一种基于Web日志的混合入侵检测方法
2022-08-29张先荣
李 钊,张先荣,郭 帆
(1.安徽医科大学 图书馆信息技术部,安徽 合肥 340100;2.广州大学 网络空间先进技术研究院,广东 广州 510000;3.江西师范大学 计算机信息工程学院,江西 南昌 330022)
随着互联网技术的高速发展,网络在人们生活中呈现爆发式的增长,Web平台具有大量的网络信息资源,这也导致了Web网站的漏洞越来越多[1]。据Gartern的统计,在绝大多数的网络攻击中,发生在Web层面的攻击高达75%左右[2],因此面向Web程序的入侵检测就显得极为重要了。
Web入侵检测系统主要分为误用检测和异常检测[3],误用检测技术通常对所有已知的攻击类型进行建立模型和规则匹配库,因此误用检测类似于黑名单机制,优点是能够检测已知的攻击和具有较低的误报率,缺点是对未知的攻击难以检测,所以当面对未知攻击时误用检测的检测率有时候并不理想。异常检测是对正常行为进行建模,构建正常行为模型,不用分析所有的攻击类型,类似于白名单机制,优点是具有较高的检测率,缺点是误报率通常较高。
对于Web入侵检测,众多学者对此领域做出了相关贡献。Almgren等[4]以Web应用日志URL的路径、编码字符等作为攻击特征,通过攻击特征来匹配攻击请求,设计了Web误用检测系统,具有较高的检测率和低误报率。著名的入侵检测攻击Snort[5]就是典型的基于网络流量检测的误用检测系统,通过官方网络攻击规则库或者自定义规则库能够对网络流量进行入侵检测。Jin Wang等[6]人提出了一种新的允许网络爬行轨迹的方法来建立基线轮廓,并设计了一种新的基于异常的http泛洪检测方案(简称HTTP-sCAN),HTTP-sCAN不受未知网络爬行轨迹的干扰,能够检测出所有的http -flood攻击。Li Bo等[7]人提出了一种基于加权深度学习的子空间光谱集合聚类方法,称为WDL-SSEC,应用集合聚类模型将异常与正常样本分离,然后,使用word2vec来获得标记的语义表示,并连接加权标记以获得url的向量。最后,基于子空间的集合聚类和局部自适应聚类(LAC)将多聚类异常分为具体类型。
以往研究大多是从误用检测或异常检测的单个纬度去讨论入侵检测系统的,因此本文设计了混合的入侵检测系统,首先,基于Web已有的攻击方法,提取Web日志的攻击向量构建攻击规则匹配库,设计了Web误用检测模型。其次,采集Web日志的正常访问数据,构建正常访问模型,设计了异常检测模型。最后,在误用检测和异常检测的基础上设计了基于Web日志的Web混合入侵检测系统模型WL-HIDSM(Web Log Intrusion Detection System Model)。
1 Web混合入侵检测系统模型WL-HIDSM
1.1 Web入侵检测系统的体系结构
Web混合入侵检测系统WL-HIDSM采用模块化设计,模型的总体设计方法如图1所示,利用这个混合入侵检测模型能够增加入侵检测的检测率和降低入侵检测的误报率,它的主要包括以下3个部分。
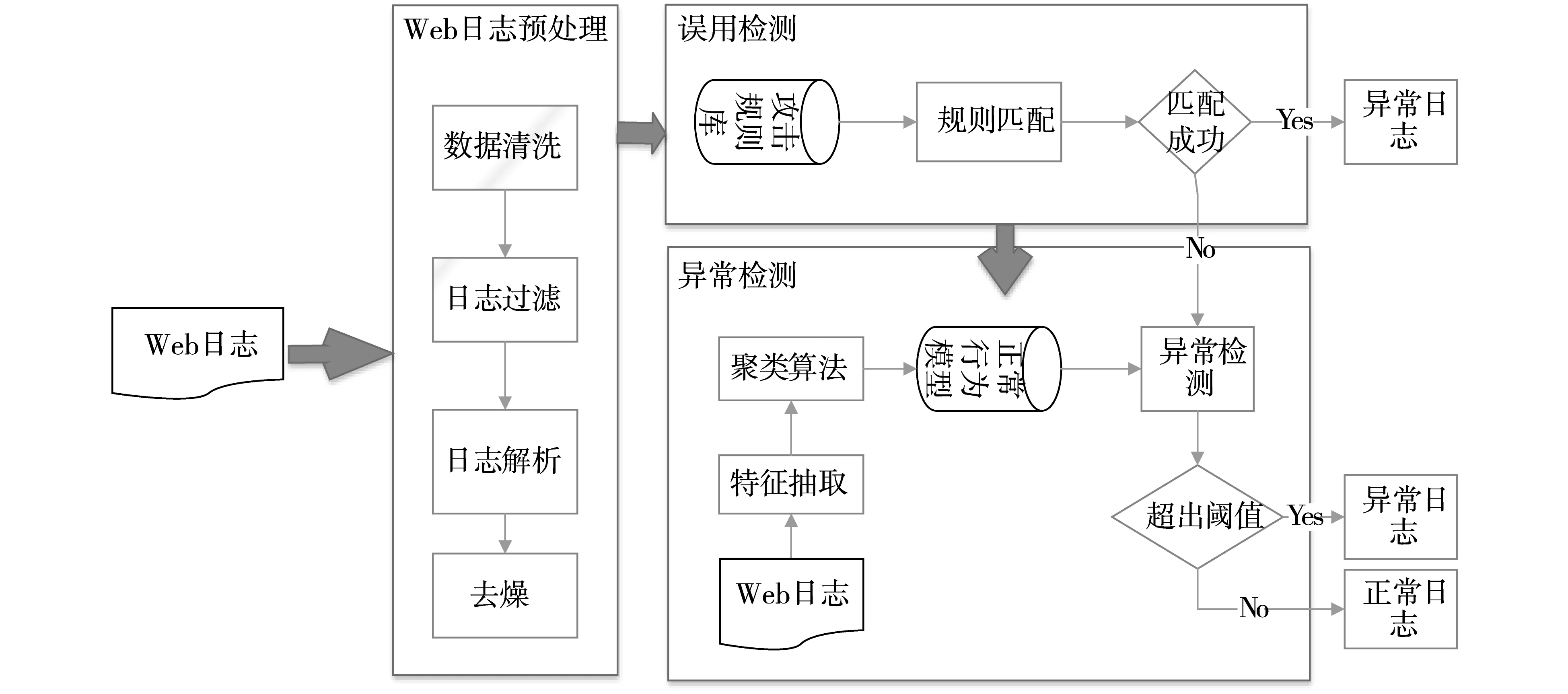
图1 Web混合入侵检测模型WL-HIDSM总体结构
(1)Web日志预处理模块:这个模块的功能是将Web日志的数据进行预处理和清洗。
(2)误用入侵检测模块:通过Web攻击向量构建规则库,将Web日志与规则库匹配,若匹配成功则表示检测到入侵,若匹配失败,则将进行异常入侵检测。
(3)异常入侵检测模块:通过正常的Web日志数据构建正常访问模型,将误用检测没有匹配成功的日志数据送至异常检测模块进行检测,若超过设定的阈值则表示检测到异常日志数据,反之亦然。
1.2 Web误用检测模块
误用检测有着检测率高和误报率低的特征,这导致大量的工业产品使用误用检测技术。
误用检测技术[8]是分析出各种已知的攻击类型数据,并将这些攻击数据集合构建一个攻击向量库,然后将待测数据与攻击向量库进行匹配,若匹配成功则表示检测到入侵行为。鉴于本文的检测数据是Web日志,所有将构建的攻击向量库与Web日志匹配,若匹配成功,则表示Web程序受到入侵。误用检测原理如图2所示。

图2 误用检测模型
由图2所示误用检测技术的原理,我们可以总结Web误用检测模型的两个关键:一是需要收集Web程序的各种攻击类型方式,并能够对已知的各种攻击类型进行分析和攻击向量提取;二是对攻击向量进行分析并构建合适的规则库。
本文Web误用检测模块从Web日志采集入侵数据,首先搭建使用PHPStudy v8.1[9]搭建Web服务器集成环境来模拟真实的运行环境,并将WebGoat[10]Web漏洞测试平台放入服务器环境中,然后再OWASP Top10 2021[11]中获取已知的Web程序攻击向量,将使用这些获取的Web攻击向量在集成环境中测试,最后,将根据获得的Web日志数据构建攻击向量匹配规则库。具体实现如图3所示。

图3 Web误用检测流程
我们以XSS跨站脚本攻击的攻击荷载payload:为例在Web漏洞站点WebGoat进行测试,获得Web日志数据为:%3Cscript%3Ealert%281%29%3C%2Fscript%3E,通过得到的入侵测试数据分析得到正则表达式为:(?i)

表1 XSS部分正则匹配库
1.3 异常检测模块
对于Web程序来说,用户的访问行为可以使用用户的访问序列来代替,即请求同一主机在特定的时间窗口内向Web服务器发送的序列,因此我们可以使用ip地址或用户代理来代表不同的用户,每个序列中的请求按响应时间进行排序。
我们使用向量Seq代表定义访问的用户序列。
定义Seqi=(Ri1,Ri2,…,Ril),其中R=(x1,x2,…,xN),Seqi为第i个用户序列,x是HTTP Requset请求报文的特征值。
从每个日志中提取特征并计算特征值,构造每个用户序列,得到每个用户L×N大小的特征矩阵来描述用户的行为。
不同的用户有着不同的访问行为,正常用户的访问行为通常与恶意用户一定是不同的,我们可以应用k-menas聚类算法来对访问用户进行分类。
所有用户的行为都可以聚类成k个集群[12],分别表示C1,C2,…,Ck。因为我们将用户的行为分为正常行为和恶意行为。所以会有一个主要集群,包括用户的主要行为和许多远离主要集群的小集群。我们使用公式(1)计算点到簇中心的距离,使用方程(2)计算每个点放到它最近的中心Cj[13]。
(1)
(2)
(3)
方程(3)中的μ是簇中所有点到中心的平均距离。我们可以得到主簇的中心,并计算每个向量到中心的距离。在距离的帮助下,我们设置一个阈值来确定它是否是一种攻击。
2 实验结果与分析
2.1 实验环境配置与设计
本文是在CPU为Intel(R)Core(TM)i5-4300M @2.60GHZ和内存为8G的硬件环境下设计的,操作系统为Windows 7专业版。
数据集为合成的数据集,数据集分为两部分,第一部分为安徽医科大学图书馆网站的Web日志,我们采集了从2020年1月份到2020年12月份的用户正常访问的日志数据。第二部分为构造的日志数据,我们使用渗透测试工具nikto[13]、Xsser[14]、sqlmap[15]、Web爬虫工具Webmagic[16]构造如下表2所示的五种Web攻击类型。

表2 构造的数据集
2.2 误用检测模型实验数据结果与分析
首先,我们先对误用检测模型进行实验并分析结果。实验结果如表3所示。

表3 误用检测模型检测率与误报率 %
表3显示了五种不同的Web攻击类型的检测率DR(Detection Rate)与误报率FPR(False Positive Rate),其中检测率最高攻击的为Dt(89.56%),检测率最低的为CSRF(71.76%),五种攻击类型的平均检测率为79.78%。误报率最低的为Dt(1.02%),最高的为Dos(2.03%),平均误报率为1.77%。
通过表3中的数据分析,检测率效率低于80%,检测率不高,误报率低于2%,误报率较低。
2.3 异常检测模型的实验数据结果与分析
异常检测需要构建一个正常的Web日志访问模型,我们使用K-means聚类算法来训练正常的日志数据集。在本实验中,将日志分为5组簇作为日志的正常模型。实验结果如表4所示。

表4 异常检测模型的检测率与误报率 %
从表4中数据显示检测率最高的攻击类型为SQLi(98.16%),最低为Dt(89.96%),平均检测率为94.14%。与表所示的误用检测相比,异常检测的平均检测率(94.14%)要高于误用检测平均检测率(79.78%),误报率最高的攻击类型为Dos,最低的攻击类型为Dt,平均误报率为3.51%,通过与误用检测的误报率(1.77%)相比,异常检测的误报率较高。鉴于异常检测能够检测到未知的攻击所以能够检测的更多的攻击。
2.4 Web混合入侵检测模型的实验数据结果与分析
在混合入侵检测模型中,Web日志首先通过误用检测进行实验,若检测到攻击则认为Web日志存在已定义的攻击,若没有检测到攻击,那么使用异常检测模型来检测Web日志,如果检测到,则表示检测到未定义的攻击。这种混合检测模型能够增加攻击的检测率,并且也能够在一定程度上减少误报率。
实验结果如图4和表5所示。

图4 Web混合入侵检测模型检测数

表5 Web混合入侵检测模型的检测率与误报率 %
从表5所示可得,混合入侵的平均检测率(95.74%)要远远高于误用检测模型平均检测率(79.78%),也要稍微高于异常检测模型(94.14%),混合入侵检测的平均误报率(1.38%)也低于误用检测模型(1.77%)和异常检测模型(3.51%)的平均误报率。
从表6中所示,Web混合入侵检测的平均检测率相比误用检测和异常检测平均提升120%,102%;误报率平均降低128%和254%。

表6 三种检测模型的平均检测率与平均误报率对比
3 结论
本文以Web日志数据作为攻击的数据源,分析各种攻击Web方法,并以此建立攻击向量匹配知识库,然后构建误用检测模型,在此基础上,对Web日志使用聚类算法分析得到一个正常用户模型的异常检测系统,最后构建了一个Web混合检测模型,此模型能够在一定程度上能够增加检测率和降低误报率。
