基于卷积神经网络的垃圾图片处理与改进
2022-08-29尚志亮嘉明珍马存良
尚志亮,王 伟,杨,嘉明珍,马存良
(江西理工大学 信息工程学院,江西 赣州 341000)
0 引 言
随着城市化的快速发展和人口数量的增加,我国城市垃圾的数量逐年上升。对于如何做到垃圾的有效分类和无害化处理,已成为环境保护和能源可持续利用的热点问题,其中垃圾分类是处理垃圾的前提。目前城市垃圾分类主要依靠人工分拣,这种方式不仅任务繁重而且效率低下,浪费了大量人力。对于经典的分类算法,黄惠玲等利用K-means聚类算法对建筑垃圾的颜色特征进行提取与分类,识别过程所需时间较长,平均为1.17 s。
随着深度学习的发展,涌现出了许多广为人知的卷积神经网络,如VGG、GoogLeNet、ResNet等。在利用深度学习进行垃圾分类方面也取得了一定的成果。武凌等设计了一种基于深度迁移学习的模型,对多种常见的可回收垃圾进行识别分类,并设计了Web应用模型,但模型的准确率仅为90%。汪洋等通过训练Inception V3卷积神经网络结合硬件设计了垃圾分类小程序,其网络识别率仅91.71%。齐鑫宇等提出采用特征多层次化解决图像局部特征表达方面存在的复杂性、模糊性不足等问题,搭建新的模型框架,将识别准确率平均提高了10个百分点,最终达到了92%。本文提出一种基于VGG网络的垃圾图片处理算法,通过加入L1、L2正则化,并使用CutMix数据增强技术来构建准确率较高和鲁棒性较强的垃圾图像识别网络。
1 数据集获取
数据集主要通过网络采集获得,包括有害垃圾、可回收物、厨余垃圾和其他垃圾4类共计17 365张图片,此外又细分为30个小类,其中包括有害垃圾5类、厨余垃圾3类、可回收垃圾19类和其他垃圾3类。数据集分为训练集和测试集,训练集有14 924张垃圾图像,测试集有2 441张垃圾图像。将所有的数据集均处理为jpg格式。
2 数据增强
目前存在的图像增强技术主要有:Mixup、Cutout和CutMix。Cutout是指随机将图像中的部分区域减除,并填充0像素值,分类的结果不变;Mixup是指将随机的两张图像按比例进行混合,分类结果按照一定比例分配;CutMix随机将图像的一部分区域减除但不填充0像素而是随机填充训练集中其他图像的等区域像素值。本文使用CutMix技术进行数据增强。CutMix操作的计算公式为:


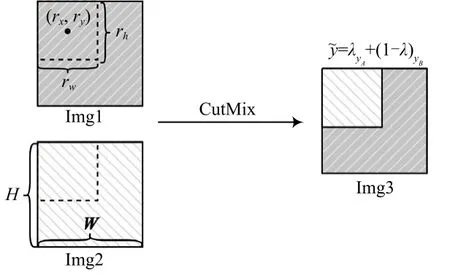
图1 CutMix数据增强技术原理
通过随机生成一个边界框得到,该边界框的参数为:=(r,r,r,r),该参数通过下式得到:
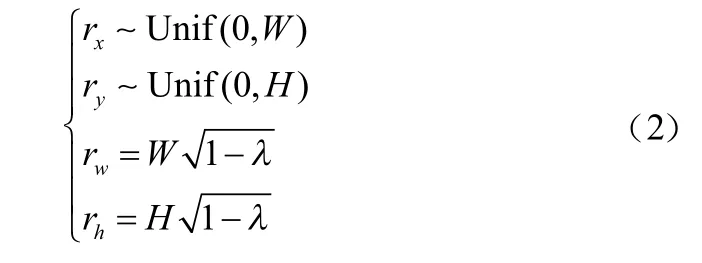


图2 CutMix处理图像
3 实验网络模型的设计
VGG网络结构简单,使用多个小卷积叠加来代替大卷积核,一方面减少了隐藏层中的参数,另一方面增强了非线性映射,通过多个卷积核的叠加达到了一定的深度,也在一定程度上增加了网络的拟合能力。根据层深将其称为VGG16或VGG19网络,本文采用VGG16网络,即13层卷积层加3层全连接层,其中池化层选取Max池化,激活函数选取ReLU函数,使用Adam方法更新参数。
本文所使用的硬件设备为Intel Corei7-10700K @ 3.80 GHz八核处理器、32 GB内存、11 GB NVIDIA GeForce RTX 2080 Ti显卡,开发环境为64位Windows 10系统、Python 3.8、PyCharm。训练过程中通过VGG16网络的13层卷积层对30个小类的垃圾图像进行特征提取,然后处理为一维数据,通过3层全连接层输出并保存垃圾图像的训练权重。测试过程中,首先输入测试集的图像数据,加载已训练好的模型权重。通过VGG16网络输出测试图像对应类别的权重,最后一层Softmax分类器输出30个小类别对应的概率。模型训练过程和测试流程如图3所示。

图3 模型训练和测试流程
神经网络的过拟合问题是指对训练集有着很好的拟合效果而对测试集拟合效果较差。我们主要采取了以下两种方法防止过拟合:
(1)Dropout方法使用在 VGG16网络的全连接层,通过在全连接层中依概率随机删除一定数量的神经元来减少网络中的参数。本文使用的删除概率为0.5,避免了训练过程中由于大权重而导致完全依赖某一权重的情况。
(2)权值衰减方法包括L1和L2正则化。卷积神经网络中单个交叉熵误差表达式为:

式中:表示交叉熵误差值;y表示神经网络的输出;t表示正确解的标签,采用one-hot编码,即t编码中只有正确解对应的索引为1,其余索引值均为0。在总体交叉熵误差值后加权重的范数平方来约束损失函数称为L2正则化,如下所示:

式中:第一项为所有样本的交叉熵误差之和,除以实现正规化;第二项为L2范数的平方,用来控制正则化强度的系数(≥0),越大对大权重的惩罚就越重,系数1/2是求导的调整量。L1正则化是指在损失函数后添加L1范数项,其表达式为:
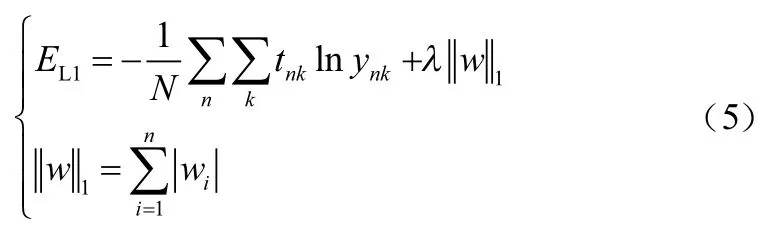
结合权重的更新,其表达式为:

式中,(≤1)为学习率(learning rate)。显然带有正则化项的损失函数经过每一次迭代首先都要乘以一个小于1的因子,这使得每一次的权重更新都在不断减小,但对于不同大小的权重减小的程度不同。若权重较大时,权重迭代更新的下降速度较快,当较小时,权重下降速度较慢,这就解释了为什么可以利用添加正则化的方法来防止过拟合。
4 实验结果分析
为了观察使用CutMix数据增强技术和损失函数修改前后的实现效果,我们通过训练原数据集和经CutMix拓展数据集前后不添加正则化、单独添加L1正则化、单独添加L2正则化以及共同添加L1、L2正则化的8类模型,并通过测试集评估各种模型的准确率和损失函数。
(1)使用原数据集,设置初始学习率为0.000 1,迭代周期为50进行训练,其测试集的准确率和训练过程损失函数如图4所示。

图4 使用原数据集的模型训练过程
Experiment 1-0、1-1、1-2和1-3分别表示不加入正则化、加入L1正则化、加入L2正则化和同时加入L1和L2正则化的训练过程,其正确率分别为:91.17%、91.43%、91.68%和91.60%,可见加入正则化后模型正确率提升幅度不大。原VGG16网络损失函数曲线有一定的波动,在10个epoch左右基本趋于平稳,但准确率在10个epoch前后仍呈上升的趋势,而加入正则化后损失函数变得更加光滑且模型准确率上升时损失函数不断下降。
(2)使用CutMix数据增强技术拓展训练集,通过若干次训练确定最优超参数。网络训练过程如图5所示。
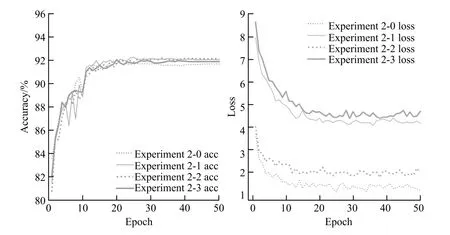
图5 使用CutMix数据增强的模型训练过程
Experiment 2-0、2-1、2-2和2-3表示使用CutMix数据增强方法拓展数据集后加入不同正则化后的训练过程,其正确率分别为:91.93%、92.26%、92.18%和92.05%,与不使用数据增强和不加入正则化的训练结果Experiment 1-0相比,在加入CutMix数据增强之后的模型正确率都有上升,分别提高了0.76%、1.09%、1.01%和0.88%。
(3)为模拟现实情况中垃圾图像的复杂性,我们通过CutMix技术随机处理测试集中若干张垃圾图片,将处理后的图片与其标签分别使用1-0和2-1模型权重进行预测,对比改进前后模型的泛化能力和鲁棒性,其预测结果如图6所示。每张图像下方是其所对应的原始类别以及两种模型输出的测试类别和测试概率。

图6 CutMix处理图片后两种模型的预测结果对比
通过对上述两种模型结果的分析,图像经过CutMix技术处理之后对1-0模型的预测结果影响较大,在对第2幅、第5幅和第8幅图片进行测试时产生了误判,且除第6幅以外的图片正确标签的得分均比2-1模型低。说明通过引入CutMix数据增强的方法训练模型在提高模型预测准确率的同时增强了模型的鲁棒性。
5 结 语
针对现实生活中垃圾图像数量不足和环境复杂等情况,导致在训练神经网络时存在准确率不高、鲁棒性不强的问题,本文通过使用CutMix数据增强技术来扩充数据集并加入正则化改进VGG16网络,分别讨论了8种不同的模型,通过大量实验确定了使用CutMix数据增强的方法可以有效提高模型的准确率和泛化性;通过加入L1和L2正则化,使损失函数在训练过程中变得光滑且不再过早趋于平稳。本文中的2-1模型较原网络有着较强的鲁棒性和更高的准确率,对日常生活中的垃圾识别率达到了92.26%,较原网络模型提升了1.09%,具有较好的应用前景和实用价值。
