基于树库转换的藏语依存句法树库构建方法
2022-09-05周毛克龙从军赵小兵李林霞
周毛克,龙从军,赵小兵,李林霞
(1. 中央民族大学 中国少数民族语言文学学院,北京 100081;2. 国家语言资源监测与研究少数民族语言中心,北京 100081;3. 中国社会科学院 民族学与人类学研究所,北京 100081;4. 中央民族大学 信息工程学院,北京 100081)
0 引言
句法分析(Syntactic Parsing)根据给定的语法规则,自动推导出句子的语法结构,是计算机实现自然语言语义理解的一项关键任务。近年来,依存句法分析(Dependency Syntactic Parsing)以形式简洁、直接面向语义、便于分析处理等优点受到研究人员的关注[1-2]。藏语依存句法分析是藏语自然语言处理的重要任务,对藏语本体研究和计算处理都具有重要价值。
相较于英语和汉语,藏语作为低资源语言(Low Resource Languages),句法研究成果积累较少[3]。目前,藏语依存句法分析存在三个问题亟待解决: 一是藏语依存句法分析标注体系不一致。研究单位或研究者提出的标注体系存在较大差异;二是没有开源可共享的语言资源库。现有的藏语依存句法分析研究都基于小规模数据,句子覆盖率低,依存分析效果差;三是依存分析算法和模型都基于传统研究方法。尽管深度学习在资源丰富的语言处理领域获得了巨大的成就,但是在如藏语一样语言资源匮乏的语言研究中没有得到充分发挥。由上述问题可知,语言资源建设仍是实现藏语依存句法分析的首要任务。基于此,本文提出了一种基于树库转换的藏语依存树库构建方法,通过半自动的方式构建藏语依存树库,实现藏语依存句法分析。
1 建立藏语依存句法分析标注体系
依存句法标注体系建设是构建藏语依存树库的重要前提。近几年,研究者在依存语法和藏语传统语言文法的基础上建立了藏语依存句法标注体系,如华却才让等[4]制定了33种藏语依存关系类型;扎西加、多拉等[5]提出了24种依存关系类型和18种语义依存关系类型;头旦才让、尼玛扎西等[6]将藏语依存关系分为5个大类36个小类;夏吾吉等[7]设计了62种语义依存关系类型等。由此可见,当前藏语并没有统一且标准的依存句法标注体系,现存的依存关系类型因研究者而异。本文在依存语法理论[8-12]指导下,结合藏语本身的形态、句法等语言特性,同时借鉴英语、汉语现有依存句法标注体系构建经验建立了藏语依存关系类型。
结合藏语语言文法[13-15],本文总结出了藏语句子内部的实词与实词、实词与功能词、短语和短语之间的依存关系,构建了藏语依存关系标注体系。在制定依存关系类型时,如果把藏语的复杂依存关系描述清楚,就需要建立许多关系类型,例如,按照谓语成分,可以把主语分为系动词的主语、存在动词的主语、自主动词和非自主动词的主语等,甚至可以再细化,这样做虽然可以全面细致地描述藏语的复杂语言现象,但是考虑到建模时过于庞大的依存关系标注集会导致句法分析器的鲁棒性和可操作性下降,数据稀疏问题突显,因此在确定藏语依存关系类型时,本文采用“大类为主”的原则,对语言描写和计算做了折中处理。最终建立的依存句法标注体系基本涵盖了藏语的句法语义关系。表1是本文制定的33类依存关系,在后续研究中,将不断完善此标注集。

表1 藏语依存关系标注集
2 树库转换
句法树库标注了十分丰富的词语形态信息、词类信息、句法结构信息、句法功能信息及语义角色信息。一个标注精细、合理的句法树库不仅可以供语言学家更好地研究语言的词汇、短语、句法等问题,也可为计算机处理自然语言提供优质的实验数据。目前,中、英文树库资源建设取得了较大的成果,但是蒙古文、藏文、维吾尔文等我国民族语言资源建设滞后,一定程度上影响了我国民族语言文字信息化进程。
随着藏语自然语言处理的深入推进,建设藏语语言资源知识库的需求逐渐增加。国内以中国社会科学院、西藏大学、西北民族大学、青海师范大学为首的研究单位通过手动或半自动方式建立了一定规模的语言资源库[16],如中国社会科学院民族学与人类学研究所的龙从军等[17]建立了1万句基本句型的藏语短语结构树库;华却才让等[18]以半自动的方式构建了1.1万句藏语依存树库,扎西加、多拉等[6]构建了1万句藏语依存树库;夏吾吉等[19]人工构建了2 106句藏语语义依存树库。但是,与英语、汉语相比,藏语信息处理研究成果零散,研究队伍分散,短期内难以形成合力,导致规模性的句法树库构建困难,在一定程度上限制了藏语句法分析进程。
2.1 藏语树库情况


图1 前期构建的藏语短语结构树

2.2 藏语句法树库转换过程
2.2.1 扩充藏语短语结构树库
前期构建的藏语短语结构树库规模较小,因此在实现句法树库转换之前,需要对短语结构树库进行扩充。本文使用中国社会科学院民族学与人类学研究所的藏语短语结构句法分析器扩充了现有短语结构树库。扩充短语结构树库的生语料来源为Essentials of Modern Literary Tibetan: A Reading Course and Reference Grammar和The New Tibetan-English Dictionary of Modern Tibetan中的例句。以上两种文献中包含丰富的藏语例句,例句基本涵盖藏语所有的句子类型,是一种可靠的数据,故将其作为实验数据来源。
在前期构建的1万句数据集基础上,本文收集了1.2万个句子,作为扩充语料。借助短语结构句法分析器,将1.2万句生语料转换成短语结构格式。经过扩充,最终获得规模约为2.2万句的藏语短语结构树库,其中包含21万个词,38.9万个藏文音节,短语结构树库扩充情况如表2所示。
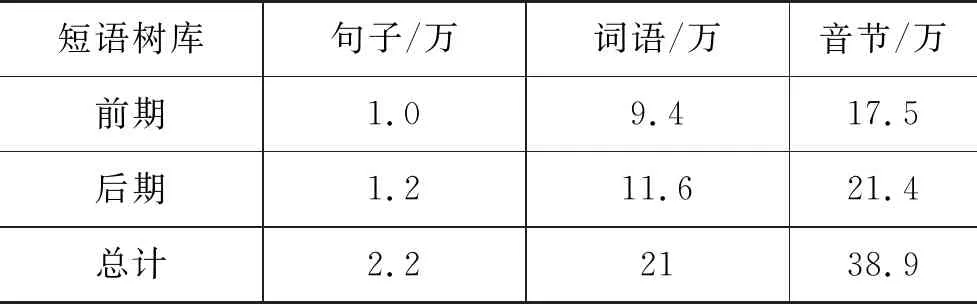
表2 短语结构树库扩充情况
2.2.2 设计树库转换规则
在短语结构树中,每个短语结构都有一个中心子节点决定着短语的主要性质,其他节点(非中心子节点)都是该中心子节点的修饰子节点[20]。现有藏语短语结构树仅仅标注了每个句子的短语层次结构而没有标注每个短语的中心子节点,所以在实现树库转换之前,首先需要确定藏语短语结构树中的中心子节点。
中心子节点过滤表是确定中心子节点的经典方法之一[21]。中心子节点过滤表主要由短语类型、优先级和搜索方向三部分组成,其中,短语类型是非终端节点的短语类型;搜索方向是在非终端节点内部搜索中心子节点的方向,包括向左(Left,L)和向右(Right,R)搜索。当搜索方向取值为L时,从短语的左侧开始向右搜索;当搜索方向取值为R时,从短语的右侧向左搜索;优先级决定着短语内部各类子节点的优先搜索次序。
确定藏语短语结构树中每个短语的中心子节点,需要根据现有藏语短语结构树库的标注特点构造完整的中心子节点过滤表。本文结合短语结构树库特点制定了藏语中心子节点过滤表,表3展示了过滤表的部分内容。
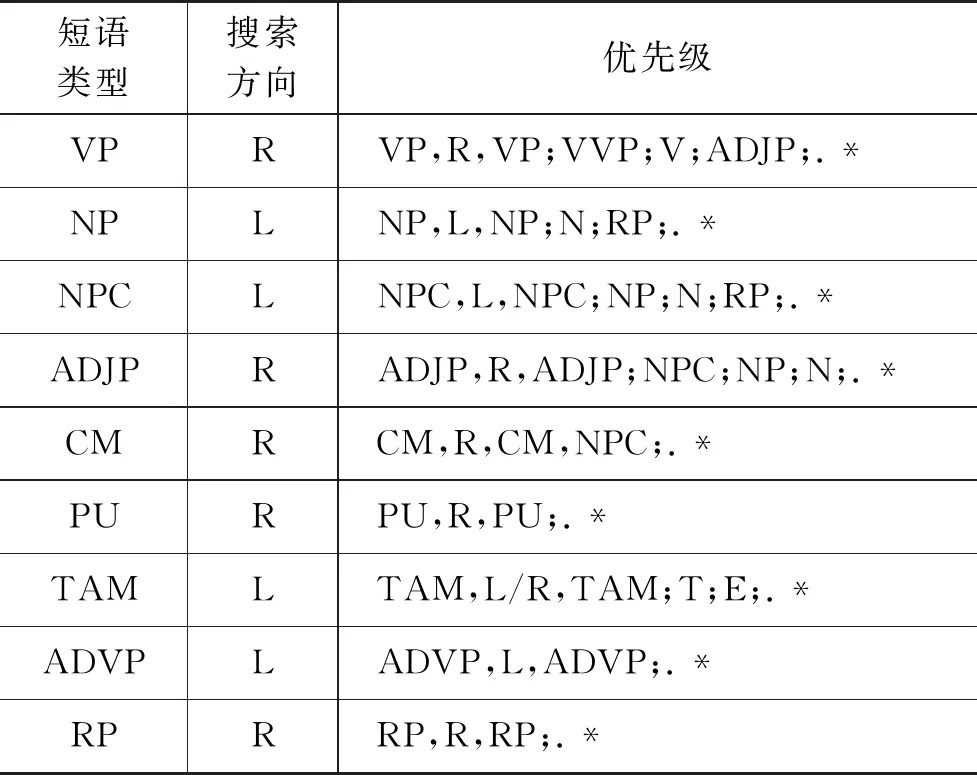
表3 藏语中心子节点过滤表
现以动词短语类型(VP)为例,确定该短语的中心子节点。动词短语的中心子节点过滤表条目为< VP,R,VP;VVP;V;ADJP;.*>,藏语是SOV型语言,动词居于句尾,所以VP短语的搜索方向为R,即从右向左搜索VP短语的每一个节点。按照优先级首先需要搜索VP,如果没有找到VP就搜索下一个优先级VVP,以此类推,匹配到则返回。当遍历完所有的优先级且没有找到匹配项时,根据搜索方向,我们就默认最右侧的子节点为中心子节点,同理,若搜索方向为L,则最左侧的子节点为中心子节点。

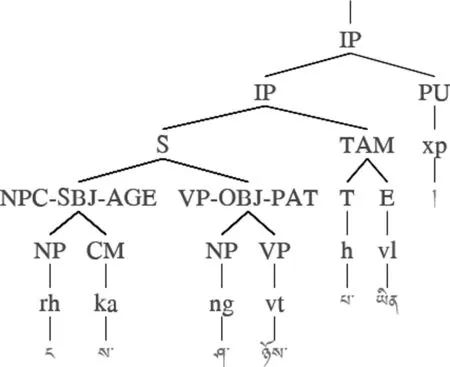
图2 已标注句法语义信息的短语结构树
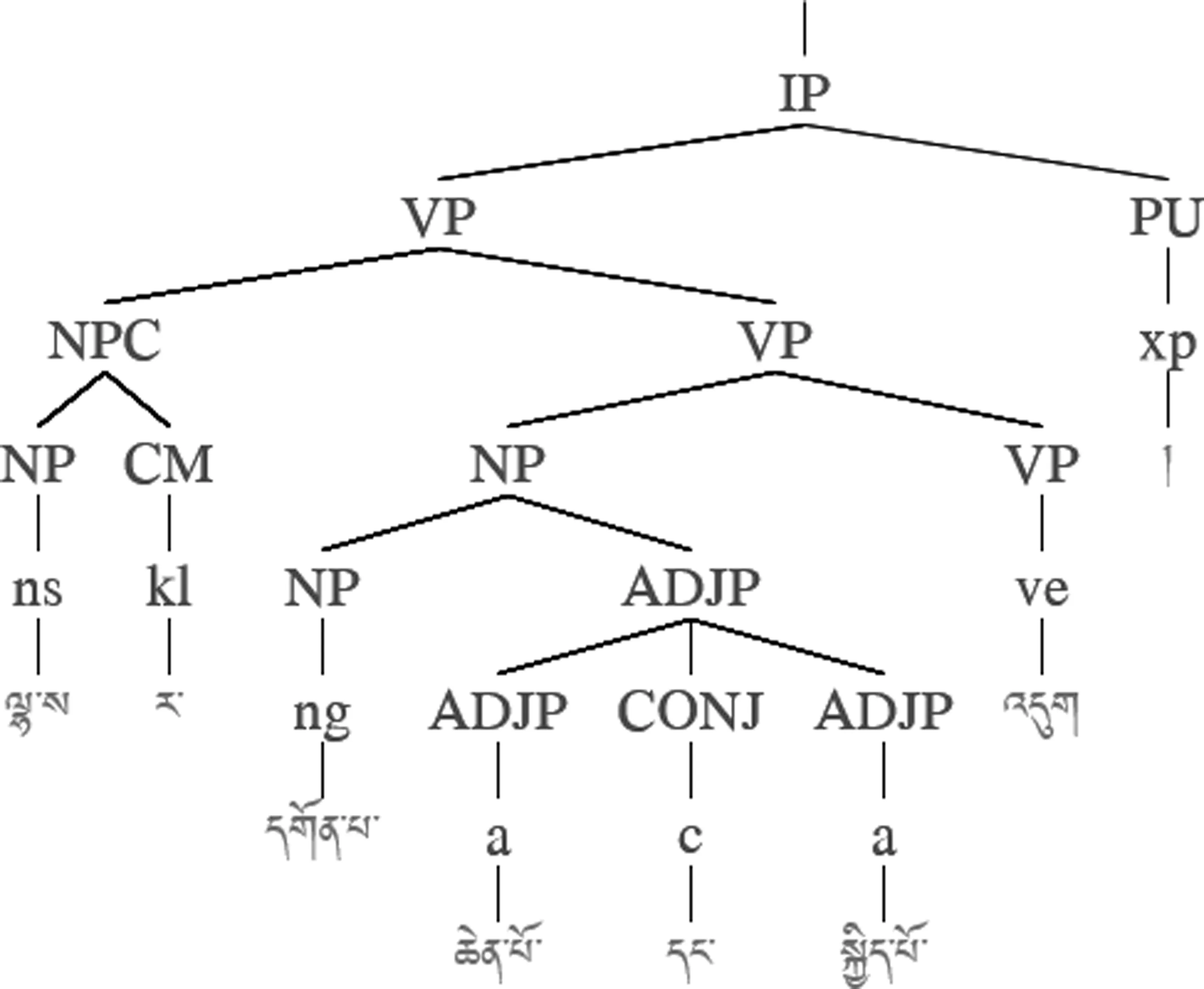
图3 未标注句法语义信息的短语结构树
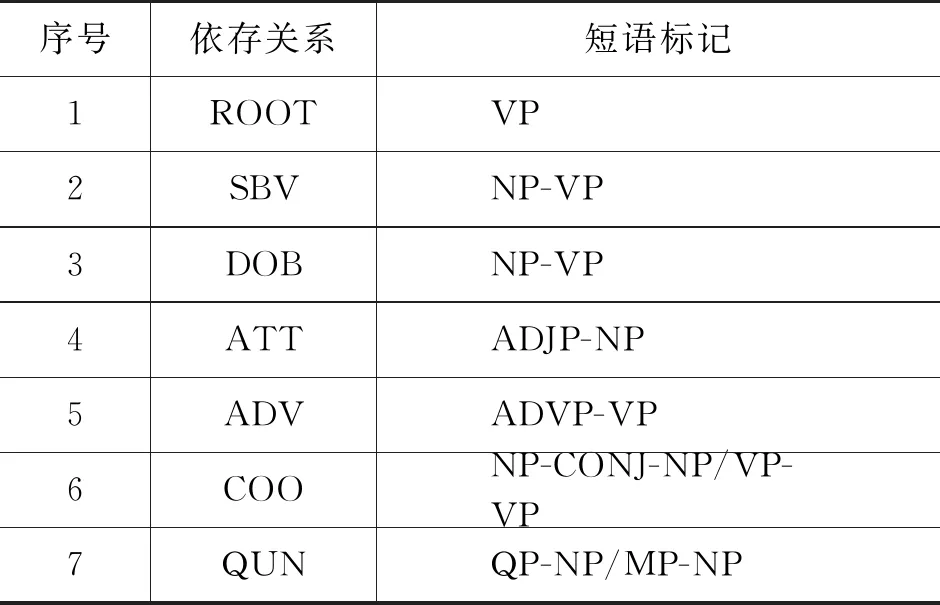
表4 短语标记与依存关系映射表(部分)
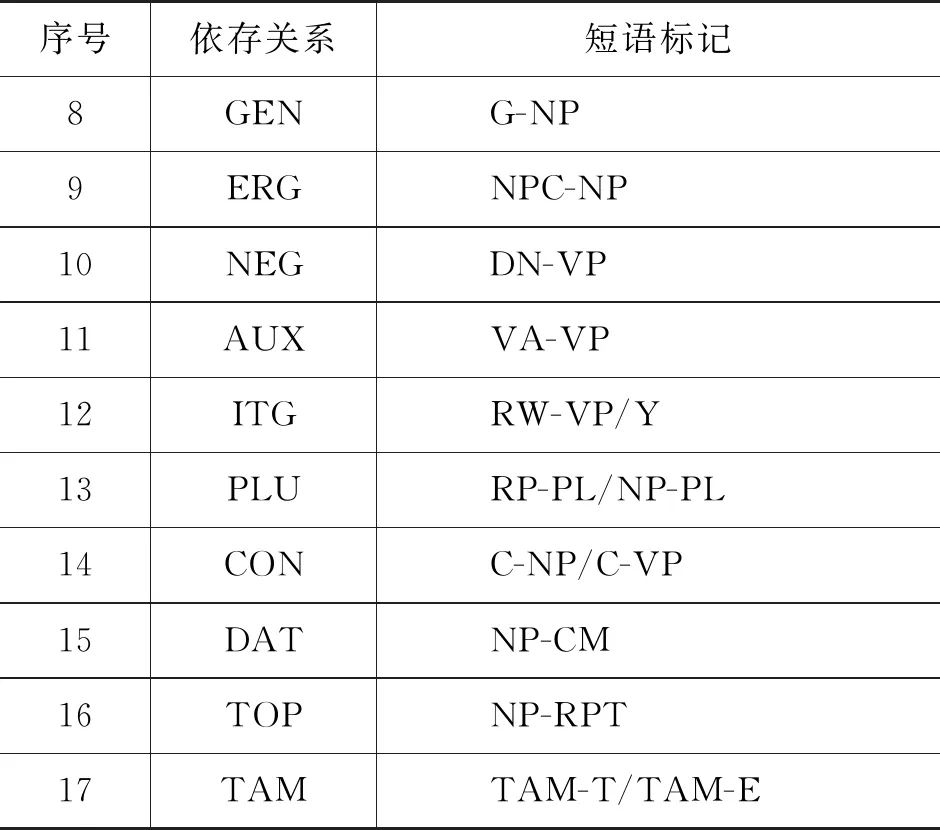
续表
2.2.3 转换算法
设计好过滤表和映射表后,就可以根据表中的规则开始转换树库。为了降低转换过程中句法树的复杂度,首先需要将长难句分块处理;其次按照过滤表中规定的短语搜索方向,依据优先级从右往左或从左往右依次搜索,搜索过程中如果某一项匹配成功,则立即确定并返回该短语的中心子节点,其他子节点依次依存于中心子节点;最后根据映射表标注词与词之间的依存关系类型, 初步实现树库转换工作。
上述为藏语树库转换的基本流程,在设计算法时,藏语短语结构树库(Tibetan Phrase Structure Treebank)和藏语依存树库(Tibetan Dependency Treebank)分别用TPST和TDT表示,具体的算法流程如下所示。

(1) 需求藏语短语结构树: TPST={pi}ni=1藏语中心子节点过滤表(Tibetan Priority Table),简写为TPT()藏语短语标记与依存关系映射表(Tibetan Phrase to De-pendency Table),简写为P2D()多层块标签: C={w,p,s}(2) 初始化藏语依存树库: TDT={dj}nj=1(3) 程序从藏语短语结构树库TPST中读取pi;步骤1: 为快速实现树库TPST转换,在此借助短语结构树的分层分块特点,将复杂句分成多个小块,使用chunk=(pi,C),确定句子pi的块边界;步骤2: 确定pi的中心词: searchRoot(pi)步骤3: 采用中序遍历的方法实现从短语结构树到依存结构树的转换: 中序遍历(pi): 如果当前节点r为根节点: 继续搜索根节点r的子节点 否则: createTree(TPT(),P2D(),r) dj=str("n","w","w","p","p","_","id","arc","_","_") 最后: 将dj添加到TDT中,直到TPST的长度和TDT的长度等于n时结束 返回TDT={dj}nj=0
3 树库转换结果及分析
3.1 树库转换结果
本文将2.2万句藏语短语结构树作为源树库,通过树库转换的方法构建依存树库。理论上,如果短语结构树库的短语标记和依存树库的依存关系标签能够一一对应,则转换结果就会有较高的准确率。但是,在实际操作中,由于源短语结构树库在构建过程中不可避免地出现了标注错误、标注缺失等问题,因此难以做到一一对应的转换。
通过上节树库转换算法,初步实现了源短语结构树到目标依存树的转换。为了对转换后的结果做出定量评价,本文从转换后的依存树库中抽取了5%的依存树进行人工校验。
经过对抽取的1 100个样本树的依存关系个数进行统计,得到8 329个依存关系类型,然后使用依存可视化工具对所有样本的依存关系进行人工校验。最终计算出树库转换的准确率,如表5所示。

表5 样本依存关系准确率
对样本的准确率进行验证我们发现,通过初步转换,本文提出的树库转换方法在实现藏语句法树库转换和构建藏语依存树库任务中具有良好的表现,准确率达到了89.36%。此外,在人工校对5%的样本时,对句子中心词(ROOT)的标注准确性也进行了统计。1 100个句子中,除87个句子中心词标注错误外,其余1 013个句子都准确地找到了句子的中心词,准确率达到92.09%,如表6所示。

表6 ROOT转换的准确率

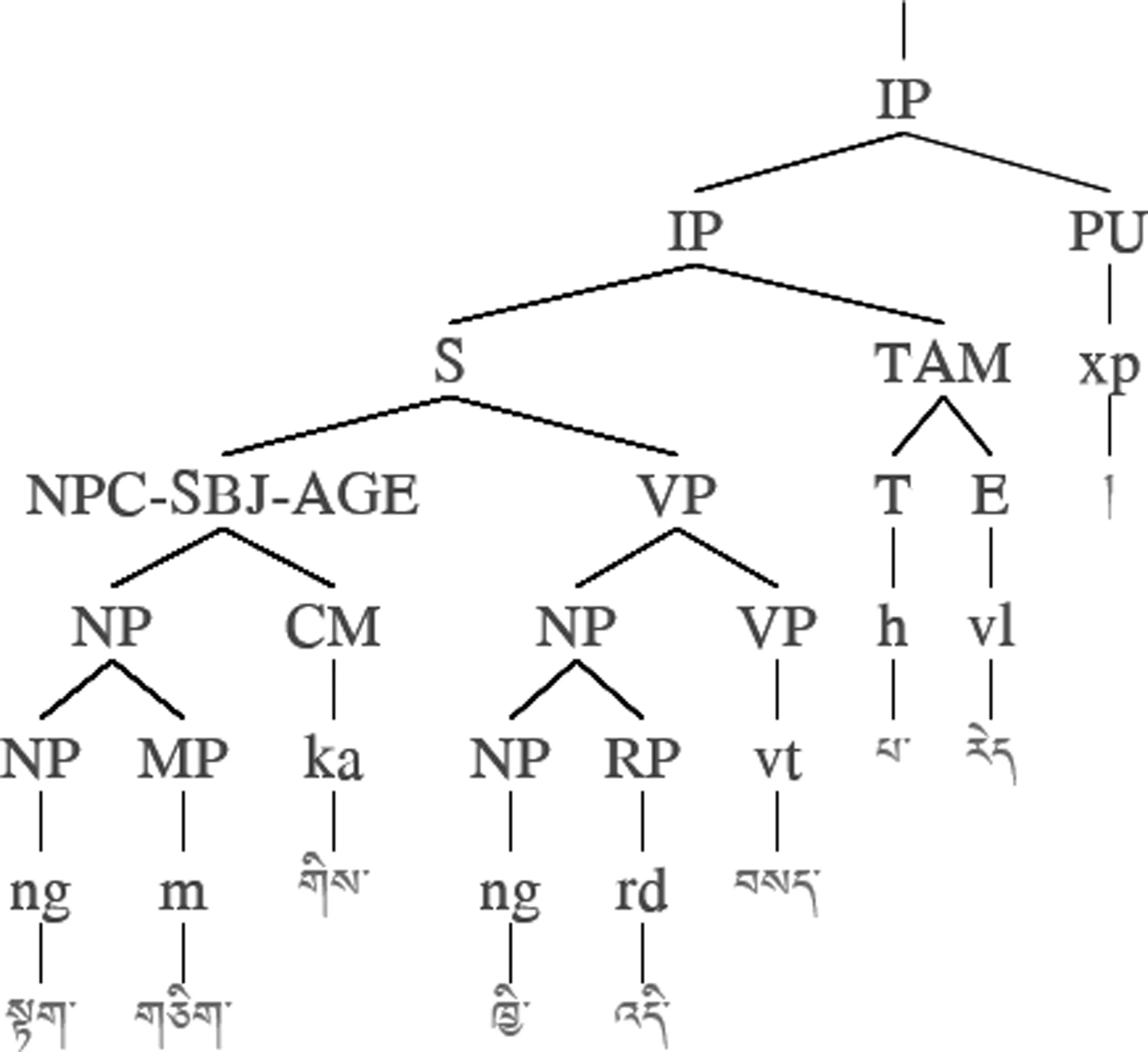
图4 源藏语短语结构树
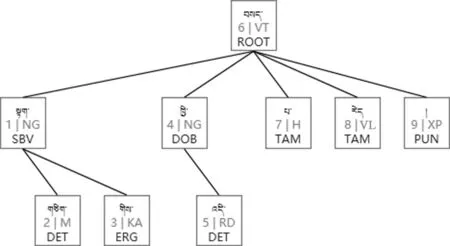
图5 目标藏语依存树
综合树库转换实验,本文最终构建了规模为2.2万句的藏语依存树库,与华却才让、扎西加等构建的藏语依存树库规模相比,本文的树库规模较大。转换后的藏语依存树库使用CoNLL格式保存,具体如图6所示。
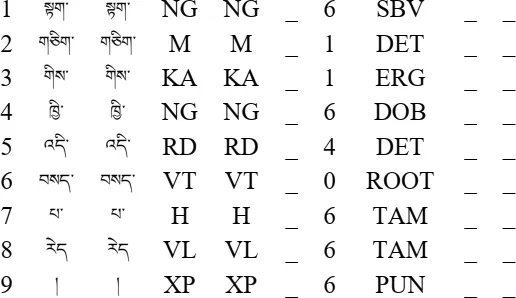
图6 CoNLL格式的依存树样例
3.2 结果分析
基于树库转换的藏语依存树库构建方法能够有效实现两种树库之间的转换,但是在实际转换过程中,无论是源藏语短语结构树库、中心子节点过滤表、映射表,还是转换算法等都存在一些问题。
3.2.1 句法树库问题

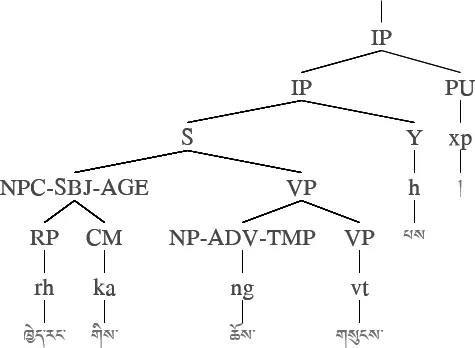
图7 短语结构树标注错误例子
另外,如果短语结构树标注了完整的句法功能信息和语义角色信息,那么在确定短语标记和依存关系之间的映射关系时,就可以借助句法和语义信息快速地获取映射关系。但是,目前的藏语短语结构树中,只标注了最常见的7类句法功能信息,通过这7类句法功能信息能够简单地找出对应的映射关系,而本文制定的藏语依存标注体系中有33种依存关系,已标注的句法功能只能确定约1/5的映射关系,剩下约4/5的映射关系需要通过人工确定。因此句法树标注的完善程度会影响映射表的完整性和准确性,从而间接影响树库转换任务。
3.2.2 过滤表和映射表问题

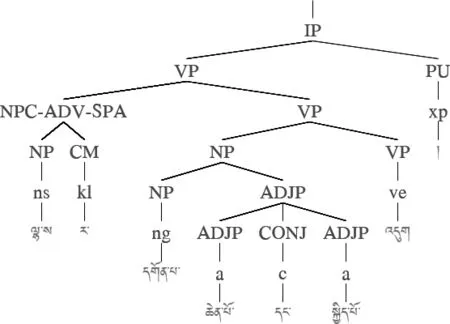
图8 特殊结构之结构并列
在本文制定的短语标记与依存关系的映射表中,部分映射关系是通过句法功能信息和语义角色信息确定的,这一部分的映射关系比较可靠且准确率较高,例如,7个句法功能标记(SBJ、PRE、OBJ、ADV、CON、APP、ATT)能直观地确定短语结构标记与依存关系的映射关系。但是,其他映射关系基本以人工观察树库总结规律得来,这类映射关系具有局限性,一方面受到研究者的主观影响,另一方面还会受到整个句法树库的影响,因此我们不能排除这类映射关系出现错误的可能。另外,映射表中的映射关系存在重复问题,例如,主谓关系(SBV)、直宾关系(DOB)和间宾关系(IOB)等都与短语标记NP-VP对应,所以在转换过程中遇到NP-VP标记时,就无法确定优先选择哪种依存关系类型。
3.2.3 转换算法问题
本文的树库转换方法包括转换和标注两部分。转换过程中,由于过滤表中列举出来的优先级不一定全面,因此在遍历优先级的过程中,对于匹配不到的情况,本文的计算处理方式为直接按搜索方向确定优先级,即从右向左搜索,右边的第一个节点为中心子节点;从左向右搜索,则左边的第一个节点为中心子节点,这样的处理方式比较武断且错误产生率较高。另外,在标注过程中,短语标记和依存关系的映射表中出现了重复的情况,例如,依存关系“SBV”“DOB”“IOB”与同一个短语标记“NP-VP”对应,“POS”“ATT”也是与同一个短语标记“NP-G”,遇到这种一对多现象时,我们直接用特殊符号“-”标记,转换结束后按照特殊符号搜索进行人工校对。这种处理方式加大了后续人工校对的成本。
3.2.4 语言本身的歧义问题

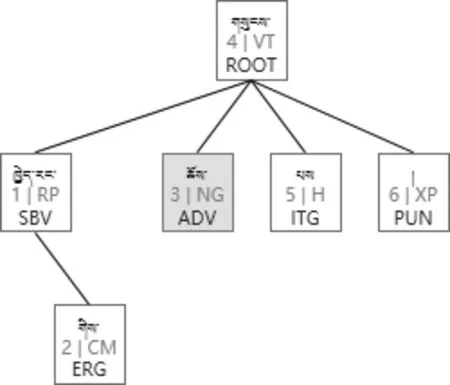
图9 标注错误引发的转换错误例子
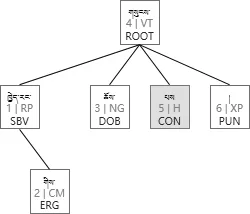
图10 转换结果1
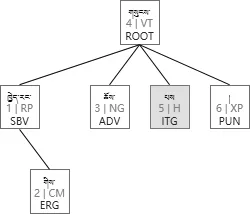
图11 转换结果2
4 藏语依存句法分析
目前的藏语依存句法分析模型几乎都是基于统计的方法,华却才让、扎西加、夏吾吉等使用感知机、最大熵等建立语言模型,虽然取得了不错的结果,但是这种传统的模型需要做大量的特征工程,特征向量稀疏且泛化能力差,特征存储和计算代价大。为了提高计算效率和准确率,本文使用Chen和Manning等[22]提出的基于神经网络的依存句法分析模型实现藏语依存句法分析,从而验证依存树库的有效性。
基于神经网络的依存句法分析模型最早由Chen和Manning提出,后来的模型大多是在其基础上调整改进而来。本文调用该模型,使用ARC-Standard转换算法实现转换处理,然后在此基础上使用神经网络作为分类器自动提取特征预测依存关系。本文的神经网络模型共有三层,分别为输入层、隐藏层和输出层,层与层之间以全连接的方式连接,模型框架如图12所示。
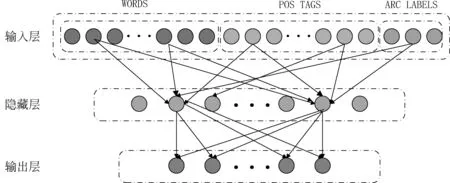
图12 神经网络模型框架
根据词向量的原理得知,如果词和词之间具有相似的关系,那么其词性、依存弧也应该能够表现出许多语义上的相似性,这些具有相似性的向量导入模型后,能够有效地提升模型的性能,所以本模型的输入层是由一组词向量(WORDS)、词性标签向量(POS TAGS)、依存弧标签向量(ARC LABELS)的拼接层;模型的输入层到隐藏层之间使用cube激活函数,该函数能够将输入层的特征向量充分组合起来,从而提高模型的性能;本任务是一个多分类任务,softmax函数在多分类任务中具有较高表现性能,因此模型的输出层使用了softmax函数。
本文以9∶0.5∶0.5的比例将语料分为训练集、验证集和测试集,使用UAS值和LAS值作为评价指标[23],运用Pytorch框架建立神经网络模型。实验过程中,经过多次迭代,模型的loss值从0.184 039 748降到0.069 148 814,验证集上的UAS值、LAS值随着loss值的下降而上升,如表7所示。
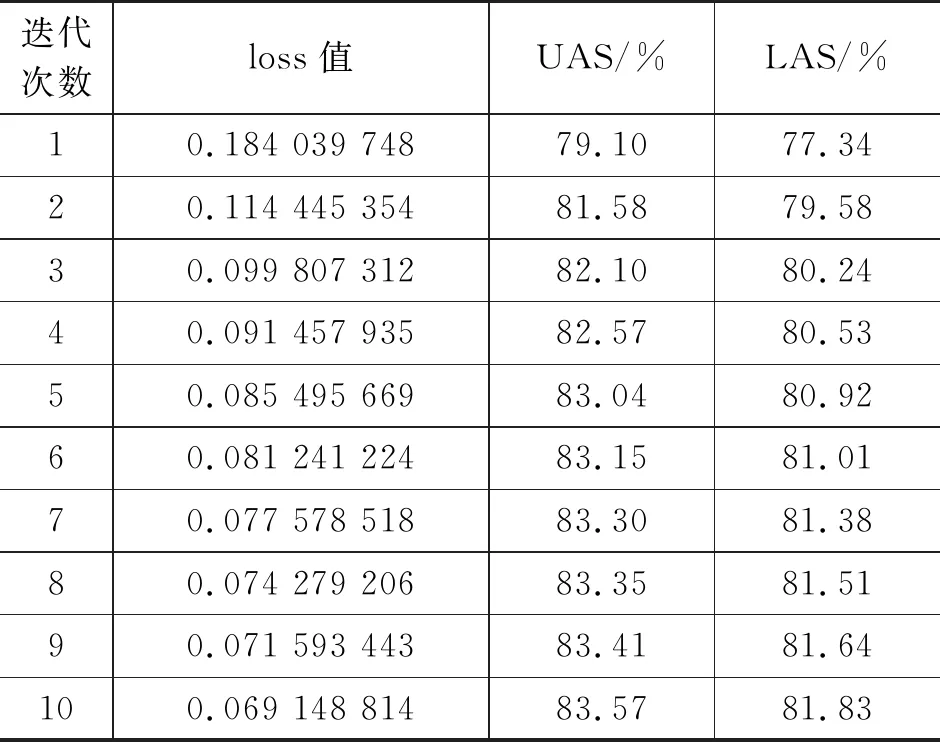
表7 loss值与验证集上的UAS值、LAS值
在模型基本达到最佳状态后,验证集上的UAS值和LAS值分别达到83.57%、81.83%,变化趋势如图13所示。
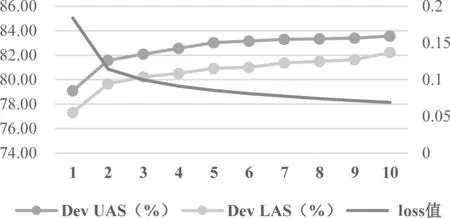
图13 loss、UAS、LAS值变化趋势图
经过训练获得最佳的藏语依存句法分析模型后,进行了测试实验。在测试集上,UAS值为83.62%,LAS值为81.90%,如表8所示。
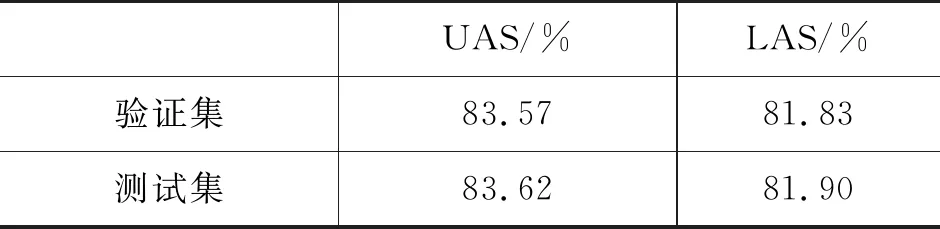
表8 测试集实验结果
经过分析实验中出现的错误实例后发现,大多数实例包含3~7个词,其中很多错误是由于句子中的歧义词、罕见词或未登录词造成的。另外,由于语料规模较小,训练过程中每个单词出现的频次有限,导致模型性能偏低。总体而言,本文构建的依存树库在神经网络模型上具有良好的表现。
5 结语
句法分析既是藏语自然语言处理的重难点,也是语言信息化处理的关键基础任务之一。长期以来,由于语言资源匮乏等因素影响,藏语句法分析方面的研究进展相对缓慢,成果较少。本文提出了一种基于树库转换的依存句法树库构建方法,为藏语依存句法分析构建基础数据。我们在扩充源短语结构树库的基础上,根据树库特征设计转换规则,通过规则实现短语结构树到依存句法树的转换,最终得到了一个规模为2.2万句的藏语依存句法树库。为了验证树库的有效性,本文使用神经网络建立藏语依存句法分析模型,实验证明,藏语依存句法分析能够达到较高的水平。在后续研究中,扩大句法树库规模仍然是研究的首要任务,其次,需要探索更多的方法,从技术上突破,节省构建树库的各项成本,将理论和实践结合起来,更好地为藏语自然语言处理的其他任务服务。
