基于循环Faster R-CNN的衬衫领型精确识别
2022-08-27张怡,侯珏,2,刘正,2,3
张 怡 ,侯 珏,2,刘 正,2,3
(1.浙江理工大学 服装学院,浙江 杭州 310018;2.浙江省服装工程技术研究中心,浙江 杭州 310018;3.服装数字化技术浙江省工程实验室,浙江 杭州 310018)
0 引 言
近年来,服装款式造型设计趋向多样化、个性化,对于经营者而言,服装产品的展示显得尤为重要。但是,目前大多数电商平台对于服装的细节要素展示并未做详细分类,导致消费者在检索某个类别的服装时,会涌现出大量信息而无法进行细致的筛选,难以找到心仪的款式[1-2]。服装细节要素特征通常存在于特定的部件区域处[3],如衣服的领部、袖口、门襟等部件,由于一件服装包含多个部件且整张服装图像中部件的占比面积较小,需要搭建同时实现部件定位与分类的算法。
相较于传统识别方法,深度学习[4]具有自动特征提取、识别效率和精度高的特点[5],现有的深度学习目标检测算法大致分为2类:一阶段检测算法,典型代表是YOLO[6]、SSD[7]及其衍生模型[8];二阶段检测算法,典型代表是R-CNN系列[9-11]。相较于一阶段方法,二阶段方法对图像质量要求低,但检测精度高且对小目标的检测效果较好[12]。目前已有学者将深度学习应用于服装属性识别,XIANG等采用改进RCNN框架的方法来识别衬衫的领、袖等属性[13];刘正东等提出基于尺寸分割和单次多盒检测(SSD)的西装领增强检测算法[14];尹光灿等通过人工截取领型区域并微调AlexNet卷积神经网络模型的超参数,实现服装领型的识别[15];张艳清等通过扩大衣领的框选范围,探讨数据集标注对Faster R-CNN识别连衣裙衣领的影响[16];SUN等提出了一种基于Faster R-CNN和多任务学习的服装属性识别方法[17]。上述研究对提高服装属性的识别率作出了一定贡献,但未特别关注小目标部件细节特征的识别,且未考虑收集到的各类别样本数量不均衡的问题。外观细节特征的差异所带来的视觉感受不同,对服装风格的塑造也有一定的影响,为了获得服装部件的细节特征信息,需要对图像进行多尺度识别,现有模型如GoogleNet[18]、SSD[7]、FPN[19]等均采用多尺度技术来提高识别效果,但该技术会增加网络负担,降低模型效率。
本文以衬衫领部为研究对象,根据领部的细节构成要素对基础领型进一步划分,提出了一种循环结构的Faster R-CNN网络模型,实现衬衫领部细节特征的识别分类。针对类别间样本数量不均衡问题,采用权重惩罚方法有效提高了模型的检测精度。衬衫领部的精确细分有利于缩小检索范围,能够更好地满足消费者的需求,并且可根据消费者的喜好提高服装设计和生产的针对性。
1 领部细节要素识别方法
1.1 Faster R-CNN
REN等提出了Faster R-CNN[11],该网络由主干特征提取网络、区域建议网络(RPN)、回归分类网络3部分组成,采用卷积神经网络生成候选框[20],减少了内存消耗,大幅度提升了检测精度与速度[21]。
1.2 循环Faster R-CNN
本文提出了一种以Faster R-CNN为基础的具有环路的网络结构,循环利用网络组件对图像进行二级细节特征的识别,将其命名为“循环Faster R-CNN”,网络结构如图1所示,其中包含一级识别和二级识别2部分。
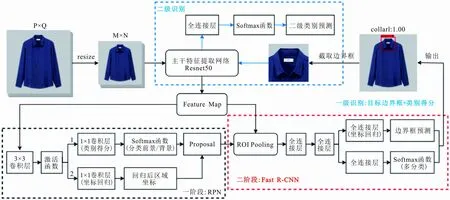
图 1 循环Faster R-CNN网络结构Fig.1 Recurrent Faster R-CNN network structure
图1中,一阶段RPN结构如图1左下方黑色虚线框内所示,其包含2个分支:分支1把特征图分割成多个小区域,识别出前景与背景区域;分支2用于获取前景区域的大致坐标。在此基础上通过区域建议层Proposal筛选掉偏移量过大及相互重叠的候选框,此时获得建议框,利用建议框在特征图上截取,得到的不同特征层反映原图中的不同位置,截取到的内容传入二阶段Fast R-CNN中,如图1右下方红色虚线框内所示,ROI Pooling层将截取到的不同大小的特征层区域转化为固定尺寸,通过全连接层映射到一个特征向量,利用回归分类网络判断截取到的图片中是否包含目标,并对建议框进一步调整,最终获得更精确的目标识别框和分类结果。
二级识别是在一级识别的基础上对领部的细节特征进行识别,为了在不增加网络负担的同时提高细节特征的识别效果,将一级识别网络识别的领部边界框截取,再次喂入主干网络Resnet50,提取并学习领部的细节特征,最后连接全连接层,实现衬衫领部的二级识别,如图1正上方蓝色虚线框内所示。
采用Faster R-CNN作为一级识别网络,其中主干特征提取网络选择文献[22]中的Resnet50层结构。Resnet50层结构中,每个残差结构包含 3个卷积层,该网络一共包含1+3×(3+4+6+3)=49个卷积层和1个全连接层,作为主干特征提取网络时去除其中的全连接层,只留下卷积层,输出下采样后的特征图。获得的特征图有2个应用,一个输入到RPN中,另一个是和ROI Pooling结合使用。
本文可视化了Resnet50在训练领部图像过程中的特征图,输入的原始图像见图2(a),由于只有卷积层包含训练参数,图2(b)~(f)展示了Resnet50不同层学到的前12张特征图。

(a) 输入的原始图像

(b) conv1

(c) conv2_x
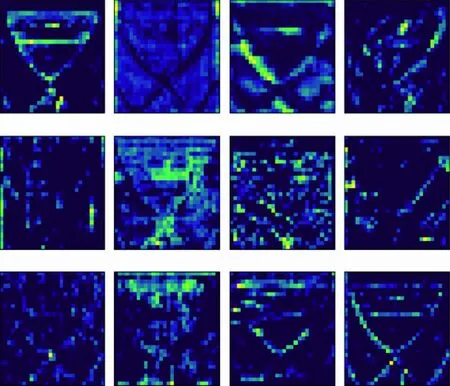
(d) conv3_x
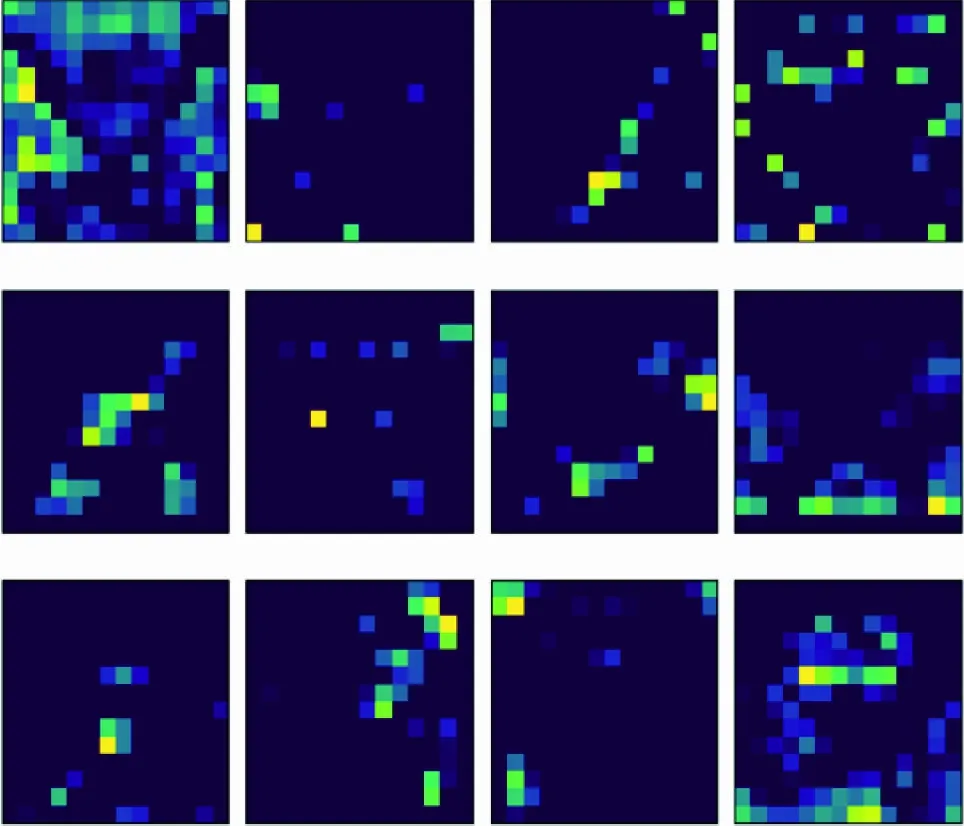
(e) conv4_x
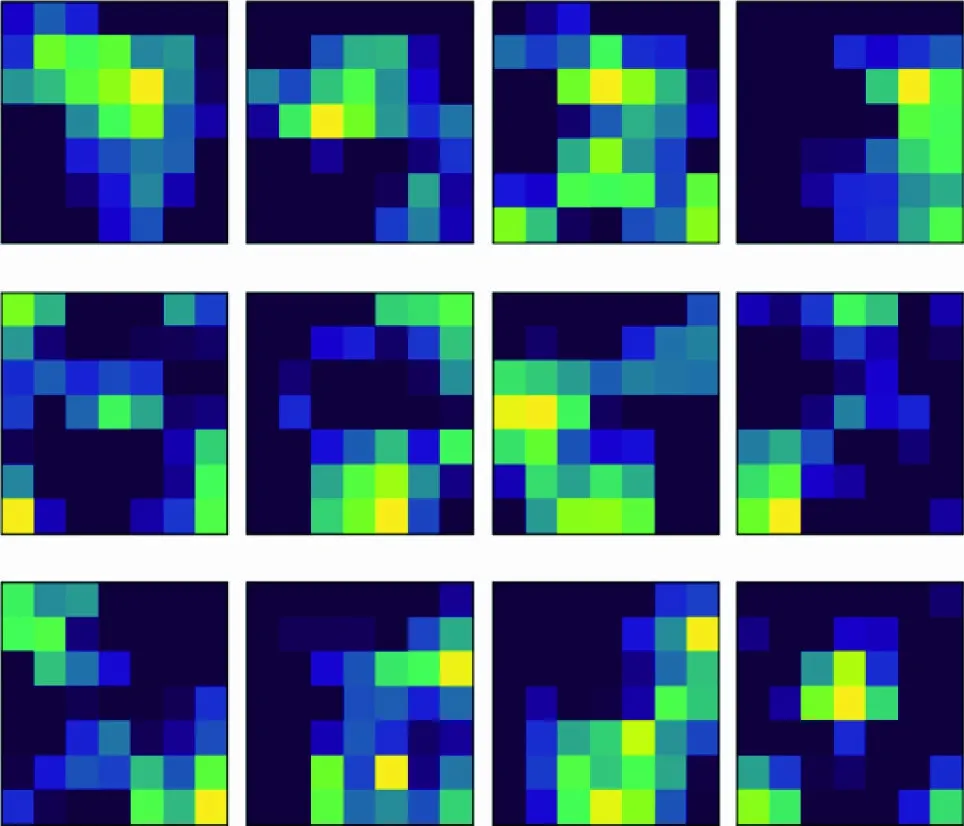
(f) conv5_x图 2 Resnet50不同层输出的特征图Fig.2 Feature maps output from different layers of the Resnet50
图2中,浅层的卷积层主要学习图像的纹理和角点信息,随着网络的加深,学到的信息越来越复杂和抽象化,结果显示网络中的卷积核均可提取到有效特征信息。
1.3 损失函数
Faster R-CNN网络的损失函数包含分类损失和回归损失2部分,表示为
(1)
式(1)等号右侧前半部分为分类损失,后半部分为回归损失。分类过程采用交叉熵损失函数,可表示为
(2)
回归采用smoothL1函数,可表示为
(3)
(4)
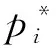
本文所提出模型的一级识别损失函数同式(1)。由于二级识别任务是对领部区域进行更细致的类别划分,因此,损失函数只包含分类损失,计算公式同式(2)。
2 数据集构建
2.1 数据采集与预处理
从天猫、唯品会等电商平台搜集1 375张平面摆放的衬衫图像作为样本集,裁剪去除图像中杂物、文字说明等信息,图3所示为样本集中各类衬衫领型示例。

图 3 各类衬衫领型示例Fig.3 Examples of various shirt collar types
为提高模型的鲁棒性与抗干扰性,对裁剪好的图片进行批量旋转,旋转角度依次为顺时针 0°、90°、180°、270°,将原本1 375张衬衫图像扩充为原来的4倍,即5 500张图像。运用数据集标注工具 LabelImg以领部为边界对样本图像进行准确标注,形成包含图像名称、尺寸、读取路径、标记框标签和坐标的标注文件,用于模型训练过程中读取数据。
2.2 衬衫领型分类
衣领按照领线和领子的组合方式,可分为有领和无领2类[23]。有领是指在领线上装有各种不同形式的领子,无领是指只有领线而无领子的领型。一级类别为常见的衬衫领型,其中有领领型包含翻立领、翻领、立领、飘带领,无领领型包含圆领、V领、方领,采用标签collar1~collar7表示各一级类别。
由于同一领型可以采用不同的结构形式进行装配制作,所呈现出的外观细节特征不同,在视觉感观上也有所差别,将一级类别中包含的领型按照其组成结构以及装配元素进行分析归纳,从而形成更精细化的二级类别,采用标签craft1~craft13表示各二级类别,具体的划分方式如下:翻立领是由领座和领面2部分经工艺装配相接而成,结构相对固定单一,标签为craft1,样本数量为1 200;翻领可分为连翻领和平翻领,连翻领的领座和领面是一体的,领子缝制于衣身上自然翻折形成领座和领面2部分,标签为craft2,样本数量为360,而平翻领只有领面而无领座支撑,领子平摊在衣身上标签为craft3,样本数量为360;立领类别的划分中,常规立领是只含有领座结构的领型,标签为craft4,样本数量为440,带花边立领是在领座的基础上添加花边装饰元素,标签为craft5,样本数量为360;飘带领是由立领延伸形成的带有飘带装饰的领子,标签为craft6,样本数量为400;圆领类别中,常规圆领是指领口形状为圆形且不含其他元素的基础领型,标签为craft7,样本数量为360,带花边圆领是在常规圆领的基础上增加了花边装饰元素,标签为craft8,样本数量为320;抽褶圆领是指领口形状为圆形且含有褶皱元素的领型,标签为craft9,样本数量为320;V领和方领的分类方式类似圆领,分为常规V领、带花边V领、常规方领、带花边方领,标签分别为craft10、craft11、craft12、craft13,样本数量分别为320、360、340、360。同属于一个一级类别下的二级子类别间领型差异较小,需要提取领部的细节特征进行识别分类。
2.3 类别间样本不均衡问题
对所收集到的数据集分析显示,在众多衬衫领型当中,翻立领样本占比最高,比例约为21.82%,其他类别的样本数量相对较少。各类别图像数量不一致将造成模型的识别精度降低,为解决类别间样本不均衡问题,通常采用的解决方法有数据扩充和权重惩罚。前者采用图像变换和添加扰动的方法扩充数量少的类别样本,需要增加样本处理的时间;后者对损失函数进行权重赋值,使得样本数量少的类别获得更大的损失权重,模型在迭代更新的过程中能够专注于减少少数类的误差。
本文采用权重惩罚法,设定了3组类权重。类权重1分别赋予各类别与其各自样本量成反比的类权重,使得类权重达到平衡状态[24],表达式为
wj=Nt/(M×Nj)
(5)
式中:j表示类;wj为每个类的权重;M为类别总数;Nj为每个类的样本数量;Nt为样本总数。
类权重2和3只针对性地降低最多类的权重,使模型关注于其他类别的检测,迭代过程中的参数主要根据其他类别的损失进行优化。类权重2中最多类的权重根据collar2~collar7样本平均数与collar1样本数之比得到;类权重3中最多类的权重根据collar4和collar6样本平均数与collar1样本数之比得到。各类别对应的类权重如表1所示。
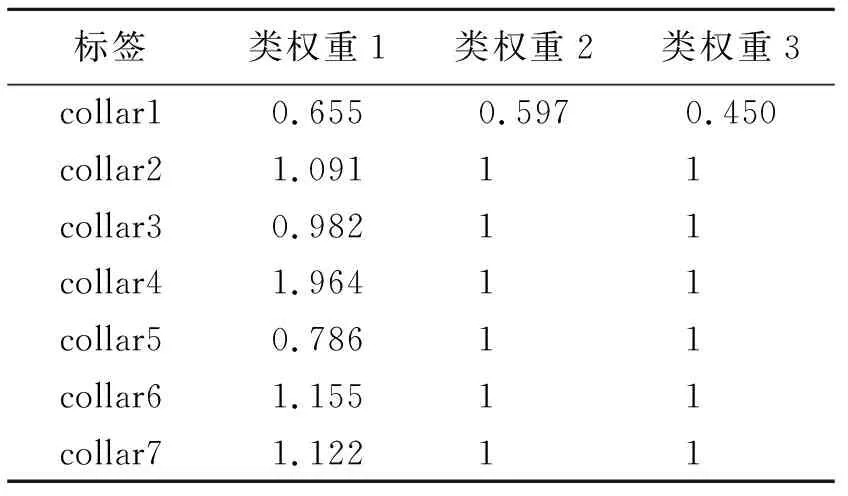
表1 类权重设定Tab.1 Class weight setting
3 实验过程与结果分析
3.1 训练参数
本文网络模型的搭建和训练均通过Python3.7软件和Pytorch框架实现,系统环境为Windows10的64位操作系统,硬件设备参数为32 GiB内存、Intel i7-10700K处理器和RTX 3090显卡。
在一级识别网络中,设定(训练集+验证集)与测试集的比例为9∶1,训练集与验证集的比例也为9∶1,将数据集按上述比例进行随机划分。参数设置:MaxEpochs为100,冻结训练Epochs为50。初始学习率为0.000 1, 更新学习率的乘法因子数值为0.95。进行二级识别时,将截取后的领部图像按9∶1的比例随机划分为训练集和测试集,再次输入主干网络Resnet50,训练迭代次数为50。
3.2 评价指标
本文采用平均精度 (average precision,AP)、mAP等目标检测常用指标进行模型性能的评价。AP为PR曲线下的面积,用于衡量训练出的模型在每个类别上的检测精度。mAP即平均AP值,衡量训练出的模型在所有类别上的检测精度,是目标检测中一个最为重要的指标。
同时,本文采用混淆矩阵、准确率、精确率、召回率和F1分数评判分类模型的优劣。
3.3 循环Faster R-CNN领部识别结果分析
3.3.1 一级识别网络训练过程与结果分析
一级识别网络训练过程中各部分的损失值随训练迭代次数的变化曲线如图4所示,rpn_cls和rpn_loc分别代表RPN训练阶段的分类和回归损失,roi_cls和roi_loc分别代表Fast R-CNN训练阶段的分类和回归损失,Train Loss代表训练集总损失,Valid Loss代表验证集总损失。
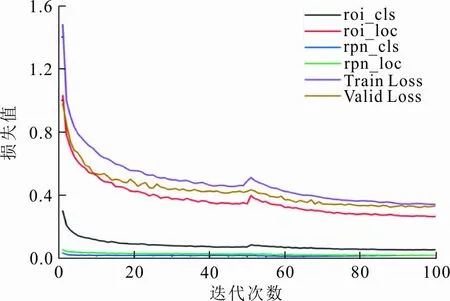
图 4 一级识别网络训练损失Fig.4 First-level recognition network training loss
从图4可以看出,在总体训练过程中,RPN阶段的分类和回归损失训练始终很小,保持在0.06以下,而Fast R-CNN阶段的分类和回归损失相比于RPN大很多,这是由于RPN阶段是对目标区域进行粗略的筛选,而在Fast R-CNN阶段再进行精细的调整。30个训练迭代次数后,损失值的波动速度降低,最后趋于稳定,最终训练集和验证集的总损失分别为0.340 3和0.329 6,模型收敛效果较好。
将测试集输入训练好的网络进行性能测试,图5显示了模型在一级类别上的AP值。
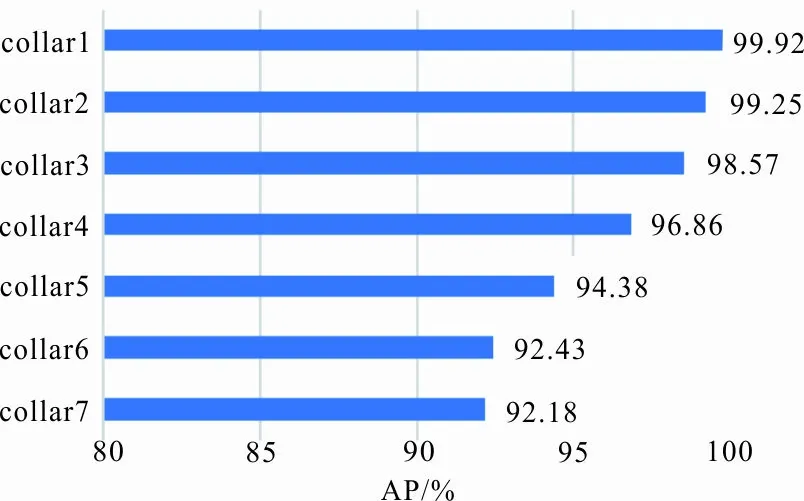
图 5 一级识别结果Fig.5 First-level recognition results
从图5可以看出,一级识别网络在所有类别上都具有较高的AP值,通过计算可知mAP约96.23%,模型对于翻立领(collar1)和翻领(collar2)的检测精度最好,AP分别为99.92%和99.25%,这是由于这2类领型都带有领面,特征较明显,易于识别。模型对于其他领型的检测精度依次降低,其中方领(collar7)的领角呈方形,形状特征较具有辨识度,AP约98.57%,而立领(collar3)虽然含有领座,但仍然具有圆领(collar5)的形状特征,可能被识别错误,由于翻立领,翻领,飘带领的内领形状可能呈V型,若V领(collar6)带有贴边或装饰,会产生多个预测框,且collar4和collar6的样本数量较少,使得这两类检测精度最低。
3.3.2 类权重对一级识别结果的影响
各个类权重方案在同一测试集下的检测精度如图6所示。
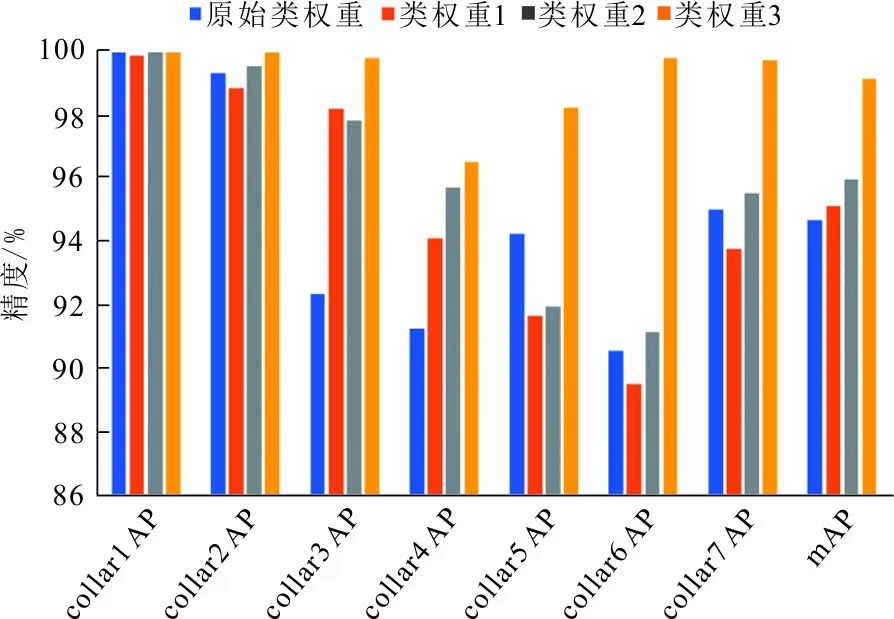
图 6 各类权重一级识别结果Fig.6 First-level recognition results of various weights
从图6可以看出,类权重改变对mAP有不同程度的提高,类权重3对于模型精度的提升效果最好,mAP约98.79%,这是由于类权重3根据特定少类别(样本量少且AP较低)与最多类的样本比例去赋予最多类更小的权重,降低了模型对最多类的关注度,并且类权重3的训练损失最低,训练集和验证集的总损失分别为0.307 4和0.291 0,模型的收敛程度最高,因此将样本数量占比最高类加权系数来控制权重,能够有效提升模型的检测精度。
3.3.3 二级识别结果分析
将测试集输入训练好的二级识别网络,图7是二级分类结果的混淆矩阵,横轴表示真实标签,纵轴表示分类结果。

图 7 二级分类结果混淆矩阵Fig.7 Confusion matrix for secondary classification results
从图7可以看出,预测值在主对角线上分布密集,表示绝大多数样本都被正确地分类,在550张测试图片中,只有16张图片分类错误,准确率达到了97.09%,最终模型在测试集上每个类别的精确率、召回率、F1分数的平均值分别为96.74%、96.89%、96.70%。由于截取后的图像只包含领部区域,能够突出目标,模型对于领部二级细节特征的识别分类效果较理想。
3.4 对比与分析
将循环Faster R-CNN的一级识别网络与一阶段检测算法YOLOv3在衬衫领部的二级类别上分别进行训练和测试,检测精度如图8所示。
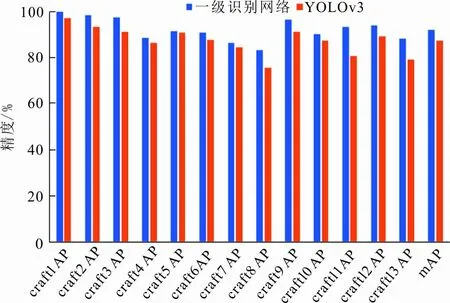
图 8 二级类别检测精度对比Fig.8 Secondary category detection accuracy comparison
从图8可以看出,一级识别网络对于二级类别的mAP约92.17%,相比于一级类别的检测精度降低了约4.06%,一级识别网络不适合直接用于领部二级细节特征的识别分类。而YOLOv3在所有类别上的检测效果均不及一级识别网络,且mAP下降约4.97%。图9为测试集中二级类别检测结果示例。

(a) 一级识别网络

(b) YOLOv3图 9 二级类别检测结果示例Fig.9 Examples of secondary category detection results
从图9可以看出,YOLOv3网络存在预测区域不准确和漏检的情况,检测效果相对较差,原因是YOLO网络对小目标不够敏感,容易漏检,不适用于衬衫领部识别。
4 结 语
本文以衬衫领部为研究对象,提出了一种基于循环Faster R-CNN的衬衫领型精确识别方法,将衬衫领部根据常见领型以及细节构成要素划分为两级类别,先利用一级识别网络Faster R-CNN实现衬衫领部的自动识别与截取,再循环利用该网络中的主干特征提取网络,连接全连接层,完成领部二级分类。为提升少样本类别的检测精度,解决衬衫领型类别间样本不均衡问题,采用权重惩罚方法设定类权重,改进后网络的mAP由96.23%提高到98.79%。在一级识别网络识别到领部时将其边界框进行截取,截取后的图像只包含领部区域,能够突出目标,二级网络的分类准确率为97.09%,模型具有较好的分类性能。实验结果显示,相比于YOLOv3算法本文网络更适用于衬衫领部细节特征的识别,模型具有一定的泛化能力,可以将其扩展到服装其他部件的精确识别。
