基于“嵩山”超级计算机系统的大规模管网仿真
2022-09-15杨周凡李冰洋谢景明刘勇杰
杨周凡,韩 林,李冰洋,谢景明,韩 璞,刘勇杰
(1.郑州大学 信息工程学院,郑州 450000;2.郑州大学 国家超级计算郑州中心,郑州 450000)
0 概述
随着世界各国对清洁能源需求的不断增长,供水管道在能源结构中发挥着重要的作用[1-2]。由于供水管道规模的扩大,导致拓扑结构也越来越复杂[3-4]。供水管道中数值的准确预测对整个管道建设和管道安全至关重要,供水管道系统的高效仿真是解决上述问题的重要手段[5]。初期人们可通过对数值方法进行改进,也可以使用更好的计算设备提升模拟计算效率,但是随着管网拓扑结构大规模的扩大以及CPU 功耗墙的出现,该方法性能逐渐降低。
近年来,GPU 加速器开始广泛用于科学计算,其提供了优越的计算处理能力和内存带宽,并提高了计算效率[6-8]。文献[8]提出一种加速单GPU 芯片上开放通道和管道组合流瞬态模拟的方法。在计算统一设备架构(CUDA)的线程级并行结构中,GPU 可以很好地利用其固有的并行性[9-10]。但是,对大规模管道网络仿真计算时,仿真计算粒度密集,而传统计算机受限于计算粒度密集的程序,可能会影响供水管网大规模数值模拟时的效率。“嵩山”超级计算机是我国自主研发的新一代E 级超级计算机,其采用符合超算国际主流趋势的海光1 号CPU+海光1 号DCU 加速器的异构体系结构,所配备的DCU 加速器件使得该平台更适合于部署高度密集型计算应用。因此,供水管网模拟系统在“嵩山”超级计算机平台上进行模拟计算,可以进一步突破瓶颈提升计算性能。
尽管管网在超级计算机平台上比传统CPU 具有更高的计算效率,但单个DCU 节点的极限存储和计算能力可能会影响管网在超扩展尺度上处理计算系统时的效率。在这种情况下,如果在多块DCU 中进行计算,则需大幅扩展管网模拟计算的规模。
本文提出一种有效的并行化方案来提高管网的计算效率。面向“嵩山”超级计算机平台,利用HIP-C 语言修改程序完成程序跨平台移植,在单DCU 中实现计算的并发。针对管网中管道元件中数据依赖问题,对其进行数据划分,并结合HIP 编程模型和消息传递接口,将多个DCU 加速器集成到网络体系结构中,通过高效的混合并行化方案对管网进行优化[11]。
1 相关工作
本节主要介绍管网管道拓扑结构,并描述HIP+MPI 混合编程。
1.1 管道网络模型
管道运输是各种清洁能源开发与输送过程中一项重要的技术[12-13]。目前,管道运输技术已有很多成熟的理论和模型,随着计算机技术和网络通信的飞速发展,能源运输技术也逐渐实现了信息化,运输管道仿真模拟系统应运而生。模拟仿真通过把数据访问接口连接到系统,及时更新数据,将实时数据传入到系统中进行计算,实现管网的动态模拟仿真[14-16]。
首先以管网实际拓扑图为基础来考虑管网模型,为清晰地描述管网的模拟计算过程,本文通过以下简单管网进行说明。图1 所示是一根独立管道的两个边界节点。图2 所示是一个简单的管道系统,中间用一个非管道元件连接两根管道,共有4 个临界点。图3 所示为扩大管道规模后构建一个闭环的管道系统,管道内由方程计算的值与非管道元件内由方程计算得出的结果通过边界值计算进行数值交互,模拟仿真得出需要的数值。

图1 单个管道图Fig.1 Single pipeline diagram

图2 简单的管道系统Fig.2 Simple pipeline system

图3 闭环的管道系统Fig.3 Closed-loop pipeline system
1.2 MPI+HIP 混合编程
并行计算在不同的粒度层次优化,粒度一般分为粗粒度和细粒度。在集群上多个进程进行计算,进程间通过消息传递的方式进行通信[17-18]。由于MPI 的通信占用成本较高,因此更适合任务划分清晰、通信不频繁的粗粒度并行[19-20]。与MPI 相比,DCU 擅长大规模密集计算,可在细粒度上进行并行计算。本文结合MPI和DCU 的优点,通过MPI 消息传递机制控制多进程计算,实现粗粒度上的并发,并在每个进程中使用DCU实现线程级计算和细粒度上的并发[21]。
“嵩山”超级计算机一个节点内共有4 块DCU,如果只在单DCU 中进行计算,每个节点的计算能力没有被充分利用。为扩展DCU 计算规模,在实现多DCU 计算时,MPI+HIP 混合编程可以发挥优势,为每一个DCU分别分配一个进程,使用MPI 控制多进程计算并进行通信[22-23]。进程之间使用消息传递接口传输数据,进程内采用HIP 技术进行线程级优化,实现粗粒度和细粒度的结合,提升科学计算的性能。HIP+MPI 混合编程结构如图4 所示。

图4 MPI+HIP 混合编程结构Fig.4 MPI+HIP mixed programming structure
2 管网仿真计算的异构实现
2.1 管网计算的并行性
管网模拟仿真系统在进行数值模拟时,大量的数据增加了计算时间,影响数值模拟的时间和精度。根据上文的内容可以了解到DCU 的计算能力,这可以解决目前模拟计算中所遇到的问题。下面将详细介绍管网拓扑结构中管道与非管道的并行特性。参照图3 结构中各元件计算的流程如图5 所示。

图5 管网元件计算流程Fig.5 Calculation procedure of pipeline network components
本文管道网络仿真计算基于王海[13]提出的立体管网建模方法。将管网“对象化”,然后把管网元件的对象属性赋予具体数值,得到每个元件与相邻元件的连接属性以及每个元件的初始状态和边界条件。管道元件和非管道元件在初始化后,可开始第1 个时间步长的计算,每次计算完成后,需要进行收敛分析,如果计算精度达到0.000 1%,则结束循环。这时能够得到稳态时管道元件与非管道元件的流量、压力和水力工况等数值。
在分析该程序代码进行数值模拟计算时,首先需要设置循环条件,直到计算结果不发散才可计算结束。在外循环中先对非管道元件进行计算,在逻辑上将数组进行切分,数组不同的分段执行不同的非管道元件,使用hipDeviceSynchronize()函数进行同步,直到所有非管道元件计算完毕,才能对管道元件进行计算,然后同步直到所有管道元件计算完成。以上所有步骤在内循环每5 000 次后进行数值更新,并对计算结果进行收敛计算,直到计算结果收敛或达到最大循环次数,整个循环计算结束。在此过程中,各个非管道元件之间的计算是独立的,管道元件之间的计算也没有依赖,管道和管道、非管道与非管道之间有较高的并行度。因此,可以考虑在粗粒度上把各管道和非管道元件作为求解任务,将其传输到设备端进行并行计算。
2.2 异构实现
供水管网仿真系统代码是由C/C++语言编写的,本文通过使用HIP-C 对代码进行改写,改写后的代码可以在“嵩山”超级计算机上运行并进行测试。通过测试可以发现,管道和非管道中水力计算部分耗时较长,一定程度上影响了模拟仿真计算的效率。因此,在工作中把管道和非管道中的计算部分在DCU 中进行并行计算,因为DCU 加速器对数据量较大、运算复杂的密集性计算有显著优势,所以对于供水管网模拟计算时把计算耗时较长的部分传输到DCU 中,计算效率有了显著的提升。供水管网仿真系统在异构架构中的模拟实现流程如图6 所示。
结合图6 分析在程序中需要读取管道和非管道元件中的数据,并写入不同的结构体数组,然后定义结构体指针,动态分配各个管道和非管道结构体指针的内存,将主机端内存的管道元件和非管道元件的结构体数组传输到DCU 加速器设备内存中,并对其进行初始化。管网中管道元件和非管道元件需循环计算,直到达到收敛条件或最大循环次数方可跳出循环结束计算。在外循环中,对管网中各元件循环计算时,管道元件和非管道元件将DCU 加速器映射到block 块中,每个block 中可以根据实际应用分配线程,非管道元件和管道元件计算时按顺序计算。首先计算非管道元件并同步,当所有非管道元件计算完毕之后开始管道的计算,同理,管道计算后也需要同步。以上操作以5 000 次为基准,开启内循环,每循环计算5 000 次,所有元件进行一次更新,并对其中的二通、三通、四通进行收敛条件判断,若达到收敛条件,则跳出循环;否则再次重复上述步骤对非管道和管道进行并行操作,直到外循环结束,跳出循环,将最终的计算结果从设备端传回到主机端,重新关联非管道元件和管道,直至模拟计算结束。

图6 异构版本供水管网仿真系统模拟流程Fig.6 Simulation procedure of water supply pipeline network simulation system of heterogeneous versions
对于小规模的管道网络,可以实现在单DCU 中计算,当管道网络规模逐渐扩大时,单DCU 中计算规模不能满足仿真计算的需求,因此将单DCU 扩展到多DCU 中进行模拟计算。
3 DCU 多卡的实现
供水管网模拟仿真系统在多DCU 中的实现,合理的管道划分方式和数据通信传输尤其重要。
3.1 管道数据划分
管网数据必须根据DCU 节点处理管道数据,并将这些数据逐个写入DCU,而不是计算整个过程中的所有管道数据。在程序优化过程中直接将管道数据分成两个部分,并将这两个部分的数据分别写入到两块DCU 内存中进行计算,但在计算过程中程序运行到一半发生了中断,测试调试发现在对管道数据循环读取时,读到一部分管道数据后循环中断,发生数据缺失的情况。经过分析,管道之间数据交互密切,各个DCU 中一部分管道和非管道元件之间存在数据依赖问题。在对管道数据进行读取时,无法实现跨进程读取操作,DCU 之间也无法进行跨设备的数据访问。为解决该问题,需要使用消息传递接口(MPI)使相关进程之间进行通信,实现数据跨进程通信交互。
使用MPI 控制两进程计算并进行通信时,将管道元件分成两部分,同时需要找到一部分管道元件作为两进程中的公有部分,传回到主机端通信传递。在此项目组的成员提出一种一维分割方法,该方法将整个管道和非管道数据分成两个部分,管道数据按组号被分割为三部分:GroupId=0,GroupId=1 和GroupId=2。把分组GroupId=1 的管道数据写入到DCU0 中,然后将分组GroupId=2 的管道数据写入到DCU1 中,管道分割图如图7 所示。从图7 可以看出,管道数据被相对均匀地分配到了两块DCU 加速器中,在两块DCU 中有一部分管道数据GroupId=0属于两块DCU 中的公有部分。这一部分数据需要同时写入到两块DCU 中,GroupId=0 的管道数据作为连接两部分管道数据的桥梁,在管道元件和非管道元件计算5 000 次后,将GroupId=0 的管道数据从DCU0 中传回到主机端进行通信,然后再传回到DCU1中,最后对管道元件刷新,代表一次通信完成。

图7 管道分割图Fig.7 Pipeline segmentation diagram
3.2 MPI 优化
本节主要描写MPI 的具体实现以及在实现过程中遇到的问题。
3.2.1 数据类型重定义
数据类型在数据结构中的定义是一组性质相同的值的集合以及定义在这个值集合上的一组操作的总称。变量用来存储值,它们有名字和数据类型。结合供水管网仿真模拟的代码,管道和非管道元件被封装成结构体,MPI 需要知道结构体的数据类型才能实现通信传输。因此,需要对结构体实现数据类型重定义。
本文对程序中管道接口和管道的结构体进行重定义。首先程序中使用MPI_Datatype 定义新的数据类型名称,通过blocklens 数组定义管道接口和管道中每个数据类型的长度,并根据oldTypes 数组描述管道接口和管道旧数据的类型,通过MPI_Address指定数组中每个块中的偏移量。然后运用MPI_Type_struct 生成新的管道接口和管道数据类型。最后采用MPI_Type_commit 提交注册新的数据类型&PipeStruct 和&PipePortStruct。
3.2.2 MPI 实现过程
在MPI 信息传递接口进行通信前,应先对分割好的管道元件和非管道元件实现读取和写入操作。利用一维分割方法对各个元件进行分割后,通过MPI_Comm_rank()获取进程号,进程号控制各个进程对非管道元件和管道的读取,将各自的数据分别读取到各进程的结构体数组中。本文主要使用数组指针进行读写操作,数组指针是动态分配空间,使用更加灵活,相比直接使用数组,其代码扩展性更好。在读写完成之后,再由hipMemcpy()将其分别传入到各自的DCU 进行计算。由于MPI 的通信是在主机端进行的,需要使用hipMemcpy()来控制设备端与主机端之间数据的传输。图8 所示为MPI 通信时数据传输的过程。

图8 MPI 通信过程Fig.8 MPI communication process
MPI 在实现过程中,主机端使用MPI_Comm_rank()获取当前的进程号,调用hipGetDevice()获取DCU 加速器的设备编号,以此确定进程编号和设备编号的对应关系。每个进程控制一个DCU,在对应的设备上进行数据显存的划分,完成主机端向设备端计算数据的传输,并各自启动内核函数;每个进程设置自己私有的主机端和设备端的数据指针,其中管道元件的数据被分为三部分,GroupId=0 是公有部分,这一部分管道元件数据使用hipMemcpy(DTH)从设备端传输到主机端被单独写入到Host_PublicPipeArray 数组中,MPI 在管道和非管道分别计算5 000 次后,将共有数据通过DCU 私有的设备端数据指针拷贝回私有主机端,在私有主机端进行数据的通信及更新,并进行收敛性检查,在主机端中结束通信后分别拷贝到私有设备端中,之后对所有非管道元件更新一次。在外循环进程中,进程对各自的管道和非管道元件每进行5 000 次密集计算都会使用MPI 通信接口进行传输通信并更新所有元件,直至供水管网模拟计算结果收敛,计算结束通信完成。图9 所示为MPI 通信传递实现过程。

图9 MPI 通信实现过程Fig.9 MPI communication realization process
从单DCU 加速器扩展到多DCU 加速器,由MPI控制多进程计算的实现解决了DCU 自身的伪并行,完成了大规模数据多进程的并发实现。多DCU 的实现扩大了密集计算的规模,突破了单DCU 加速器计算资源的限制,对以后大规模程序的计算需求具有重要意义。
4 实验测试
“嵩山”超级计算机系统的操作系统为Centos-6.7,集群作业管理系统为Gridview,CPU 编译器为gcc/g++-7.3.1,DCU 加速器编译器为hipcc-2.9.6,MPI 版本为hpcx-2.4.1,CPU 处理器为英特尔®酷睿™i9-9980XE。
4.1 功能性测试
本文在“嵩山”超级计算机平台单节点单DCU上进行正确性验证。首先对CPU+DCU 异构实现的供水管网模拟仿真计算进行小规模数据测试,将记录模拟出的数值与管网串行实现的模拟仿真结果进行比较,经对比发现,两者计算结果的数值变化在允许范围内,通过了正确性验证。
4.1.1 异构实现结果对比
将供水管网模拟实现的异构版本与在CPU 处理器英特尔®酷睿™i9-9980XE 上的运行结果进行对比,为使描述清晰简洁,将在单DCU 内优化方法简称为方法1,在多DCU 内优化方法简称为方法2。通过输入小规模器件数量和大规模器件数量,并在不同的计算平台上进行仿真计算测试。如表1 所示,选取器件规模数分别为10 000、30 000。

表1 不同规模器件在CPU 和方法1 下的结果对比Table 1 Comparison of results of different scale devices in CPU and method 1
由表1 数据可以看出,在器件数为10 000 时,在DCU 加速器上的加速比为5.065,随着计算规模的增加,当输入器件数为30 000 时,加速比达到了9.833。分析其原因,是因为在小规模数据计算时,不能充分利用DCU 加速器的并行资源,计算性能有一定幅度的提升,但不能达到最优。当器件数量增多时,DCU加速器在大规模密集计算的计算优势突出,加速效果明显提升。实验结果证明了CPU+DCU 异构实现的供水管网模拟计算在“嵩山”超级计算机平台的单DCU 加速器环境中,加速效果十分显著,在保证相同计算精度的前提下,计算速度提升5~10 倍,且管网模型规模越大,DCU 加速效果则越显著。
表2 所示是GPU 异构平台上的运行结果与方法1进行对比,加速比提升了2~3 倍。可以看出,在“嵩山”超级计算机上的移植相比显卡为GT 730 的GPU异构平台仍有显著的优势。

表2 不同规模器件在GPU 和方法1 下的结果对比Table 2 Comparison of results of different scale devices in GPU and method 1
本节实验验证了供水管网模拟仿真系统在不同平台的测试结果,表明“嵩山”超级计算机更适合于大规模仿真计算,且其相对于以往实施x86 平台或GPU 异构平台,计算性能都有明显提升。
4.1.2 多DCU(方法2)实现测试分析
由于越来越多管道的建立,管网拓扑复杂,计算量大,单DCU 的计算规模已经不能满足庞大的管网数据计算量。本节基于MPI+HIP 模型选择供水管网仿真计算在多DCU 上的实现进行实验,将在单DCU 上管网模拟仿真运行的时间作为基准,测试该模拟程序在单节点内多个DCU 上运行的并行效率,如表3 所示。
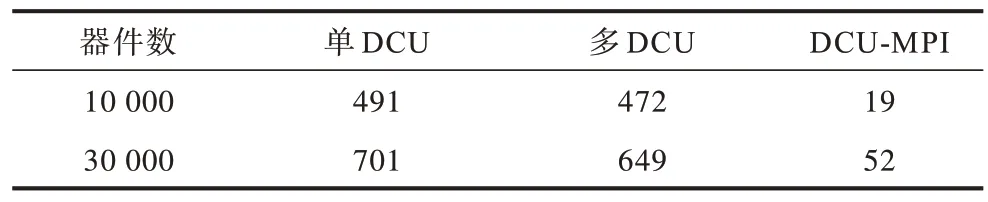
表3 不同规模器件在方法1 和方法2 下的结果对比Table 3 Comparison of results of different scale devices under method 1 and method 2 s
在输入管器件数量分别为10 000、30 000 时,DCU 单卡加速与DCU 多卡加速速度相当,多卡加速效果略优于单卡,但当面对超大规模管网模型时,多卡加速效果将明显优于单卡环境。原因是由于在MPI 进行通信传输时,需要将管网中管道和非管道元件从设备端传输到主机端进行数据通信,然后再传回到设备端。在输入规模少的管道和非管道数据进行计算时,使用hipMemcpy()进行传输所占用的时间较长,核函数内密集计算占比较小,性能提升不明显,但是随着输入管网规模的增大,在核函数内计算占比远超过传输占比时,加速比取得大幅提升。
表4 所示是将在CPU 加速器上的运行结果与DCU 多卡加速结果进行对比,加速比提升了5~10 倍。从表4 可以看出,将数据规模扩展到多块DCU 中测试结果取得较优的性能,随着规模的扩大,加速比与规模的扩大成正比。

表4 不同规模器件在CPU 和方法2 下的结果对比Table 4 Comparison of results of different scale devices under CPU and method 2
实验结果证明了基于HIP 编程模型和MPI 实现的供水管网模拟仿真计算在“嵩山”超级计算机系统的多DCU 上具有良好的可拓展性,对供水管网在“嵩山”超级计算机平台上实现规模扩展具有重要的意义。
5 结束语
本文利用HIP-C 语言实现供水管网模拟仿真计算在“嵩山”超级计算机平台的移植,通过对管道和非管道元件的数据进行划分,并基于CPU+DCU 异构架构,利用HIP 编程模型和消息传递接口控制DCU 的并发和多进程之间数据的通信传递,扩展管网仿真计算的规模,同时提升模拟实现的效率。实验结果验证了本文优化方法的有效性。下一步将进行管网内核函数计算部分的优化工作,研究扩展核函数内管道和非管道元件的并行特性,以达到提升管网仿真计算性能的目标。
