基于改进EfficientNet的植物图像分类算法*
2022-08-30光金正梁鉴如刘义生
光金正,梁鉴如,刘义生
(1.上海工程技术大学 电子电气工程学院,上海 201620; 2.苏州科技大学 机械工程学院,江苏 苏州 215000)
0 引 言
近年来,卷积神经网络[1]已被广泛应用于图像分类领域中。深度学习[2]也逐渐被应用于植物图像分类中[3],植物图像分类算法的精度虽然已经得到了很大的提高[4,5],但是大部分的高精度分类算法[6,7]的模型都很大,难以在嵌入式设备等设备终端使用。其中主要原因是大多数分类算法提升精度仅是通过对神经网络的深度、宽度和分辨率中的单一维度进行扩张获得。例如,残差网络[8]是通过不断加深网络的深度以获取更高的精度,但随着网络的加深,优化难度也在加大,并且会出现精度逐渐趋于饱和的现象。经研究发现[9],仅增加网络的宽度和分辨率与仅增加网络深度一样,都会出现精度逐渐趋于饱和的现象。因此,在精度即将趋于饱和时,微小的精度提升往往需要非常多的网络参数。这使得模型变得十分庞大,执行效率也变得更加慢。
综合上述,要提高植物图像分类的精度应该是同时从深度、宽度和分辨率三个维度进行放缩,在放缩时最重要的问题是如何平衡网络中所有维度。
本文是使用EfficientNet基线平衡网络所有维度[9],同时,对EfficientNet进一步改进以获得更高的植物图像分类精度。
1 原 理
1.1 EfficientNet系列网络
EfficientNet是一个结合神经网络搜索技术的多维度混合放缩的网络。EfficientNet系列网络是在EfficientNet—B0的基线上调整深度、宽度、分辨率和丢失率获得的。深度、宽度和分辨率的放大倍率是由一个混合系数φ决定的
d=αφ,ω=βφ,r=γφ
s.t.α·β2·γ2≈2
α≥1,β≥1,γ≥1
(1)
式中α,β,γ和φ为固定常数。α=1.2,β=1.1和γ=1.15为令φ=1时通过网格搜索获得的最优常数,从而确定最基本的EfficientNet—B0模型。在固定α=1.2,β=1.1和γ=1.15值后,通过使用不同的φ值,从而计算出如表1所示的B0~B7模型的深度系数、宽度系数和分辨率。显然,常规卷积运算的计算量(FLOPS,每秒浮点运算次数)与d,W2,r2呈正比关系。例如,宽度增大为原来的2倍,则FLOPS增大为原来的4倍。而EfficientNet系列网络的FLOPS是由(α·β2·γ2)φ决定的。在α·β2·γ2≈2约束下,EfficientNet系列的FLOPS约等于原来的2φ。
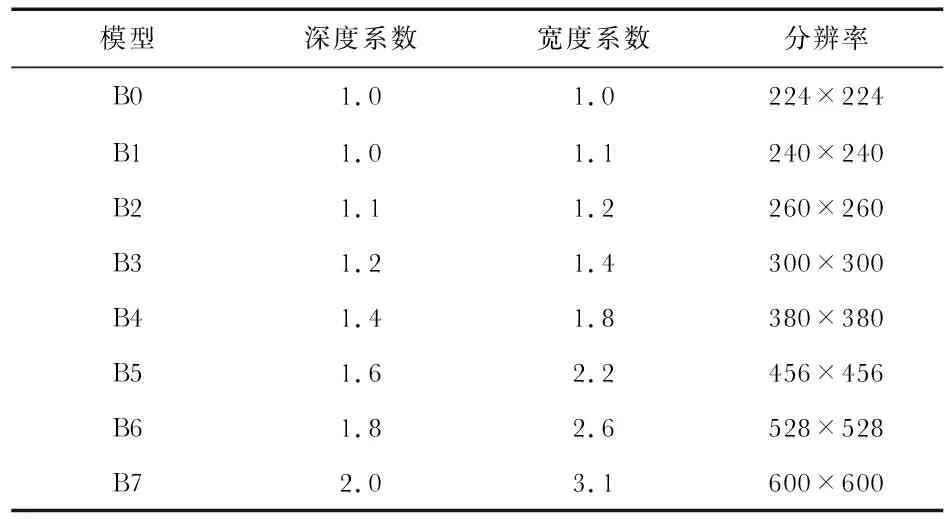
表1 EfficientNet系列网络模型系数
1.2 EfficientNet-B0网络模型
EfficientNet—B0的核心结构是移动翻转瓶颈卷积(mobile inverted bottleneck convolution,MBConv)。与MobileNet—V2结构类似,MBConv是由深度可分离卷积和压缩与激发网络(squeeze-and-excitation network,SENet)组成的。EfficientNet主干网络如图1所示。

图1 EfficientNet主干网络
首先,图像以224×224×3作为输入,开始降采样卷积层是用32个3×3×3和步长为2×2的卷积核。接着是进行批归一化层处理和激活函数,输出为112×112×32。然后进入16层不同步长和卷积核的MBConv层。主干网络最后卷积层是有1 280个1×1×320和步长为1×1的卷积核,输出大小为7×7×1 280。此外,为了提高网络的泛化能力,主干网络加入大量在训练过程中随机丢弃的DropConnect。
1.3 激活函数
激活函数是将非线性因素从神经元的输入端映射到输出端的函数,在神经网络训练和精度上都起重要的作用。本文实验使用到如图2所示的ReLU,Swish和Mish激活函数[10]。ReLU函数是神经网络中最常用的激活函数,具有加快训练和克服梯度消失的特点,但若输入为负数时ReLU函数就无法激活。ReLU函数数学表达式

图2 激活函数对比
F(x)=max(0,x)
Swish函数主要克服了ReLU在输入为负数时无效的问题。Swish函数数学表达式
F(x)=x*sigmoid(β*x)
式中β为常量。与Swish函数比,Mish函数更加平滑,负值时允许更小的负梯度流入神经网络,从而得到更好的精度。Mish函数数学表达式
F(x)=x*tanh(ln(1+ex)
1.4 迁移学习
迁移学习是一种机器学习技术,是将在某一任务上学习到的特征应用到相近的任务上。迁移学习的具体实现是先冻结预训练好提取模型特征的前几层,然后用目标任务的新层替换模型剩下的几层,最后再进行训练。与从头训练一个模型比,迁移学习具有训练耗时少和精度高的特点。
1.5 EfficientNet改进
EfficientNet改进是以图1的EfficientNet—B0主干网络来提取图像的特征,依次加入批归一化(batch normalization,BN)层、Mish激活函数、全局平均池化层(GAP)、随机失活(Dropout)层和SoftMax分类层,最后,把主干网络中的Swish激活函数也全部替换成更优的Mish激活函数,详细网络结构如图3所示。BN层作用是为了加快模型收敛速度和缓解深层网络中梯度弥散问题;全局平均池化层作用是代替全连接层,减少模型的参数量;Dropout作用是缓解网络模型过拟合,提高网络的泛化能力;SoftMax分类层作用是把输出值转化为所有类别概率之和为1的概率分布[11]。
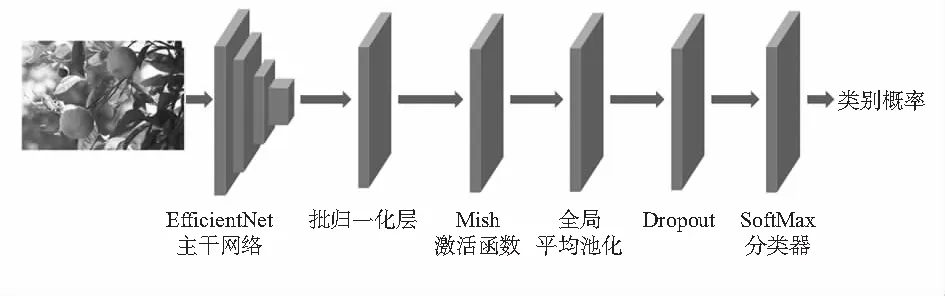
图3 改进EfficientNet网络
1.6 损失函数
本文是植物图像多分类问题,采用交叉熵损失函数辅助网络训练,有利于提高植物分类精度。交叉熵损失函数是评估训练输出概率与期望输出概率之间的距离差异情况,如果距离越小,说明两者的概率分布就越近,训练结果越好,反之,训练结果越差。交叉熵损失函数数学公式
式中y为期望输出,a为实际输出(a=σ(z),z=wx+b)。
2 实验与数据分析
2.1 环境配置
本文实验运行环境配置如下:操作系统(OS)采用Windows 10 Professional,CPU:Intel®CoreTMi7—10700K CPU@ 3.8 GHz,GPU:NVIDIA GeForce RTX 2080 SUPER,RAM为16 GB,DISK为1 TB,Frame为TensorFlow 2.3.1,CUDA为v10.1.243,cuDNN为v7.6.5,Env为PyCharm 2020.2。
2.2 数据集和评价指标
实验数据集由自制植物数据集(Plants 105)和牛津大学公开的花卉数据集(Oxford 102 Flowers,简称Flowers102)组成。由于目前在国际上没有公开统一标准的植物数据集,因此本文自行构建一个植物数据集,数据主要来源互联网,少部分来源实拍。Plants105有105种常见的植物,每种植物图片的数量有100~2 000张,共有22 717张图片,按照6︰2︰2的比例将训练集划分训练集13 591张、验证集4 624张和测试集4 502张。该数据集包含常见的蔬菜、水果、药材和花草等物种,部分植物图片如图4所示。另一个Flowers102有102类英国本土常见的花卉,每类花卉有40~256张图像,总共有8 189张图像,官方已将图像划分为训练集6 146张,验证集1 020张,测试集1 020张。Flowers102图像分类难度中等,它图像的差异主要表现在姿态、角度、光照和比例上,然而也有少数类别间差异较小。两个数据集图像共30 906张,训练集19 740张,验证集5 644张,测试集5 522张。

图4 部分植物数据集例子
本文的植物图像分类评价指标是使用Top—1准确率、Top—5准确率、模型体积(model size)和CPU耗时。Top—1是指预测结果中概率最大的一个结果作为预测结果,如果预测最大结果正确,则预测正确。Top—5是指预测结果中最大的前5个结果,如果最大的前5个中有出现正确的结果,则预测正确。模型体积是指模型占用的存储空间。CPU耗时是指在CPU上预测一幅图像消耗的时间,用于检测模型的速度。
2.3 参数设置
迁移学习可以缩短模型训练时间和解决过拟合问题,本文训练是采用在ImageNet数据集上预训练好的权重进行迁移训练[12]。首先,将输入图像调整为224×224×3大小输入网络中。然后,选用交叉熵损失函数和Adam优化器,初始学习率为0.000 1,当验证Loss不提升时则减少学习率,每次减少学习率因子为0.2,最小学习率为10-8。接着,Batch size设置为32,Epoch设置为50。最后,为了保证实验精度的准确性,每个模型进行10次独立重复训练,取这10次实验结果的中位数作为训练结果。
2.4 结果与分析
本文EfficientNet系列模型训练Loss曲线如图5所示,ReLU EfficientNet是EfficientNet使用ReLU激活函数训练的Loss,Swish和Mish EfficientNet同理。

图5 EfficientNet系列模型训练Loss曲线
从图5中看出,在经过20次训练后,ReLU、Swish和Mish的训练Loss曲线基本收敛,ReLU的训练Loss相对较大,Swish的Loss与Mish的Loss差不多,但是Swish的Loss较大一点。随着训练次数的增加,最终三条Loss曲线都在0.02左右,这说明模型是稳定收敛的。
在模型训练结束后,将预先划分好的两个测试集用本文训练好的模型进行测试,得到如表2所示的Top1和Top5准确率。从表2得出,本文使用Mish激活函数的EfficientNet网络在这两个数据集上的精度都优于使用Swish和ReLU函数的精度。在Plants105上,Mish Top—1精度为97.201 %,比Swish Top—1的96.801 %提高了0.4 %,比ReLU的96.002 %提高了1.2 %。而在Mish Top—5精度上因为已经达到了99.5 %以上,虽然它的精度有提升,但是提升的幅度相对较小。同理,在另一个公开的Flowers102上也得到了类似的验证,Mish在Top—1和Top—5的精度上都比Swish和ReLU的精度要高。从实验结果表明,本文改进的EfficientNet算法在植物图像分类上比原Swish函数的EfficientNet提高了0.4 %左右,比ReLU函数的EfficientNet提高了1.2 %左右。
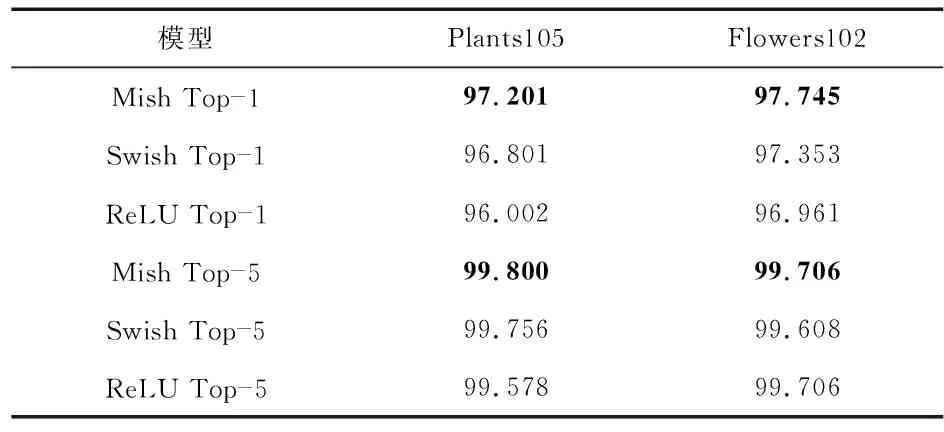
表2 EfficientNet模型Top—1和Top—5精度 %
为了进一步了解本文改进EfficientNet (mEfficientNet)的性能,本文在表3与不同模型的Top—1准确率(Top—1 Acc)、模型体积(model size)和CPU耗时进行了对比。
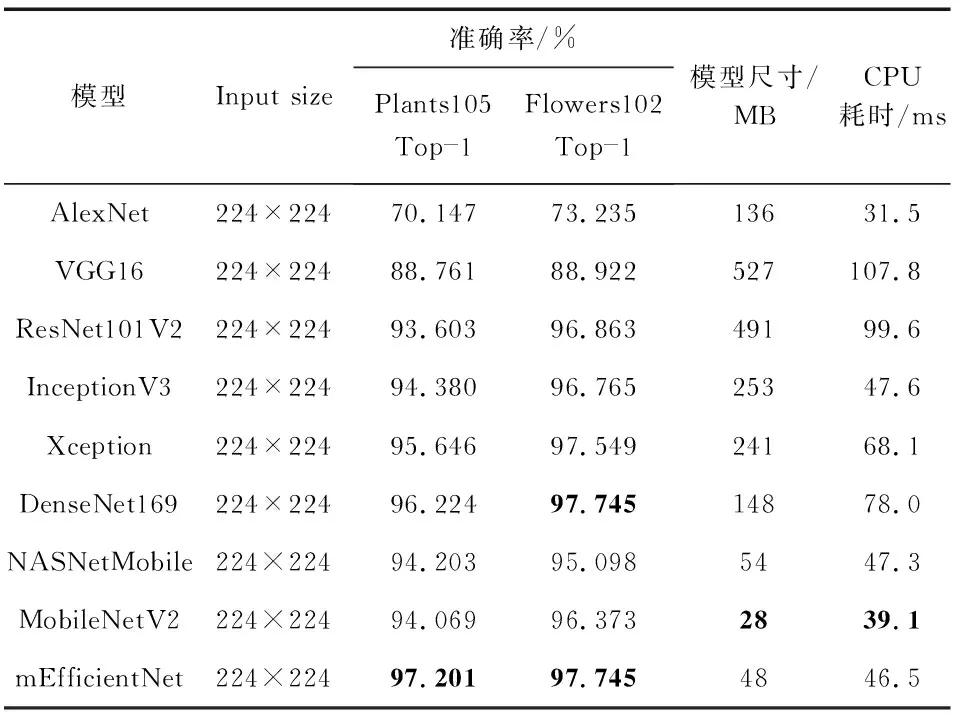
表3 不同模型对比
在Plants105上,mEfficientNet准确率比其他模型都高,比紧接着第二名的DenseNet169高了约1 %,比MobileNetV2和NasNetMobile轻量化网络高了约3 %。在另一个Flowers102数据集上,mEfficientNet除了与DenseNet169准确率一样,比其他模型的准确率都高,但是DenseNet169的模型体积是mEfficientNet的3倍。在模型体积和CPU耗时上,表3前6个模型的体积都比后3个模型体积大几倍,而且在准确率上也和后3个模型相差不多。与MobileNetV2比,mEfficientNet模型体积大20 M和慢7 ms,但在Top—1准确率上却提高了1 %~3 %。如果其他模型要提高到这个准确率,则需要更大的模型体积和更低的速率。例如,DenseNet169提高到这个精度,则需要比MobileNetV2增加5倍左右的模型体积和2倍的CPU耗时。因此,从实验结果表明,改进的EfficientNet能在计算量相当时增加少量的网络参数,实现更高的分类准确率提升,也证明了对网络进行多维度的放缩能更有效地提高模型的准确率。
3 结束语
本文以EfficientNet网络作为植物图像分类特征提取的主干网络,并用更优的Mish函数替换原来的激活函数。与其他网络比,改进的EfficientNet在植物图像分类上表现更加出色,有着更高的分类准确率、更小的模型体积和更快的识别速率。本文方法因为具有对硬件设备要求低和计算量小的特点,更适合嵌入式设备末端部署。然而,本文方法如何在嵌入式设备末端部署是今后研究的重点。
