基于数据重构增强的采空区遗煤自燃预测模型
2022-09-16王民华
王民华,牛 显
(1.山西能源学院 矿业工程系,山西 太原 030006;2.内蒙古工业大学 矿业学院,内蒙古 呼和浩特 010051)
采空区遗煤自燃是煤炭开采过程中面临的主要灾害之一,对采空区遗煤自燃特征参数的快速准确预测,是实现煤矿安全高效生产的重要的技术保障。煤自燃灾害的防治应当遵循精准、快速、智能的原则,以实现煤自燃火灾由被动治理向主动防控的根本性转变[1],煤炭自燃智能预测预报,是矿井自燃灾害主动防控的主要技术手段之一。近年来煤矿智能化开采是我国煤炭综采技术发展的新阶段,也是煤炭工业技术革命和升级发展的需求和必然方向,智能化开采的核心三要素为智能感知、智能决策和智能控制[2]。进行矿井灾害智能决策研究,可以为煤矿智能化提供数据支持,准确及时修正控制决策方案,为矿井自适应智能化开采提供安全技术保障。
随着计算机与信息科学技术的进步,煤自燃预测预报方法正朝着智能化的方向发展,多年来大量学者开展了机器学习在煤炭自燃预测方向的研究。王德明等[3]根据专家给出的危险性判别指标,建立了一种新的基于无导师神经网络的聚类发火危险性预测模型;徐精彩等[4]运用动量法对BP 神经网络进行了算法改进,建立了了煤自燃极限参数的BP 神经网络预测模型;周福宝等[5]提出了一种基于BP 网络的多参数火区复燃预测方法,并建立了预测模型;桂祥友等[6]运用BP 神经网络的时间序列预测模型对煤炭自然发火进行预测;程结园等[7]提出了基于小波神经网络的多传感器信息融合技术应用于煤炭自燃火灾的监测,建立一个煤炭自燃监测的综合评判系统;赵伟等[8]建立了基于模糊C 均值聚类的方法的矿井待开采煤层自燃的可能程度预测模型;边冰等[9]利用LVQ(学习向量量化)神经网络建立了一种基于学习向量量化神经网络的煤自然发火预报系统;温廷新等[10]提出了基于KPCA-Fisher 判别分析的煤炭自燃预测模型;邢媛媛等[11]根据最小信息鉴别原理,利用反熵权法确定了评价指标的权重,构建了基于理想点法的煤炭自燃风险评价模型;孟倩[12]运用用支持向量机、粒子群算法、粗糙集等智能算法进行煤炭自燃预测的建模,并进行了模型预测对比;邓军等[13-15]建立了PCA-PSOSVM 预测模型、参数优化的PSO-RF 预测模型、COWA 修正的G1 组合权重云等模型用于识别煤矿自燃危险性。
综上所述,在煤炭自燃数据驱动智能预测方向,经过多年研究,形成了大量研究成果,但能用于生产现场实际成功的预测模型案例鲜有报道。主要原因是数据样本过少,以及现场监测样本数据多为不发火状态,数据样本特征单一,足够多的样本容量和均匀的样本分布是决定预测模型的准确性和稳健性的2 个关键因素[16]。在机器学习中煤炭自燃预测属于典型的小样本预测问题,目前对于小样本数据增强和重构的有效方法之一,是运用GANs 生成式对抗网络,生成虚拟样本。GANs 作为一个具有“无限”生成能力的模型,利用欠完备的2 组样本数据,生成与真实数据分布一致的数据样本,并且能增强数据特征[17]。为此,通过生成式对抗网络生成更加真实的采空区遗煤自燃样本数据,提高模型的泛化能力,形成自适应的采空区遗煤自燃智能决策模型。
1 WGANs-GP 数据增强算法
生成对抗网络是一种无监督的学习方法,它是根据博弈论中的二人零和博弈理论提出的,GANs具有1 个生成器网络和1 个判别器网络,并通过对抗学习进行训练[18]。GANs 示意图如图1。
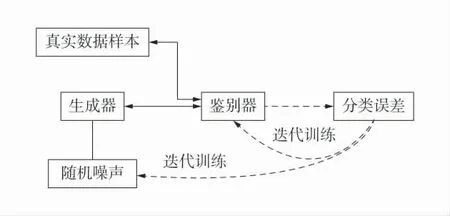
图1 GANs 示意图Fig.1 Schematic diagram of GANs
GANs 训练过程中,先将数据样本噪声z~PZ送到生成器。判别器对真实数据或生成数据中的部分样本进行判断。判别器的输出可以表示为:
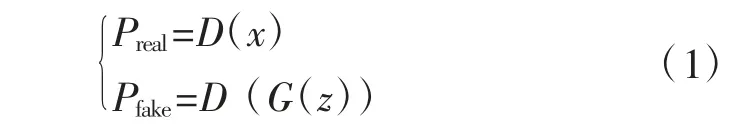
式中:Preal为判别器对真实样本的判别概率;Pfake为判别器对生成样本的判别概率;D(x)为生成器函数;G(z)为判别器函数;D(G(z))为复合函数。
生成器希望增大判别器G(z)的概率输出Pfake,对给定的生成器,判别器则要在最小化Pfake的同时寻求Preal的最大化。判别器和生成器中损失函数为:

式中:LG、LD为生成器和判别器的损失函数;E为样本的期望值。
在生成器和判别器之间建立1 个博弈关系,使2 个网络可以同时训练,其博弈模型目标函数可以表示为[18]:

式中:VGANs(G,D)为对抗网络的价值函数。
GANs 网络在使用权重剪枝的方式时,会让大多数的权重极端化,会使得网络的拟合能力大大减弱,同时,权重更新变化过大导致训练不稳定,容易发生梯度消失或者梯度爆炸。2017 年蒙特利尔大学学者Martin[19]等提出一种WGANs-GP 的形式作为改进,用梯度惩罚(Gradient Penalty)的方式代替权重剪枝,使得权重的分布正常化,不再集中在剪枝范围的两极,缓解训练困难的问题。
2 基于生成式对抗神经网络的数据增强
由于采空区观测工作量大,埋管维护工作困难,所以采空区遗煤自然预测所使用的样本数据容量较少,属于典型的面向小样本数据特征的预测,所建立的机器学习预测模型往往外推泛化能力较弱。通过WGANs-GP 学习原始数据样本的内部分布信息,从而得到与小样本分布一致的生成样本,然后将生成样本添加到原样本中以达到数据增强的作用[20]。采用WGANs-GP 算法通过生成器D 能够学习到采空区遗煤自燃监测数据的真实分布,那么生成器D 就能生成原来不存在采空区遗煤自燃监测数,但又很真实的样本数据,然后把真实数据集和虚拟数据集进行合并,再运用机器学习算法训练扩容增强的数据集建立采空区遗煤自燃预测模型。预测模型框架图如图2。

图2 预测模型框架图Fig.2 Frame diagram of prediction model
2.1 数据现场实测与处理
现场数据实测来源于晋煤控股三元福达煤业15101 工作面,15101 工作面煤层平均厚度4.5 m,采用一次采全高综合机械化采煤法,矿井属高瓦斯矿井,15#煤层自燃倾向性为Ⅱ级。15101 工作面现场监测方案为:在进回风巷共布置8 个测站,每个测站距离为15 m,预先把热电偶线和束管布置在钢管内,观测有效工作面推进距离为150 m。工作面测点布置示意图如图3。
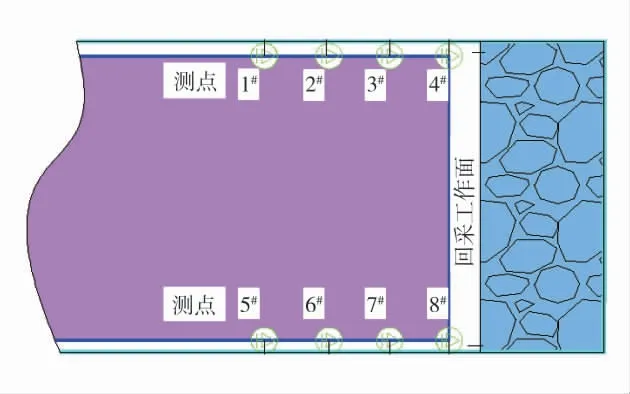
图3 工作面测点布置示意图Fig.3 Schematic diagram of measuring point layout in working face
随工作面推进过程中共收集到包含工作面距离、采空区温度、O2、CO、CO2、CH4信息的312 条数据信息,剔除数据噪声共保留272 条数据用于预测模型的学习训练。由于数据样本中CO 数据只有3 号测站测得有效数据,CO 数据特征值不明显,属性的取值对特征的提取意义不大,数据样本中剔除了CO数据,本次预测模型,采用工作面距离、O2、CO2、CH4为输入值,采空区温度为输出预测值。
2.2 参数设置
采用Facebook 公司发布的Python 机器学习库PyTorch 来构建和训练WGAN-GP 模型。WGAN-GP模型中判别器G 和生成器D 都是3 层全连通神经网络,其中神经网络的层数和神经元数量对于在当前样本数据下模型所生成样本数据的特征质量有决定性的作用,参考文献[21-24],采用试错法,确定了判别器G 和生成器D 的神经网络结构参数。
生成器D 网络结构参数:输入维度100 的随机噪声;第1 层全连接神经网络32 个神经元、LeakyReLU 激活函数;第2 层全连接神经网络64 个神经元、LeakyReLU 激活函数;第3 层全连接神经网络128 个神经元,LeakyReLU 激活函数;第3 层全连接神经网络5 个神经元,Tanh 激活函数。
判别器G 网络结构参数:输入维度为5 的样本;第1 层全连接神经网络256 个神经元,LeakyReLU 激活函数;第2 层全连接神经网络128个神经元,LeakyReLU 激活函数;第3 层全连接神经网络1 个神经元。
训练中为了保持对抗训练平衡,设置判别器模型与生成器模型的更新次数为1∶2,以确保判别器损失值不会为0。其他参数具体设置为:学习率0.000 1、小批量大小16、adam 一阶矩估计参数0.5、adam 二阶矩估计参数0.999。
2.3 样本数据相关性
WGAN-GP 模型生成的数据样本中,存在一定量的数据偏离了真实数据的上下限,例如温度数据中存在小于20 ℃的数据,和实际情况不符,这种和实际情况不符生成的原始分布的数据加入训练集后,将会严重影响模型的泛化能力。为了解决生成数据分布特征和实际情况不符的问题,采用斯皮尔曼等级相关系数对生成的虚拟数据和实测数据的相关性进行评价。虚拟数据预处理后,对各参数之间的相关属性ρ 进行分析,其计算方式如下[25]:
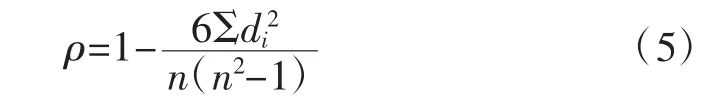
式中:n 为数据的数量;di为2 个数据次序的差。
实测数据参数相关性分布图如图4,虚拟扩容数据参数相关性分布图如图5。由图4 和图5 可知,虚拟扩容数据各参数属性之间的相关性和实测数据各参数属性的相关性非常相近,说明扩容数据能够很好表达实测数据的特征分布。
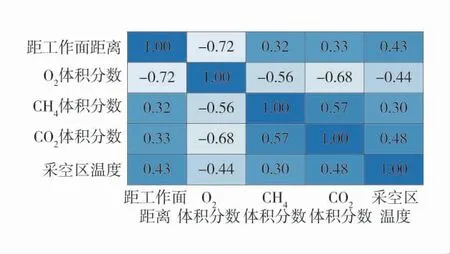
图4 实测数据参数相关性分布图Fig.4 Correlation distribution of measured data parameters
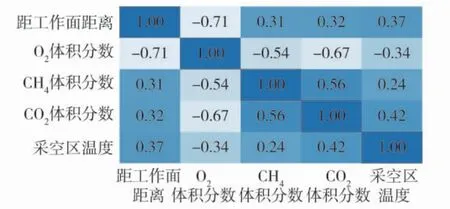
图5 虚拟扩容数据参数相关性分布图Fig.5 Correlation distribution of virtual capacity expansion data parameters
使用对抗神经网络生成虚拟数据样本的数量,不是越多越好,往往生成的虚拟数据样本中存在特征不明显的低质量数据,会影响后期预测模型的预测精度和外推能力,虚拟样本的生成数量需要根据真实样本数据特征,以及所预测问题的具体情况选择,参照文献[26-28],并结合研究数据集的特征,发现实测数据集扩容1 倍虚拟数据时,数据样本集的特征分布和实测数据集非常相似,为此,使用1 倍的生成虚拟样本进行真实样本数据的扩充。生成的扩容数据集分布如图6~图9,由实测和扩容样本数据集分布示意图可知,所生成的数据集分布相似,并且比原实测数据集有一定的外扩。

图6 实测和扩容温度数据集分布示意图Fig.6 Distribution diagram of measured and dilated temperature data sets

图7 实测和扩容氧气体积分数数据集分布示意图Fig. 7 Distribution diagram of measured and expanded oxygen volume fraction data sets

图8 实测和扩容甲烷数据集分布示意图图Fig. 8 Schematic diagram of the distribution of measured and expanded methane data sets

图9 实测和扩容二氧化碳数据集分布示意图Fig. 9 Distribution diagram of measured and expanded CO2 data sets
3 预测模型
3.1 GA-BPNN 预测模型
使用WGAN-GP 模型生成的数据样本和现场实测的数据样本进行混合,得到数据增强扩容的采空区遗煤自燃预测训练数据集,使用AI 模型进行数据集的学习训练,并建立采空区遗煤自燃预测模型。
机器学习算法在工业问题预测中应用较为广泛,近年来发展较快的深度学习模型也已经在许多工业问题预测中进行了运用,例如DCNN、RNN、LSTM、GRU 等模型,在相关工业问题预测和机械故障诊断中都获得了一定竞争力的性能,但是深度学习模型往往较为复杂,对于很多工业预测性问题的解决有一定的局限性,使用配置良好的简单机器学习模型对工业性预测问题的解决,完全可以取得良好的效果。BP 神经网络是工业预测中应用最为广泛和成熟的人工神经网络,为此,使用遗传算法GA 对BP神经网络的参数和结构进行寻优,消除BP 神经网络的缺点建立采空区遗煤自燃预测的进化神经网络(GABPNN)预测模型,并和其它模型进行对比分析。
神经网络结构参数进化过程中,搜索空间取1个隐含层,节点数范围为5~50;种群规模为35 个,杂交概率0.82,变异概率0.25;初始权值进化过程中,搜索范围为-10.0~10.0;种群规模80 个,杂交概率0.96,变异概率0.05。BP 网络学习率取0.1,动量项系数为0.5。在模型训练过程中,随机抽取样本数量的20%为测试样本。GA-BPNN 实测数据训练集测试样本如图10,GA-BPNN 增强扩容训练集测试样本如图11。

图10 GA-BPNN 实测数据训练集测试样本Fig.10 GA-BPNN test sample of training set of measured data
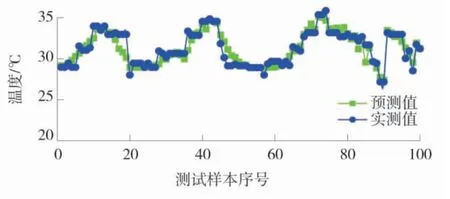
图11 GA-BPNN 增强扩容训练集测试样本Fig.11 GA-BPNN test sample of enhanced capacity expansion training set
3.2 模型对比
为了进一步研究使用WGANs-GP 模型对实测数据进行增强扩容数据集对采空区遗煤自燃预测模型性能的影响,使用相同增强扩容的数据集分别建立了GA-SVM 预测模型和随机森林RF 预测模型。
支持向量机(SVM)是基于统计学习理论的一种通用学习方法,采用遗传算法(GA)对其参数优化,提高模型的训练效果。支持向量机优化学习参数为3 个,惩罚系数C、不敏感损失系数ε、基函数带宽δ。种群规模设置为80 个,杂交概率(交叉概率)0.9,变异概率0.1,倒序概率0.2。在模型训练过程中,随机抽取样本数量的20%为测试样本。GA-SVM 实测数据训练集测试样本如图12,GA-SVM 增强扩容训练集测试样本如图13。

图12 GA-SVM 实测数据训练集测试样本Fig. 12 GA-SVM test sample of measured data training set

图13 GA-SVM 增强扩容训练集测试样本Fig.13 GA-SVM test sample of augmentation and capacity expansion training set
随机森林(RF)是一种基于分类树的算法,它可以用于分类和回归问题,它由决策树的分类器构成,树的构建遵从分类与回归树策略。随机森林(RF)模型训练速度快,容易做成并行化方法,对于不平衡数据集来说,随机森林可以平衡误差。随机森林在解决回归问题时,在超越训练集数据范围的预测能力较差。
决策树的数量达到100 时,R2呈平缓趋势且数值达到最大,决策树的深度为4.5~5.5 时,模型拟合效果达到最好[29]。为此,训练过程中决策树量参数设置为100,决策树深度参数设置为5。在模型训练过程中,随机抽取样本数量的20%为测试样本。RF 实测数据训练集测试样本如图14,RF 增强扩容训练集测试样本如图15。
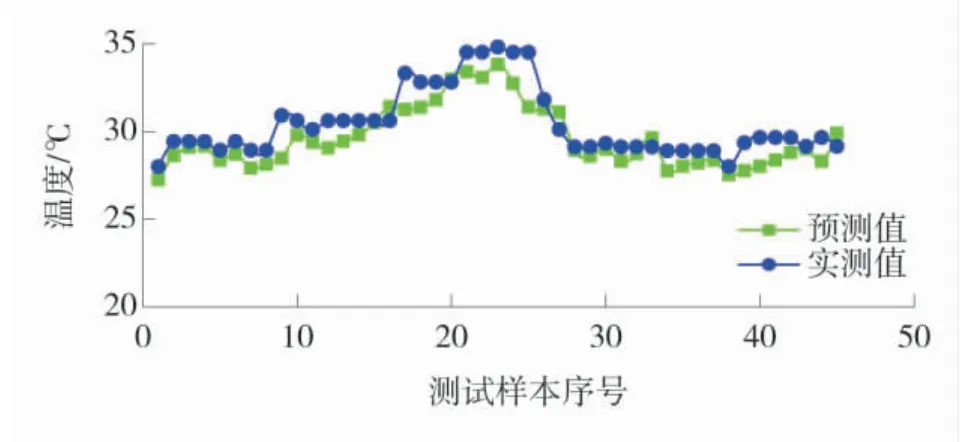
图14 RF 实测数据训练集测试样本Fig.14 RF test sample of training set of measured data

图15 RF 增强扩容训练集测试样本Fig.15 RF test sample of enhanced capacity expansion training set
不同训练数据集和模型预测性能指标见表1。由表1 可知,使用增强扩容的数据集进行训练,3 种预测模型的R2指标均有提高,GA-BPNN 模型提高了12%,GA-SVM 模型提高了4%,RF 模型提高了3%,GA-BPNN 模型R 2 指标提高幅度最大;3 种预测模型MAE 指标均降低,GA-BPNN 模型降低了0.67 ℃,GA-SVM 模型降低了0.54 ℃,RF 模型降低了0.33 ℃;3 种预测模型RMSE 指标均降低,GABPNN 模型降低了0.41 ℃,GA-SVM 模型降低了0.46 ℃,RF 模型降低了0.39 ℃。增强扩容的数据集对3 种预测模型的泛化能力都有提高,其中GABPNN 模型预测性能提高幅度较大。

表1 不同训练数据集和模型预测性能指标Table 1 Performance indicators predicted by different training data sets and models
4 结 语
1)采用WGAN-GP 生成式对抗神经网络,进行反映真实数据特征分布的虚拟样本生成过程中,需要根据实测数据及样本实际合理范围上下限进行数据的处理,虚拟数据扩容的数量对数据的相关性及后期模型预测精度的影响非常大。所使用的数据集,在扩容1 倍的虚拟样本数据后,增强扩容数据集的各参数的相关性变化不大。
2)采用斯皮尔曼等级相关系数对生成的虚拟数据和实测数据的相关性系数进行计算,虚拟数据和实测数据集中各参数属性的相关系数变化幅度较小,各指标相关性变化幅度均未超过20,数据集扩容后各参数相关性变化不大,较好保留了数据的特征分布。
3)使用增强扩容数据集进行3 种预测模型的训练,各模型的预测性能均有提高,其中R2指标GABPNN 模型提高12%,GA-SVM 模型提高4%,RF 模型提高3%,;MAE 指标均降低,GA-BPNN 模型降低0.67 ℃,GA-SVM 模型降低了0.54 ℃,RF 模型降低0.33 ℃;RMSE 指标均降低,GA-BPNN 模型降低0.41 ℃,GA-SVM 模型降低0.46 ℃,RF 模型降低0.39 ℃。增强扩容的数据集对3 种预测模型的性能都有提高,其中GA-BPNN 模型预测性能提高幅度最大。
