LiDAR点云特征变量对天然林林分因子模型反演的影响研究
2022-09-02王浩伟王照利杨佳乐段梦琦
王浩伟, 王照利, 杨佳乐, 段梦琦
(1.中煤航测遥感集团有限公司,西安 710199; 2.国家林业和草原局西北调查规划设计院,西安 710048)
0 引言
传统森林资源调查多利用卷尺、测高器等工具进行人工测量,受各种条件的限制,劳动强度大,费时费工,而激光雷达技术的出现为林业资源调查提供了新的思路与方法[1]。激光雷达具有与被动光学遥感不同的成像机理,对植被空间结构和地形具有较强的探测能力,特别是在森林高度探测方面具有其他遥感技术无法比拟的优势[2]。通过激光雷达获取林区三维空间点信息,并在此基础上分离植被特征,进而实现森林资源的估测。
通过点云数据获取的特征变量,由于其描述的森林信息不同,对不同林分因子的相关性也各不相同。多数学者在利用激光雷达点云数据进行林木因子估测时,往往将提取到的所有特征变量作为输入参数送入相关回归算法中直接进行计算,由于没有对繁多的特征变量进行筛选,存在如下问题:
1)提取的特征变量与林分因子之间相关性较差,使用该特征进行林木因子估测不具有可靠性。
2)提取的特征变量之间存在较强的线性相关性,模型训练时使用冗余的特征相当于加入了大量的噪声数据,使得模型训练过程易产生震荡,导致稳定性较低。
3)特征过多容易造成存储空间和处理时间的浪费,模型收敛速度降低,甚至会对决策的制定造成误导。
本文针对天然林实验区,研究并分析了不同特征值对不同林分因子模型反演的影响,通过实验计算出特征变量对模型的贡献值,根据贡献权重的不同,对特征变量进行筛选,保留核心特征子集,并对其进行回归分析,从而生成合适的模型。通过对特征变量的权重分析与重要性评估,实现了特征集合的降维处理,既能够保持特征集合不失真,又能够消除特征集合中冗余的特征属性。
1 研究现状
苏迪等以点云和正射影像为研究对象,利用冠层高度模型提取高程,并通过一元线性回归分析估测平均树高和平均胸径模型[3];吴思敏等以广西高峰林场为研究对象,借助机载激光雷达点云,构建不同分辨率的冠层高度模型,结合地面实测数据,提出一种结合自适应阈值与峰值探测提取林分平均高的方法[4];许子乾等从集成高分辨率无人机影像和LiDAR两组点云数据中提取特征变量并进行亚热带森林林分特征反演[5]。李旺等利用机载激光雷达点云数据,结合实测单木结构信息,分别从样地和单木尺度估算森林地上生物量[6]。上述学者对获取到的特征信息均未进行权重比较,不能排除噪声数据的干扰。
2 研究区概况
研究区位于陕西省安康市岚皋县国营林场,属北亚热带大陆性季风气候,林场位于巴山北坡,平均海拔1 400m,属天然次生林,适应各种林木的生长,森林资源丰富,植被较好。此次用于实验的林场位于岚皋县南部,面积约300km2,活立木蓄积量约为461.49万立方米,林区树种主要包括桦、栎、华山松、云杉等。
3 研究方法
传统林分因子反演使用激光雷达点云数据提取冠层高度模型,并以此为基础提取相关的特征变量,结合样地实测数据进而完成模型训练。本文在该技术的基础上新增特征权重分析模块,通过对特征变量权重的比较分析筛选出最优核心特征变量子集,从而实现模型精度的提高(图1)。
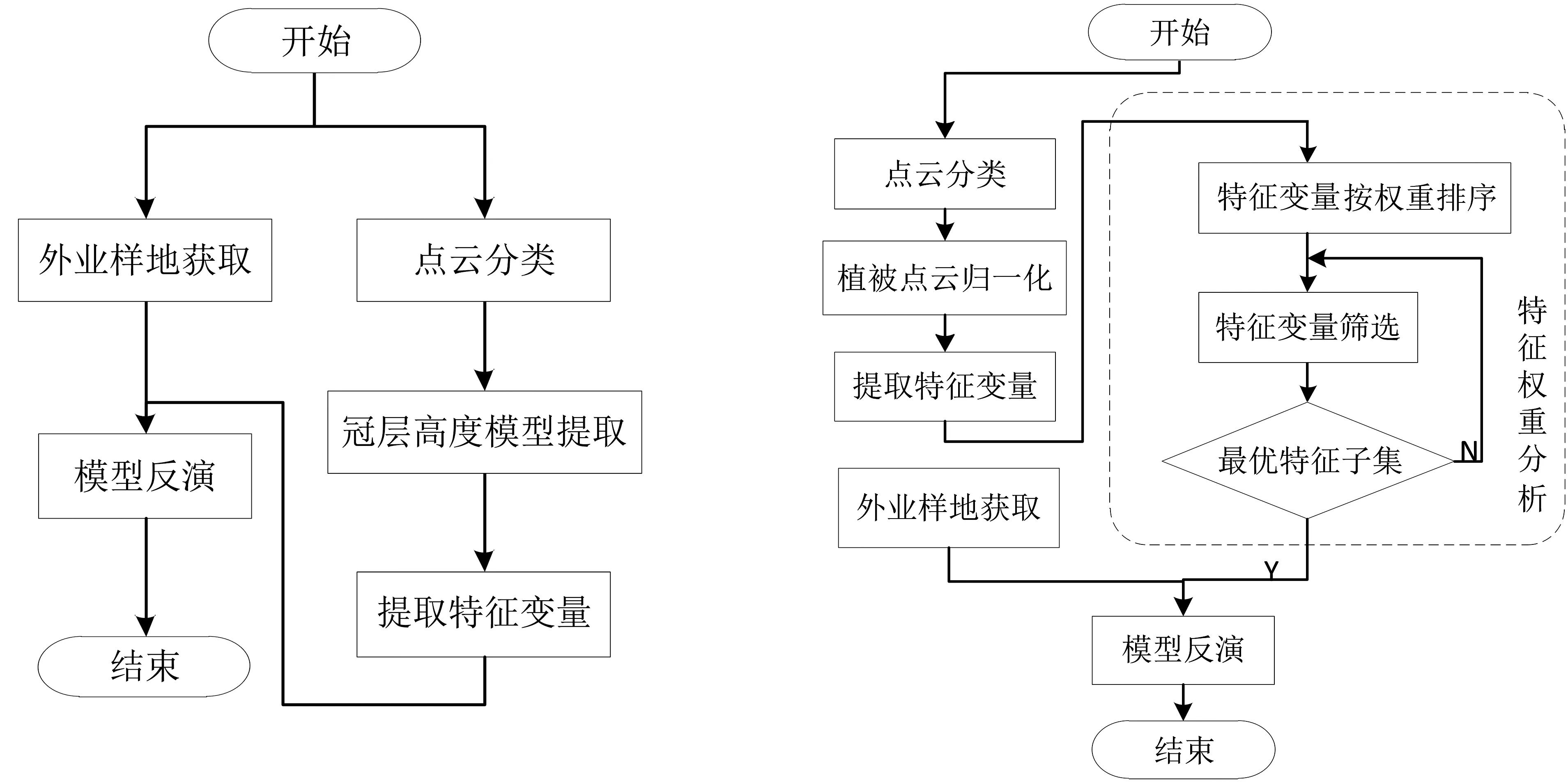
a.传统林分因子反演流程 b.本文改进的林分因子反演流程
3.1 样地数据获取
2021年3—4月在岚皋县国营林场内,布设方形样地115块,样地面积为667m2,均为硬阔林。每块样地中心点使用实时动态差分技术(Real-Time kinematic,RTK)进行精密定位,精度控制在2~3cm内[7]。对样地进行每木检尺,记录其树高、胸径、材积等,记录样地的蓄积、株数及郁闭度等森林参数[8](表1)。
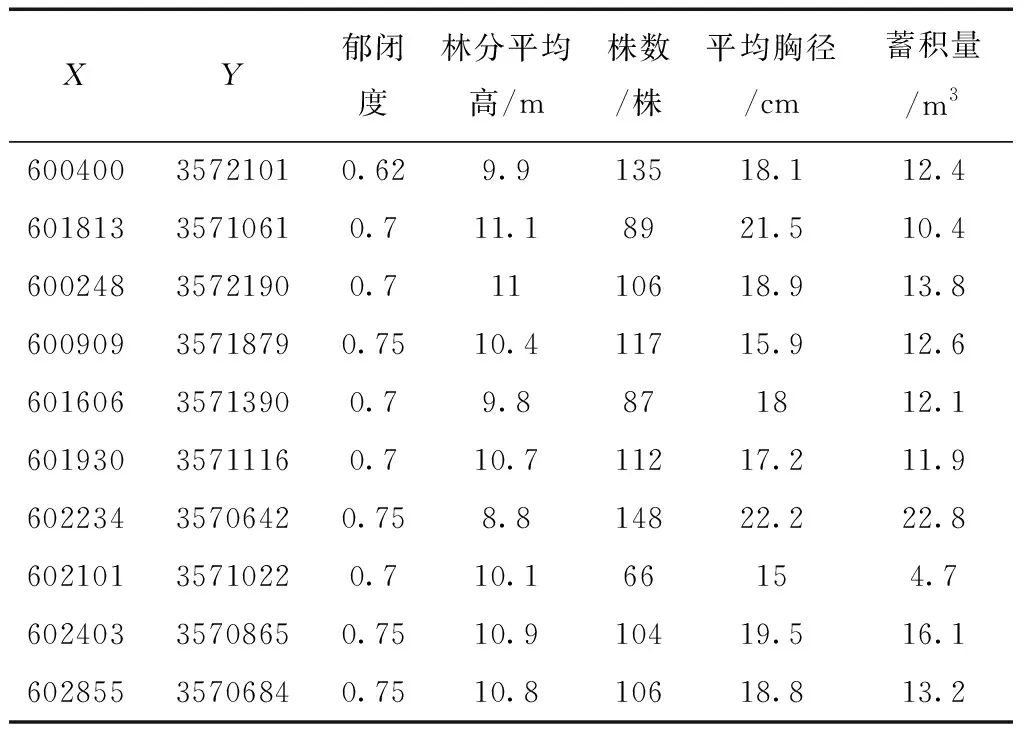
表1 部分样地外业调查情况
3.2 LiDAR点云数据获取
2021年5月,使用机载激光扫描仪,搭载Phase OneIXA 180数码相机,在研究区同步获取50km2范围内激光雷达点云数据及航空正射影像数据。飞行速度为250km/h,激光发射频率为400kHz,扫描速率为106lps,点间距优于70cm,点云数据均匀分布于作业区。
3.3 LiDAR点云数据预处理
(1)滤波与分类
滤波是基于去噪后的点云数据进行分离地面点和非地面点的操作[9]。经过近几十年国内外学者的研究,已经形成了众多研究成果,如主动轮廓线法、分级稳健内插法、数学形态学滤波法、移动窗口滤波法等[10]。本文使用渐进加密三角网算法对研究区点云数据进行地物点与地面点的分类。首先在粗放的尺度寻找地面点,并根据这些地面点建立粗尺度的TIN网络表面;随后逐一判断其余的三维点与所构三角网的垂直距离与位置关系,当距离小于阈值,就将该点纳入并重构新的TIN表面,否则将该点删除。如此往复,逐步纳入新的地面点,直至所有点判断完成。对于非地面点云再根据高程阈值实现植被点云的分类。分类前后对比情况如图2所示。

a.点云分类前 b.点云分类后
(2)植被点云归一化
归一化的植被点云是描述森林垂直结构参数的重要指标,对于森林参数反演估测有着重要作用。通常使用地物点云与地面点云生成数字高程模型(Digital Elevation Model,DEM),与数字表面模型(Digital Surface Model,DSM)相减得到,将植被点云归一化至同一水平线上,从而去除地形起伏对树木高度及生长形态的影响[11]。本文在生成归一化的植被点云时,直接计算分类后的植被点云数据相对于地表的垂直高度,从而减少因点云栅格化引起的精度丢失。另外,在计算时忽略高程值为0的点,可减少空白点对后续操作的影响[12]。样地归一化植被点云按高程渲染结果如图3所示。

a.样地点云 b.样地归一化植被点云
3.4 基于归一化植被点云的特征变量提取
归一化后的植被点云数据仍包含有植被类别的所有空间信息,对其空间结构位置的分析能够分离出描述植被信息的特征参数[13]。针对归一化的植被点云数据,提取能够表征林木特点的特征变量,主要包括高度特征、密度特征、其他特征。其中,高度特征描述林区植被垂直结构特性[14],本文将植被点云的高程值按升序排序,并记为Hveg,提取的高度特征变量及其描述如表2所示。

表2 高度特征变量
密度特征描述植被点在林区全部点云数据中所占的比重,为准确区分不同高度点云在总体数据中的密度情况,针对不同高度的植被点分别计算其密度特征,并按升序排序,记为Dveg,具体描述如表3所示。
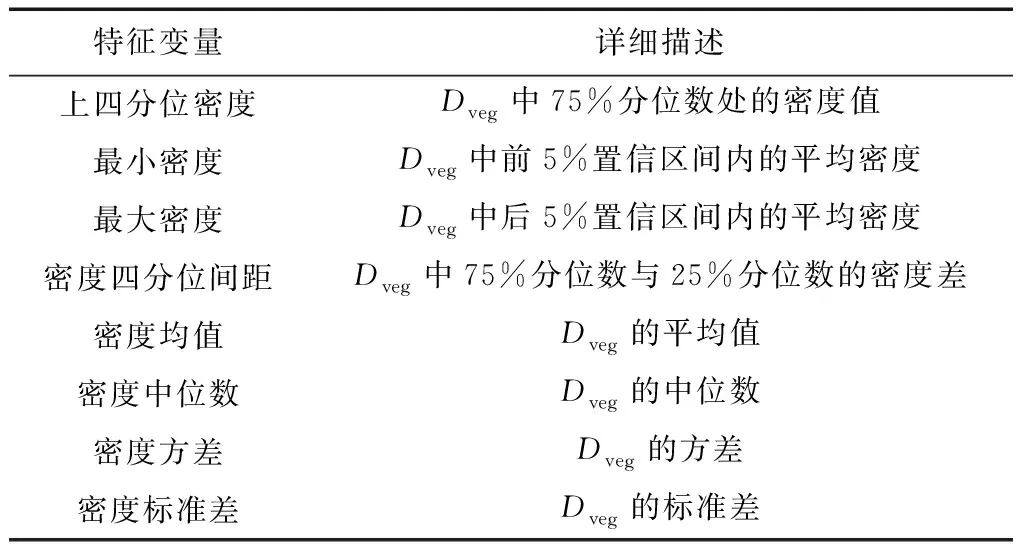
表3 密度特征变量
除高度特征及密度特征外,根据研究区中点云数据不同类别点的个数可以描述植被的其他特征变量,具体描述如表4所示。

表4 其他特征变量
3.5 基于随机森林的特征权重分析
(1)
式中:K为有K个类别;pmk为节点m中类别k所占的比例。特征Xj在节点m的重要性,即节点m分值前后的Gini指数变化量为
(2)
式中:GIl和GIr分别表示分支后两个新节点的Gini指数。如果特征Xj在决策树i中出现的节点为集合M,那么Xj在第i颗树的重要性为
(3)
假设随机森林中共有n颗树,那么
(4)
最后将所有求得的重要性评分做归一化处理即可得到每个特征变量的特征权重,最大值为1,该值越大越重要,即与因变量密切相关,对因变量的变化影响较大,对决策的指定起决定性作用。在进行反演时,将提取的特征提供给随机森林模型,并通过特征权重分析比较各特征变量对林分因子反演的贡献程度,根据其贡献值排序,从而对特征变量集合进行筛选,去掉冗余特征变量,保留核心特征子集,目标预测更为准确。具体步骤如下:
1)将提取到的高度特征Dheight、密度特征Ddensity及其他特征Dother,组合为特征变量Dall,并使用线性函数转换法,将所有特征变量取值范围映射到[0,1]区间内,得到Dnormalize。
2)将归一化后的全部特征变量送入随机森林回归器中进行模型训练,以Dnormalize为自变量,待预测的林分因子为因变量,多次实验选取最优参数结果,以该模型精度作为基准分数Scorebase,并记录该模型中各特征变量的贡献。
3)反复实验,在保证Scorebase不降低的前提下,分别删除权重低的特征变量,并用减少后的特征子集重新训练模型,记录分数。
4)最终保留分数最高的模型所对应的特征变量组合Dbest,以此作为该因变量的最优特征变量子集。
由于一些特征属性对于决策的制定所做出的贡献度低,因此将其去除后并不影响对信息的理解与表达。通过权重分析筛选后的特征变量去除干扰特征对模型精度的影响,降低无效特征变量对训练过程的干扰,在一定程度上提高模型精度。
4 结果与分析
4.1 不同林分因子的特征权重对比分析
针对研究区内布设的115块样地开展实验,使用随机森林算法分别对蓄积量、林分平均高、株数这三个森林因子进行回归预测,并在保证模型精度不降低的前提下不断缩减特征变量个数,找到对模型贡献最大的特征子集,记录每个特征变量的权重值,为各个林分因子找到本研究区下的最优特征子集(图4至图6)。
本文使用的精度验证指标为拟合优度R2,该值越大则因变量与自变量之间的相关性越强,其定义如公式(5)所示:
(5)
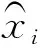
图4中a,b展示了在进行特征权重分析前蓄积量的反演情况,c展示了蓄积量因子在使用特征子集时的反演情况,拟合精度为0.915,相比之前有所提升,d展示了在当前拟合精度下使用的特征变量及其权重,上四分位数高程、最大高程、郁闭度、上四分位密度、最小密度、最大密度所占权重分别为0.576、0.23、0.161、0.016、0.013、0.004。
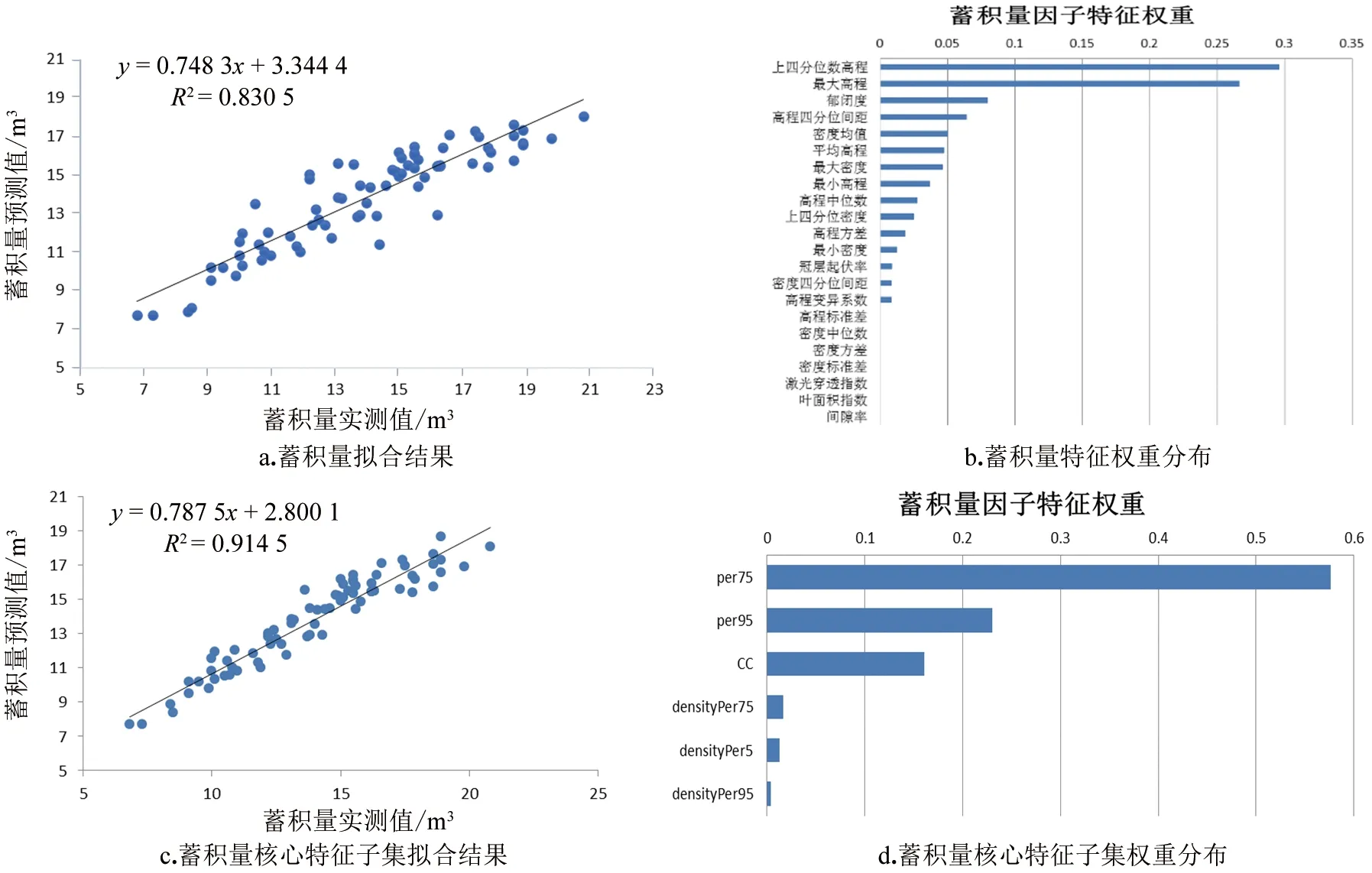
图4 蓄积量因子拟合结果及特征权重分析Figure 4 Accumulation factor fitting results and feature weight analysis
图5中a,b展示了在进行特征权重分析前林分平均高的反演情况,c展示了林分平均高因子在使用特征子集时的反演情况,拟合精度为0.923,相比之前有所提升,d展示了在当前拟合精度下使用的特征变量及其权重,上四分位数高程、平均高程、高程中位数、最大高程、冠层起伏率、上四分位数密度、高程方差、最小密度、高程四分位间距所占权重分别为0.36、0.229、0.167、0.075、0.052、0.048、0.037、0.026、0.006。
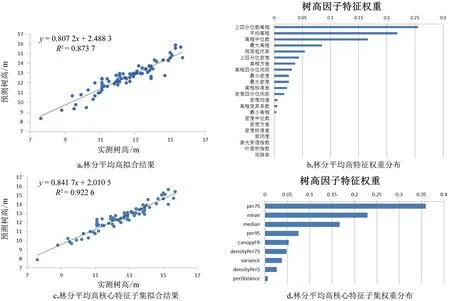
图5 林分平均高拟合结果及特征权重分析Figure 5 Analysis of stand average high fitting results and feature weights
在进行株数的反演时,将蓄积量作为其中的一个特征变量进行权重分析,图6中a,b展示了在进行特征权重分析前株数的反演情况,c展示了株数因子在使用特征子集时的反演情况,拟合精度为0.902,相比之前有所提升,d展示了在当前拟合精度下使用的特征变量及其权重,蓄积量、高程方差、最大高程、间隙率、叶面积指数、上四分位数高程所占权重分别为0.403、0.333、0.195、0.044、0.013、0.012。
图6 株数因子拟合结果及特征权重分析Figure 6 Plant number factor fitting results and feature weight analysis
4.2 不同点云密度下模型精度对比分析
为验证本方法的稳定性,对不同点云密度下的LiDAR数据开展实验分析。对实验区点云数据进行均匀抽稀,并保证稀释后的结果能覆盖到所有类型的点云。分别以2、3、4倍的间距对点云进行均匀抽稀处理,得到不同密度的点云数据,并根据不同密度的点云数据分别进行试验,获取不同密度下相关林分因子的模型精度及相对均方根误差,实验结果如表5所示。
除拟合精度外,本文还使用相对均方根误差RRMSE对实验结果进行评价,RRMSE为实测值与预测值偏差的平方和样地数量比值的平方根再与实测值的算术平均数之比,该值越小,则模型预测的效果越好,其定义如公式(6)所示。
(6)
由表5可知,在不同的点云密度下,对于蓄积量、林分平均高及株数三个林分因子,通过分析特征权重后保留的特征子集在森林因子回归计算时均取得较好的精度结果。另外,由于评估了不同特征的重要性程度,使用筛选后的特征子集与原始特征相比在模型构建方面仍保持较高的精度,并且对不同的点云密度均具有较好的适应性。
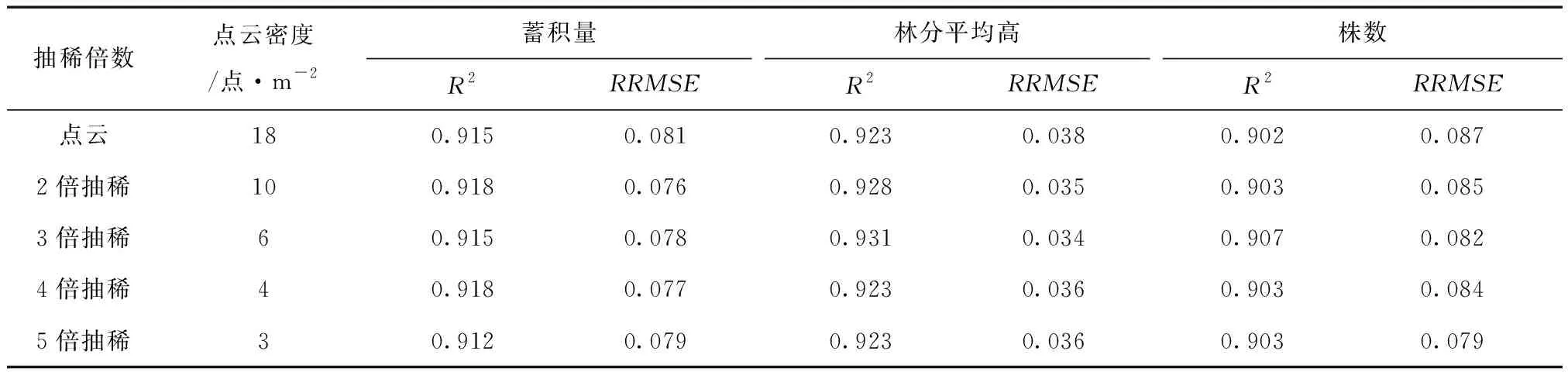
表5 不同点云密度下的各林分因子拟合精度
5 结论与讨论
机载激光雷达点云穿透性及抗干扰力强,应用于森林资源调查能够去除地形影响,有效提高调查精度。本文以陕西省安康市岚皋县国营林场为研究对象,借助机载激光雷达点云,对天然次生林进行植被点云归一化,并提取实验区森林特征参数变量,提出一种在特征变量权重分析基础上进行林分因子反演的技术流程,结合大量实验结果进行特征权重评估,保留权重高的核心特征变量,并通过实验验证该技术的有效性及稳定性。实验结果表明:
1)保留的特征变量子集与林分因子之间的相关性较强,能够全面清楚地描述林木特征,具有较高的拟合精度。
2)在不同点云密度下,基于高权重特征变量训练的回归模型均具有良好的鲁棒性。在保证抽稀后点云均匀分布的前提下,拟合精度及相对均方误差受每平方米点个数的影响较小。
本研究使用到的特征变量主要包括高度特征及密度特征,对林区特征描述存在一定的局限性,后续研究可以利用点云多次回波的特性,提取回波次数及强度等特征变量进行实验研究。
