基于机器学习的初中人工智能编程教学实践
——以利用线性回归预测某城市房价项目为例
2022-08-29付东升
付东升
(厦门英才学校,福建 厦门 361000)
0 引 言
人脸识别、自动驾驶、智能客服、短视频推荐、金融风控、智慧医疗、智慧农业、机器人技术等,这些都是人工智能在各个行业中的具体应用。人工智能涉及的范围较广,知识难度较大,根据目前人工智能丛书中所提出的内容,主要以了解人工智能在生活中的应用为主,或结合给定功能的开源硬件,体验人工智能项目的应用,往往不能真正理解人工智能中某个项目的原理,代码编程项目设计更是无从下手,因此,本文尝试以线性回归项目为基础,开展项目化的人工智能教学,结合初中生认知水平,从原理的讲解到代码的编写,以期给中学人工智能教学以借鉴作用。
1 课堂实践
机器学习分为监督学习、无监督学习和强化学习,其中监督学习又包含回归问题和分类问题,线性回归是机器学习中的经典模型。初一学生对人工智能已有初步的了解和接触,学生已达到学习机器学习基础知识的认知水平,本节将应用Pycharm 编程软件,通过Python 语言尝试对“某城市房价问题”这一线性回归问题做编程尝试,学生在实际代码的编写过程中探究线性回归的基本原理,切身体验分析问题、设计算法、编写程序、调试运行的过程。
2 项目方案设计
教师围绕计算机解决问题的一般过程:分析问题、设计算法、编写程序、调试运行与“导入相关的工具包、加载数据集、模型训练和预测、预测结果可视化”四个步骤进行教学活动,具体教学过程有以下几个方面。
2.1 联系生活分析线性回归问题
2.1.1 提出问题
中国人一般都有家的情节,我们每天住在宽敞的房子中,有没有想过能住在漂亮的房子里,是因为父母辛勤的工作?回到问题上,现已知:20 世纪70年代中期,某城市郊区住宅的一些数据点,比如犯罪率、当地房产税率等。
教师提出问题:假设你是一个房地产商人,根据给定的一组关于郊区住宅的数据点,如图1所示,你能够预测出其他住宅的售价为多少会更合适吗
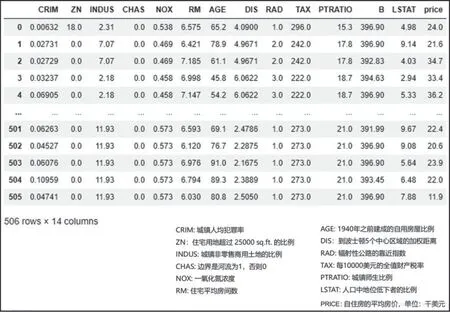
图1 郊区住宅数据点
设计意图:在情感态度价值观上,学生能更理解父母工作的不易,只有付出才有回报,同时基于问题的教学法开篇,抛出回归问题案例,激发学生兴趣。
2.1.2 认识数据集中存有哪些数据
(1)load_boston 数据集是以字典(Dictionary)的方式存储数据,使用以下三行代码,可输出load_boston 数据集中所含有的“键”,输出结果如图2所示。

图2 load_boston 数据集中所含有的“键”
代码:

设计意图:引导学生深度挖掘某城市房价数据,掌握其采用字典存储方式的意义,即便于通过“键”查找其“值”,从而理解数据集中存储的每一个“键”的含义。
数据集含有数据(506 个样本,14 个属性):主要为:数据(‘data’),目标价格(‘target’),特征名称(‘feature_names’)。
(2)引导学生思考数据集中字典的“值”是多少呢?应用一行代码,可以输出完整的某城市数据集,输出结果如图3所示。
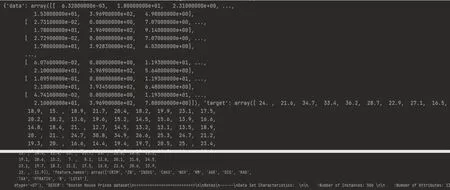
图3 数据集中的数据
代码:
print(dataset)
设计意图:学生理解字典存储数据意义的基础上,输出完整数据,清楚认识“键”和其所对应的“值”,只有深度了解数据集中的数据,才能便于调用数据。
2.2 设计算法理解线性回归原理
(1)我们提取住宅平均房间数这一个特征(rooms)作为横坐标值,根据值找到数据集所对应的值,也就是住宅的价格(price),形成散点图如图4所示。
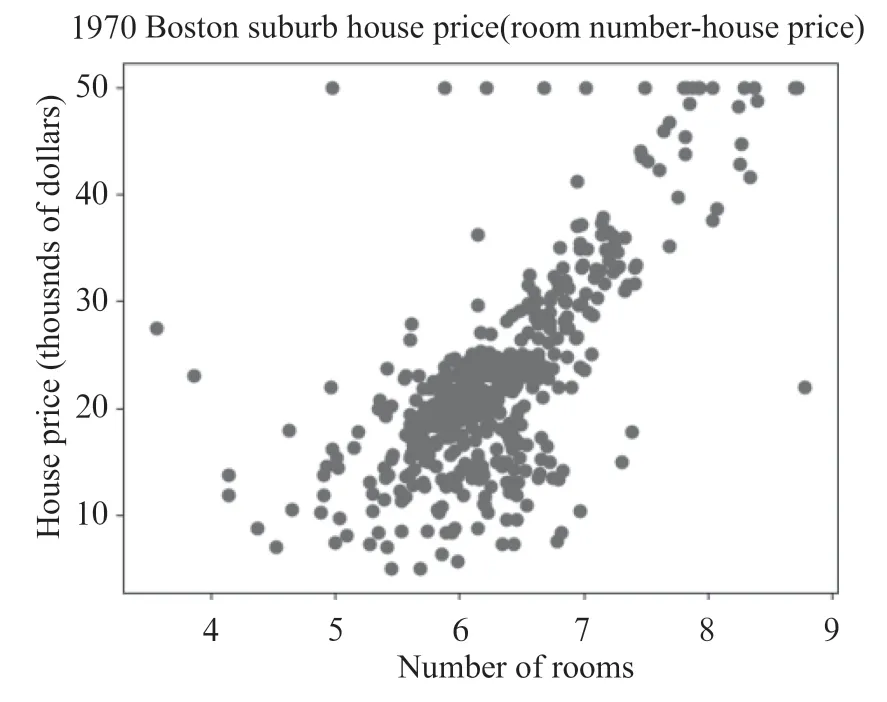
图4 住宅平均房间数(x 值)与住宅所售价格(y 值)散点图
设计意图:数据集中有13 个特征,可引导学生从一个特征(住宅平均房间数rooms)入手,找出住宅平均房间数与房价的关系,即从特殊到一般的科学探究方法。
(2)观察这个散点图,会发现一些规律,大概率是住宅平均房间数越多,住宅的价格越高,此趋势可用一次线性函数=·+(输入特征为住宅平均房间数,输出标记为住宅所售价格,是与轴的截距)拟合,如图5所示。
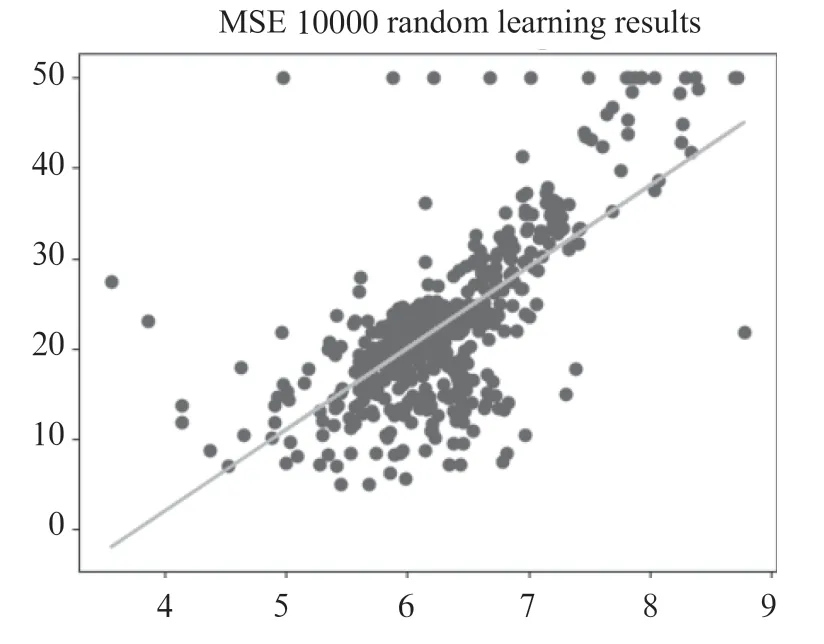
图5 一次线性函数
设计意图:这就是最简单的线性回归模型。我们要做的就是利用已有数据,去学习得出这条直线,拟合出这条直线,则对于横坐标(rooms)的任意取值,我们都可以找到直线上对应的值,也就是模型的预测值(price),当然从图5中能看出存在一定的误差,这就需要学有余力的同学去深度思考,如何减小误差。
2.3 编写程序探究线性回归过程
2.3.1 步骤一:导入相关的工具包
# 使用 sklearn 内置的房价数据集,load_boston 是加载数据集的函数
from sklearn.datasets import load_boston
# 使用sklearn 中的 train_test_split 划分数据集
from sklearn.model_selection import train_test_split
# 使用 sklearn 中的直线回归模型进行预测
from sklearn.linear_model import LinearRegression
# 使用 matplotlib 模块中的 pyplot 函数进行数据可视化
import matplotlib.pyplot as plt
设计意图:基于上述设计算法和线性回归的原理,对照讲解sklearn 数据集train_test_split 函数、LinearRegression 直线回归、matplotlib 模块的作用。sklearn 是内置于Pycharm编程环境中的数据集,只需加载数据集即可。
典型问题:如何划分“测试集”和“训练集”?
解决方法:在机器学习中,我们通常将原始数据按照比例分割为“测试集”和“训练集”,train_test_split 函数就是起到划分“测试集”和“训练集”的作用。
2.3.2 步骤二:加载数据集
# 加载房价数据集,返回特征X 和标签y
X, y = load_boston(return_X_y=True)
# 只取第6 列特征RM:住宅平均房间数
X = X[:,5:6]
# 划分为训练集和测试集,测试集取20%
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2, random_state=2020)
设计意图:采用从特殊到一般的科学探究方法,从13个特征中,只取RM 住宅平均房间数这一个特征,找出其与住宅价格的关系,测试集取20%时,观察程序运行后的可视化结果。
典型问题:每次运行得到不同的结果,主要是分割的“测试集”和“训练集”并不相同问题。
解决方法:同样的算法模型在不同的“测试集”和“训练集”上运行的效果并不一样。如果每次sklearn 分割的“测试集”和“训练集”都不相同,那么程序每运行一次,都会得到不同的结果,导致无法调参。此时加上random_state 以后就可以保证程序每次运行都分割一样的“测试集”和“训练集”,便于调参。
2.3.3 步骤三:模型训练和预测
# 创建线性回归对象
regre = LinearRegression()
# 使用训练集训练模型
regre.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = regre.predict(X_test)
设计意图:在理解应用线性回归能预测住宅房价原理的基础上,在程序中可直接调用LinearRegression 直线回归。
2.3.4 步骤四:预测结果可视化
plt.scatter(X_test, y_test, color=’blue’)
# 画线性回归模型对测试数据的拟合曲线
plt.plot(X_test, y_pred, color=’red’)
# 显示绘图结果
plt.show()
# 打印斜率和截距
print(‘斜率k:{}, 截距b:{}’.format(regre.coef_,regre.intercept_))
设计意图:引导学生观察当测试集取20%,输入房间数量为8 时,=·+函数图像,其中斜率:[9.111 633 98],截距:-34.475 577 892 806 62,效果如图6所示。
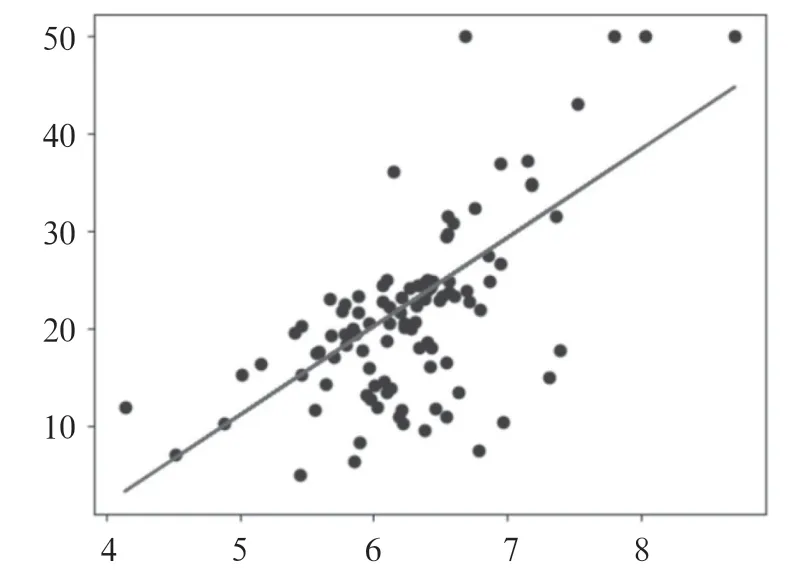
图6 测试集取20%时y=k·x+b 函数图像
设计意图:引导学生观察当测试集取80%,输入房间数量为8 时,=·+函数图像,其中斜率:[12.144 071 32],截距b:-53.322 051 223 109 96,效果如图7所示。
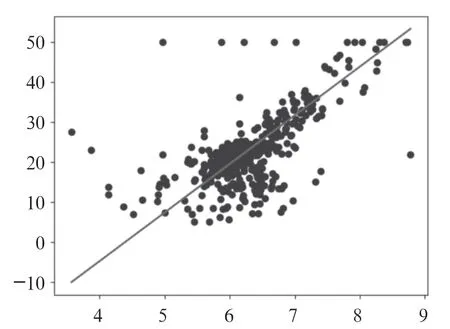
图7 测试集取80%时y=k·x+b 函数图像
典型问题:测试集的取量,会影响=·+函数图像的斜率和截距。
解决方法:其他参数保持不变,只更改测试集取量,观察会出现何种效果,学生提出测试集取量对=·+函数图像的影响。
# 打印斜率和截距
print(‘斜率k:{}, 截距b:{}’.format(regre.coef_,regre.intercept_))
x=int(input(‘请输入住宅平均房间数: ’))
y=regr.coef_*x+regre.intercept_
print(‘预测的住宅价格是:%s’%y)
# 显示绘图结果
plt.show()
设计意图:matplotlib 是Python 的绘图库,掌握应用其画出图形,实现数据可视化的方法。
拓展延伸1:当测试集取量20%,输入住宅平均房间数为8 时,运行程序后显示:预测的住宅价格是:[38.417 493 97],当测试集取量80%,输入住宅平均房间数为8 时,运行程序后显示:预测的住宅价格是:[43.830 519 36],为何会出现不一样的预测结果?
拓展延伸2:只有住宅平均房间数这一个特征与住宅价格的关系,那13 个特征与住宅价格的关系会有什么预测结果呢?
设计意图:测试集的取量、住宅平均房间数都会对住宅价格产生影响,考虑到存在一定的误差,为进一步学习均方误差(MSE),均方根误差(RMSE),平均绝对误差(MAE)的方法来减小误差做铺垫。同时提出从13 个特征中只取住宅平均房间数这一个特征和住宅价格的关系,这是从一般到特殊的科学探究方法,我们从一个特征与住宅价格的关系中找到规律,把它应用到13 个特征与住宅价格的关系的研究中,这就是再从特殊到一般的探究过程。程序完整代码如图8所示。
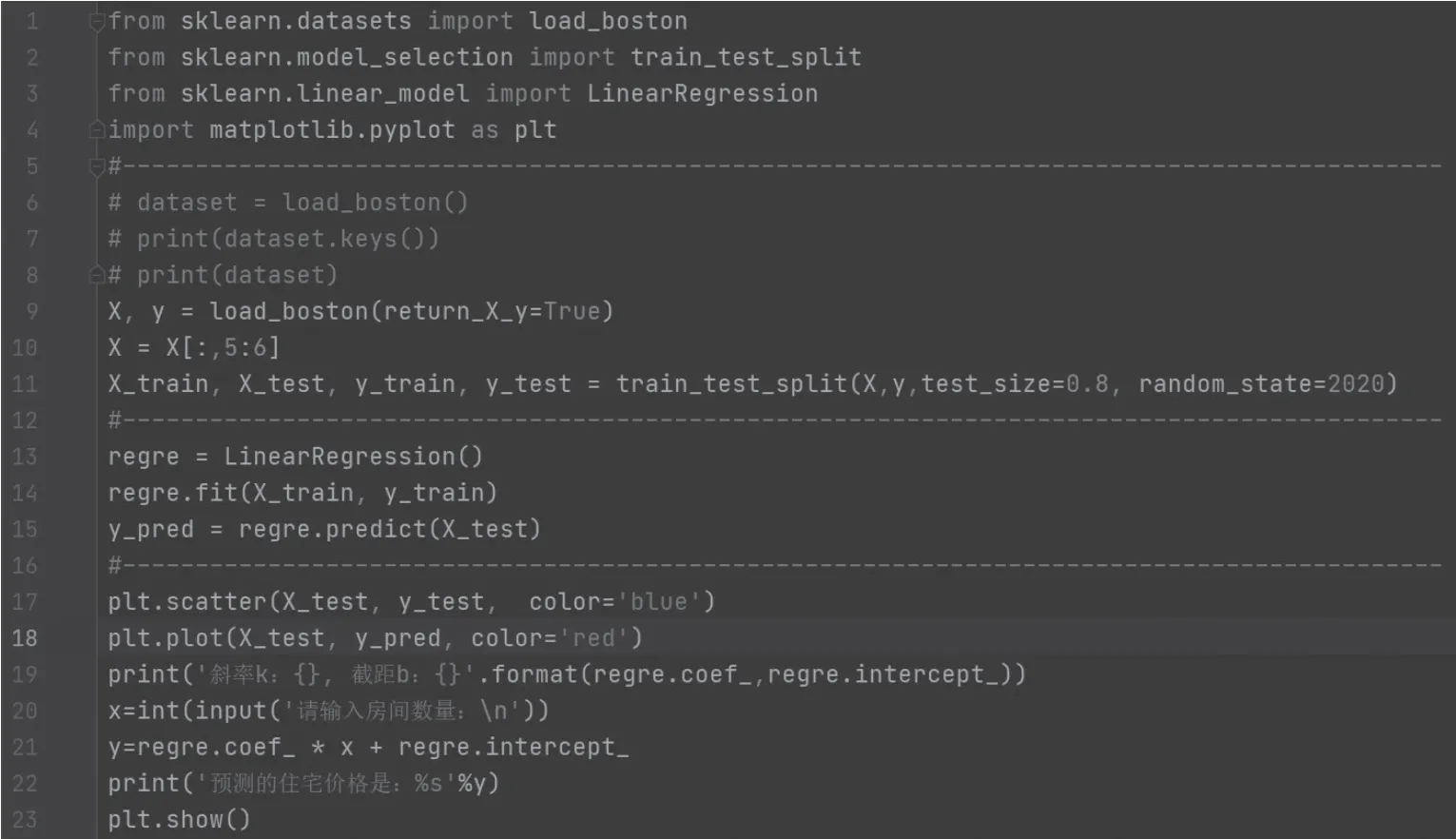
图8 利用线性回归预测某城市房价项目完整代码
2.4 调试运行提升解决问题能力
问题1: 出现提示ModuleNotFoundError: No module named ‘sklearn’错误或者出现提示ModuleNotFoundError:No module named ‘matplotlib’错误
解决方法:出现此问题的原因是没有加载’sklearn’和’matplotlib’库所导致的,以Pycharm 2020.3.3 版本为例,介绍Pycharm 软件加载库或模块的方法:点击左上角的File 后,选择Settings 进入到设置页面,如图9所示。

图9 Pycharm 设置页面
选择Project 下的Python Interpreter,此时右侧能看到已安装的库或模块,如图10 所示。
图10 显示已安装库或模块
在已安装库或模块下方点击“+”号,出现Available Packages页面,输入库或模块名称后,点击下方的Install Package,进行库或模块的安装,如图11 所示。
图11 搜索库或模块页面
问题2:Available Packages页面显示Nothing to show 或搜索sklearn 库时不能出现sklearn 库。
解决方法:点击Manage Repositories,默认有https://pypi.python.org/simple 镜像源,可增加一些国内的镜像源,如清华:https://pypi.tuna.tsinghua.edu.cn/simple、阿里云:https://mirrors.aliyun.com/pypi/simple/、 豆 瓣:https://pypi.douban.com/simple/等镜像源,如图12 所示。
图12 添加国内镜像源
此时再搜索sklearn 库时,因作者添加了4 个镜像源,则可能会出现4 个sklearn 库,选择其中一个安装即可,如图13 所示。

图13 多个源会出现多个sklearn 库
3 结 论
本文分析的线性回归模型是建立在一次函数=·+基础上,一次函数是初中数学的学习内容,应用数学知识与编程算法相结合去探究线性回归经典模型,既可以降低程序理解的难度,又可将教学重心放在线性回归经典模型的教学上,同时为学生提供使用不同学习方式再次深入理解一次函数的机会。学习线性回归经典模型有助于学生理解什么是机器学习,更重要的是走出与智能音箱、智能机器人等智能设备对话就理解为人工智能的全部这种误区。
教师围绕计算机解决问题的一般过程:分析问题、设计算法、编写程序、调试运行这种逐层递进方式开展教学,结合线性回归经典模型的逻辑步骤,即“导入相关的工具包、加载数据集、模型训练和预测、预测结果可视化”四个步骤,教学设计符合皮亚杰的认知发展理论和维果茨基的最近发展区理论,适应学生的认知发展水平、学生的学习是主动建构知识的过程,提升了学生计算思维等高阶能力的培养。本次人工智能编程教学实践仍处于初步尝试阶段,有部分内容需要在后续教学实践中不断探索、完善。
