基于CARS-CNN的高光谱柑橘叶片含水率可视化研究
2022-09-05代秋芳廖臣龙宋淑然薛秀云熊诗路
代秋芳, 廖臣龙, 李 震*, 宋淑然, 薛秀云, 熊诗路
1. 华南农业大学电子工程学院(人工智能学院), 广东 广州 510642 2. 国家柑橘产业技术体系机械化研究室, 广东 广州 510642 3. 广东省农情信息监测工程技术研究中心, 广东 广州 510642
引 言
水分是影响柑橘生长发育的主要因素之一。 调亏灌溉(regulated deficit irrigation, RDI)是近年来发展起来的一种新型节水灌溉技术[1]。 RDI的作用是利用作物生长的特定阶段实施水分胁迫来调节光合作用产物在不同器官中的分布情况, 防止其营养过盛并促进其生长。 柑橘叶片是植株水分胁迫的最明显的特征之一, 是光合作用最重要的地方, 叶片含水率会影响叶片的活性, 进而影响果实的生长和产量。 研究表明, 在果实的抽梢开花期和幼果期应用轻度至中度亏水处理可显著提高作物的水分利用率, 然而在柑橘果实膨大期应用亏水处理, 会显著降低柑橘果实的产量。 因此, 检测柑橘叶片的含水率对于柑橘生长和水分利用是非常重要的[2-4]。 传统的作物水分测量方法有烘干法、 蒸馏法等, 虽然精度高, 但是过程繁琐且测量时间长, 对作物具有破坏性。 高光谱成像技术可同时采集样品的空间及光谱信息, 实现对样品的快速无损检测。 Murphy等发现莴苣叶片与NDWI, MSI和IA指数之间具有相关性, 可以用于预测莴苣叶片的含水率[5]。 Zhen利用偏最小二乘法结合特征波段提取的方法预测冬小麦叶片的含水率[6]。
近几年, 卷积神经网络(convolution neural network, CNN)由于具有权值共享和自动提取特征等优点, 被广泛应用于生物学、 食品学、 医学等多个领域[7-9]。 钟亮利用不同的卷积神经网络模型预测土壤有机质, 结果表明卷积神经网络在土壤高光谱样本建模中具备可行性[10]。 Jie结合卷积神经网络测定柚子果实颗粒化, 结果表明卷积神经网络模型可以有效提高分类的准确性[11]。
本工作结合高光谱与卷积神经网络, 研究柑橘叶片的含水率。 首先利用烘干法测出柑橘叶片的含水率作为实际含水率, 然后结合不同的预处理和特征波段选择的方法, 将数据导入不同的检测模型中, 得到最佳的预测模型。 最后, 将叶片所有像素导入到最佳的预测模型中, 得到每个像素的含水率预测值, 应用伪彩色处理实现柑橘叶片的含水率分布的可视化。
1 实验部分
1.1 柑橘叶片样本和样本含水率测定
2021年5月, 在华南农业大学工程学院六楼天台, 在柑橘水分管理的关键时期随机均匀地摘取100片柑橘叶片; 为了提高研究的泛化性和得到更多的不同含水率的叶片, 摘取不同大小、 营养状况和颜色的叶片, 并立即将样品带回工程学院302实验室。 使用电子天平测量每个叶片的质量记为G1, 随后拍摄高光谱图像, 然后使用恒温鼓风干燥箱在50 ℃下烘干叶片, 50 min后取出放入装有干燥剂的密闭玻璃缸内冷却至室温, 取出称其质量记为G2, 再次拍摄高光谱图像, 重复测量5次, 每次烘干的温度和时间均为50 ℃和50 min, 得到质量为G2,G3,G4和G5的叶片, 最后再将叶片放入85 ℃的干燥箱内烘干至恒重, 恒重叶片记为G0。 柑橘叶片的含水率计算公式如式(1)所示。
(1)
式(1)中,Mn为第n次测量的叶片含水率;Gn为第n次测量的质量(g); n的取值为1~5;G0为叶片干重(g)。 对采集的叶片烘干4次, 一共获得了鲜叶和烘干叶片500个样本。 样本的含水率分布统计如表1所示, 含水率在19.59%~83.05%之间, 平均值为62.22%, 方差为0.93%。

表1 柑橘叶片的含水率分布统计(%)
1.2 高光谱数据采集
所有的样本均使用实验室的高光谱成像仪(HyperSIS Zolix, China)拍摄扫描, 该仪器主要由4个卤光灯、 CCD相机(Gilden Photonics Ltd, UK)、 样品移动台、 计算机等组成。 成像仪的光谱波长范围为369~988 nm, CCD相机曝光时间设置为8.96 ms, 平台移动速度为0.8 cm·s-1, 光谱分辨率为1.2 nm。 高光谱成像仪控制及图像校正软件为SpectraVIEW。 后续数据处理采用ENVI5.3软件, Anaconda中的Spyder, 版本为Python3.6。
为了减少光照和探测器灵敏度对原始高光谱图像的影响, 在与柑橘叶片图像采集相同的实验条件下, 通过拍摄白色校正图像和黑色校正图像对原始图像进行黑白校正。 最终校正图像由式(2)所示。
(2)
式(2)中,R为校正后的高光谱图像,I为原始高光谱图像,W为白色校正图像,B为黑色校正图像。 使用ENⅥ5.3软件提取整个柑橘叶片作为感兴趣区域, 得到叶片的平均反射率值, 一共500个样本×256个波段, 数据用于后续数据分析和建模。
不同含水率叶片的光谱曲线如图1所示。 图1(a)中为同一叶片在四次烘干后的不同含水率的光谱反射率, 在其他条件不变的情况, 每次烘干叶片的含水率逐次减少, 含水率与光谱曲线成负相关变化趋势, 这与前人研究的结果相一致; 图1(b)为不同叶片的含水率的光谱反射率, 其中三个不同叶片的含水率均为70%, 但是光谱反射率却不尽相同, 由于叶片的大小、 颜色、 营养状况等因素均会影响叶片的光谱反射率, 因此不同叶片的含水率与光谱反射率并非呈简单的线性相关趋势。
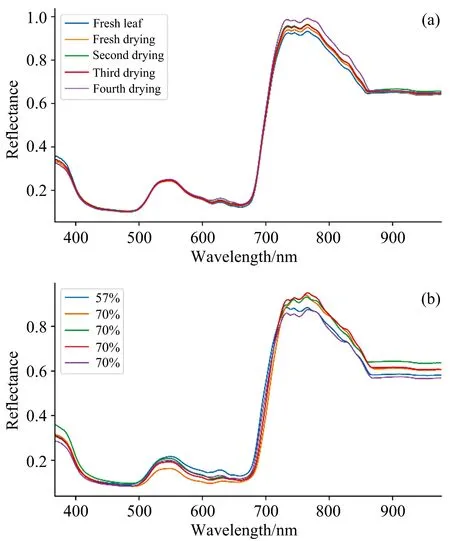
图1 不同含水率叶片的光谱曲线
2 结果与讨论
2.1 光谱预处理
数据包括原始光谱数据和卷积平滑(savitzky golay, SG)、 多元散射校正(multiplicative scatter correction, MSC)、 标准正态变量变换(standard normalized variate, SNV)3种预处理后的光谱数据。 不同预处理后的光谱曲线如图2所示。
2.2 特征波段的选择
2.2.1 CARS筛选特征波长
竞争性自适应重加权(competitive adaptive reweighted sampling, CARS)是基于蒙特卡罗采样和偏最小二乘回归(partial least squares regression, PLSR)模型中回归系数的一种特征波长选择方法[12-13], 旨在筛选最具有竞争力的波数组合。 CARS算法通过自适应加权采样计算回归系数中绝对值权重, 去掉权值较小的点, 权值较大的点会作为新的子集, 然后基于新的子集建立PLSR模型, 选取交互验证均方根误差(root mean square error of cross validation, RMSECV)最小的PLSR模型所对应的波长作为特征波长。 结果如图3所示, 最终最佳迭代次数为23次, 此时的RMSECV值最小, 得到493, 498, 508, 522, 589, 592, 601, 627, 635, 658, 678, 685, 736, 752, 788, 790, 826, 835, 845, 862, 874, 888, 914, 917, 938, 943, 962, 967和969 nm共29个特征波段。
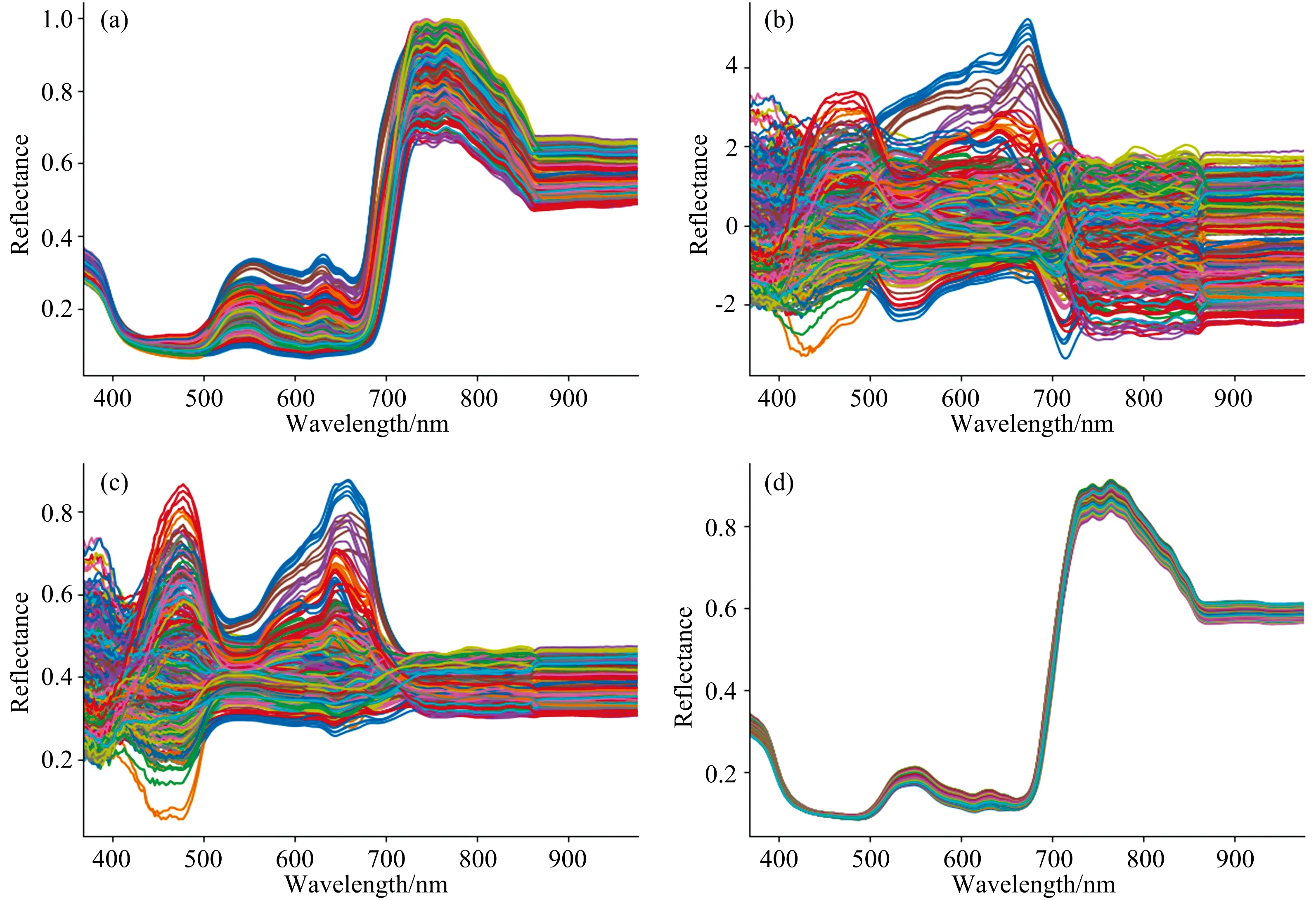
图2 不同预处理后的光谱曲线

图3 CARS筛选特征波段
2.2.2 PCA提取特征波长
主成分分析(principle component analysis, PCA), PCA是将多个变量通过线性变换转换为相互正交、 信息不重叠的新变量[14], PCA概念简单、 运算简洁, 能够在保留有效信息的同时解决变量之间的多重共线性问题, 在高光谱数据降维、 特征提取、 消除噪声、 去相关性等方面得到广泛应用。 采用PCA算法对全部样本的高光谱数据进行降维, 前10个主成分(principle component, PC)累积贡献率达到99.83%, 因此选择前10个主成分。
2.3 模型
2.3.1 卷积神经网络
卷积神经网络是深度学习的典型模型之一, 具有卷积计算和深度结构的前馈神经网络, 基本结构由输入层、 卷积层、 激活层、 池化层和全连接层组成。 卷积层能够自动提取光谱样本的特征波段, 卷积之后通常会加入偏置, 并引入非线性激活函数, 经过激活函数激活后, 得到结果, 如式(3)所示
(3)
2.3.2 模型建立
卷积神经网络模型的参数如表2所示, 模型一共采用三个卷积池化层, 卷积核的大小均设置为1×3, 步长为1, 卷积核个数分别为16, 32和64个, 对于经过特征波段选择的光谱数据, 最大池化层设置为1×1, 步长为1, 而全波段数据导入模型, 为了减少数据维度、 提取有效特征, 最大池化层设置为1×2, 步长为1。 在每个卷积层设置一个线性整流(rectified linear unit, RELU)激活函数, 数据输入后, 经过三层卷积池化, 再将数据展开, 将得到的一维数据输入到全连接层, 全连接层有两个隐藏层, 隐含层1的神经元个数为32个, 激活函数设置为RELU函数, 隐含层2的神经元个数为1个, 激活函数设置为linear, 用于回归预测。 模型训练使用均方误差(mean squared error, mse)作为损失函数, 采用nadam算法对模型进行优化更新, epoch设置为1 000轮, batch size设置为10。 整个网络模型的基本架构如图4所示。
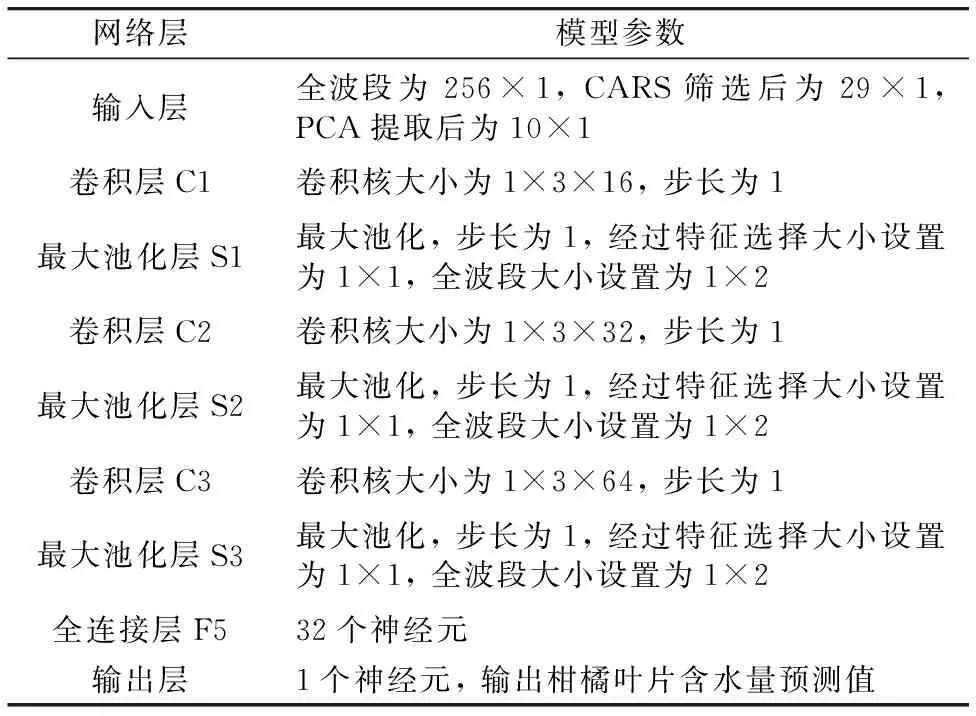
表2 CNN模型参数设置
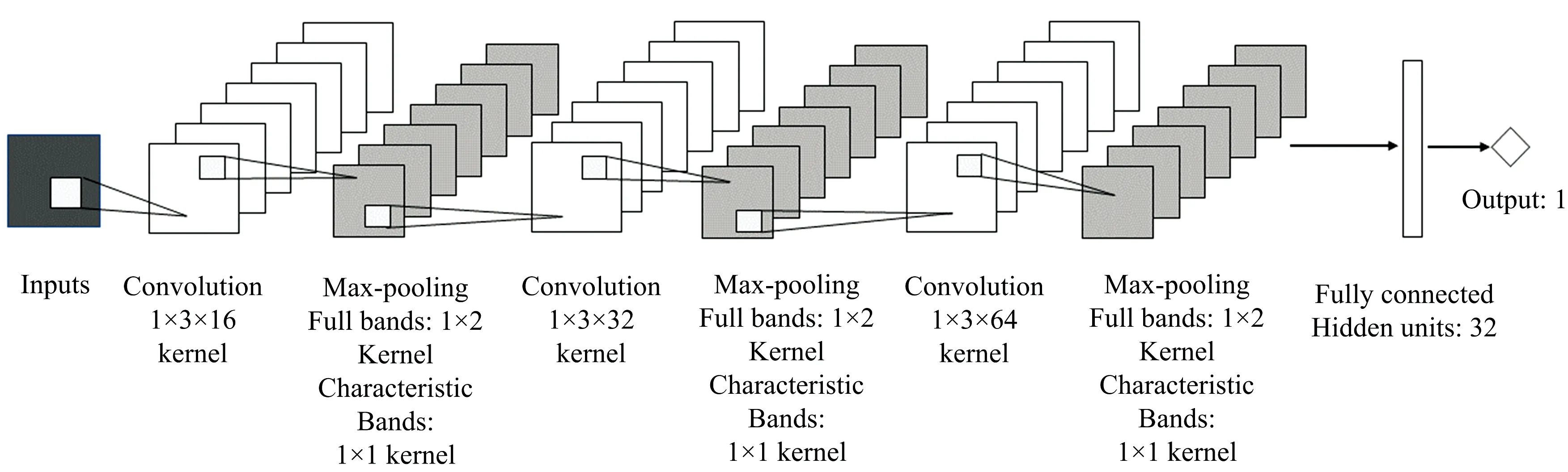
图4 CNN模型结构图
将500个样本按7∶3的比例划分成训练集和测试集。 350个样本被选为训练集, 150个样本被选为测试集, 模型使用决定系数(coefficient of determination,R2)和均方根误差(root mean square error, RMSE)来评估,R2越大、 RMSE越小, 则模型的预测效果越好。 将原始数据和不同预处理后的光谱数据经过不同特征波段选择后导入到CNN模型中, 结果如表3所示。
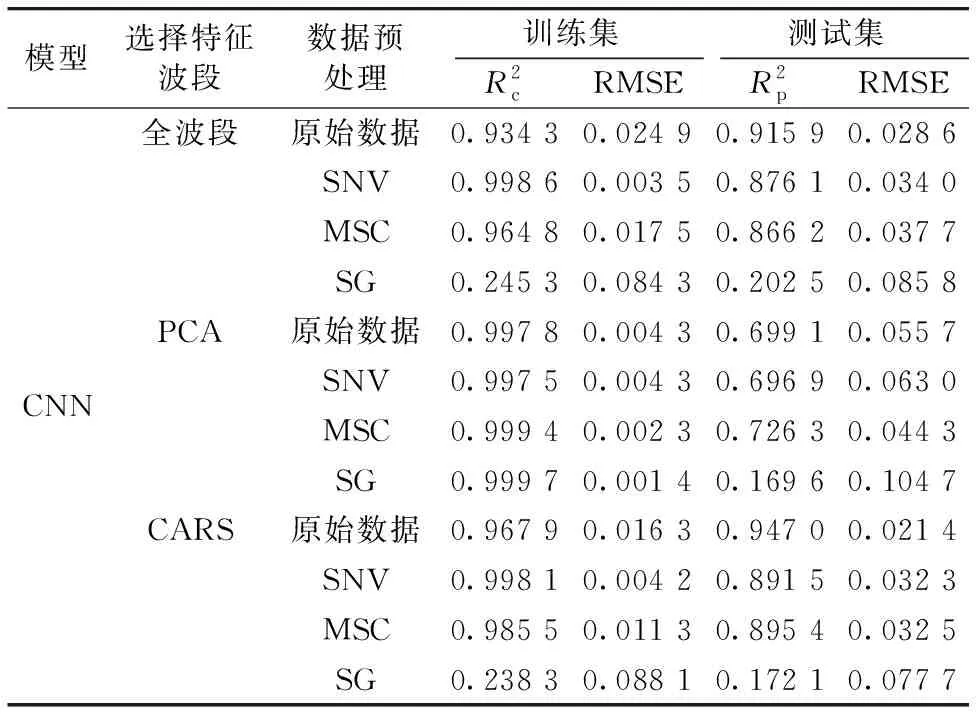
表3 不同模型预测结果
2.3.3 不同模型比较
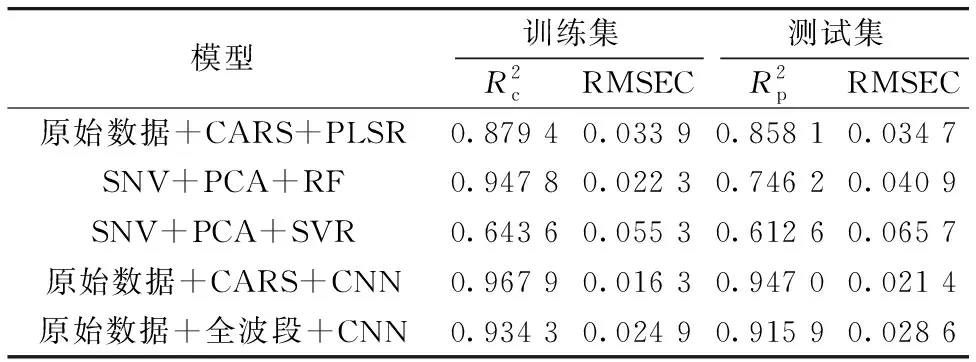
表4 不同模型的预测效果对比
图5分别为不同模型的训练集和测试集中的预测值和实际测量值的三点拟合图, 其中蓝色的点代表训练集, 红色的点代表测试集, 由图可以明显观察到CARS-CNN模型的拟合效果最佳, 优于其他三个模型。 而其他的三个模型均有明显的离散数据, SNV+PCA+SVR最差, SVR模型整体预测的误差相对较大, 因此出现明显的偏移现象。
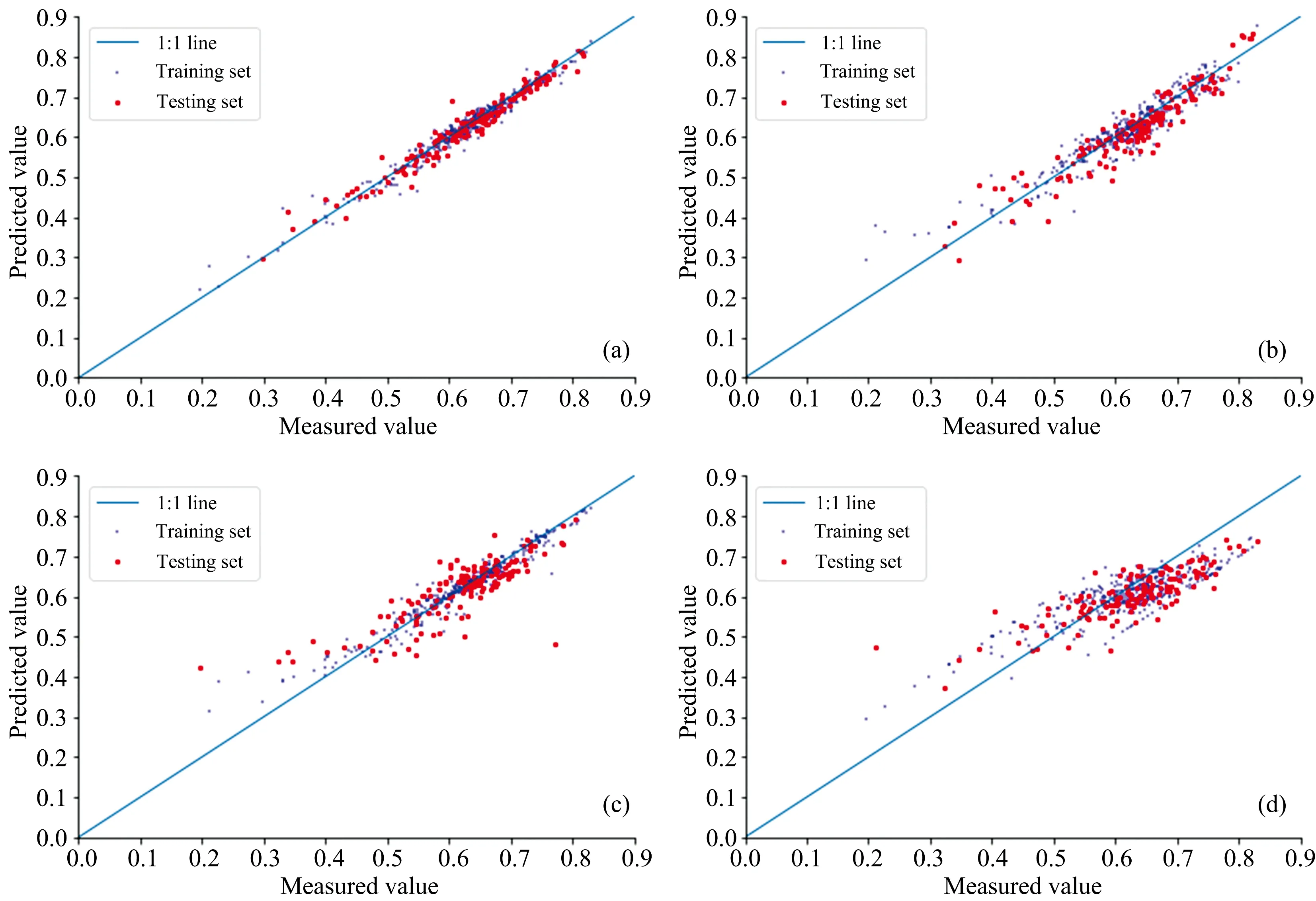
图5 不同模型回归曲线图
2.4 柑橘叶片含水率可视化
每个叶片样本仅使用对应感兴趣区域提取的平均光谱表示, 然而高光谱图像中存在丰富的空间分布信息未被充分研究。 因此本研究中利用最佳模型CARS-CNN预测高光谱图像中各个像素点的含水率, 以实现其分布可视化。 首先通过ENVI5.3软件去除叶片的背景, 将提取叶片的光谱反射率值导入到训练好的CARS-CNN模型中, 得到每个像素的含水率预测值, 转换为灰度图, 再应用伪彩色技术将灰度图转为伪彩色图。 柑橘叶片的不同含水率分布图如图6所示。

图6 不同含水率分布图
图6从左到右的含水率分别为81%, 63%, 42%和19%。 从图中可以看到, 含水率越高, 叶片图像素越接近红色, 含水率越低, 叶片图像素越接近蓝色。 柑橘叶片水分分布图的可视化为每个像素的水分含量提供了更直观、 更全面的评估, 并提供了一种评估植物灌溉策略优劣的新方法。
3 结 论
(2)同时对比了不同预处理和特征波长提取选择的PLSR, RF和SVR模型组合的最佳结果, 将最佳组合模型(原始光谱数据+CARS+PLSR, NV+PCA+RF, SNV+PCA+SVR)与原始光谱数据的CARS-CNN对比, 结果依然是CARS-CNN模型预测效果最佳;
(3)使用训练好的CNN模型计算叶片每个像素点的含水率, 得到81%, 63%, 42%和19%不同梯度的含水率伪彩色图, 为检测和评估柑橘生长和叶片含水率提供了一种全新的方法。
(4)在其他条件不变的情况下, 同一叶片的含水率与光谱反射率呈负相关趋势, 而在自然条件下, 由于叶片的光谱反射率受叶片的大小、 颜色、 营养状况、 种类等多种因素的影响, 叶片的含水率与其他因素会共同影响叶片的光谱反射率, 因此叶片的含水率与光谱反射率并非呈简单的线性关系, 具体的因素仍需进一步研究。
