基于联邦学习的风险管理研究进展
2022-08-27戴雨璇张永杰
戴雨璇,张永杰,熊 熊,冯 绪,张 维
(天津大学管理与经济学部,天津 300072)
Facebook泄露5.33亿用户数据的事件引起了一时轰动。2021年4月,据Appleinsider称,Facebook官方正式作出了回应,称其数据泄露并非黑客入侵系统所致,而是2019年Facebook同步联系人工具中的漏洞被恶意破坏者利用所造成的。在人工智能时代背景下,人们的关注点逐渐由数据转向数据隐私与数据安全,随着人工智能应用的智能化程度不断提高,数据隐私风险程度会越高,但数据安全问题仍存在诸多漏洞,比如计算机的开放性特点使得存储在计算机中的信息遭到泄漏,亦或是人为操作不当、计算机软件和硬件设施陈旧都会增加数据泄漏的风险。在国家提出“互联网+”“大数据+”的计划后,人们对于数据价值的重视度也随之提高,但人们对于数据隐私范围以及特征的界定没有明确的标准。由于数字经济出现的时间较短,对于数据隐私保护与数据安全的解决办法仍在探索之中,在面对这种不确定的情况时,人们的态度也会愈加保守[1]。欧美国家是较早进行数据隐私保护方面探索的,最早的研究框架是“知情—同意”机制,而这一机制在如今的大数据时代和人工智能背景下,受到了严峻冲击与挑战[2]。2016年,谷歌首次提出了联邦学习的概念,联邦学习被用于更新Gboard系统。在我国,微众银行的AI团队开源了第一个工业级的联邦学习框架FATE[3],用以解决数据泄露、数据孤岛等问题。
在联邦学习的发展过程中,联邦学习与区块链的结合取得了有效的研究进展。将区块链应用到联邦学习中,能够同时存储训练的最终模型和在训练过程中产生的迭代模型。Unal等提出了整合区块链与联邦学习的方案,引入区块链的联邦学习算法能够有效减少外部攻击,提升了联邦学习的隐私保护能力[4]。基于区块链的联邦学习的训练模型能够得到更高的市场定价,模型产生的价值能够为联邦学习用户(参与方)带来经济效益,从而吸引更多的用户提供更高质量的数据参与到联邦学习训练中,得到高质量聚合模型,这也将成为联邦学习激励机制建立的基础。
联邦学习在医疗领域中也得到了很好的应用,医疗数据通过联邦学习在不共享的前提下进行模型的联合训练,从而有效克服医疗数据不能共享的难题,提升医疗机构的服务效率。Price等根据相关法律法规对患者隐私泄露问题进行了剖析,并提出了相应的解决方案[5]。近两年在医学领域,如Sheller等[6]以及Kaissis等[7]通过应用验证证明了联邦学习的有效性,也为联邦学习的实践应用奠定了基础。
一、联邦学习的提出与研究进展
1.联邦学习的概念
联邦学习的概念最早由谷歌提出,是一种新兴的机器学习范式,是机器学习联邦优化的一种特殊形式。将分布于多方设备的数据集,在确保隐私的情况下进行联合建模,是一种跨多个设备训练神经网络的方法,以安全收敛和差分隐私相结合的方式来保证隐私安全。联邦学习的目的是根据参与方收集的特征,协作地建立一个共享机器学习模型[8]。现有的入侵监测模型是基于传统的机器学习算法进行展开的,很难不涉及用户的隐私,联邦学习的出现减少了传统的中心化机器学习方法带来的风险。传统的机器学习多采用集中式的方法进行模型训练,这就要求训练数据集需集中于同一服务器上。在联邦学习的框架下,每个工作节点都是自身数据的唯一所有者和模型的培训参与者,各参与方可以共享梯度信息与模型参数,不同设备的计算资源在中央服务器的协调下合作训练模型,训练数据保存在本地设备中,不与中央服务器共享,能够提供更好的数据隐私保护。根据现有研究,构建了联邦学习的标准训练框架(见图1)。
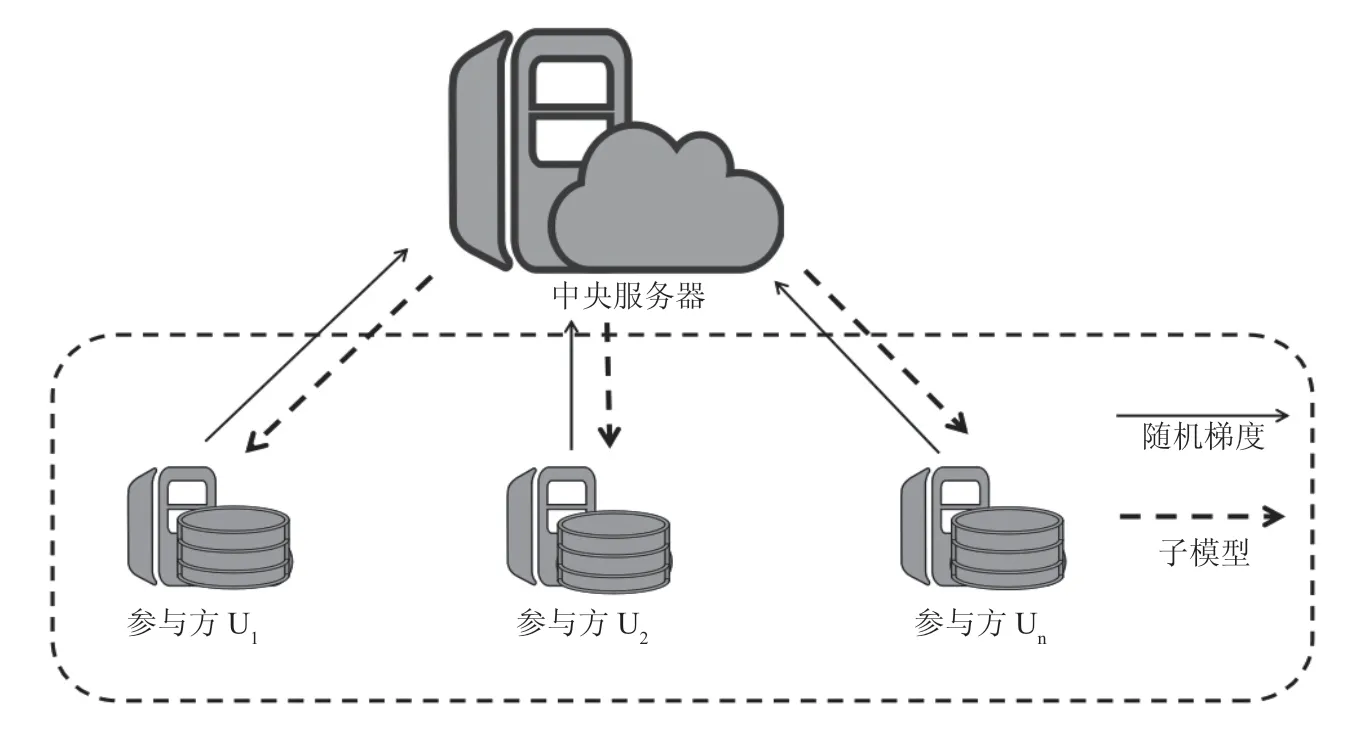
图1 联邦学习标准训练框架
联邦学习与分布式机器学习有一定的相似之处,它是加密的分布式机器学习。在物理组成上,联邦学习系统与分布式系统都是由中心服务器与多个分布式节点构成的[9]。顾龙浩等在研究中指出,联邦学习与传统的分布式机器学习的区别在于是否需要共享原始数据,联邦学习是在不共享数据的前提下进行的,只共享训练结果[10];在分布式机器学习的框架下,数据需要在多个计算元素之间进行共享,因此分布式机器学习不适用于数据隐私保护。在联邦学习中,共享预测模型可以通过多个分布式节点使用其本地存储的数据协作学习,各参与方在最终模型中有所收获的同时,其隐私数据也得到了有效保护。Chandiramani等通过在Fashion-MNIST数据集上建模的形式,对分布式机器学习和联邦学习进行比较,模型训练结果表明,联邦学习训练比分布式机器学习训练多消耗2秒时长,这是由于联邦学习需要将平均值应用于迭代过程中的两个局部模型的额外步骤[11]。
2.联邦学习的架构
在联邦学习的应用与训练过程中,不是所有情况都需要中央服务器作为协调方进行的。鉴于这种情况,联邦学习架构被分为客户—服务器架构,也可视为中心化的联邦架构(见图2);以及对等网络架构,也可视为去中心化的联邦架构(见图3)[8]6。
客户—服务器架构是指参数服务器将初始模型发送至用户U1~U3,用户U1~U3利用各自的数据训练该初始模型,训练后将更新的模型权重(参数)发送到参数服务器。参数服务器将每个用户发送回的模型更新进行聚合,聚合后的模型再次被更新,并再发送给用户,上述步骤会持续迭代到最大次数或训练时长达到最久,直至模型收敛。
对等网络架构是指在没有参数服务器的协调下进行。在此架构下,参与到联邦训练中的用户之间不依靠参数服务器的协调可以直接通信,训练过程更加安全,但是解密与加密步骤也随之增多。
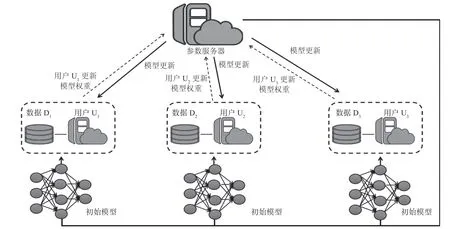
图2 客户—服务器架构

图3 对等网络架构
3.联邦学习的场景
联邦学习在数据上共分为3类,分别是根据样本划分的联邦学习称为横向联邦学习,根据特征划分的联邦学习为纵向联邦学习,如果样本与特征重叠部分较小或均不重叠时使用联邦迁移学习。
横向联邦学习(horizontal federated learning,HFL)一般是指按照样本划分的,也可定义为按照用户维度(横向)划分的联邦学习,还可称之为“特征对齐的联邦学习”[12]。用横向联邦学习训练模型能够增加用户样本数量,同时还能够提高模型准确性。2016年,谷歌发布了一种为安卓系统手机提供模型更新的解决方案——谷歌输入法Gboard,该方案是基于横向联邦学习提出的[13]。在横向联邦学习的框架下,各参与方能够共享梯度信息与模型的参数,各参与方计算局部梯度后上传至服务器,共同维护梯度更新。Wang等在横向联邦机器学习的背景下,通过横向联邦学习的删除法,公平地衡量整体数据质量,以此来实现公平的信用分配[14]。举例来说,A和B是两家不同地区的银行,两家银行房贷产品的用户特征重叠较多,而用户重叠较少,A银行与B银行通过横向联邦学习进行合作建模,既增加了模型训练的样本量,又能够提升模型的质量。
纵向联邦学习(vertical federated learning,VFL)一般是指数据集上各参与方利用样本空间相同、特征空间不同构成的联邦学习,也可称之为样本对齐的联邦学习[12]。在纵向联邦学习的框架下,各参与方的不同特征被聚合在同一加密状态下,以此来增强模型能力。基于纵向联邦学习系统的模型包括逻辑回归模型、神经网络模型、树形模型等多种机器学习模型。Wang等在纵向联邦学习的背景下,通过纵向联邦学习的Shapley值,计算多方在联邦学习中的贡献,以此实现公平的信用分配[14]。举例来说,A是某地的银行,C是同一城市的保险公司,A与C的用户重叠较多,用户特征重叠较少,银行A与保险公司C可以通过纵向联邦学习进行合作建模,从而提升模型质量。
联邦迁移学习(federated transfer learning,FTL)是指在用户或特征不对齐的情况下,在数据间通过交换加密参数达到知识迁移的效果[15]。它采用有限的公共样本集,根据学习到的两个特征空间表示获取只有单侧特征的样本预测[16]。迁移学习的本质是发掘出资源丰富的源域同资源稀缺的目标域之间的相似性,通过这一相似性在这两个领域之间进行知识的传输。目前学术界对于联邦迁移学习的研究内容较少,更多关注于横向联邦学习和纵向联邦学习。举例来说,A是位于中国的银行,D是位于国外的一家保险公司,由于地域和行业的不同,A与D的用户和用户特征均重叠较少,为了实现有效的联邦学习,需引入迁移学习解决单侧数据规模小、标签样本少的问题,以此提升模型质量。
4.联邦学习的隐私保护技术
根据陈琨等[17]、田家会等[18]、李凌霄等[19]诸多学者的研究发现,常见的联邦学习的隐私保护技术有3种,分别是同态加密、安全多方计算和差分隐私。
同态加密的概念最早在1978年由Rivest通过“隐私同态”的概念提出来[20]。Sander等在研究中首次提出了同态加密算法,并定义了整数域内的加法与乘法的同态加密机制[21]。加密算法能够隔着加密层进行运算,对多项式进行加密,分解成每项加密的多项式。同态加密算法能够允许人们对于加密的数据进行特定运算,该运算结果与不加密状态下进行的运算结果一致[22]。仝秦玮等在研究中设计了一种基于DGHV适应智能合约的同态加密方法,该方法能够直接对密文进行计算,起到保护交易双方隐私安全的作用[23]。Fang等在同态加密和秘密共享的基础上,提出了一项新颖的隐私保护协议,用来保护个人客户的隐私[24]。在以往的研究中[25-26],有一些基于同态加密技术的隐私保护解决方案被用于训练机器学习模型,如神经网络、决策树等。
安全多方计算起源于“百万富翁的问题”,学者姚期智于1982年提出该问题并进行了推广。安全多方计算是指各参与方不透露或传输原数据,各自在加密状态下进行分散计算再融合协作得到联合计算结果,以此达到数据可用不可见的目的。安全多方计算的目的是协同地在参与方各自的隐私输入中计算函数的结果,不必将这些输入展示给其他参与方[8]22。该方法是解决模型在联邦学习中进行训练时客户端的私有数据被泄露或被反向推断出的有效方法。
Dwork等在研究中首次提出了利用差分隐私来解决各种隐私攻击方式以及现代隐私保护机制中的一些缺陷问题[27]。相比于传统的隐私保护方法,差分隐私法是一种流行的隐私保护机器学习方法,是解决客户端私有数据被泄露的另一种有效方法,它定义了一个严格的攻击模型,对于隐私泄露的风险也给出一个固定隐私损失预算。实现差分隐私主要有两类方法,一类是给数据加上噪声来实现差分隐私,另一类是指数机制[8]31。Liu等基于差分隐私法提出了一种自适应隐私保护联邦学习框架APFL,通过向数据注入自适应噪声来平衡模型的准确性和安全性[28]。有不少学者针对基于区块链的联邦学习框架进行了研究,这类研究多采用噪声添加机制的差分隐私方法[29]。
5.联邦学习在金融领域中的研究
为了响应我国数字金融的政策,各行各业积极开展数字化转型工作。在万物互联的时代,数字化转型也是必然趋势。机构、组织、企业等通过人工智能AI、大数据、云计算等一系列新技术实现生产效率与资源利用率的提升,从而推动了数字金融的快速发展。互联网数据的更新迭代速度在不断加快的同时,互联网风险也随之加大,为防止隐私数据的泄露,数据间的不互通成为常态,这对数字金融的发展产生了阻碍。2020年11月17日,由中国互联网金融协会金融科技发展与研究专业委员会组织撰写的《金融业数据要素融合应用研究》(以下简称《报告》)正式发布。《报告》中指出了数据在数字化浪潮中的重要地位,金融业作为数据密集型的行业,要平衡好数据要素融合应用与数据安全保护。《报告》中将联邦学习作为金融业数据要素融合应用的支撑技术进行了着重介绍,并探索了如何依托联邦学习等相关隐私保护技术实现数据要素融合应用与数据安全保护之间的平衡关系。2019年,微众银行开发的全球首个工业级联邦学习框架FATE,旨在提供一个安全的计算框架来支持联邦AI生态系统,并开始尝试将联邦学习应用于金融业务中。同时,腾讯云与微众银行联合宣布成立金融科技创新实验室,正式立项微众银行与腾讯云神盾沙箱的联邦学习联合研究项目。2020年,江苏银行作为首家与腾讯安全合作的金融机构,联合共建智能化信用卡管理联合实验室,实现联合信贷风控建模。
目前,联邦学习在我国银行业和保险业中都得到了一定的应用,如百度金融安全计算平台中的车险和健康交叉险业务、腾讯安全的保险广告投放RTA、微众银行的联邦信贷风控等,但在银行业中开展的工作更多[17]。联邦学习应用于银行业,主要针对信贷风控领域,如信用卡反欺诈、信贷、反洗钱等业务[12,17]。各银行在销售理财产品时,通过纵向联邦学习与其他金融机构、借贷平台进行联合建模,对客户的风险偏好有更精准的判断,从而调整产品结构吸引更多客户购买[30]。将联邦学习应用于信用卡业务中,能够提高对客户的风险识别效率,从而降低人工成本[31]。联邦学习目前在我国银行业中的应用仍处于初步发展阶段,在计算成本、技术的成熟性、相关法律法规的监管等多个方面还存在一定缺陷,联邦学习在金融行业中的应用还需不断进行探索。
二、基于联邦学习的小微企业风险评估
根据OECD数据得知,2018年在我国企业贷款的总数中,中小企业的贷款占比为64.96%,在发展中国家占据领先优势,并超过了多数发达经济体[32]。在信贷风控领域,金融机构面对小微企业的贷款需求时,由于数据源不足,无法有效反应企业经营状况,导致我国小微企业面临的现状是融资难、融资贵的问题。我国小微企业获贷难的原因有以下几点:第一,企业规模较小,管理制度不集中;第二,其内部管理制度体系不健全,缺乏一定的财务数据与经营数据;第三,多数小微企业都不能提供经由第三方机构出具的有效的审计报告,部分小微企业还存在数据造假的情况;第四,尤其是国有银行、全国股份制银行的信贷市场更加关注实力强的企业,往往忽略了发展较弱的小微企业;第五,银行对企业进行放贷后,不再核实这些原因都会对小微企业的公信力产生严重的负面影响。
大数据时代的到来,为信用风险的评估带来了新的契机,为化解小微企业融资难的问题提供了机遇。在消费金融机构中,传统的信贷模型数据量小,数据维度低,缺乏有效的数据对用户还款能力和意愿进行评估,可能会导致客户资质参差不齐。从海量的大数据信息中挖掘出具有风险评估能力的指标,建立具有公信力而稳定的信用风险评估模型,为授信审批提供客观的量化标准。
在过去几十年的发展过程中,针对小微企业的信用风险评估研究已经取得了一系列重要的理论与实践突破。在数据方面,现有研究已从单一来源数据转向同一主体控制下的多源数据;在信用评估方法方面,机器学习方法已占据主流地位,已有学者开始基于多种方法融合的形式对小微企业进行信用风险评估。学者们通过联邦学习的方法,可以合规合法地利用多源数据,在保证数据隐私安全的同时,多角度刻画用户资质。李铭雨等在研究中指出,目前银行在向小微企业借贷过程中面临着两个问题:第一,信贷风险的量化评估;第二,信贷决策方案的制定[33]。针对信贷风控问题,Yang等利用联邦学习构建了信用卡欺诈风险检测系统,发现消费金融机构的样本存在数据倾斜问题,本文通过SMOTE算法解决了数据不平衡问题[34]。Zheng等提出了垂直联邦学习方法FL-LRBC,使多个机构能够在单个培训课程中联合培训优化的信用评估记分卡模型[31]。李健萌解决了数据隐私问题和信贷大数据的异构特点问题,尝试构建了适合信贷风控场景的联邦学习系统[35]。联邦学习的出现为小微企业充分发挥其数据价值提供了新的技术,既能够解决有效数据确实造成的征信白户问题,又能解决小微企业融资难的问题,风控水平也同时得以提升[36]。
三、联邦学习在应用中面临的问题
1.安全问题
联邦学习在应用过程中,安全方面仍然存在一定的缺陷,联邦学习中的数据存在一定的风险。模型每一轮更新后的信息都会发送至中央服务器,在此过程中,攻击者能够通过与模型的交互对更新信息的敏感部分经过逆向推理获取参与方的私有数据。如Hitaj等在研究中生成的对抗网络在共享梯度中推断出参与方的本地数据[37]。当恶意的参与方加入到联邦训练过程中时,利用中央服务器中的共享参数推理得出其他参与方的数据,最终达到窃取数据的目的[38]。这就说明,仅依靠模型更新保护参与方的数据隐私是不够的。除此之外,联邦学习还可能会存在间接泄露隐私的风险[24]。因此Dong等在研究中设计了三元联邦学习防止隐私泄露问题[39]。
在大数据的驱动下,联邦学习在人工智能系统应用中将发挥更大价值,扮演更重要的角色。首要解决的问题是设计安全的加密协议,以抵御更多的外部攻击。
2.性能优化与通信效率
联邦学习在性能优化方面具有一定的挑战性。由于各参与方的本地数据资源缺乏透明度,使其容易受到对抗性联合攻击。中央服务器在整合多方数据进行协作训练时,难以建立一项有效机制筛选出恶意参数的更新,由于参与训练的数据都是不可访问的,因此难以辨别出经过良好操作的模型源于良性模型[40]。由于联邦学习框架集中于中央服务器,如果单个节点发生故障时,整个模型的安全就会受到挑战。联邦学习的模型训练过程较为复杂,模型的可解释能力就会较差,这对模型的可靠性会产生威胁。
解决通信问题也是目前联邦学习在性能优化方面的重要环节。网络带宽的限制与先进的隐私攻击,使联邦学习的传输效率降低,进而会影响其训练速度,在全局模型更新过程中会消耗大量的通信资源[41],造成联邦学习在通信和隐私方面存在缺陷。这些问题直接导致的结果是不能将所有数据都收集到中央服务器中[42]。针对上述情况,Li等提出了预留带宽的方案以提高训练效率[43]。Konečny等[44]、Sattler等[45]针对联邦学习中的本地模型更新引起大量通信开销的问题,他们在研究中试图通过数据压缩的方法解决这一挑战。Wu等[42,46]设计了新的框架ACFL、FedMed等解决资源有限和通信成本的问题。也有学者针对联邦学习中同步梯度的高网络通信成本问题,提出了量化梯度方法,利用联邦学习寻求高效率通信方法,最小化通信成本,解决高通信开销问题。
3.联邦学习激励机制的探索
如何建立激励机制使得参与方持续参与到数据联邦中是一项重要的挑战。由于缺少高效的激励机制吸引更多的客户端参与到训练过程中,训练数据的不足最终导致模型质量难以保证。为此,有学者设计了激励机制确定了边缘节点的最优训练策略[47]。引入联邦学习激励机制,参与方能够根据各自在聚合中的不同贡献得到不同的奖励,这种奖励可以是资金奖励或是最终模型的奖励[18]。
模型的训练结果离不开前置输入的数据,通过建立联邦生态系统,设计联邦学习激励机制吸引更多用户参与到联邦学习生态系统,最大化联邦学习系统下协调方与供给方各自的贡献、最小化双方代价,从而保证参与方能够贡献更高质量的数据,公平、安全地分享利润,达到联邦学习训练效果的最优化。同时,激励机制不仅鼓励参与者加入,也鼓励设备提供方积极加入,鼓励设备提供方提供更多的通信带宽,有效解决通信效率低的问题。
4.发挥在小微企业中的价值
当前,针对小微企业信贷融资服务和信贷监测考核等多个方面的金融服务存在明显不足和提升空间,在数字化转型的大趋势下,如何充分利用金融大数据资源,评估小微企业信用风险,是提升小微企业信贷服务决策水平的关键性环节。使用联邦学习的框架构建可解释的小微企业信用风险评估模型成为了有效的解决办法。应充分考虑联邦学习在确保隐私安全的情况下多主体所有权数据同时建模的约束,发展使用多主体所有权数据构建小微企业信用风险特征的分布式方法,并对相应的模型进行可解释性研究。在多主体所有权数据隐私保护与安全共享的背景下,小微企业的多主体所有权数据的样本重合度低,样本特征不同,不能在同一数据节点上进行计算,如何构建小微企业信用风险特征的分布式度量,是未来研究工作的关键问题。
利用拥有高价值密度的多主体所有权数据构建小微企业信用评估模型,提升小微企业的信用风险评估精度,降低小微企业信贷违约率,并借助数字科技,搭建小微企业信用评估的应用平台。基于互联网供应链构建小微企业信用评估的应用平台,通过该平台上各小微企业留下的信息形成大数据,为融资服务需求奠定基础[32]。
四、结 语
人们对隐私安全问题的日益关注是联邦学习出现的主要原因,联邦学习的出现,有效解决了具有异质数据分布在大量客户端的分散数据上开发AI服务的挑战,它成为了解决当前人工智能面临的数据孤岛、数据隐私安全不稳定等困难的解决方案。但就目前情况而言,联邦学习面临着隐私保护技术的不成熟、联邦学习的参与方公平与效率得不到满足、计算成本高等亟待解决的问题。在未来,联邦学习还会被应用到万物互联的各种场景中,将联邦学习与新技术进行融合应用,如自然语言处理技术、边缘计算技术,实现数据隐私保护的同时训练模型的质量也得以提升。设计联邦学习激励机制吸引更多用户参与到联邦训练中,通过用户提供更高质量的数据获取更高质量的模型,营造联邦生态系统的良好环境,为隐私安全保驾护航。
