基于深度神经网络的综采工作面视频目标检测
2022-09-16杨艺付泽峰高有进崔科飞王科平
杨艺, 付泽峰, 高有进, 崔科飞, 王科平
(1. 河南理工大学 电气工程与自动化学院,河南 焦作 454003;2. 河南理工大学 河南省煤矿装备智能检测与控制重点实验室,河南 焦作 454003;3. 郑州煤矿机械集团股份有限公司,河南 郑州 450000;4. 郑州煤机液压电控有限公司,河南 郑州 450013)
0 引言
煤炭是我国重要的战略能源,智能化开采是煤炭工业发展的重点方向[1-2]。随着人工智能技术的不断进步和煤矿智能化的持续发展,计算机视觉在保障煤矿安全生产、提高煤炭开采效率和煤矿智能化水平等方面的作用愈加突出[3-5]。视频目标检测是计算机视觉的重要分支。针对工作面关键设备及行人的目标检测及跟踪,是煤矿智能化开采信息感知的重点内容,也是工作面“三机”智能控制的基础信息[6]。
目前,应用于煤矿井下的目标检测方法主要分为传统目标检测和基于深度学习的目标检测两大类。传统目标检测方法大部分是通过人工提取特征并确定视频帧中目标的位置。特征提取方法主要有方向梯度直方图[7]、尺度不变特征变换[8]和可变形组件模型[9]等。针对矿井视频图像人员跟踪中目标尺度变化频繁的问题,孙继平等[10]提出了一种矿井视频图像中人员目标匹配与跟踪方法,基于压缩感知和归一化矩形特征,得到尺度不变压缩特征,提高了目标位置跟踪的准确度。针对行人检测系统中存在的难以同时具有较高检测率和较快检测速度的问题,徐美华等[11]提出了一种自适应由粗到精的可变形 组 件 模 型(Coarse-to-Fine Deformable Part Model,CtF DPM),用于提取井下行人特征,该模型能够在保证检测性能的同时,显著提高检测速度。但这些传统检测方法复杂度较高、特征提取难度较大、泛化能力较差。
随着人工智能技术不断取得突破,基于深度学习的各种神经网络被应用到了井下目标智能识别和检测中,随着计算机算力的不断增强,各类算法的检测精度也得到了极大提升。针对光线强度不确定问题,张银萍[12]首先对轨道图像进行针对性预处理,然后使用Canny算子完成煤矿地面轨道的边缘检测,最后构建了基于YOLOv3算法的识别模型,实现了对运行矿车前方不同光线亮度下不同类别的障碍物检测。卢万杰等[13]采集大量煤矿设备图像建立数据集,通过基于卷积神经网络的目标检测算法,并使用基于粒子群优化的支持向量机建立了煤矿设备匹配模型,该模型对多目标具有较高的识别准确率。针对井下特定设备的检测,林俊等[14]采用基于卷积神经网络的Mask R-CNN模型提取输送带图像,该模型可以自动准确地对输送带区域进行标注,使输送带检测更具针对性。针对采煤工作面行人目标检测方法因网络较深、计算量大而不能达到实时检测效果的问题,董昕宇等[15]提出了一种基于参数轻量化的井下人体实时检测模型,采用深度可分离卷积模块和倒置残差模块构建轻量级特征提取网络,有效解决了井下人员漏检及误检问题,为后续井下目标检测轻量化网络构建提供了新的思路。针对井下人员、采煤机滚筒的检测,南柄飞等[16]提出了一种基于随机采样的实时显著性目标检测、分割提取方法,实现了煤矿井下复杂场景中关键设备的实时感知。韩江洪等[17]将深度学习网络模型移植到嵌入式开发平台,在井下目标识别场景下,提高了目标识别准确率。
综上可知,目前针对井下的目标检测方法存在特征提取难度较大、泛化能力较差、检测目标类别较为单一等问题,且主要应用于巷道、井底车场等较为空旷场景,较少应用于综采工作面场景。综采工作面环境较复杂,地形狭长,且多目标多设备经常出现在同一场景当中,使得目标检测难度加大。针对上述问题,本文提出了一种基于深度神经网络的综采工作面视频目标检测方法。首先,针对综采工作面环境复杂多变、光照不均、煤尘大等不利条件,针对性挑选包含各角度、各环境条件下的综采工作面关键设备和人员的监控视频,并进行剪辑、删选,制作尽可能涵盖工作面现场各类场景的目标检测数据集。然后,通过对 YOLOv4模型[18]进行轻量化改进,构建了轻量化YOLO(Lightweight YOLO,LiYOLO)目标检测模型,该模型对综采工作面环境动态变化、煤尘干扰等具有较好的鲁棒性。最后,将LiYOLO目标检测模型部署到综采工作面,应用Gstreamer对视频流进行管理,同时使用TensorRT对模型进行推理加速,实现多路视频流的实时检测。
1 基于深度神经网络的综采工作面视频目标检测
针对综采工作面的特殊环境,结合开采工艺过程,提出了一种基于深度神经网络的综采工作面视频目标检测方法,其流程如图1所示。
(1) 综采工作面关键设备及人员数据集制作。因煤矿综采工作面环境复杂,存在行人遮挡、护帮板收回放下、滚筒旋转、刮板输送机逆光等问题,因此,制作一套标注准确的综采工作面关键设备及人员的数据集是目标检测的前提。首先调取综采工作面的监控视频,然后对其中含有行人和工作面关键设备的视频进行剪辑、删选,选出具有代表意义的视频,制作数据集,最后使用视觉目标标注工具(Visual Object Tagging Tool,VOTT)对剪辑后的视频进行标注。
(2) 目标检测模型构建。深度学习中的网络框架众多,选取一个能够适应综采工作面复杂条件的网络框架是后期目标检测效果的保障。本文建立了LiYOLO目标检测模型,该模型是对基于Darknet的YOLO模型进行轻量化处理后得到的一种6分类轻量化模型。首先经过主干特征网络CSPDarknet对输入的图像进行初步特征提取;然后通过空间金字塔池化与路径聚合网络增加感受野,通过不同维度的特征融合,使特征得到充分提取,增强网络的适应性;最后利用YoloHead提取的特征进行目标检测。该模型具有良好的检测能力,能够满足综采工作面视频目标检测的实时性和精度要求。
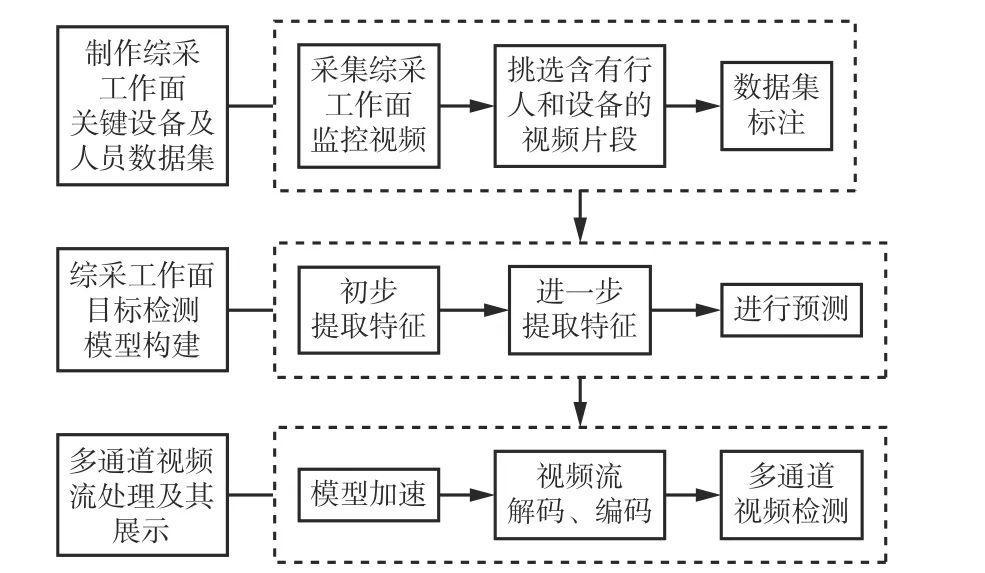
图 1 综采工作面视频目标检测流程Fig. 1 Flow of video object detection in fully mechanized working face
(3) 视频目标检测模型工程部署。将LiYOLO目标检测模型进行工程部署是视频目标检测的落脚点。为保证模型的实时检测,选取TensorRT推理优化器对模型进行推理加速,使模型可以在运行时进行压缩、优化。采用Gstreamer完成视频的编码与解码,并对多路视频流进行高效管理。
2 目标检测数据集制作
不同综采工作面的地质条件、开采环境、配套设备各不相同,使得目标检测关键性特征出现较大差异,从而导致数据集的通用性较差。为此,本文以安徽省淮南市某矿2324工作面为例,结合综采工作面环境特定条件制作视频目标数据集。该工作面液压支架高度低、设备布置紧凑、煤尘和水雾扩散条件差。为使数据集尽可能覆盖主要场景,本文首先根据背景条件对数据集样本进行筛选,然后对标注对象的特性进行分析并绘制标注框,完成整个数据集的制作。
2.1 数据集背景分类
视频的背景因素主要包括光照条件、尘雾和检测区间3个方面,各背景下的图像样本示例如图2所示。

图 2 不同条件下的综采工作面图像Fig. 2 Images of fully mechanized working face under different conditions
2.1.1 不同光照背景下的图像选取
对该矿工作面所部署的摄像头与光源之间的空间关系进行梳理,当光源与摄像头距离较近(通常小于2架液压支架)时,摄像头顺光拍摄效果较好,而逆光拍摄效果较差。为此,本文根据综采工作面实际光照情况,将数据集中光源场景分为顺光和逆光2类情况。同时为确保数据的有效性和样本覆盖范围,将顺光与逆光图像的采集比例设为4∶1。
2.1.2 不同尘雾背景下的图像选取
在煤炭开采过程中,综采工作面充斥着大量煤尘,采煤机会在工作时进行高压喷雾降尘。根据对采煤机喷雾系统与滚筒割煤过程观察发现,当采煤机滚筒转速较慢时,尘雾轻微。而在采煤机高速运转过程中,扬尘起雾现象较为严重。为此,本文根据综采工作面现场情况,将数据集中的尘雾场景分为无尘、轻微、严重这3类情况,为保证数据集在工作面的通用性,将无尘、轻微、严重的图像采集比例设为2∶1∶1。
2.1.3 不同检测区间的图像选取
工作面端头的设备及环境较为杂乱,而中部的背景相对单一。2个复杂度不同的场景中,目标的特征表征方式存在较大差异。为了使目标检测更具通用性,本文将工作面的视频目标检测区间分为端头区间和中部区间2个部分。该矿工作面部署有181架液压支架,端头区间为1-10号和172-181号支架,端头与中部的图像采样比例设为1∶8。但只有端头区间包含检测目标护帮板,所以需适当调高端头区间图像比例,因此,端头与中部区间的图像采集比例设为1∶5。
上述3种情况的图像采集数量见表1。
2.2 数据集目标标注
图像标注的主要目的是为计算机视觉模型提供有关图像的信息,通常使用可视化标注工具对图像进行标注。图像标注时需预先确定标签,称为“类”,并向神经网络模型馈入图像的标签信息。模型经过训练和部署后,将预测和识别尚未标注的图像中的目标对象。本文使用边界框标注技术标注图像,使用这种方法时,会在特定帧围绕目标对象创建一个边界框,并为其选择最适合框中对象的标签。
本文依据综采工作面的实际情况,将关键设备及人员标签分为6类,见表2。
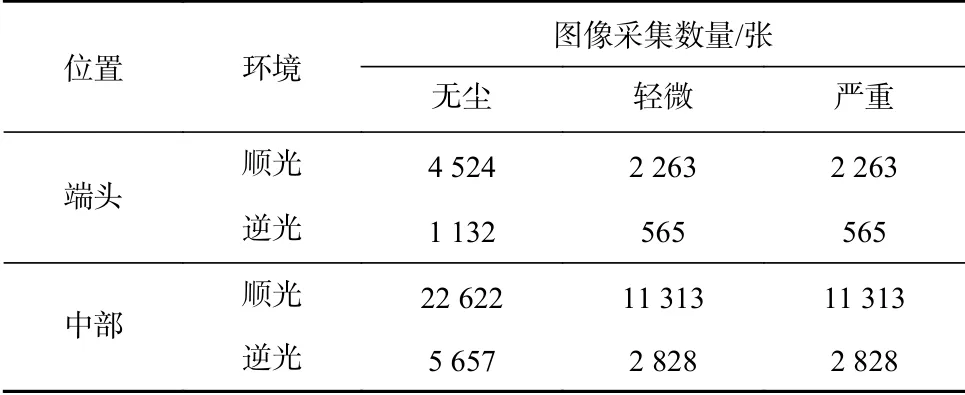
表 1 不同条件下的图像采集数量Table 1 Number of image samples under different conditions
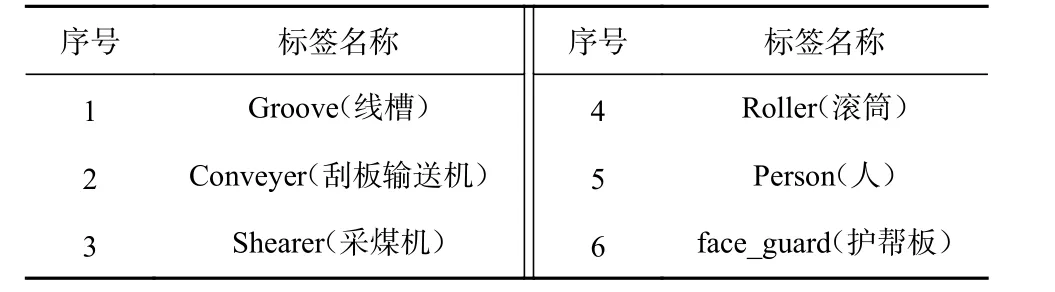
表 2 标签分类Table 2 Classification of labels
以一张含有多个工作面设备及工作人员的图像为例进行标注,整体标注效果如图3所示。
通过VOTT对选取视频片段每帧图像中的工作面设备及工作人员进行人工标注。标注信息包括目标的左上和右下2个锚点的横纵坐标。需要注意的是,锚点坐标需要进行归一化处理,将数据映射到0~1,增加数据分布稠密性,有利于网络的快速收敛。图3中灰色框、绿色框、红色框、橙色框、紫色框标注的目标分别为工作人员、线槽、刮板输送机、滚筒、采煤机。标注要求为标注目标需在标注框中央,且占比应大于2/3。
对于线槽和刮板输送机的标注,因其在图像中成像较为狭长,如果直接使用一个标注框进行标注,将会使标注框过大,从而在目标框中引入大量非目标信息,淹没目标特征,导致检测失败。根据刮板输送机与线槽成像的特殊情况,本文针对线槽与刮板输送机采取分段式标注方式,线槽以栏杆为单位进行标注,刮板输送机以节为单位进行标注,使线槽与刮板输送机得到较为准确标注的同时,也使目标特征完整呈现。

图 3 数据集标注示例Fig. 3 Example of dataset annotation

图 4 LiYOLO模型结构Fig. 4 LiYOLO model structure
在开采过程中,因受煤块影响,滚筒目标容易丢失,导致后续使用目标检测模型追踪检测时,易出现漏检情况。为此,根据滚筒状态,本文采取完整标注方式对采煤机滚筒进行标注,以增加数据集对被遮挡滚筒目标检测的鲁棒性。
3 综采工作面视频目标检测模型构建
3.1 LiYOLO模型构建
Darknet是一种较为轻型的开源深度学习框架,该框架包含YOLO的一系列模型[19]。YOLO模型实现了对标定物体的实时检测,检测精确度较高,同时具备较快的检测速度,能够很好地满足现场部署需求,因此,YOLO系列目标检测模型得到了广泛研究与应用。
在原生的YOLO模型中,使用的数据集为视觉目标分类(Visual Object Class, VOC)数据集,其分类标签为20类,如果本文使用原生YOLO模型进行目标检测,加上表2中的6类综采工作面关键目标,标签分类达26类,分类相对复杂。为适应综采工作面视频目标分类相对较少的问题,本文对Darknet中的YOLO模型进行轻量化处理,形成一种6分类LiYOLO模型。LiYOLO模型结构如图4所示。
在LiYOLO模型中,对于输入的图像,首先使用Darknet中 的CSPDarknet53模 块 提 取 特 征。CSPDarknet53模块通过下采样和多次残差结构的堆叠使网络深度更深,特征提取效果和网络鲁棒性更好。其次采用空间金字塔池化(Spatial Pyramid Pooling,SPP)[20]模块作为承接,SPP模块极大地扩大了感受野,使LiYOLO模型对上下文特征有了更好的理解。然后使用路径聚合网络(Path Aggregation Network,PANet)[21]作为颈部,加强模型对视频目标的特征提取能力。最后,在充分提取视频特征后,使用YoloHead进行目标预测。YoloHead共有3个特征层,以VOC数据为例,3个特征层对应的输出为(19,19,75),(38,38,75),(76,76,75),而为适应本文提出的6类综采工作面关键目标数据集,将这3层的输出修改为(19,19,33),(38,38,33),(76,76,33)。此外,为保障模型检测速度,本文通过在YoloHead中引入深度可分离卷积(Depth Separable Convolution,DS-Conv)代替传统卷积,极大地降低了模型的计算量与参数量。YoloHead改进前后的结构如图5所示。
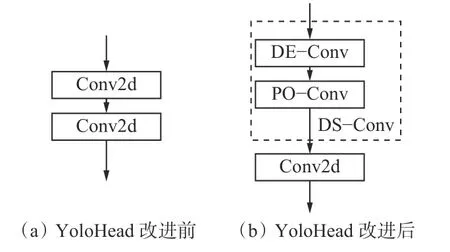
图 5 改进前后 的YoloHeadFig. 5 YoloHead before and after improved
DS-Conv常被用来处理深度神经网络冗余量大的问题,能够降低传统卷积操作中的参数量和计算量,提高模型的训练速度。DS-Conv由深度卷积(Depthwise Convolution,DE-Conv)与 逐 点 卷 积(Pointwise Convlution,PO-Conv)2个部分组成。假设输入数据大小为5×5@3,前2个5为数据的宽和高,3为数据的通道数。首先对数据集进行DE-Conv计算,因输入通道数为3,则使用3个3×3@1卷积核进行卷积运算,特征图输出为5×5@3,DE-Conv的参数量为3×3×3=27,计算量为3×3×(5-2)×(5-2)×3=243;接着进行PO-Conv计算,若要得到4个特征量,则需使用4个1×1@3卷积核进行卷积计算,最终特征图的输出为5×5@4,PO-Conv过程的参数量为1×1×3×4=12,计算量为1×1×3×3×3×4=108。由上述计算可知,DS-Conv训练参数总量为39,计算总量351。若进行传统卷积计算,则参数总量为4×3×3×3=108,计 算 总 量 为3×3×(5-2)×(5-2)×3×4=972,远 高 于DS-Conv的参数量与计算量。因此,相较于传统卷积,深度可分离卷积能够极大降低参数量和运算成本。LiYOLO模型具备较强的尺度适应性和高效的头部特征提取能力,能够较好地应用于综采工作面视频目标检测中。
3.2 模型的训练与测试结果分析
3.2.1 实验环境与配置
用于实验的计算机CPU为Intel Xeon(R) Gold 6146 CPU@3.20 GHz, GPU 为Nvidia Geforce RTX 2080T,系统为Ubuntu18.04.5 LTS,采用了Darknet深度学习框架,并调用OPENCV,CUDA,cuDNN库。
为了使LiYOLO模型能够更好地适应综采工作面相对复杂的环境,本文制作的数据集包含综采工作面各种情况下的设备和工作人员图像,共计67 873张。数据集分为训练集与验证集,其中53 760张用来训练模型,14 113张用来验证模型。在训练过程中一个处理单元为64张样本图像,初始训练的学习率为0.001,迭代到144 000次时,学习率衰减10倍,162 000次迭代时,学习率又会在前一个学习率的基础上衰减10倍。动量设置为0.949,权值衰减设置为0.000 5。
3.2.2 评价指标
本文采用召回率(Recall)、平均准确率均值(mean Average Precision,mAP)2种 评 价 指 标 对LiYOLO模型进行评价。Recall是被正确识别出来的正样本个数与测试集中所有正样本个数的比值;mAP是对所有类别的平均准确率取均值。这两者都能在一定程度上体现目标检测的效果,Recall、mAP的值越高,表示该目标检测模型效果越好。
召回率r的计算公式为

式中:TP为设备及行人被正确检测的数量;FN为漏检的数量。
mAP计算公式为
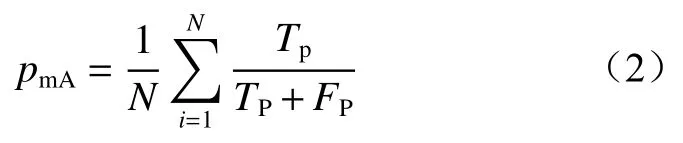
式中:N为标签总数,本文中N=6;FP为检测框与真实框的IoU(Intersection over Union,交并比)阈值小于所设阈值的数目,本文IoU设置为0.5。
3.2.3 实验结果与分析
为保证实验结果的客观性,在同等条件下将LiYOLO模型与YOLOv4进行对比,两者的mAP和损失函数变化曲线如图6、图7所示。
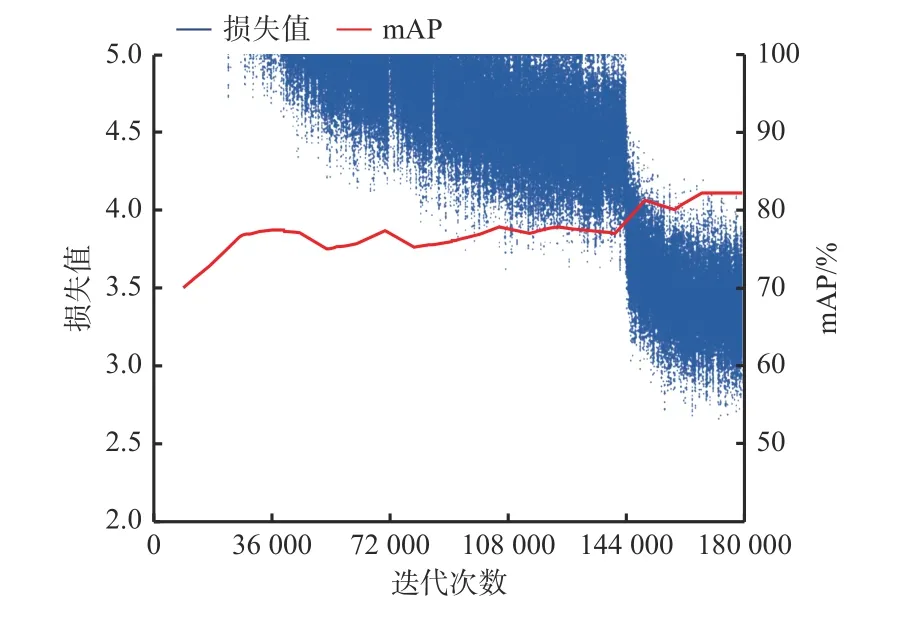
图 6 YOLOv4模型的mAP和损失变化曲线Fig. 6 mAP and loss variation curves of YOLOv4 model
从图6、图7可看出,LiYOLO模型的mAP变化曲线呈平滑稳步上升趋势,而YOLOv4模型的mAP变化曲线波动明显,表明LiYOLO模型具有更加稳定的特征提取能力。此外,YOLOv4模型的mAP在162 000次迭代后达到最大值,而LiYOLO模型的mAP在144 000次迭代附近便达到了最大值,LiYOLO模型相较于YOLOv4模型有更好的收敛性。进一步对比发现,YOLOv4模型的损失值从36 000次迭代后慢慢收敛至5以下,而LiYOLO模型的损失值在20 000次迭代就开始收敛至5以下,LiYOLO模型在收敛速度上要快于YOLOv4模型。
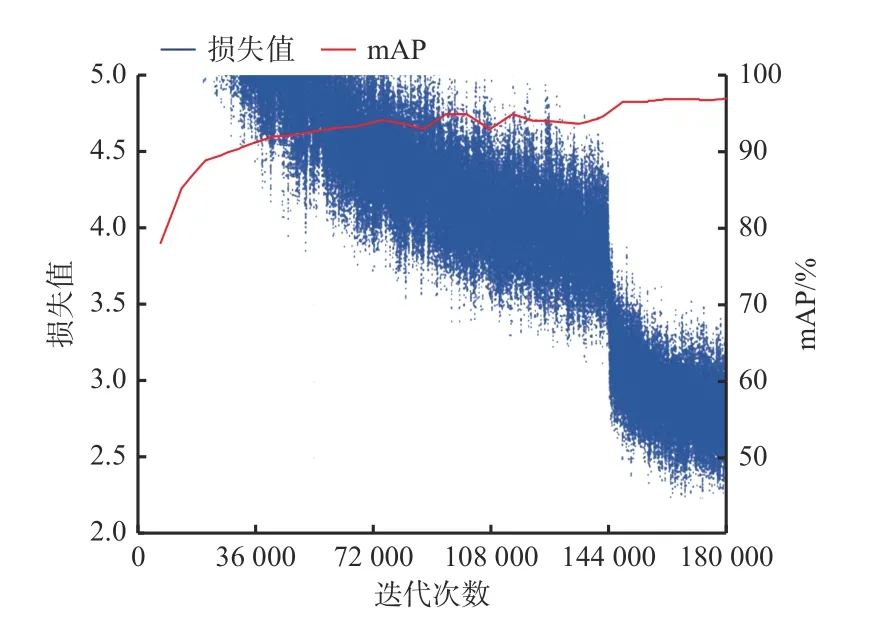
图 7 LiYOLO模型的mAP和损失变化曲线Fig. 7 mAP and loss variation curves of LiYOLO model

图 8 3种模型对不同场景下设备及行人的检测效果Fig. 8 Detection effect of three models for devices and pedestrians in different scenes
YOLOv4模型与LiYOLO模型各评价指标实验结果见表3。可看出在主要的评价指标mAP、Recall上,LiYOLO模型比YOLOv4模型 分别高14.79%、5%。表明LiYOLO模型能够提取更加丰富的工作面关键设备及人员的基本特征,检测效果更好。YOLOv4模型针对的是26类目标进行分类,因此其收敛效果较差,而LiYOLO模型仅针对井下关键设备及人员的特定6类目标进行分类,提取特征更具针对性,收敛性更好。
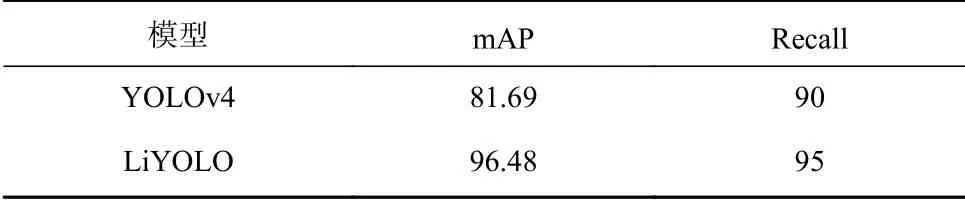
表 3 主要实验结果对比Table 3 Comparison of main experimental results %
为了进一步验证LiYOLO模型在工作面关键目标检测中的有效性,本文挑选了采煤机开采、单人巡检、多人巡检3组经典场景验证模型应用于复杂场景时的效果,并与YOLOv3、YOLOv4模型进行对比,检测效果对比如图8所示。
第1组原图中包含的检测目标有线槽、刮板输送机、采煤机、滚筒、行人,从检测结果可以看出,对于靠近摄像头的设备,如线槽和刮板输送机,3个模型的检测效果相差无几,而对于离摄像头较远、尺度较小的行人,LiYOLO模型的检测效果较好,而YOLOv3、YOLOv4模型均未检测出行人。在第2组原图中有2名工作人员,且存在人与人之间遮挡的情况,LiYOLO模型相较于其他2个模型提取到了被遮挡行人的轮廓特征,完整地检测出了2个人,而其余2个模型均未检出。第3组原图中包含有多台尺寸不同的刮板输送机,从检测结果可以看出,LiYOLO模型对于近中远各尺度的设备的检测效果均优于YOLOv3、YOLOv4模型,具有更良好的适应性。第1组实验的行人处于顺光条件下,第2组实验的行人处于逆光条件下,结合2组实验检测效果发现,在不同的光照情况下,LiYOLO模型都可以保证工作面关键设备及行人的检测率,而其余模型的鲁棒性较差。上述结果表明,在光照强度不同、是否有遮挡、目标尺度变化等的情况下,LiYOLO模型都能够准确检测出目标数量及种类,具有更好的鲁棒性。
此外,对于输入为1 920×1 080的图像,各模型的检测时间见表4,LiYOLO模型检测速度近乎是YOLOv3模型的2倍。对于输入为1 920×1 080的视频,LiYOLO模型的每秒传输帧数(Frames Per Second,FPS)均高于其他2 个模型。
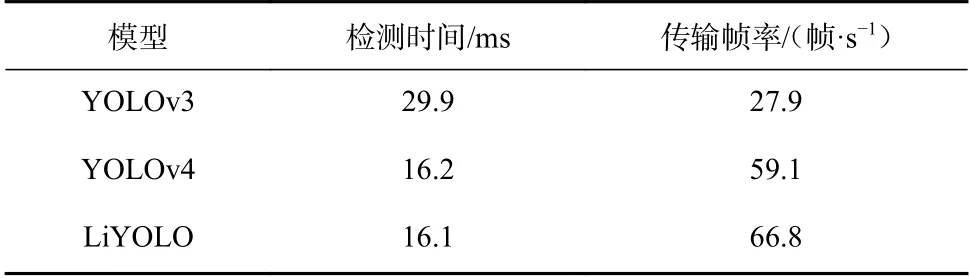
表 4 检测时间Table 4 Detection time
综合实验结果可知,在相同条件下,LiYOLO模型能检测出的目标数量更多,种类更完整,检测速率更快。
4 综采工作面视频目标检测模型的工程部署
在LiYOLO目标检测模型的工程部署中,首先需将井下相机采集到的视频流通过光纤传输到调度室的服务器中,再对多路视频流进行处理。本文采用Gstreamer媒体框架管理视频流,该框架可以实现视频的采集、编码、解码、渲染、滤镜等功能。但Gstreamer的重心在于如何处理视频流,而未能将视频流处理与深度学习相结合。因此,本文在Gstreamer的基础上,结合TenserRT高性能深度学习推理优化器,以实现管理多路视频流的同时,对各路视频流的检测进行推理加速。TensorRT可以为深度学习的网络框架提供低延迟、高吞吐率的部署推理。该推理优化器支持目前几乎所有的主流框架(Pytorch,TensorFlow,Caffe等)。LiYOLO模型工程部署过程如图9所示。
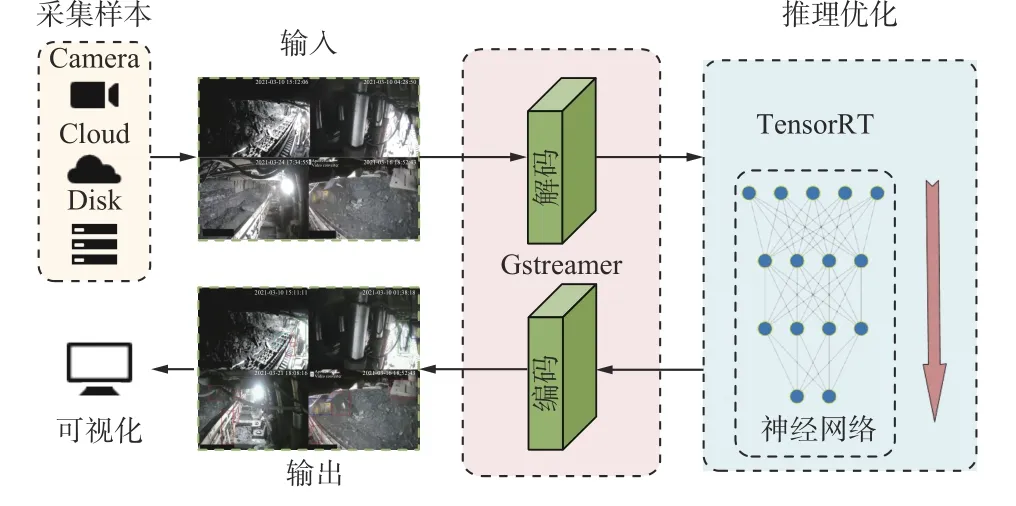
图 9 LiYOLO模型工程部署过程Fig. 9 Project deployment process of LiYOLO model
基于LiYOLO模型的多视频检测效果如图10所示。可同时检测、展示6路视频,且对于不同场景下的检测目标都有较好的检测效果。

图 10 多路视频检测效果Fig. 10 Multi-video detection effect
为进一步验证TensorRT对于LiYOLO模型推理加速的效果,本文设计了一组加速前后的对比试验,结果见表5。因实验环境需求,本次对比实验在Tesla T4高性能运算显卡上进行,从模型大小分析,LiYOLO原模型大小为256 MB,经过TensorRT压缩后的模型大小仅为167 MB,节省了近1/3的空间,极大降低了电脑内存负荷。从传输帧率分析,针对输入为1 920×1 080的视频流,经过TensorRT推理加速的模型相较于原模型,传输帧率提高了30.2帧/s,极大地提高了检测效率,能够很好地满足工作面关键设备及人员的实时检测需求。
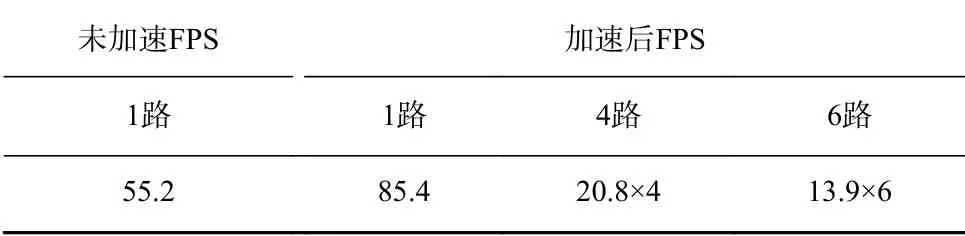
表 5 未加速与加速后模型FPS对比Table 5 Comparison of FPS between the unaccelerated model and the accelerated model 帧/s
5 结论
(1) 针对综采工作面环境复杂多变、光照不均、煤尘大等不利条件,针对性挑选包含各角度、各环境下的综采工作面关键设备和人员的监控视频,并对其进行剪辑、删选,制作了涵盖综采工作面现场的各类场景的目标检测数据集。
(2) 构建了LiYOLO目标检测模型,首先经过主干特征网络CSPDarknet对输入的图像进行初步特征提取;然后通过空间金字塔池化与路径聚合网络扩大感受野,通过不同维度的特征融合,使特征得到充分提取,增强网络的适应性;最后利用YoloHead提取的特征进行目标检测。与YOLOv3、YOLOv4模型相比,LiYOLO目标检测模型具有良好的检测能力,能够满足综采工作面视频目标检测的实时性和精度要求,在综采工作面数据集上的mAP为96.48%,召回率为95%,同时检测视频的帧率达67帧/s。
(3) 完成了LiYOLO目标检测模型在综采工作面的工程部署。使用基于Gstreamer的视频流处理模块管理多路视频流,应用TensorRT优化器对LiYOLO目标检测模型进行加速,有效提升了模型的运算速度,可快速实现综采工作面视频目标的检测,且支持多路视频流的实时检测,针对光照、煤尘等不同环境也具有较好的目标检测效果。
