面向非均衡类别的半监督辐射源识别方法
2022-09-01谭凯文张立民闫文君徐从安凌青刘恒燕
谭凯文 张立民 闫文君 徐从安 凌青 刘恒燕
(海军航空大学信息融合研究所 烟台 264001)
1 引言
特定辐射源识别(Specific Emitter Identification,SEI)是指从接收信号中提取细微差异用于关联单个辐射源的技术[1]。随着物联网(Internet of Things,IoT)应用的大规模普及和IoT接入设备数量的迅速增长,高效、安全、稳定的物联网设备认证方案是防范恶意攻击、确保用户隐私安全的关键[2]。由于发射机的物理层缺陷不可避免且难以复制,例如功率放大器的非线性失真[3—5],因此相比于采用协议分析、MAC地址关联或密钥验证的无线设备认证技术,基于物理层射频指纹(Radio Frequency Fingerprint,RFF)提取的SEI方法可靠性更强。根据发射机的工作特点,现有的辐射源识别技术通常可划分为瞬态方法[6—8]和稳态方法。瞬态方法利用发射机开关瞬间产生的状态畸变用于特征提取,但这类畸变持续时间通常较短,且性能易受噪声及非理想的信道条件影响发生恶化。相比于瞬态方法,稳态方法从发射机传输的稳定信号中提取RFF用于分类,因而应用更加广泛。包括高阶累积量(Higher Order Cumulant,HOC)[9,10]、希尔伯特变换(Hilbert Transform,HT)[11—13]、无意调相特征[14]、变分模态分解(Variational Mode Decomposition,VMD)[15]和功率谱密度(Power Spectral Density,PSD)[16]等在内的手工特征已经被证明是有效的稳态RFF,但上述基于变换域分析的稳态特征提取依赖大量的先验知识,且特征提取的有效性易受传输数据影响,导致算法的泛化性降低。
近年来,以卷积神经网络(Convolution Neural Network,CNN)为代表的深度学习(Deep Learning,DL)模型凭借其特征检索能力在SEI中表现出巨大潜力[17—22]。Merchant等人[17]开发了基于时域复基带误差信号输入的CNN框架,在一组7个 2.4 GHz商用ZigBee设备上实现了92.29%的识别精度;Qian等人[18]将从CNN中提取的隐藏浅层特征和深层特征与船舶自动识别系统(Automatic Identification System,AIS)信号拼接为多级字典,并使用主成分分析(Principal Component Analysis,PCA)方法进行基于稀疏表示的字典识别;Wu等人[19]提出了一种基于长-短记忆结构(Long Short-Term Memory,LSTM)的递归神经网络(Recurrent Neural Network,RNN)用于自动识别硬件特征,在信噪比(Signal to Noise Ratio,SNR)低至—12 dB的情况下仍能实现较高的检测精度;Wang等人[20]提出了一种基于雷达脉冲波形和CNN结合的SEI方法,通过对全脉冲信号进行建模提取精细的差异特征,并利用小卷积核神经网络进行监督训练;何遵文等人[21]基于多通道变换投影和生成式对抗网络(Generative Adversarial Networks,GAN)设计了一种多特征融合的SEI方法,在多径衰落信道下仍具有较强鲁棒性。
目前基于DL模型的SEI方案通常是在大量标记样本上进行的监督学习。但在实际非合作场景中,受信号采集条件、电子干扰等因素制约,数据集的标签往往不完整,一定程度上限制了监督学习的分类性能[22]。其次,辐射源数据的类别间失衡导致DL模型性能的下降。在类别不平衡的数据集中,大量样本属于少数类别,而多数类别中只包含少量样本。目前处理类不平衡数据的方法大致可分为数据平衡算法和代价敏感算法。数据平衡算法[23—26]通过对样本进行过采样和欠采样以改善训练集的样本分布:过采样是指增加少数类样本以平衡类别数量,欠采样则从多数类样本中进行采样以达到所需的类别分布。Abdi等人[23]提出了一种基于Mahalanobis距离的过采样技术(Mahalanobis Distance-based Over-sampling technique,MDO),通过保留少数类样本的协方差结构并在特征密集区域生成新样本,从而降低类别重叠风险;Bunkhumpornpat等人[24]将密度聚类引入过采样当中,通过求取正样本到少数类别集合的最短路径来生成新样本;Kang等人[25]指出少数类样本可能会向分类器中引入无关噪声,因而提出一种结合噪声滤波器的欠采样框架;Hou等人[26]提出一种基于密度的欠采样算法(Density-Based Under-sampling algorithm,DBU),并将其与AdaBoost进行集成从而保留有效类别。基于数据平衡的方法无法利用来自负类实例的信息,重复的采样将导致数据规模的扩大,提高训练过程中的计算成本,甚至在少数类样本上出现过拟合;而且原始数据分布的改变可能会向分类模型中引入噪声。代价敏感算法[27—30]通过引入类间错误分类因子以改善非均匀的误分类代价。Krawczyk等人[27]提出用于不平衡分类的集成代价敏感决策树,并在随机特征子空间上进行训练,以确保集合的多样性;Duan等人[28]设计基于信息熵的代价敏感支持向量机(Cost Sensitive Support Vector Machine,CSSVM),利用数据集中的信息熵确定CSSVM的惩罚因子值,改善SVM在不平衡数据集上的分类性能;Zhang等人[29]将多分类问题分解为多个二元子问题对,并利用成本敏感反向传播神经网络(Cost-Sensitive Back-Propagation Neural Networks,CSBPNN)进行协同二进制分类;Dhar等人[30]在通用支持向量机(Universum-Support Vector Machine,U-SVM)中为假阳性和假阴性错误提供不同的错误分类成本,在稀疏的高维数据集上表现出较高的识别精度。但错误分类代价的设置依赖基分类器的建模,导致代价敏感函数的可迁移性较差;而且需要具体的语义标签以确定数据的误分类信息,因此面对类别高度失衡的半监督数据集时性能改善有限。
基于此,本文提出一种基于半监督生成式对抗网络和代价敏感学习的SEI方法。该方法利用二元博弈结构挖掘无标记实例的潜在分布特征,并设计类不平衡损失弥补由标记实例置信度不同导致的误分类代价差异。在判别网络中,将残差单元串联以提高梯度传播效率,并嵌入多尺度拓扑模块提取一维时间序列的多维分辨率特征。实验结果表明,该框架提高了无标记样本的利用效率,所设计的代价敏感损失有效提升了对于类别失衡数据集的识别性能。
2 半监督SEI框架
2.1 辐射源信号建模
考虑一个由K个辐射源组成的通信场景,辐射源物理层特征主要来源于功率放大器的非线性系统响应,功放的输入信号s(nT)可表示为

式中,m(nT)表 示基带调制信号,fc和fs分别表示载频和采样频率。引入泰勒多项式描述功放的特异性,功放输出T(i)(·)可表示为
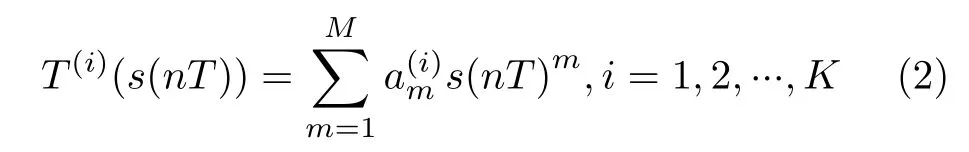
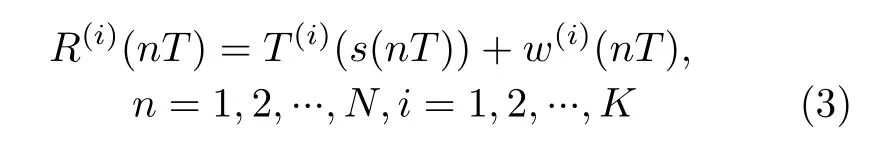
式中,w(i)(nT)为信道加性噪声。
2.2 生成式对抗网络模型
GAN[31]由判别网络和生成网络组成,生成器的目标是输出逼近真实样本分布的数据,判别器对生成器的输出和真实样本进行真假判别,生成器又通过反向传播的梯度信息更新自身参数。生成器的优化目标表示为

式中,V(G,D)表 示待优化函数,z~Pz(z)为输入噪声,D(x)表 示判别器的正确判别概率,G(z)表示生成器输出,E (·)表示期望算子。判别器通过训练提高真假分类能力,其优化目标为
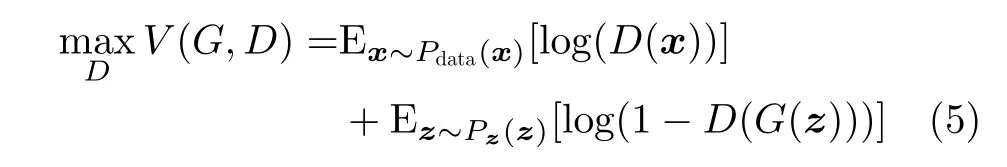
x~Pdata(x)表 示样本服从真实分布,D(G(z))表示判别器将生成样本判别为真实样本的概率。网络的损失函数可表示为

生成器和判别器在二元博弈过程中不断调整优化,当生成样本和真实样本匹配时达到纳什均衡,此时的V(G,D)为全局最优解。
2.3 IC-SGAN网络结构
针对GAN无法有效利用标签和样本之间的互相关信息,对抗训练过程中存在模式崩塌等问题,本文将半监督学习引入GAN框架中,提出了一种面向非均衡类别的辐射源识别方法(Semi-supervised GAN for imbalance category,IC-SGAN),框架在图1给出。
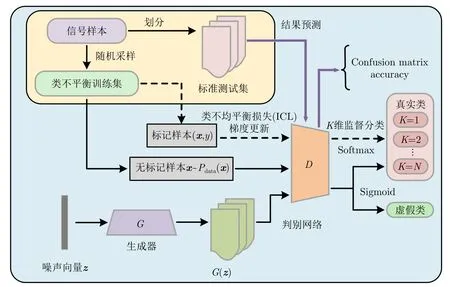
图1 IC-SGAN整体结构Fig.1 The overall structure of IC-SGAN
在IC-SGAN中,生成器的输入为噪声向量z,经过卷积操作后输出样本G(z)以欺骗判别器。判别网络则同时接收生成器输出G(z)、标记样本(x,y)~Pdata(x,y)和无标记样本x~Pdata(x)进行半监督分类。考虑一个存在K个辐射源的半监督分类任务,对于生成器输出G(z)和无标记样本x~Pdata(x),IC-SGAN分别赋予其标签为“0”和“1”,判别网络利用输出层的Sigmoid函数完成对于G(z)和x~Pdata(x)的二元真假判别

式中,xi为二分类矢量中的输出。在无监督部分中,无标记样本被统一视作为真实类别,而生成器的输出G(z)被作为“假样本”,二者共同完成二进制真假判别。在监督部分中,判别器的输入为K类标记样本,利用Softmax函数实现K维监督分类

式中,lk,k=1,2,...,K为K维分类矢量。对于采集到的信号样本,将其随机划分为训练集和测试集,并采样得到类不均衡训练集。定义标记比为标记样本数NL与训练样本数NT的比值,并按照所设置的标记比随机抽取样本对半监督判别网络进行在线训练。训练结束后保存模型并将测试集输入判别网络进行离线测试,选取混淆矩阵、识别准确率作为衡量模型性能的指标。
2.4 损失函数设计


2.5 网络结构搭建
DCGAN[32]将卷积层引入生成器和判别器,提高模型的特征提取能力。本文在残差网络[33]的基础上引入多尺度拓扑模块(Multiscale Topological Block,MTB)融合信号在不同尺度下的分辨率特征,图2给出了网络结构。网络输入为1×1000维的时域信号包络R(i)(nT),经过全连接层和维度变换后输出2×512×1的三维张量,便于后续进行2D卷积。由于时域信号中附加了功率放大失真,连续时间内的幅度信息能够表示辐射源的辨识特征,因此可以利用MTB提取采样序列的时域互相关特性。如图2所示,该结构中存在①—④ 4条支路,其中支路①—③的结构相同,均由3个卷积层串联组成,每层的卷积核个数为256,卷积核大小分别为1×7,1×5和1×3。设置不同尺寸卷积核的目的是从多个尺度纵向提取R(i)(nT)的时间跨域关联信息,实现时域特征的跨层流动;而构建的支路①—③则从横向维度丰富通道信息,提高网络的多维表征能力,卷积层后添加修正线性单元(Rectified Linear Unit,ReLU)、批归一化层(Batch Normalization,BN)和最大池化层防止梯度爆炸。为避免3条并联支路中的卷积层堆叠而导致的特征丢失,添加支路④的跨越连接将前端初始特征直接传递至后端感受野,利用拼接操作(concatenate)融合时域信号的细微信息和并联支路映射的高维特征。

图2 基于MTB和残差单元构建的判别网络Fig.2 The discriminator based on MTB and residual units
为解决由于卷积层数的增加而导致的梯度消失,网络主体采用串联的残差单元提高多尺度融合特征的利用效率。每个残差单元均由3个卷积层构成,每一卷积层后添加BN层和ReLU层提高网络的非线性表征能力,卷积步长设置为1用于保留高维特征映射。4个残差单元的卷积核个数分别为128,64,32和16。特征向量经过展平操作后分别由Softmax层和Sigmoid层输出判别网络的监督分类概率和无监督二元“0-1”判别概率。
表1给出了生成器的网络结构。输入为1×100的随机噪声向量,每个卷积层后添加批归一化层和泄露修正线性单元(Leaky Rectified Linear Unit,LReLU)层,斜率设为0.2,卷积核大小为1×3,步长设置为1。全连接层的激活函数设置为tanh,用于将输出信号限幅为[0,1]。
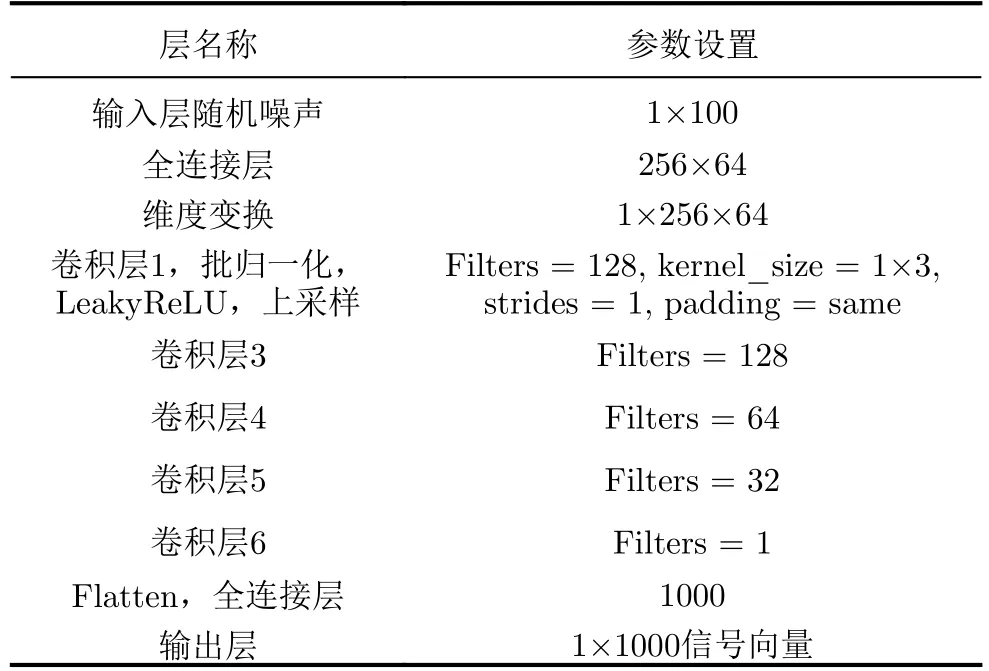
表1 生成器结构Tab.1 The structure of generator
3 非均衡类别损失
3.1 非均衡类别损失定义
本文提出一种面向非均衡类别的改进交叉熵,用于抵消由于样本类别不均匀所导致的梯度失衡,提高低置信度样本对于损失值的贡献度。标准交叉熵(Cross Entropy,CE)损失表示为

式中,yi∈(0,1)为 置信概率,pi∈(0,1)为预测概率,N为样本类别。CE损失通过假设损失权重与所属类别频率的无关性以实现训练误差的最小化,对于置信度高的多数类样本和分类困难的少数类样本分配相等权重。但这将导致多数类误导梯度的下降方向,因此需要足够的类别频率样本才能实现分离边界的泛化。非均衡类别损失(Imbalanced Category Loss,ICL)定义为
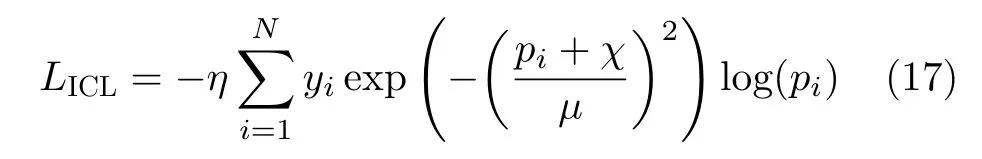
式中,η,χ和μ为超参数。其中η代表权重因子,当样本集合中存在标签信息极少的困难分类样本时,可以通过增大权重因子η提高对于低置信度样本的损失加权;χ表示调制系数,用于调节ICL损失曲线的斜率,其实质是对不同置信样本的损耗分离度进行设置;μ则定义为缩放系数,主要决定模型对于多数类样本的损失抑制程度,可以用于高置信度样本的损失向下加权。Zhang等人[34]和Lin等人[35]分别提出焦点损失(Focal Loss,FL)LFL和类不平衡(Class Imbalance,CI) 损失LCI,其表示为

式中,γ,υ和λ表示超参数。
图3描述了CE损失、FL、CI损失和ICL的损失值随置信度变化的曲线。图示几类损失均能根据样本的置信度自适应地调整模型损耗:对于易分类样本,降低权重直至接近于0;对于置信概率较低的困难分类样本,图示几类损失均通过附加增益提高对于该部分数据的“损失注意力”。相比于FL采用的幂函数调制因子和CI损失的三角函数因子,采用指数因子的ICL扩展了易分类样本的低损失值范围,对于困难分类样本附加更低的损失增益。而且指数缩放因子使得ICL具有比FL和CI损失更大的导数绝对值,这在图3中表现为ICL曲线具有更大的“陡峭度”,能够提高损失函数针对不同置信样本的损耗分离度。权重因子η主要决定对于低置信度样本的损失加权,当η=1.02时,ICL损失与FL损失和CI损失的左端点相同;而χ=0.06,μ=0.41参数组合能够保证ICL损失具有比CE损失和FL损失更高的向下加权速率,而且相比于CI损失具有更好的边界分离性能。超参数υ和γ取值分别为0.25和2[34]。
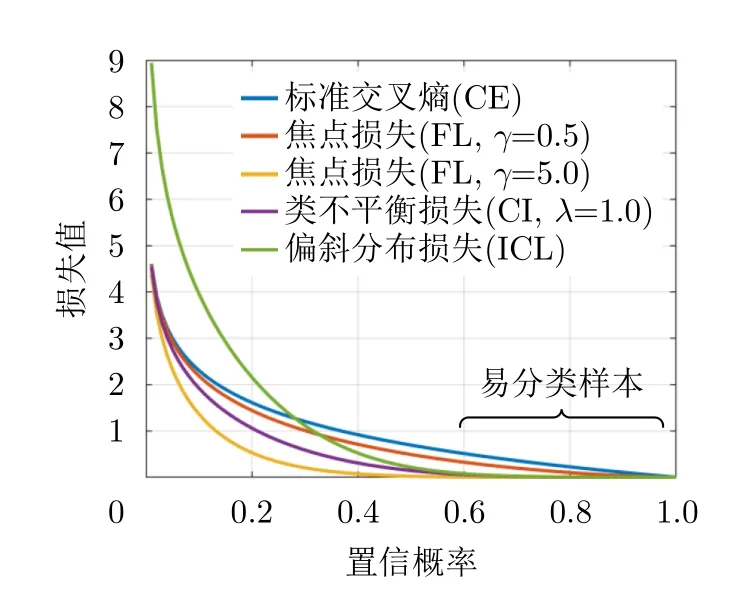
图3 5类代价敏感损失曲线Fig.3 Five types of cost-sensitive loss curve
3.2 可导性证明
在回归或者分类任务当中,可导性是设计损失函数的重要原则,即通过迭代得到损失函数的最小值或鞍点,从而确定输入输出之间的最佳非线性映射。图4表示神经元的基本结构。图4中b表示偏置项,σ(·)表示激活函数,第i个神经元的输出zi为

图4 基本神经元结构Fig.4 The basic neuron structure
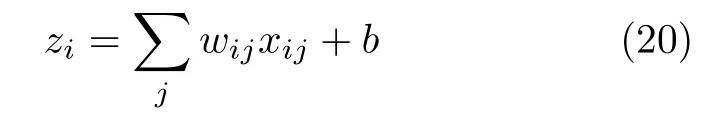
其中,wij表示第i个神经元的第j个权重值,Softmax层的输出ai表示为

在IC-SGAN中,判别网络的监督部分利用ICL损失实现K维分类。可导性证明详见附录,由证明过程可知网络对于神经元输出的梯度∂L/∂zi存在,通过比较真实值yi与网络预测值ai的加权误差,网络能够依靠梯度的反向传播收敛至全局最优解。
4 仿真结果与分析
4.1 数据集设置
本节在仿真数据集上针对IC-SGAN的性能进行验证和分析。首先选取泰勒多项式对来自5个发射机的非线性失真进行建模[12],多项式的阶数M=3。调制方式为BPSK,采样频率为200 MHz,载波频率设置为20 MHz,码元速率为1M Baud,码元序列为随机比特流B∈{0,1}。利用5 组泰勒系数β[1]=[1,0.01,0.01],β[2]=[1,0.6,0.08],β[3]=[1,0.08,0.6],β[4]=[1,0.4,0.01],β[5]=[1,0.5,0.3]代表不同的功放响应。SNR的取值范围为0~24 dB,w(i)(nT)为服从N(0,σ2)分布的高斯白噪声。单一SNR下采集4800条样本,每条样本的采样点数为1000,测试集和标准训练集的划分比为1:1。在标准训练集中随机采样得到不平衡数据集,训练集和测试集的设置如表2所示。

表2 仿真数据的训练集和测试集设置Tab.2 Training and test set settings for simulation data
4.2 实验设置
本文模型的搭建在基于Tensorflow 2.2.0的ker-as 2.3.1框架下实现,操作系统为Windows 10,CPU为Intel(R) core(TM) i7-10750H,GPU为NVIDIA GeForce RTX 3080,运行内存大小为16 GB。
4.3 实验结果分析
4.3.1 网络收敛性分析
由于引入了反目标优化的生成器和判别器,因此GAN模型的收敛特性值得关注。图5记录了IC-SGAN在训练集2上迭代后的损失函数曲线,batch-size为128,信噪比为16 dB,训练集的标记比为0.6,选取Adam作为优化器,学习率设置为0.002。曲线表明判别器的损失值在训练过程中存在波动,而生成器损失则在低值范围内平稳下降,二者在训练60个epoch之后均能达到稳定。

图5 判别器和生成器损失值变化曲线Fig.5 The loss value change of the discriminator and generator
4.3.2 网络参数寻优
IC-SGAN的核心是充分利用无标记样本分布实现判别网络前端权重的共享,因此网络的参数设置对于识别性能具有重要影响。选取识别准确率对网络性能进行衡量,实验在标准训练集上进行,仿真结果如图6所示。当残差单元内的卷积层数为2时,识别准确率随残差单元数量的增加而显著提高;而卷积层数为3或4时,识别准确率均超过89%和90%。这表明IC-SGAN的识别精度与卷积层数量和残差单元个数呈非线性的正比关系。

图6 判别器结构参数对识别准确率的影响Fig.6 The influence of discriminator structure parameters on recognition accuracy
4.3.3 MTB有效性验证
为了证明判别网络中引入的多尺度拓扑模块的有效性,选取MTB-ResNet和去除MTB的原始Res-Net进行识别性能对比。二者除了是否保留MTB,网络其余参数和结构完全一致,实验在同一均衡训练集和测试集上进行。训练样本数量NT为2000,标记比为0.3,MTB-ResNet与ResNet的识别准确率对比如图7所示。

图7 MTB-ResNet与ResNet的识别准确率对比Fig.7 Comparison of recognition accuracy between MTB-ResNet and ResNet
相比于原始ResNet,添加了多尺度拓扑模块的MTB-ResNet在低SNR下表现出更为明显的性能优势。在SNR为0 dB和4 dB时,MTB-ResNet的识别准确率较ResNet分别提升6.1%和6.7%,说明提出的MTB能够利用多维卷积核和多通道结构改善低SNR下网络对于信号的互相关特征提取能力。随着SNR的提高,MTB-ResNet与原始ResNet的识别性能差距逐渐缩小,这是由于采用残差单元作为骨干结构,在增强非线性映射能力的同时避免卷积层堆叠导致的梯度消失;在SNR超过22 dB的高SNR条件下,二者识别准确率的差异来自参数更新的不确定性。
4.3.4 网络鲁棒性分析
对标准训练集进行均匀随机采样,从而验证训练样本数量NT对于网络性能的影响。训练集标记比为0.6,损失函数设置为CE由图8可知,各个SNR下的识别率随NT的增加而稳定提升。当SNR为0~10 dB时,不同NT条件下的识别准确率相差不大,NT为2400时的识别率高于NT=1200大约10%,即NT缺失50%情况下识别准确率降低10%左右。当SNR高于12 dB时,该指标上升至20%,主要由于判别网络的卷积层数较多,在NT=1200的少样本情况下发生过拟合,此时可以通过精简网络改善识别准确率。
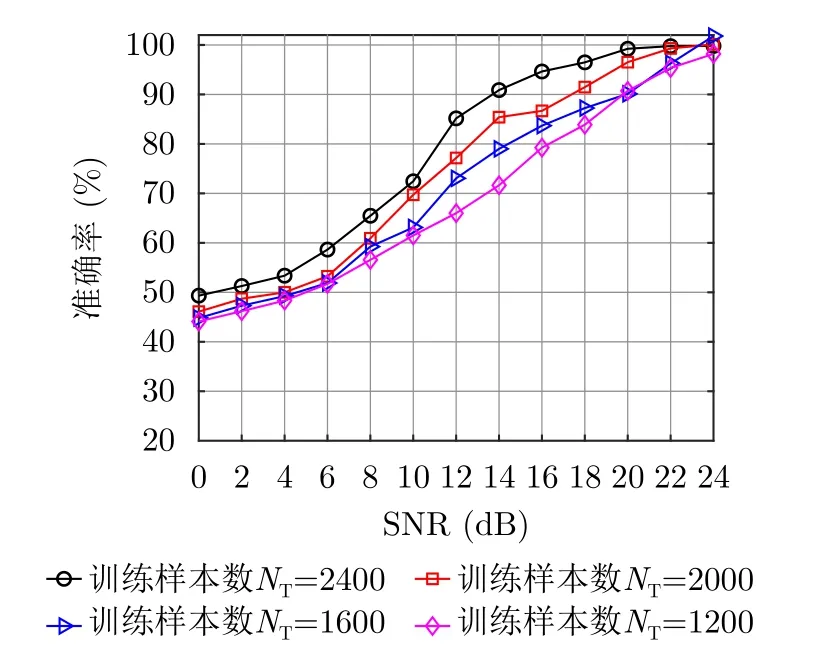
图8 不同训练样本数下识别性能对比Fig.8 Comparison of recognition performance under different numbers of training samples
4.3.5 半监督分类性能分析
对IC-SGAN在不同标记样本数NL下的识别性能进行验证,损失函数设置为ICL,SNR分别选择为16 dB和 20 dB,实验结果如图9所示。

图9 不同标记比下的混淆矩阵Fig.9 Confusion matrix under different labeled ratios
IC-SGAN在标准训练集3类标记比下的识别准确率分别为95.4%,94.8%和90.9%,在训练集3的3类标记比下的识别准确率分别为75.8%,74.2%和72.4%,说明NL的增加能够提高网络的识别性能。在标记样本数量相差40%的情况下,两种数据集的识别准确率仅相差了4.5%和3.4%,说明IC-SGAN能够利用较少的标签信息实现较高的识别精度,对于标签信息的规模表现出较强的适应性。
4.3.6 非均衡类别损失性能评估
利用3类损失函数(CE损失、FL损失和ICL损失)在1个均衡数据集和4个失衡数据集上进行训练,训练集的标记比为0.6,并在标准测试集上给出测试准确率,结果在表3给出。
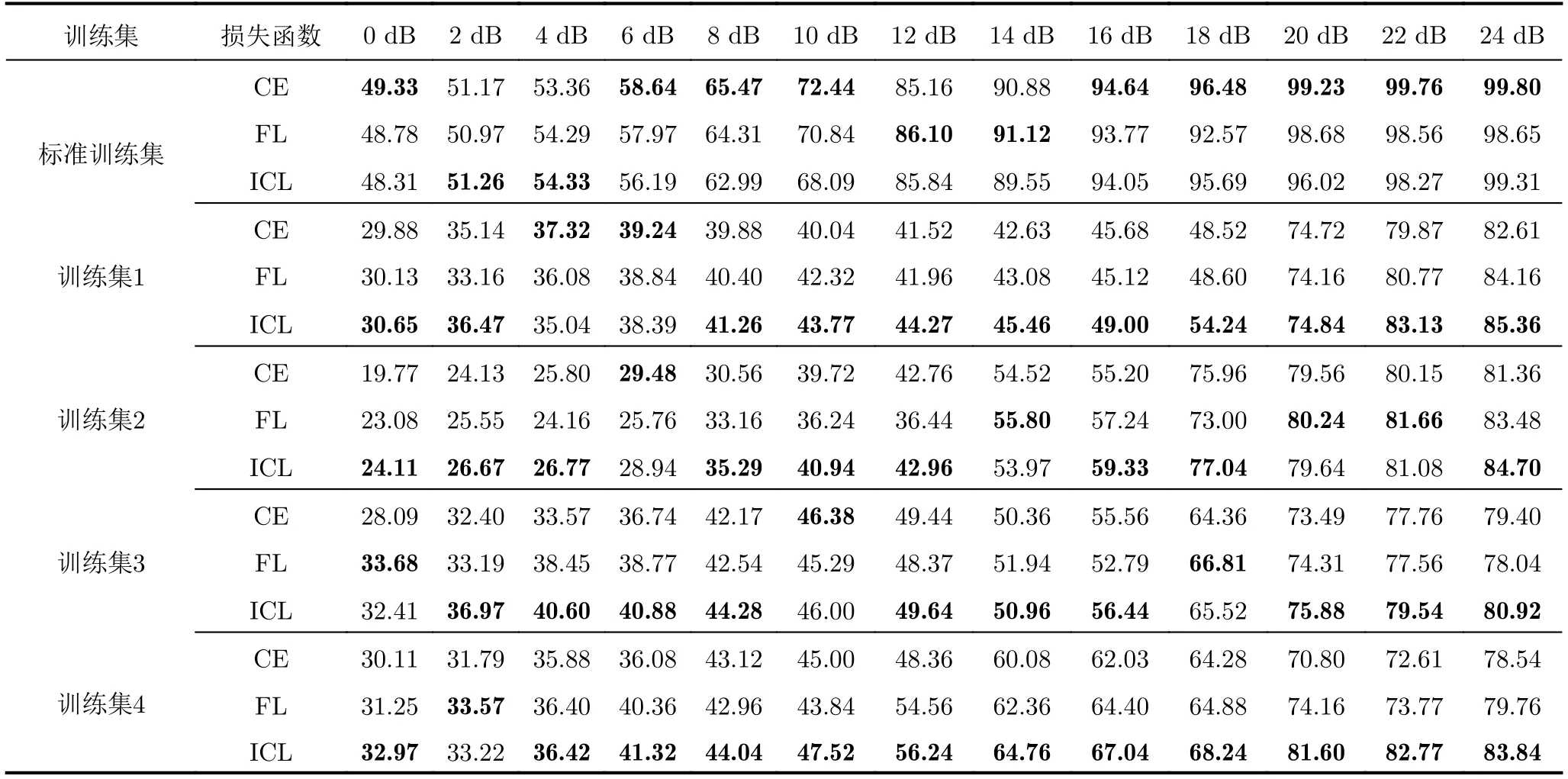
表3 不同损失函数在不同信噪比下的性能评估(%)Tab.3 Performance evaluation of loss functions under different SNRs (%)
横向对比来看,识别准确率能够随SNR的改善而稳定提高。在SNR<10 dB的恶劣信道条件下,SNR的增加对于识别性能的提高十分显著,这是由于表征个体差异的功放响应失真淹没在高斯白噪声中,模型无法从当前信号中获取足够的差异信息;当SNR超过某一阈值时,当前信道环境下的功放失真差异较为明显,SNR的提高对于识别性能并未表现出较大的贡献度。
纵向对比来看,在标准训练集上CE损失、FL损失和ICL损失的识别准确率差异较小,FL损失和ICL损失未表现出明显优势,这是由于标准训练集中的样本类别呈现均匀分布,因此FL损失和ICL损失无法根据置信概率对梯度进行加权。对于4种类不均衡训练集,FL损失的识别性能高于CE损失,而且ICL损失在大多数情况下表现出最高的识别准确率,由此验证了FL损失和ICL损失均能利用置信概率自适应地调整损耗值,对于易分类的多类样本附加向下的加权速率。在4种类不平衡数据集上,ICL损失的平均识别准确率相比CE损失和FL损失分别提高5.34%和2.69%。
4.3.7 算法识别性能比较
为验证IC-SGAN的性能优势,选择文献[22]、文献[9]、文献[11]以及文献[13]中的方法进行对比,实验在训练集4上进行。文献[22]引入特征匹配损失指导网络的训练,作为方法1;文献[9]提出了基于信息最大化生成对抗网络(InfoGAN)和RFF嵌入的无监督SEI框架,作为方法2;文献[11]提取Hilbert光谱特征并利用SVM进行分类,作为方法3;文献[13]采用深度残差网络学习Hilbert谱图像中的视觉差异,作为方法4。识别准确率的对比结果如表4所示,标记比为0.6。
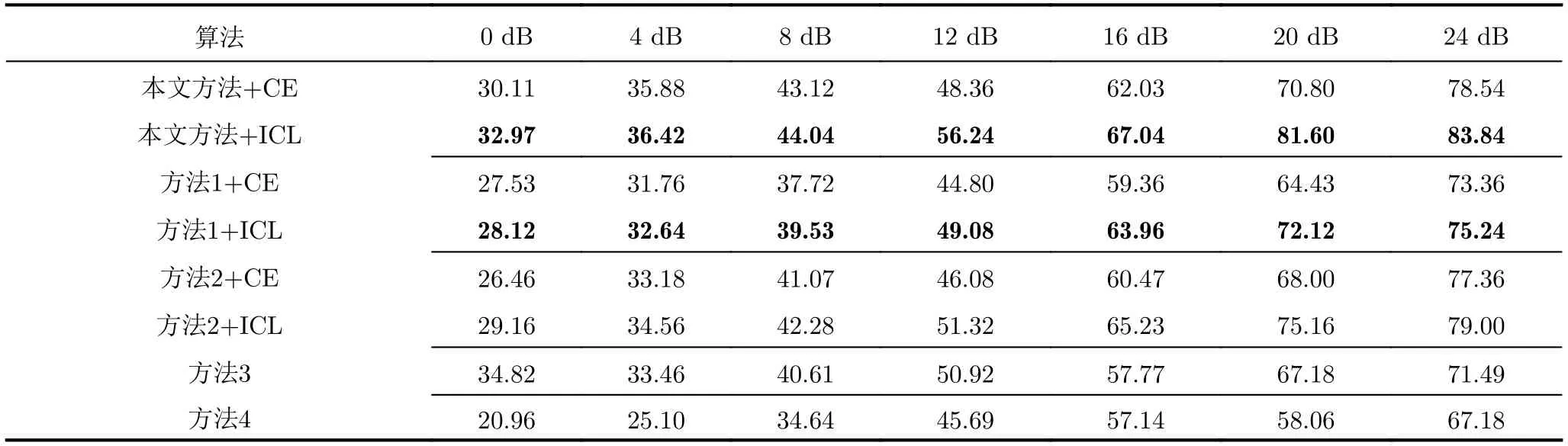
表4 不同算法识别准确率对比(%)Tab.4 Comparison of recognition accuracy of different schemes (%)
横向对比来看,IC-SGAN在所给条件下均具有最高的识别准确率。相比于方法1,IC-SGAN嵌入MTB提取信号的多维分辨率特征,且利用残差单元改善梯度消失,特征挖掘能力更强;方法2将高阶矩作为RFF嵌入到InfoGAN框架当中,但判别网络的分类效率低于IC-SGAN,识别性能相比于方法1有所提升;方法3利用SVM提取Hilbert谱的熵特征,但SVM处理类不均衡数据的能力有待提高;方法4本质属于监督网络,因此只能从60%的标记数据中学习样本分布,无法利用未标记数据,模型容易过拟合。纵向对比来看,相比于CE损失,ICL损失能够明显改善方法1和方法2在非平衡数据集上的分类性能,证明了ICL损失的可迁移性。
4.3.8 网络复杂度分析
对两种改进GAN结构的复杂度进行比较,并将空间复杂度和时间复杂度作为算法复杂度的衡量指标。空间复杂度指网络中待优化的参数NO,时间复杂度从迭代平均耗时ttrain和平均识别时间ttest方面进行考虑。3类模型均在SNR=24 dB的标准训练集上进行训练,样本数量为2500,标记比为0.4,并在标准测试集上进行预测。
表5给出了IC-SGAN与RFFE-InfoGAN[9]以及E3SGAN[22]的计算复杂度比较。其中NO为判别网络和生成器的可优化参数总和,迭代平均耗时ttrain为模型训练迭代100次的平均时间,平均识别时间ttest为模型在标准测试集上的预测时间。由表5可知,IC-SGAN的空间复杂度NO和迭代平均耗时ttrain最低,这得益于残差学习结构利用短连接提高了特征传递效率。在RFFE-InfoGAN中,判别网络采用多层感知机(Multi-Layer Perceptron,MLP)进行特征降维,导致参数数量大幅增加。3种模型的平均识别时间相差较小,均具有较强的识别实时性。

表5 网络复杂度对比Tab.5 Network complexity comparison
5 基于USRP的IC-SGAN性能验证
5.1 实验环境搭建
采用基于GNU Radio和USRP的软件定义无线电(Software Defined Radio,SDR)平台收集经过真实信道传输的辐射源信号。搭建由装有GNU Radio软件的计算机和6台USRP-B210组成的SDR平台作为信号采集系统,信号的采集过程如图10所示。其中1台USRP-B210固定为接收机,其余5台USRP-B210作为发射机,每台USRP-B210 具有两个射频发射、接收通道,因此可以模拟10个目标辐射源。
5.2 信号参数设置
在GNU Radio的GUI界面中,将发射信号的参数设置如下:信号的调制方式为BPSK,载波频率为2.4 GHz,带宽为100 kHz,收/发增益为50,USRP的降采样率为1 MHz,码元序列为方波。收发天线距离为0.15 m。每台USRP的采集样本数量为720,训练集和测试集的划分比例为2:1,单条样本的采样点数为1000。
5.3 实验结果分析
图11给出了辐射源个数改变时的混淆矩阵。实验在类别均衡训练集上进行,损失函数选择为CE,样本的标记比为0.7。显然,识别性能随着辐射源数量的增加逐渐下降。辐射源数量K=10时,ICSGAN的整体识别准确率能够达到81.4%,而且6号、8号以及10号个体的射频指纹特征较为接近,识别时发生混淆。

图11 IC-SGAN对于不同辐射源数量的识别结果Fig.11 The recognition results for different numbers of emitters
为验证ICL在真实场景下处理类不均衡样本的有效性,从采集的USRP -B210信号样本中采样得到类不均衡数据集。选择奇偶交叉采样法[36]构造类不均衡训练集。将原始训练集中的偶数类全部作为训练集,奇数类中选择10%和25%的样本作为训练集,反之亦然。数据集参数在表6给出。
选择3类损失函数(标准交叉熵CE、焦点损失FL和非均衡类别损失ICL)在5个训练集上进行训练,训练样本的标记比为0.6,并在标准测试集上进行预测。当K小于10时,取表6中前K类作为新的训练集。表7给出了3种损失函数在不同数据集上训练后的测试结果。
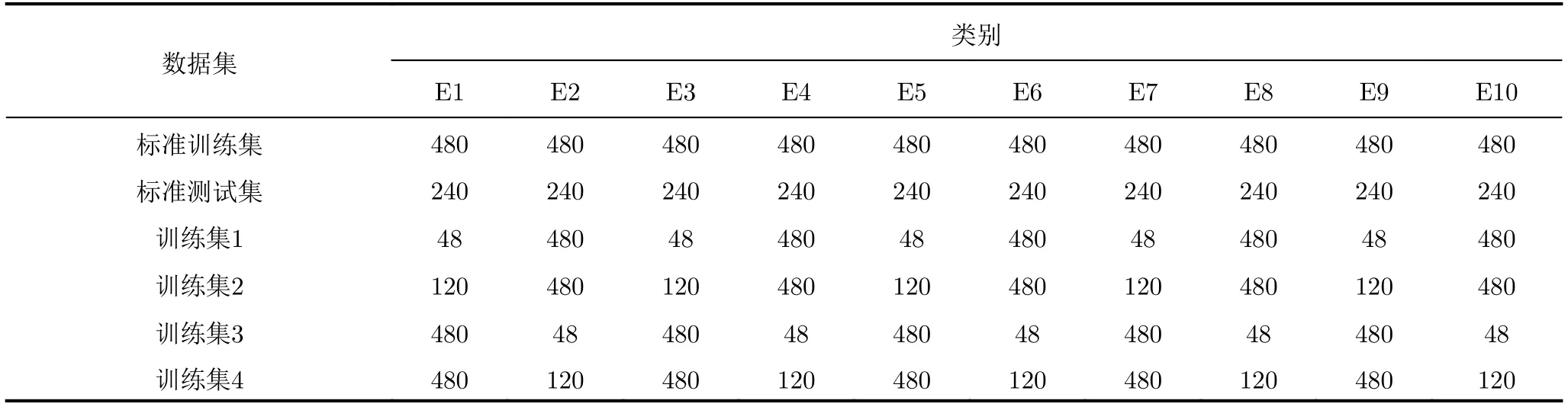
表6 真实数据的训练集和测试集设置Tab.6 Training set and test set settings for real data

表7 3类损失函数的识别性能评估(%)Tab.7 Recognition performance evaluation of three loss functions (%)
在K相等的情况下,在类不均衡数据集上的识别准确率相比于标准训练集均发生下降。这是由于某类别下的训练样本数量剧减,导致模型无法从当前样本中获取该类别足够的特征表示,而且样本置信概率的不均加剧了梯度传播的失衡。同一训练集下,ICL损失表现出最高的平均识别准确率,由此验证其在真实场景下的泛化性。
6 结语
针对训练样本标签不完整和类别不均衡导致个体识别性能受限的问题,本文提出了一种基于SSGAN和代价敏感损失的SEI方法。通过定义新的优化函数并向判别网络中引入多尺度拓扑模块和残差单元,直接对一维时间序列进行数据增强和分类,克服RFF提取泛化性较差的问题;利用修正后的交叉熵损失克服多数类样本带来的梯度主导,在多个类不平衡数据集上表现出较高的识别性能,为非均衡类别场景下的半监督SEI问题提供新的解决方案。
附录
根据链式求导法则,损失函数L对于第i个神经元的输出的梯度可表示为
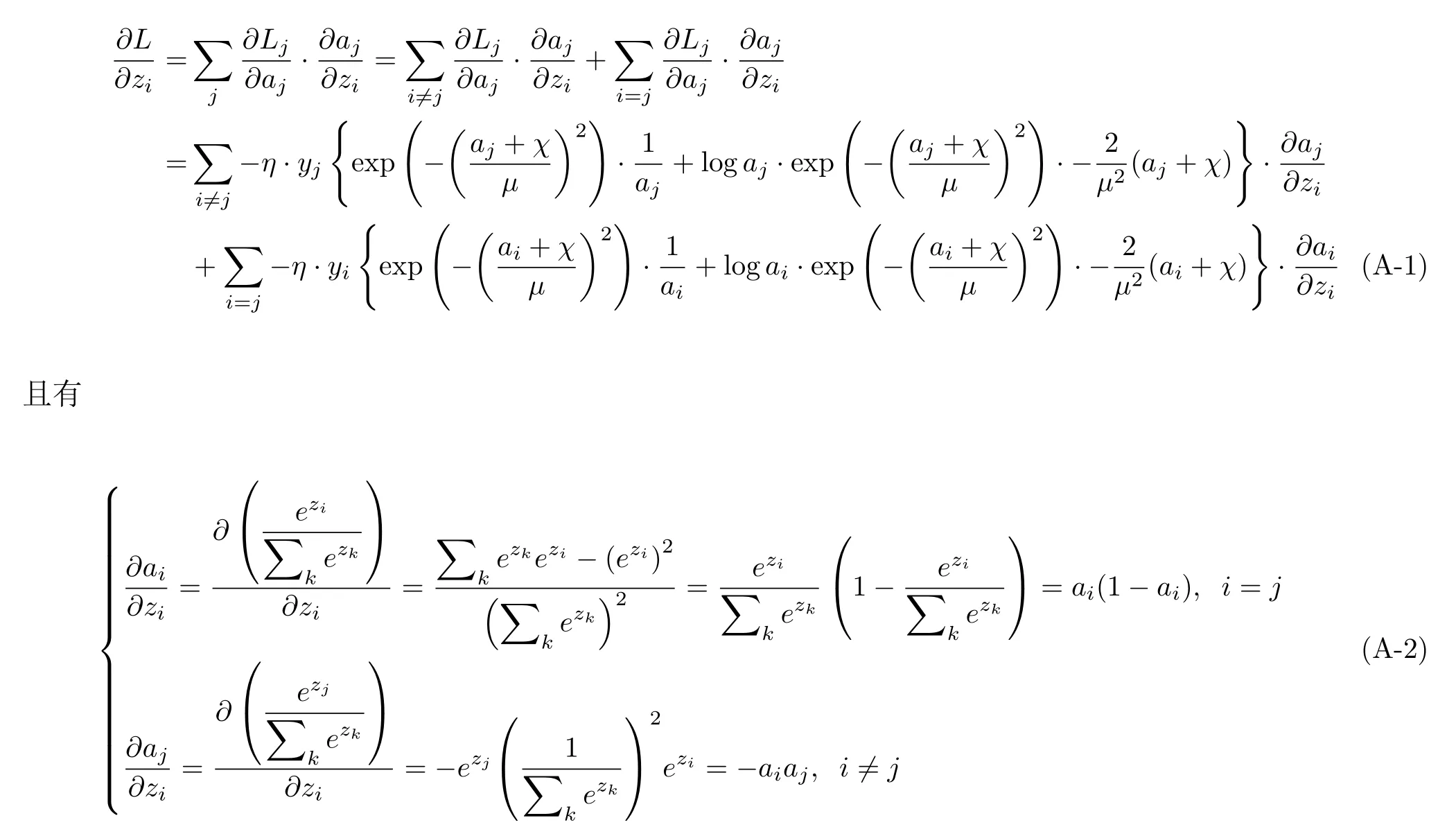
将式(A-2)代入式(A-1),则得到
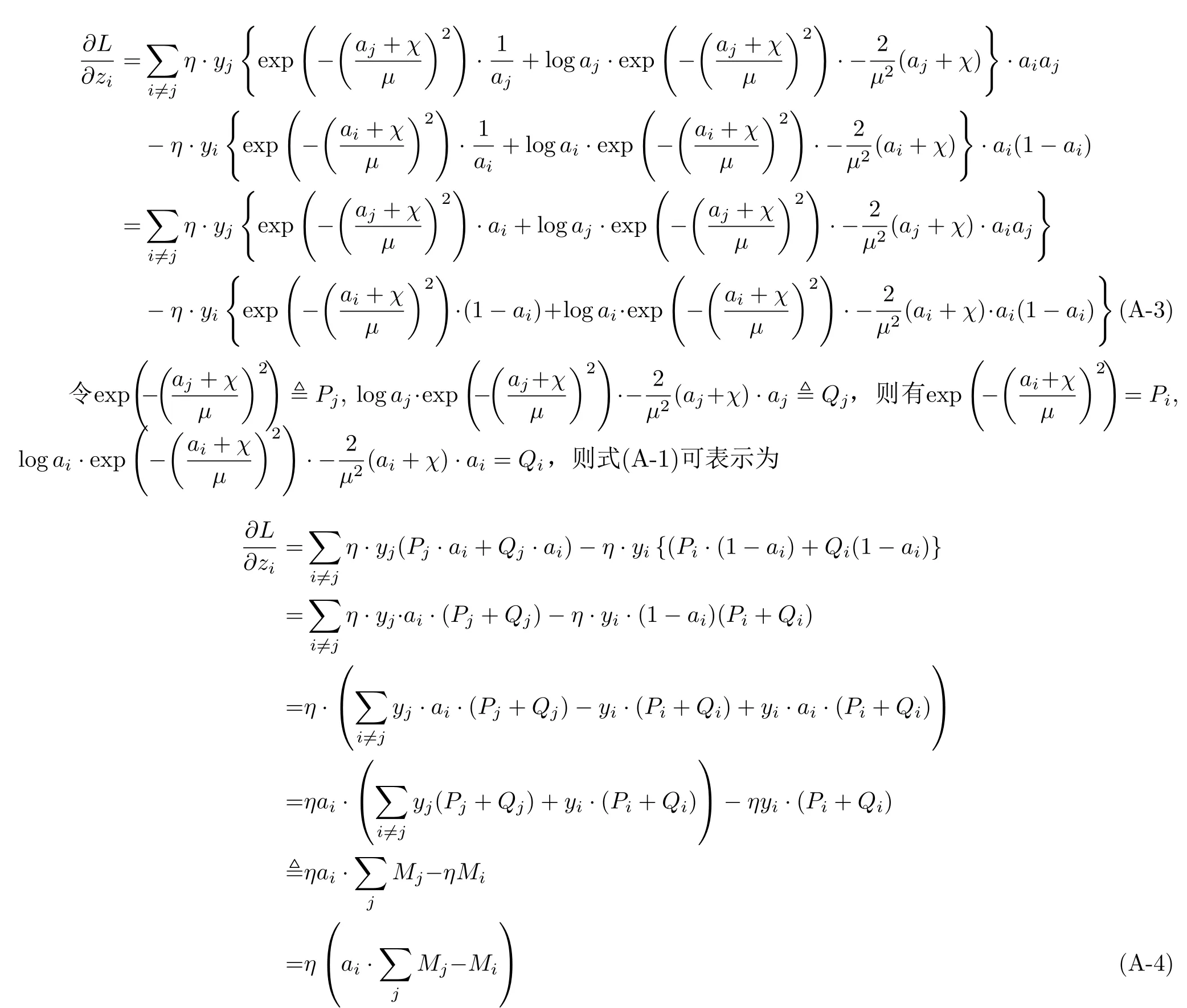

式中,ai表 示预测值,η和c表示常数,φ(ai)是关于预测值ai的函数,用来调节不同类频率样本引起的权重变化速率。