基于人工智能算法的无人机自动控制研究
2022-09-13罗锦彬
罗锦彬
(龙岩学院 物理与机电工程学院,福建 龙岩 364000)
近年来,无人机引起了许多研究人员的极大兴趣并获得了广泛的应用[1-3]。四旋翼无人机具有稳定悬停、垂直起飞着陆、高机动性和简单机械结构等优点,但由于其非线性动态、强耦合、多输入多输出等特点,难以实现高性能控制,复杂的任务和动态的环境也增加了控制的难度。针对四旋翼无人机的控制问题,诸如 PID(Proportional Integral Derivative)之类的线性控制器因其易于实施和可观的性能常被用于四旋翼无人机的控制[4]。但当飞行器失去平衡时,该类方法的性能会下降,研究者对此提出了诸如反步控制器、具有分层动态递归反演的非线性控制器以及二阶滑模控制器的非线性控制方法[5]。在现实应用场景中,四旋翼无人机经常受到风等多种干扰。考虑到这些问题,有研究者提出了干扰抑制控制器,例如鲁棒信号补偿控制器[6]和基于基本函数神经网络 (RBFNN) 补偿的控制器。抗扰技术提高了四旋翼无人机在户外工作时的性能。但是,这些方法无法优化复合性能指标。对此,LQ(Linear Quadratic)控制将一般动力系统化为线性化系统,通过求解Riccati方程得到最优控制器。Riccati方程是 Hamilton-Jacobi-Bellman (HJB) 方程的简化形式,而人工智能算法中的强化学习算法是求解HJB方程的有效方法。但是,现有基于强化学习的控制器没有考虑计算消耗和执行器的饱和度。
如何设计四旋翼无人机的控制策略使其适应环境的动态性是一个亟待解决的关键问题。针对现有控制方法存在的问题,本文基于深度强化学习这一人工智能中的主流算法,提出了无人机控制策略(记为DRLUAVC)。该策略利用Critic-Actor神经网络来实现无人机自动控制,采用基于事件触发的控制更新机制以减少计算开销。
1 无人机模型和问题描述
首先对所使用的无人机模型进行介绍,并提出无人机控制优化问题。将四旋翼无人机作为研究模型,其惯性坐标系(X、Y和Z)和机身坐标系(X′、Y′和Z′)如图1所示。四旋翼无人机的动力学模型可表示为[7-8]:
(1)
其中m是四旋翼无人机的质量;以惯性系为参考,px、py和pz是无人机在机身坐标系中的位置;φ、θ和ψ是描述机身坐标系相对于惯性坐标系方向的欧拉角;τ1、τ2和τ3为三轴的扭矩,τ4是总推力;Ix、Iy和Iz是机身坐标系三轴上的转动惯量(MoI);L是从CoM 到每个执行器中心的长度;JR记录了执行器的MoI,ΩR提供了执行器的转速;d1,…,d6是外部干扰。

图1 坐标系
扭矩和总推力取决于执行器的转速,根据系统模型,可以得到推力和扭矩τ与转速Ω的关系:
(2)
其中CT和CM是将转速转换为推力和扭矩的参数。假设执行器的动力学模型是线性的,转速Ω与控制信号u之间的关系可表示为:Ω=kmu+bm,其中km和bm是电机参数。
假设四旋翼无人机的控制信号受饱和边界约束,即{|ui|≤λα}。四旋翼无人机的负载和功率非常有限,无法搭载一些强大的计算平台。对此,设计了一种非周期性更新控制器来减少计算消耗。所提出的控制器会对传感器的数据进行持续采样,但控制动作和控制器参数将会按照单调递增序列{δi|δi<δi+1}更新,其中δi是第i个触发的时刻。


u=[u1,u2,u3,u4]T
(3)
触发状态用xj表示,而相关的控制动作是u(δj)。根据状态误差和控制约束,设计的四旋翼无人机控制器性能指标定义如下:
(4)
其中W是对称正矩阵,可用于设置收敛速度;λ是一个正向量,可用于设置约束边界;u是由策略μ(x(δj))生成的控制值(即动作)。所提出控制器的目标是稳定系统式(3)并最小化性能指标式(4)。
2 基于深度强化学习的控制策略
在本节中,为四旋翼无人机设计了一个基于强化学习的控制器(记为DRLUAVC),所提出的控制器包含一个值函数(用于评估策略)和一个策略(用于生成动作)。DRLUAVC使用Critic网络逼近价值函数,使用Actor网络确定动作。式(4)可以被转化为

(5)
其中V*是最佳性能指标。
DRLUAVC是事件触发控制器,当满足设定条件时,会对动作进行更新。控制器接收到的系统状态是不连续的,最优控制可以描述为:
(6)

(7)
采样误差定义为采样状态和实时状态之间的差距,用ej表示:
ej=x(δj)-x(t)=xj-x
(8)
事件触发条件具有以下形式:
(9)
其中,α是收敛速率,ru(xj)的定义如下所示:
(10)

(11)
事件触发速率β2是用于平衡性能和计算消耗的。β2的值越小,说明事件触发次数越多,计算消耗越大,性能越高。使用神经网络来计算V*和μ*,用于计算V*的网络称为Critic,用于近似μ*的网络称为Actor。所提出的事件触发RL控制的详细过程如算法1所示。
算法1 基于强化学习的无人机控制算法
1:初始化神经网络Critic和Actor权重
2:For eachiin Epoch_MAX do
3:随机初始化x(0),x0←x(0),j←0
4:计算μ0
5:For eachtin Step_MAX do
6:u(t)←μj
8:观察回报r(t)和新状态x(t+ 1)
9:If‖x(t)-xj‖2>βzeTthen
10:rj←r(t),xj+1←x(t)
11:在经验缓冲区中保存转移(xj,μj,rj,xj+1)
12:随机从缓冲区采样转移
13:使用式(14)和式(15)更新网络权重
14:计算μj+1
15:j←j+1
经验缓冲区用于存储历史的数据,其中,xj和xj+1是系统状态,uj是控制值,rj是回报值。值函数Q(x,u)定义为:
(12)
其中ωc是系数,εc是网络和实际Q值之间的误差。μ(x)定义为
(13)
其中ωα是系数,φα表示隐藏层神经元,tanh是激活函数。将式(12)和式(13)代入式(7)中,可以得到Critic网络权重的更新公式,如下所示:
(14)
最优控制μ(x)可以使Q(xj)值最小化。Critic网络权重的更新公式如下所示:
(15)
控制器仅在事件触发发生时进行控制更新,因此实际的控制规则如下所示:
(16)
3 稳定性分析

(17)

(18)
此时,对式(17)取导数后可得:
(19)
其中K1和K2是参数,用于调整约束边界。‖1-diag(μ2)j‖的最小值可以根据式(12)、式(13)用λ确定。如果满足以下不等式,
(20)
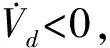
(21)

4 仿真实验
仿真实验部分使用无人机仿真软件进行实验评估,实验环境配置为CPU i7-10700 2.9 GHz、64 GB内存和1 TB固态硬盘。
用于仿真的无人机是四旋翼无人机,无人机的质量为1500克,半径为45厘米,重力加速度为9.8 m/s2,x、y、z轴的惯性矩分别为0.0175、0.0175和0.0318 Ns2/rad,电机矩为0.000099 Ns2/rad,推力系数CT为0.0000111 N(rad/s)-2,扭矩系数CM为0.000000149 N(rad/s)-2,电机速度系数km为646 rad/s,电机速度偏差为166 rad/s。执行器的控制信号取值范围为(0, 1)。Critic和Actor网络的初始权重服从(-1, 1)的均匀分布,无人机的初始状态也是随机选择的。Actor网络隐藏层的神经元数为100,Critic网络隐藏层中的神经元数为300。Actor网络的激活函数为tanh。
在实验中,一个步骤包括5个流程,即状态输入、动作计算、状态更新、策略训练和数据收集。为了分析步骤中各流程的计算时间,执行1000个步骤,并统计每个流程的平均计算时间,结果如图2所示。由图2可知,策略训练和动作计算所需的计算时间占总时间的80%以上。
仿真实验提出了一个稳定性控制任务来验证所提出方法的控制性能,以评估本控制策略在维持稳定性方面的性能。在此模拟过程中,无人机的初始状态为[-5,5,0,0,0,0,0,0,0,0,0,0],无人机根据Actor网络生成的动作保持稳定。我们在系统中添加随机的干扰噪声,其方差为1。当事件触发发生时,执行动作的更新算法、Actor网络的权重和Critic网络的权重。如图3、图4所示,无人机从初始状态很快被调节到了平衡稳定状态。由图5可知,无人机的动作在2.5秒后变得稳定,随后保持着较小的变化幅度以对抗干扰。当满足事件触发条件时,动作不连续更新,虽然节省了计算资源,但是会导致如图4所示的角速率抖动。通过上述结果和分析可知,所提出的策略能够在随机干扰的环境中保持稳定,结合图2中动作计算、状态更新和策略训练的计算时间结果可知,提出的策略维持无人机稳定的计算时间开销是可以接受的。

图2 各流程的耗时
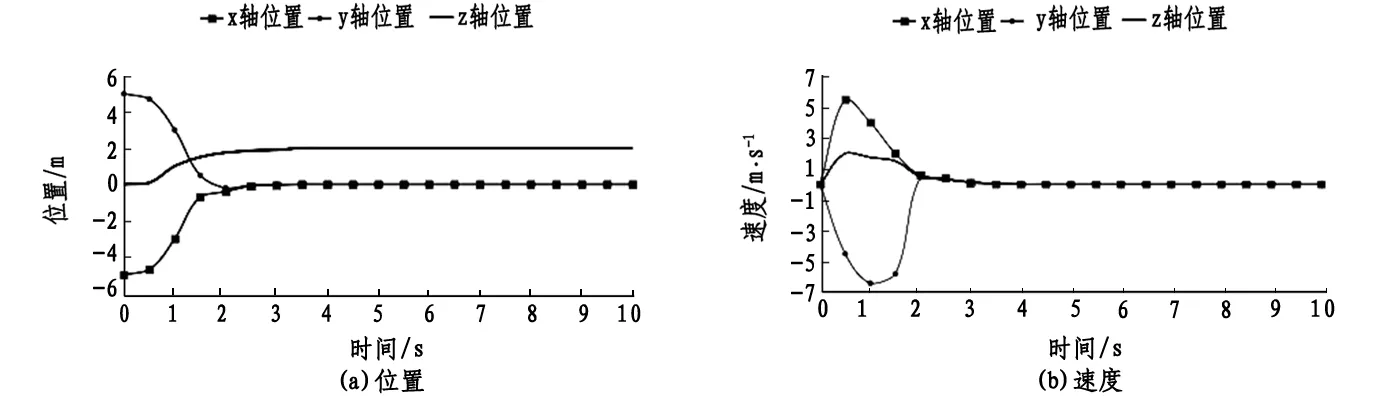
图3 无人机的位置和速度变化情况

图4 无人机的姿态变化情况 图5 无人机的动作变化情况
5 结论
本研究提出了基于深度强化学习算法的无人机自动控制策略,使用了两个神经网络来优化控制策略,并结合事件触发的驱动模式来降低计算成本,提高系统的鲁棒性。仿真实验结果表明所提出的策略具有有效性。在未来的研究工作中,我们将针对更复杂的无人机系统优化基于深度强化学习的控制器。
