基于数据挖掘的业务系统元数据文档自动更新模型
2022-09-02萧展辉孙刚邹文景
萧展辉,孙刚,邹文景
(南方电网数字电网研究院有限公司,广东广州 510000)
业务系统的应用发展会受到两大因素的阻碍,一是与业务领域相关的分析模型比较复杂,用户在应用时不知道如何采用智能手段对业务进行持续改进;二是业务系统中的元数据质量较低,无法保证用户获取到的元数据文档是准确无误的[1]。业务系统中的元数据文档质量问题逐渐受到了社会各界的广泛重视,基于此,要加大力度让更多人认识到元数据文档在管理与应用中的重要性。在业务系统中,元数据文档自动更新处于整个系统结构的核心部分[2]。元数据文档贯穿于业务系统中整个数据流动的全过程,只有对元数据文档进行自动更新,才能为业务系统提供一个全局视图,把握好业务系统元数据文档的组成、转换以及来龙去脉,从而对元数据文档的质量进行有效管理[3]。目前,在业务系统中元数据文档自动更新是对其进行集中且统一管理的新课题,可以从根本上解决业务系统元数据文档在数据管理上的难题。
针对动态摘要信息缺乏、冗余严重的问题,文献[4]提出了一种自动更新动态摘要的方法,根据动态摘要的认证方案,对动态摘要信息的多样性和主题代表性进行综合评价,并利用所提出的主题签名模型来评价动态摘要的新奇程度,动态摘要生成策略可以减少更新方案实现的复杂度,实验结果表明,张祯等人提出的更新方法不需要进行语言匹配和模型训练,大大降低了实现的复杂度,提高了提取动态摘要的效率;考虑到云计算数据在网络应用中经常遭到非法窃取,文献[5]利用密文策略属性提出了动态更新操作加密方案,通过线性分段的方式将云计算数据分成数据块,利用密文策略属性的加密技术对每一块云计算数据进行加密,实现云数据的动态更新,结果显示,提出的更新方案可以有效减少云数据更新的时间开销。
基于以上研究背景,提出基于数据挖掘的业务系统元数据文档自动更新模型,将数据挖掘应用到业务系统元数据文档的自动更新模型设计中,从而提高业务系统元数据文档自动更新性能。
1 业务系统元数据文档自动更新模型设计
1.1 优化设计业务系统元数据文档存储结构
在对业务系统元数据文档的存储结构进行优化设计的过程中,存储结构的基础是采集与触发业务系统元数据,通过触发业务系统建立缓冲区,利用系统中的预处理模块将元数据文档发送到主控计算机[6],通过对元数据文档进行聚类处理,分析缓冲区元数据文档的频谱,结合抗干扰操作,保证业务系统元数据文档在存储过程中的负载均衡性。业务系统元数据文档存储结构如图1 所示。
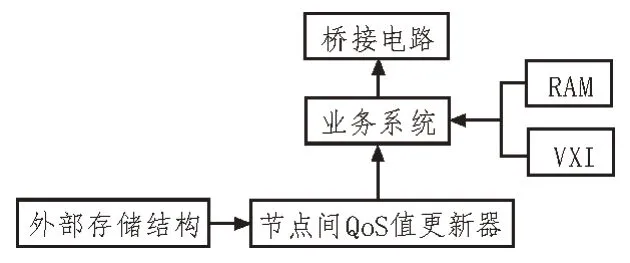
图1 业务系统元数据文档存储结构
对于业务系统元数据文档而言,先采用非线性时间序列重组的方式[7],对业务系统中的元数据文档进行重组,假设元数据文档在业务系统中的任意两个聚类簇为Ki和Kj,采用分布式自适应筛选的方式,压缩业务系统元数据文档的特征,过滤并删除冗余数据文档,建立元数据文档特征压缩器,表示为:

式中,Ai表示业务系统元数据文档的幅值,θi(t)表示相位。
根据业务系统中元数据冗余数据具有的丢失文档特征,采用特征压缩器得到一个最优函数[8],对元数据文档特征进行匹配,得到压缩处理后的元数据文档分块输出结果,表示为:
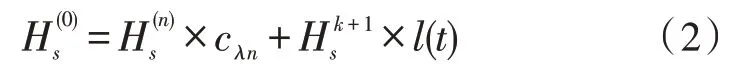
采用以上步骤对元数据文档进行处理后,可以降低业务系统的存储开销,采用数据挖掘算法对元数据文档进行聚类操作,优化元数据文档的存储结构[9]。数据挖掘算法的输出函数表示为:

式中,Gh表示元数据文档在计算过程中的开销负载量,φ表示权重值,Hi表示冲击响应函数,m×n表示元数据文档的幅值。
元数据文档的聚类属性特征产生之后,需要对其进行聚类,为了减少元数据文档在存储过程中的冗余,令元数据文档在存储空间中的存储介质性能衰减函数为:
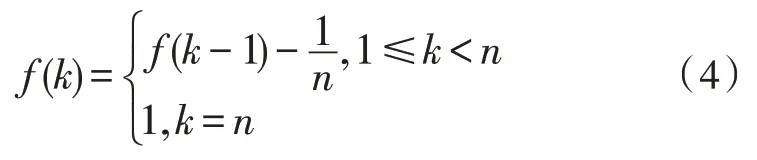
式中,k表示元数据文档的特征融合中心,那么得到元数据文档的融合集合为:

式中,q1、q2,…,qm分别表示元数据文档在融合时的嵌入维度系数。
假设X=[X1,X2,…,Xk,…,XN]T表示业务系统中元数据文档分布的训练样本集,采用数据挖掘算法对元数据文档进行处理[10],得到业务系统对元数据文档的存储区域函数,表示为:
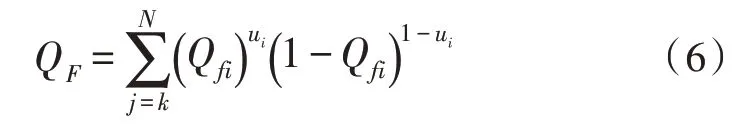
式中,Qfi表示元数据文档在挖掘时的聚类中心,N表示元数据文档的采集频率,ui表示数据挖掘的模糊隶属函数。
利用以上步骤,完成业务系统元数据文档存储结构的优化设计。
1.2 检索业务系统元数据文档
通过对业务系统元数据文档存储结构进行优化设计,可以将原始的元数据文档过滤,但是往往忽略了业务系统包含的元数据文档[11]。可以通过采用数据挖掘算法确定业务系统元数据文档的重要性,判断元数据文档在检索时的优先级顺序,对元数据文档进行检索。
假设B和Bi分别表示业务系统元数据文档的页面,在Bi中存在一个指向B的连接,这就说明Bi的拥有者认为B是重要的,将Bi的一部分重要性赋予给B,记做,其中,P(B)表示元数据文档页面B的PageRank 值,C(Bi)表示元数据文档页面Bi中的出链数量,P(B)的计算公式为:
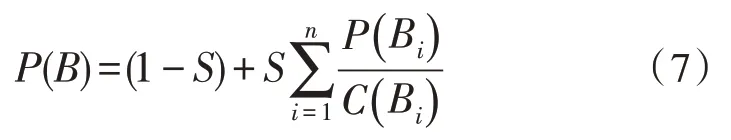
式中,S表示阻尼系数,通过调节S的大小可以调节业务系统中其他元数据文档页面对B的重要性。
在业务系统中,从锚文本和URL 地址两个方面,分析元数据文档的主题与链接的相关性,计算公式为:

式中,M表示特征词总数。
对R1和R2进行加权平均运算[12],可以得到元数据文档的主题相关度计算公式,即:
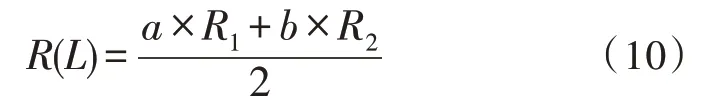
根据式(10)的计算,可以得到PageRank 值,通过判断元数据文档在检索过程中的优先级顺序,对元数据文档进行检索,完成业务系统元数据文档的检索。
1.3 构建业务系统元数据文档自动更新模型
基于业务系统元数据文档的检索,可以通过以下过程对业务系统元数据文档进行更新。业务系统元数据文档在更新前,需要提取出元数据文档,将更新前和更新后的相同数量元数据文档进行叠置并比较,实现元数据文档的增量式更新[13]。
令元数据文档在更新之前的集合为A′,表示为:

式中,m表示更新之前的元数据文档对象。更新之后的元数据文档集合为B′,表示为:

式中,v表示更新之后的元数据文档对象。将A′与B′合并,得到集合C′,表示为:

综上,可以得到元数据文档的增加集合,表示为:

元数据文档的删除集合,表示为:
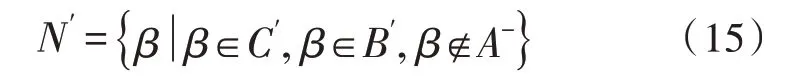
根据以上过程得到的元数据增量文档就是增加部分和删除部分,需要将其分别储存在增加表和删除表中[14],便于后续的更新。
业务系统中元数据文档的增量融合是更新环节中最重要的一步,其将元数据的增量文档写到目标数据库中,对元数据文档进行更新[15]。由于元数据文档在增量识别过程中已经将其划分为增加和删除两部分,因此对元数据文档的增量融合就是其处理过程。对于增加元数据文档中的增加表来说,文档的处理过程比较简单,只需要将元数据文档增加表中的要素转移到目标层[16]。
在元数据文档的识别与融合过程中,通过数据挖掘算法实现业务系统的同步更新,实现元数据文档的自动更新。综上所述,通过优化设计业务系统元数据文档存储结构,检索了业务系统元数据文档,结合业务系统元数据文档自动更新模型的构建,实现了业务系统元数据文档的自动更新。
2 实验对比分析
为了验证基于数据挖掘的业务系统元数据文档自动更新模型的性能,引入文献[4]和文献[5]的元数据文档自动更新模型进行对比,从自动更新召回率、更新效率两个方面进行测试,3 个模型的召回率测试结果如图2 所示。
从图2 的结果可以看出,随着元数据文档数量的增加,3 个元数据文档自动更新模型的召回率都在逐渐增加。该文模型的召回率增加较快,当元数据文档数量达到500 个时,召回率达到了90.5%,当元数据文档数量达到3 000 个时,召回率达到了91.5%,而其他两个元数据文档自动更新模型的召回率还不到82%,说明基于数据挖掘的业务系统元数据文档自动更新模型在召回率方面具有明显的优势。
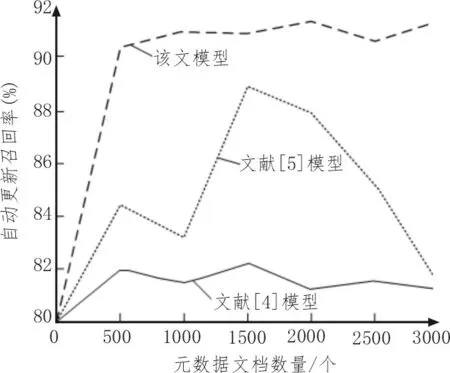
图2 不同模型召回率测试结果
3 个元数据文档自动更新模型的更新效率测试结果如图3 所示,采用更新耗时来衡量元数据文档的自动更新效率。

图3 不同模型元数据文档自动更新效率测试结果
从图3 的结果可以看出,基于数据挖掘的业务系统元数据文档自动更新模型在对元数据文档进行自动更新时,更新的时间是最短的,由于该更新模型在业务系统中可以对元数据文档的存储结构进行优化设计,并利用数据挖掘算法减少业务系统中的元数据文档传输量,减少了元数据文档自动更新的用时,提高了业务系统元数据文档的自动更新效率。
3 结束语
该文提出了基于数据挖掘的业务系统元数据文档自动更新模型,采用数据挖掘算法对元数据文档的存储结构进行了优化设计,通过检索业务系统元数据文档,构建了业务系统元数据文档自动更新模型,实现了元数据文档的自动更新。结果显示,该更新模型在召回率和更新效率方面具有更好的性能。
