于自制的数据集图片数量有限,为了让模型更好地学习到目标特征和提高鲁棒性,需要对数据做数据增强。
本文采用Mosaic数据增强算法。Mosaic算法的流程有三步:(1)在数据集中随机选取四张图片;(2)对这些图片进行缩放、剪切和水平变换,裁剪的过程中保留含有待检测目标的区域;(3)将这四张图片合并处理为一张。通过Mosaic算法的数据增强,丰富了数据集的检测背景,提高了模型训练后的泛化能力。本文雾天车辆数据集的Mosaic数据增强效果如图4所示。

图4 Mosaic数据增强效果
3.3 评价指标
对训练后模型的检测平均精度(mean Average Precision,mAP)进行对比。mAP的计算如式(13)~(16)所示。

式中:TP为真正例;FP为假正例;FN为负正例;为种类数。
3.4 聚类计算先验框
对雾天车辆检测数据集进行K-means聚类分析后,得到9种先验框的尺寸。K-means聚类计算先验框的结果对比见表1所列。
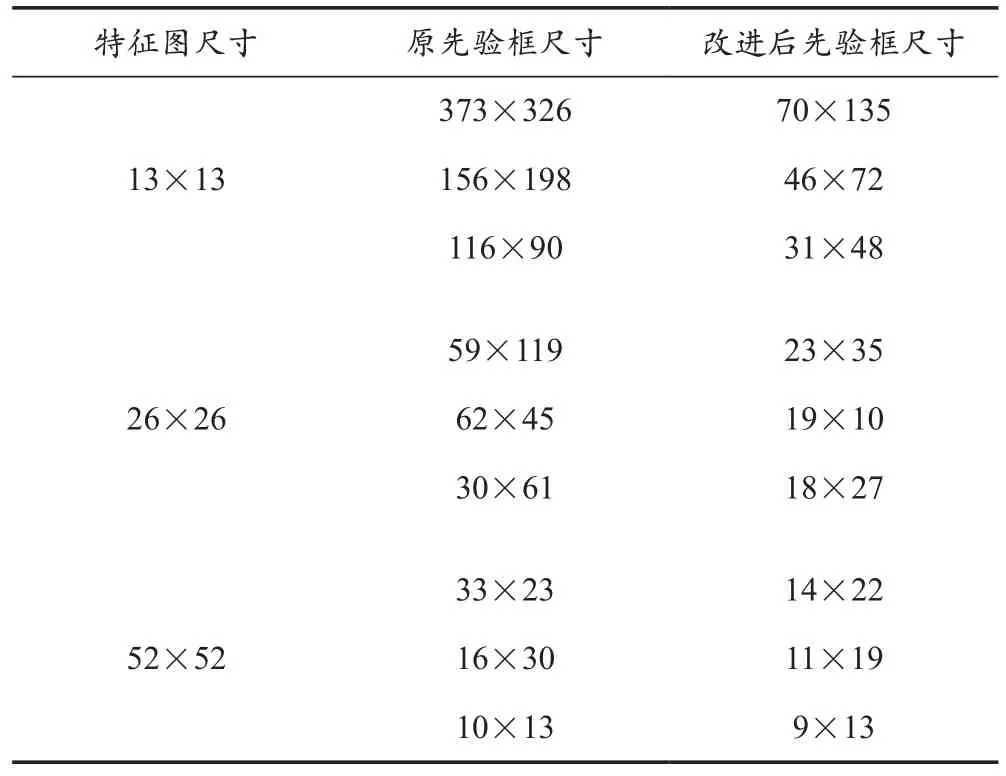
表1 K-means聚类计算先验框结果对比
在尺寸为13×13的特征图中具有最大的感受野,采用70×135、46×72、31×48这三种尺寸的先验框检测最大的车辆。相较于原先验框的平均宽高比1.04,改进后的先验框尺寸更小,平均宽高比为0.61,更适用于本文数据集。在尺寸为26×26的特征图中,采用23×35、19×10、18×27这三种先验框检测图像中尺寸较大的车辆。在尺寸为52×52的特征图中具有最小的感受野,采用14×22、11×19、9×13这三种尺寸的先验框检测小目标车辆。综上所述,改进后的先验框尺寸更小,平均宽高比更适用于本文数据集,有利于提升小目标车辆的检测精度。
3.5 对比实验
为了验证本文算法对雾天车辆的检测性能,将本文算法与目标检测算法效果良好的SSD、Faster RCNN、YOLOv2和YOLOv3在雾天车辆数据集上进行实验对比。5种算法的实验结果对比见表2所列。

表2 5种算法的实验结果对比
从表2中可以看出,本文算法比SSD算法的mAP提升了11.8%。SSD的卷积层较少,特征提取不够充分,导致检测效果欠佳。相较于Faster RCNN,本文算法的mAP提高了5.9%。Faster RCNN 使 用 RPN(Region Proposal Networks)推荐候选区域,针对多尺度的目标不能保证较好的检测效果。与YOLO系列的算法相比,本文算法比YOLOv2的mAP提升了14.9%,比YOLOv3提升了4.1%。本文算法基于YOLOv3进行了相应的改进和拓展,提升了对雾天车辆的检测性能。对比本文算法和YOLOv3算法对雾天车辆检测的效果,如图5所示。

图5 雾天车辆检测效果对比
3.6 消融实验
为了验证本文改进方法的有效性,以及不同改进策略对检测效果的影响,以YOLOv3算法为基础作消融实验,实验结果见表3所列。

表3 消融实验结果对比
由表3可知,单独引入去雾算法时,算法的mAP提了0.8%;单独使用K-means聚类计算先验框时,mAP提升了1.2%;单独向模型中加入注意力机制时,mAP提升了0.5%。组合使用去雾算法和聚类先验框使算法的mAP提升了3.2%,利用去雾算法和注意力机制使算法的mAP提升了2.3%,引入聚类计算先验框和注意力机制使算法的mAP提升了3%。最后将三种改进策略添加到模型中,得到的本文算法将mAP提升了4.1%,因此本文提出的改进策略对提升雾天车辆检测效果具有有效性。
4 结 语
本文针对雾天车辆检测准确率较低的问题,提出了一种基于暗通道去雾和改进YOLOv3的检测算法。首先利用暗通道方法对图像进行去雾,然后通过K-means聚类计算适用于车辆检测的先验框,最后引入注意力机制,加强了算法对特征图的特征挖掘能力。通过以上改进,本文算法对雾天车辆检测具有良好的性能。
与主流的目标检测算法相比,在雾天车辆检测数据集上,本文算法具有更好的检测精度,mAP达到了97.5%。下一步将在引入去雾算法和网络模型的基础上,针对算法的复杂度进行研究,以提高算法的检测速度。
