多源特征融合的能见度预测方法研究
2022-09-14狄瑞彤王希凯孟宪栋赵京峰侯红运
狄瑞彤 王希凯 孟宪栋 赵京峰 侯红运
(山东省济宁市气象局,山东 济宁 272000)
1 相关工作
能见度的高低与人们的日常生活紧密相关,当能见度较低时,易引发交通事故,造成危害和经济损失。气溶胶粒子、大气透明度以及气象要素等因素会对能见度产生影响,当出现雾、霾等天气过程时,大气的透明度降低,能见度变差。因此,能见度的相关研究受到广泛的关注,对能见度的预测也显得尤为重要。
在能见度影响因素方面,DOYLE M等人根据获取的8个英国气象局观测站点的资料,使用4种不同的统计方法构建了1950—1997年能见度的变化趋势。LEE D O研究发现,英国能见度主要受燃料燃烧和气象条件的影响,与日照时数、风向以及风速无明显关系,能见度提高的原因是二氧化硫排放量降低。王楠等人发现风速是能见度的影响因子,且与其呈正相关。姜江等人研究了北京地区大气能见度的主要影响因子,并分析了2007—2015年北京地区能见度的时空特征分布。
在能见度预测方面,Li Xiang等人使用SAE方法从获得的数据中进行特征提取,然后利用多元线性回归模型进行能见度预测。DEBASHREE等人使用NO、风速等气象因子构建了印度加尔各答机场基于神经网络算法的能见度预测模型,预测结果表明,所使用的气象因子对能见度的总体解释度较高。施悯悯等人构建了多元线性拟合模型和非线性拟合模型对合肥市能见度进行预测,结果表明非线性拟合模型对能见度的预测效果比线性拟合模型更好。丁卉等人通过构建多个多函数统计模型对广州市大气能见度进行预测,获得了较好的预测效果,实际测量值和模拟预测值间的相关系数高达0.9。
因此,该文利用逐步回归方法对与能见度有影响的多源数据进行特征选择,构建有序逻辑回归能见度预测模型,并通过试验对比验证了多源特征和构建模型的有效性。
2 数据来源
数据来源包括气象数据和空气质量数据2个部分。该文气象数据来源于2016—2021年济宁国家气象观测站(54915,116.6014E,35.4411N)逐小时地面观测资料(包括气压、水汽压、温度、相对湿度、降水量、风向、风速以及能见度),且这些数据均经过“台站级—省级—国家级”三级严格的质量控制。其中,能见度数据是利用DNQ1型前向散射式能见度仪进行观测所得的数据,观测范围为1 m~35 000 m;空气质量数据来源于同期的济宁市环境监测站所属的3个国控环境空气质量监测站点(火炬城站、污水处理厂以及圣地度假村站)的逐时观测资料(包括SO浓度、NO浓度、CO浓度、O浓度、PM浓度以及PM浓度),采取这3个站点各颗粒物浓度的平均值代表济宁市的空气质量数据。
3 多源特征提取
3.1 能见度滞后项相关性分析
能见度具有小时周期性,能见度原始序列与24 h~48 h的滞后项之间的Pearson相关系数见表1,其取值范围为[-1,1]。当其为正值时,两者为正相关;当其为负值时,两者为负相关;当取值为(0.95,1]时,表示两者具有显著相关性;当绝对值取值为[0,0.3)时,表示两者的相关性极弱或者不相关;当绝对值取值为[0.3,0.5)时,表示两者呈低度相关;当绝对值取值为[0.5,0.8)时,表示两者呈中度相关;当绝对值取值为[0.8,0.95)时,表示两者呈高度相关;当绝对值取值为[0.95,1]时,表示两者呈显著相关。

表1 Pearson相关性分析
该文根据相关性系数等级划分,舍弃两者相关性极弱或者不相关的特征,将与原始序列之间的相关性系数大于或等于0.3的小时能见度滞后项作为特征选择的备选特征。所选择的小时能见度滞后项分别为24 h、25 h、26 h、27 h以及28 h能见度滞后项,与原始能见度序列之间的相关性系数分别是0.39、0.38、0.36、0.34以及0.31,其余小时能见度滞后项均被舍弃。
3.2 基于逐步回归的多源特征提取
已有的研究表明,气象条件、环境条件对能见度有较大的影响,且通过前文能见度滞后项的相关性分析也可以看出其中一部分小时滞后项与能见度原始序列具有较密切的关系,为了从这些与能见度有关的信息中提取最有效的信息,该文利用逐步回归法进行特征选择,分别对气象因子、环境因子以及24 h滞后项中与能见度相关性大于0.3的数据进行特征选择,构建多源特征融合的数据集。该方法可以剔除不显著的特征,且使剩余特征间的共线性不明显,使其对能见度具有较高的解释贡献。
逐步回归法的基本思想如下:逐个引入影响能见度的特征,每次均引入对能见度影响最显著的特征,并对之前已引入的特征进行检验,看其是否受后引入特征的影响(变得不再显著),如果不显著,就将其删除;如果显著,则保留。最终,模型中存在的特征是对能见度影响最显著的特征,其进行特征选择的基本步骤如图1所示。

图1 逐步回归基本步骤
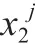
特征剔除的判定条件如下:为了避免新引入的特征与已选择的特征之间存在共线性,使已选择的特征显著性不再明显,当>2时开始进行筛选剔除,其方法为将已选择的所有特征和新引入的特征相结合,与能见度进行线性回归,从特征集中剔除统计值小于给定的显著性水平的特征。
筛选结束的判定条件如下:为了避免陷入死循环,令<,依次进行迭代计算,直至没有被引入和剔除的特征。
4 基于有序多分类逻辑回归的能见度预测
该文结合《水平能见度等级》(GB/T 33673—2017)将能见度划分为4个等级,且这4个能见度等级所表示的程度是逐级递增的。为便于表达,对4个能见度等级进行量化(表2),且给出2016—2021年各等级能见度发生天数所占的比例。其中,把能见度等级定义为因变量,把影响能见度等级变化的特征定义为因变量,=(,,…,x)。当<0.5(为能见度距离,km)时,能见度等级为0,能见度被定义为“差”;当0.5≤≤2.0时,能见度等级为1,能见度被定义为“较差”;当2.0≤<10.0时,能见度等级为2,能见度被定义为“较好”,当10.0≤时,能见度等级为3,被定义为能见度“好”。

表2 能见度等级量化
从各等级能见度发生天数占比可以看出,能见度“差”等级的占比为0.6%,“较差”等级的占比为4.2%,“较好”等级的占比为51.3%,“好”等级的占比为43.9%。其中,济宁市能见度“差”和“较差”的占比极小,能见度“较好”和“好”等级的占比很大,集中分布于这2个等级,说明济宁市出现能见度较低的天数很少,能见度整体状况较好。
由此可以看出,这4个能见度等级所表示的程度是逐级递增的,因此该文选择有序多分类逻辑回归模型对能见度等级进行预测,在该过程中利用累积概率函数得到每个样本隶属于每个等级的概率。
4.1 有序多分类逻辑回归
传统的Logistic回归模型可以写成关于因变量的函数表达式,如公式(1)所示。

式中:为被预测能见度等级为的值,=(0,1,2,3);为截距项参数,=(,,,);为偏回归系数,=(,,,α),均为待估计参数;为特征向量数量;p为当前样本被预测为类别的概率。
该文通过累计概率函数对p进行计算,如公式(2)所示。

式中:p'为当取前个等级的累计概率;为累计概率;为能见度等级。
综上所述,该文的4个能见度等级的预测概率p如公式(3)所示。

4.2 能见度预测模型
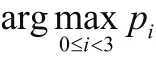

5 试验结果与分析
5.1 多源特征确定
该文分别利用逐步回归方法对气象特征、环境特征以及滞后项特征进行特征选择,在该过程中令引入的显著性水平=0.05,令剔除的显著性水平=0.1。经过特征选择后,最终共有16个特征被引入,2个特征被剔除,分别是风速和降水量。其中,气象特征共有5个特征被引入,2个特征被剔除,被引入特征的顺序依次为相对湿度、水汽压、温度、风向以及气压;环境特征全部被引入,且被引入的顺序依次为CO、SO、PM、PM、O以及NO浓度;滞后项特全部被引入,且被引入的顺序依次为24 h滞后项、26 h滞后项、25 h滞后项、27 h滞后项以及28 h滞后项。最终由上述数据构成了具有多源特征融合的数据集。
5.2 多源特征提取方法验证
为了判断特征提取方法的有效性,现对其进行检验。回归模型检验方法主要分为3种,即似然比检验、计分检验以及Wald检验。其中,似然比检验既适用于多特征的假设检验,又适用于单特征的假设检验;计分检验在小样本上的结果比似然比检验更接近于x分布,在大样本空间上则相反;与似然比检验相比,Wald检验适用于单特征检验。因此,该文选取似然比检验方法。
似然比检验统计量的计算如公式(5)所示,该公式的含义为通过增加或者去掉某个特征观察似然比的变化来分析该特征对因变量影响的显著性。所选取的气象特征、环境特征和滞后项特征的、值以及其他拟合信息见表3。

表3 模型拟合信息

式中:为不包含检验特征时该模型对应的对数似然值;为包含检验特征时该模型对应的对数似然值。。
通过分析表3可知,在分别引入气象特征、环境特征以及滞后项特征后,似然比均发生明显变化,值均变小,且显著性的值均小于0.05,说明在每类特征中至少存在1个特征的偏回归系数取值不为0,从而验证了该特征提取方法的有效性。
5.3 能见度预测模型验证
为了验证能见度预测模型的有效性,通过对比试验的方法对其进行验证,利用有序多分类逻辑回归模型对不同的类别特征分别进行试验,通过精确率、召回率和调和平均数值3个指标值对能见度预测模型的优劣进行验证,在该过程采用五折交叉验证。召回率、精确率和值的计算公式分别如公式(6)~公式(8)所示。

式中:为被正确划分且本身为正类的样本数量;为被错误划分且本身为负类的样本数量;为被错误划分为正类的负类样本数量。
为了证明多源特征融合的有效性,图2展示了不同类别特征能见度预测的召回率、精确率和值的对比,“气象”代表仅包括气象特征,“气象+环境”代表既包括气象特征,又包括环境特征,“气象+环境+滞后项”代表3种特征均在内。由图2可知,3种特征融合的能见度预测的精确率、召回率和值均高于另外2种特征组合,“气象+环境”特征组合表现次之,仅包括“气象”特征的组合表现最差。在精确率方面,3种特征融合的能见度预测比包括“气象+环境”特征组合和仅包括“气象”特征组合分别高出0.09和0.15。在召回率方面,3种特征融合的能见度预测比包括“气象+环境”特征和仅包括“气象”特征的组合分别高出0.21和0.30;在值方面,3种特征融合的能见度预测比包括“气象+环境”特征和仅包括“气象”特征的组合分别高出0.16和0.24。其表现最佳的原因是所含的信息更多,对能见度特征的度量更精确,对其的分析更全面,因此利用多源特征融合可以更好地提高能见度预测精度。
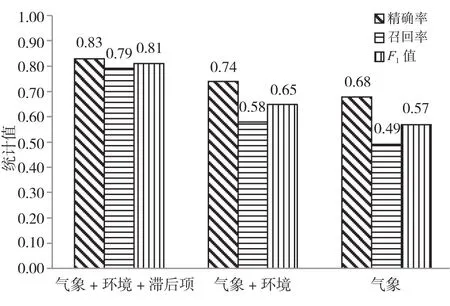
图2 不同特征能见度预测效果
为了证明有序逻辑回归方法的有效性,图3展示了在数据集上进行不同算法预测能见度的召回率、精确率和值的对比,该文选取了多分类逻辑回归方法和线性回归方法进行对比。由图3可知,在有序多分类逻辑回归上的表现是最好的,略高于多分类逻辑回归,在线性回归上的表现最差。在精确率方面,有序多分类逻辑回归比多分类逻辑回归和线性回归分别高出0.02和0.14。在召回率方面,有序多分类逻辑回归比多分类逻辑回归和线性回归分别高出0.02和0.25。在值方面,有序多分类逻辑回归比多分类逻辑回归和线性回归分别高出0.02和0.20。其原因是能见度的等级是递增的,而其使用的是累计概率函数,与能见度的性质相符,因此预测结果更科学、准确。在线性回归上的表现最差,其原因可能是数据为非线性的,不能很好地对其进行拟合。

图3 不同算法能见度预测效果
6 结语
首先,利用Pearson相关系数研究了能见度与气象因子、环境因子以及24 h滞后项间的相关性,并把与能见度相关性大于0.3的滞后项纳入候选特征,利用逐步回归方法对以上各类特征分别进行了特征选择,构造了多源特征融合的数据集。其次,提出了有序多分类能见度预测模型,使用累积概率函数计算每个样本隶属于每个等级的概率。最后,利用精确率、召回率以及值3个指标对模型进行评价,验证了该文所提的多源特征融合的能见度预测方法的有效性。。
