一种量子概率启发的对话讽刺识别网络模型
2022-09-17张亚洲朱少林
张亚洲,俞 洋,朱少林,陈 锐,戎 璐,梁 辉
(郑州轻工业大学软件学院,河南郑州 450002)
1 引言
现代汉语词典将“讽刺”解释为“讽刺是一种修辞策略,通过夸张、比喻等手法对人或事进行揭露、批评或嘲笑”.讽刺表达的字面含义往往与真实意图截然相反,从而可以完全扭转作者的情感极性,传递出批评或嘲弄的隐含情绪.随着互联网与社交网络的迅速发展,越来越多的用户参与网上聊天、评论互动等,讽刺语言的使用日趋频繁,在日常对话中扮演着重要的角色.例如,“你看这位大哥面相如何?”,“我觉得他长得真有创意,太抽象了”.
识别文本中的讽刺情感在许多领域都有广泛的应用,例如帮助企业预测消费者对其产品的态度,根据用户偏好进行个性化推荐,或帮助政府机关了解民众的舆论态势等[1].因此,学术界与工业界对识别文本中的讽刺产生了浓厚的兴趣[2,3].一般而言,讽刺识别是指利用自然语言处理技术、统计知识、机器或深度学习等,对语句、文档、对话等不同粒度的文本的讽刺极性进行鉴别.讽刺识别也属于情感分类的子任务.传统的讽刺识别方法主要集中在叙述式文本,例如产品评论,微博等,没有涉及到用户之间的互动对话.
对话讽刺识别正在成为该领域一个崭新且更具挑战性的研究课题,主要是因为:(1)互动对话中,每位谈话者并不独立,而是持续受到其他谈话者的影响,导致其讽刺情绪前后发生变化;(2)谈话者间的交互,默认隐藏了许多信息,例如他们的性别、周围环境、文化背景等[4,5].目前的对话讽刺识别方法主要探讨上下文作用或学习上下文依赖,难以考虑自然语言固有的不确定性.
量子的必要性解释在语言哲学范畴上,根据已有的研究成果[6,7],自然语言固有的不确定性是指人类情感活动的自发性,不经过任何先前的知觉,而由身体的组织、精力或由对象接触外部感官而发生于自身的原始感官印象,即主观情感无需经过任何理性推理过程而自动生成,且情感活动的变化无需任何符合理性逻辑的理由.即使已经收集了全部先验知识,也可能无法提前预知人类的情感起伏.例1:小明发现他的手机坏了,小明可能会感到难过,生气,也可能感到高兴.如果小明生性节俭,那么小明会自然感到伤心;如果小明正好想换一部新手机,那么小明会有一种找到借口的高兴.因此,情感规律具备这样的内在不确定性.反映到书面语言(文本)上,指的是情感表达的不完备性与上下文性,使得其无法孤立地表达确切的情感[7].已有的方法都是建立自经典概率和经典逻辑基础上,认为任何时刻(即使在决策判断之前),建模对象的状态也是确定的.然而一旦面对情感活动的不可确定性时,经典概率有时很难发挥作用.国内外的科学家们已经证实人类的情感与决策并不总是遵循经典概率,譬如琳达问题[8],次序选择(即人们对先听好消息后听坏消息与先听坏消息后听好消息两种顺序有不同的情感态度)[9]等.
量子概率(Quantum Probability,QP)作为量子物理中建模不确定粒子行为的数学框架,已被用于描述人工智能中各种自然语言处理任务[10~13].作为量子力学背后的抽象数学与统计解释,量子概率不应只被用于描述微观物理世界的规律,而同样可以脱离原始的物理背景,作为一种数学框架应用于信息科学等宏观领域.注意,这种应用并不是把宏观系统还原为微观粒子的量子效应,而是将它看作是一个整体系统.鉴于基于量子理论的对话讽刺识别研究几近空白,本文计划将量子几何的哲学思想与数学主义应用于对话讽刺识别领域,从量子视角重新探讨情感表达与演化的本质属性,构建量子启发的对话讽刺识别网络模型,为自然语言处理与人工智能领域提供一种新思路.
本文提出一种量子概率启发式对话讽刺识别网络(Quantum Probability Inspired Network,QPIN).具体而言,QPIN 包含一个复值话语嵌入层,一个量子复合层,一个量子测量层以及一个全连接层.首先,本文将对话中每句话语视作是一组单词的类量子叠加,表示为复值向量.其次,我们将相邻话语之间的上下文交互建模为量子系统与其周围环境的交互,构成一个量子复合系统,由密度矩阵表示.再次,鉴于量子系统的信息与性质可以由量子测量结果的概率分布描述,我们对每句话语进行量子测量,进一步提取讽刺特征,将其输入到全连接层和softmax函数获得讽刺识别结果.
本文在MUStARD 与2020 Sarcasm Detection Reddit Track两个基准数据集上进行实验评价,以验证QPIN模型的有效性.通过与众多前沿模型的比较,例如卷积神经网络(Convolutional Neural Network,CNN),双向门控循环单元(Bidirectional Gated Recurrent Unit,BiGRU),多头注意力长短期记忆网络(Multi-Head Attention
based Bidirectional Long Short Term Memory,MHABiLSTM),上下文LSTM(Contextual Long Short Term Memory,C-LSTM),双向自注意力变换网络(Bidirectional Encoder Representations from Transformers,BERT),上下文交互网络(Contextual Network,C-Net)以及多任务学习框架(Multi-Task Learning,MTL),表明本文的方法在F1与Acc指标上取得更高的分类结果.
本文的主要创新贡献有以下几点.(1)首次利用量子概率,提出面向对话讽刺识别的量子概率启发式网络.它能够自然地将量子理论引入到宏观人工智能领域,是一套从文本表征到上下文交互再到特征识别的端到端式理论结构,探索量子理论的潜力.(2)引入复数概率幅,提出一种复值话语表示方法.该方法将文本话语表征为指数形式的复值向量,将振幅与语义知识联系起来,将隐藏的相位角与情感知识联系起来,既能够同时捕捉语义与情感,也能够借助复数概率幅描述不确定性.(3)提出一种建模话语上下文性的量子复合表示方法.量子复合将能够以“全局到局部”方式建模上下文交互.
2 量子概率基础
2.1 量子概率
量子概率理论是由冯·诺依曼发展建立的一种基于线性代数的一般化概率理论,目的是解释量子理论的数学基础[14,15].量子概率理论是量子力学背后的抽象数学与统计解释,它更关心的是符号之间抽象的关系与结构,而非符号对应的实物(例如物理量).因此,量子概率并不是只能描述微观粒子,同样可以脱离于原始物理背景,而去描述宏观系统中的类量子现象,例如人类决策判断、次序效应、认知干涉、不确定性等.
在量子概率中,量子概率空间封装于复数希尔伯特空间H.希尔伯特空间是欧式空间的直接推广,是一个无限维的内积空间,被广泛应用于数学分析与量子力学中.量子概率中,假设一个量子状态向量u=(u1u2…un)T∈H,记作左矢|u>.它的转置向量,记作右矢<u|.两个状态向量|u>和|v>的外积构成一个矩阵,记作|u><v|.对于状态向量|u>,在u方向上的投影算符可以写作Π=|u><u|,代表量子概率空间的基本事件.
2.2 量子叠加
量子叠加是指一个量子系统可以同时处于多个互斥基态的叠加态,直到它被测量.测量之后,该系统从叠加态塌缩到其中一个基态上.假设{|w1>|w2>…|wn>}构成量子概率空间上的一组正交基,那么|u>=,其中zj是复数权值.
量子概率中,量子态可以处于纯态,也可以处于混合态.纯态对应于希尔伯特空间中的状态向量|u>,而混合态是由几种纯态依照概率组成的量子态,由密度矩阵ρ表示.假设量子系统处于纯态|u1>|u2>…|un>的混合中,对应的密度矩阵定义为其中pj代表每个纯态的经典概率,全部概率的总和为1.密度矩阵是经典理论中位置和状态概率分布的量子扩展,将量子态与经典不确定性容纳进同一体系下,描述了系统全部信息与性质.
3 量子概率启发式讽刺识别网络
本文提出的QPIN 模型,如图1 所示.QPIN 模型包含一个复值嵌入层、一个量子复合层、一个量子测量层以及一个全连接层.
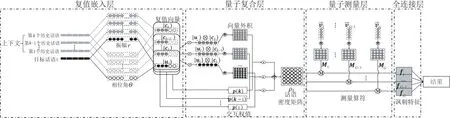
图1 类量子交互网络结构示意图.⊗表示张量积,⊛表示向量外积操作,⊙表示逐位相乘,⊕表示矩阵相加,表示量子测量操作
3.1 复值嵌入层
受李秋池的工作启发[11],本文采用复值嵌入表示方法.鉴于单词是组成人类语言的基本单元,本文将对话中的每个单词w视作一个基态|w>,假设{|w1>|w2>…|wn>}构成对话希尔伯特空间Hdig的正交基向量.本文采用独热编码(one-hot encoding)去表示每一个单词基向量例如第j个基向量
为了捕捉讽刺话语中的不确定性,本文将每句话语视作是一组单词基向量{|w1>|w2>…|wn>}的量子叠加.那么目标话语ut可以表示为:
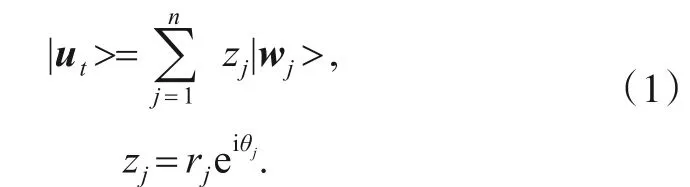
其中,zj是第j个单词的复数概率幅,满足.i称为虚数单位,r是概率幅的振幅,θ是相位角.本文赋予振幅与相位具体的含义,将振幅与语义信息关联,将相位角置为情感倾向程度,从而同时建模了语义与情感信息.
3.2 量子复合层
在量子概率中,理想的量子测量描述了被测系统,测量装置以及周围环境(例如临近系统)的完全交互.但是,在实际测量中,我们认为测量装置与周围环境并不会同等地参与被测系统的交互,即它们的参与程度不是相等的,例如距离远的系统与距离近的系统对被测系统的影响是不同的.这种交互类似于对话中不同话语之间的交互.不同的上下文话语表达着不同强度的人际交互.
本文将目标话语|ut>视作被测系统,将其上下文{|c1>|c2>…|cλ>…|ck>}视作周围环境.两者的交互构成一个量子复合系统,例如目标话语|ut>与第λ个上下文话语|cλ>之间的交互构成了一个量子复合系统.考虑到所有上下文的影响,本文建模每一个上下文与目标语句的交互,构造出k个不同的复合系统.其中,第λ个复合系统形式化为:

其中,p(λ)是第λ个复合系统的交互概率,衡量第λ个上下文话语的交互程度,我们在模型训练过程中自动更新它的值.
根据式(3),目标话语已经由密度矩阵ρt表示.本文使用密度矩阵表示的原因是:密度矩阵能够统一目标话语的全部信息与性质,例如语义知识,情感信息,上下文交互,概率分布信息等.
3.3 量子测量层

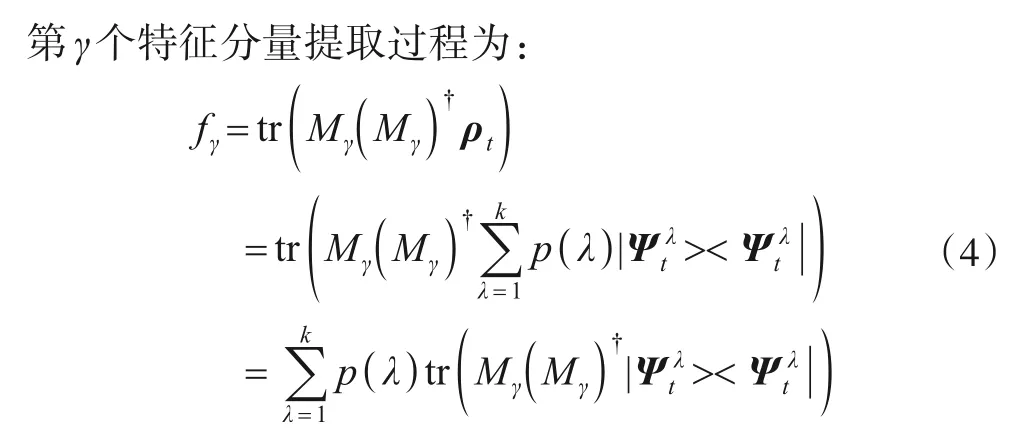
其中,tr是迹操作,γ∈[1,2,…,G].fγ是特征向量ft的第γ个特征分量,得到ft=(f1f2…fγ…fG).
3.4 卷积层
本文同样设计一个卷积层针对密度矩阵提取特征.目的是调查量子测量与卷积层的特征提取效率对比,旨在理解量子测量对宏观信息提取的潜力,如图2所示.
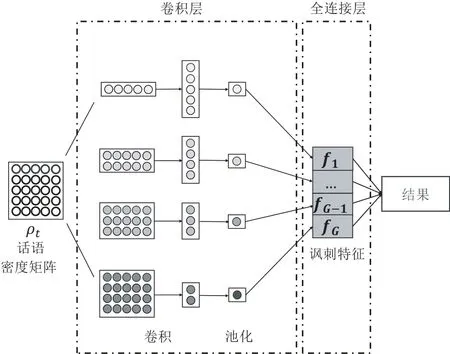
图2 卷积层对话语密度矩阵提取特征框架
本文尝试了不同的卷积核,并根据最优实验结果,设置了4个卷积核,卷积核大小分别是{1,2,3,4}×d,对目标话语的密度矩阵进行卷积操作,对卷积后的特征最大池化,将池化后的信息连接到一起构成讽刺特征ft=(f1f2…fG).
3.5 全连接层

其中,N是训练集样本量表示真值标签表示预测标签,t是话语索引,∊是类别索引,μ‖φ‖2是正则项.本文使用反向传播算法训练网络模型并更新参数.为了避免训练过程中出现过拟合现象,本文使用随机剪枝策略.
3.6 方法讨论
介绍量子概率启发式对话讽刺识别网络(下面简写为QPIN)之后,本文详细阐述并讨论其与现有深度神经网络方法的区别与相似.
相似之处从模型构建角度分析,QPIN 与深度神经网络,譬如卷积神经网络、全连接神经网络及长短期记忆网络等类似,仍然采用深度学习与逐层训练的思路,包含了输入层、隐藏层、输出层等基本组件,通过深度多层抽象,逐渐将初始的“低层”特征表示转化为“高层”特征表示.整个训练是一个端到端式监督学习与拟合过程.
区别之处从模型构建角度分析,QPIN 与已有的神经网络存在五点不同:(1)整体架构不同,QPIN 是量子概率驱动的架构,由量子理论中的核心组件自下而上搭建而成,具备量子概率的数学支撑,每一个组件都有物理解释,不是作为“黑盒子”使用;(2)输入层不同,首次将复数带入到讽刺识别任务中,将每句话表征为复值表示,不再是实数向量;(3)隐藏层不同,QPIN采用量子符合与混合态构建隐藏层.目标话语与上下文的交互,被视作是k个复合系统上的量子混合态,表示为密度矩阵;(4)特征提取方式不同,已有方法通常直接采用全连接层提取特征和降维,而QPIN 以一种测量的视角,采用G个测量算符对目标话语的密度矩阵表示进行量子测量,提取最终特征.从研究目标分析,QPIN 作为量子讽刺识别领域的有效尝试,旨在推动量子人工智能与量子信息处理的发展.
4 实验与结果
4.1 实验数据
本文采用MUStARD[16]和2020 Sarcasm Detection Reddit Track[17]两个基准数据集进行实验.MUStARD 数据集收集自“生活大爆炸”、“老友记”等情景喜剧,共包含690 个视频对话.每个对话记录了目标话语以及对话上下文话语,其中目标话语被标注为“讽刺”或“非讽刺”.
2020 SarcasmDetection Reddit Track(下面简写为Reddit)收集自Reddit 论坛,仅包含文本模态.它共有3 100个讽刺博文,3 100个非讽刺博文以及18 618个上下文博文.实验数据统计如表1所示.
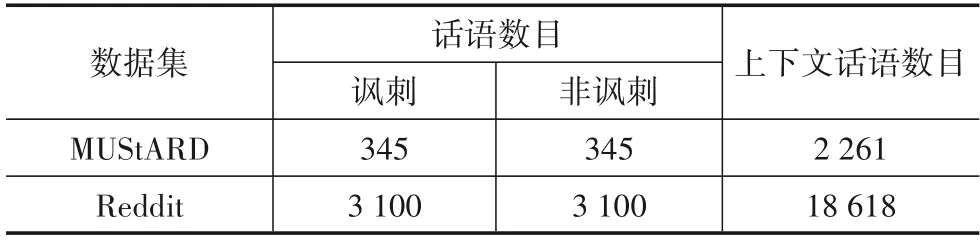
表1 实验数据统计
4.2 评估指标与参数设置
本文采用精确率(Precision,P)、召回率(Recall,R)、微观F1(Micro-F1,Mi-F)及准确率(Accuracy,Acc)作为性能评估指标,详细参数设置如表2所示.
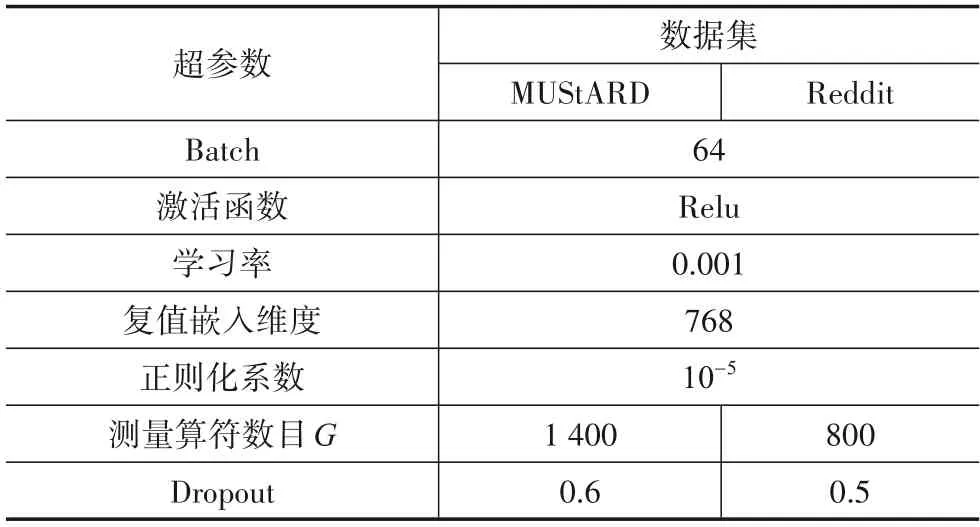
表2 参数设置
4.3 对比模型
为了评估QPIN 的有效性与实际性能,本文对比了一系列前沿基线模型.它们分别是:
(1)CNN[18]:它包含两个卷积层,一个全连接层.它采用预训练的GloVe词向量对话语文本执行讽刺分类.
(2)BiGRU:它采用一个双向的门控循环网络去学习目标话语的隐藏状态,输入到softmax 函数执行讽刺识别.它考虑了单词的历史和未来的上下文信息.
(3)MHA-BiLSTM[19]:它使用自然语言处理领域内热门的多头注意力机制,并与双向LSTM 融合去抽取目标话语中更突出的特征,学习更优的话语表示.
(4)C-LSTM[4]:它首先利用CNN 去提取话语特征,然后将历史话语特征与目标话语特征拼接,输入到LSTM中执行讽刺识别.
(5)SVM+BERT[16]:它首先利用BERT 得到目标话语的向量表示,然后输进SVM 分类器执行讽刺分类.本文将SVM的核函数设置为“高斯核”.此外,本文也将上下文特征与目标话语特征拼接,以考虑上下文的影响.
(6)C-Net:它利用目标话语的标签去标注上下文话语,然后利用目标话语与上下文训练BERT,学习话语上下文表示.
(7)MTL:它是最前沿的多模态多任务学习框架,首先提出段内与段外两种注意力机制去学习段内与段外信息,拼接这两种信息得到话语表示.其次,利用情感知识帮助提升讽刺识别的性能.为了公平比较,本文只用文本与图像模态的结果.
(8)QMSA[12]:为了验证本文提出QPIN 的有效性,本文对比了其他量子启发的多模态情感分类模型.与QPIN 不同,QMSA 采用的是实数BERT向量构建每一句文本与图像文档的密度矩阵,并不考虑对话上下文,最后将密度矩阵输入到SVM分类器中执行讽刺分类.
(9)QSR[10]:它是一个基于量子理论的文本情感分类模型,利用量子语言模型与word2vec 将其表征为量子叠加态,利用最大似然估计训练为密度矩阵,输入到随机森林分类器中执行分类.
(10)QMN[4]:QMN 使用密度矩阵去表征文本与图像特征,通过LSTM 提取上下文特征后,采用量子干涉对文本与图像特征进行融合.
此外,本文也设计了QPIN 的三种变体,分别是QPIN-QM,QPIN-CNN和QPIN-QM-CNN.其中,QPINQM 只使用量子测量层提取特征,QPIN-CNN 只使用卷积层提取特征,而QPIN-QM-CNN 将量子测量与卷积层提取的特征拼接到一起,组成的新特征输入到全连接层执行分类.
4.4 MUStARD数据集结果分析
各个模型在MUStARD 数据集上的实验结果如表3所示.MUStARD 数据集采集自情景喜剧,对话中逻辑跳跃性强,由于是演绎性样本,台词隐喻性、刻意性强,比较考验模型的上下文理解与文本表征能力.因此,在该数据集上模型的上下文建模与语义捕捉能力影响其性能.BiGRU、MHA-BiLSTM、C-LSTM、SVM+BERT、CNet、MTL 以及QPIN 模型全部优于CNN.原因是它们均考虑到了上下文信息,表明在对话讽刺识别中上下文的重要性.BiGRU、MHA-BiLSTM 与C-LSTM 三个RNN变体模型中性能处于同一水平,BiGRU 获得最高F1 结果,而C-LSTM 获得最高准确率.相比于这三种模型,SVM+BERT 在微观F1 指标上表现更好,这依赖于预训练BERT能够提供更优良的话语表示.SVM+BERT显著地超越CNN,在F1 与Acc 指标上分别提升13.3%与9.7%.这展示了预训练语言模型的特征抽象能力.此外,BERT 作为预训练模型,已经在庞大的数据集上训练完成.但是BERT 计算量过于庞大且参数量远高于CNN.相比于BiGRU、MHA-BiLSTM 与C-LSTM,SVM+BERT 在F1 指标上获得显著改进,分别提升了3.7%、5.4%与4.4%.但是在Acc指标上没有显著改进,甚至落后于MHA-BiLSTM 与C-LSTM.原因可能是MUStARD数据集数量很少,且角色话语分布极度不平衡,导致MHA-BiLSTM 与C-LSTM 获得很低的F1分值,却拥有较高的Acc 分值.LSTM 的优势在于建模短文本上下文,一定程度上缓解了梯度消失的缺点.对于这种不平衡数据集,机器学习领域通用做法是更加注重F1 指标上的表现.SVM+BERT(+上下文)通过将上下文特征与目标话语拼接,提升了微弱的性能.
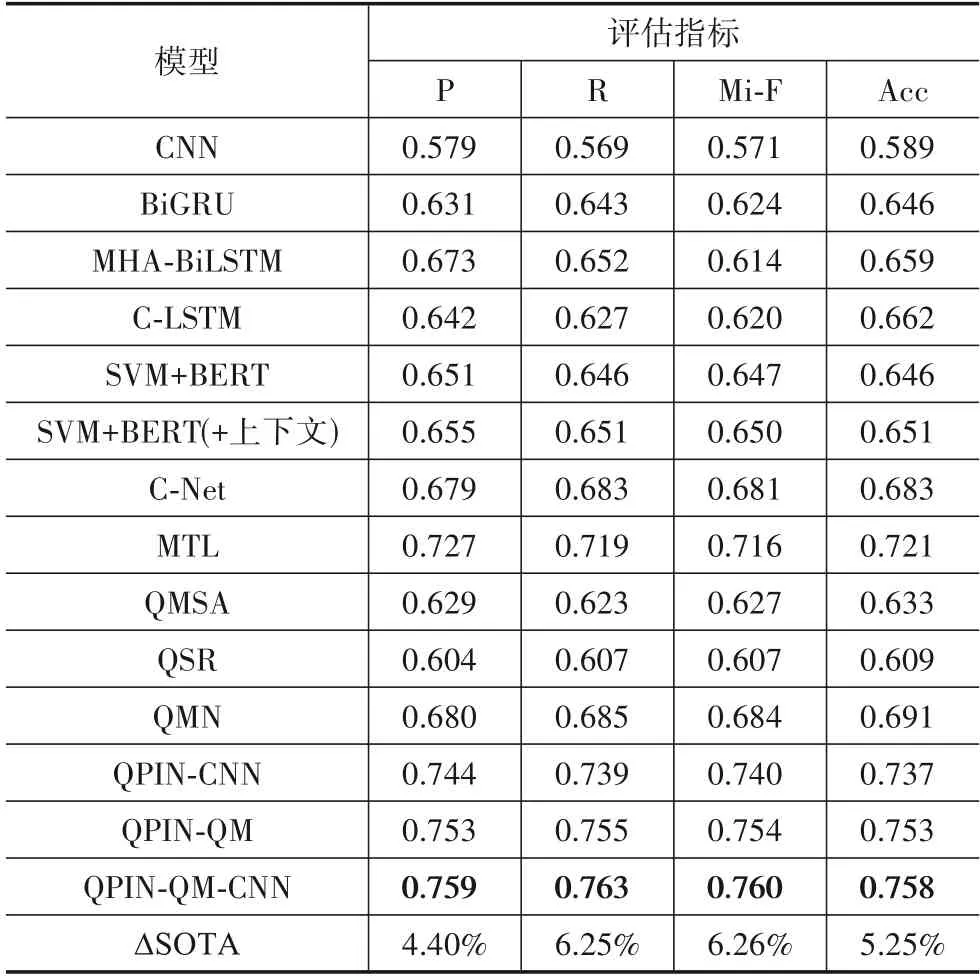
表3 各个模型在MUStARD数据集上的实验结果
作为最新的对话讽刺识别模型之一,C-Net 通过建模谈话者间的依赖信息,超越SVM+BERT 而获得不错的结果.在众多基线模型中,MTL 取得最优实验结果.相比于C-Net,MTL 分别在F1 与准确率方面提升了1.8%和1.7%.原因在于MTL 既考虑到上下文信息,也利用了情感知识对讽刺识别的帮助.QMSA作为经典的量子启发的多模态情感分类模型,其性能表现不佳.原因是QMSA 是浅层模型,仅仅利用定义构建密度矩阵,也并不考虑对话上下文,限制了文档的表征能力.QMSA 不是端到端模型结构,密度矩阵自定义之后不会根据训练集而自适应学习.通过与QPIN-QM 的结构对比,QPIN-QM 在文档表示上引入了复值,包含了BERT实数部分与虚数部分,该表示相比于QMSA加入新的补充知识,即相位角.此外,引入了上下文复合表示与密度矩阵的可学习设置,使得能够根据上下文不同,自适应学习话语密度矩阵.这两个组件对QPIN 模型性能的提升贡献度最大,也是QPIN-QM 显著超越QMSA 模型的主要原因,体现了QPIN 的先进性与创新性.QSR 性能结果相比于QMSA更差,原因是其既不考虑多模态信息,不涉及多模态表示,也不考虑对话上下文交互,严重限制QSR 模型分类能力.QMN 作为目前量子对话情感分类领域中最前沿的方法之一,性能结果非常良好,超越了C-Net,仅次于MTL,证明了量子对话情感分类方法的潜力.
4.5 Reddit数据集结果分析
相比于MUStARD,Reddit 数据集不仅样本量更大,每条话语也更长,且仅包含文本模态.但是Reddit数据集是论坛回复性样本,上下文的时效性较长,交互性较差.同时,每条话语都是长文本,对于捕捉关键信息,譬如表达讽刺的单词或短语,更加困难.长文本内单词间的上下文性也需要考虑在内.因此从样本角度,Reddit 数据集更加考验模型的语义、情感表征能力.各个模型在Reddit 数据集上的实验结果如表4 所示.CNN、BiGRU、C-LSTM 性能最差,而MHA-BiLSTM 表现相对较好.因为Reddit 数据集中上下文话语篇幅较长,上下文建模更为困难,使得拼接上下文话语特征入LSTM 效果不明显.SVM+BERT 显著地超越CNN、BiGRU、C-LSTM,在F1 与Acc 分值上分别提升了1.4%、2.7%,6.3%、6.3%,4.5%、4.1%.这表明在数据量更大、数据分布平衡的数据集上,BERT 凭借预训练模型显露出明显的优势.类似地,SVM+BERT(+上下文)凭借BERT 的特征学习能力,超越了传统的神经网络结构,原因是LSTM 抽取特征的能力远弱于Transformer.
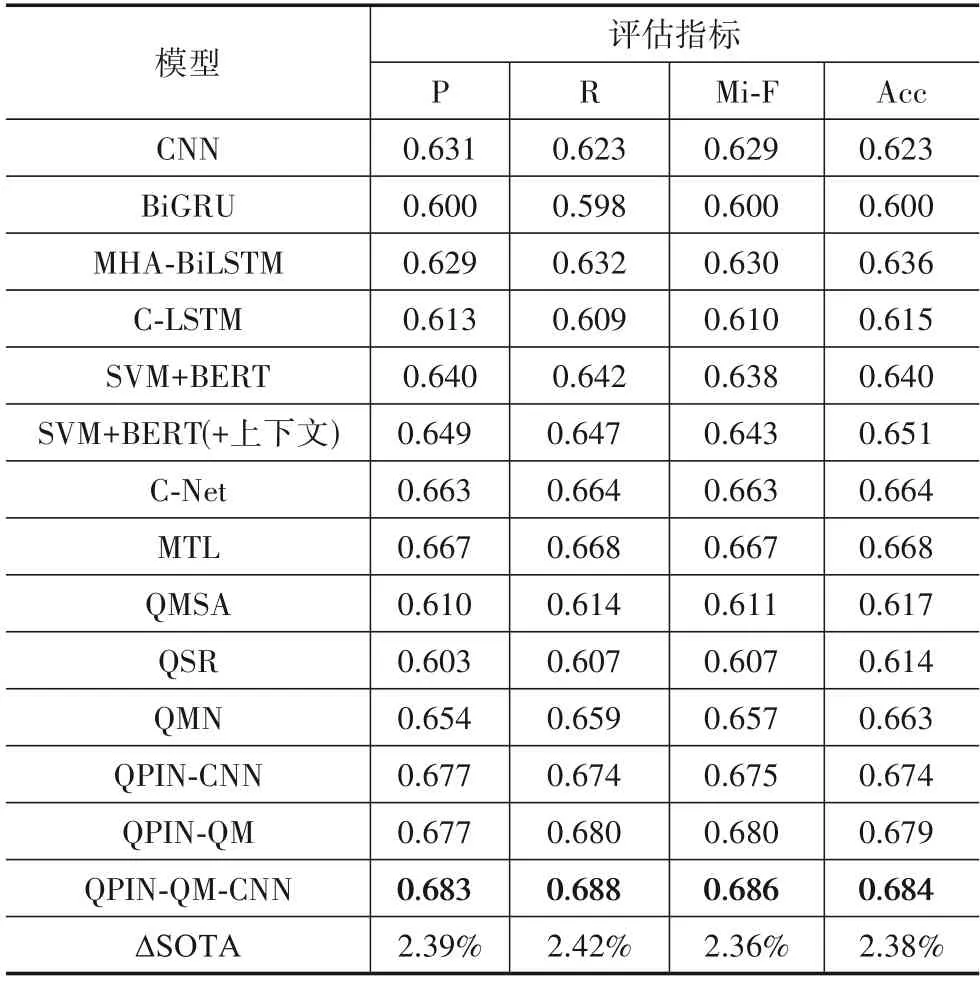
表4 各个模型在Reddit数据集上的实验结果
C-Net 与MTL 作为最前沿的对话讽刺识别框架在各项指标上胜过其他基线模型,且两者获得近乎相等的识别结果.原因是两者均是基于预训练语言模型设计文本表征方法,如BERT和ALBERT,均可以建模长文本内部的单词上下文以及利用多头注意力机制捕捉长文本中的关键信息.而作为量子启发的多模态情感分析模型QMSA 表现非常差,其准确率位列最后一位.QMSA 模型的两大核心组件分别是密度矩阵与多模态干涉特征融合.鉴于Reddit数据集只包含文本数据,并不涉及多模态交互.QMSA中的量子启发的决策融合完全失效,只剩下利用量子理论定义文本密度矩阵,且不会随着训练过程而改进.初始密度矩阵表征能力有限且固定,这严重限制了QMSA 在Reddit 数据集上的性能.相比而言,QPIN 的四个核心组件:复值表示、上下文复合表示、端到端式训练以及量子测量均没有受到数据集的影响.因此QPIN 远远超过QMSA 框架,获得最佳了性能.
本文提出的QPIN-CNN 与QPIN-QM 仍然优于CNet 与MTL,取得优良的识别结果,F1 分数分别达到67.5%与68.0%.但是由于本文在Reddit 数据集上仅选择了800 个量子测量算符,远远少于在MUStARD 数据集中的1 400个测量算符,使得QPIN-QM 提取的特征维度减少,降低了信息承载与描述能力,导致QPIN-CNN与QPIN-QM 相差无几,处于同一水平.这表明,测量算符的数目将会直接影响QPIN 的性能.QPIN-QM-CNN以微弱优势超越了QPIN-CNN与QPIN-QM,取得最佳识别性能.原因是在测量算符数目较少的情况下,结合CNN 以补充提取特征是一种性能补偿手段.相比于MTL,QPIN-QM-CNN 分别在F1 与准确率方面提升了2.3%和2.3%.
4.6 量子概率与经典概率实验对比
本文已经分别从动机、理论层面详细描述了量子概率的潜力.为了支撑这一观点,本节将从实验角度出发,通过对比经典(贝叶斯)概率与量子概率的实验结果,验证量子概率的有效性.对于贝叶斯概率方法,本文将设计与QPIN 相似的网络结构,以保证两者公平比较.鉴于贝叶斯概率并无复数、密度矩阵、量子复合与量子测量等概念,本文首先利用BERT 得到每句话语的语义向量表示,并将每句话语的情感极性作为补充特征与之拼接,成为新特征(该设置对比复值嵌入表示).其次,对目标话语与其上下文的特征进行线性相加,用于捕捉上下文信息(该设置对比量子复合).再次,将上下文特征输入到朴素贝叶斯分类器中获得目标话语的预测概率,作为进一步提取的概率特征(该设置对比量子测量层).最后,将这些预测概率输入到全连接层得到讽刺识别结果.对比结果如表5所示.
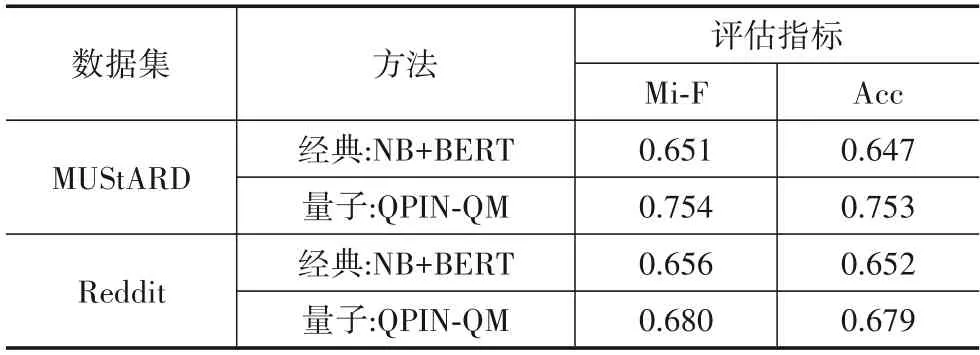
表5 量子概率与经典概率实验结果
可以观察到,在MUStARD 与Reddit 数据集上,量子概率启发的网络QPIN 在F1 值与准确率方面均显著超越经典概率方法NB+BERT.该实验结果支撑了本文的理论论点,表明量子概率从动机、理论与实验都有较大潜力,可以作为另外一种更加一般化的概率体系去解决自然语言处理难题.
4.7 谈话者角色重要性分析
鉴于对话中谈话者角色也会影响讽刺极性的判断,例如情景喜剧“生活大爆炸”中“谢尔顿”这一角色相较于其他角色表达更多的讽刺,本文将谈话者的角色信息作为一种补充知识考虑到QPIN 模型内,分析角色对模型性能的影响.此外,鉴于Reddit数据集都是论坛用户,用户名各种各样,并不体现特定讽刺信息,其角色信息并没有记录,因此我们只建模MUStARD 数据集中的角色信息.我们采用两种方法引入角色信息以及角色对讽刺的影响:(1)利用BERT 将每个角色名表征为向量,与对应的话语向量拼接成一个新向量,再执行后续的量子复合等操作;(2)受Transformer 模型启发,将每位角色与讽刺表达的关联度作为缩放因子γ,例如“谢尔顿”与讽刺表达的关联度较大,那么可以设置γ=1.2,“拉杰什”与讽刺表达关联度较低,可以设置γ=0.8.该缩放因子γ与讽刺特征ft=(f1f2…fγ…fG)结合组成新的讽刺特征fnewt=γft.然后,我们将新讽刺特征输入到全连接层获得讽刺识别结果.为了寻求最佳性能,我们将每位角色的缩放因子γ随机初始化,并设置为可训练.详细的实验结果如表6所示.

表6 角色信息实验结果
可以观察到,仅仅利用BERT 将每位角色表征为向量的做法并未取得模型性能的提升,与之前的QPINQM 处于同一性能水平,表明这种融入角色信息的方法过于朴素,需要更加详细深入的角色建模方法.第二种只采用缩放因子的方式以0.66%的微弱优势超过了当前的QPIN-QM,表明了角色引入对模型性能的帮助与必要性.第三种同时利用缩放因子和角色向量的方法并未超越第二种,但是胜过QPIN-QM.这印证了我们之前的解释,即仅仅将角色名表征为BERT 向量对模型提升并无实质性帮助.综上,缩放因子的效果仍然有待提升,需要进一步深入研究,这些将留给我们下一步工作.
5 结论
对话讽刺识别是一项崭新且具有挑战性的人工智能任务.本文尝试了将量子概率与复数体系引入到经典讽刺识别中.基于此,本文提出了一种量子概率启发的对话讽刺识别网络模型,旨在建模人类讽刺语言中固有的不确定性问题.本文在两个基准数据集上进行了大规模实验,验证了本文提出方法的有效性.本文也进行了一系列模型分析,例如量子概率与经典概率方法对比分析、参数分析等,全方面剖析QPIN 模型的优缺点,探索了量子概率在讽刺识别任务的潜力.
