基于XGBoost与可见-近红外光谱的煤矸识别方法
2022-09-05王学文李廉洁樊书祥
李 瑞, 李 博*, 王学文, 刘 涛, 李廉洁, , 樊书祥
1. 太原理工大学机械与运载工程学院, 山西 太原 030024 2. 北京农业智能装备技术研究中心, 北京 100097
引 言
煤炭在我国的能源结构中占据主体地位; 综放开采是开采大储量特厚煤层的主要方法, 而煤矸智能识别是实现综放开采智能化亟待研发的新技术[1]。 目前的识别方法有射线法[2]与图像识别法[3], 但分别存在放射源安全隐患与易受粉尘、 光照等环境条件影响的不足。 可见-近红外光谱技术具有实时、 无污染、 高信噪比、 仪器成本低等诸多优势, 满足煤矸分选的要求。 基于可见-近红外光谱的煤的品质测定[4]、 煤种分类[5]、 煤系岩石识别[6]等领域的研究为煤矸识别提供了理论基础。 在此基础上, 学者们提出了多种基于可见-近红外光谱的煤与矸石的分类方法。 杨恩等[7]建立了GRB-KPCA-SVM模型实现了对烟煤与碳质页岩(块状与粉末)的识别; Mao[8]等利用IAM-ELM算法实现了室外环境下煤与矸石的分类; Xiao[9]等建立了ICELM-LRF模型实现了对不同煤种以及煤与矸石的分类; Hu[10]等基于LBP算法对样本多光谱图像进行特征提取, 并采用GS-SVM分类器实现对煤与矸石的分类。 在目前的煤矸识别研究中, 样品大多仅采自一个煤矿, 针对该煤矿样品设计出的算法对其他矿区的适用性有待检验; 部分研究虽使用了不同煤矿的煤与矸石样品, 但样品预处理, 如清洁、 研磨等, 脱离了实际应用背景。 此外大多研究采集样本光谱时使用的背景与实际背景也存在较大差异。
Chen[11]等提出的极端梯度提升树(XGBoost)算法, 是一种Boosting算法, 引入正则化项且支持并行运算, 具有快速、 准确、 可解释等特点, 模型表现较BP神经网络与SVM等有更高的准确率[12], 广泛应用在医学、 遥感、 电气、 电子商务、 故障诊断等领域。 但在可见-近红外光谱分析领域应用较少, 尤其是煤矸识别方向还未见研究报道。
本工作进行了以下研究: (1)基于XGBoost算法建立了块状煤与矸石黑色背景下的可见-近红外光谱分类模型, 并与常用机器学习分类模型进行比较; (2)基于多种特征选择算法筛选的特征波长建立XGBoost以及对比算法的简化模型, 并选出最优简化模型; (3)在相同实验条件下更换其他煤矿的煤与矸石作为样品对XGBoost算法以及选出的最优特征选择与分类的组合简化算法进行煤矿适用性的检验。
1 XGBoost算法
极端梯度提升算法(XGBoost), 为梯度提升决策树(GBDT)的一种实现方法, 以分类与回归树(CART)为子模型, 通过梯度提升实现多个CART子模型的集成学习[13-14]。 XGBoost对目标函数进行二阶泰勒展开, 一阶导数与二阶导数同时参与运算, 提升了模型优化过程中的收敛速度。 算法的步骤如下
目标函数
(1)
正则项
(2)

根据贪心算法, 每次建立新的弱学习器时都以使目标函数降低最大为目标, 第k棵树的目标函数为
(3)
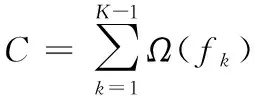
(4)
(5)
化简后的目标函数对wj求一阶导并令导数为0, 求得wj的最优解为
(6)
目标函数的最优解为
(7)
XGBoost分裂节点时遍历所有特征, 以带来最大分裂增益Gain的点作为分裂节点, 定义某特征在整个模型构建中作为分裂结点的次数为weight, 该特征作为分裂节点的平均增益为gain。
(8)
(9)
2 实验部分
2.1 样本与光谱数据采集
在我国煤炭的主要产地山西省、 陕西省与内蒙古自治区, 分别采集部分煤与矸石样品。 如表1所示, 依据产地对样品进行编号与信息统计。如图1所示, 不同产地的样品形状、 颜色存在较大差异。
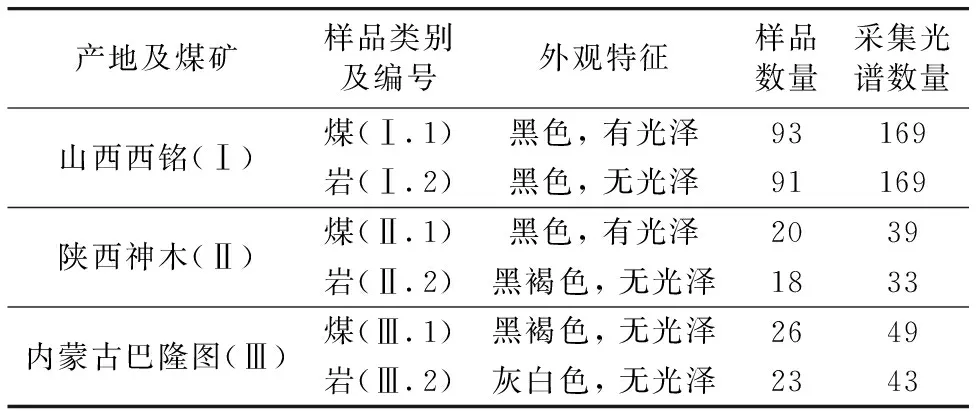
表1 样品信息
图2为搭建的可见-近红外光谱采集系统。 使用150 W卤素灯(JCR15V150WBAU, USHIO, USA)作为光源, 置于光纤探头一侧, 距背景平面垂直距离500 mm, 入射角度调整至与垂直面夹角为30°。 光谱检测光纤(1SMA1S-SI0.6-1500S, Nanjing Shen Lue Technology Co., Ltd, China)的反射光纤探头由干板夹(GCM-1311M, Daheng Optics, China)夹持, 可通过支座(GCM-030304M, Daheng Optics, China)与支杆夹(GCM-55, Daheng Optics, China)调节探头位置与角度, 经调试置于检测样本平面正上方200 mm处。 可见-近红外光谱仪(USB2000+, Ocean Insight, USA)与检测光纤连接, 使用光谱仪配套软件(OceanView2.0.7, Ocean Insight, USA)采集反射光谱, 采集的波长范围为370~1 049 nm, 波长数为2 048个。 采集平台以黑色纸板作为采集背景, 原始块状样品作为采集样品, 模拟选煤环境, 并以黑布与外界隔开, 避免外界杂散光影响。

图1 不同煤矿的煤(a, c, e)与矸石(b, d, f)样品
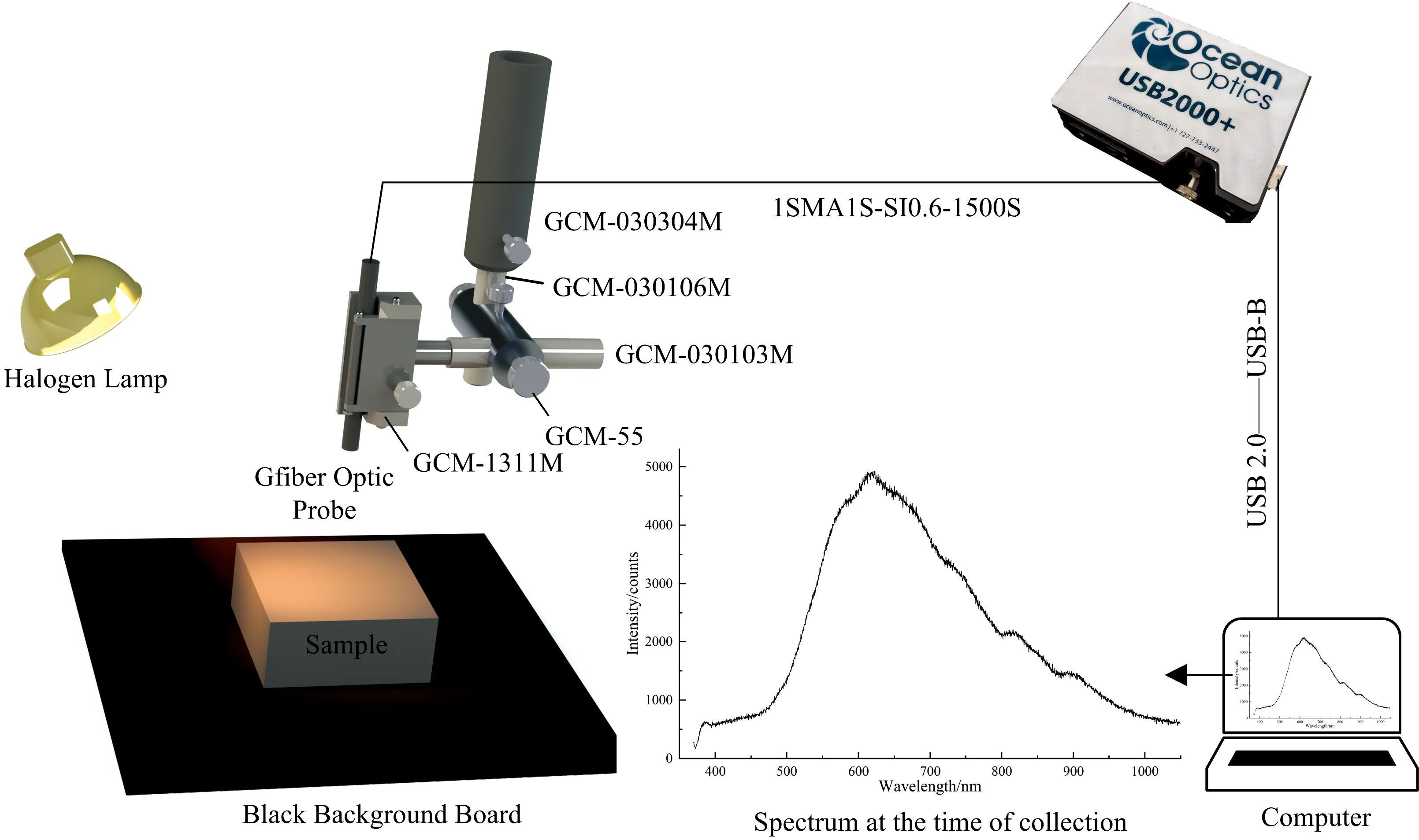
图2 可见-近红外光谱采集系统
采集数据前, 将光谱仪和光源预热15~20 min待光谱曲线稳定后再进行采集。 为避免光谱饱和, 采集时积分时间设置为9 ms, 同时利用平均值采样法以连续三次采集取平均的光谱数据作为最终数据, 以提高数据的准确性。 在室内相同环境下采集样品的反射光强L, 每个样品通过翻转采集面采集1~2条光谱, 并在每次连续采集前利用聚四氟乙烯为材料的标准白板采集白参考Lwhite, 关闭光源盖住光纤探头采集暗参考Lblack。
2.2 光谱预处理
原始光谱数据因受仪器、 采集环境等影响含有噪声与冗余信息, 增加数据维度的同时, 掩盖了关键信息。 因此进行光谱预处理, 去除噪声及冗余信息, 提取特征信息。 根据实验原数据的特点, 使用以下方法进行预处理。
(1)黑白校正与波段挑选
为减小光照不均与暗噪声的影响, 参照式(10)对原始样品数据进行黑白校正以求得相对反射率R, 并以去除含有大量随机噪声的始末波段(369.51~517.69, 859.37~1 049.07 nm)后的反射光谱波段(518.00~857.05 nm)作为后续预处理数据, 特征维度由2 048降至1 000。
(10)
(2)Savitzky-Golay(SG)卷积平滑
使用Savitzky-Golay(SG)卷积平滑法对反射光谱进行去噪, 选择一次多项式拟合, 窗口设为29, 即式(11)中w=14。
(11)
式(4)中,k为当前波长,hi为平滑系数, 2w+1为窗口内的波长数。
(3)标准正态变量变换(SNV)
由于煤矸样品高度在40~95 mm将引起光程变化, 使用标准正态变量变换(SNV)来消除煤矸样品高度变化对反射光谱的影响。 实现公式为式(13), 使用前将反射光谱单位按式(12)进行转换。
A=lg(1/R)
(12)
(13)

在得到预处理后的光谱曲线后, 根据同一煤矿煤与矸石反射光谱差异的显著性, 将样品划分为实验组与测试组。 实验组煤与矸石的反射光谱差异微小, 用于比较全波段与特征波长光谱下不同模型的表现, 选出最佳的算法; 测试组煤与矸石的反射光谱差异较实验组明显, 用于对选出的最佳算法进行矿区适应性检验。
2.3 XGBoost建模与模型评价指标
使用python 3.8.3语言以及XGBoost, Scikit-Learn和Numpy等开源工具包, 在Jupyter notebook编译器中进行建模。 训练集与测试集以7: 3的比例随机划分, 通过学习曲线与网格搜索对模型超参数进行寻优, 同时通过训练集十折交叉验证平均分类准确度ACC10对模型超参数进行调整以避免过拟合, 以期提高测试集的分类准确度ACC。 为更好的评价模型性能, 加入AUC (area under the curve)值为评价指标, 通过上述三个指标可以综合体现模型的稳定性与分类能力。
为更好地评价XGBoost模型对可见光-近红外波段煤矸石分类的性能, 引入k近邻法(KNN)、 随机森林(RF)、 支持向量机(SVM)三种分类算法做对比。
2.4 特征选择算法与简化模型寻优
光谱数据虽经剔除噪声波段预处理, 降低了维度, 但仍为含有冗余信息的多维数据。 因此利用特征选择对光谱数据进行再次降维, 以降低模型计算量, 缩短模型运行时间, 为进一步在线识别研究奠定基础。 选用递归特征选择算法(RFE)、 连续投影算法(SPA)和竞争性自适应重加权算法(CARS)进行特征选择, 并基于特征选择后的波长数据建立简化分类模型, 通过评估模型寻找出最优的特征波长选择与机器学习分类算法的组合。
(1)递归特征选择(RFE)
递归特征选择是一种基于模型特征重要性的特征选择算法, 在每轮迭代时依据特征重要性排名消除若干末尾特征, 并将包含保留特征的数据集作为下一轮的训练样本, 直至将特征降低到一定维度。 XGBoost模型可以通过特征重要性度量指标对特征重要性进行排序, 本工作以式(9)中gian的归一化权重score为度量指标作为特征重要性排序依据, 并通过迭代模型的五折交叉验证均方根误差(RMSECV)进行最佳特征维度的选择。
(2)连续投影算法(SPA)
连续投影算法的选择原理为, 从选入某一波长数据开始, 循环计算新选入的特征波长在未选入特征的投影, 将投影向量最大的波长选出, 直至选出的波长数量达到设定值。 为得到最佳的起始波长与选出波长数量, 利用多元线性回归分析(MLR)对划分后的数据集进行建模, 以测试集均方根误差(RMSE)为模型评价指标, 选出最佳特征波长。
(3)竞争性自适应重加权算法(CARS)
竞争性自适应重加权算法在每次循环中通过蒙特卡洛采样法从训练集中选出一定比例样本建立偏最小二乘(PLS)回归模型。 以指数衰减的方式去除回归系数较小的特征, 并在达到蒙特卡洛采样次数时停止, 以交叉验证均方根误差最小的特征集为最佳特征波长集。 设定采样次数为50, 采样比例为0.8。
2.5 最佳算法的矿区适用性检验
不同产地的煤与矸石物理与化学性质存在差异, 光谱曲线也存在差异, 选出的最佳算法在单一煤矿样品分类中的表现存在局限性, 因此有必要对实验组选出的最佳算法进行煤矿适用性检验。 通过使用选出的最优算法建立测试组全波段以及特征波长光谱的分类模型, 测试模型的性能来检验算法的煤矿适用性。
3 结果与讨论
3.1 反射光谱的分组
原始光谱在经黑白校正、 波段挑选、 SG卷积平滑与SNV预处理后, 降低了环境条件的影响, 并去除了冗余信息, 将特征维度由2 048降至1 000。 图3为预处理后的三个煤矿的光谱图像, 反映出了以下信息:
Ⅰ煤矿煤与矸石的反射光谱曲线整体较相似, 均在619 nm附近出现吸收峰, 750 nm附近出现吸收谷, 但在750~857 nm波段煤与矸石曲线斜率差异明显。
Ⅱ煤矿煤与矸石反射光谱曲线差异明显, 煤的光谱曲线在625和820 nm附近出现吸收峰; 矸石的光谱曲线在680 nm附近产生吸收峰, 在730 nm附近出现吸收谷, 另外有部分样品在825 nm附近出现吸收峰。
Ⅲ煤矿煤与矸石反射光谱曲线差异同样明显, 煤的光谱曲线在680和820 nm附近出现吸收峰; 矸石的光谱曲线在680 nm附近出现吸收峰, 736 nm附近出现吸收谷。
依据三个煤矿煤与矸石样品反射光谱曲线差异的显著性, 将差异微小的Ⅰ煤矿样品作为实验组, 用于对比不同模型的性能, 挑选最佳算法; 将差异较明显的Ⅱ与Ⅲ煤矿样品作为测试组, 用于测试选出的最佳算法的模型性能, 检验算法对不同煤矿的适用性。
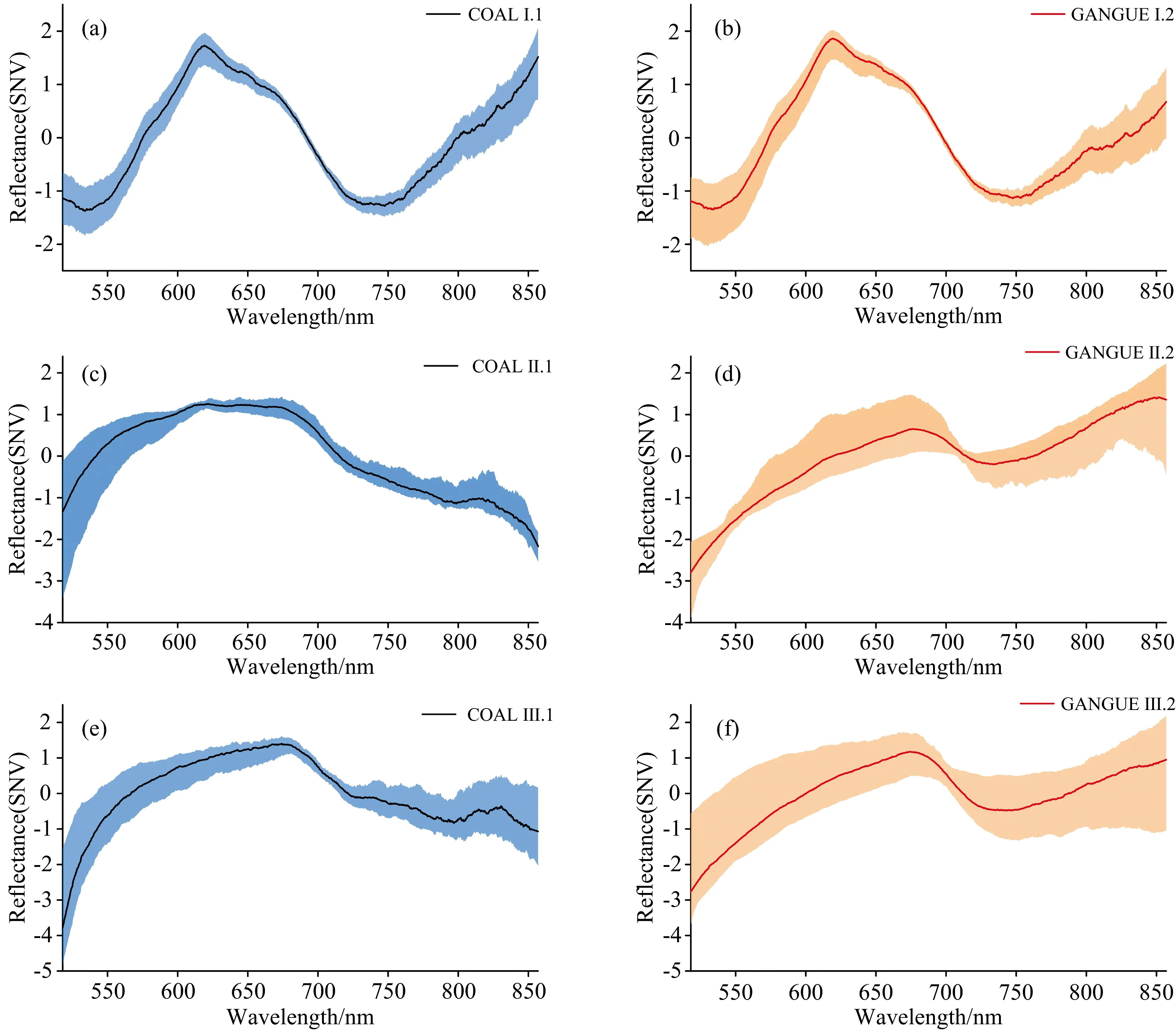
图3 Ⅰ: (a)(b), Ⅱ: (c)(d), Ⅲ: (e)(f)煤矿煤与矸石预处理后的光谱
3.2 基于全波段光谱的煤与矸石XGBoost分类模型
表2为基于实验组全波段光谱的煤与矸石XGBoost分类模型以及k近邻法(KNN)、 随机森林(RF)、 支持向量机(SVM)三种对比算法的模型分类表现, XGBoost表现最佳, ACC10, ACC, AUC分别达到0.957 2, 0.970 5和0.971 6, 较其他模型有更强的分类能力, 可以稳定且准确地完成煤与矸石的分类。

表2 基于全波段光谱的不同分类模型对比
3.3 基于特征波长的煤与矸石分类模型
为降低光谱数据的维度, 缩短模型训练与预测的时间, 分别使用RFE, SPA和CARS算法对预处理后的光谱数据进行特征选择。
RFE的筛选过程如图4所示, 特征数量为9时, RMSECV达到最小, 挑选出的特征波长为673.15, 689.55, 692.27, 698.72, 699.06, 699.74, 700.41, 704.14和707.18 nm。
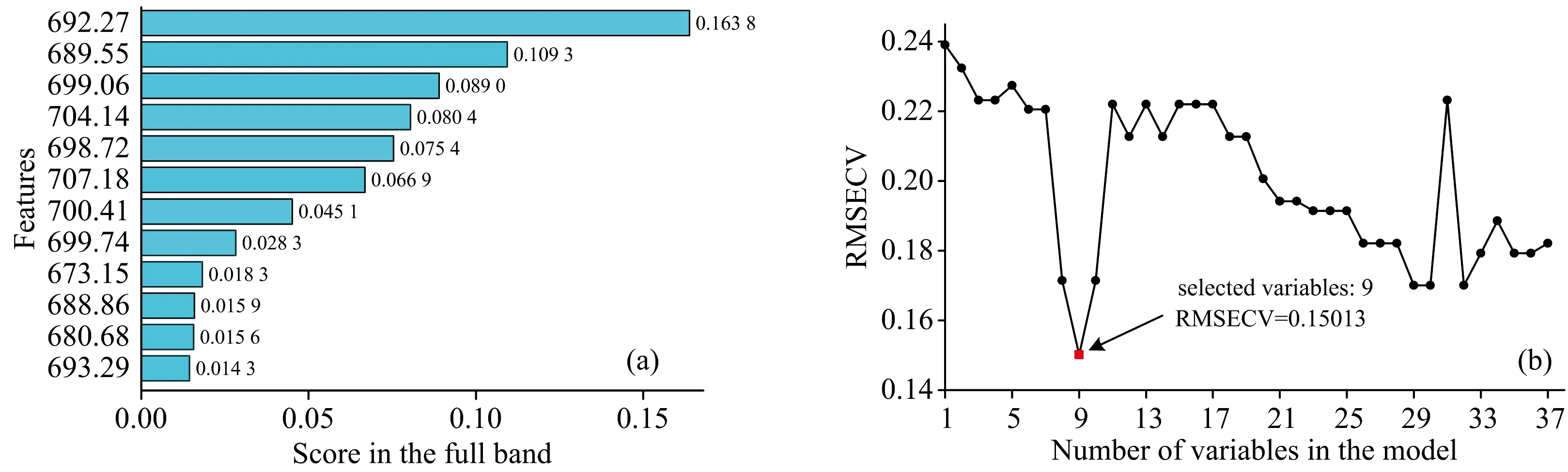
图4 RFE波长筛选过程
SPA的筛选过程如图5所示, 最佳波长数为5, 即: 518.00, 588.17, 671.78, 690.56和718.30 nm。
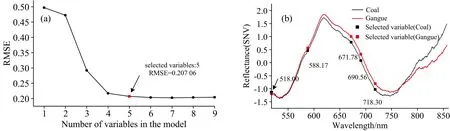
图5 SPA波长筛选过程
CARS的筛选过程如图6所示, 在第23次采样时, RMSECV值最小, 此时的变量子集为最佳特征波长集, 含有61个波长。
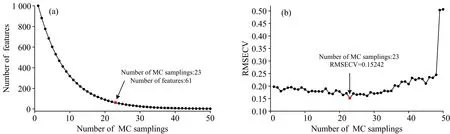
图6 CARS波长筛选过程
将上述三种方法选出的特征波长与四种分类算法两两组合建立基于特征波长的煤与矸石分类模型, 经测试模型表现如表3所示。
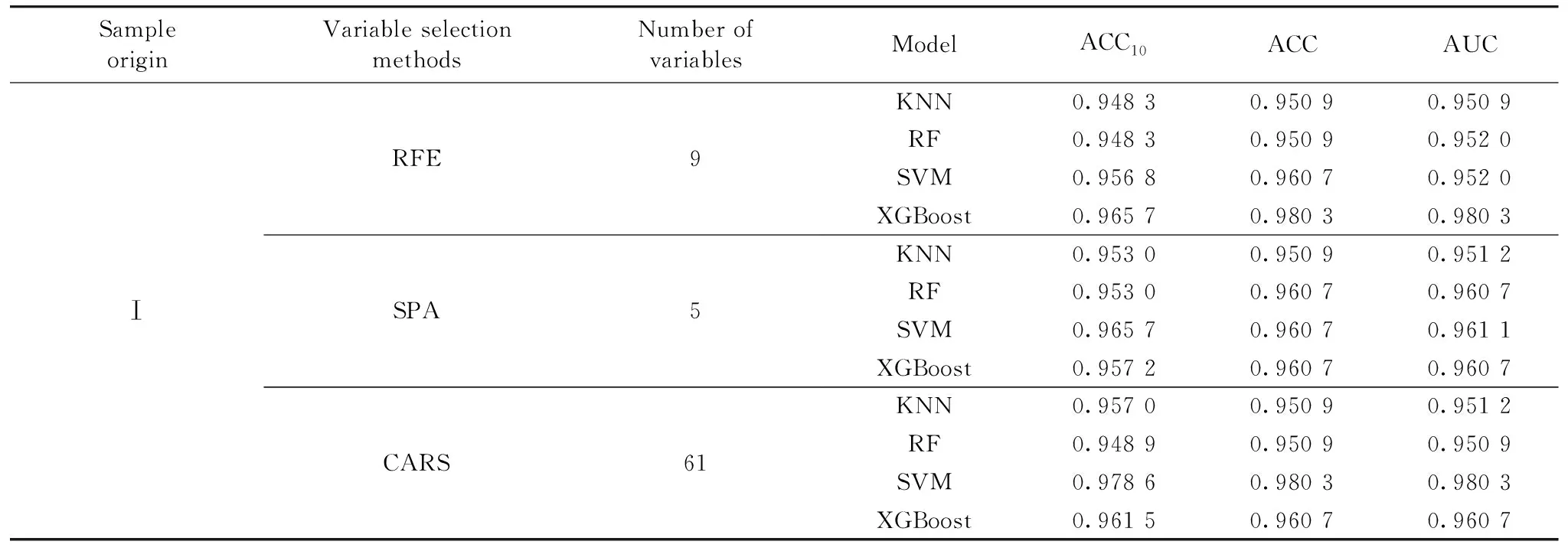
表3 基于特征波长光谱的不同分类模型预测结果
首先对比特征波长与全波段光谱数据建立的模型分类表现, 基于特征波长的分类模型大多提高了模型的稳定性, 并且与测试集下的分类准确度相近, 并有部分模型准确度与AUC值有所提升。 可见上述三种特征选择方法不仅有效地剔除了数据中的冗余信息, 而且保留了关键信息, 在降低数据复杂度的同时, 有利于模型更稳定地分类。
分别对比四种模型用相同特征选择算法的模型分类表现可知, 对RFE算法, XGBoost模型较其他三种算法优势明显; 对SPA算法, XGBoost, RF和SVM分类表现较KNN更好; 对CARS算法, SVM分类效果最优, XGBoost次之。 单从模型表现来看, 表现最好的是CARS-SVM, 其次为仅ACC10上略差的RFE-XGB。 但由于CARS选出的特征波长数量为61, 相比RFE选出的9维特征, 增加了采集、 预处理以及模型训练时的数据复杂度与处理时间, 对于实际应用中要求快速判别的煤与矸石的在线分选, RFE-XGB更合适。 因此以RFE-XGB作为最佳的基于特征波长光谱的分类算法。
3.4 最佳算法的矿区适用性检验
为验证在实验组——西铭煤矿煤与矸石样品全波段和特征波长光谱下选出的表现最好的XGBoost和RFE-XGB算法是否适用于其他矿区, 分别建立基于测试组——神木与巴隆图煤矿煤与矸石样品反射光谱数据的XGBoost和RFE-XGB模型。
RFE的波长数与RMSECV如图7, 神木与巴隆图煤矿的最佳特征波长数分别为3个与7个, 挑选出的特征波长分别为528.12, 534.25, 843.46 nm与706.84, 707.18, 707.51, 709.54, 711.90, 839.98, 851.70 nm。
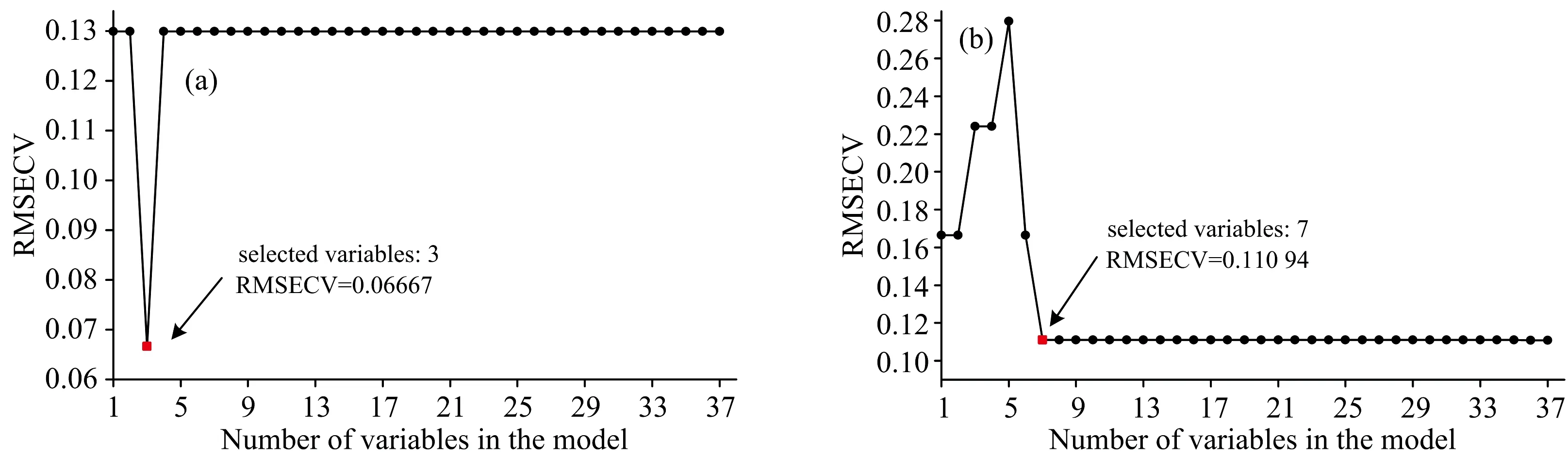
图7 测试组的RFE波长筛选过程
模型表现如表4所示, 对于神木与巴隆图煤矿基于全波段数据建立的XGBoost模型表现同样很好, 准确率分别达到1和0.964 2, AUC值达到1和0.9687, 在测试集中表现出较佳的分类能力, 且ACC10分别达到0.955 0与0.940 4, 模型也具有较好的稳定性。 基于两矿区样品建立RFE-XGB模型较全波段XGBoost模型均显著提高了模型的稳定性, 并且巴隆图煤矿模型的准确率与AUC值有了明显提升, 分类能力更强。 综上所述, XGBoost与RFE-XGB算法适用于其他矿区的煤与矸石样品, 建立的模型与西铭煤矿样品的模型表现一致, 都具有较强的分类能力与稳定性, 并且RFE-XGB模型表现更好。

表4 测试组的模型预测结果
4 结 论
针对同一煤矿黑色背景下不同高度的块状煤与矸石的分类问题, 结合预处理方法——黑白校正、 始末波段去除、 SG卷积平滑与标准正态变量变换, 建立了基于XGBoost算法的煤与矸石可见-近红外光谱分类模型, 得到以下结论:
(1)基于全波段光谱数据的XGBoost模型较KNN, RF和SVM三种常用的分类模型表现更好, 在实验组下ACC10, ACC, AUC分别为0.957 2, 0.970 5和0.971 6, 具有更强的稳定性与分类能力, 可以实现对煤与矸石稳定而准确地分类。
(2)基于特征波长光谱的模型较全波段, 在显著降低特征维度的同时, 提升了模型的性能, 尤其是模型的稳定性。 RFE-XGB模型较其他特征选择方法与分类模型的组合表现最优, 在实验组下的特征维度、 ACC10, ACC, AUC分别为9, 0.965 7, 0.980 3, 0.980 3, 不仅显著降低了数据复杂度, 而且提升了模型性能, 更适合于实际煤矸分选短时高效的要求。
(3)基于神木与巴隆图煤矿煤与矸石建立的XGBoost模型与RFE-XGB模型均与西铭煤矿表现一致, XGBoost模型实现了对煤与矸石较精确的分类, RFE-XGB模型可实现特征降维并提升模型的稳定性。 XGBoost与RFE-XGB算法对于不同煤矿的煤与矸石分类具有良好的适用性, 为基于可见-近红外光谱进行煤和矸石分类提供了参考方法。
