海量GPR检测数据负载均衡并行处理技术
2022-09-05杜翠程远水张千里
杜翠 程远水 张千里
1.中国铁道科学研究院集团有限公司铁道建筑研究所,北京 100081;
2.中国铁道科学研究院集团有限公司高速铁路轨道技术国家重点实验室,北京 100081
探地雷达(Ground Penetrating Radar,GPR)是一种快速、无损、高效的地球物理探测方法,广泛应用于交通设施检测、地质勘察、环境工程等领域。作为一种高效的浅层地球物理检测技术,GPR以高频或超高频电磁波为信息载体,利用不同介电常数传播介质之间的界面对电磁波的反射特性和传播速度变化规律,对目标物进行探测和定位,具有连续探测和实时显示的特点[1]。GPR技术是铁路路基、隧道等基础设施检测的重要手段[2-4]。随着铁路运营里程的迅速增长,GPR数据量呈指数增长趋势。实现快速、智能的海量GPR数据处理与智能识别,为铁路智能检测监测提供技术支撑。
GPR数据处理技术在处理中小尺度数据集上已经相对成熟。但这些技术绝大部分基于单计算节点,涉及的算法往往高度串行化[5-6]。此外,已有的实现方法多基于传统的单机计算机体系结构和计算模型,完全无法适用于当前大内存、多源异构、高度并行化的硬件架构体系。新一代高性能硬件架构体系的快速发展,给海量GPR数据快速处理的开展创造了新的机遇。目前,由于地震数据规模较大,已开展了较多基于集群模式的算法并行化研究[7-9],采用了CPU并行、CPU+GPU异构并行、Hadoop等技术。大量高精度、大区域的GPR检测数据可以利用并行技术进行处理,极大提高处理效率[10-12]。
本文提出海量GPR数据的分布式存储方法,适应多种文件组成结构,提高数据I/O效率,研究具有较强适应性和较高扩展性的负载均衡并行技术,建立面向数据并行+算法并行的混合并行计算模式。
1 GPR数据分布式存储方法
以高容错性为特点的分布式文件系统HDFS(Hadoop Distributed File System)可以利用大量廉价PC机组建成一个来存储超大文件的集群文件系统。当一台服务器的存储容量已经不能承载需要储存的数据集时,数据集会被分成多个块以分布存储在机架的各个服务器上。在进行数据存储时,HDFS是以数据流的方式写入的,在实现分布式存储的同时还具有一次写入、多次读取的高效访问模式。
GPR原始数据为非结构化的特定文件格式,如意大利IDS雷达的*.dt格式,中国矿业大学(北京)GR雷达的*.gpr、*.raw、*.dat格式等。这些文件格式的共同点在于采用二进制存储,分为文件头和数据道2部分,数据道的道头也包含特定的标记信息。在本文研究中,为适应HDFS分块存储的模式,将文件头信息存入关系型数据库MySQL中,数据道则分块存储到HDFS中。
2 混合并行计算模型
2.1 计算任务拆分方法
探地雷达数据划分的主要目的是将待处理的探地雷达数据合理、均衡地划分给计算环境包含的所有计算节点,使得不同计算节点承担的计算任务量大体相当,从而在并行计算开始前尽可能保证负载均衡。数据划分策略的有效性体现在:各计算节点分配的数据尽可能不相交,具有较小的划分时间消耗比例及均衡的任务量分配比例。如果以原始文件为拆分颗粒度,有时导致单个计算单元过大,且无法动态调整,从而不能实现并行计算过程中的负载均衡。
首先,确定不同算法类型包含的数据粒度。探地雷达的数据特点在于各道数据间无依赖关系,可根据道号进行切分。根据不同算法原理,可将GPR信号处理算法中的数据粒度设置为单道A-scan较小的B-scan。假如以B-scan为计算单元,则应注意源文件大小或者分布式存储单块数据量应为B-scan大小的整数倍,以适应数据边界。
然后,将算法按计算步骤合理拆分为子任务。从数据起点开始,沿里程方向逐个数据粒度移动,在各个数据粒度内按照规则对各个计算单元进行各个子任务的处理,从而完成全部计算。当数据粒度为B-scan时,假如单个节点划分的数据量过大,容易产生物理内存不足的情况,从而导致其他节点等待,无法实现负载均衡。
因此,在任务拆分时,应验证集群内存资源是否满足数据粒度×节点数量的需求,从而得出数据粒度的最大阈值,并保留一定的冗余空间。
采用Hadoop平台的MapReduce并行计算框架。MapReduce封装了并行处理、容错处理、数据本地化优化、负载均衡等技术难点的细节,这使得MapReduce库易于使用。MapReduce处理数据流如图1所示。数据流首先进行分片,与HDFS的分块大小一致,然后每个分片会分配给用户定义的map方法进行处理(通过JNI调用dsp_alg),之后针对reduce的数量产生对应的输出分片,得到map方法输出的<key,value>对后,把相同key值相同的放到一起,最后输出结果。

图1 MapReduce处理数据流
2.2 动态负载均衡方法
Hadoop平台中以Slot作为计算资源的分配单位,map任务和reduce任务都是在Slot上运行。Slot可以理解为单位计算资源,与CPU对应。由于存在数据倾斜或者计算倾斜,每个任务的运行时间不同,可能会出现某个Slot任务完成空闲了,而其他的Slot上还有大量的任务没有完成。显而易见,如果此时能够把其他Slot的任务放到这个Slot上来运行会大大提高系统的资源使用率,同时能够提升任务的处理效率及系统的吞吐量。
解决方法整体上分静态负载均衡和动态负载均衡两类。静态负载均衡大多是进行算法优化,改变用户程序,使得整个作业的执行时间尽可能降低。这样的负载均衡一般都是需要对于当前的作业任务、输入数据特征和各个机器节点资源有先验知识。
相比于静态负载均衡,动态负载均衡不需要改变用户的应用代码,也不要针对不同的输入数据做算法定制优化,系统能够自动地完成均衡工作。动态负载均衡关注的是Slot的空闲与否,在运行时根据当前运行状况做出负载分配决策。当系统中出现空闲Slot时,从正在运行的task中挑选一个作为Straggler,即系统中节点的任务,从计算任务重的Slot中迁移一部分任务到空闲Slot中。
3 试验与分析
为验证本文提出的GPR数据并行处理方法的应用效果,利用某线路路基检测数据进行测试。测试数据集由5个40 000道数据的雷达文件组成,执行的算法工作流包含背景去噪、增益、一维滤波、二维滤波、滑动平均共5个步骤。Hadoop集群测试环境见表1,由9个节点组成,其中1个节点为主节点,8个节点为计算节点。

表1 Hadoop集群测试环境
3.1 并行颗粒度测试
将计算任务拆分为不同大小的颗粒度,计算效率见图2。可知:当最小颗粒度为单个原始文件(40 000道)时,共耗时9 min 42 s。将雷达文件采用本文方法进行分布式存储,以支撑任意大小道集的并行颗粒度,切片道数从640到3 200,计算耗时变化不大,为1 min 13 s~1 min 31 s。通过对并行颗粒度进一步细分,大幅优化了计算性能,提升了集群资源的利用率。
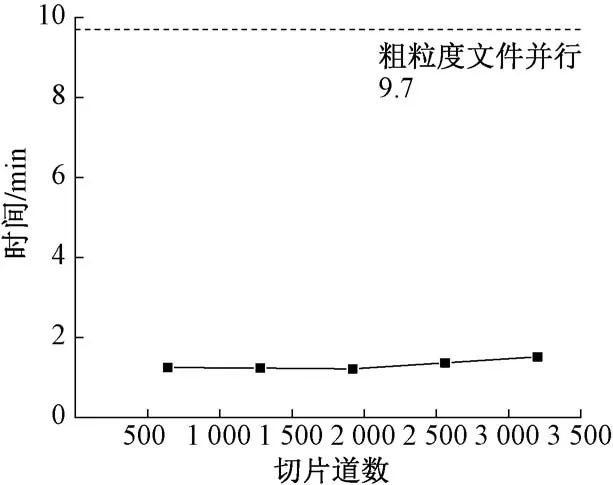
图2 不同颗粒度并行的计算效率对比
3.2 负载均衡测试
对本文采用的动态负载均衡效果进行测试,测试结果见表2。可知:场景1设置全部节点执行1次二维滤波算法,耗时31 min27 s;场景2设置全部节点执行2次二维滤波算法,耗时60 min17 s,约为场景1的1.92倍。场景3设置1/2的计算节点(A类)执行1次二维滤波算法,1/2的计算节点(B类)执行2次二维滤波算法。假如采用静态负载均衡,将数据平均分配至各节点,则B类节点耗时将约为A类节点的2倍,最后运行时间与场景2近似,很明显这种情况下A类节点的算力未充分利用。采用本文设计的动态负载均衡方法,将会有2/3的数据流转到A类节点,1/3的数据流转到B类节点,使得所有节点的计算量大致相等。场景3耗时42 min 6 s,约为场景1的1.34倍,达到了很好的负载均衡效果。

表2 负载均衡测试结果
3.3 进程数测试
对10 GB数据运行二维滤波算法,计算时间与加速比见图3。可知:当进程数小于物理核数16时,启动的进程数加倍,计算耗时减少接近1/2。当进程数大于物理核数时,计算性能只有微小的提升。通过测试集群,在8台物理服务器计算集群上多进程并行可以使二维滤波性能提升100倍左右(相对于单机单进程)。通过8台服务器一共8×16核=128核,可知集群并行本身框架调度数据读写等有一定的消耗,并不能完全达到实际核数使用上的性能翻倍。鉴于集群并行计算环境为Linux,并不运行其他软件,故可以按照实际物理核数来设置单服务器的并行数,以获取最大的性能加速比。

图3 二维滤波并行计算时间与加速比
4 结语
随着铁路运营里程的快速增长以及检测频次的增加,路基、隧道等基础设施探地雷达检测数据量呈指数增长,传统的单机处理模式无法满足时效性要求。本文设计了GPR数据的分布式存储方法,采用Hadoop平台的MapReduce并行计算框架,基于动态负载均衡方法建立了混合并行计算模型,并搭建了9节点集群环境进行了测试试验。对并行颗粒度进一步细分大幅优化了计算性能,在模拟迭代算法场景下取得了较好的负载均衡效果,服务器的进程数可按照实际物理核数设置,以获取最大的加速比。在未来的研究中,将探究各类算法的细粒度拆分方法,进一步完善数据+算法的混合并行计算模式。
