基于Python 爬虫的旅游网站数据分析与可视化
2022-09-02赵蔷
赵蔷
(咸阳师范学院计算机学院,陕西咸阳 712000)
我国旅游业在国家的大力推动下出现了高增速的发展状态,旅游业已成为我国GDP 的重要组成部分,是具有显著发展速度与竞争优势的产业[1]。据旅游部发布的数据显示,旅游业对GDP 综合贡献从2014年的6.61万亿元上升到2018年9.94万亿元,旅游业GDP比重占总GDP贡献榜单的11.04%。2018年我国从事旅游行业和相关产业的就业人数达7 991 万人,占全国就业总人口10.3%[2]。与此同时,在线旅游服务作为新兴的生活模式,在国内发展十分迅速,已成为旅游业的中流砥柱[3]。
在线旅游是指旅游消费者通过网络向旅游服务提供商预定旅游产品或服务,并通过网上支付或者线下付费,旅游主体通过网络进行旅游产品营销[4]。在此过程中,人们通过搜索引擎浏览和查询相关旅游信息。而随着海量数据的出现,搜索引擎技术凸显了其重要性[5]。为了快速搜索到所需信息,聚焦网络爬虫引起人们关注。
结合旅游网站的特点,创建基于Python 的聚焦型网络爬虫,爬取旅游网站的数据,然后通过数据分析和可视化,给出全国热门旅游城市和地区的分布和排名情况。
1 网络爬虫技术
网络爬虫(Web Crawler)是一种按照一定规则自动抓取万维网信息的程序或者脚本[6],被广泛应用于搜索引擎以及相关网站的设计。爬虫技术在数据分析、科学研究、web 安全、舆情监控等领域都有广泛应用。在数据挖掘、机器学习、图像处理等科学研究领域,通过编写爬虫脚本程序在网上爬取信息,为理论研究提供数据[7]。网络爬虫主要分为以下几种类型:
1)通用型网络爬虫[8]。其针对的目标范围最广,又被称为全网爬虫,缺点是爬行效率低而且对于网页抓取数据的质量难以保证。
2)增量式网络爬虫。将已经爬取过的网页作更新和添加操作,其时间成本小但实现难度较大,算法要求高[9]。
3)Deep web爬虫。可分为surface web和deep web,前者针对表层网络和深层网络,主要用来对大多数静态网站页面进行爬取,后者则是对动态网页进行爬取[10]。
4)聚焦型网络爬虫。也称为主题网络爬虫,其原理是在通用网络爬虫的基础上添加机制和步骤,以实现特定的功能需求[11]。通过制定相关规则,过滤掉已经抓取或不需要的数据,能够在短时间内从网络上抓取大量有用数据,这种爬虫目标明确且工作量较小[12],是目前应用较多的一种网络爬虫。
聚焦型网络爬虫的实现原理如下:
①根据数据需求和功能需求,定义爬虫程序的爬取目标,对爬取目标内容进行描述;
②获取初始的URL,即最初的网址;
③根据去哪儿网初始的URL 爬取页面,并获得新的URL,每一个被爬取数据的URL 都是不同的,爬取一个数据后,把这个URL 加入到已爬取URL 列表里,接着获取新的URL,此过程本质是去重和判断是否已爬取内容;
④在新的URL 中,过滤掉与定义爬取目标不相关的链接和信息数据;
⑤将判断和过滤的URL 链接地址加入到URL队列里面;
⑥再次获取URL,重复以上步骤直到满足设置的停止条件时,或无法获取新的URL地址时,停止爬取。
聚焦型网络爬虫的原理如图1 所示。
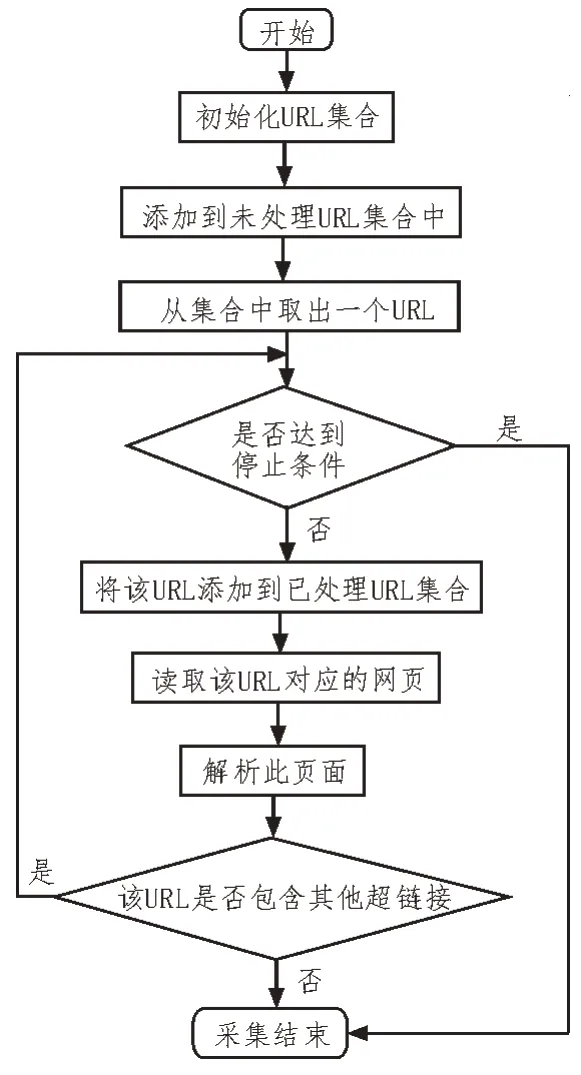
图1 聚焦性网络爬虫的流程图
2 基于Python的旅游网站爬虫
为了获取旅游网站的大量旅游信息并进行分析,研究的内容包含四部分:聚焦型网络爬虫、数据储存、数据预处理以及数据分析与可视化。
2.1 聚焦型网络爬虫
创建专门针对旅游网站的聚焦型网络爬虫,针对旅游网站的目标数据进行爬取。以Python 语言和Scrapy 框架创建Scrapy 项目,在CMD 窗口中,运行scrapy startproject 命令创建爬虫项目框架,其中包含项目配置文件、Python 模块、item 文件、piplines 管道文件、爬虫目录等。通过建立Cookie 池定时更换Cookie、伪装user-agent、设置爬取时间间隔来应对网页的反爬。
2.2 数据储存
随着大数据与云计算的发展,MongoDB 作为一种非关系型数据库,其使用越来越广泛。MongoDB是一个面向文档存储的数据库[13],它将数据存储为一个文档,数据结构由键值(key=>value)对组成,字段值可以包含其他文档/数组及文档数组。MongoDB能够为web 应用提供可扩展的高性能数据存储解决方案[14],具有高性能、可扩展、易部署、易使用、存储数据非常方便等特点。
使用非关系型数据库MongoDB 储存从网络爬取的数据,在Pycharm 编辑器下进行MongoDB 数据库的可视化配置安装,首先执行启动操作,等待连接建立,当连接被建立后,开始打印日志信息,然后使用MongoDB shell 来连接MongoDB 服务器。
2.3 数据预处理
数据预处理模块主要负责对数据采集模块所获取的原始数据做进一步的处理与分析,消除网页噪声、去除重复网页及利用网页文字分词技术进行网页内容和特征项的提取。
在数据清洗环节,一般从数据的合法性、完整性、唯一性和正确性对采集的数据进行检验。对去哪儿网上采集的旅游数据进行清洗也是从这几方面进行的,并使用排序算法以及isnull 和drop 等技术对数据进行检验和清洗。清洗之后的旅游数据信息完整准确,文件中包含区域、名称、景点id、类型、级别、热度、地址、特色、想要去哪里旅游、哪些城市等信息字段。
2.4 数据分析与可视化
数据可视化能够更加有效、直接地反映数据,也有利数据分析,可以采用柱状图来展现全国各个城市旅游地区的热度。旅游地区的热门程度通过该地区内旅游景点受关注程度体现,景点的主要参照点是级别和热度。根据热门景点的出现次数,并结合其热度对全国旅游热门地区进行统计分析。根据地区内热门景点的出现次数,对其求和从而得到该地区的热门程度。
大陆所有省、市、自治区热门旅游地区的旅游热度饼图如图2 所示。
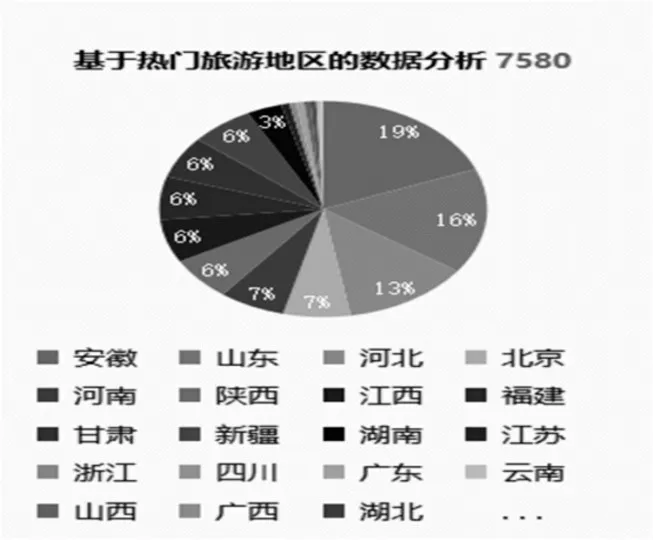
图2 热门地区的热度统计饼图
从图2 可以看出,全国排名前十位的热门旅游省份分别是安徽省、山东省、河北省、北京市、河南省、陕西省、江西省、福建省、甘肃省和新疆维吾尔自治区。其中排在前三位的省份内景区所有采集到的信息比重已经超过了10%,第三名的河北省已经达到13%。
3 绘制词云
词云(WordCloud)是目前流行的可视化方法,是文字组件的一种[15]。词云通过字体的大小反映分词出现的频率,是由词汇组成类似云的彩色图形,对网络文本中出现频率较高的关键词予以视觉上的突出显示,形成“关键词云层”或“关键词渲染”,从而过滤掉大量文本信息,使浏览者一眼扫过文本就可以领略其主旨。词云的作用是快速感知最突出的文字、快速定位按字母顺序排列的文字中相对突出的部分,其本质是点图,是在相应坐标点绘制具有特定样式的文字的结果[16]。
在Pycharm 里面完成词云的生成。首先下载Pycharm 第三方库中文jieba 分析词库,通过第三方库Pandas 和Matplotlib、wordcloud、PIL 和numpy 实现数据可视化,读取数据并保存到脚本文件,通过在前面加入#encoding=gbk 防止出现格式错误,使用jieba分词提取所爬取数据中的高频率分词,绘制300×400 大小的画布,导入词云的背景图生成词云。
对“去哪儿网”上大陆所有省、市、自治区的旅游热度进行统计,其词云如图3 所示。

图3 大陆所有省市自治区旅游热度词云
对“去哪儿网”上大陆地区旅游热度排名前15的省、市、自治区进行统计,其词云如图4 所示。

图4 排名前15的旅游热门地区热度词云
4 结论
通过研究网络爬虫技术,提出一种专门针对旅游网站的聚焦型网络爬虫,使用MongoDB 存储爬取的数据,并进行预处理,最后使用Pandas库和Matplotlib库等第三方库进行数据分析和可视化,统计热门旅游地区排名情况。实验结果表明,提出的聚焦网络爬虫能够提高对旅游数据的检索效率,在旅游网站海量数据里快速找到所需信息,能够为旅游爱好者以及同时为各地区、景点优化服务提供参考,促进旅游行业的发展。
由于聚焦型网络爬虫的局限性,不能实时更新数据。后续的研究工作将对系统进一步优化,将聚焦网络爬虫和增量网络爬虫相结合,用于旅游网站的数据爬取。
