命名实体识别方法研究综述
2022-09-15李冬梅罗斯斯张小平
李冬梅,罗斯斯,张小平,许 福
1.北京林业大学 信息学院,北京 100083
2.国家林业和草原局林业智能信息处理工程技术研究中心,北京 100083
3.中国中医科学院 中医药信息研究所,北京 100700
命名实体识别(named entity recognition,NER)是指识别出文本中具有特定意义的命名实体并将其分类为预先定义的实体类型,如人名、地名、机构名、时间、货币等。在大数据时代,如何精准并高效地从海量无结构或半结构数据中获取到关键信息,这是自然语言处理(natural language processing,NLP)任务的重要基础。命名实体通常包含丰富的语义,与数据中的关键信息有着密切的联系,NER 任务可以用于解决互联网文本数据的爆炸式信息过载问题,能有效获取到关键信息,并广泛应用于关系抽取、机器翻译以及知识图谱构建等领域。
NER 历经了MUC(message understanding conference)、MET(multilingual entity task)、CoNLL(conference on computational natural language learning)、ACE(automatic content extraction)等,众多研究者不断深入研究,其理论和方法愈加完善。研究方法从最初需要人工设计规则,到后来借助传统机器学习中的模型方法,目前已经发展到利用各种深度学习。研究领域从一般领域到特定领域,研究语言从单一语言发展到多种语言,各种NER模型的性能随着发展也在不断提升。
本文调研了NER 发展史上有代表性的综述论文,孙镇等综述了NER 的方法,包括对基于规则和词典的方法以及基于统计的方法的介绍。Li 等详细总结和分析了NER 的深度学习方法。李猛等从迁移学习的角度,总结了NER 的迁移方法。赵山等调研了在不同神经网络架构下最具代表性的晶格结构的中文NER 模型。以上综述都是对NER 的传统方法或者深度学习的部分方法的阐述,没有详细地包含基于规则和词典的NER 方法、基于统计机器学习的NER 方法和基于深度学习的NER 方法这三者的介绍,且并未针对最新的基于提示学习的方法进行总结。本文首先从基于规则和词典、基于统计机器学习和基于深度学习的NER 方法这三方面对目前NER 研究工作进行系统性梳理,归纳总结了每一种NER 方法的关键思路、优缺点和具有代表性的模型。同时对基于提示学习的NER 方法进行了比较分析。其次,扩充了中文NER 的介绍,给出了中文NER 的特殊性,总结归纳中文NER 特有的数据集,对各个阶段的主流方法均单独进行了综述。
1 NER 概述
1.1 NER 定义
最初在1991 年第7 届IEEE 人工智能应用会议上,Rau发表了一篇“从文本中抽取公司名称”的论文,提出了一种从文本中提取公司名的方法,在文中需要识别的命名实体仅为公司名称。在1996 年MUC-6 会议上,命名实体被定义为“实体的唯一标识符”,需要识别的命名实体包含:人名、地名、机构名、时间、日期、货币和百分比。
NER 是对文本中的命名实体进行定位和分类的过程。对给定文本的标注序列=<,,…, w>,经过NER 过程后得到三元组列表,如<,,>,每一个三元组都包含一个实体的信息。在三元组<,,>中,∈[1,],∈[1,],分别指代实体的开始索引和结束索引,是预定义类别集合中的实体类型。图1 给出了一个标注序列的样例,在经过NER 系统后得到了3 个三元组,根据三元组判断得到:Zhang San 是Person 类实体,Beijing 和China 是Location 类实体。
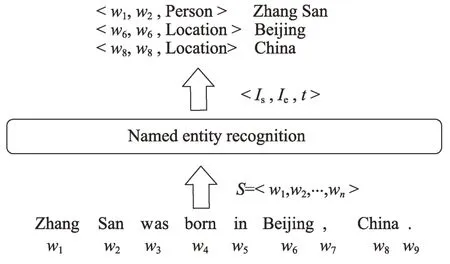
图1 NER 任务的实例Fig.1 Example of NER task
1.2 NER 的研究难点
目前,针对NER 的研究仍存在一些通用难点。
(1)未登录词。随着时间的推移和各领域发展,会产生大量新实体,这些新产生的实体并没有一个统一的命名规则,传统的方法不再适用,此时要求NER 模型具有较强的上下文推理能力。
(2)嵌套实体。嵌套实体是指该实体中存在其他命名实体。这类实体不仅需要识别外层实体,还要识别内层实体,对模型来说具有很大的挑战,这也是目前NER 的一个研究热点。
(3)文本歧义。文本在某处为命名实体,而在另一处为普通名词,或者为不同的实体类型,即文本类型是不明确的。因此,需要在NER 之前进行额外的命名实体消歧任务。
(4)非正式文本。随着社交软件的流行,如微博等社交媒体中含有大量的语料,但这些语料有着简短、口语化、包含谐音等特点,这使得NER 任务更加难于处理,可以使用注意力机制和迁移学习结合深度学习完成对非正式文本的识别。
1.3 中文NER 的特殊性
面向中文的NER 起步较晚,而且中文与英文等其他语言相差较大,由于其自身的语言特性,中文领域的NER 主要存在以下3 个特殊性。
(1)中文词语的边界不明确。中文的单元词汇边界模糊,缺少英文文本中空格这样明确的分隔符,也没有明显的词形变换特征,因此容易造成许多边界歧义,从而加大了NER 的难度。
(2)中文NER 需要同中文分词和语法分析相结合。只有准确的中文分词和语法分析才能正确划分出命名实体,才能提升NER 的性能,这也额外增加了中文NER 的难度。
(3)中文存在多义性、句式复杂表达灵活、多省略等特点。在不同领域的同一词语所表示的含义并不相同,且同一语义也可能存在多种表达。此外,互联网的迅速发展,尤其是网络文本中的文字描述更加个性化和随意化,这都使得实体的识别更加困难。
1.4 NER 常用数据集
常用于NER 的英文数据集有:MUC-6、MUC-7、CoNLL2002-2003、ACE2004-2005、GENIA、Onto-Notes5.0、BC5CDR、NCBI Disease、Few-NERD 等。中文数据集有:1998年人民日报数据集、MSRA、Onto-Notes5.0、BosonNLP NER、Weibo NER、Chinese Resume、CCKS2017-2020、CLUENER2020 等。以上数据集总结如表1 所示。
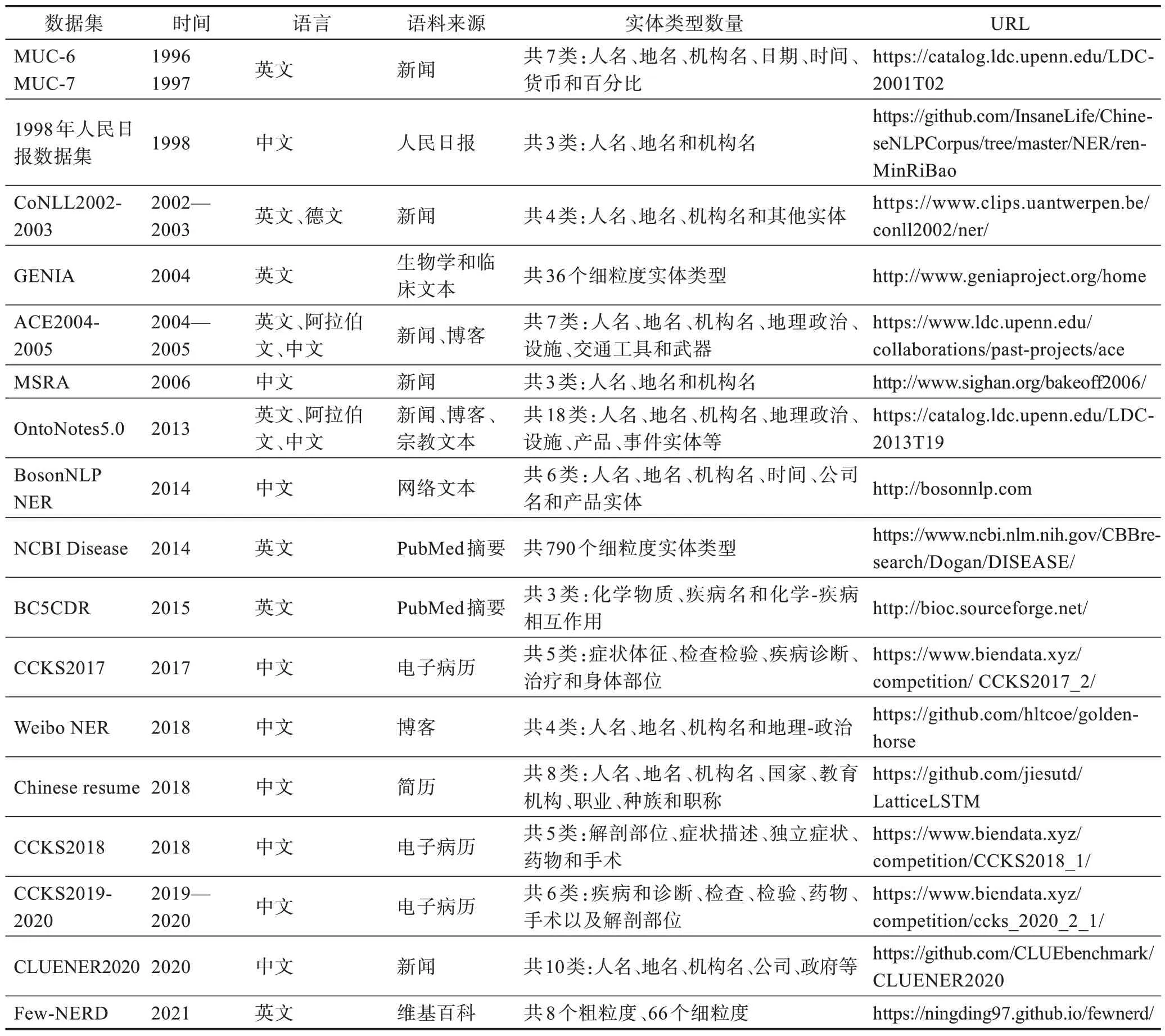
表1 NER 数据集总结Table 1 Summary of NER datasets
1.5 评估标准
在NER 领域,通常使用准确率(precision)、召回率(recall)和F1 值作为评估指标。其中,准确率是对于给定的测试数据集,分类器正确识别的实体样本数与提取出来的全部实体样本数之比;召回率则是对于给定的测试数据集,分类器正确识别测试集中的全部实体的百分比;而F1 值则是准确率和召回率的调和平均值,可以对系统的性能进行综合性评价。准确率、召回率和F1 值的计算公式如下:

其中,表示将正例预测为正;表示将负例预测为正;表示将正例预测为负。
2 NER 的方法
根据NER 的发展历程,主流的NER 方法可以分为3 类:基于规则和词典的方法、基于统计机器学习的方法和基于深度学习的方法。这3 类方法根据处理特点又细分为若干种不同的子方法。图2 给出了NER 方法的详细分类,后面的内容围绕该分类方法分别进行详细阐述。

图2 NER 方法的分类Fig.2 Classification of NER methods
2.1 基于规则和词典的NER 方法
早期的NER 方法主要运用由语言学专家根据语言知识特性手工构造的规则模板,通过匹配的方式实现命名实体的识别。针对不同的数据集通常需要构造特定的规则,一般根据特定统计信息、标点符号、关键字、指示词和方向词、位置词、中心词等特征来构造。Krupka提出了一个用于英文NER 的SRA系统,系统包括NameTag 和HASTEN 两个子系统,HASTEN 根据文本的语义信息来构造生成人名和地名规则模板,进一步来识别。Shaalan 等利用文本的上下文特征构造规则,并同时增加地名词典来识别专业名词。
对于中文NER,最初的研究聚焦于专业名词的研究,张小衡等根据机构名称的结构规律和形态标记等特点进一步总结规则,从600 多万的三地语料库
中识别高校名称实体,正确率达到了97.3%。王宁等从专业名词识别的角度,充分考虑金融领域的特征,利用规则的方法专门针对公司名的识别问题进行了研究。该方法分析研究了金融新闻文本,总结了公司名的结构特征以及上下文信息,归纳形成知识库,并采取两次扫描的策略进行识别。在共1 336 篇真实金融新闻的数据集上进行实验,其中在封闭测试环境中的准确率和召回率分别为97.13%和89.13%,在开放测试环境中分别为62.18%和62.11%。
表2 对上述提及到的方法进行了总结。基于规则和词典的方法可以利用相关语言特性或特定领域知识来制定规则,在特定的语料库中该类方法具有较好的识别效果,但是该方法存在规则制定成本高、规则无法移植到其他语料等局限性。因此在其他大型语料中单纯依靠这种方法较难获得有效的识别结果。

表2 基于规则和词典的主流NER 方法总结Table 2 Summary of mainstream NER methods based on rules and dictionaries
2.2 基于统计机器学习的NER 方法
随着机器学习在NLP 领域的兴起,研究者们借助机器学习的方法研究NER。这种方法可以在一定程度上克服基于规则和词典的NER 方法的局限性,该类方法可以归纳为三种:有监督学习、半监督学习和无监督学习。
有监督学习的NER 方法是将NER 任务转换成分类问题,通过机器学习方法将已标记的语料构造为特征向量,以此建立分类模型来识别实体。基于特征的有监督学习的NER 方法一般流程包括:(1)获取实验原始数据。(2)对原始数据预处理。(3)根据数据的文本信息,选择合适的特征。(4)给不同的特征设置不同的权重并选择合适的分类器训练特征向量,得到NER 模型。(5)利用NER 模型进行实体识别。(6)对结果进行评估。
采用有监督机器学习的分类模型包括:HMM(hidden Markov models)、MEM(maximum entropy models)、SVM(support vector machines)和CRF(conditional random fields)等模型。
(1)HMM
基于HMM 的NER 方法利用维特比算法将可能的目标序列分配给每个单词序列,能够捕捉现象的局部性,进而提高了实体识别性能。Bikel 等基于大小写、数字符号、句子首词等特征,利用HMM 来计算某一单词为某一实体类型的概率。但该模型仍然无法捕捉到远距离信息,还存在一些无法识别的实体。Zhou 等提出一种基于HMM 的组块标记器的NER 方法,在Bikel 的基础上扩充了内部语义特征、内部地名词典特征以及外部上下文特征,对HMM 的传统公式做了改进,以便能融合更多的上下文信息来确定当前预测类型。
对于中文NER,张华平等借助HMM 提出了基于角色标注的中国人名自动识别方法。该方法采取HMM 对分词结果进行角色标注,通过对最佳角色序列的最大匹配来识别和分类命名实体,该方法解决了不具备明显特征的姓名的丢失、内部成词以及上下文成词的人名难召回的问题。俞鸿魁等提出一种基于层叠HMM 的中文NER 模型,该模型由三级HMM 构成。在分词后低层的HMM 识别普通无嵌套的人名、地名和机构名等,高层的HMM 识别嵌套的人名、地名和机构名。
(2)MEM
基于MEM 的NER 方法的主要思想是在已知部分知识的前提下选择熵最大的概率分布,从而来确定某一实体的类型,MEM 能够较好地融合多种特征信息进行分类。Borthwick 等最早将MEM 用于英文NER 任务,综合考虑了首字母大小写、句子的结尾信息以及文本是否为标题等多种特征信息。Bender等在Borthwick 的基础上进行改进,模型结构依次为输入序列、预处理、全局搜索、后处理和序列标注。
对于中文NER,周雅倩等最早将MEM 应用在中文名词短语的识别上,将短语识别问题转化为标注问题。利用预定义的特征模板从语料中抽取候选特征,然后根据候选特征集识别名词短语。但该模型未能将更多的语义、词语共现等信息融合在模型中。因此,张玥杰等提出一种融合多特征的MEM中文NER 模型,该模型能集成局部与全局多种特征,将规则和机器学习的方法相结合,分别构建了局部特征模板和全局特征模板,同时引入启发式知识解决效率和空间问题。
(3)SVM
SVM 是定义为特征空间上的间隔最大的线性分类器。首先通过高维特征空间的转化使分类问题转换成线性可分问题,然后基于结构风险最小理论构建最优分割超平面,使得分类器得到全局最优化。该模型在NER 任务上被广泛使用,Isozaki 等提出了一种基于SVM 的特征选择方法以及有效的训练方法,能增加系统训练的速度。为了验证SVM 在不同领域的表现效果,Takeuchi等在MUC-6 评测语料与分子生物学领域语料使用SVM 进行实体识别,发现SVM 在生物领域的NER 具有良好的表现。
对于中文NER,李丽双等提出一种基于SVM的中文地名的自动识别的方法,结合地名的特点信息作为向量的特征。此外,面对训练数据不足的难点,陈霄等针对中文组织机构名的识别任务,提出了一种基于SVM 的分布递增式学习的方法,利用主动学习的策略对训练样本进行选择,逐步增加分类器训练样本的规模,进一步提高分类器的识别精度。
(4)CRF
CRF 模型统计了全局概率,不仅在局部进行归一化,且考虑了数据在全局的分布情况。CRF 具有表达长距离依赖性和交叠性的优势,能有效融入上下文信息以及领域知识,可以解决标注偏置问题。即使CRF 具有时间复杂度高导致的训练难度大等问题,但仍十分广泛地被用于NER。McCallum 等提出了一种基于CRF 的特征归纳的NER 方法,与传统方法相比,自动归纳特征既提高了准确性,又显著减少了特征数量。Krishnan 等提出了一种利用非局部依赖且基于两个耦合的CRF 分类器的方法。第一层CRF 利用局部信息提取特征,第二层CRF 将局部信息和从第一层CRF 的输出中提取的特征结合,在整个文档中使用特征去捕捉非局部的依赖信息。
对于中文NER,冯元勇等在CRF 框架中引入了小规模的常用尾字特征来降低特征集的规模,在提高模型训练速度同时保证识别准确率。燕杨等针对中文电子病历的NER 问题,提出一种层叠CRF,该模型在第二层中使用包含实体和词性等特征的特征集,对疾病名称和临床症状两类命名实体进行识别。与无自定义组合特征的层叠CRF 相比,该模型的F1 值提高了约3 个百分点,和单层CRF 相比,F1 值提高了约7 个百分点。
综上所述,以上几种有监督机器学习NER 方法各有所长,也各有所短。研究者充分利用各种算法的优势,进一步提升实体识别的性能。上述几种方法的相关比较如表3 所示。

表3 基于有监督机器学习NER 比较Table 3 Comparison of NER methods for supervised machine learning
有监督学习的方法需要专家手工标注大量训练数据,为了解决这一问题,学者开始研究利用少量的标注语料进行NER 任务,因此,半监督的NER 方法应运而生。该方法通过使用少量标记和大量无标记的语料库进行NER 的研究。半监督学习NER 的一般流程:(1)人工构造初始种子集合。(2)根据命名实体上下文信息生成相关联的模式。(3)将生成的模式和测试数据匹配,标识出新的命名实体,生成新的模式,便于促进循环。(4)将新识别的命名实体添加到实体集合中。流程图如图3 所示。
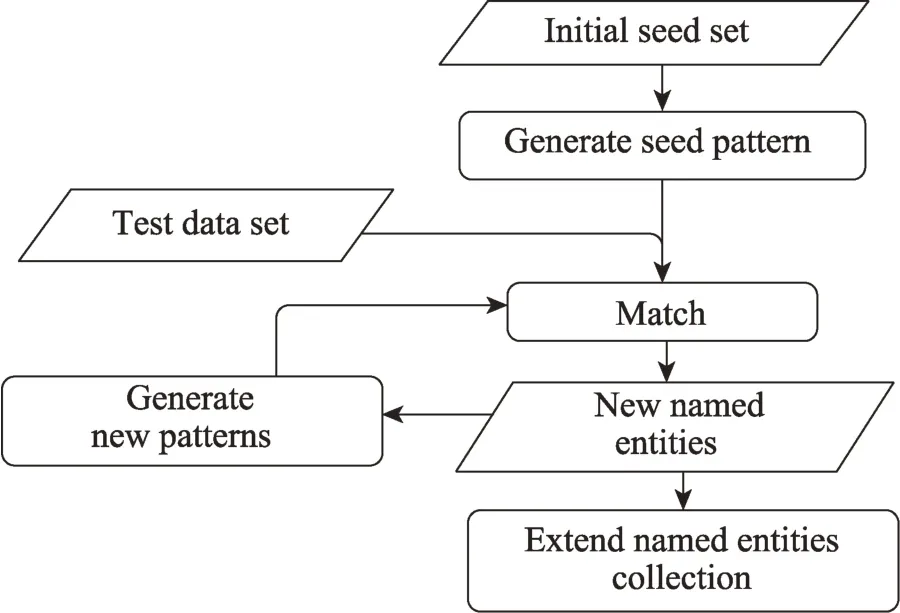
图3 半监督学习的NER 一般流程Fig.3 General process of NER based on semi-supervised learning
半监督学习的NER 方法主要采用自举的方法,该方法利用少量的标注数据进行训练,从而取得良好的实验结果。如Teixeira等提出一种基于CRF 的自举训练方法,首先基于词典对50 000 条新闻标注人名,并使用标注好人名的数据作为训练集建立基于CRF 的分类模型。然后使用CRF 分类模型对初始种子语料库额外标注,并将其用于训练新的分类模型。该模型经过7 次自举方法的迭代后,在HAREM数据集上进行实验表现良好。此外,Thenmalar 等不仅在英文语料中使用半监督的自举方法,还增加了泰米尔文语料进一步验证该方法的可行性。该方法利用少量训练数据中命名实体、单词和上下文特征来定义模式,分别对英文和泰米尔文进行NER,两种语言的平均F1 值为75%。
对于中文NER,针对结构复杂的产品名的识别任务,黄诗琳等提出一种半监督学习方法,提取不同产品实体的结构特征和相互关系,构建一种三层半监督学习框架。首层结合规则和词典选取数据集中的候选数据;第二层利用相似度算法,把与种子集上下文相似的候选词加入正例中,这一步骤能解决数据稀疏问题;第三层是一个CRF 的分类器用于识别相似度较低的实体。但因产品名的表达方式多样化,该方法与一般的NER 方法相比,性能还存在一定的差距。在医学NER 任务上,Long 等提出一个基于自举的NER 方法,在自举训练过程中将命名实体特征集表示为类特征向量,候选命名实体的上下文信息表示为示例特征向量,这两种特征向量的相似程度决定了候选实体是否为命名实体。此外,针对少数民族语言的NER 任务,王路路等以CRF 为基本框架,通过引入词法特征、词典特征以及基于词向量的无监督学习特征,对比不同特征对识别结果的影响,进而得到最优模型。
为了解决跨域和跨语言标注文本的不足,学者们提出了NER 的无监督学习技术。无监督学习是不需要使用标注数据的算法,该方法使用未标注的数据来做出决策。无监督学习旨在考虑数据的结构和分布特征,从而发现更多关于数据的学习。
早期,Etzioni 等提出了一个名为KnowwitAll的无监督NER 系统,该系统以无监督和可扩展的方式自动地从网页中提取大量命名实体。Nadeau 等在Etzioni 等的基础上进一步研究,该系统可以自动构建地名词典以及消解命名实体歧义,将构建的地名词典与常用的地名词典相结合。Han 等提出一个基于聚类主动学习的生物医学NER 系统,该聚类方法通过使用底层分类器在文档中查找候选命名实体来进行聚类,因而更能反映命名实体的分布。
综上所述,无监督学习的NER 方法既能解决有监督学习中需要大量带标注的训练数据的问题,也不需要少量标注的种子数据,但是这种方法需要提前确定聚类阈值并且性能较低,仍需进一步改善聚类方法。
对基于有监督、半监督、无监督的三种方法进行了比较,如表4 所示,并对基于统计机器学习的各种主流NER 模型进行了总结,如表5 所示。

表4 基于有监督、半监督、无监督的NER 比较Table 4 Comparison of NER methods for supervised,semi-supervised and unsupervised
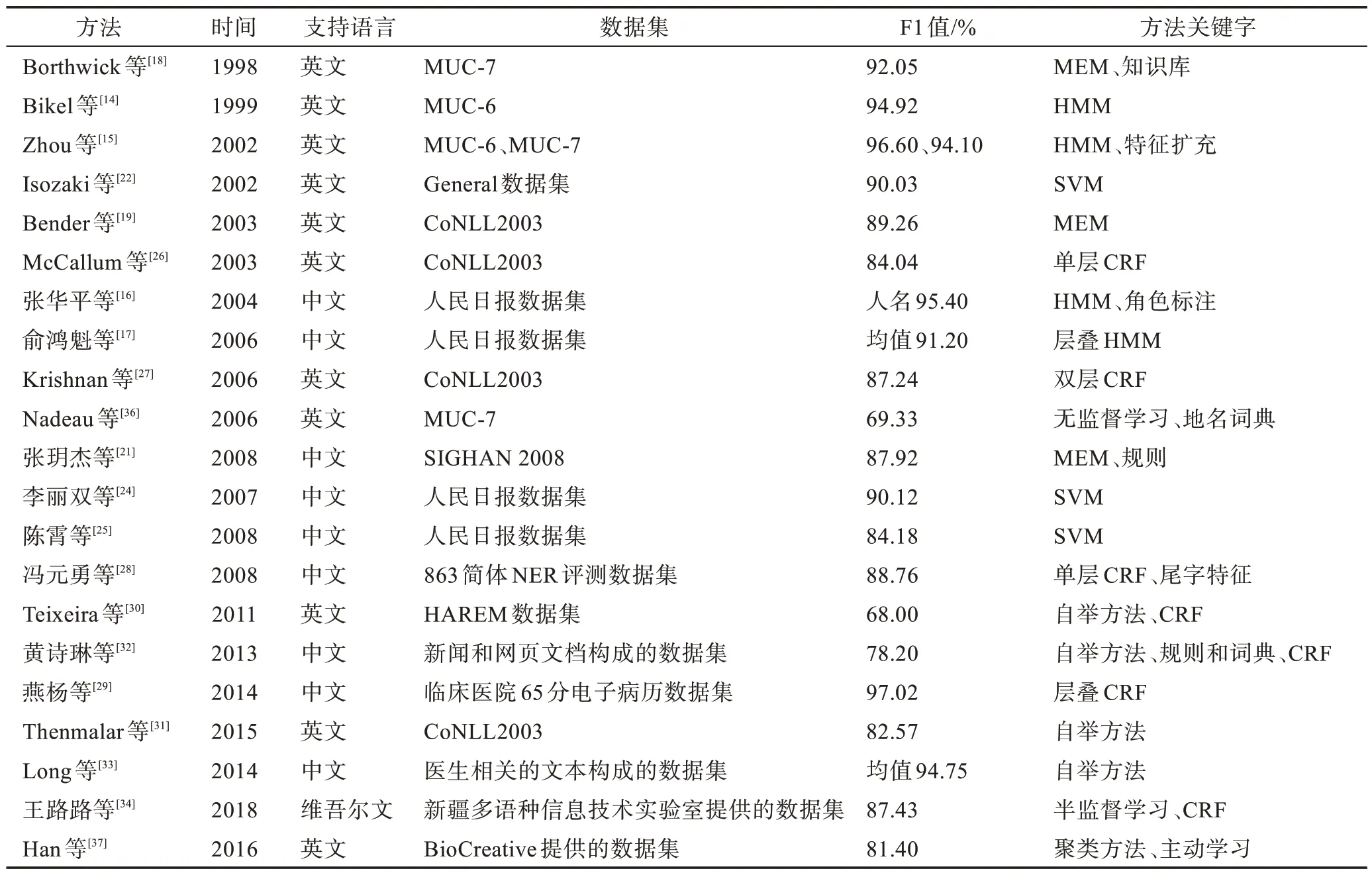
表5 基于统计机器学习的主流NER 模型总结Table 5 Summary of mainstream NER models for statistical machine learning
2.3 基于深度学习的NER 方法
基于深度学习的方法对处理NER 等序列标注任务的处理流程是类似的。首先,将序列通过Word2Vec 等编码方式转换成分布式表示,随后将句子的特征表示输入到编码器中,利用神经网络自动提取特征,最后使用CRF 等解码器来预测序列中词对应的标签。早期,研究者大多对基于有监督和远程监督两种深度学习的NER 方法进行深入研究。预训练模型BERT(bidirectional encoder representation from transformers)自2018 年提出以来,也备受研究者关注。最近,基于提示学习的方法也在NER 任务上得到了初步尝试,并取得了成功。
基于深度学习的NER 方法一般流程如图4 所示,共分为4 步:(1)Sequence,预处理后的输入序列。(2)Word embedding,将输入序列转换成固定长度的向量表示。(3)Context encoder,将词嵌入进行语义编码。(4)Tag decoder,进一步进行标签解码。
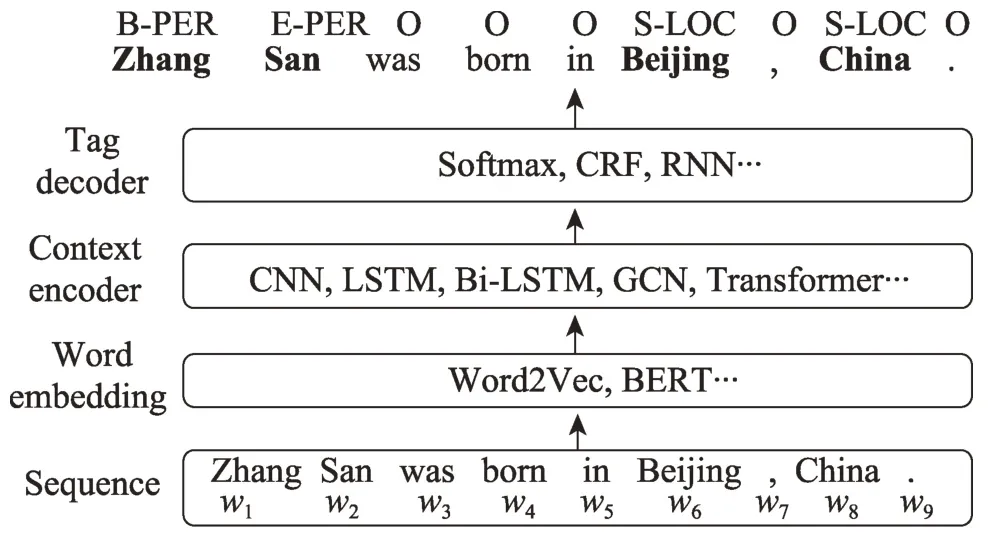
图4 基于深度学习的NER 一般流程Fig.4 General process of NER based on deep learning
基于有监督深度学习的方法目前主要分为CNN(convolutional neural network)、RNN(recurrent neural network)和GNN(graph neural network)等。
(1)CNN
早期,CNN 在计算机视觉领域取得突破性成果,后来也逐渐在NLP 领域被广泛使用。2011 年,Collobert 等提出了一种基于CNN 的NLP 模型,能处理包含NER 等多种任务。该模型不需要利用人工输入特征,而是基于大量未标记的训练数据来学习内部表示,在输入时减少特征的预处理,使用以端到端方式训练的多层神经网络体系结构。在Collobert 等的基础上,Yao 等将CNN 应用到生物医学NER 上,模型具有多层结构,每层根据底层生成的特征提取特征。该模型具有良好准确率,但并未充分利用CPU并行性,其计算效率不高,因此,Strubell 等提出了一种迭代扩张卷积神经网络(ID-CNNs),与传统的CNN 相比,该模型具有更好的上下文和结构化预测能力并能大幅缩短训练时间。
对于中文NER,2015 年Wu 等利用卷积层生成由多个全局隐藏节点表示的全局特征,然后利用局部特征和全局特征以识别临床文本中的命名实体。Wu 等提出了一种CNN-LSTM-CRF,以获取短距离和长距离内容依赖,同时提出将NER 和分词任务联合学习以挖掘这两个任务之间的内在联系,增强中文NER 模型识别实体边界的能力,但该模型无法捕捉全局的上下文信息。因此,Kong 等提出一种融合多层次CNN 和注意力机制的中文临床NER 方法。该方法既能捕捉短距离和长距离的上下文信息,且注意力机制还能获取全局上下文信息,进一步解决了LSTM 在句子较长时无法捕捉全局信息的问题。但该方法目前对稀有命名实体仍然存在难以识别的问题,因此,Gui 等将词典信息融合到CNN 结构中,解决稀有实体识别的问题。
综上所述,CNN 最大的特点是可以并行化,每个时间状态不受上一时间状态的影响,但其无法很好地提取序列信息。随着RNN 的深入研究,CNN 和RNN 常常混合使用。
(2)RNN
RNN 是基于深度学习的NER 方法中的主流模型,RNN 将语言视为序列数据,能很好地处理序列数据,解决了CNN 无法记忆上下文信息的问题。Huang 等在Collobert 等基础上,提出了多种基于LSTM 的序列标注模型,包括LSTM、Bi-LSTM 和Bi-LSTM-CRF 等。首次将Bi-LSTM-CRF 模型用于NER,该模型不仅可以同时利用上下文的信息,而且可以使用句子作为输入。Gregoric 等在同一输入端采用多个独立的Bi-LSTM 单元,通过使用模型间正则化来促进LSTM 单元之间的多样性,能够减少模型的参数。Li 等提出一个模块化交互网络模型用于NER,能同时利用段级信息和词级依赖。Xu 等提出一种有监督多头自注意网络的NER 模型,利用自我注意力机制获取句子中词与词之间的关系,并引入一个多任务学习框架来捕捉实体边界检测和实体分类之间的依赖关系。
对于中文NER,Zhang 等首次提出了基于混合字符和词典的Lattice-LSTM 模型,通过门控单元,将词汇信息嵌入到每个字符中,从而利用上下文中有用的词汇提升NER 效果。但是由于词汇的长度和数量无法确定,Lattice-LSTM 存在无法批量训练而导致模型训练较慢的问题。为了解决该问题,Liu 等提出了基于单词的LSTM(WC-LSTM)。该方法在输入的向量中融入最优词汇的信息,在正向LSTM 中融入基于该字开头的词汇信息,在反向LSTM 中融入基于该字结尾的词汇信息。Ma 等也在Lattice-LSTM 模型基础上做了改进,不修改LSTM 的内部结构,只在输入层进行词与所有匹配到的词汇信息的融合,该方法还可以应用到不同的序列模型框架中,如CNN和Transformer。
(3)GNN
近年来,GCN(graph convolutional network)和GGNN(gated graph neural network)在NER 任务中得到广泛的关注。Cetoli 等率先在NER 任务中使用图GCN 来解决实体识别问题,在传统的Bi-LSTMCRF 模型的Bi-LSTM 层和CRF 层中间额外添加一层GCN 层。Bi-GCN 层利用句子的句法依存关系构图,通过GCN 将节点信息传递给最近的节点,通过将层图堆叠在一起,该网络结构可以传播最多相距跳的节点特征。
在中文领域,为了解决在NER 过程中使用词典的最长匹配和最短匹配带来的问题,Ding 等提出了一种基于GNN 并结合地名词典的NER 方法,其目的使模型自动学习词典的特征。该模型首先根据地名词典构图,然后依次通过GGNN 层、LSTM 层和CRF层进行实体的识别。Gui等通过引入一个具有全局语义的基于词典的GNN 模型来获取全局信息。此外,Tang 等进一步研究了如何将词汇信息整合到基于字符的方法中,提出一种基于单词-字符图卷积网络(WC-GCN),通过使用交叉GCN 块同时处理两个有向无环图,并引入全局GCN 块来学习全局上下文的节点表示。
基于远程监督深度学习的方法主要利用外部词典或知识库对无标注数据进行标注,可以解决有监督学习需要大量已标注数据这一问题,其常采用的方式包括词典匹配和词典匹配与神经网络相融合两种。Peng 等仅借助未标记数据和命名实体词典,提出了一种新的PU(positive-unlabeled)远程监督NER模型,该模型不需要利用词典标记句子中的每个实体,能大幅度降低对词典质量的要求。此外,Yang等提出了一个基于部分标注学习和强化学习的远程监督的NER 模型,不仅可以通过远程监督自动获取到大规模的训练数据,而且通过使用部分标注学习和强化标注学习,解决了远程监督方法产生的不完全标注和噪音标注的问题。
对于中文NER,Zhang 等利用远程监督的方法识别时间,提出了一种利用中文知识图谱和百度百科生成的数据集进行模型训练的方法,该方法不需要像手动标注数据,且对不同类型的文本的适应性良好。此外,边俐菁基于深度学习和远程监督的方法针对产品进行实体识别,利用爬虫整理得到的词典高质量地标注数据,按照词典完全匹配、完全匹配+规则、核心词汇+词性扩展+规则这三种方式进行实体识别,该方法能大大减少手工标注语料库的工作量。
远程监督的方法相对于有监督的方法极大地减少了人工成本,但远程监督的方法会产生不完全标注和噪音标注,导致自动标注获得的数据集准确率较低,会影响整个NER 模型的性能。
基于Transformer 方法典型代表是BERT 类的预训练模型。Souza 等在NER 任务上提出一种BERT-CRF 模型,将BERT 的传输能力与CRF 的结构化预测相结合。Naseem 等提出一种针对生物医学NER 的预训练语言模型BioALBERT,该模型在ALBERT 中使用自我监督损失,能较好学习上下文相关的信息。Yang 等提出了一种分层的Transformer模型,应用于嵌套的NER。实体表征学习结合了以自下而上和自上而下的方式聚集的相邻序列的上下文信息。
对于中文NER,李妮等提出了基于BERTIDCNN-CRF 的中文NER 模型,该模型通过BERT 预训练模型得到字的上下文表示,再将字向量序列输入IDCNN-CRF 模型中进行训练。Li等为解决大规模标记的临床数据匮乏问题,在未标记的中国临床电子病历文本上利用BERT 模型进行预训练,从而利用未标记的领域特定知识,同时将词典特征整合到模型中,利用汉字字根特征进一步提高模型的性能。Wu 等在Li 等的基础上,提出了一个基于RoBERTa 和字根特征的模型,使用RoBERTa 学习医学特征,同时利用Bi-LSTM 提取偏旁部首特征和RoBERTa 学习到医学特征向量做拼接,解码层使用CRF 进行标签解码。Yao 等针对制造文本进行细粒度实体识别,提出一种基于ALBERT-AttBiLSTMCRF 和迁移学习的模型,使用更轻量级的预训练模型ALBERT 对原始数据进行词嵌入,Bi-LSTM 提取词嵌入的特征并获取上下文的信息,解码层使用CRF 进行标签解码。
随着NLP 技术的发展,近两年有研究者在低资源任务中使用提示学习的方法来获得良好的任务效果。提示学习通常不需要改变预训练语言模型的结构和参数,而是通过向输入中添加一些提示信息,并修改下游任务来适应预训练模型,进而获得更好的任务效果的一种方法。Brown 等首次在文本分类任务中使用提示学习的方法进行了小样本学习任务。在低资源的NER 任务中,没有大规模的训练语料,大量依赖训练数据的模型都无法取得较好的效果。因此在低资源的NER 任务中使用提示学习是现在的一种新思路。Cui 等提出一种基于模板的NER 方法,再利用标注实体填充的预定义模板提示对预训练模型BART(bidirectional and auto-regressive Transformers)微调,该方法解决了小样本NER 的问题。Chen 等受提示学习的启发,提出一种轻量级的低资源提示引导型注意生成框架,将连续的提示输入到自我注意层中,来重新调节注意力并调整预先训练的权重。基于模板提示的方法需要枚举所有可能的候选实体,存在较高的计算复杂度问题,因此,Ma 等提出一种在小样本场景下无模板的提示微调方法,放弃模板构建的枚举思路,采用预训练任务中的掩码预测任务的方式,将NER 任务转化成将实体位置的词预测为标签词的任务。该方法能减少预训练和微调之间的差距并且解码速度比基线方法快1 930.12 倍。此外,Liu 等提出一种带有问答的提示学习NER 方法,将NER 问题转换成问答任务。该方法在低资源的场景下具有更高的性能和更强的鲁棒性。总的来说,提示学习在低资源场景的NER任务上得到了初步尝试,未来会有更多复杂的方法来增强提示,并应用于低资源场景下的许多任务中。
综上所述,本文针对基于有监督深度学习、基于远程监督深度学习、基于Transformer 和基于提示学习的四种方法进行了比较分析,具体如表6 所示。此外,本文还总结了一些经典的基于深度学习的NER模型,具体如表7 所示。
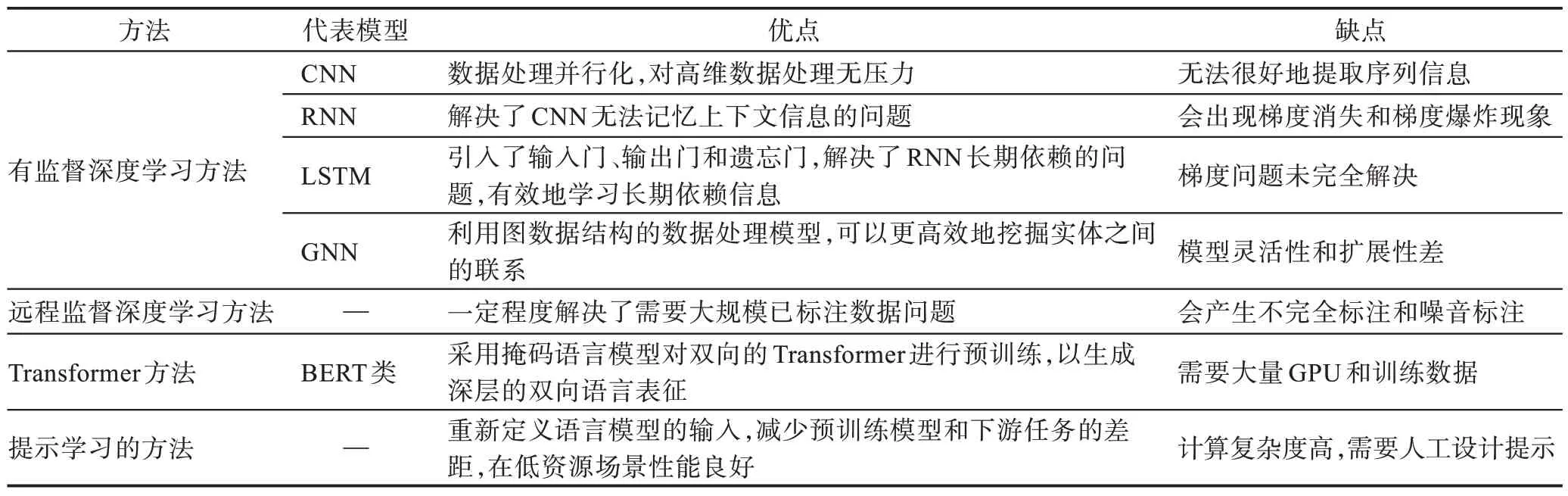
表6 基于深度学习的NER 方法比较Table 6 Comparison of NER methods for deep learning
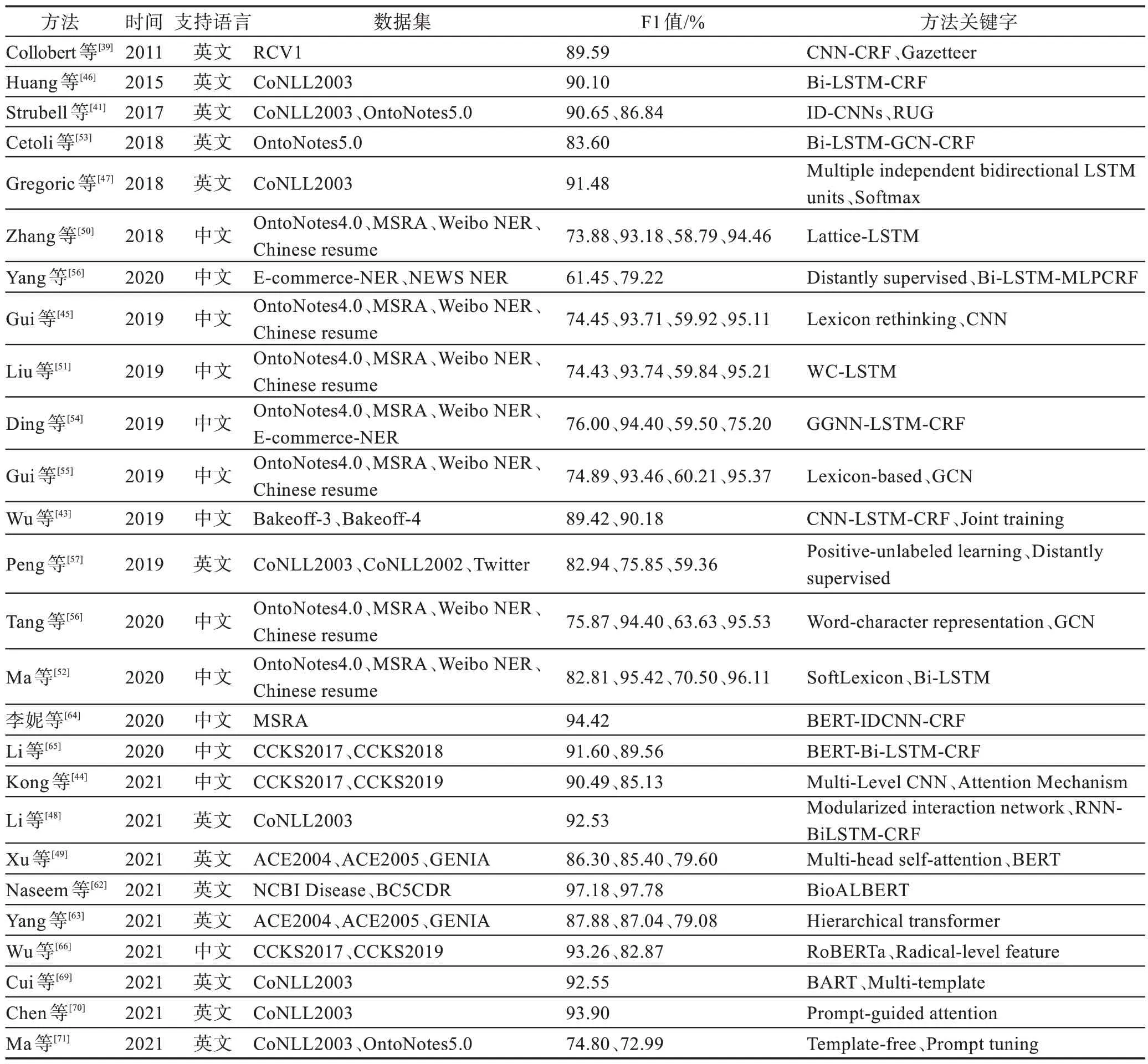
表7 基于深度学习的主流NER 模型总结Table 7 Summary of mainstream NER models for deep learning
3 NER 的研究趋势
目前,NER 技术日渐成熟,但依然需要研究人员投入大量精力进行不断探索,通过对现有NER 研究工作进行总结,在以后的研究中可以从下面几个方面展开相关的研究。
(1)多任务联合学习。传统的pipeline 模型有一定的局限性,例如,NER 任务中的实体标注错误,将会进一步导致后续任务的标注错误;同时,多个任务之间会有一定信息共享,但是pipeline 模型是无法利用这些潜在的信息的。多任务的联合学习,能解决pipeline 模型局限,使得多任务学习之间相互影响,提高学习的性能,利用这种方法来进一步研究NER 仍是未来的一个研究热点。
(2)基于提示学习的低资源NER 研究。在近些年的研究中,NER 任务在广度上已经延伸到跨领域、跨任务和跨语言等任务中。在一般领域,大多数最先进的NER 模型需要依赖大量已标记数据进行训练,这使得它们难以扩展到新的、资源较少的语言中。随着提示学习在低资源NER任务上的成功应用,这种方法能在低资源和高资源之间架起桥梁,从而实现知识转移。因此,探索更优的提示学习方法来提升低资源的NER模型性能是该领域的重要研究方向。
(3)中文嵌套NER 的研究。由于中文构词规则,中文信息文本中的实体嵌套更为明显,此外中文词语没有明显的边界,使得中文的嵌套NER 具有一定挑战。近年来,随着深度学习的发展,中文嵌套NER方法出现新思路,如金彦亮等提出一种基于分层标注的中文嵌套NER 的方法,能充分捕捉嵌套实体之前的边界信息,有效地提高中文嵌套NER 的效果。因此,将各种神经网络、BERT、注意力机制等方法融合用于中文嵌套NER 仍然值得研究。
