基于时间编码LSTM的高校舆情热点趋势预测研究
2022-09-18易杰曹腾飞黄明峰黄肖翰张子震
易杰,曹腾飞,黄明峰,黄肖翰,张子震
1. 青海大学计算机技术与应用系,青海 西宁 810016;
2. 云上贵州大数据产业发展有限公司,贵州 贵阳 550081
0 引言
随着互联网通信技术的快速发展,多样的新媒体平台(如微博、抖音、贴吧等平台)将信息及时推送给用户,使得社会发生的实时新闻能迅速传播。据中国互联网络信息中心发布的第47次《中国互联网络发展状况统计报告》统计,截至2020年12月,我国网民规模达9.89亿,其中学生占比最高[1],达到21%。新时代下高校学生作为互联网用户的主要群体,在网络上的参与度以及活跃度比较高。当高校突发一些热点事件时,由于高校学生思想活跃并且乐于表达自我看法,实时热点问题会引发激烈的讨论[2]。若舆情信息的价值取向是负面的,则极易带偏高校学生的思想观念,从而引发一系列高校舆情管理问题,高校舆情管理的重要性不言而喻[3]。
近些年,高校舆情事件频频发生,其中舆情信息的主题主要围绕社会时事、校园安全、师风师德、学术造假等方面,例如研究生校内身亡、高校实验室爆炸、学生违纪违法等事件。在事情的真相还未正式公布时,网络上各种评论的助推极易导致错误的舆情发展方向,引发一系列高校以及社会舆情管理问题[4]。高校舆情发展一般是阶段性的,初期由个别大学生在网络上发布自己对某个问题的想法,而后随着时间的推移,逐渐引起大范围的关注,引发更多的讨论。一般情况下,网络舆情的发展趋势遵循新闻传播学中的“沉默螺旋效应”,大多数人支持的意见会因为更多的人赞同而越来越流行;而少数人支持的观点会逐渐减少直至最后消失[5]。基于此原理,若舆情的发展趋势能比较及时、准确地被预测,高校有关部门就能在短时间采取相应的应对措施,合理地解决问题,以达到对舆情发展进行管控的目的。因此,对高校舆情的发展趋势进行预测,有助于新媒体时代下的大学校园完善管理体系,及时预测舆情发展趋势并加以正确的引导[6],能极大地提升高校对突发舆情事件的处置水平[7-8]。
基于上述分析,对舆情热度的预测分析显得尤为重要,不仅关乎高校学生的思想健康发展,而且关乎整个社会的价值观取向和稳定性。由于舆情信息的发展一般会随着时间变化,当获取到舆情的时序数据后,需要对数据进行分析处理,找到数据的变化和发展趋势,对未来舆情事态的发展做出预测,以便及时管控。随着互联网技术的发展,在大数据和人工智能等技术的推动下,时序数据处理的有效性逐渐提高。因此,本文利用长短期记忆网络(long short-term memory,LSTM)对时序数据处理的有效性,研究基于时间编码的LSTM模型。LSTM对时序数据的处理具有极大的优势,但是其只考虑了数据相对的先后顺序,不包含绝对的时间意义,如LSTM在自然语言处理任务上的应用[9]。对输入数据加入时间编码,即在使用LSTM处理数据时,同时考虑热点话题发生的具体时间,以实现对高校舆情热点的精准预测。与支持向量机(support vector machine,SVM)和循环神经网络(recurrent neural network,RNN)两种模型的预测结果进行对比发现,基于时间编码的LSTM在热度预测准确率上具有明显优势。
1 相关工作
1.1 舆情分析和预测
高校舆情经常引发全社会的广泛关注,而舆情的正确引导对于高校管理以及社会的稳定发展有着十分重要的意义。参考文献[10]针对高校在舆情管理和引导工作中遇到的挑战与问题,构建以“大数据”为支撑、新媒体为载体、机制创新为保障的“三位一体”的舆情管理和引导的工作模式,营造了良好的校园舆论生态环境。该参考文献考虑了高校舆情对学生意识形态管理的意义,并提出引导舆情向正确方向发展的策略,然而其在舆情发展趋势预测方面的考虑不足,导致难以有效地引导舆情的发展[11-13]。在网络舆情预测的研究方面,参考文献[14]针对区间犹豫模糊集在描述决策信息时会导致决策信息重要性程度降低这一问题,构建了一种基于概率区间犹豫模糊几何算子的多属性群决策模型,且通过网络舆情预测系统的选择实例验证了所提决策模型是可行和有效的。秦涛等人[15]提出一种基于排序学习的舆情事件演化趋势重要性评估算法。在模型训练过程中,充分利用标注数据中的专家知识以及有标签数据和无标签数据的关联关系,筛选出重要舆情事件并进行管控,提升了资源的利用效能。参考文献[16]以网络流文本为对象,通过分析网络话题内容焦点的迁移特性,提出了网络话题内容焦点的识别方法。上述方法由于模型训练未考虑舆情事件的动态变化性,预测准确率不高,还需要进一步增强模型的适应性。
1.2 舆情时序数据处理
由于舆情热度数据按照时间序列变化,刘定一等人[17]针对单一模型预测精度不高和社交媒体对舆情走势影响较大的问题,提出了融合微博热点分析和LSTM的舆情预测方法。然而特征集的数量较少,网络舆情谣言识别的准确率还有待提高。笱程成等人[18]利用深度循环神经网络对社交消息的传播过程进行建模,提出了SMOP模型。该模型由于优化目标单一,未考虑通过联合建模优化来进一步提升预测准确率。彭丹蕾等人[19]针对如何高效挖掘处理大量评论数据并进行情感分析的问题,采用SVM和LSTM分别对从京东网站爬取的商品评论进行建模。由于情感分析涉及的学科跨度比较大,并且采集的数据集比较单一,该模型适应性不强。为了有效监控和管理新型冠状病毒肺炎疫情引起的网络舆情,景楠等人[20]基于差分自回归移动平均(autoregressive integrated moving average,ARIMA)模型以及LSTM预测和分析舆情数据,对舆情模型进行参数估计、模型诊断和模型评价。由于未考虑各地区疫情发展的影响因素不同,该模型适应性不足。张陶等人[21]针对无属性社交网络的节点分类问题,提出了一种基于图嵌入与SVM的社交节点分类方法。由于采用静态的社交网络数据集进行模拟,该方法对动态社交网络的适应性不足,应用范围受到限制。针对方面情感,宋婷等人[22]提出基于方面情感分析的深度分层注意力网络模型,利用改进的LSTM获取句子内部和句子间的情感特征。由于未包含跨领域的词汇和网络用语句子的方面情感分析,该模型的情感分类效果有待进一步提高。
根据以上分析,现有的时序数据处理模型存在算法预测精确度不够高、特征集和数据集比较单一的问题,并且很少结合舆情数据动态更新预测值。本文在对高校舆情数据进行处理时,利用关键词匹配全面考虑高校的相关信息,目的在于提高对高校舆情信息预测的准确率。结合时间编码方法,对舆情热度数据的绝对时间因素进行分析,可以解决L S T M处理时序数据时仅考虑数据先后关系的问题。同时利用实时舆情数据动态更新预测值,使得预测精确率进一步提升。本文提出基于时间编码L STM的高校舆情热点趋势预测研究方法,动态调整评估参数。本文研究主要包括以下5个方面:一是获取微博热搜数据集合;二是通过降维、筛选、升维3种方法对数据集进行处理;三是将热点话题的时间编码加入数据集并进行归一化处理;四是生成训练集和测试集,利用训练集训练模型并生成预测模型,再利用测试集进行模型预测;五是对比分析预测值与真实值,最后评估各个模型的性能,验证了基于时间编码的L S T M在舆情热点时序数据处理方面的优越性。
2 模型介绍
2.1 LSTM模型
RNN在时序数据处理过程中会保留之前所有输入数据信息。一方面,随着后序数据的输入,先前的输入对模型隐含层的影响会越来越小,即长距离的依赖问题;另一方面,一些不重要的信息将被RNN保留。为了克服上述困难,LSTM被提出,该模型具有保持长期记忆性的特点,在时序数据处理方面具有良好的性能,LSTM结构如图1所示。LSTM模型的构建如下。

图1 LSTM结构
首先,对输入数据xi-1和隐含状态hi-1进行运算,得到LSTM的遗忘门,如式(1)所示:
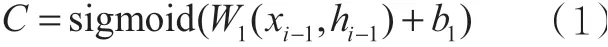
在式(1)中,对输入数据xi-1、隐含状态hi-1与遗忘门的权重W1进行线性运算,b1表示引入的偏置项,再经过sigmoid激活函数引入非线性元素,此时C⊂(0,)1。C越大,记忆的部分越大。将C与当前的长期记忆状态ci-1相乘并输出,即遗忘门的输出表示对长期记忆状态的记忆程度,如式(2)所示:
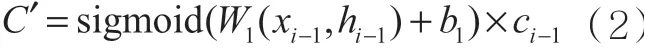
接下来计算LSTM的输入门部分,图1中si表示输入门的sigmoid神经网络层,符号×表示点乘运算操作,激活函数tanh将输入的新信息归一化到(-1,1),通过点乘运算对信息进行缩放,决定保留哪些新信息,如式(3)、式(4)所示:
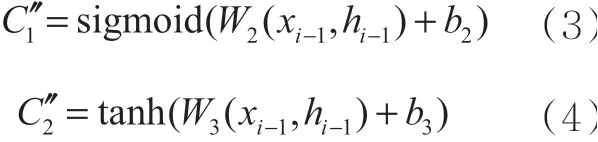

通过上述过程,LSTM模型可以完成对已有长期记忆元素的更新,如式(6)所示:

其中,ci将被用于下一层LSTM的计算。与RNN相比,LSTM在输出时也进行了一定的改进。LSTM在输出时综合考虑了当前长期记忆和当前输入数据的影响,如式(7)所示:
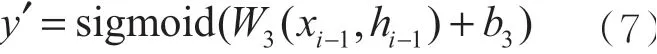
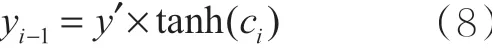
使用tanh函数激活当前长期记忆结果的值,得到LSTM的实际输出,yi-1表示当前时刻的话题热度。
2.2 损失函数与优化
在训练模型时,需要将损失函数的值降至较低水平,以提高模型性能。损失函数是衡量神经网络性能的重要参考指标,通常损失函数在测试集上的结果越小,模型的性能越好。常用的损失函数有适用于回归问题的均方误差(mean square error,MSE)损失函数和适用于分类问题的交叉熵(cross entropy)损失函数等。对高校热点舆情话题的预测属于回归问题,因此将MSE作为损失函数,如式(9)所示:
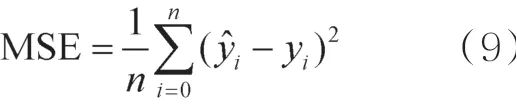
时序数据通常具有隐含关系。通过神经网络的训练,挖掘数据的潜在特征,从而实现对数据的预测,即神经网络目标是一个回归任务。因此选择MSE对损失函数进行优化,提升模型性能。
2.3 评价指标
除了M S E,还可将平均绝对误差(mean absolute error,MAE)和平均绝对百分比误差(mean absolute percentage error,MAPE)作为模型的评价指标。
MAE表示预测值与真实值之间的误差平均绝对值,如式(10)所示:
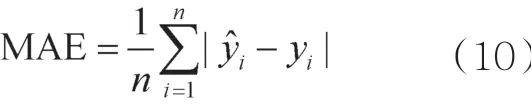
MAE能更好地反映预测值误差的实际情况(已经经过归一化)。模型测试数据的MAE越大,预测误差越大。MAPE表示预测值与真实值的平均差距百分比,如式(11)所示:
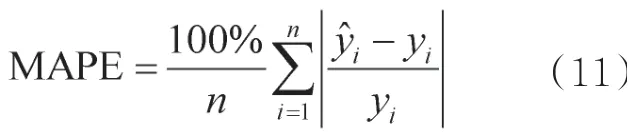
值得注意的是,一个较好的评估模型的MAPE值应该为0,其表示预测值与真实值之间没有差别。
3 实验与分析
3.1 数据集的获取
本研究使用的数据集来自新浪微博热搜榜,由于微博是一个实时信息交流分享平台,一旦舆情信息出现,将在短时间内迅速传播,因此分析微博热搜数据的热度变化趋势具有重要的研究意义。
具体的热度数据采集过程如下,首先通过Python框架对页面内容进行解析,并定义需爬取的字段,接着从某个时刻开始,每间隔15 min对热搜榜数据进行一次爬取,例如从0:00起,采集0:00、0:15、0:30等时间点的数据。如果热点话题仍在热搜榜上,就继续采集并添加热度值;否则,将新上榜的热搜数据添加至表中,最后保存所收集的数据,用于后续实验分析。热搜榜每次显示50个热点话题,按照其搜索热度进行排名。
由于研究对象是包含时间序列关系的话题名和热度值,因此将收集到的数据按照时间变化存储,对于某时刻不在热搜榜的话题,其在该时刻的热度为空。最终用于实验仿真的数据包含排名、关键词、热度、热度标识、时间5个维度,共15 000余条数据。整理收集到的数据,部分热搜数据示例见表1。
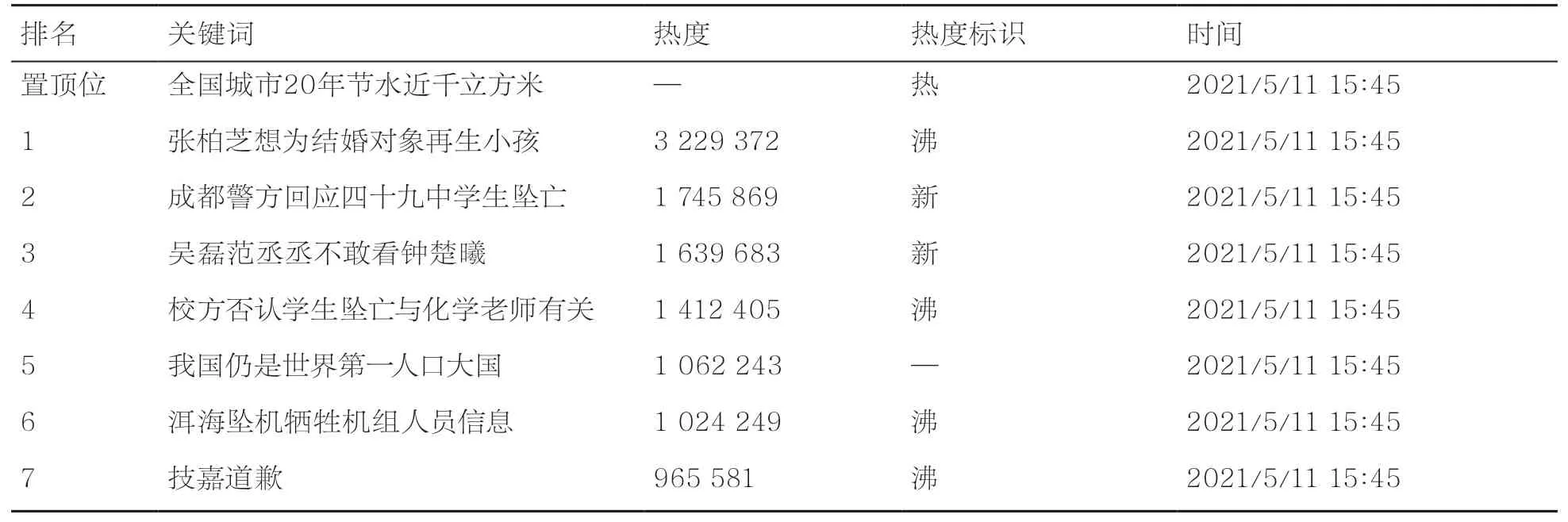
表1 新浪微博部分热搜数据示例
3.2 数据集的处理
3.2.1 降维
本文针对话题热度值进行预测,在获得原始数据集后,首先对数据集进行降维处理,删减与本文研究内容无关的维度,去掉冗余变量,这有助于提高算法的准确率。一方面,微博热搜榜的“爆”“沸”“热”等热度标识来源于实时热度值高低,热度标识与热度值意义重复,关系冗余,因此将数据集的热度标识维度删除。另一方面,微博话题热度序号只显示热度排名前50的话题,而热搜榜在实时变化,某一时刻的热度排名只与该时刻的话题热度有关,在对热度进行预测时,该时刻的相对排名对于研究意义不大,因此将热度排名维度删除。通过对数据集的降维处理,可以节约高校舆情热点趋势预测方法的训练时间。降维后的热搜数据示例见表2。
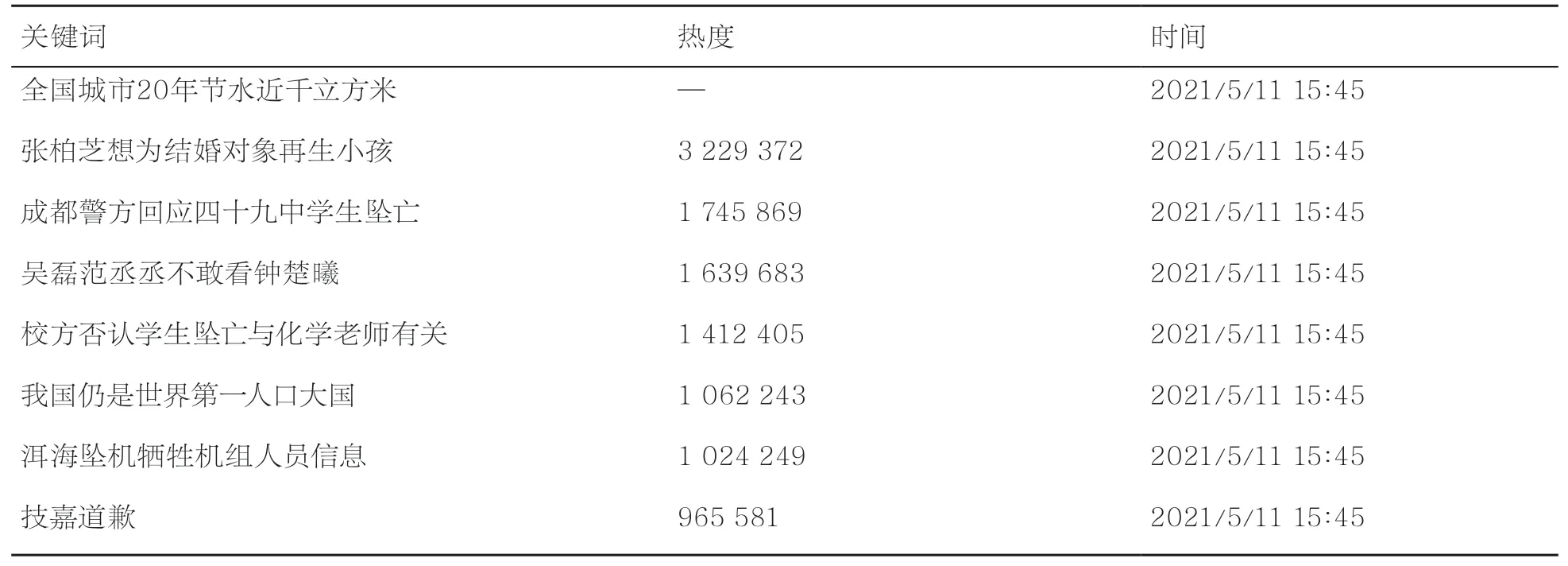
表2 降维后的热搜数据示例
3.2.2 升维
在收集舆情数据时,按照15 min的间隔进行收集。热点话题在热搜榜不断地出现或消失,在存储某一时刻的热搜榜数据时,下一时刻该话题的热度数据可能消失,新的话题可能出现,因此在数据的整合和存储方面,需要考虑热搜话题变化带来的数据维度不一致问题。
针对上述问题,对原数据集进行升维操作,在原始数据基础上增加时间序列维度,按时间顺序记录每一数据爬取时刻的热度值。若话题热度不够高,未进入热搜榜或热度已经下降并离开热搜榜,则该时刻的热度值为空。升维后的热搜数据示例见表3。
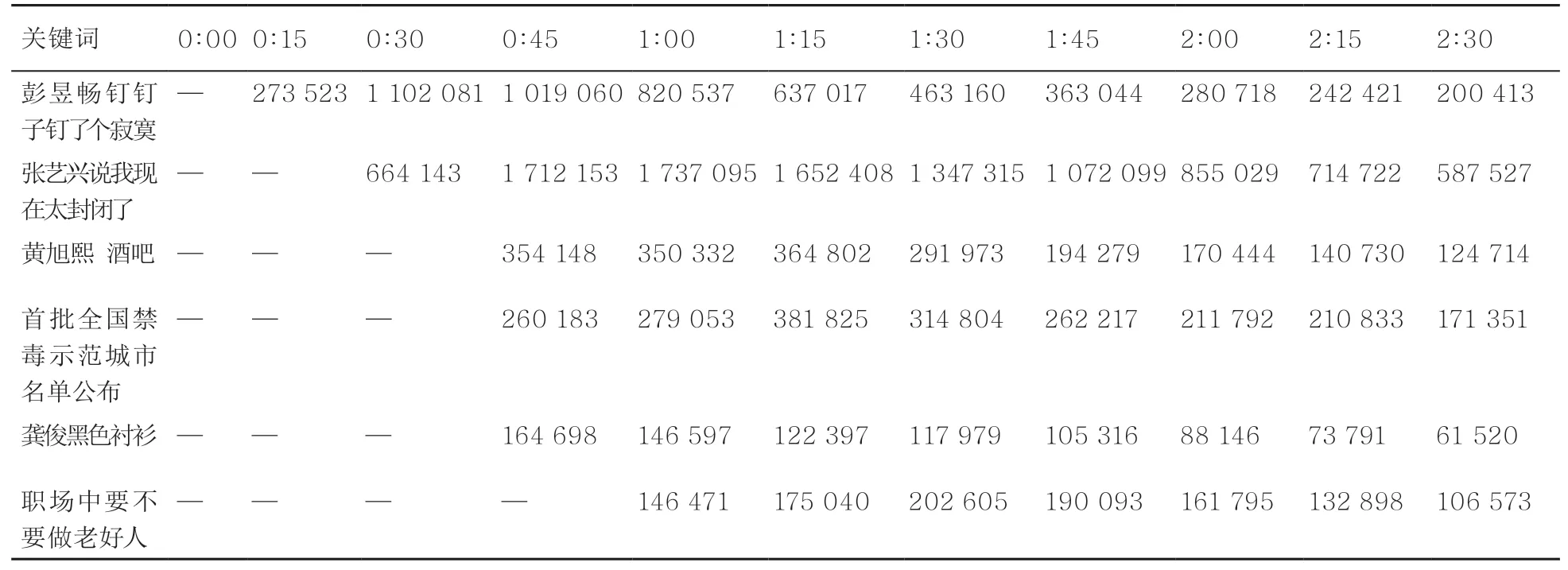
表3 升维后的热搜数据示例
3.2.3 筛选
微博热搜榜的话题包含娱乐、体育、民生、时政等多个话题类型,本文针对高校舆情类话题进行研究,因此需要对热搜话题进行筛选。针对与高校舆情相关的话题,通过关键词方式进行筛选。在获得的数据集中,将“高校”“大学”“学院”等与高校相关的话题关键词表示为集合K={k1,k2,k3,…},若话题与集合无交集,则为无关话题,对无关的话题进行忽略处理。对舆情话题进行分词处理,分词前后的话题见表4。

表4 分词前后的话题
接着将分词后的舆情话题与高校关键词集合K进行匹配与筛选,保留与高校舆情相关的热点话题以及热度值变化情况,去除与高校舆情无关的数据信息,筛选后的高校热点数据见表5。
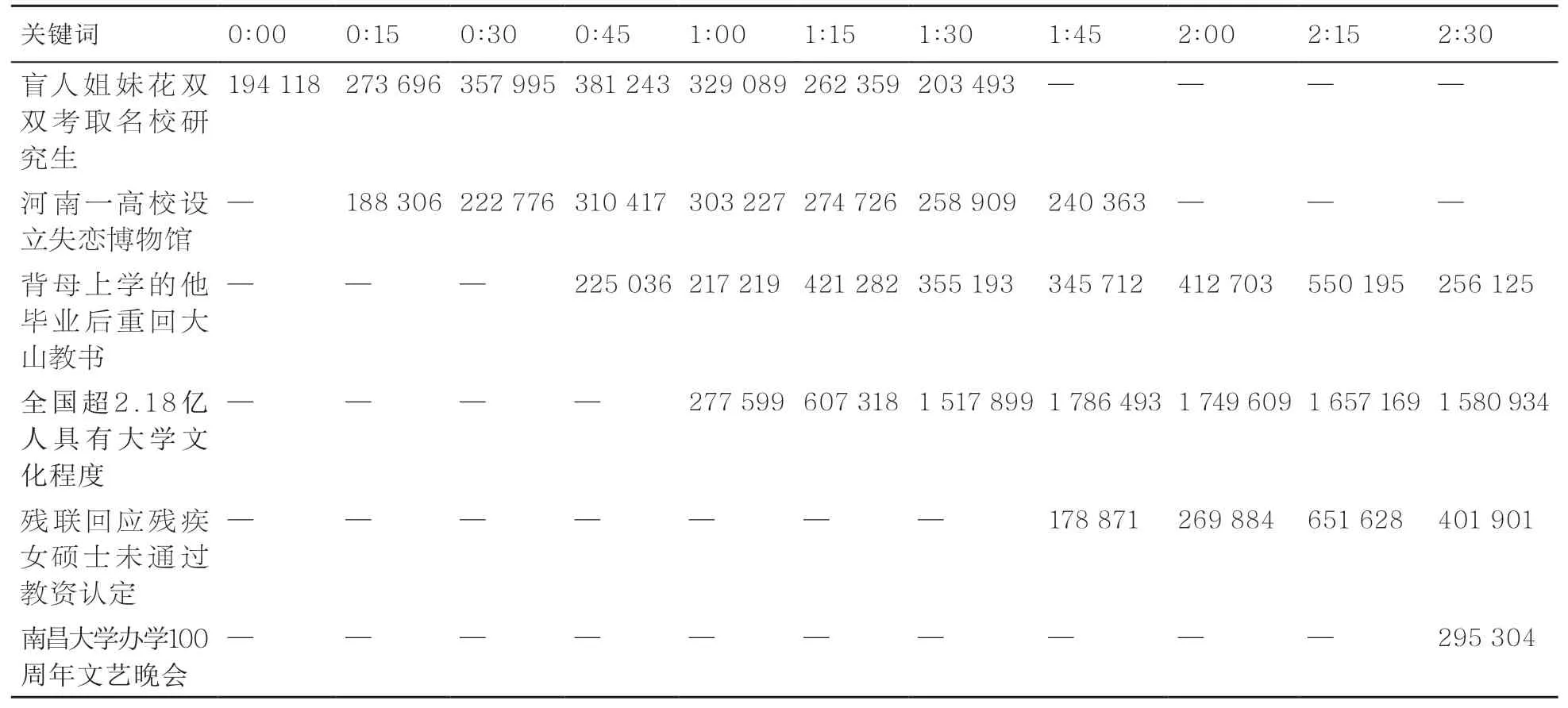
表5 筛选后的高校热点数据
3.3 时间编码与归一化
在对数据进行归一化处理之前,首先加入时间编码,具体过程是对收集数据的每个时刻进行编码,例如从0:00开始收集数据,0:15的时间编码参数是0.25,0:30的时间编码参数是0.5,0:45的时间编码参数为0.75……具体的时间编码参数设置过程是将每小时分为4个部分,每部分占比为25%,若当前时刻为H时M分,编码参数设置为。对高校舆情数据进行时间编码的优势是,若热度持续时间大于或等于24 h,此时时间编码大于或等于24,规定从0进行编码。在时间编码后,舆情数据之间的前后关系由于含有绝对时间的编码参数,舆情热度会随着时间发生变化,因此进一步结合不同时间段的舆情数据进行分析,可以提高舆情热度预测的准确率。接着对数据进行归一化操作,对以十万甚至百万为单位的热度数据进行归一化处理,能加速模型收敛,提高模型精度。热度数据归一化可以对每个热点话题的时间变化序列数据进行归一化,也可以针对所有热度值进行归一化。考虑到每个话题的热度变化范围不同,某些话题的峰值热度可能仍低于其他话题的中等热度,导致归一化后的相对热度表示误差较大,因此采用整体归一化的思路进行处理。数据归一化表示为:

在式(12)中,x表示某一时刻的热度值,xmin表示该话题的最小热度值,xmax表示该话题的最大热度值。通过热度值的归一化,有效地减小了热度值范围跨度。在后续神经网络训练及预测时,数据不会因为微小扰动而产生巨大误差,因此数据拟合与损失函数的收敛速度将进一步提高。
3.4 RNN、SVM、LSTM和基于时间编码的LSTM的舆情热度预测
首先将数据集分为训练集和测试集两类,将数据集的70%作为训练集,30%作为测试集。训练时设置学习批次大小为128,使用随机梯度下降法对模型进行优化,学习率设置为0.01,损失函数使用MSE。为了进一步对比验证时间编码的优势,与不含时间编码的LSTM进行对比。
实验一共进行100轮训练,使用梯度下降法反向传播误差,更新隐含层权重
经过100轮训练,损失函数已经趋于零,说明模型性能基本达到最优。RNN、SVM、LSTM和基于时间编码的LSTM在训练集上的预测效果分别如图2、图3、图4、图5所示。其中,SVM使用高斯核函数,该核函数的参数gamma设置为0.1。
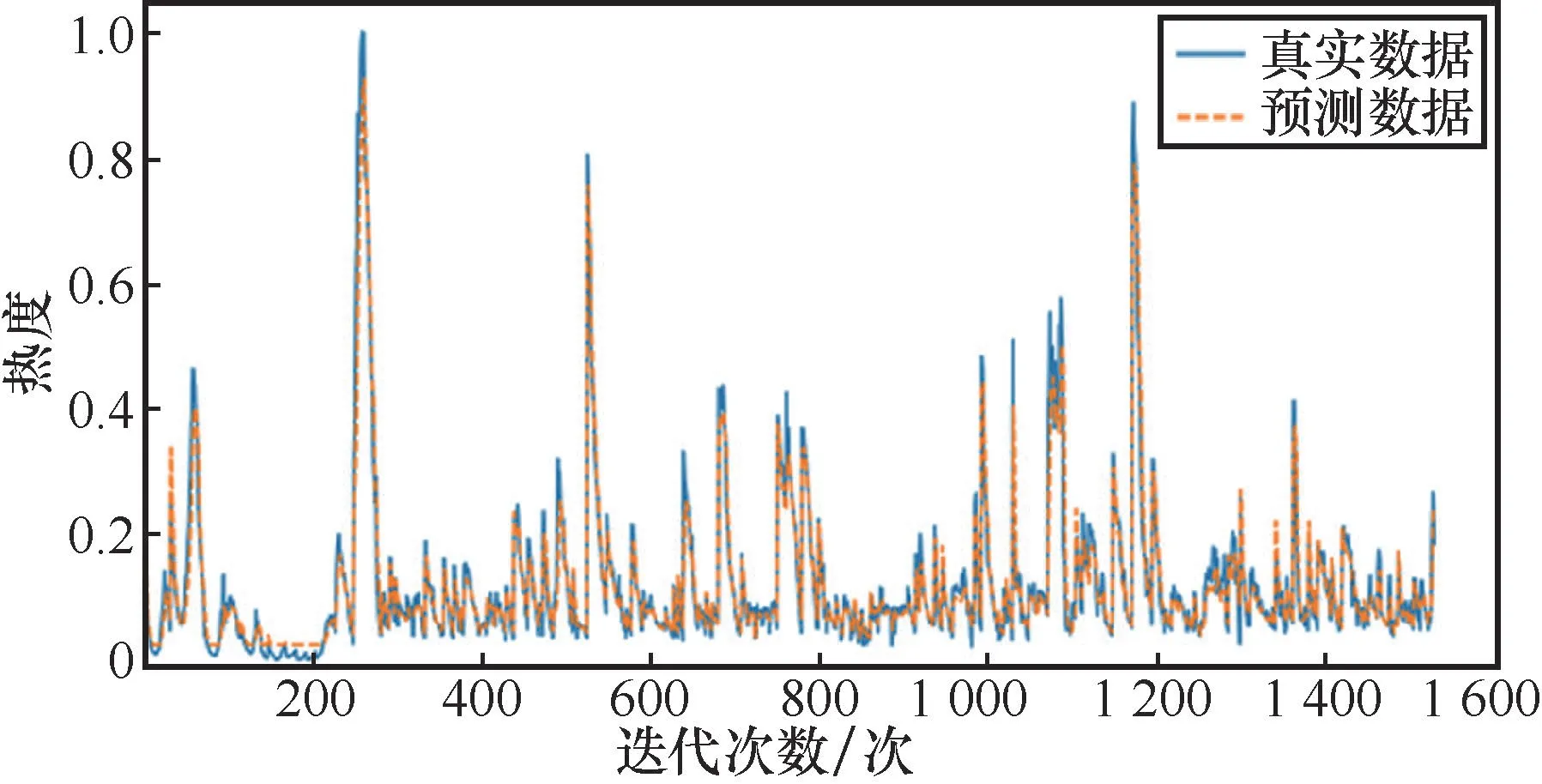
图2 RNN训练集预测效果
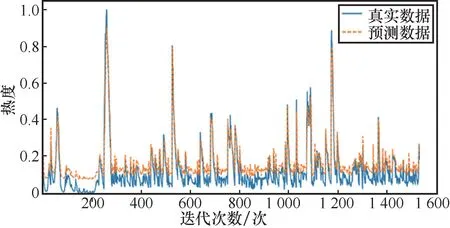
图3 SVM训练集预测效果
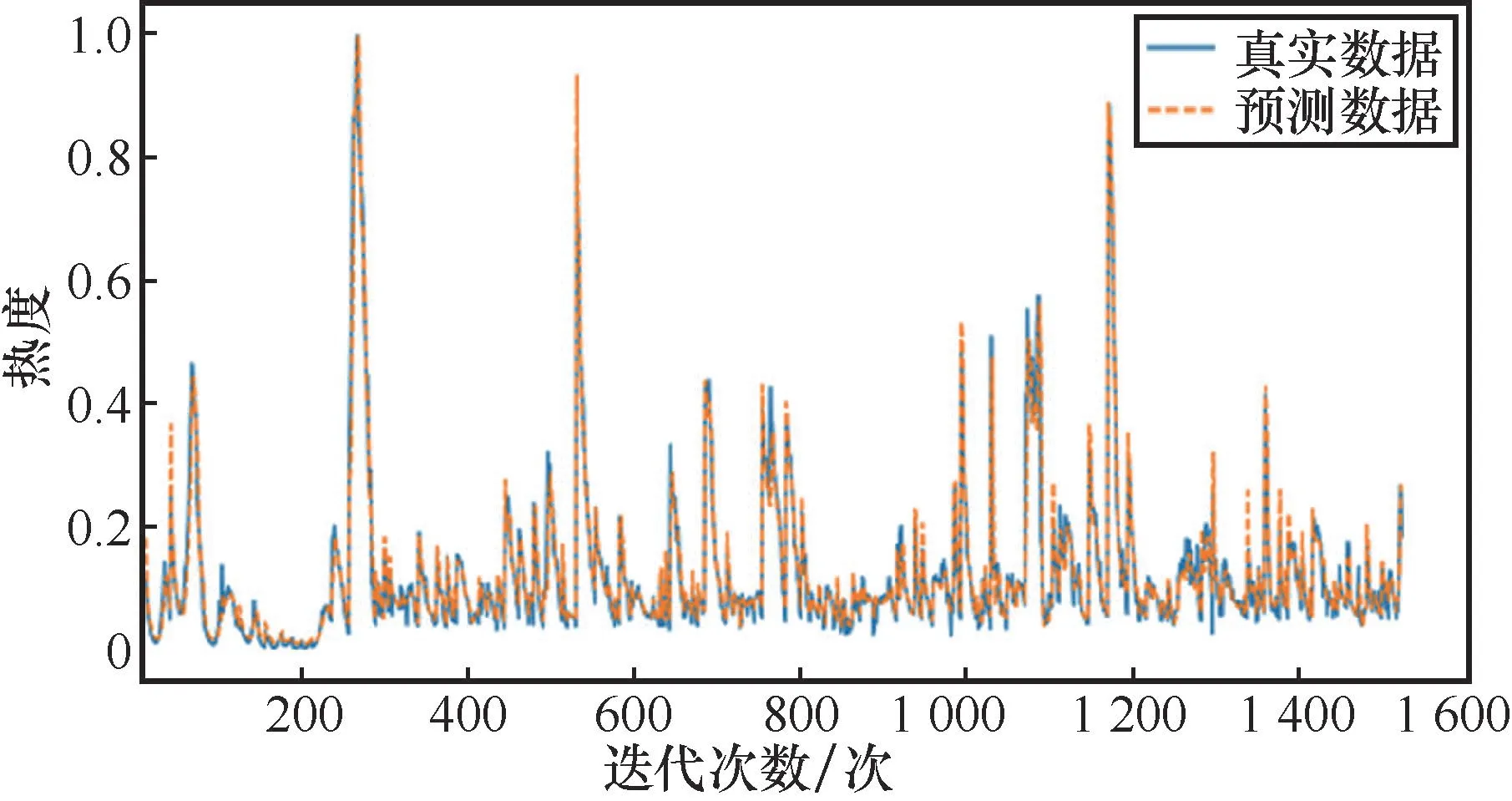
图4 LSTM训练集预测效果
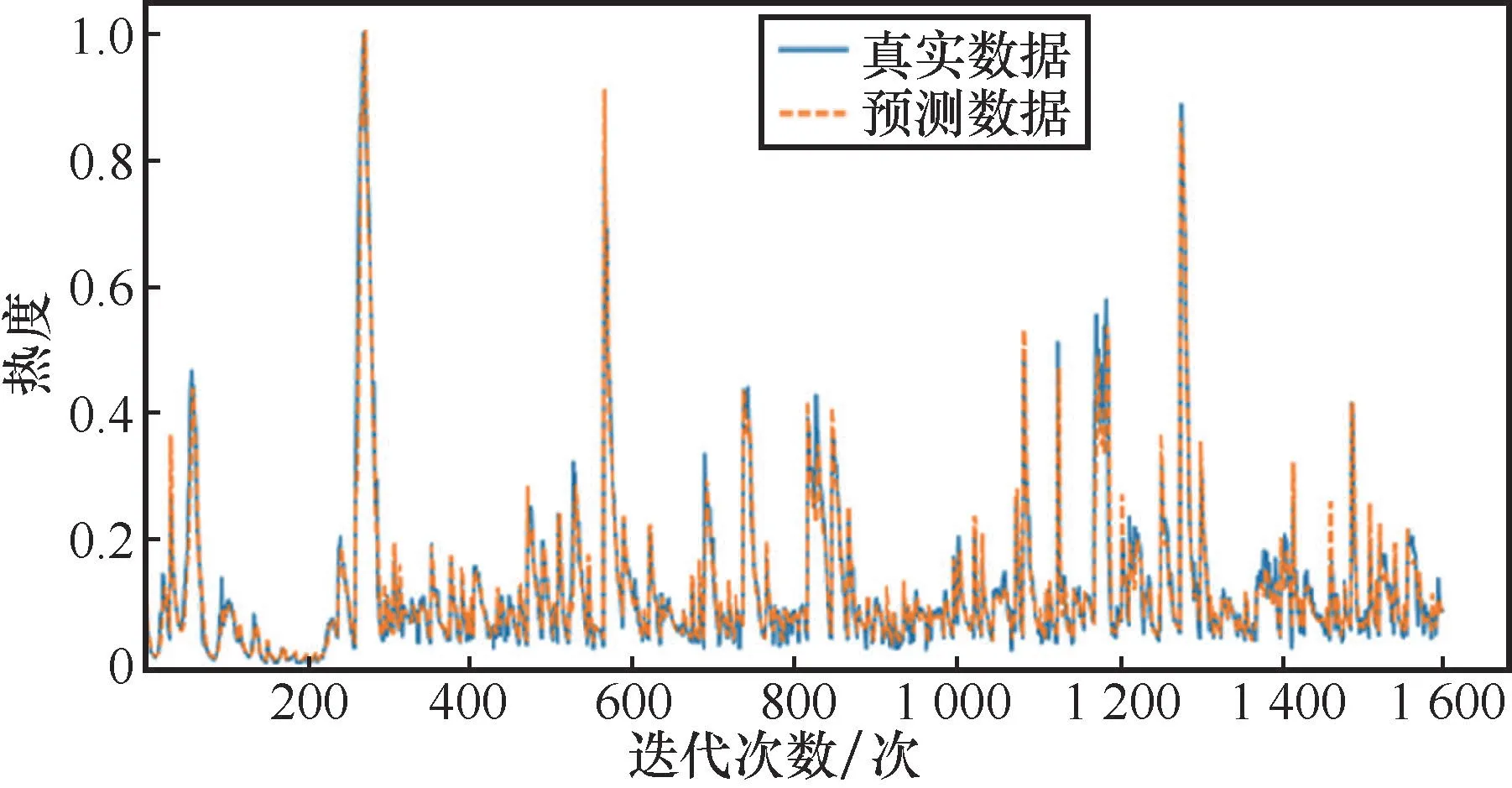
图5 基于时间编码的LSTM训练集预测效果
从图2~图5可以看出,基于时间编码的LSTM的预测性能略优于普通的LSTM,同时预测结果也比SVM、RNN更加准确,原因在于基于时间编码的LSTM不仅对时间序列数据保持长期的记忆性,而且具有更新数据信息的能力。同时,加入时间编码后,LSTM在舆情热度值与绝对时间之间建立了相应的联系,因此其在舆情趋势预测方面具有较好的性能。
接着使用100轮训练后LSTM、RNN、SVM和基于时间编码的LSTM模型,在测试集上进行预测,依次对每个话题的数据集进行测试,预测数据与真实数据的误差在较低水平。RNN、SVM、LSTM和基于时间编码的LSTM在测试集上的预测效果分别如图6、图7、图8、图9所示。
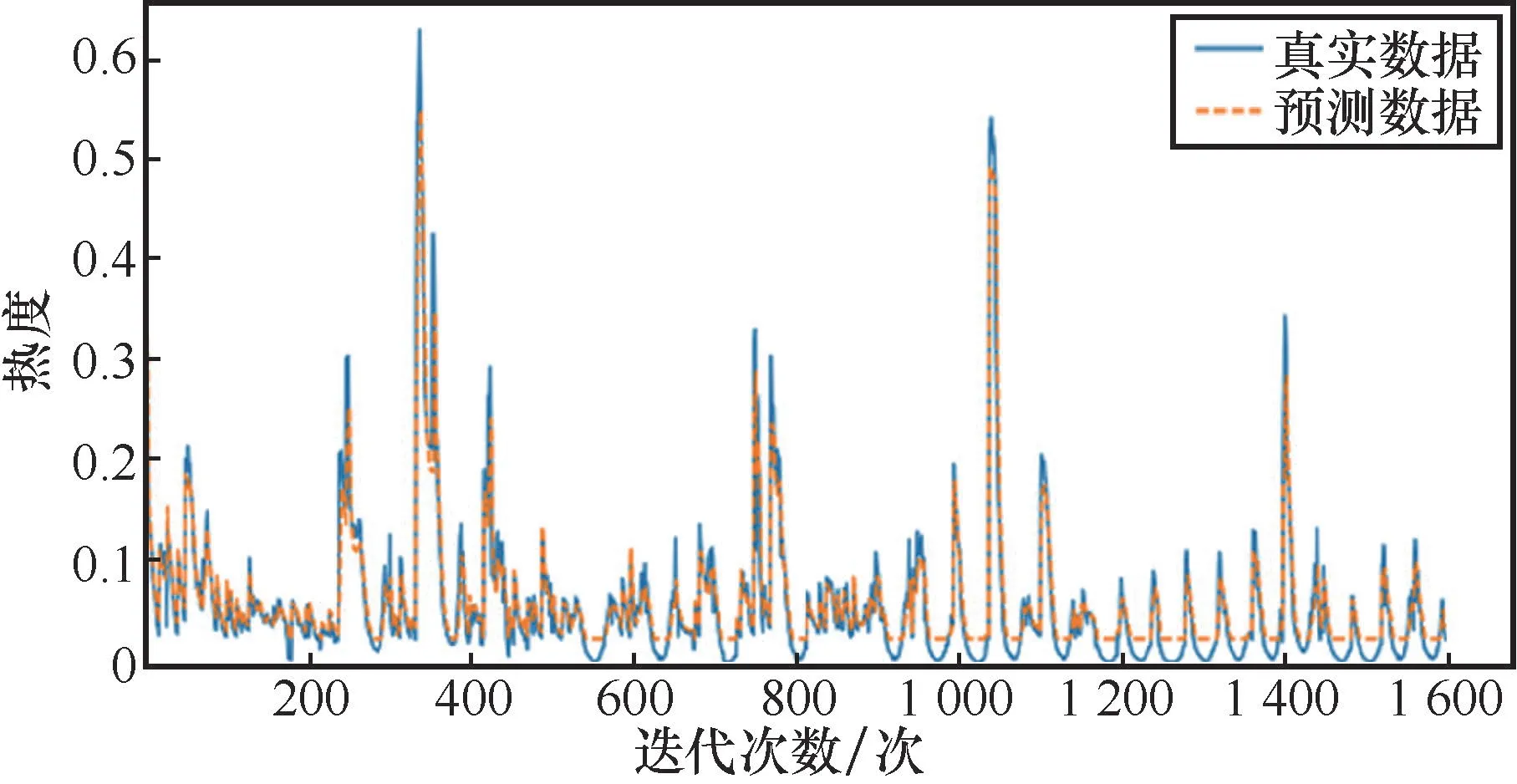
图6 RNN测试集预测效果
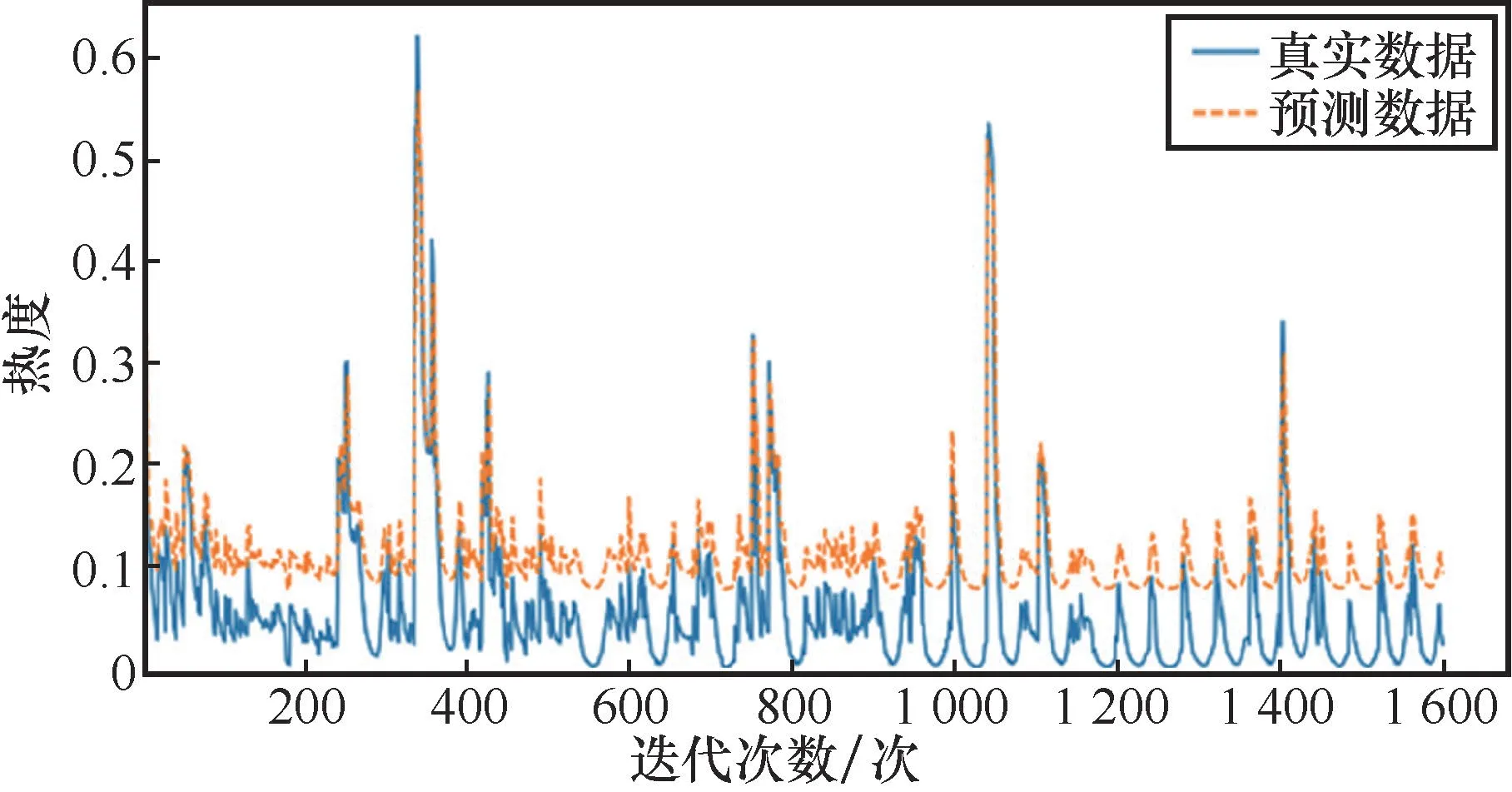
图7 SVM测试集预测效果

图8 LSTM测试集预测效果
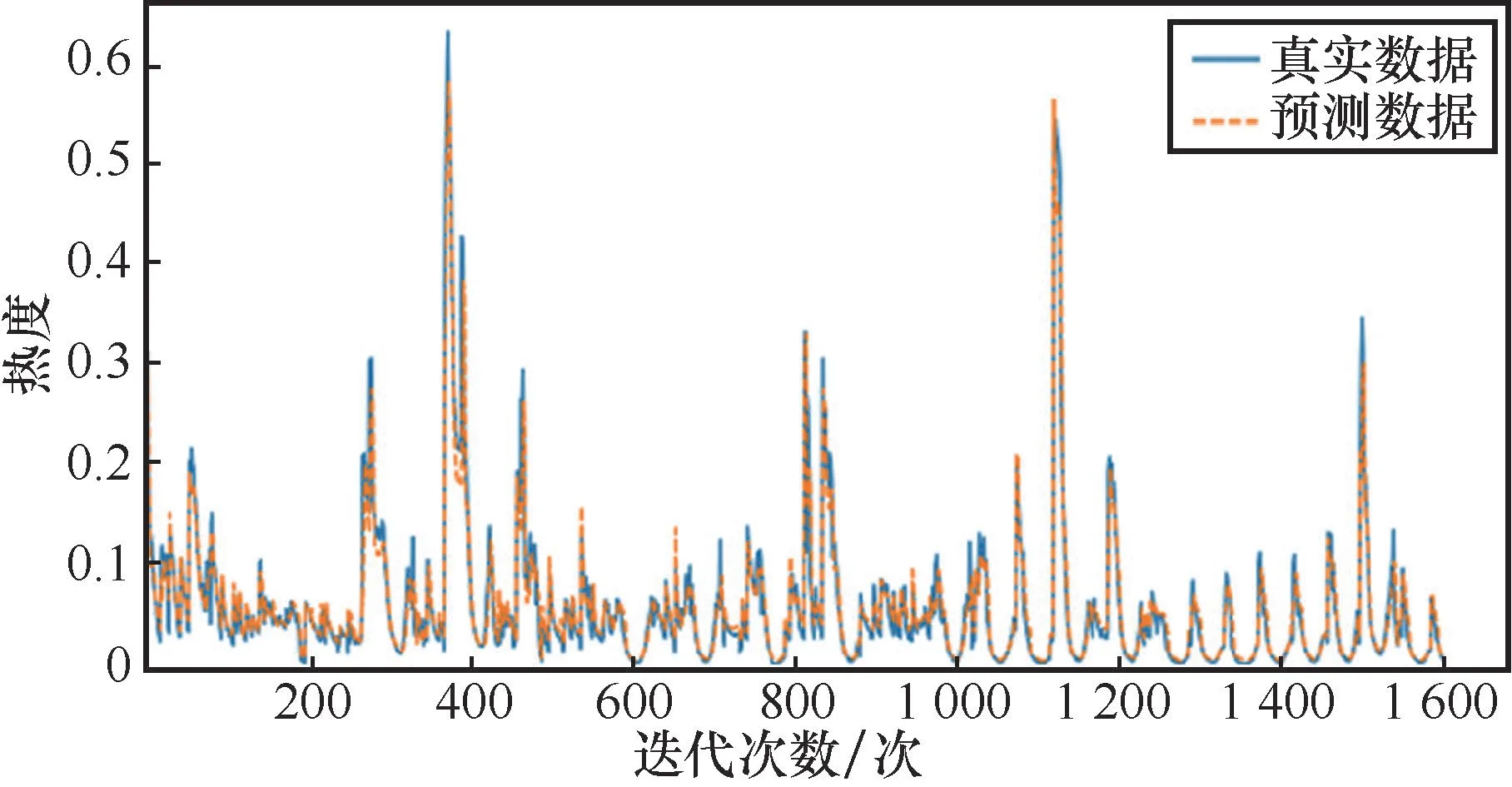
图9 基于时间编码的LSTM测试集预测效果
对比4种模型在测试集上的预测效果,基于时间编码的L STM性能最优。SVM在热度较低时的预测结果偏高,在热度值最高点的预测结果偏低。由于热度变化是有规律的,可以根据前序数据得到后序数据,而SVM没有考虑前序数据的变化特征,导致其回归精度不够高。出现高校舆情后,通过基于时间编码的LSTM对舆情热度趋势进行预测,及时引导舆论发展的方向,将有利于高校对学生思想健康的管理,提升高校处理舆情事件的水平。
4 模型评估
4.1 基于时间编码的LSTM模型真实集评估
以某真实事件为例,对新浪微博中该事件的真实热度数据每间隔15 min采集一次,并对收集到的数据进行整理保存。首先,对上述数据进行预处理归一化,并加入时间编码参数,将前45 min的数据作为神经网络的输入,预测得到下一时刻的输出。由于舆情数据受多种因素的影响,单独使用模型进行预测的效果不理想,故需要结合舆情实时的动态变化性对评估参数进行调整。在预测下一时刻的热度值时,可以根据舆情变化做出相应的处理,在获得真实数据后,结合真实热度数据进行预测,即进行动态的校正与下一步预测,动态调整过程如图10所示。
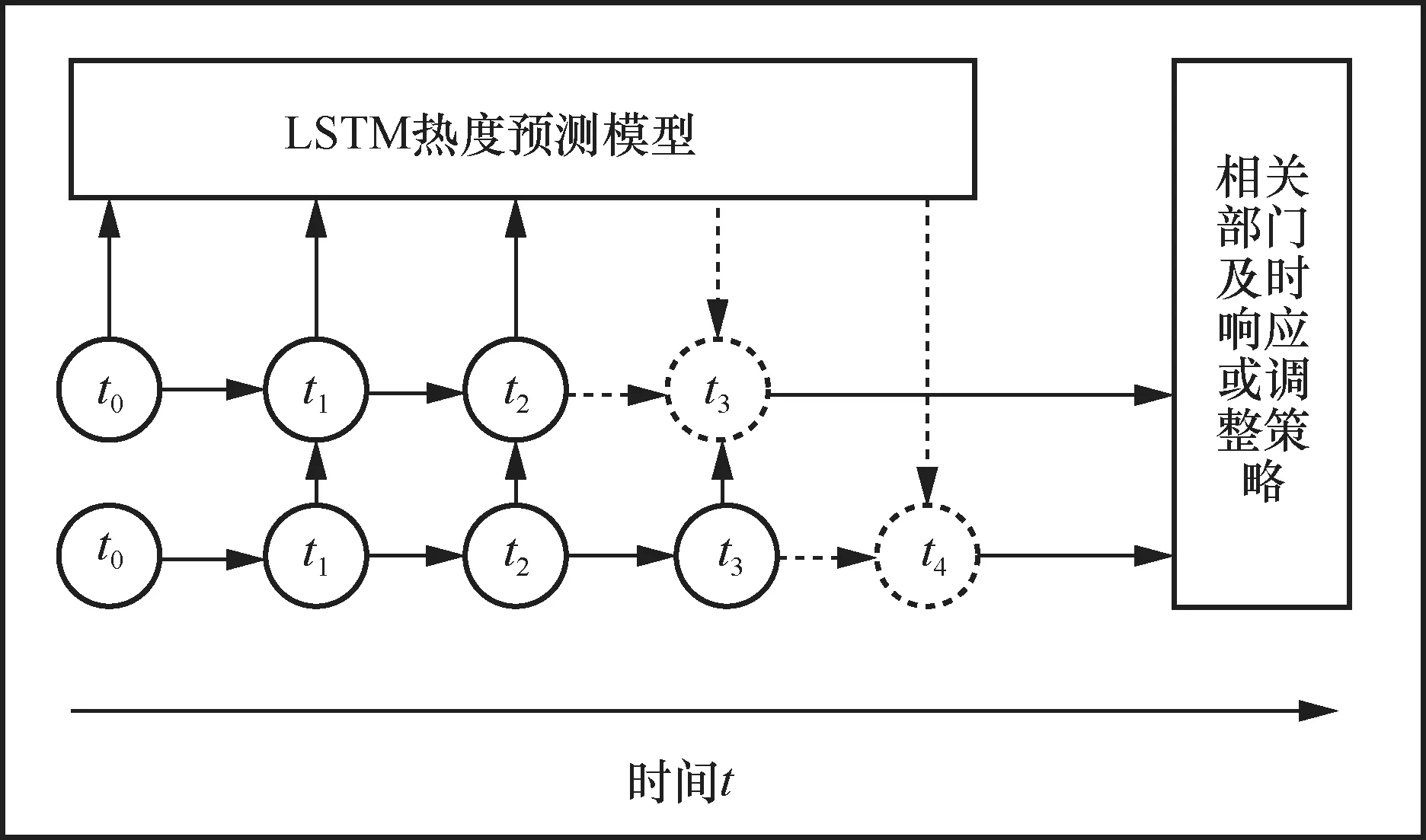
图10 动态调整评估参数
结合动态调整策略,对真实事件持续处于热搜榜的18.5 h(即74个时刻)进行预测,分别使用SVM、RNN、LSTM以及基于时间编码的LSTM进行预测,结果分别如图11、图12、图13、图14所示。分析实验结果可知,基于时间编码的LSTM模型能得到事件在具体时刻的热度,结合动态调整策略,其适应性得到提高。与其他3种算法相比,基于时间编码的LSTM的预测准确率是最高的。当高校舆情热点趋势即将进入爆发期时,相关部门及时响应或调整策略,对舆情热点发展趋势进行管控,有助于高校完善舆情管理体系。
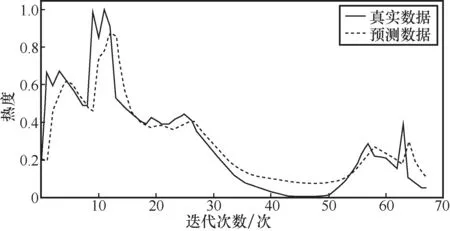
图11 SVM真实集预测效果
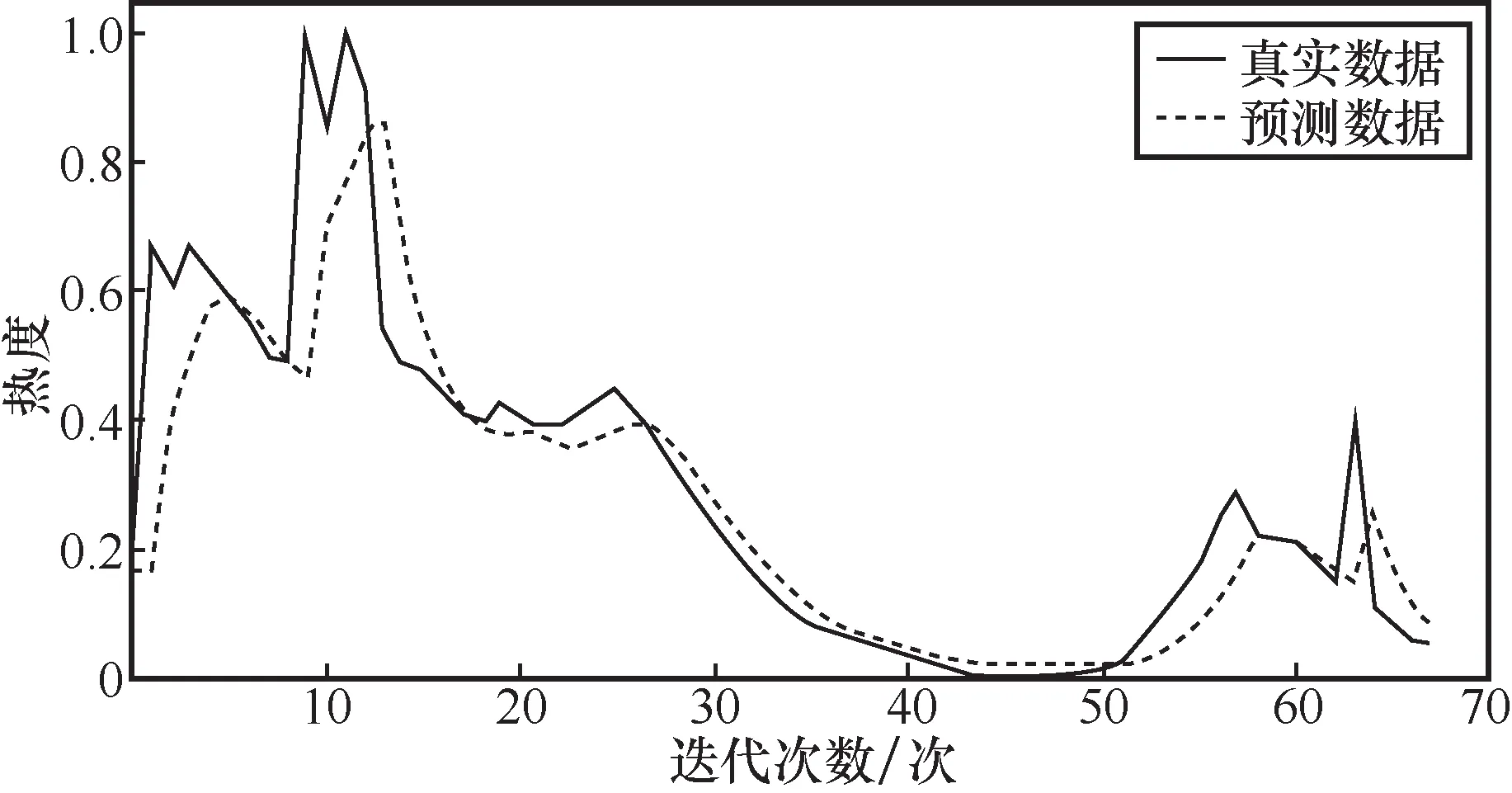
图12 RNN真实集预测效果
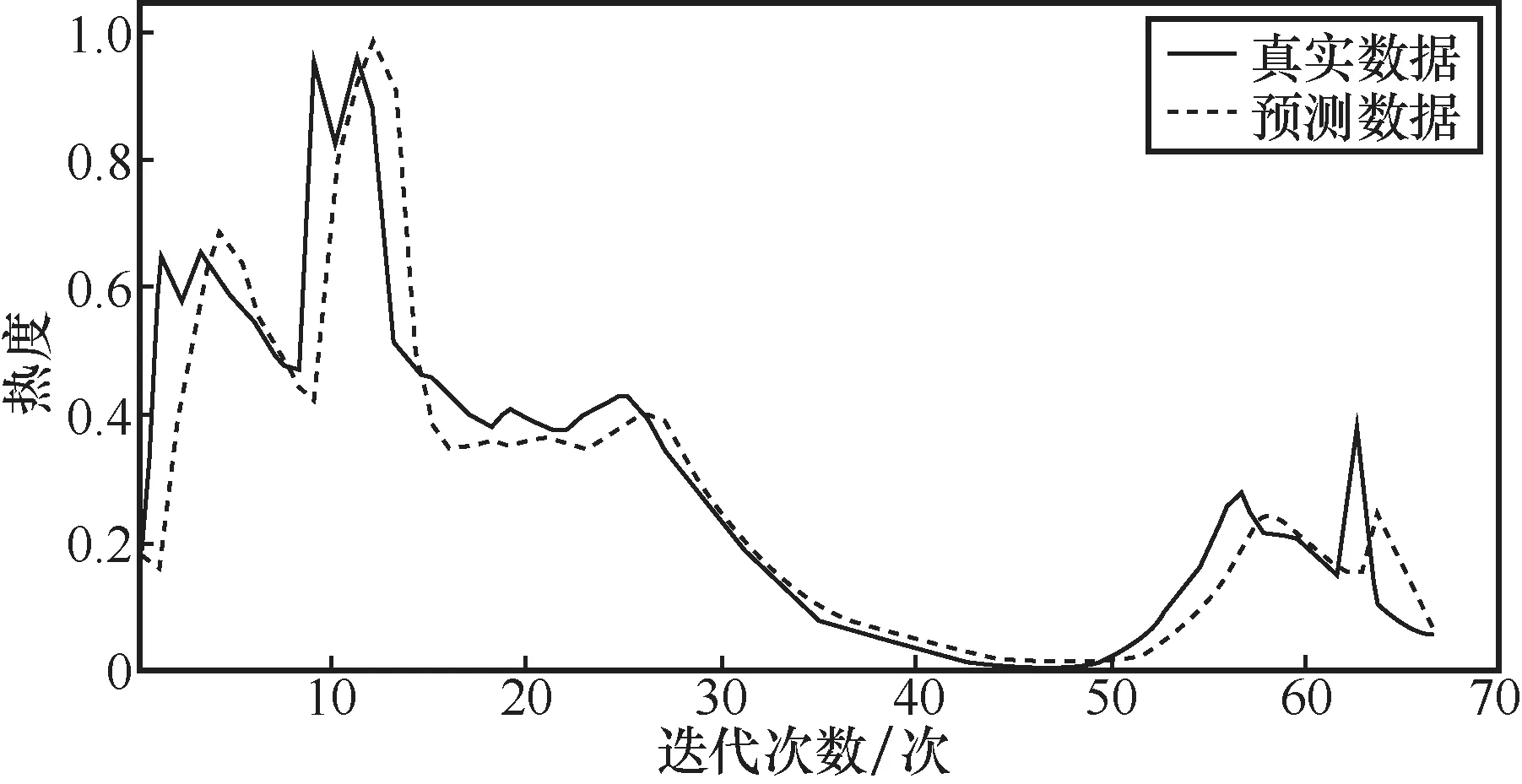
图13 LSTM 真实集预测效果
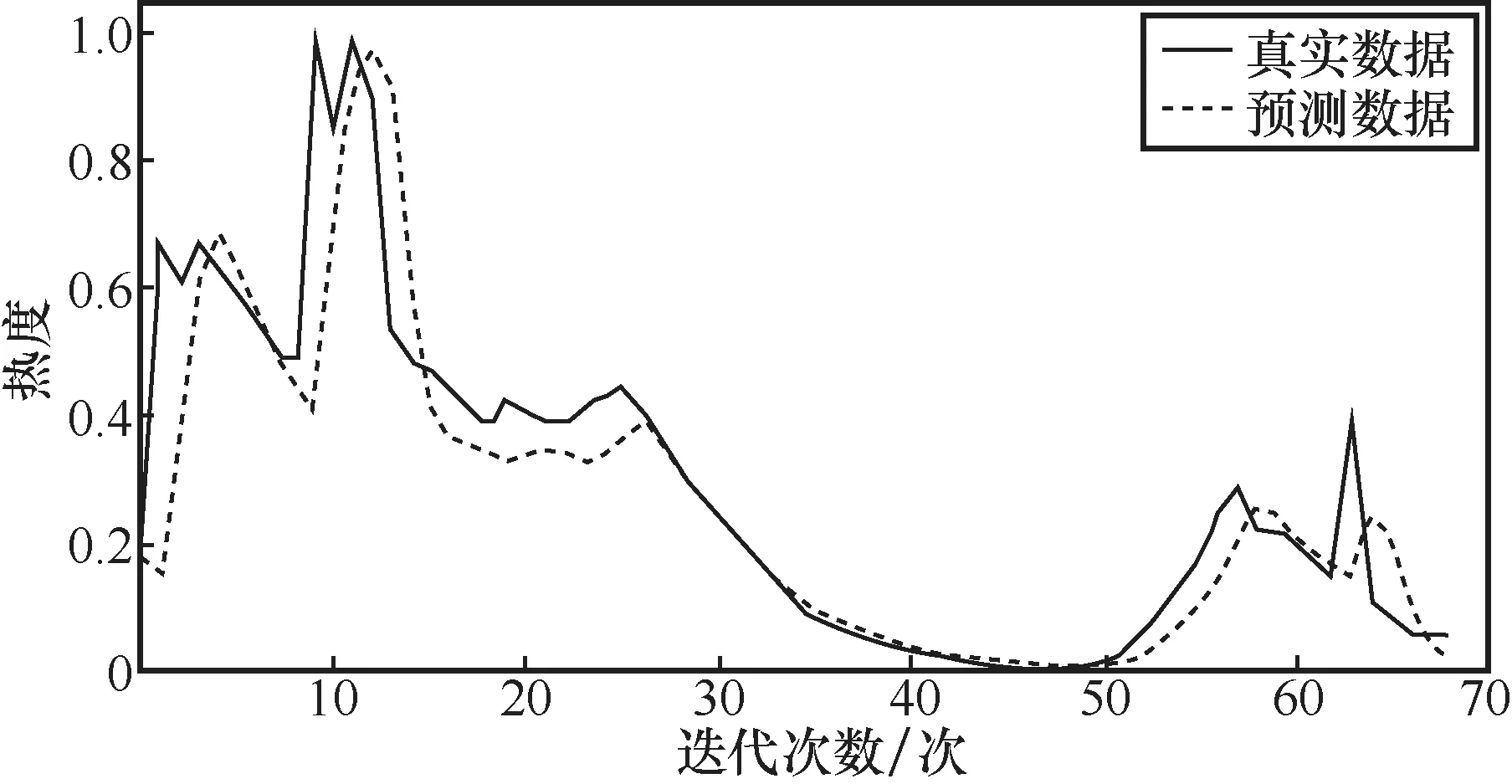
图14 基于时间编码的LSTM真实集预测效果
随着时间推进,相关部门可根据预测结果,提前为舆情的发展做出判断和回应。然而,神经网络不能自动判断预测停止时间。通过实验和数据分析可以得出,当热度数据预测值低于最低话题热度值时,可认为话题热度低于热搜榜上榜要求,停止预测。
4.2 误差评估分析
对基于时间编码的LSTM、LSTM、RNN和SVM 4种模型在不同数据集上的MAPE和MAE进行对比,结果如图15所示。从图15可知,MAPE和MAE的数值越小,预测值与真实值的误差越小,即预测结果越接近真实值。在4个模型中,基于时间编码的LSTM的预测效果是比较准确的。从MAPE对比实验结果分析:基于时间编码的LSTM在训练集和测试集上的预测效果明显优于其他3种模型。从MAE对比实验结果分析,基于时间编码的LSTM模型预测效果在训练集、测试集和真实集上明显优于RNN和SVM。但受到真实事件的动态变化性以及不确定因素的影响,基于时间编码的LSTM模型在部分预测集上的效果略差,后续研究需进一步提升模型的稳定性。综合比较,基于时间编码的LSTM还是具有明显优势的,在测试集上的预测效果优于其他模型。因此,使用基于时间编码的LSTM对高校舆情热点趋势进行预测具有较高的准确率,可以降低舆情带来的不利影响。
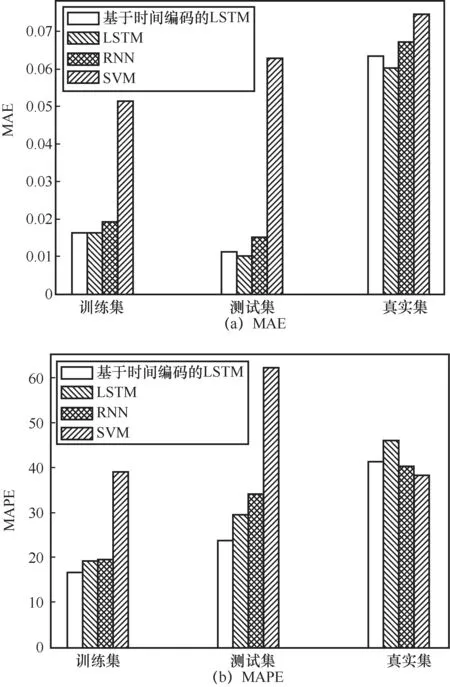
图15 模型预测效果
5 总结与展望
本文通过爬取新浪微博中高校的舆情热点数据,使用基于时间编码的LSTM学习舆情数据热度的时序变化情况,并对时序数据进行建模。将经过多轮训练和参数调优的基于时间编码LSTM的高校舆情热点趋势预测模型与RNN、SVM和LSTM 3种模型的预测结果进行对比分析,实验结果表明,基于时间编码的LSTM在训练集、测试集、真实集上的预测结果误差较小,具有良好的实时预测效果。本文可为相关部门预测热点事件的舆情趋势变化提供一定的参考,从而及时做出相应的决策。未来研究将从热点问题的内容与评论入手,进一步研究基于时间编码的LSTM模型的稳定性,建立更完善的舆情预测模型,挖掘更深层次的舆情趋势的发展规律。
