基于YOLOX 改进模型的茶叶嫩芽识别方法
2022-09-14俞龙黄楚斌唐劲驰黄浩宜周运峰黄永权孙佳琪
俞龙,黄楚斌,唐劲驰,黄浩宜,周运峰,黄永权,孙佳琪
(1.华南农业大学电子工程学院(人工智能学院),广东 广州 510642;2.国家精准农业航空施药技术国际联合研究中心,广东 广州 510642;3.广东省农业科学院茶叶研究所/广东省茶树资源创新利用重点实验室,广东 广州 510640;4.华南农业大学工程学院,广东 广州 510642)
【研究意义】长期以来,中国茶产量和贸易量稳居世界前列,对世界茶产业发展产生了重要影响[1]。进入21 世纪以来,农业劳动力不断向其他产业转移,结构性短缺和老龄化趋势成为全球性问题[2]。随着人们对茶叶的需求量越来越大,茶农也需要加速茶叶制作生产的过程,而尤为迫切的是提高茶叶嫩芽采摘效率。现阶段茶叶的采收方式主要以人工手采为主,机械化粗采为辅[3]。机械化粗采虽然解决了人工采摘耗费人力巨大且效率低下的问题,但不能精确区分嫩芽与老叶。
【前人研究进展】机器视觉技术是近20 年发展起来的一种新兴检测技术,在农产品的大小分级、形态检测、颜色识别等方面应用较多[4]。针对茶叶嫩芽识别问题,国内外学者基于传统机器视觉开展了许多研究。陈妙婷[5]基于改进PSOSVM 算法对茶叶嫩芽图像进行分割以获取嫩芽特征信息,并选择YOLO 算法进行嫩芽采摘点的识别,准确率达到84%以上;唐仙等[6]对RGB 颜色模型的色差法(R-B)进行分析,对比研究了多种阈值分割法的优劣;段勇强等[7]基于改进Kmeans 算法对富硒绿茶图像进行采集并识别其中的嫩芽,识别率最高达到95%,但该方法在图片分辨率很高的情况下会严重影响聚类过程,存在一定的局限性;周颖颖等[8]基于传统视觉技术对茶叶嫩芽图像进行分割后,再通过对分割后图像的关键区域进行色差判断实现了龙井茶嫩芽的分级并提供了合理的采摘点。上述传统机器视觉的方法虽然能较为准确地识别茶叶嫩芽,但识别的图片背景环境比较单一,对于复杂环境下的识别任务鲁棒性较低,并且在选择物体特征时需要人工进行选择,难以满足更多的实际需求。在提取物体特征方面,基于深度网络的目标检测算法远超于传统机器视觉方法。近年来,越来越多的学者将目标检测算法应用于农业检测领域,代表算法有R-CNN[9]、Fast R-CNN[10]、Faster R-CNN[11]、YOLO(You Only Look Once)[12]及SSD(Single Shot MultiBox Detector)[13]等,它们在农业检测领域不断被改进优化[14],加速了农业作物检测领域的发展。黄河清等[15-16]基于Fcos[17]的思想,以Darknet19 为主干网络,连接特征金字塔进行特征多尺度融合,训练完成后,将权重小于30%的通道删除,实现了对柑橘的识别。在茶叶嫩芽识别领域中,张晴晴等[18]针对复杂场景下传统嫩芽识别方法准确率低的问题,提出一种基于改进YOLOV3 模型的识别方法,提高模型对茶树嫩芽的识别能力,但在茶树冠层出现与嫩芽相似的其他作物或杂草时,模型可能会出现误检。孙肖肖等[19]将深度学习与OSTU 算法结合,对茶叶嫩芽图像进行分割,使得茶叶嫩芽区域更加明显,提高了检测精度,但由于其茶叶嫩芽数据集中小目标较少,会导致模型对目标较小的茶叶嫩芽的检测能力不强,在实际场景中应用时,对于较小的茶叶嫩芽,会出现漏检的情况。许高建等[20]选用基于不同特征提取网络的Faster R-CNN网络模型对茶叶嫩芽数据样本进行训练,得出基于VGG-16 网络的Faster R-CNN 模型识别效果较好的结论。施莹莹等[21]基于YOLOv3 算法,通过单一的特征提取网络进行多尺度目标检测,对自然环境下的茶叶嫩芽进行识别时具有较高的召回率以及准确度。王子钰等[22]通过提取超绿因子对嫩芽图像进行预处理,利用SSD 模型进行训练,实现对茶叶嫩芽的检测,但其并未就SSD 模型对小目标检测效果不好的问题进行优化。
【本研究切入点】目前,深度学习、神经网络等技术手段发展迅速且日益成熟[23]。YOLO 系列算法为“one stage”目标检测算法,在不损失精度的同时,具有较快的检测速度。为改善上述方案的误检、漏检等问题,本研究以YOLOX[24]模型为基本框架对茶叶嫩芽识别展开研究,在模型中融入SE(Squeeze and excitation)[25]注意力模块,并引入Soft NMS[26]算法替代原模型中传统NMS[27]算法。【拟解决的关键问题】采用基于YOLOX 改进模型的茶叶嫩芽识别方法,明显改善复杂场景下的识别能力及小目标嫩芽识别能力。
1 数据集准备与模型设计
1.1 数据采集及处理
数据集原始图像采集自广东省英德市英德茶叶世界,采集对象为英红九号,采集设备为Iphone XR。对茶叶嫩芽图像进行采集时,嫩芽以外的信息为背景,所拍摄图像包含1 个或多个目标。共采集原始图像1 215 幅,包括晴天、阴天、顺光、逆光等情况,数据集图片示例见图1。为加强数据的多样化、提高模型的鲁棒性,对原始数据集进行镜像翻转、光照亮度调整操作。经过镜像翻转后,数据集扩充为2 430 幅,再对原始数据集进行亮度调整操作,最终数据集为3 645 幅。

图1 数据集图片示例Fig.1 Sample dataset pictures
1.2 图像标注
将上述嫩芽图片整理经增强后的数据集共3 645 张,使用LabelImg 图像标注工具对图片中的目标嫩芽进行标注:图2A 表示采集设备正视茶叶嫩芽时一芽一叶的类型,标注为“one”;图2B 表示采集设备正视茶叶嫩芽时一芽两叶的类型,标注为“two”;图2C 表示采集设备侧视茶叶嫩芽的类型,标注为“side”,其特点为嫩叶对嫩芽茎部造成遮挡;图2D 表示采集设备俯视茶叶嫩芽的类型,标注为“top”,其特点为嫩芽本身对茎部造成遮挡。将数据集中晴天、阴天、顺光、逆光4 种情况的图片数据均按照70%、20%、10%的比例划分,最终组成训练集2 552 幅、验证集729 幅、测试集364 幅,图片总数3 645 幅。

图2 茶叶嫩芽标注类型Fig.2 Schematic of marking types of tea buds
1.3 茶叶嫩芽检测模型设计
1.3.1 YOLOX 模型改进 YOLOX 模型主要可分为Backbone、Neck 以及YOLO Head 3 个部分。输入端的图片首先会在Backbone 进行特征提取,提取到的特征信息所包含的位置信息、细节信息较多,语义信息较少;Neck 作为YOLOX 模型的加强特征提取网络,会结合不同尺度的特征信息,进行上采样特征融合以及下采样特征融合以获取更丰富的特征信息;最后在YOLO Head 对获取到的特征信息通过分类器和回归器进行判断,判断是否有对应物体。
由于在Backbone 提取的特征包含的细节信息较多,而语义信息较少,小目标(茶叶嫩芽)的特征信息经过处理后,特征信息易丢失,从而引起对茶叶嫩芽的误检和漏检。为提高YOLOX 原始模型对小目标嫩芽的检测精度,在原有的网络模型基础上,在Backbone 和Neck 之间增添SE 模块,改进YOLOX 网络模型框架如图3 所示。
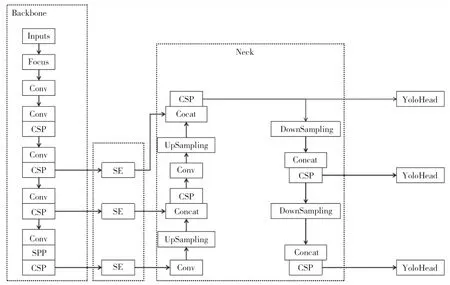
图3 改进YOLOX 网络模型框架Fig.3 Improved YOLOX network model framework
1.3.2 融合SE(Squeeze.and.excitation)注意力机制 SE 模块通过构建特征通道之间的依赖关系,先通过学习的方式获取每个特征通道的重要程度,再依据每个通道的重要程度抑制对识别任务用处不大的特征信息并增强有用的特征信息,提升识别精确度。该模块新增的参数和计算量较小,原模型参数总量为8.94 M,引入SE 模块后,模型参数总量为8.99 M。SE 模块的结构如图4所示。

图4 SE 模块结构Fig.4 Structure of SE module
SE 模块主要由Squeeze 和Excitation 两部分组成,Squeeze 部分通过全局平均池化操作将原始维度为H*W*C 的特征图压缩为1*1*C 的特征图,如下式所示:
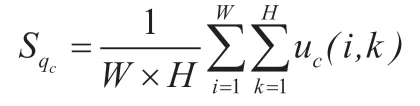
式中,Uc(i,k)表示第i个通道位置为(i,k)的元素,H是高度(height)、W 为宽度(width)、C 为通道数(channel)。Squeeze 操作后获取到H*W的全局特征感受区域更广。
Squeeze 操作完成后,通过Excitation 操作获得通道之间的依赖关系,这一部分由两个全连接实现,第一个全连接层FC1将C个通道压缩成C/r个通道(r为压缩比例,本研究取r=16),以降低计算量,再经ReLu 函数激活通过FC2;第二个全连接恢复回C个通道,再经Sigmoid 函数生成权重,最后经过Scale 操作生成最终的输出X。
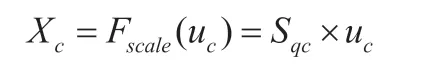
1.3.3 引入Soft NMS 算法 目标检测算法在检测过程中,通常会在目标附近产生较多候选框,NMS(Non-Maximum Suppression)算法的核心思想对重叠度较高的候选框进行评分,最后保留分数最高的候选框。利用传统的NMS 算法去除检测时的重复框,会将与目标框相邻的且正确识别出物体检测框的分数强制归零,容易导致漏检。针对这种情况,本研究引入Soft NMS 算法。Soft NMS 算法是基于NMS 算法改进而成,为避免出现分数为0 的情况,对候选框进行小分数权重打分。权重打分有线性加权和高斯加权两种,本研究采用高斯加权的Soft NMS 算法,其计算公式为:
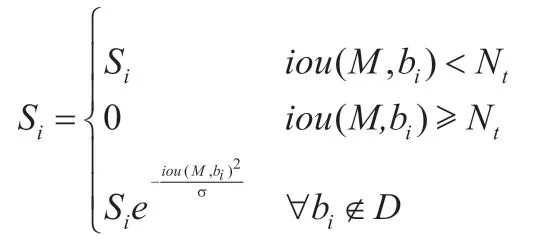
式中,Si为当前检测框的得分,M为权重最高的候选框,bi为检测过程中产生的候选框,Nt为IoU 阈值,ϭ为高斯惩罚系数,D为最终检测结果集合。两个检测框重叠度越高,高斯惩罚系数越大,则得分Si越小。
1.3.4 试验环境 本试验训练模型使用的操作系统为Ubuntu 20.0.4,处理器为Inter i7 11700@2.6G Hz,GPU 型号 为Nvidia Geforce RTX3090。测 试框架为pytorch1.7.0,使用CUDA 11.0 版本并行计算框架配合CUDNN8.0.5 版本的深度神经网络加速库。
1.4 评价指标
本研究所使用模型的性能采用均值平均精度(mAP)进行衡量,计算公式为:


式中,R为召回率,TP为阳性的正样本数量,FN为阴性的负样本数量,n 为目标类别数量。
2 结果与分析
2.1 Loss 曲线
本研究主要参数设置:每次迭代训练的样本数为16,对数据集样本迭代47 000 次,初始学习率为0.001,采用余弦退火的学习率下降方式改变学习率,网络模型的Loss 值变化曲线如图5 所示。图5 显示了每次迭代的Loss 变化,随着迭代次数的增加,模型的损失值减小。在迭代到40 000 次左右时,损失曲线趋于收敛,模型可以用于茶叶嫩芽图像的识别。
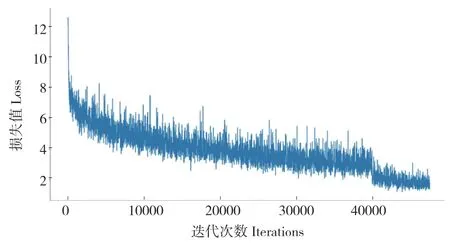
图5 网络模型Loss 值变化曲线Fig.5 Curve of change in Loss value of network model
2.2 mAP 曲线
本研究检测目标共4 类(one、two、side、top),需先计算每一类的平均精度(Average precision,AP),然后再计算所有类的平均精度(mAP)。用相同数据集分别对YOLOX 模型和YOLOX 改进模型进行训练,在训练结束时,用两个模型得到的最佳权重文件进行性能的对比,改进前后两种模型mAP值变化曲线如图6 所示。从图6 可以看出,随着训练轮数的增加,两种模型的mAP曲线均呈现上升的趋势,且YOLOX模型的收敛速度快于SS-YOLOX 模型。在第20个epoch 前,YOLOX 模型的mAP值略高于SSYOLOX 模型;在第20 个epoch 后,SS-YOLOX 模型的mAP值明显高于YOLOX 模型;由图5 可知,在第90 个epoch 后,SS-YOLOX 模型Loss 值已不再明显下降,因此在第100 个epoch 后停止训练。
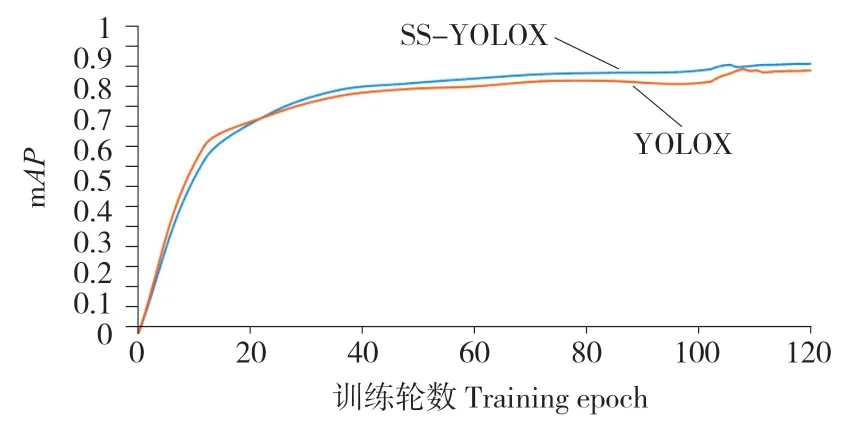
图6 改进前后两种模型mAP 值变化曲线Fig.6 Curve of change in mAP value of two models beforeand after improvement
2.3 YOLOX 消融
为验证本研究提出的对YOLOX 的两种改进策略,对数据集进行消融实验,以判断每个改进点的可行性,在原有模型上加入SE 与Soft NMS函数,运用该改进点用“√”表示,训练过程中,除有无运用改进点外,其他参数配置均一致,消融实验结果见表1。从表1 可以看出,原模型mAP值为0.841,引入SE 后,mAP值提高1.7%,Recall 提高2%,而引入Soft NMS 算法的提升较小。分析认为引入SE 后,增强了网络融合特征信息的能力,关注到许多易被忽略的语义信息,因此在检测精度上的提升较为明显;而Soft NMS 仅在检测框重叠程度较大时发挥作用,因此仅有小幅度提升。
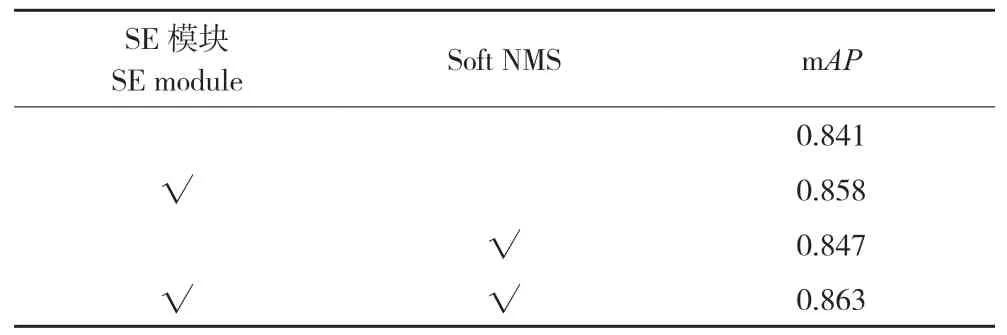
表1 YOLOX 消融实验结果Table 1 Result of YOLOX ablation experiment
从实际场景出发,茶叶嫩芽姿态千姿万化,嫩芽大小以及嫩芽数量不同、不同光照的光照条件、采集设备拍摄的距离和角度不同,都会导致由于采集的原始图像的波动对模型识别效果产生影响。下面通过对比两个模型的识别结果,讨论分析两种模型的性能。
2.4 模型识别结果对比
两种模型在茶叶嫩芽数量较多的情况下的识别结果(图7)显示,两种模型均能识别出茶叶嫩芽,但可以看到YOLOX 模型的检测结果(图7A)有一处一芽一叶“one”类型以及一芽两叶“two”类型没有被YOLOX模型检测到,存在漏检的情况;而SS-YOLOX 模型可以检测到(图7B),表明SS-YOLOX 模型对于图片中的小目标检测性能有所提升。

图7 两种模型识别结果对比Fig.7 Comparison of recognition results of two models
图8 显示,YOLOX 原模型存在误检,将“top”类型错误检测为“one”类型,其原因可能是嫩叶遮挡住部分嫩芽,导致模型错误将其检测为“two”类型。

图8 错误检测结果Fig.8 Error detection results
3 讨论
YOLOX 模型是旷视科技发表的开源高性能检测器,旷视的研究者将目标检测领域中诸如解耦头、数据增强等亮点与YOLOX 以往的系列进行集成。本研究基于YOLOX 模型,针对在复杂场景下可能出现的茶叶嫩芽误检、漏检的问题,对原YOLOX 模型进行改进,引入Soft NMS 算法改善检测框重叠时的打分机制。传统的NMS 算法在去除与目标框重叠度较高的检测框时,会将相邻的检测框分数强制归零,导致模型容易出现漏检的问题。Soft NMS 的打分机制分为两种,分别为线性加权以及高斯加权,本研究采用高斯加权打分机制的Soft NMS 算法,两个检测框重叠度越高,惩罚系数越大,得分Si 越小,而不是强制归零。此外,在一幅图像中远处的茶叶嫩芽会成为小目标,增大模型的检测难度,容易造成误检、漏检的问题,为了进一步改善以上问题,在已引入Soft NMS 算法的模型中融入SE 模块,将SE 模块加入到主干特征提取网络CSPDarknet 和加强特征提取网络FPN 之间。SE 模块通过学习的方式得到每个特征通道的重要程度,再依据通道的重要程度增强有用的特征信息并抑制无用的特征信息,能够更好地识别图像中的小目标,从而达到提升精度的目的。SE 模块内部主要分为Squeeze部分和Excitation 部分,引入模块后新增的参数和计算量小,提升精度的同时并不会给网络模型增加繁重的参数量。
由试验结果可知,改进后的模型SS-YOLOX对茶叶嫩芽进行检测,且引入的Soft NMS 算法和SE 模块均能提升模型的检测性能。虽然本研究模型对茶叶嫩芽图像的识别具有较好的精确度,但未与其他网络模型进行对比,后续将会加入其他检测模型进行研究对比,如Faster R-CNN、SSD模型等。此外,本研究暂未考虑到茶树的叶片对嫩芽遮挡较多的情况,对于遮挡较为严重的嫩芽,在数据集标注阶段根据情况进行了取舍;对于不同茶叶品种对识别结果的影响也暂未作进一步研究。
在后续研究中将会实现软硬件通信,将模型移植入边缘设备,利用边缘设备对茶园中茶叶嫩芽进行实时检测,研究此模型是否能满足实时检测的要求;也会将芽叶遮挡情况对识别结果的影响进行研究,从而提升模型的泛化能力,使其更适用于茶叶嫩芽的识别。
4 结论
随着农业工程与信息化技术的迅速发展,农业信息化已经成为一种趋势。针对目前茶叶嫩芽识别领域中的研究现状及出现的问题,本研究提出了一种改进的茶叶嫩芽检测识别模型SSYOLOX。该模型在原YOLOX 模型上融入注意力模块SE,加强模型对特征信息的提取能力,改善小目标的漏检、误检的问题;引入Soft NMS 算法改变检测框的打分机制,进一步提高模型的识别准确率。对算法模型进行性能分析,SS-YOLOX的mAP值达到0.863、比原模型提高0.022,召回率为76%、比原模型提高2 个百分点,证明了本研究提出模型的可行性。
