电力变压器油色谱在线监测装置的故障识别技术
2022-08-29周敏
周 敏
(国网江西省电力公司抚州供电公司,江西 抚州 344000)
0 引言
在现代电力系统中,油色谱在线监测装置得到了广泛应用,成为保障电力系统安全、稳定运行的重要工具。对油色谱在线监测装置本身的故障,目前应用较多的诊断方法是油中溶解气体分析(DGA),但是从实际应用来看,由于溶解气体成分复杂,因此故障诊断的准确率不高。目前,通过数据建模进行装置故障识别成为一种主流趋势,利用数学模型可以对在线监测数据进行降噪处理、拟合处理以及缺失值处理,让最终的故障诊断结果更加可靠。其中,基于最近邻编辑采样法(ENN)的故障识别算法可以准确、全面地识别油色谱在线监测装置的隐蔽故障,在该装置的日常维护和故障检修等方面发挥了重要作用。
1 电力变压器油色谱在线监测装置的结构组成和常见故障
1.1 装置的结构组成
该装置的核心模块包括油气分离模块、气体组分检测模块、网络通信模块以及故障诊断模块等,整体结构如图1所示。

图1 变压器油色谱在线监测装置
油气分离模块的功能是将溶解在油中并且将包括故障特征的气体分离出来,为下一步的气体检测提供有利条件。如果该模块发生故障,无法正常实现油气分离,则油色谱在线监测装置无法在线监测和准确识别变压器的运行故障。气体组分检测模块的功能是对油气分离、气体组分分离后的特征气体进行浓度检测,然后通过数模转换器将物理信号变成电信号,以便于下一步进行计算机分析。电信号经通信网络传输至主控计算机,利用各种算法、数学模型等完成故障诊断。
1.2 油色谱在线监测装置的故障类型
为进一步提高在线监测的即时性和准确性,现阶段的油色谱在线监测装置结构更精密,故障类型也更多样。根据以往的装置检修与维护经验可以将其故障大体分为4个类型:1) 载气欠压故障,可能与气瓶未完全打开、载气端口漏气等有关。如果载气压力不足,就会导致分离出来的特征气体在色谱柱内停留时间偏短,特征气体的分析不彻底,影响故障诊断的精确性。2) 倒油故障,可能与废油箱排油不畅、倒油管路堵塞等有关。如果废油无法顺利倒入废油箱,也会导致该装置无法正常运行。3) 色谱电气故障,可能与相关电子器件的老化、短路等有关。在发生该故障后,无法进行正常的色谱分析,故障识别和诊断也会受到影响。4) 数据中断故障,可能与通信网络的硬件损坏有关。在发生该故障后,主控计算机无法正常接收气体检测数据,从而不能识别和诊断该装置的运行工况。
2 油色谱在线监测装置的故障识别算法
2.1 基于ENN的故障识别算法
由于油色谱在线监测装置的各类故障具有隐蔽性、突发性等特点,如果采集样本数量偏少,就会导致识别准确率不高。因此,需要扩大样本数量,获得包括大量样板的训练集,通过计算机的深度学习和训练提高对故障的诊断精度。将故障发现时间点与假设故障发生时间点之间的时间间隔定义为故障时间窗口(),然后采集内的油色谱在线监测装置的所有历史数据,并保存到训练集中。考虑训练集中存在不平衡数据,还要对基于最近邻编辑算法(ENN)对得到的训练集进行重采样。具体方法如下。
首先,设训练集={,,…,p,…,p},将中的所有样本按照“数量”与“标签”分成2类,分别是多数类和少数类。从集合中任意选择一个样本p,用最近邻算法求得p的3个最近邻样本,则待计算样本p与其余样本q的关系如公式(1)所示。

其次,将3个最近邻样本分别作为待计算样本,继续运用最近邻算法求其余样本。
最后,在集合中所有样本全部计算完毕后,得到一个新的样本集,则中多数类样本和少数类样本的数量达到平衡状态,在该基础上开展故障分类识别既可以提高故障分析速度,又能保证故障诊断精度。基于ENN的采样流程如图2所示。
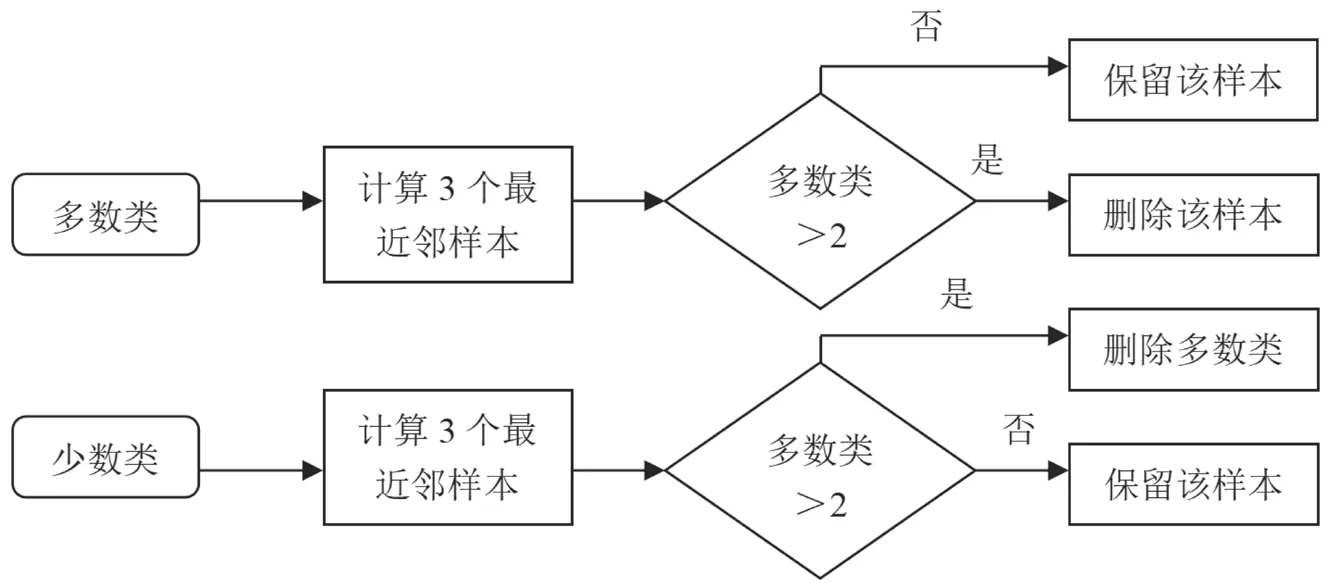
图2 最近邻编辑算法采样流程图
2.2 故障识别算法的基本步骤
基于故障识别算法的油色谱在线监测装置故障分类识别流程如下:1) 获取故障工作清单(xi),输入变压器编号j。2) 对在故障时间窗口内的历史数据进行重采样,得到数据集(aj)。3) 将(aj)加入故障训练集中,添加故障标签。4) 在中运用基于ENN算法进行重采样处理,得到新的数据集。5) 把中的所有数据输入随机森林数学模型中。6) 采取“有放回取样”的方法从中随机抽选个样本。7) 将每个独立样本构成1个决策树,获得个决策树。8) 分别对个决策树进行归类,得到故障分类结果,完成故障识别。
2.3 基于遗传算法的随机森林参数优化
随机森林模型是一种由多个弱分类器组合形成的集成模型。该文基于Sklearn库对随机森林模型进行参数优化。从Sklearn库中调取以下调优函数:1) 决策树数量函数(n_estimators),利用该模型并使用有放回抽样的方式从收集到的原始数据中获得数据,以生成决策树,n_estimators表示决策树的数量。该函数能保证决策树的数量适中,既避免了决策树数量过多导致算法运行速度变慢的问题,又解决了决策树数量太少导致分类识别精度不高的问题。2) 决策树最大深度函数(max_depth),在样本数量以及样本特征较多的情况下,运用该函数能够有效提高模型的泛化性能和运算速度。3) 最大特征数量函数(max_features),当随机森林模型生成分类决策树时,需要考虑其最大特征数是否合适。如果最大特征数≥原始数据集,则需要重新调整随机森林模型,保证其产生的决策树<原始数据集,缩短生成决策树的时间,进而提高故障识别效率。
3 油色谱在线监测装置的故障识别试验
3.1 试验准备
该试验以Windows10系统作为平台,所选数据来自于30台220 kV电力变压器的油色谱在线监测数据,样本数据共82 850条,特征气体包括H、CO、CH和总烃等,详细的气体类型及监测数据见表1。

表1 电力变压器油色谱在线监测数据(单位:μL/L)
对获取到的油色谱在线监测装置相关数据,使用遗传算法进行参数优化。寻化标准设定如下:1) 决策树的数量以[1,50]为寻优空间。2) 决策树的最大深度以[1,10]为寻优空间。3) 最大特征数量以[1,8]为寻优空间。4) 节点可分的最小样本数以[1,50]为寻优空间。5) 叶子节点最小权重以[0,0.2]为寻优空间。
基于上述标准,使用CostFuction函数进行迭代寻优,迭代次数设定为100次,基于寻求结果绘制参数寻优曲线图,如图3所示。
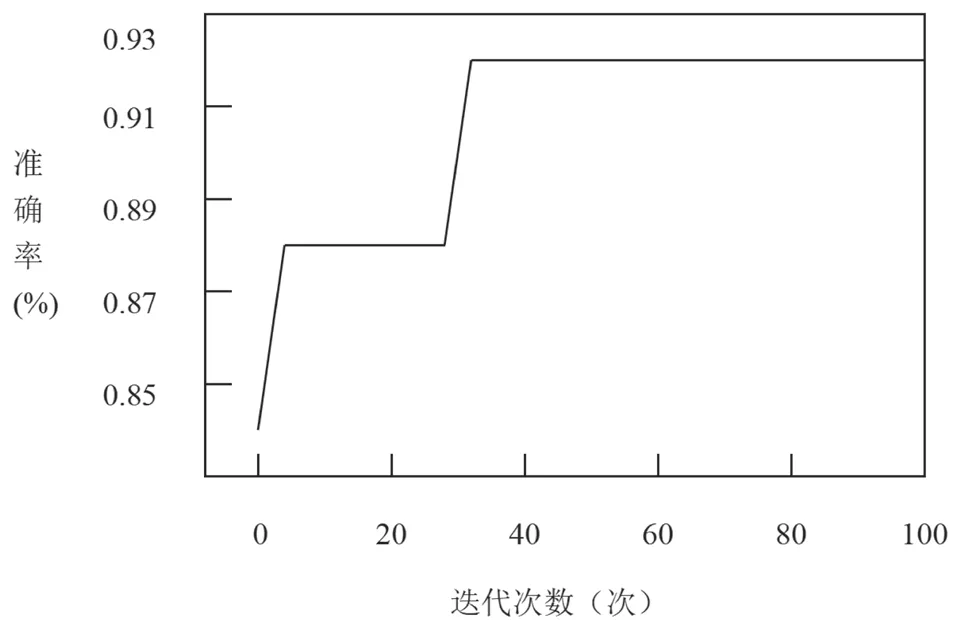
图3 遗传算法参数优化
3.2 基于ENN的随机森林的故障识别
该试验将故障时间窗口设定为20,选择油色谱在线监测装置的4项典型故障(倒油故障、载气欠压、数据中断以及色谱电气故障)展开分类预测。将优化后的数据输入基于ENN的随机森林模型中,根据模型计算结果绘制故障识别混淆矩阵,如图4所示。
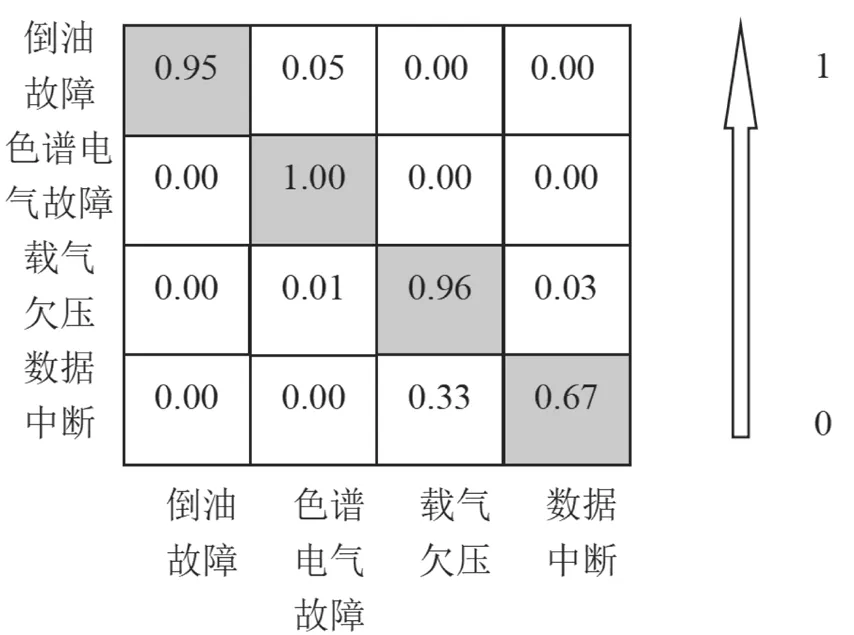
图4 故障识别混淆矩阵
3.3 多分类的ROC曲线
该试验共选择4项评价指标,分别是准确率、查准率、查全率以及查准率和查全率的加权平均值。各指标如公式(2)~公式(5)所示。

式中:为正确识别的正类样本数量;为正确识别的负类样本数量;为预测正类样本的数量;为实际正类样本的数量。
各项评价指标的计算结果见表2。

表2 分类评价指标统计
结合上表数据可以发现,该算法模型平均分类正确率在90%以上,明显高于人工判断水平。在该基础上,另外选择2项指标TPR(真正例率)和FPR(假正例率)来判断数学模型在故障识别方面的应用效果。2项指标如公式(6)、公式(7)所示。

根据公式(6)、公式(7)的计算结果绘制多分类的ROC曲线图。二维图以作为轴,以作为轴,如图5所示。
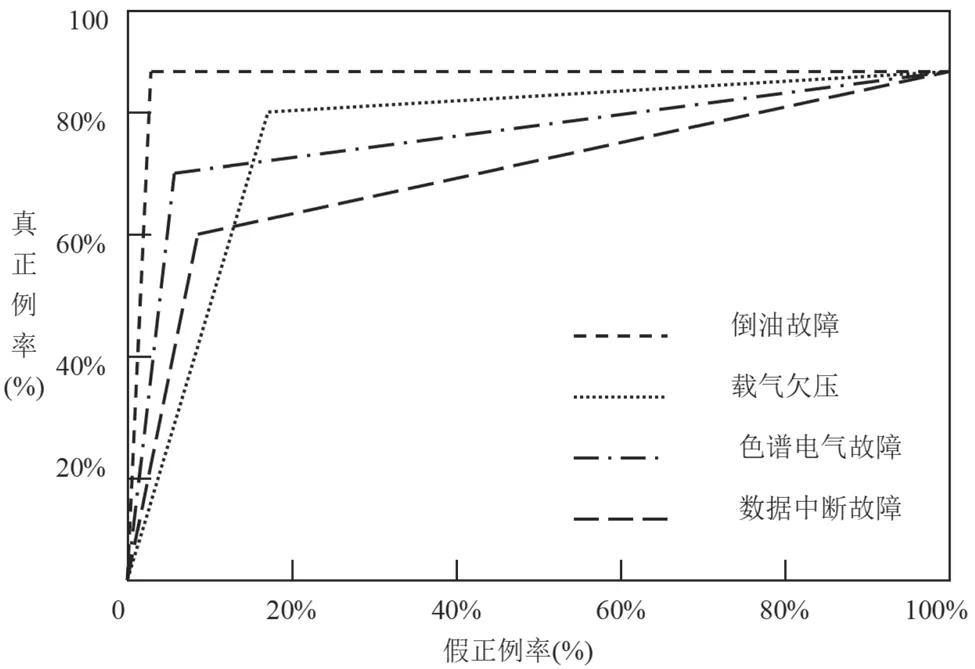
图5 多分类的ROC曲线
在多分类ROC曲线图中,引入作为模型性能的评价指标。表示曲线的线下面积,越大,说明模型性能越好。其中,的取值范围为[0,1]。由图5可知,4条曲线的数值基本都维持在0.9左右,说明该算法模型对油色谱在线监测装置的4种常见故障均有良好的识别效果。综合表2和图5的数据可知,该文提出的基于ENN的故障识别算法能够精准识别油色谱在线监测装置常见的倒油故障、载气欠压、色谱电气故障和数据中断故障,在辅助设备管理人员开展日常检修和故障排查方面发挥了实用价值。
4 结语
油色谱在线监测装置是保证电力变压器稳定、可靠运行的关键设备,如果该装置发生故障,就不利于变压器的检修维护,增加了变压器发生故障的概率。经试验证明,该文提出的一种基于最近邻编辑采样法的故障识别技术可以对油色谱在线监测装置的几种常见故障进行准确识别,识别精度维持在90%以上。该技术的应用可以及时发现油色谱在线监测装置的异常工况和潜在故障,可以保证在线监测装置的正常运行。
