结合显式句法依赖与分层注意力进行方面级情感分析
2022-09-06范明炜张云华
范明炜,张云华
(浙江理工大学信息学院,浙江 杭州 310018)
719068852@qq.com;605498519@qq.com
1 引言(Introduction)
方面级这种细粒度的情感分析解决了针对一段评论的不同方面,情感的判断可能出现两种相反结果的问题,因此目前方面级情感分析逐渐成为研究的热点,对商品评论、推荐系统等领域具有重要意义。
现有的深度学习模型在情感分析方面取得了较好的效果。基于语义的方法将输入的句子看作单词序列,通过注意力建模,例如RNN、Transformer等;基于语法的方法通过引入句法依赖关系树构造输入句子的语法结构,采用GNN通过依赖关系树上下文词的表示来丰富方面表示;但它们均未充分利用上下文词与方面词之间的语法依赖。XIONG等采用字符级别词嵌入实现文本分类。YANG等做出改进,提出了基于TD-LSTM的方法。但邵兴林通过实体信息与属性信息的比较,发现实体信息更加重要,同时评论可能会有多个句子,选出情感更加强烈的句子也具有重要意义。
受此启发,本文提出结合分层注意力机制与显式句法依赖的多层网络,结合依赖路径编码和实体信息的嵌入表示一并发送到注意力层。构建单词-句子、句子-文档的层次结构,通过加入多级注意力机制,使模型对不同单词、句子赋予不同的注意力权重,对最后的结果做出更准确的判断。
2 相关工作(Related work)
2.1 Stanford Parser
Stanford Parser是基于概率统计的开源句法分析器。基于Penn Treebank作为分析器的训练数据,面向中文、英文等语种提供句法分析功能,可以输出句法分析树,如图1所示。
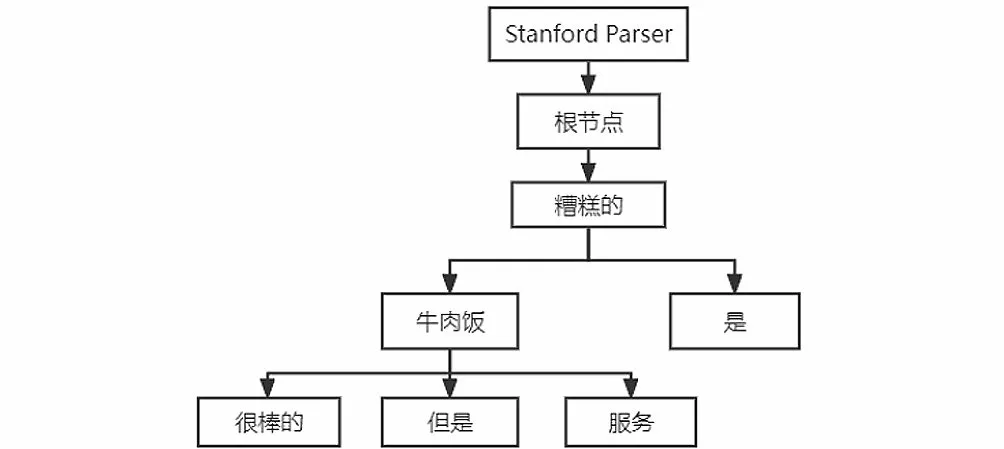
图1 句法分析树Fig.1 Syntactic parse tree
2.2 层次注意力
注意力机制就是关注输入权重分配,可以理解成一个由查询矩阵和对应的键,以及需加权平均的值构成的一层感知机。
层次注意力用于解决多层次问题。如在分析评论时,把词作为一层,把句子作为一层,这样就有了多层,下一层对上一层产生影响,因此建立了一种堆叠的层次注意力模型,如图2所示。
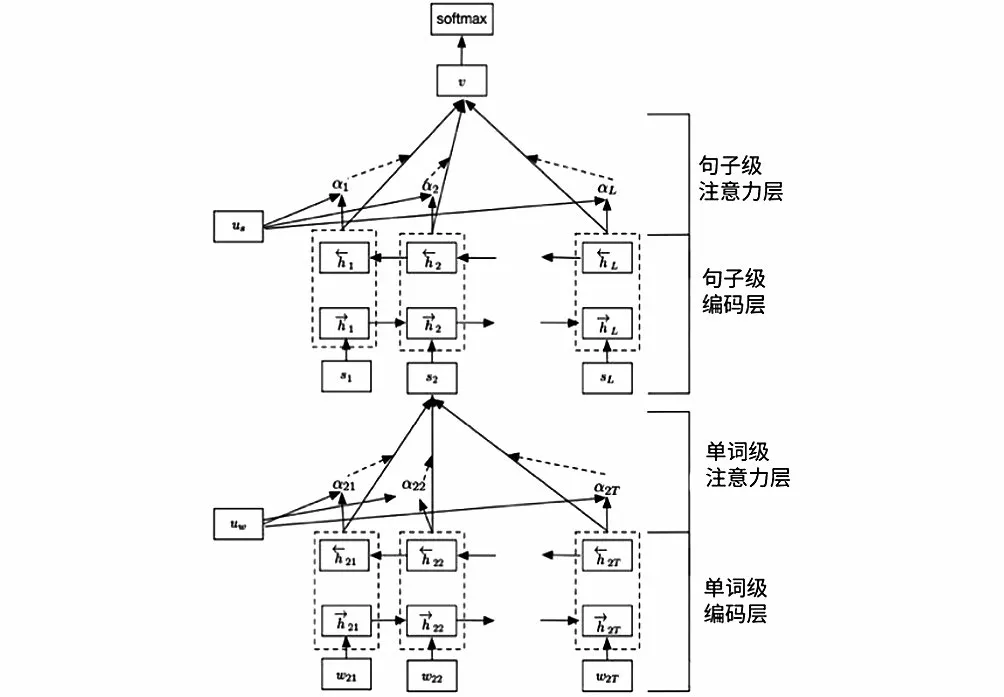
图2 层次注意力模型Fig.2 Hierarchical attention model
2.3 LSTM
LSTM是一种特殊的RNN,主要是为了解决长序列训练过程的梯度消失和爆炸问题,长序列使用LSTM有更好的表现。传输过程中,通过门控状态来控制需要长时间记忆的和忘记不重要的信息,其内部可划分为忘记阶段、选择记忆阶段以及输出阶段,如图3所示。
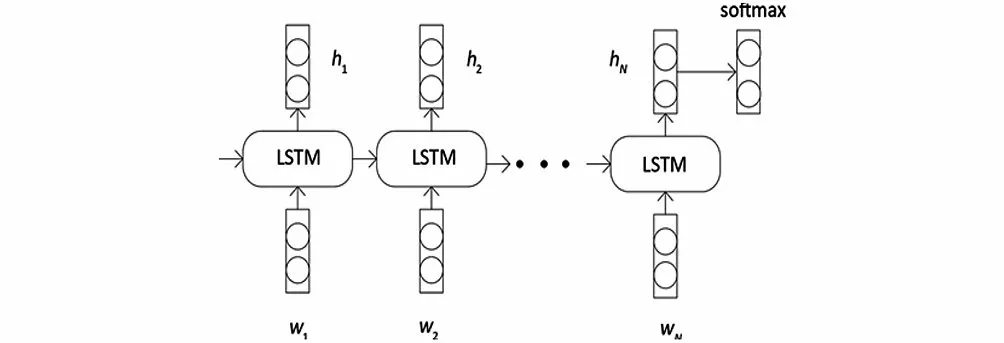
图3 LSTMFig.3 LSTM
3 模型构建(Model building)
给定长度为的句子={1,2,3,…,},以及长度为(0<<)的方面项={[+1],…,[+]},其中∈,可以是词或者短语。目标是对方面项进行情感分析,最终分为积极、消极、中性。
图4展示了模型的整体设计。在词级别,通过句法分析获取句法依赖树,从而得到每个单词到方面项的路径编码和距离。同时获取句子中单词的词性及方面项的实体信息,结合上述路径编码和距离一起馈送到各自的编码层,通过注意力网络得到句子表示。在句子级别,评论中的其他句子表示获取同上,通过LSTM及注意力给予重要的句子更大的权重。这样,单词和句子都有了自己的注意力权重。

图4 模型整体设计Fig.4 Overall design of the model
3.1 输入层
通过Stanford Parser获取句子结构树与每个单词的词性。词性对于情感分析任务是非常重要的,通常形容词和动词比名词表达的程度更深。句法结构树包含词对的关系,在句法依赖路径编码中需要用到。
句法依赖树中每个词到方面词的有向关系路径称为句法依赖路径,路径上边的个数称为距离。例如图1中的依赖树,针对“牛肉饭”这一方面词,句中单词到它的距离为{1,0,1,1,2,1}。针对“很棒的”到“服务”这一方面词的路径,“很棒的—(-amod)→牛肉饭—(+conj)→服务”可以被转换为“[(很棒的,-amod,JJ),(牛肉饭,+conj,NN),(服务,self,NN)]”。“+”和“-”表示有向路径的正反,即关系的方向,并且在最后为方面词附加一个预定义的关系“self”。简单地将依赖路径进行分解容易丢失路径的全局特征,因此使用LSTM对依赖路径序列进行编码,如图5所示。
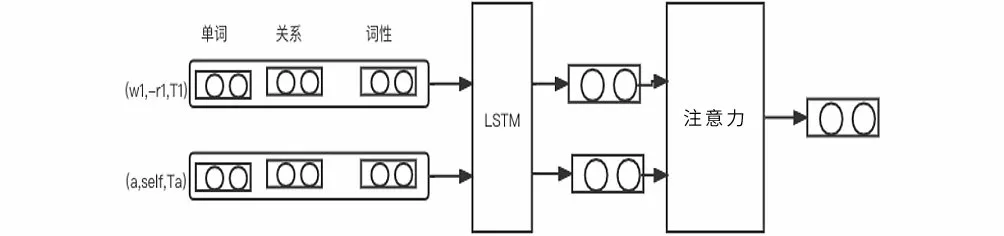
图5 依赖路径编码Fig.5 Dependent path encoding
实体信息对方面级情感分析具有重要作用,如“牛肉饭”这一方面词的实体信息为“食物”,将“食物”通过词向量矩阵获取词向量,同时结合依赖路径编码与距离编码,将上述组成的向量送入注意力层,获得句子向量表示。
3.2 分层注意力
一段评论可能包含多个句子,给句子加入注意力可以使模型提取更适合的句子进行情感极性分析。本文加入新一层句子级别的注意力机制,依照句子向量表示的方法,对每一句话都获取向量表示,将这些句子向量表示作为LSTM新的输入,再将LSTM的输出与实体信息结合,通过注意力机制提取对评论情感极性更加重要的句子,以获取最终评论的向量表示。
3.3 模型训练
利用交叉熵损失函数和L2正则化对模型进行训练,公式如下:

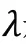
4 实验结果分析(Experimental results and analysis)
4.1 数据集
为了验证模型的有效性,本文使用了SemEval 2014 Task 4中的restaurants数据集,包含三种情感和五个方面,如表1所示。
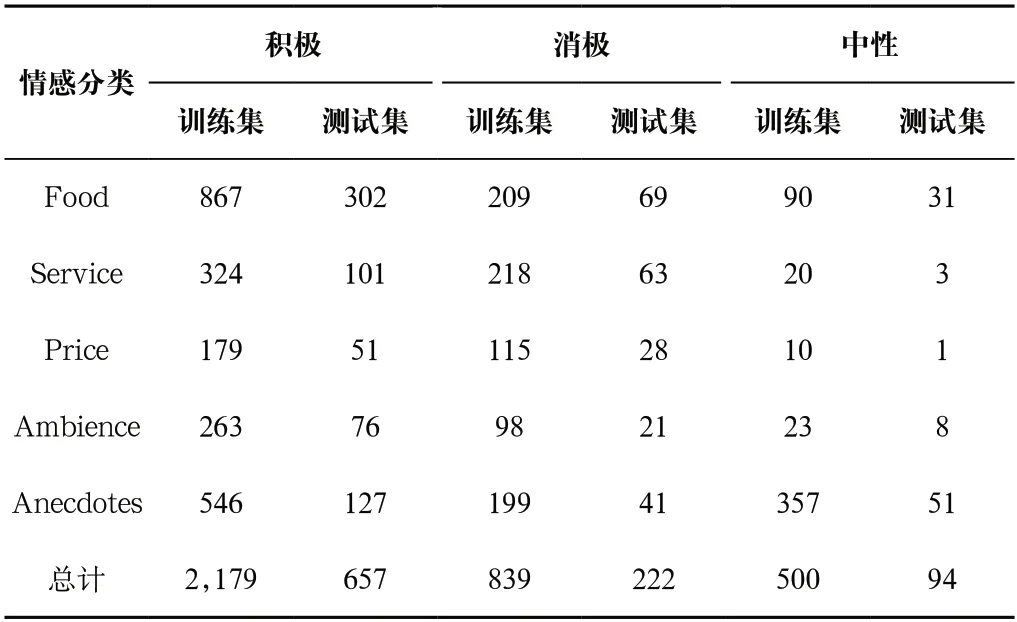
表1 数据集分类统计表Tab.1 Statistical table of the dataset classification
4.2 注意力机制有效性
对于例句“很棒的牛肉饭,但是服务是糟糕的”,当给定实体为“食物”时,“牛肉饭”和“很棒的”被赋予了更高的权重,在句子情感分析中二者起到重要作用。对于该评论“很棒的牛肉饭”和“但是服务是糟糕的”这两个句子,第一句在情感分析中起到重要的作用,而这句话是实体“食物”对应的句子,结果符合预期,如图6所示。
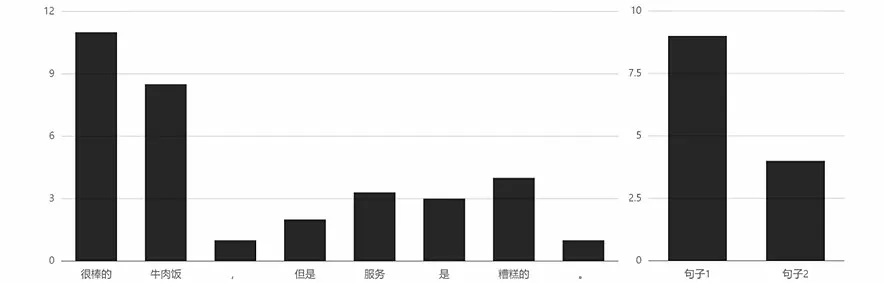
图6 针对“食物”的注意力权重分布Fig.6 Attention weight distribution for "food"
同理,将实体换为“服务”时,单词和句子的注意力权重数据也同样符合预期,如图7所示。
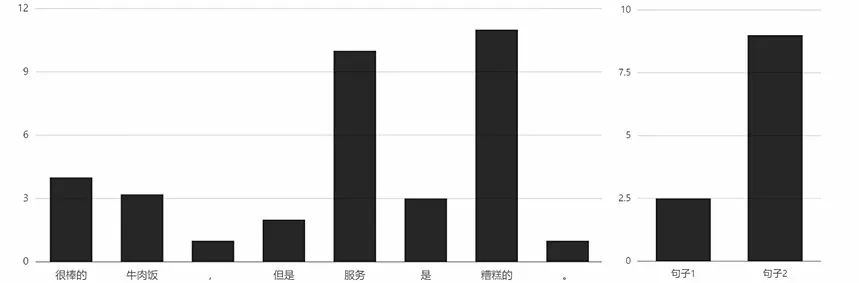
图7 针对“服务”的注意力权重分布Fig.7 Attention weight distribution for "service"
4.3 模型对比
通过在相同数据集中与其他模型进行对比,验证本文模型的有效性,主要采用F1值和Acc值(准确率)进行评估。对比的模型主要有BiLSTM-AMM、BiGRU-AAM、Bi-LSTM、ATAE-LSTM等。
如表2所示,从实验结果来看,本文的方法在数据集上相比于基本的深度学习模型,Acc值和F1值都有所提高,主要是因为模型通过引入实体信息,充分利用显式语法结构获取到更加有用的信息;其次,分层注意力机制的引入也使得结果变得更加精确。
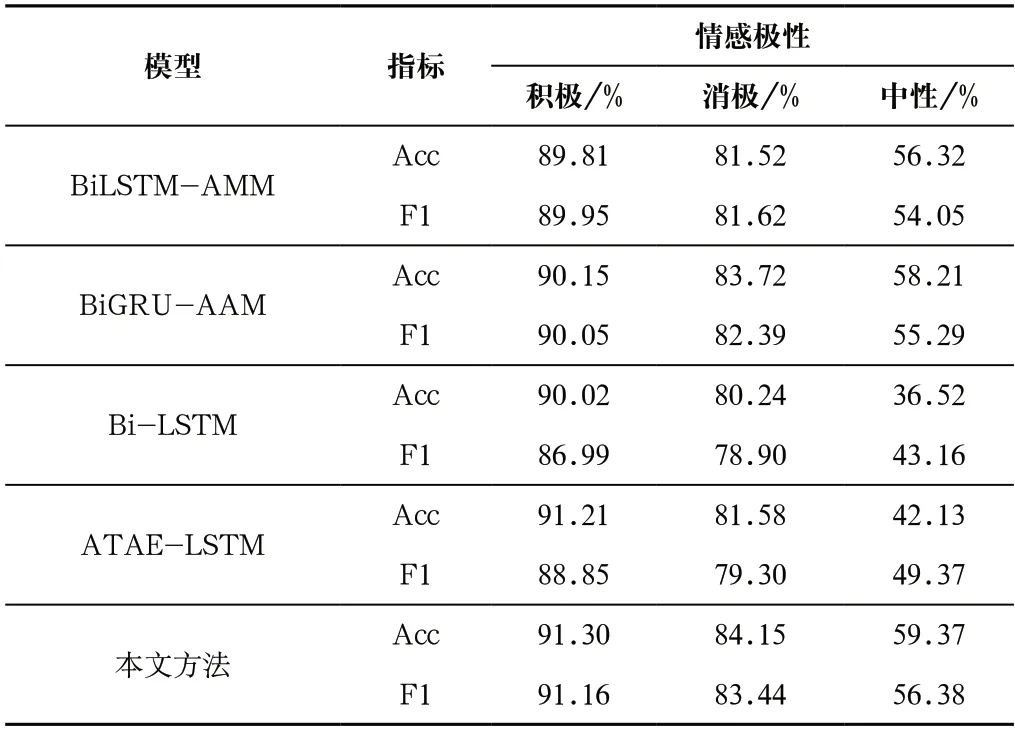
表2 不同模型在数据集中的结果Tab.2 Results of different models on the dataset
5 结论(Conclusion)
针对方面级情感分析中未对句法结构信息与属性信息进行深度挖掘的问题,本文提出的模型一方面利用句法结构、实体信息加强特征获取的能力,另一方面利用分层注意力机制使模型能够赋予重要单词和句子更大的权重。从实验结果来看,该模型能有效提高情感分类的效果。
