基于引用-作者联合传播的学术影响力度量
2022-09-05李思莹沈华伟徐冰冰程学旗
李思莹,沈华伟,徐冰冰,程学旗
(1. 中国科学院 计算技术研究所 网络数据科学与技术重点实验室,北京 100190;2. 中国科学院大学 计算机科学与技术学院,北京 100049)
0 引言
一直以来,科研人员的学术成就和影响力度量都是一个富有挑战性的问题,涉及到的应用领域十分广泛[1]。一名科研人员的学术影响力主要是通过发表学术论文等方式提出新的专业理论、实践方法与技术,或者对原有成果的发展、修正、革新和完善,从而对相关领域的理论和实践产生影响[2]。传统学术影响力评价是由领域内的专家根据科研人员的简历做出一些定性或定量的评价,但这种方式更适用于一些特定场景的小规模评价,如奖项评选和项目基金申请[3]等。随着科研人员数量和科研产出的爆炸式增长,对大规模科研人员的累积影响力进行评价和比较成为了科学计量领域备受关注的问题。尤其是在相关资源有限的情况下, 学术影响力度量也是国家进行科研资源分配和政策制定的重要依据之一。
近年来,科研人员学术影响力的量化评价指标被相继提出,很多工作对比和总结了这些量化指标[4-7]。现有量化指标多是基于科研人员的科研产出,即发表论文数量和论文引用数量来定义量化指数并进行评价。目前广泛使用的量化指数有以下三类: 一是更关注科研人员生产力的发表论文数;二是更关注发表论文水平的论文总引用数[8]和影响因子[9];三是将二者结合的指数,如h-指数[10]、g-指数[11]等。上述指数类学术影响力评价有明确的物理意义、优秀的泛化能力和便捷的获取渠道,使得这类方法成为了目前最主流的学术评价方法。在现在广泛使用的学术网站 (如谷歌学术(1)https://scholar.google.com/和Web of Science(2)https://apps.webofknowledge.com/) 上,这些指数都会在检索页面上直接显示出来。但上述方法将作者和论文看做是独立的个体,而忽略了所有的科研实体都具有互相关联和影响的天然属性。实际上,一个科研人员的学术影响力是整个领域内的科研群体对他的肯定和认可程度,而不是仅由个人的学术产出单独决定[12]。
为了建模学术影响力来自于科研群体的天然属性,图上的排序算法(如PageRank算法)被引入到学术网络中,来模拟学术影响力在整个学术网络的传播过程。现有对科研人员的排序方式主要为以下两类: 一是作者粒度的方法,这类方法首先构建作者引用网络,在作者引用网络上用图排序算法直接进行影响力传播[13-14]。但是作者粒度的方法无法区分引用发生的时间,作者从发表时间靠前的论文中累积到的学术影响力会错误地传播给后续引用的论文作者,引起影响力的错误分配;二是论文粒度的方法[15-17],不直接对作者的影响力进行传播,而是先在论文引用网络上对论文的影响力进行传播,再将论文的学术影响力以一定的规则[18-20]分配给论文的作者。
上述指数类评价方法和基于传播的排序评价方法,主要使用了论文之间的引用关系作为传播载体来评价科研人员的学术影响力。这隐含的假设是,当读者阅读论文时,可能会通过查阅参考文献列表来寻找与该论文相关的著作,进而使一篇论文的影响力以引用关系为载体传播给其引用的论文,但这种传播方式过于单一。随着时代的进步与发展,信息获取的方式越来越便捷,读者可以通过直接访问学术服务网站和学术大数据平台(如Arnetminer(3)https://www.aminer.cn/[21]、谷歌学术和微软学术搜索(4)https://academic.research.microsoft.com/)来获取科研人员信息,使读者可以通过点击论文作者的主页来查阅该作者发表的其他论文。这种通过论文作者来检索文献的学术行为,使科研人员自身成为了学术影响力传播的一种重要载体,然而现有方法并没有研究和建模这种传播途径在学术影响力评价中的作用。
本文提出一种基于影响力联合传播的科研人员学术影响力度量新方法,该方法同时建模了论文引用和科研人员自身在影响力传播中的作用。具体来说,学术影响力不仅可以通过引用从施引论文向被引论文传播,也可以在同作者的论文之间互相传播。该方法更加符合当下日常检索文献时的学术行为,削弱了通过引用信息只能进行影响力前向传播带来的不合理评价,丰富了影响力的传播方式。此外,以科研人员为载体的传播,使学术影响力可以通过学术合作在科研人员之间传播,将学术界普遍存在的学术合作行为引入到影响力评价当中。本文将详细介绍科研人员学术影响力评价的相关工作,剖析了只通过引用传播影响力带来的弊端,指出了影响力通过引用和作者信息联合传播的必要性,并提出基于“引用-作者”联合传播的学术影响力度量方法。通过在真实的数据集上对传播过程的细致分析,深入对比了引用传播和“引用-作者”联合传播之间的联系与不同。
1 相关工作
本节主要介绍科研人员学术影响力的两类评价方式,分别是指数类评价和学术网络上的排序类评价。
1.1 指数类评价
指数类评价方式是基于一个科研工作者的科研产出,定义一种量化的评价指标,用该指标的值代表科研人员的学术影响力。
经典的指数类评价方式有:
(1)科研人员的发表论文总数: 该指数代表一个科研人员的科研产出能力, 但是其无法量化科研产出的质量、重要性和影响力。
(2)发表论文所在期刊的影响因子[9]: 该指数代表一名科研人员学术产出的质量,但由于同一期刊的论文质量并不相同, 因此论文所在期刊的影响因子并不能真正代表某篇特定论文的质量和影响力。
(3)发表论文的总引用量[8]: 该指数代表一个科研人员累积的影响力,但是当一名科研人员有一篇论文引用量很高时,总引用量就会被这篇论文支配。尤其是当这个科研人员在这篇高引用量论文中并没有做出核心贡献时,由总引用量带来的评价不合理问题更加严重。
(4)h-指数[10]及其衍生指数: 如果一个研究人员的h-指数为h,则代表他发表的论文中有h篇论文每篇被引用不少于h次,且其他的论文每篇被引用不多于h次。h-指数第一次将科研人员的生产力(即发表论文数)和影响力(即论文的引用量)融合到同一个统计量中来评价一名科研人员,因此得到了广泛认可和使用。但是,h-指数对部分高引用量的论文和大量低引用量的论文不敏感,大量h-指数的衍生指数近年来被相继提出来改进上述缺点,例如,g-指数[11]、多重h-指数[22]和hg-指数[23]等。
本文作者也对指数类评价进行了探索,发现h-指数的缺点本质上来自于直接比较科研人员的生产力和影响力,提出了生产力和影响力统一尺度的hu-指数[24],带来了更好的跨领域学术评价效果。
1.2 排序类评价
排序类评价方式是通过构造学术网络[25],引入排序算法来模拟学术影响力在全局范围内的传播过程。
一类方法通过将论文的引用关系投影到作者粒度,构建作者引用网络,如图1所示,在此网络上模拟影响力传播,如SARA算法[13]和RLPR算法[14],直接在该网络上使用PageRank算法[26],对作者排序;LeaderRank算法[27]通过引入一个与所有作者都相连的接地节点,使排序对噪声和操纵行为更加鲁棒。
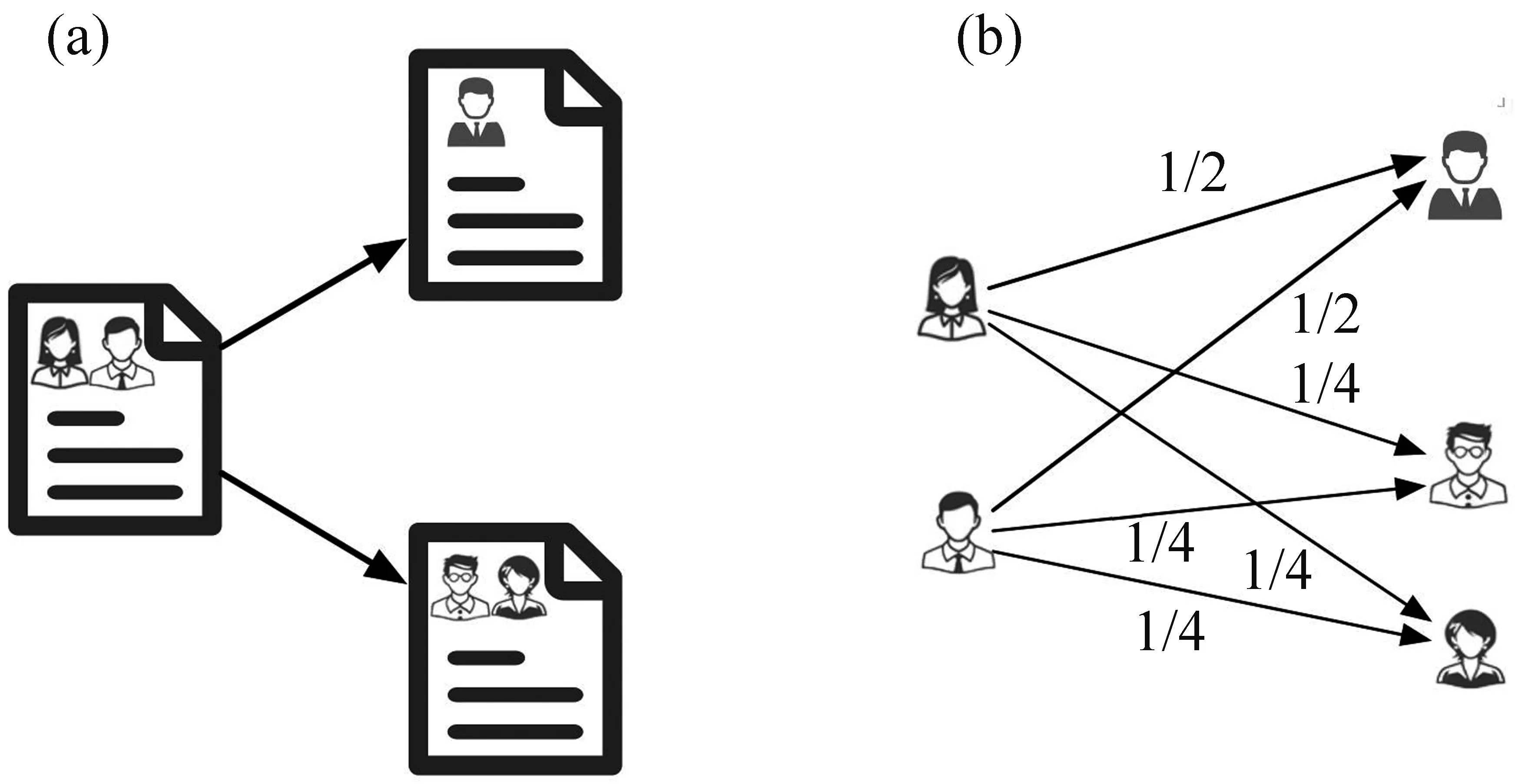
图1 影响力传播的两类典型网络
另一类方法是直接模拟影响力在论文引用网络上的传播,认为科研人员的影响力是他发表的每一篇论文影响力的加权累积。有些方法不区分论文之间的引用权重[15-17],有些方法通过引入论文发表时间[28]建模论文创新性的时间衰减因素,还有一些方法关注到了传播的非线性特征,如NonlinearRank[29]和SPRank[30]等。
但这些方法都只使用了论文之间的引用信息作为学术影响力传播的载体,忽略了以其他信息为载体的学术影响力传播行为。
2 方法
本节介绍了学术网络上只以论文引用做载体的学术影响力传播方法,并通过真实数据分析了这类传播带来的问题。接下来我们提出了影响力也可以通过科研人员自身为载体传播的假设,联合建模了基于引用信息和基于作者信息的传播,并详细定义了“引用-作者”联合传播的方法。
2.1 基于引用的影响力传播
基于引用的传播方法主要分为以下两种模式: 作者粒度的直接传播方法和论文粒度的先传播后分配方法。
2.1.1 作者粒度的方法
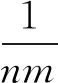
在这个加权的作者引用网络上,我们用排序算法来模拟影响力从一个作者传向他引用的作者的过程,并用于最终学术影响力的计算。作者粒度的经典排序算法有SARA算法[13]和PLPR算法[14],他们的传播过程如式(1)所示。
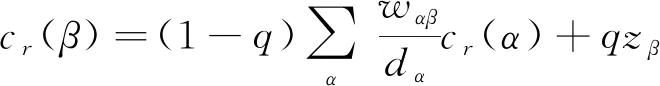
(1)
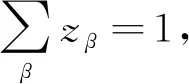
2.1.2 论文粒度的方法
论文粒度的方法是一种两阶段的方法[15],先在论文引用网络上进行影响力传播,再将论文的影响力分配给该论文的所有作者。
论文粒度的方法首先构建一个论文引用网络,该网络的邻接矩阵用C表示,网络中的每个节点是一篇论文,连边代表论文之间有引用关系,且每条连边权重相同,即如果论文i引用了论文j,则Cij=1,反之Cij=0。接下来,第一步将PageRank算法应用在论文引用网络上,如式(2)所示。
(2)
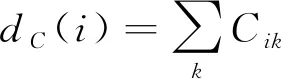
第二步,影响力从每一篇论文分配给他的所有作者,我们用f(β,j)表示作者β可以从他的论文j中分配到的影响力份额。在这里我们假设论文j的所有作者共享这篇论文的影响力,即∑βf(β,j)=1。
通过论文粒度的影响力传播,一个科研人员β的学术影响力最终表示成他从他发表的所有论文中分配到的累积影响力,记为
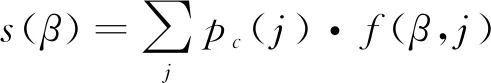
(3)
Wang在2016年发表的文章中仔细比较了作者粒度和论文粒度的传播方法[31],发现作者粒度的方法容易出现以下两种学术影响力的错误传播。一是由于不区分论文发表时间带来的错误传播,如图2的左半部分所示,作者α通过论文1累积到的影响力通过论文3到论文2的引用传给了作者β,模型应该尽可能避免这种传播。这种错误传播的根本原因是作者粒度的方法没有区分作者的影响力的来源。二是作者之间的影响力传播权重的错误计算引起的错误分配,如图2的右半部分所示。作者之间的传播权重由他们发表论文的共同作者数决定,而不是由施引论文的重要性决定,这就导致作者α通过学术影响力更高的论文3只能传递1/6的影响力给作者β,却可以通过影响力很低的论文4传递1/4的影响力给作者β。
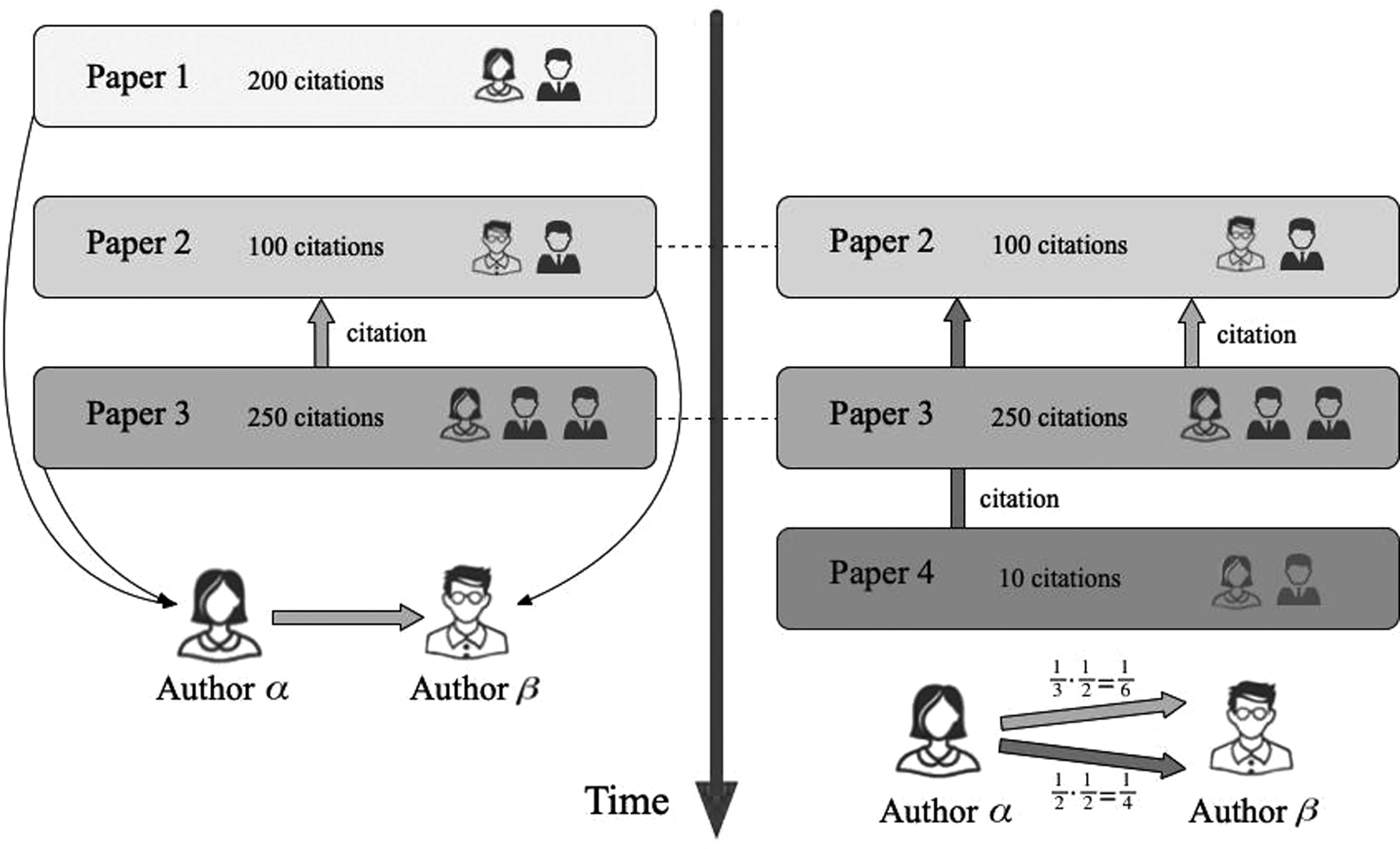
图2 作者粒度方法带来的学术影响力错误传播
这种错误传播的根本原因是作者引用网络的不合理构建。论文粒度的方法通过将论文的影响力传播和论文到作者的影响力分配拆分成两个独立的过程,避免了作者粒度的方法带来的错误分配问题。同时,无论是论文之间影响力传播还是作者的影响力分配的最新进展[18-19],都可以分别直接应用到论文粒度的方法当中进行优化。
2.2 引用和作者联合的影响力传播
虽然论文粒度的方法部分解决了作者粒度的方法存在的错误传播问题,但由于论文引用网络是一个有向无环图,影响力只能单向传播,引发了新的问题。更严重的是上述方法都只考虑到了以引用为载体的影响力传播,忽略了学术影响力传播的其他方式(如作者作为载体带来的影响力传播)。接下来,我们通过分析只使用论文引用网络带来的不合理现象,提出加入新的传播方式的必要性。
2.2.1 数据分析
由于PageRank算法的机制是被重要节点连接的节点更加重要,所以当论文网络中只存在引用带来的连边时,影响力就会通过引用传递给更早发表的论文。如图3所示,我们统计了发表在美国物理学会(American Physical Society, APS) 旗下的所有同年发表论文的平均PageRank分数随时间的变化趋势。我们发现仅APS创刊初期和两次世界大战时期,PageRank会倾向于给发表时间更靠前的论文更高的分数,因此上述论文粒度的方法会更倾向于给资深科研人员更高的影响力[32]。
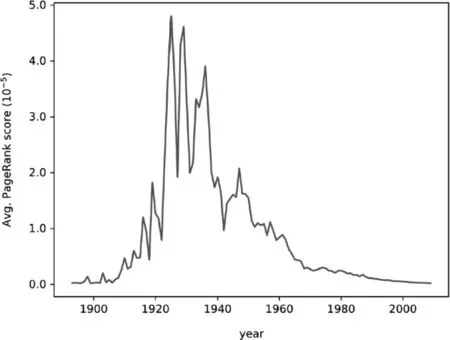
图3 同年发表的论文的平均PageRank分数随时间的变化统计图
此外,我们还发现不同论文的PageRank分数差异巨大,远远超过论文总引用量之间的差异。将每篇论文的PageRank分数和总引用量通过最大最小值进行(0,1)归一化,由于二者的概率密度函数P(x)会出现很多波动,我们在这里统计累积分布情况,即PageRank分数(或引用量)不少于x的科研人员所占比例,如式(4)所示。

(4)
如图4所示,我们发现PageRank分数的分布广度比引用量的分布广度高了将近3个数量级,这说明用PageRank算法对论文进行评价会进一步扩大不同论文之间的影响力差异。这就会导致论文粒度的方法会让某一篇PageRank分数显著较高的论文主导这个科研人员的排名,而忽略科研人员其他论文和发表论文总数在评价科研人员时的作用。尤其当这篇具有高PageRank分数的论文并不具有公认的高影响力时,会造成更加严重的学术影响力评价偏差,这种情况将会在第3节给出详细的分析和案例。

图4 归一化的论文引用数和PageRank分数的累积分布
2.2.2 引用-作者联合传播模型
只使用引用信息在论文粒度的网络上进行影响力传播带来了不合理的影响力度量,因此我们需要探索学术影响力传播是否存在其他方式。
受到科研人员查阅领域相关论文过程的启发,当我们阅读一篇论文时,我们不仅可以通过查阅这篇论文的参考文献查看相关的工作,也会通过点击该作者的主页信息获得作者的论文列表,从中选择相关文献。并且随着论文存档逐渐电子化,我们可以非常容易地在学术网站上通过点击一篇论文的作者找到他发表的所有论文。上述学术行为带来一种论文引用关系之外的影响力传播方式,即以科研人员本身为载体的影响力传播,这使得拥有相同作者的论文之间也会传播学术影响力。
受前述现象启发,我们在论文引用网络上增加一些通过作者信息建立的连边,构建一个“引用-作者”联合传播的论文网络。在图5(a)中,只考虑引用带来的连边,示例网络中就会存在一篇与其他论文都无法建立联系的孤立论文。引入作者信息连边后,拥有相同作者的论文就会被连接起来,如图5(b)所示,这就使得原本没有引用关系的论文也可以接受和向外传播影响力,这将极大地丰富论文网络中的影响力传播过程。
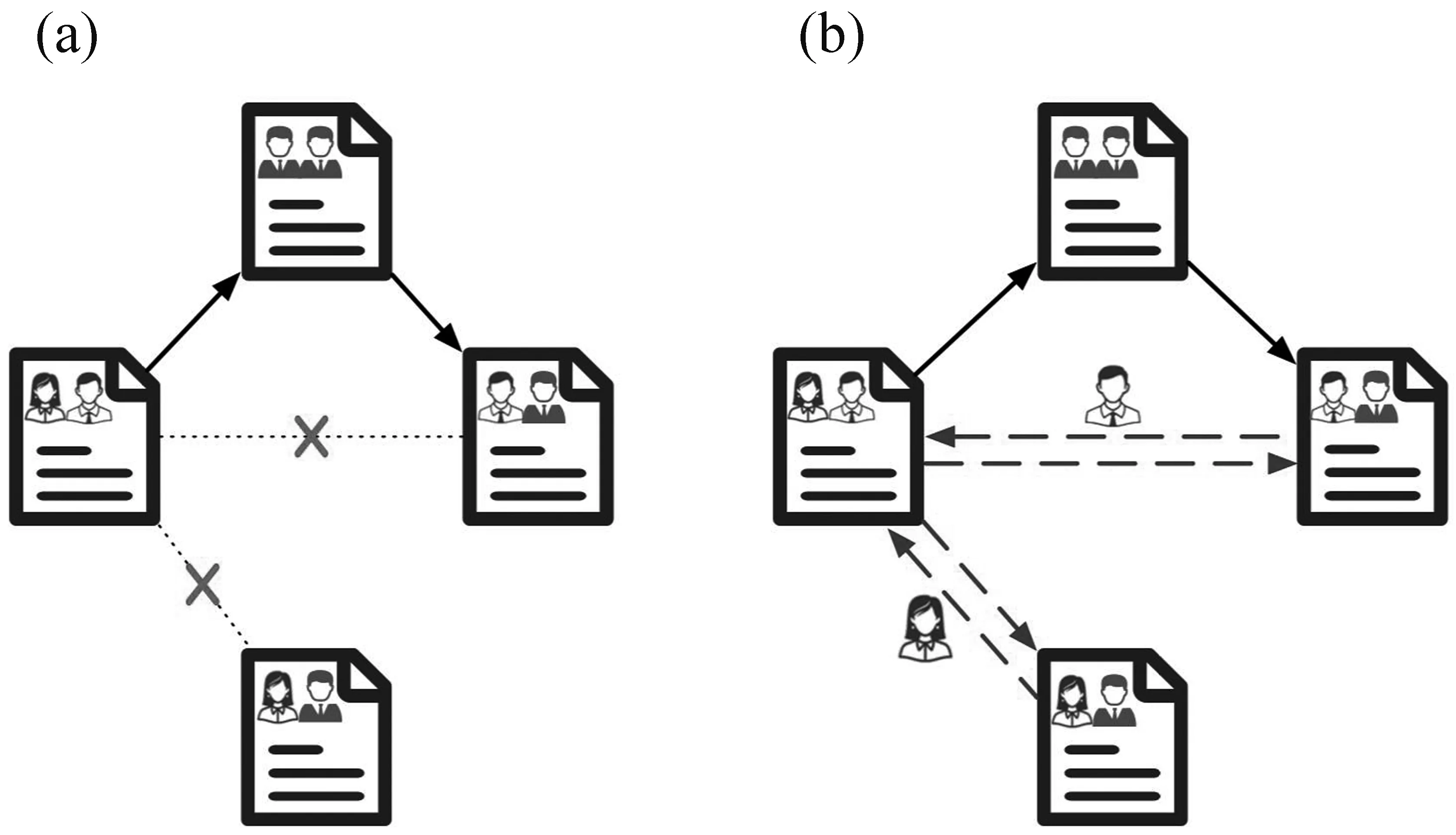
图5 论文引用网络引入作者信息后的变化示例
具体地,我们沿用两阶段的论文粒度的排序方法,提出一个先通过引用和作者信息两种类型的连边联合传播论文影响力,再将论文影响力分配给作者的方法。类似于论文的引用关系矩阵C,我们定义一个论文的作者关系矩阵A,矩阵中的每个元素Aij表示论文i与论文j的相同作者数,如果没有相同的作者,则Aij=0。基于此,论文影响力沿引用关系和作者关系联合传播的影响力可以建模为:
(5)
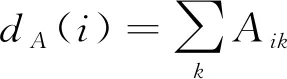
这种学术影响力的联合传播模式也是对我们日常学术检索过程的一个模拟: 当我们阅读一篇感兴趣的学术论文时,我们会以概率q1查看他的参考文献列表,以概率q2查看作者发表的其他论文,以较小的概率q3在所有论文中随机查看一篇。
在通过论文网络上的联合传播得到论文的影响力分数之后,我们用f(β,j)表示作者β从他发表的论文j中分配到的影响力份额。一名科研人员的学术影响力表示为他从他每篇论文中获得的影响力的加权和,即
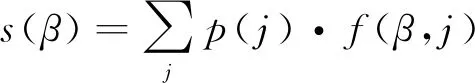
(6)
目前,科学计量领域已有一些工作对多作者论文中作者的功劳分配问题做过探索[18-20],设计了精巧的分配方式。但功劳分配并不是本文的重点研究对象。因此,在本文中,我们使用最简单的平均分配方式进行多作者论文的功劳分配,即在一篇nj个作者合著的论文j中,每个作者分配到的功劳相同,即
(7)
3 实验
本节通过实验来对比传统的只通过论文引用作为载体传播影响力的方法(记为引用传播方法)和我们提出的“引用-作者”联合传播的方法(记为联合传播方法)。我们使用美国物理学会(American Physical Society, APS) 收录的发表在1893年到2009年之间的463 348篇论文和248 512个作者作为实验数据,对两种方法进行详细的对比分析。
3.1 排序差异分析
为了更全面地比较使用不同载体的传播方法对学术影响力度量的差异,我们选择两种评价指标来比较不同方法对作者排序所得序列的影响。直观来说,我们可以用两个序列中排在前k位的共同作者数来刻画序列的差异,但是这种评价方式对名次不敏感。因此,我们进一步定义一个基于排序差异的更细粒度的评价指标比较两种方法得到的排序序列的差异。假定两种传播方法得到的作者排序序列分别为r和r′,对某一作者α的排序差异定义如式(8)所示。
rank_diff(r,r′,α)=|rank(r,α)-rank(r′,α)|
(8)
其中,rank(r,α)是作者α在排序r中的排名。
对两个排序而言,排序差异被定义为排名在前k名的作者在两个排序上的平均差异如式(9)所示。
(9)
其中,S(r,k)是在序列r中排名在前k名的作者集合。
在我们提出的联合传播方法中,式(5)中的参数q3控制影响力的全局重新分配概率。为了更加清晰地比较只通过引用的传播方法和本文提出的联合传播方法的区别,我们首先将全局重新分配的概率设为0,即q3=0。式(5)中的q1和q2分别控制通过引用关系和通过作者关系传播的概率,且q1+q2+q3=1。特别地,当q2=0时,我们的方法等同于只使用引用信息做载体进行影响力传播;当q2=1时,等同于只使用科研人员本身做载体进行影响力传播。
接下来,我们分别选取了不同作者传播概率,对科研人员的学术影响力进行排序评价,得到了不同的作者序列。我们选取每个作者序列中排在前1 000名的作者序列,并对这些序列进行比较。如图6所示,随着作者传播概率的增大,引用传播方法和联合传播方法的差异越来越大,这说明引入不同的传播方法对改变科研人员的排序序列有明显的影响。当只使用由作者关系带来的连边进行影响力传播时,即q2=1时,作者的排序较引用传播方法产生一个巨变。
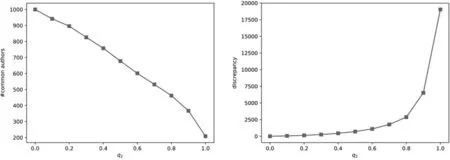
图6 作者连边概率对排序差异的影响
3.2 统计差异分析
为了更进一步地挖掘引入作者信息连边带来的变化,我们改变作者传播概率q2的取值,得到科研人员排序序列的前1 000名科研人员,并对他们的统计信息进行比较和分析。
我们首先定义一名科研人员的“科研年龄”,它是科研人员发表第一篇文章的时间与2009年(5)APS数据集中论文最晚发表时间为2009年。相隔的年数。通过对不同作者传播概率得到的前1 000名科研人员的平均“科研年龄”进行比较(表1),可以发现,随着作者传播概率的提高,作者的“科研年龄”在不断下降,这主要是因为只使用引用作为传播载体时,论文的影响力只能向该论文引用的更早发表的论文传播,导致先发表的论文更容易累积影响力分数,而本文方法可以借助作者信息这个载体,使影响力可以向论文作者后续发表的论文传播,抑制了时间效应带来的优势,对年轻的科研人员更加友好。

表1 不同作者传播概率传播得到的科研人员序列,前1 000名的作者各类统计信息的均值
此外,我们将每篇论文只通过引用连边传播得到的PageRank分数记为引用传播分数,在比较不同作者传播概率得到的科研人员序列中,前1 000名作者发表的所有论文的总引用传播分数均值和总引用量均值。如表1所示,我们发现随着作者传播概率的提高,总引用传播分数的均值在缓慢降低,而总引用量均值却在逐步上升。总引用量可以看做科研人员影响力的直观体现,不同排序中的前1 000名科研人员的总引用传播分数和总引用量却呈现负相关关系。这说明引用传播分数刻画的高影响力并不等同于高引用量,很多论文具有高引用传播分数的原因是高引用传播分数的论文引用了它们,而不是这篇论文本身具有深远的学术影响力,我们会在下一节的案例中更具体地分析这一现象。
同时,随着作者传播概率不断增大,作者发表论文数均值也在逐步提高,这说明影响力通过作者载体传播的概率越高,科研人员排名越注重论文数代表的生产力水平,越不容易被某篇高引用传播分数的论文主导。
当然,我们也要强调,虽然引入作者信息让影响力的传播更加多元化和合理化,我们也不能只使用作者信息连边对论文的影响力进行传播。假设网络中没有引用连边,即q1=0,论文影响力只传播给同作者的其他论文,这就鼓励科研工作者盲目提高论文产量,并扩大合作,使自己的论文与更多的论文产生连边,获得更大的影响力。
我们需要认清,发表论文时对相关工作的引用是对前人工作的认可,因此由引用关系作为载体带来的影响力传播是必要的。同时由同一作者发表的论文代表了这些论文同时得到了该作者的认可,隐含着这些论文之间的互相认可,因此由科研人员本身做载体的影响力传播也是必要的。综上所述,本文认为“引用-作者”联合传播方法可以得到更合理的科研人员学术影响力评价。
3.3 案例分析
为了更直观地展示引用传播的排序方法和联合传播的排序方法的不同,我们选择了不进行影响力全局重新分配(即q3=0),且学术影响力等概率的通过引用信息和作者信息联合传播(即q1=q2=0.5)的方式对科研人员进行排序评价。
我们将这种联合传播方式得到的科研人员序列与只通过引用传播得到的科研人员序列进行比较,并将这两个序列中分别排在前1 000名的科研人员画在了图7中。整体来看,由于两种传播均使用了引用信息,所以产生的科研人员排序序列是正相关的,这也从侧面解释了即使只通过引用传播影响力存在一些不足,大家依然会使用这一类影响力传播方法的原因。

图7 引用传播和联合传播方法所得序列中,分别排在前1 000名的科研人员分布散点图
除了科研人员排序整体的正相关现象,基于引用的传播方法和联合传播方法也有着非常明显的区别。如图7所示,联合传播的排序方法将论文发表数量更多的科研人员和更加年轻的科研人员排在了更加靠前的位置。
此外,很多科研人员的排名在引用传播方法和联合传播方法得到的序列中有巨大差别,图7中给出了两个案例,并标注了他们的名字。首先,我们先来分析科研人员C. B. Bazzoni,通过引用传播的排序方法他的排名为899,而通过联合传播的排序方法他的排名仅为39 994。Bazzoni在APS数据集中只被收录了一篇论文,这篇论文发表在1924年,并且只被引用了6次。但是在只使用引用连边进行传播的情况下,这篇论文在所有论文中影响力排名为195名,因为有一篇排名第5的文章引用了它。因此,仅使用引用传播的方法在度量这些学术生涯开始很早,发表论文数量很少,但影响力被早期某篇论文主导的科研人员的任务上是失败的。
接下来我们来分析科研人员J. Ollitrault,他的引用传播方法排名为8 884,而联合传播的排名为854。他有19篇文章收录在APS数据集中,并且发表时间都在1989年到2009年之间,是一位比较年轻的科研工作者。在他20年学术生涯中,累积了448次引用,且与159名科研人员进行过合作。由于Ollitrault多数论文发表在2000年以后,引用这些论文的论文还没有充足的时间累积影响力,所以在只使用引用信息进行影响力传播时,他的排名很低。但是引入了作者信息后,他发表的其他论文以及他合作过的作者发表的论文都可以直接或间接地向他的论文传播影响力,因此给了他更高的排名。这说明我们的联合传播方法除了建模一名科研人员发表论文被引用的情况,也同时包含了作者论文产量和作者社交能力的影响。
3.4 诺奖得主识别任务
本节我们利用诺奖得主识别任务,验证联合传播方法对科研人员学术影响力评价的有效性。一直以来,诺奖得主都是公认的“对人类作出巨大贡献”的人士。我们收集了APS数据集中收录的1950—2016年间获得过诺贝尔物理学奖的125位杰出科学家,并通过比较他们在各类评价方法中所得序列中的位置,比较评价方法的性能。具体地,我们使用诺奖得主在序列中的平均排名(Average Rank, AR)和平均准确率(Average Precision, AP)对各种方法所得科研人员序列进行评价。此外,我们选择了以下方法作为基准方法,与本文提出的联合传播方法进行对比: 指数类方法中,选择了使用最为广泛的科研人员总引用量和h-指数;在基于引用的排序方法中,选择了作者粒度(RLPL算法[14])和论文粒度的方法。
由表2可以看出,基于传播的排序方法的诺奖得主识别效果均优于指数类方法。在识别所有诺奖得主的任务中,本文提出的联合传播方法与基于引用的方法在平均排名指标下差距不大。但联合传播方法更加关注排名靠前的科研人员,因此在平均准确率指标上,效果远优于其他基准方法。此外,通过比较了不同方法在识别2000年后获奖的36位诺奖得主任务上的性能,我们提出的联合传播方法在平均排名和平均准确率指标上均优于其他方法。实验结果表明,联合传播方法是一个更加有效、公平、对年轻科研人员更加友好的学术影响力评价方法。
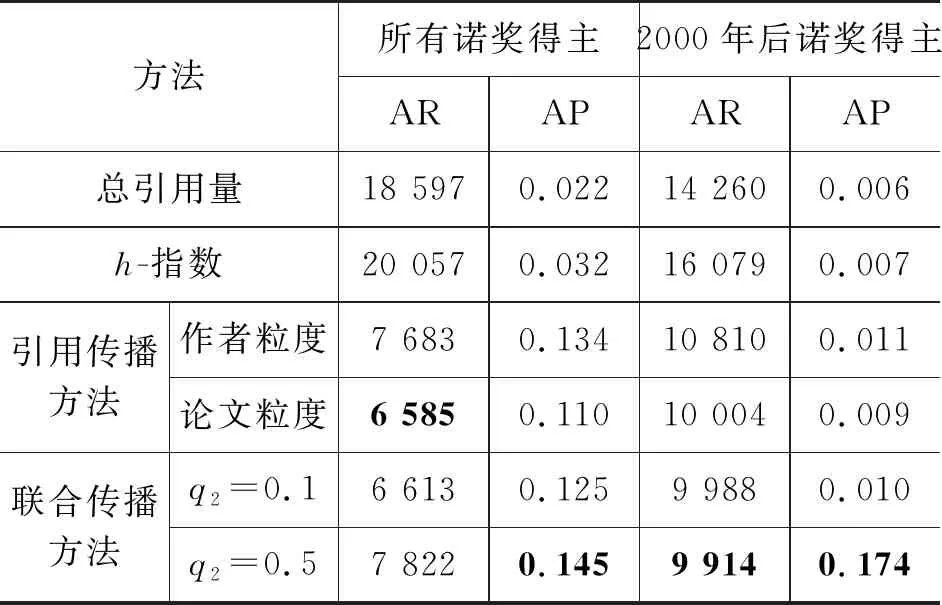
表2 不同学术影响力评价方法在识别诺奖得主任务上的性能比较
3.5 全局重新分配的影响力分析
除了改变不同影响力传播载体的传播概率对作者排序产生的影响,我们接下来固定引用传播概率和作者传播概率的比值,将通过两种载体联合传播的模式固定,探索全局重新分配的概率q3对科研人员排序的影响。
如图8所示,我们选取了以更大概率通过引用传播和等概率通过引用和作者连边传播两种模式,即q1:q2=9: 1以及q1:q2=5: 5两种模式,在不同的全局重新分配概率下,比较联合传播与引用传播的差异。
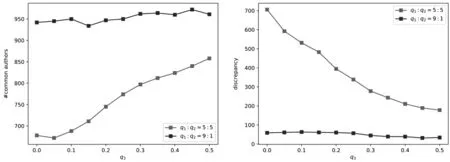
图8 全局重新分配概率对排序差异的影响
我们发现随着全局重新分配概率的提高,联合传播和引用传播两种方法产生的序列差异均越来越小。这是因为全局重新分配使影响力同等概率地传播到每一篇论文上,全局重新分配的概率越高,所有论文影响力越趋于一致,弱化了不同的传播方式对论文影响力分数的影响。
4 结论
本文聚焦于科研人员的学术影响力评价问题,首先剖析了用图上的排序方法模拟学术影响力在引用网络上的传播存在的问题,发现无论是直接构造一个作者粒度的引用关系网络直接进行作者排序,还是先构建一个论文粒度的引用网络,再将论文影响力按权重分配给作者,都隐含了同样的假设: 学术影响力只能通过论文之间的引用为载体进行传播。
随着时代的变化,大数据时代让我们能便捷地使用大规模学术数据平台,从中直接获得论文的作者信息和科研人员发表论文情况。这使读者可以非常容易地从一篇论文直接跳转到作者的其他论文中去,给学术影响力带来了独属于信息时代的传播方式,以科研人员本身为载体进行传播,即学术影响力可以在同一作者发表的论文之间传播。因此,我们提出了学术影响力可以通过引用信息和作者信息两种方式联合传播的排序评价方法,为学术评价带来了更加丰富的信息。基于“引用-作者”联合传播的方法使学术评价不仅考虑到了科研人员发表的论文被引用的情况,也考虑到科研人员的论文发表能力和学术社交能力。在美国物理学会数据集上的实验结果表明,我们的联合传播方法有效改善了只使用引用信息的排序方法带来的不合理评价,且对年轻和多产的科研人员更加友好。
