融合时序和信任值矩阵的协同过滤推荐算法
2022-09-09石京京于敬赛娜
石京京 于敬 赛娜
(达而观信息科技(上海)有限公司 产品技术中心 上海市 201203)
1 引言
随着移动互联网和大数据技术的迅猛发展,人们每天接触到的信息种类繁多,并且成指数级增长。在信息汪洋中,如何让用户高效并且快速地获取自己感兴趣的有价值信息,成为各大产品设计的重中之重事项。用户获取信息主要有两大方式,一是当需求比较明确时通过搜索引擎的方式找到自己感兴趣的信息,二是当需求不是很明确时会通过浏览被推荐的信息以筛选自己感兴趣的内容。虽然搜索引擎在一定程度上缓解了用户筛选信息的难度,但是在很多场景中,如在线购物、听音乐、看新闻等等,当用户无法准确表达自己的信息关键词时,智能推荐系统则显得尤为重要。推荐系统通过对用户与推荐信息的持续交互行为进行分析挖掘,生成用户画像,通过推荐算法实现用户和信息的精准匹配,自动地从海量信息中筛选出用户最可能感兴趣的信息推荐列表。
实践证明推荐系统不仅有效地缓解了信息过载(information overload)问题,也可以很好地应对信息长尾(long tail)问题,因此一直是工业界和学术界研究的热点领域。在众多推荐算法中,协同过滤推荐算法因其原理简单、易于实现和并行化处理、无监督学习、具有较好的解释性等诸多优点,在工业界得到了最广泛的应用,同时在学术界也在通过各种方式不断地进行算法改进和优化。
基于对协同过滤算法的深入研究和分析,结合推荐场景的数据特点,本文提出了一种融合时序和信任值矩阵分解的协同过滤推荐方法(SeqTMF)。该方法首先通过引入信任值矩阵表征用户和物品间的交互行为,在一定程度上缓解了海量行为数据稀疏性对推荐效果生成的不利影响。其次在构建信任值矩阵时融入了时序性(即用户对物品交互行为的先后顺序)的考量,从而可以在原有用户对物品的评分矩阵基础上,进一步丰富数据的多样性。同时分别引入了用户和物品自身的结构关系,即分别利用用户和物品自身之间的内在关联关系以进一步地深入刻画用户和物品自身的画像,从而为推荐精准度提供了可靠保障。实验结果表明,本文提出的SeqTMF推荐方法相对于传统的协同过滤推荐方法在RMSE指标上明显的提升。
2 相关工作
协同过滤(Collaborative Filtering,CF)根据用户-物品评分矩阵或点击行为交互矩阵,寻找最近邻用户或者物品集合,以预测用户对未发生交互行为物品的评分。目前协同过滤推荐算法主要分为两种,分别是基于邻域的方法和基于模型的方法。而基于邻域的方法又分为三种,即基于用户的协同过滤、基于物品的协同过滤和混合推荐方法。
与传统的基于邻域的协同过滤推荐算法不同的是,基于模型的协同过滤推荐算法是结合用户对物品的评分矩阵进行模型的迭代训练,通过不断优化后得到最终的推荐模型,进而对未知物品预测用户可能的评分并最终生成推荐结果。当前,基于模型的协同过滤推荐方法主要包括概率相关模型、聚类模型、潜在因子模型、贝叶斯层面模型等。在概率模型方面,业界也取得了诸多研究成果。Salakhutdinov等[于2007年提出了概率矩阵分解算法(Probabilistic Matrix Factorization,PMF),利用低维的近似矩阵计算代替高维矩阵的计算,降低了计算的时间复杂度,并且优化了算力且提升了推荐效果。同时为解决PMF算法中参数调整对算法的影响,进一步提出了贝叶斯概率矩阵分解算法(Bayesian probabilistic matrix factorization,BPMF),在该算法中使用了马尔可夫链蒙特卡洛算法(Markov Chain Monte Carlo,MCMC)进行参数估计,实现了参数的自动化训练,从而进一步提升了推荐效果。
围绕推荐效果持续优化的深入研究,很多研究学者探索将更多维度的附加信息引入至概率矩阵分解算法中,如社交网络信息、物品标签信息、时序信息等。Jamali等于2010年提出了SocialMF,主要思想是构建用户社交网络关系,并将该关系应用到用户概率矩阵分解的协同过滤算法中,不过该方法缺乏了对产品之间关联性的考虑。Wu L等于2012年提出了TagMF,即将物品标签引入至概率矩阵模型中进行推荐效果优化,结果表明该方法对矩阵分解的推荐精确性有一定的提升。
此外,不少研究学者也在探索时序信息的有效应用,通过将时序信息加入至推荐模型中,使得模型可以动态地学习到交互数据的动态变化,Koren等提出了TimeSVD++,将时间特征加入到向量中,有效解决了兴趣漂移的问题,且在推荐效果中取得不错的效果。孙光福等提出了时序矩阵分解(SequentialMF)的方法,该方法增加了对时序性和物品间的关联性的考量。
在协同过滤算法的持续改进的研究上,Manuel等将信任定义为商务环境中最重要的角色。Jiang等提出的一种基于改进的融合用户信任数据和用户相似度的Slope One算法,解决了传统的Slope One算法的准确率低和不信任数据的问题。蔡晓娟提出了融合相似度和信任度的协同过滤算法,引入了信任度至协同过滤算法中,缓解了数据稀疏对推荐效果的影响。
综上研究分析,在协同过滤推荐算法的应用以及改进上虽然取得了不同程度效果提升的研究成果,但是在实际应用中,协同过滤推荐算法依然存在着问题有待持续研究,一是因评分矩阵的数据稀疏导致推荐置信度不高,二是构建评分矩阵时丢弃了一部分原始数据特征,导致推荐过程易忽略用户和用品的结构关系,因而影响了推荐准确率。针对上述客观存在的问题,本文提出一种全新的融合时序和信任值矩阵的协同过滤算法,以提升推荐精准度。
3 算法工作
本文提出的融入时序和信任值矩阵的协同过滤方法在一定程度上缓解了数据稀疏对效果的影响,并且充分考虑了时序性对推荐效果的影响。
首先,传统的基于矩阵分解的协同过滤,所构建的用户-用户相似度矩阵是对称的,即sim(用户A和用户B的相似度)与sim(用户B和用户A的相似度)是相等的。引入了信任值的考虑之后,Trust(用户A对用户B的信任值)未必等同于Trust(用户B对用户A的信任值),则用户-用户信任值矩阵不是对称矩阵。
其次,根据用户的行为序列分别构建了融合信任值矩阵的用户关系网络图和物品关系网络图。传统的用户关系图是一个无向图,但在现实生活中未必如此。比如用户A为著名人士,而用户B为普通公民,则很大可能是用户A对用户B的行为影响比较大,而用户B对用户A的影响甚微。结合实际情况,构建有向的用户关系网络图更加贴合实际情况。
本节主要介绍算法的整体框架流程、用户-用户信任值矩阵和用户(物品)网络关系图的构建方法以及基于矩阵分解技术如何预测未知推荐物品的评分。
3.1 算法框架流程
本文提出的SeqTMT方法的整体框架流程图如图1所示。该方法的输入为用户-物品评分矩阵以及用户和物品间的交互行为序列,输出为算法预测的用户对未知物品的评分。关键步骤主要分为构建用户-用户信任值矩阵、构建用户-用户关系网络和物品-物品关系网络图和基于矩阵分解技术进行推荐结果预测。

图1:SeqTMF整体框架流程图
3.2 用户的信任值矩阵
首先,本文使用Pearson相关系数计算用户之间的相似度,则用户u与用户v之间的相似度计算方法如式(1)所示。
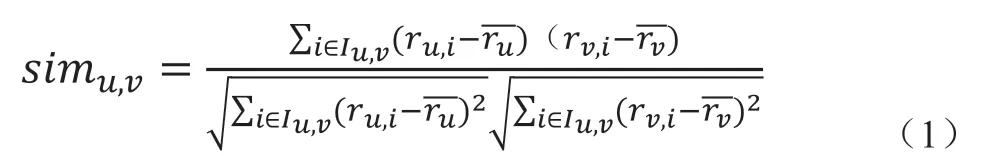
其次,用户u与用户v的信任值的计算公式如式(2)所示。

其中,Trust表示用户u对用户v的信任值,SK表示和用户u最相似的 K个用户的集合,SK表示和用户v最相似的 K个用户的集合,sim表示用户u和用户j之间的相似度。
如表1-3所示,首先根据用户-物品评分矩阵(表1)以及式(1)得到用户-用户相似度矩阵,则用户-用户相似矩阵是一个对称的上三角矩阵。相对于传统的协同过滤方法利用该对称矩阵取TopK的相似用户或者物品集合来预测未知评分,本文方法进行了改进,即根据式(2)计算得到用户-用户信任值矩阵,然后取Top3最相似的用户集合。如表2所示,和用户A最相似的用户集合为{B,D,E},和用户B最相似的用户集合为{A,D,E},则trust=0.452,trust=0.5497,由此可见trust≠trust且用户A对用户B的信任相较于用户B对用户A的信任低一些,即用户-用户信任值矩阵是一个非对称矩阵,具有方向性。

表1:用户-物品评分矩阵
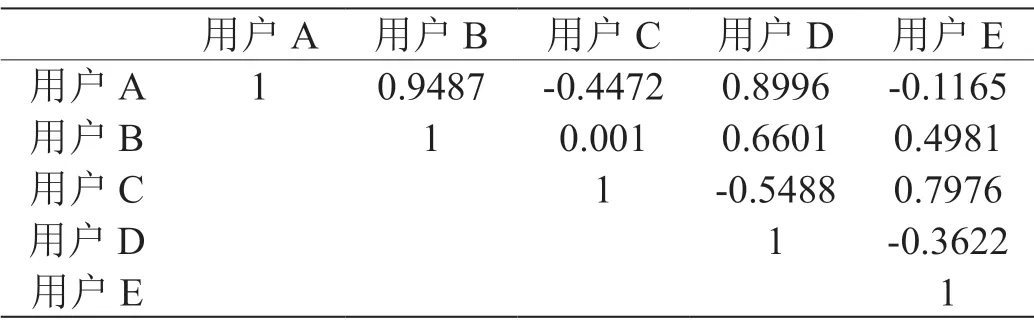
表2:用户-用户相似度矩阵
3.3 构建用户及物品关系网络图
在基于关系的矩阵分解模型中,核心步骤是获取用户或者物品关系。传统的协同过滤方法忽略了用户与物品交互时间的先后顺序对模型的影响。考虑到用户之间的关系以及信任值都是有向的,则在构建用户之间的关系网络图时需要融合两者,而物品间的网络关系图则比较单一。
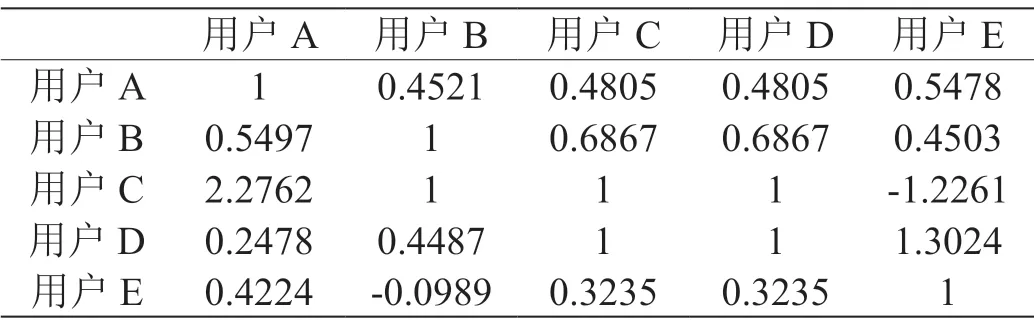
表3:用户-用户信任值矩阵
在用户关系网络图G={U,E}中,U表示用户集合,E表示边集合,W表示边的权重。如果在一定时间内,用户u和用户v先后与同一个物品产生交互行为,则边E的权重W自增1,遍历完所有物品会后,即得到边E的权重W。考虑用户信任值的影响,本文定义用户间的相互影响的关系权重计算方式如式(3)所示。
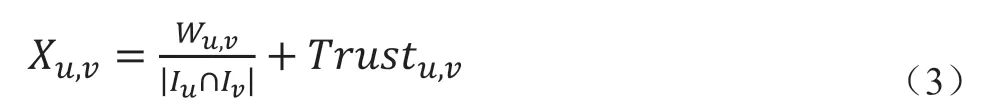
其中I表示和用户u产生交互行为的物品集合,I表示和用户v产生交互行为的物品集合。
同理,我们可以建立物品的关系网络图,与用户关系图类似,其节点物品,其边表示有多少用户与边关联的两个节点都产生过交互行为。构建物品网络图中,可以利用式(4)计算节点之间的相关影响的关系权重。

其中,U表示与物品i产生交互行为的用户集合,U表示与物品j产生交互行为的用户集合。
3.4 生成预测评分
基于前述得到的用户关系网络以及物品关系网络,寻找到用户或者物品的最近邻集合,并且将此应用到矩阵分解中。则用户和物品的特征向量主要受其最近邻特征向量的影响,如式(5)所示。


通过贝叶斯推断,其后验概率如式(8)所示。

为了方便求解,式(8)得到的后验概率的对数函数的处理方式如式(9)所示。
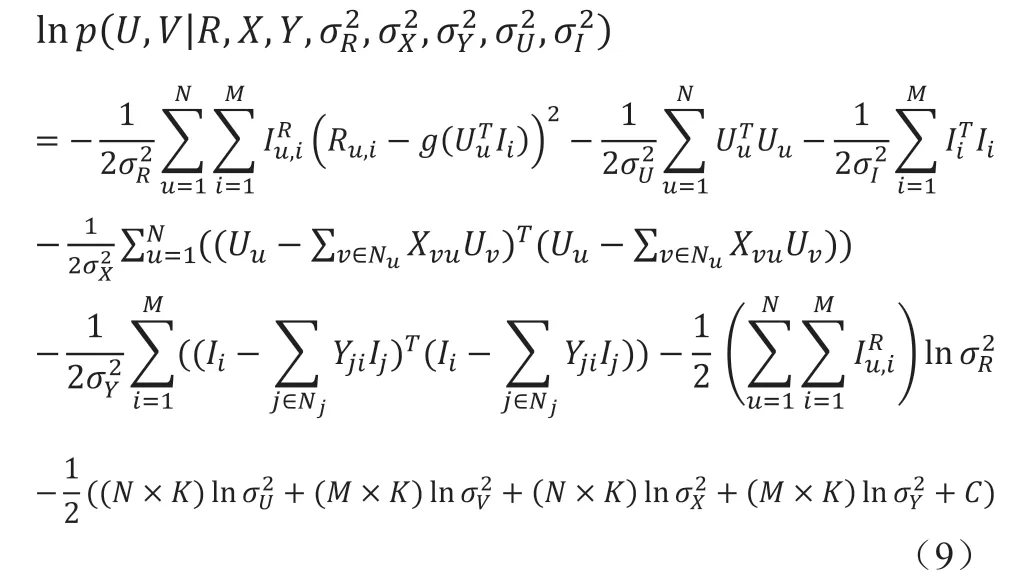
其中,g函数表示sigmod函数。接下来需要最大化后验概率,即通过式(10)求解目标函数的最小化。
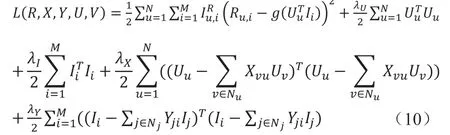

4 实验结果及分析
为了验证本文提出的SeqTMF方法的有效性,本文在公开数据集MovieLens-1M上进行实验,并计算RMSE指标以验证效果,实验结果表明推荐效果优于其它对比方法。
4.1 实验数据集
MovieLens(ML-1M)数据集的相关信息如表4所示。

表4:MovieLens(ML-1M)数据集信息
因本文着重考虑时序性且防止数据穿越,因此按照时间严格将数据集划分成8:2,其中8份为训练集,2份为测试集。
4.2 评价指标


4.3 实验结果与结果分析
为了充分验证本文提出的SeqTMF方法的有效性,在实验中选择了多个基线方法进行对比。各基线方法的简单说明如表5所示。

表5:实验对比方法说明
在数据集上进行充分实验,当设置不同的K值,各推荐方法的RMSE趋势如图2所示。从图中数据来看,随着K值的提升,RMSE值越来越低,表明推荐效果随着K值的增加会越来越好。SocialMF的效果相对BPTF略差,这主要是本实验中的SocialMF方法所构建的社交网络关系数据过于稀疏导致的。而TagMF的效果优于BPMF,表明引入物品侧的标签对推荐效果的影响是正向的。SequentialMF效果优于SocialMF和TagMF,说明时序性对推荐效果的影响大于物品侧,且大于社交数据相对稀疏的SocialMF方法。SeqTMF在几种算法中推荐效果表现最优,从侧面说明了时序性、用户间的信任值、物品间的关联性三者的融合推荐效果是大于单一因素的考量。

图2:各推荐方法在不同K值下的RMSE变化趋势图
5 总结及展望
本文通过对协同过滤推荐算法进行深入地研究分析,并对比目前的一些研究成果,结合在实际应用中的相关问题的调研,提出了一种改进的融合时序和信任值矩阵的协同过滤推荐方法。首先基于用户和物品的交互行为数据构建用户-物品评分矩阵,然后生成用户-用户相似度矩阵,接着得到非对称矩阵的用户-用户信任值矩阵,进一步地融入行为数据的时序特征,最终生成用户-用户关系网络图和物品-物品关系网络图。其次,将中间结果保存的关系网络图数据引入到矩阵分解的协同过滤推荐算法中,得到最后的推荐结果。实验结果表明,本文提出的推荐方法,在一定程度上提升了推荐精准度。在今后的研究工作中,会进一步探索将社交关系、物品标签、用户静态属性等融入至SeqTMF算法中,以期进一步提升推荐结果的精度。
