高光谱成像技术检测油茶果成熟度
2022-09-01胡逸磊姜洪喆周宏平许林云
胡逸磊,姜洪喆,周宏平,许林云,鞠 皓,王 影
(南京林业大学机械电子工程学院,江苏 南京 210037)
油茶果采摘期受环境因素影响较大,不同地区的天气、气候、积温、土壤肥力等条件不同,造成油茶果的成熟期有早有晚,因此油茶果的采摘时间应根据其具体成熟度而定。油茶果采收前的最后一个月是油脂积累的高峰期,这段时间油茶果含油量增幅最为明显,同时伴随着内部营养物质的相互转化。然而在此时期油茶果的外部形态特征如形状大小、鲜果质量、颜色等趋于稳定,无明显变化,从而给茶农判断油茶果的成熟度和最佳采摘期带来一定的困难。故迫切需要提出一种快速准确地检测油茶果成熟度的方法,为油茶果的精准采收作业提供帮助。
高光谱成像技术是一种集图像和光谱于一体的技术,图像中的每个像素点都包含特定位置的光谱信息,可实现被测物各组分分布情况的可视化。近年来不少研究人员利用高光谱成像技术在检测果品的成熟度及相关成熟度参数方面取得了重大进展。Pu Hongbin等比较了两台成像光谱仪(光谱集I:600~1 000 nm和光谱集II:1 000~2 500 nm)检测荔枝成熟度的能力,建立的偏最小二乘判别分析(partial least squaresdiscrimination analysis,PLS-DA)在光谱集I上对成熟和未熟荔枝的分类正确率比在光谱集II上高6.25%。Zhang Chu等采集了成熟、半熟和未熟草莓在两组不同波段下的高光谱图像,融合草莓的光谱特征和纹理特征建立的支持向量机(support vector machine,SVM)模型发现:在441.1~1 013.97 nm,SVM模型识别正确率为95%,在941.46~1 578.13 nm,SVM模型识别正确率只有70.83%。Rosli等将柑橘样品划分成6 个区域,分别采集每个区域的光谱反射率,发现尽管生长期和成熟期的柑橘果皮颜色相差不大,利用粒子群优化(particle swarm optimization,PSO)算法建立基于光谱反射率的分类模型能筛选出未成熟的柑橘。周宏平等通过比较不同成像波段(400~1 000 nm及900~1 700 nm)得到油茶籽光谱反射率数据建立的偏最小二乘回归(partial least squares regression,PLSR)模型性能的优劣,得出900~1 700 nm是油茶籽含油率最佳检测波段的结论。这些研究结果为使用光谱分析技术检测油茶果成熟度奠定了良好的理论基础。
本研究通过高光谱成像技术获取油茶果的高光谱数据并结合化学计量学方法获取油茶果的成熟度参数作为参照,使用分类算法完成对油茶果成熟度的判别,并验证分类模型的正确率,旨在为油茶果最佳采摘期的判断提供科学依据。
1 材料与方法
1.1 材料
油茶果样品来自江苏南京市江宁区金航油茶专业合作社的油茶林,采集的油茶果均属于霜降籽品种(在霜降节气前后成熟),具体采样要求为:采集位于近似同一海拔高度的茶树上向阳面的油茶果,且油茶果的大小相似,以最大程度保证每一批次的样品处于同一成熟度水平。
于2020年10月13号、10月20号、10月27号、11月3号、11月10号分别采集油茶鲜果各200 个,当天带回进行油茶果高光谱图像的采集,并于11月14号采集果壳开裂的油茶果20 个作为对照组进行含油率的测量(11月14号茶树上几乎没有果皮完整的油茶果,由于过熟导致果壳开裂,整个茶园的油茶果采收工作基本完毕,因此特意留出5 棵茶树用于实验样本的采集)。
1.2 仪器与设备
南京林业大学生物质包装无损检测实验室搭建的高光谱成像无损检测平台如图1所示,包括成像光谱仪(GaiaField-V10E-AZ4型,400~1 000 nm)、探测器(sCMOS相机)、白色食品级传送带(HSIACSD800)、一套由12 只50 W的卤素灯和漫反射穹顶组成的照明系统以及一台计算机,其中成像光谱仪的光谱分辨率为5 nm,被测物品置于传送带上的载物台由步进电机驱动,暗箱用于屏蔽外界杂散光对数据采集的干扰;111-101v-10G型游标卡尺 桂林广陆数字测控股份有限公司;BSM-220.4型分析天平 上海卓精电子科技有限公司;DHG-9101-2SA型干燥箱 常州朗越仪器制造有限公司;NAI-ZFCDY-6Z型脂肪测定仪 上海那艾精密仪器有限公司。
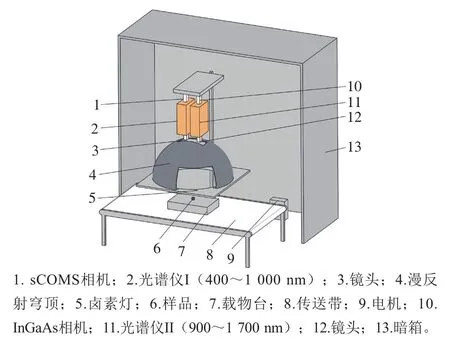
图1 高光谱成像系统Fig. 1 Schematic of hyperspectral imaging system
1.3 方法
1.3.1 高光谱图像的采集和校正
高光谱图像数据获取基于计算机上的Specview软件,将高光谱仪器预热30 min后进行油茶果图像采集。为避免获取的图像失真,经过多次预实验确定最佳的数据采集参数如下:光谱仪I的曝光物距为300 mm,曝光时间为1.2 ms,电控位移台扫描速率为0.601 4 nm/s,扫描线实际长度为200 mm,图像分辨率为800像素×666像素。每次采集2 个油茶果,采集完成后统一裁剪成230像素×290像素的单个油茶果高光谱图像。
由于高光谱图像采集过程中存在暗电流的影响,而且不同波段下成像系统光源的强度分布也不均匀,从而导致获取的高光谱图像中含有较大的噪声。因此要对其进行黑白校正以消除暗电流的影响,校正方法如式(1)所示:

式中:为校正后的漫反射光谱图像数据;为样本原始的漫反射光谱图像数据;为暗图像数据;为白板的漫反射图像数据。
1.3.2 理化指标测定
分别测定油茶果的果高、果径、鲜果质量、鲜籽质量以及烘干后的油茶果壳质量,得到油茶果壳的含水率和出籽率计算如式(2)、(3)所示:

式中:为油茶果壳含水率/%;为出籽率/%;为果壳烘干后质量/g;为油茶鲜果质量/g;为油茶鲜籽质量/g。
油茶果的含油率按照GB 5009.6—2016《食品中脂肪的测定》的方法测定,并按照黄佳聪等的方法计算含油率,如式(4)所示:

式中:为含油率/%;为出油量/g;为茶仁质量/g。
1.3.3 曲率校正方法
油茶果表面曲率较大,使得油茶果高光谱图像每个像素点的光谱强度存在较大差异,因此必须校正反射强度的变化。Gowen等发现,均值归一化比最大值法和中值法更适合校正球形水果表面的光谱强度变化。本研究使用均值归一化方法对高光谱图像的像素点光谱反射率进行逐一校正,并利用变异系数评价光谱校正的质量,计算如式(5)、(6)所示:
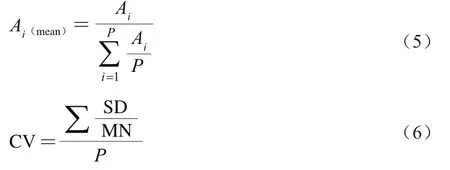
式中:A为高光谱图像中单个像素点的光谱向量;为光谱向量中元素个数(即波段数量);A为单个像素点校正后的光谱向量;SD为光谱矩阵的标准差;MN为光谱矩阵的平均值;CV为变异系数。
1.3.4 变量选择方法
高光谱数据量大且数据之间的共线性严重,影响模型的运算速度。因此采用以下3 种方法提取有效信息变量进行对比,从而得到最优的变量选择方法。
连续投影算法(succesive projections algorithm,SPA)是一种前向选择算法,通过在光谱中寻找最低限度冗余光谱信息变量集,使得变量之间的共线性最小化。该方法需预先设置选择的变量数范围,最终选择的变量数在该范围内的均方根误差(root mean square error,RMSE)最小。本研究中选择的最佳变量数范围为5~30,选择出28 个特征波长。
竞争性自适应重加权算法(competitive adaptive reweighted sampling,CARS)是一种以回归系数(regression coefficient,RC)作为变量重要性评价指标的变量选择方法。该方法利用自适应重加权采样技术结合指数衰减函数优选出PLSR模型中RC绝对值大的变量点,并将交叉验证选出个PLSR子集模型中交叉验证均方根误差(root mean square error of cross-validation,RMSECV)最小的子集定义为最优变量子集。本研究中将蒙特卡洛采样次数设置为5 000,每次运行程序选择的训练集和测试集的样本比例为2∶1,筛选出28 个特征波长。
遗传算法(genetic algorithm,GA)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。本研究设置进化代数为200,算法运行次数50,种群大小为64,初始时平均5 个波长构成一个染色体,染色体个数为30,变异概率为1%,筛选出26 个特征波长。
1.3.5 模型建立与评价
采用SVM、-最近邻(-nearest neighbor,KNN)算法、随机森林(random forest,RF)算法、PLS-DA四种分类方法建立油茶果成熟度分类模型。其中SVM是一种非线性模型,能够有效避免样本空间的维数灾难;KNN属于简单的线性分类方法,易于实现;RF是一种集成算法,抗过拟合能力强;PLS-DA也是一种线性分类方法,鲁棒性较好。最后通过图像分类的方法,以整幅油茶果的高光谱图像为输入量,搭建基于迁移学习的卷积神经网络模型,并讨论模型性能。
KNN算法的核心思想是用距离最近的个样本数据的类别代表目标数据的类别,其中值是超参数,会很大程度上影响分类的效果。将值设置为[3,40]以2为步长递增,以平均正确率为依据,使用10折交叉验证法进行值寻优。
RF算法是以Bagging为框架的基于CART决策树的集成算法,该算法使用随机抽样形成的多个分类器达到更低的泛化误差。对RF算法分类效果影响最大的超参数主要包括Bagging框架参数N estimators和CART决策树参数Max depth,其中N estimators为学习器的最大迭代次数,Max depth为决策树的最大深度。本研究中将N estimators的值设置为[10,200]以10为步长,将Max depth的值设置为[1,15]以1为步长进行网格搜索。
SVM算法中使用高斯核函数,其中参数和对模型的性能影响很大,是惩罚系数,表示对误差的容忍度,是高斯核函数中的一个参数,反映数据映射到新的特征空间后的分布状况。本研究将设置为以2为底,在[-10,10]内以指数0.1为步长递增,将设置为以2为底,在[-10,5]内以指数0.375为步长递增进行网格搜索。
PLS-DA是根据样品的光谱矩阵和类别矩阵分解出的载荷矩阵和得分矩阵计算测试样本的类别信息矩阵,然后根据类别信息矩阵与类别标签的接近程度确定样品所属类别。该模型中的潜变量数N components为超参数,该值过大,容易发生过拟合,该值过小,则模型的精度不足。本研究将N components设置在[1,20]之间进行网格搜索。
本实验采用分类正确率作为模型评价指标,计算如式(7)所示。正确率越高,说明模型的预测性能越好。使用的数据处理软件包括ENVI5.1、Matlab2014a、Python3.8。
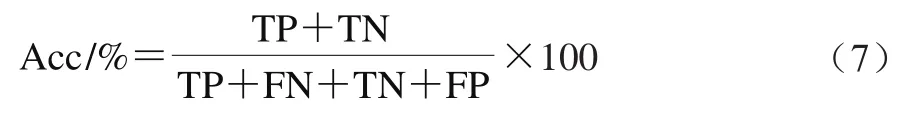
式中:Acc为正确率/%;TP为正确识别为正样本的数量;TN为正确识别为负样本的数量;FP为错误识别为正样本的数量;FN为错误识别为负样本的数量。
2 结果与分析
2.1 油茶果成熟期理化参数
从每一批次中取10 个样品进行油茶果果高、果径、鲜果质量、鲜籽质量、出籽率、含油率、果壳含水率等理化参数的统计,取每一批次各理化参数的平均值作为该批次样品的理化值,计算每个理化参数在整个采摘期内的平均值和标准差,结果如表1所示。
可以发现油茶果的果高、果径在整个采摘期内出现些许的递增,但递增幅度很小,因此标准差较低,只有0.43 mm左右;鲜果质量范围在25~30 g之间,鲜籽质量范围在10~15 g之间;油茶果的果壳含水率在采摘期内有下降的趋势,但下降的幅度较小;油茶果出籽率在35%~40%之间波动,油茶果含油率随着采摘时间的推迟而递增,增幅达到59%,其标准差为5.55%,比其他理化参数的标准差高很多,可见若提前采摘油茶果将造成茶油产量的严重损失。并且从采样时间上看,11月10号油茶林中部分油茶果的果壳开裂,油茶果进入全面采收阶段,至11月14号采收工作基本完毕,预留的5 棵茶树上的大部分油茶果的果壳开裂,有的油茶果已脱落在地,符合油茶果过熟期特征,将此时采集的油茶果作为对照组,发现其含油率基本保持稳定,说明11月10号左右油茶果进入完全成熟期,此时采摘可使茶油产量最大化,并且陆续有油茶果果壳开裂并脱落导致难以收集,无法再推迟油茶林的整体采收时间。

表1 油茶果理化参数随采摘时间的变化Table 1 Changes in physicochemical parameters of C. oleifera with picking date
因此本研究采用含油率作为油茶果成熟度的衡量指标,并结合表2给出其成熟度的定量判别标准:采收前30 d左右,且含油率为(22.00±1.00)%的样品作为成熟度I;油茶果采收前23 d左右,且含油率为(24.00±1.00)%的样品作为成熟度II;茶果采收前16 d左右,且含油率为(27.00±2.00)%的样品作为成熟度III;茶果采收前9 d左右,且含油率为(31.50±2.50)%的样品作为成熟度IV;油茶果采收期间,且含油率为(35.00±1.00)%的样品作为成熟度V。成熟度等级I~V的油茶果样品的成熟度依次递增,成熟度V的油茶果为完熟期样品。本实验不包含过熟期样品,因为过熟期的油茶果果壳开裂容易脱落,凭借人眼很容易判别,无需借助高光谱设备。将以上5 种成熟度油茶果样品的高光谱数据作为数据集,用作成熟度的分类。

表2 油茶果含油率的变化Table 2 Changes in oil content in C. oleifera with picking date
2.2 基于像素点的油茶果高光谱图像曲率校正
油茶果果面曲率较大造成高光谱成像后每个像素点的光谱强度差异较大,并且从油茶果图像的中心区域往果子边缘处的光谱强度逐渐减小,导致边缘处的光谱反射率比中心处低,直接使用这种状态下数据进行建模分类的误差较大,现使用均值归一化方法进行校正。归一化方法在光谱曲线预处理中有重要的应用,可以在一定程度上减小水果形状对采集光谱的影响。
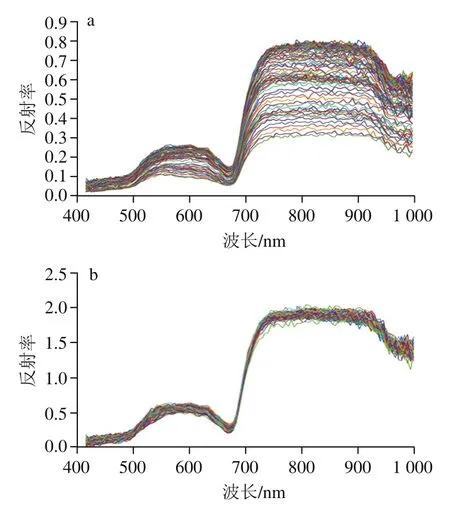
图2 校正前(a)、后(b)油茶果半径方向像素点光谱曲线Fig. 2 Pixel spectral curves of C. oleifera in the radius direction before (a) and after (b) correction
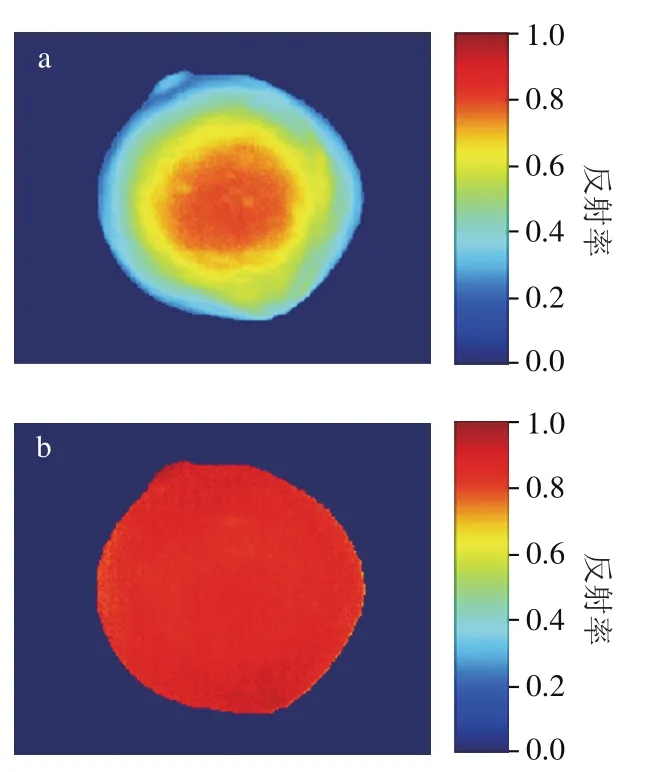
图3 774 nm波段校正前(a)、后(b)油茶果像素点反射率分布Fig. 3 Reflectivity distribution of the pixel points of C. oleifera before (a) and after (b) correction at 774 nm
图2a是校正前从油茶果中心沿半径方向至边缘处89 个像素点的光谱曲线图,可以看出由于油茶果曲率的影响,不同位置的光谱反射强度差异很大,光谱CV为0.244 0;图2b是相同位置的像素点校正后的光谱曲线图,可以发现每个像素点之间的光谱强度差异变小很多,CV为0.075 3。
774 nm通道油茶果样品的反射率与背景的反射率差异最大,因此该通道能清晰地显示油茶果样品的灰度图。图3是在774 nm波段校正前后油茶果反射率的伪彩色分布,可以直观地看到校正后油茶果像素点的反射率分布比校正前更均匀,说明均值归一化方法的有效性。
2.3 不同成熟度油茶果光谱特征分析
在对1 000 份油茶果样本的高光谱图像进行曲率校正之后,使用掩膜的方法计算油茶果的光谱值:以反射率0.2作为分割原始高光谱图像中油茶果样本与背景的阈值,将背景区域的像素值置为0,样品区域的像素值置为1生成掩膜图像,将掩膜图像与油茶果图像做内积运算得到去除背景信息的油茶果高光谱图像,最后将分割出来的油茶果样品每个波长通道所有像素点反射率的平均值作为该样品的最终光谱值,从而提取出1 000 份样品的平均光谱曲线。
由于总样本中可能存在奇异样本影响最终分类效果,使用马氏距离法分别对不同成熟度等级的样本进行检测并予以剔除,最终将剩余939 个样品的光谱数据用于建立分类模型。

图4 939 个样本的原始(a)及其曲率校正后(b)的光谱曲线Fig. 4 Spectral curves of 939 samples before (a) and after (b)curvature correction
939 个样本曲率校正前后的光谱曲线图见图4,校正后的数据分布更加集中,数据特征更加明显。670 nm处的吸收峰主要与油茶果壳中的花青素和叶绿素有关,970 nm处的吸收峰与果壳中的水分有关。将5 个不同成熟度等级的油茶果光谱数据分别取平均值,得到油茶果的成熟度曲线如图5所示。可以发现,不同成熟度油茶果的光谱强度差异主要体现在500~630 nm和720~970 nm之间。在500~630 nm之间,成熟度I和成熟度II样品的反射强度差别较小,随着采样时间的推迟,成熟度III和成熟度IV样品的反射强度较前者有所降低,成熟度V样品的反射强度降至最低,该波段范围内呈现出油茶果的光谱反射率随成熟度的增加而降低的规律。在720~970 nm之间,成熟度II~V样品的反射强度随成熟度的增加而降低,而从成熟度I~V样品的反射强度经历两次先增高后降低的过程,可能是与果壳中内源激素含量的动态变化有关。在5 个不同的采收时间点,成熟度曲线存在较明显的区别,为成熟度分类提供了理论依据。

图5 成熟度曲线Fig. 5 Spectral curves with different maturities
2.4 基于全波长的油茶果成熟度分类
将5 种不同成熟度等级的油茶果样品赋予类别标签1~5,分别采用KNN、RF、SVM、PLS-DA建立基于全波长光谱信息的油茶果成熟度分类模型,各模型参数设置如表3所示。在对各个模型进行参数寻优后,获得了各模型在最优参数下的分类结果如表3和图6所示。可以发现,SVM相比于其他3 个模型的分类效果最好:训练集的分类正确率为98%,测试集的平均分类正确率为97%,对成熟度I样品的分类正确率最高;其次是RF模型,对油茶果成熟度的平均分类正确率为86%,对成熟度I和成熟度IV样品的分类正确率较高;PLS-DA模型的分类效果一般,测试集的正确率为76%;KNN模型在训练集和测试集上的分类正确率是所有模型中最低。

表3 不同分类模型的分类结果的比较Table 3 Comparison of results of classification of different classification models

图6 不同算法对5 种成熟度样品的分类正确率Fig. 6 Classification accuracy of different algorithms for samples at five maturity stages
2.5 基于特征波长的油茶果成熟度分类
通过降维的方式选取特征波长建立分类模型,在最大程度保留有效波段信息的基础上,通过减少特征维度提高计算速度。由于在4 种分类模型中,SVM分类器对油茶果光谱信息的分类效果最好,为便于比较不同降维方法的优劣,这里统一使用SVM建立分类模型。
CARS和GA选出的特征变量数目较多,而且CARS属于快速粗选算法,因此本研究尝试在CARS和GA降维的基础上,再使用SPA算法进行二次降维,进一步消除干扰波段,最大程度保留有效波段。表4是不同降维方法选择特征变量建立的SVM分类模型结果。可以发现,使用CARS降维后的28 个特征波长的光谱数据建立的SVM模型效果最好:训练集平均正确率为91%,测试集平均正确率为82%,对成熟度IV样品的识别率最高为91%,对成熟度II样品的识别率较低为73%。经SPA和GA降维后建立的分类模型的效果相差不大:训练集上对油茶果的分类正确率为86%左右,测试集上的识别率为80%左右。主成分分析(principal component analysis,PCA)-SVM模型的效果最差:训练集上的分类正确率为64%,测试集上的分类正确率只有55%,可见PCA方法将全波段光谱数据转化为7 个PC的过程中即使保留了99%的信息量,结合SVM建立的分类模型的性能还是较差。CARS-SPASVM和GA-SPA-SVM都是经过二次降维之后建立的分类模型,两组数据集下的SVM模型分类效果相当:测试集的正确率为75%左右,并且两个模型均对成熟度V样品的分类正确率最高,对成熟度II和成熟度III样品的分类正确率较低,究其原因,成熟度V样品的光谱强度相对于其他4 个成熟度等级的样品最低,而成熟度II和成熟度III样品的光谱强度相差不大,在某些波段甚至重叠,导致这两类样品的误判数量较多。总的来说,无论通过哪种方法寻找特征变量建立分类模型,在测试集上对成熟度I和成熟度V样品的识别率最高,因为这两类样品的采样时间间隔最长,光谱特征差异最大,而对成熟度II、成熟度III和成熟度IV样品的分类正确率相对低一些,因为这3 类样品采样时间较为集中,光谱特征的差异性相对较小。

表4 不同降维方法的SVM分类模型结果Table 4 Results of SVM classification models with different dimensionreduction methods
2.6 基于图像特征和光谱特征融合的油茶果成熟度分类
采用颜色直方图表征油茶果高光谱图像的颜色特征。由于常用的颜色空间是RGB和HSV空间,分别取高光谱图像的第64(641.8 nm、红)、46(552.3 nm、绿)、27(459.8 nm、蓝)3 个通道生成对应油茶果样品的伪彩色RGB图像。同时采用灰度共生矩阵表征油茶果高光谱图像的纹理特征,为了能更直观地以灰度共生矩阵描述纹理状况,从矩阵导出能量、对比度、相关度、熵和逆差距5 个参数。
为验证油茶果高光谱图像的颜色特征和纹理特征是否能作为成熟度分类的表征因子,以及在油茶果的光谱特征数据中融入图像特征数据是否能起到优化分类模型、提高模型正确率的效果,分别建立基于油茶果的颜色特征、纹理特征、融合图像特征和光谱特征的SVM分类模型,同时约定光谱特征采用经CARS降维后的数据集,因为各种变量选择方法中,经CARS选择的特征波段建立的SVM模型效果最好。由于颜色特征中灰度级出现频次的量级差异较大,纹理特征中各个纹理参数的量级也不同,因此在建模之前先对数据进行归一化处理。
表5是不同输入特征下的SVM模型分类结果,可以发现,使用单一的颜色特征建立的油茶果成熟度SVM模型测试集正确率为79%,相比使用单一的光谱特征建模的正确率降低了3.7%,并且该模型对成熟度IV和成熟度V样品的识别率较高,分别为92%和95%,对成熟度II和成熟度III样品的识别率较低。使用单一的纹理特征建立的油茶果成熟度SVM分类模型正确率不足50%,说明油茶果的纹理特征参数在油茶果成熟期间没有发生较明显的变化,并且油茶果的表皮光滑,纹理特征并不明显,不能较好地作为油茶果成熟度的表征因子。进一步地,融合油茶果高光谱图像中的颜色特征和纹理特征建立的SVM模型正确率没有使用单一的颜色特征建立的模型正确率高,原因是数据集中的纹理参数拉低了模型性能。融合图像中的光谱特征和颜色特征建立的SVM模型正确率达到93%,说明颜色特征对使用光谱特征建立的分类模型起到优化增益作用,原因是在光谱数据中加入颜色数据,使得不同油茶果样品的特征得到更为充分详尽的描述,也使得不同成熟度等级油茶果的特征得到差异化表达,该模型对成熟度I、IV和V样品的识别率较高,对成熟度II和成熟度III的油茶果样品识别率稍低。融合图像特征(颜色及纹理)和光谱特征建立的油茶果SVM模型的正确率为88%,比使用单一的光谱特征建立的模型正确率提高了7.3%,比使用光谱特征和颜色特征融合建立的SVM模型正确率降低了5.4%,说明油茶果的光谱信息与纹理信息相比占绝对主导,加入纹理数据后反而会导致信息冗余,使得模型性能有所降低。

表5 不同输入特征下的SVM分类结果Table 5 Results of SVM classification with different input characteristics
总体上说,融合颜色特征和光谱特征建立的油茶果成熟度SVM分类模型的效果最优,并且模型对成熟度I、IV、V油茶果样品的识别率普遍高于对成熟度II、III样品的识别率,原因是成熟度I、IV、V油茶果样品之间的特征参数差异性较大,易于分辨,而成熟度II、III样品之间的特征差异相对较小。
3 结 论
对利用高光谱成像技术进行油茶果成熟度检测的可行性进行探究,采用实验室内静态测量的方式观察和分析油茶果的光学特性,在此基础上分析利用油茶果的光学特征判断油茶果的成熟度的准确性。目前结合田间动态测量讨论自然环境下光谱检测油茶果成熟度的可行性的田间试验正处于方案论证阶段,将在今年油茶果成熟期(10—11月)进行,为达到油茶先熟先采、后熟后采、随熟随采的智能化采摘新阶段奠定理论基础。主要结论如下:1)分别使用KNN、RF、SVM、PLS-DA建立基于全波段光谱数据的油茶果成熟度判别模型,发现SVM模型的分类正确率最高:训练集正确率为98%,测试集正确率为97%。2)分别使用SPA、CARS、GA、CARS-SPA、GA-SPA对全光谱进行降维,建立基于特征变量的SVM模型,发现经过CARS方法选择的特征波段建立的分类模型正确率最高:训练集分类正确率为91%,测试集的正确率为82%。3)提取油茶果高光谱图像中的颜色特征和纹理特征,分别建立SVM分类模型后发现,融合颜色特征和光谱特征建立的SVM模型的正确率高于使用单一的光谱特征(经CARS降维)建立的模型正确率:训练集分类正确率为95%,测试集正确率为93%。
