针对细微特征进行K-means聚类的电台分选识别技术*
2022-08-26杨亮亮
杨亮亮
(中国西南电子技术研究所,成都 610036)
0 引 言
随着无线电技术的快速发展,现代战场中的通信电子设备规模和数量不断增长,对通信电台实现精准分选与识别已成为电子侦察对抗领域的研究热点,但也是难点。电台的分选能够快速分析兵力规模及部署,个体识别可以有效判别目标,对掌握战场态势具有很大的支撑作用,而传统只针对信号层面的分析识别显然已不能完全满足需求。
通信电台不同于雷达系统,通信类设备技术参数差异小,尤其是同型号电台进行组网后,很难从同频带、同带宽、同调制的非协同信号中分离出个体。另外,随着复杂加密技术的广泛应用,非授权的接收方在没有密匙的条件下也很难解析出在线电台的组网信息。
但是电台自身固有的一些特征与其他不同个体之间存在差异,为分选识别提供了依据。研究人员从不同的角度提出了不同的特征提取方法。从信号参数角度出发,有时频域参数特征(短时傅里叶变换[1])、高阶矩高阶谱参数特征(积分双谱特征[2])等。从变换域角度出发,有小波分析方法[3]、EMD变换(也称为HHT)[4]等。但由于各自产生机理不同,很多特征不具备普适性。
另外,很多先进的机器学习算法也被应用到了辐射源的分选识别中,有基于最邻近距离分类器[5]的识别方法,有基于贝叶斯分类器[6]、神经网络分类器[7]的辐射源指纹特征识别,有基于支持向量机(Support Vector Machine,SVM)的雷达辐射源识别[8]等。上述均为有监督或半监督的学习算法,需要事先提供已知正确的数据信息集进行训练,在训练的基础上进行分选识别。而在实际应用中,很多场景是针对未知辐射源的,并没有足够的先验知识。
综上,本文从电台物理层面出发,针对其辐射信号的杂散、暂态细微特征,提出采用基于K-means聚类算法的技术,能够在没有先验知识的条件下对未知信号进行高效分选识别。
1 细微特征
1.1 杂散细微特征
电台发射机的模拟部分一般由数模转换器(Digital-to-Analog Converter,DAC)、放大器、滤波器、混频器、射频功放等器件级联组成,相比数字电路,模拟器件的细微差异更明显也更易提取。
DAC会引入量化误差和取整非线性误差。量化误差具有均匀分布的性质,不会有太大特征差异。取整非线性误差则会带来实际步进值与理想步进值的差异,从而引入非线性失真,从频域观察为不同程度的谐波形式,不同器件的谐波失真会有所差异;中频本振、射频本振等频率源器件受相位噪声影响,会体现一定非线性特征,从频域观察不再是单一谱线,这些相噪参与混频、调制等非线性处理后,会引入更为复杂的谐波形式;功率放大器同样具有非线性特性,理想的放大器输出端的信号比输入信号大且形状与输入信号完全一样,但现实不同的放大器件传输曲线不能保证完全相同的线性特性,尤其在邻近放大器饱和区域,为了提高放大器的工作效率,输出功率范围一般都会达到P1 dB压缩点,不同放大器器件线性区的差异以及压缩点的不同均会使得输出信号产生非线性的畸变失真,从而扩展信号频谱,出现杂散。
综上,不同的电台个体,即使同型号、同批次产品,由于内部各级物理元器件特性以及工艺差异性等影响,使得其辐射信号除主成分外会有噪声以及一定的杂散分量,这些杂散特性由电台个体本身的物理属性决定,相互之间具有一定的细微差异。
图1(a)为某型电台能量归一化后一段时域波形图,时域放大可以观察到噪声与谐波杂散波形的存在。图1(b)为某型同一批次三部电台进行无线通信时,用同一接收系统多次接收采集后的能量谱图,可以看到不同电台辐射信号在不同频点的杂散特性相互之间略有差异,而自身却相对稳定。
(a)时域
1.2 暂态细微特征
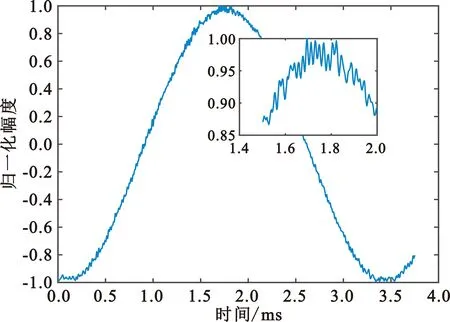
在电台状态切换时,尤其是发射能量的加载及释放的过度过程中,由于内部电源及元器件差异,使得不同电台辐射信号之间也存在相应暂态特性的差异。虽然随着使用时间增加元器件老化等影响使得这些特性有所变化,但短时间内该特性相对比较稳定,也可作为细微特征进行提取使用。图2(a)为电台通信启动时的能量前沿瞬时时域波形,启动过程为一个阶跃振荡过程,其中没有夹杂任何调制,只包含个体自身特征信息。图2(b)为某型同一批次的三部电台分别进行多次无线通信启停,用相同接收系统进行接收采集后,对启动过程的能量前沿波形的谱图分析,可以看到不同的电台启动过程的频谱能量分布略有差异,而本身相对稳定。

(a)时域
2 K-means聚类
2.1 K-means聚类算法
与分类不同,聚类没有任何先验知识作为依据,其目的就是要从没有标记的样本集中提取其内部性质和规律。聚类算法作为无监督学习的核心问题,在机器学习领域被广泛研究[9-11]。
K-means是一种从划分角度[12]出发的聚类算法,对大样本数据具有较高效率和良好伸缩性。该算法依据距离衡量样本间相似度,距离越近相似度越高,通过迭代更新方式,不断降低类内样本跟质心的误差平方和,最终将样本数据聚成K类,K值为提前设定值。算法具体步骤如下:
Step1 收集样本集{x1,x2,x3,…,xn},n为总样本数,每个样本向量为xj={xj1,xj2,xj3,…,xjm},xjt为第j个样本第t个属性,共m维属性。
Step2 根据给定K值,选K个样本(也可以非样本点)作为初始质心,初始质心向量集为{a1,a2,a3,…,ak}。
Step3 计算每一个样本点xi到每个类质心向量ak的距离(欧氏距离或余弦距离),欧氏距离为
(1)
依次比较样本到每个质心的距离大小,将样本归为距离最小的类内,分别为{c1c2c3…ck}类,aj为cj类的质心。
Step4 所有样本归类后,根据类内样本更新质心位置:
(2)
质心即为类内所有对象各个维度属性的均值。
Step5 使用更新后的质心,重复Step 3,直到所有质心向量收敛,则表示聚类完成。
2.2 聚类评价指数
K-means算法进行聚类的前提,是要事先给出确定的类的数目K值,而实际应用中样本的类别数目往往未知,需寻找最优K值。通过对一定范围的k(2≤k≤kmax)值进行遍历搜索,用聚类质量效果的评价指标来选取最优值。常用指标有CH(Calinski-Harabaz)指标、SC(Silhouette Coefficient)指标、DB指标、Dunn指标、I指标等。基于电台杂散和暂态细微特征分布形式与特点,本文分别选取CH和SC两种指标进行聚类质量评价。
CH系数主要衡量聚类的紧密度和离散度,通过计算类内协方差度量类内的紧密程度,通过计算类间协方差度量离散度。CH系数由两个协方差的比值得到,值越大代表类内越紧密、类间越分散。
(3)

SC系数也叫轮廓系数,主要衡量类内相似度和类间差异度,通过计算样本与同类中所有其他样本的平均距离度量类内的相似度,通过计算样本与其相近类中的所有样本的平均距离度量类间的差异度。SC系数由两个平均距离的比值得到,SC值越大代表类内越紧密、类间越分散。
(4)
式中:n为总样本数,a(i)为样本i与同类内其他样本的平均距离,b(i)为样本i与非同类的所有样本的平均距离。
3 电台分选及识别算法
3.1 电台分选及特征属性提取
传统的电台分选方法在信号协议层面进行,在接收无线电信号后,进行参测、识别、解调,然后解码、解析,从而掌握电台个体信息及其之间的通联关系。但针对非协同电台,往往不具备解析条件。尤其对于加密电台,在没有密匙的条件下,无法破解报文内涵,更无法获取节点信息;对于抢占式、主属式电台通信,没有采用网络协议,无法通过截获信号信息对在线电台进行有效分离。
结合前文,针对电台细微特征进行K-means聚类,以实现对电台的分选并获取个体特征信息。分选步骤如下:
Step1 采集M个同频点同调制在线电台样本值(电台数未知,2~M个)。
Step2 将样本进行归一化处理后,进行时频域转换,提取特征值作为参与聚类的样本向量。
Step3 从K=2开始,对样本集进行K-means聚类。
Step4 计算当前K值聚类的评价指数,选取合适的评价指数,杂散特性聚类评价指数选择CH值,暂态特性聚类评价指数选择SC值。
Step5 重复Step 3,直到K=M(或某一个指定可能最大值Kmax)。
Step6 遍历所有评价指数,寻找最优评价指数对应K值,即可视为目标电台个数,每个分类即为各对应电台的信号样本。
分选流程图如图3所示。最优K值对应的每个类的质心向量,可作为其对应电台个体的特征属性值,该特征属性值可入库作为对新样本进行有监督分选和个体识别的依据。
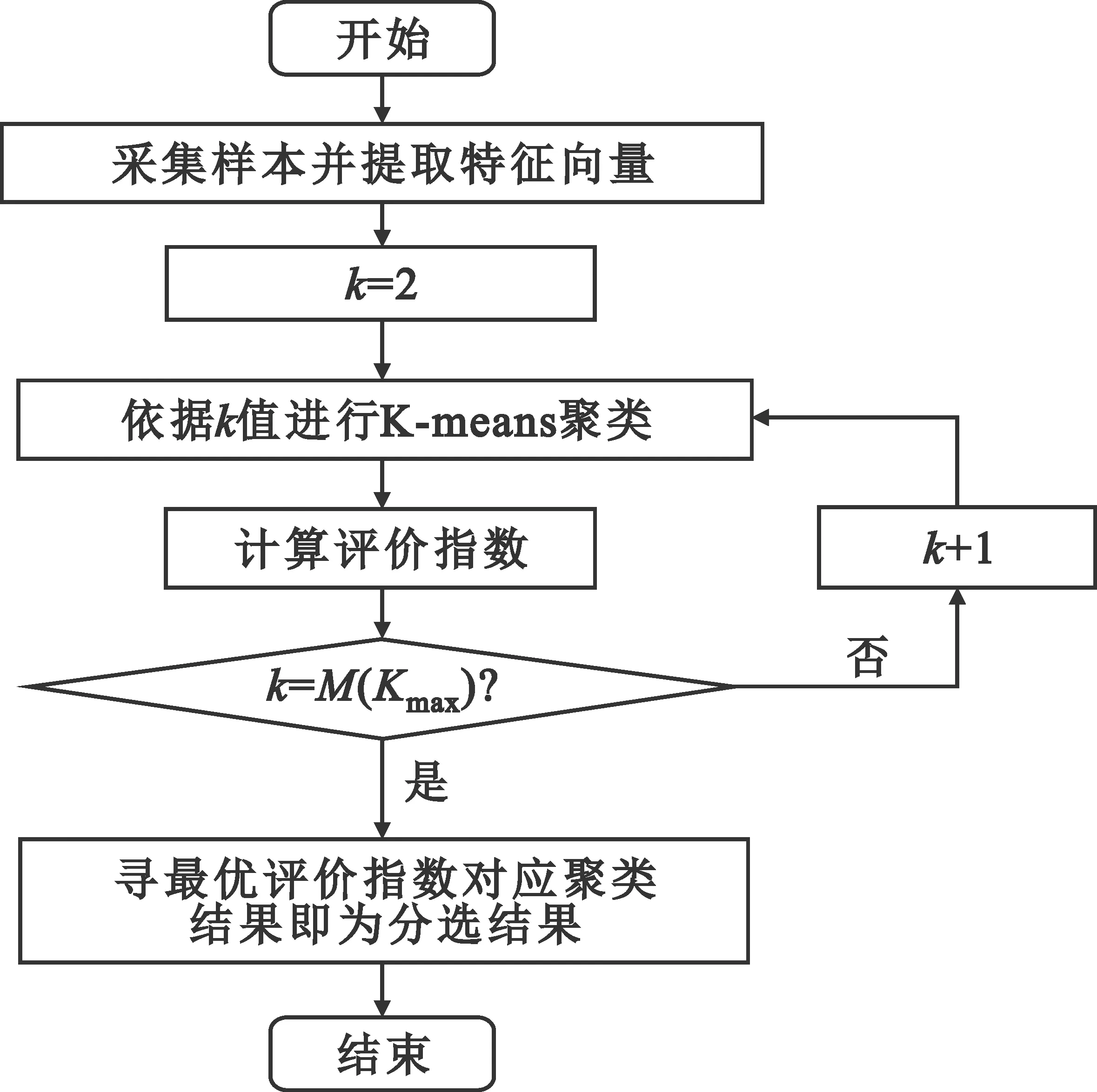
图3 分选流程图
3.2 个体识别
经过K-means聚类,一方面将目标电台进行了分选,同时提取了各个个体的特征属性值。个体识别即为新样本与各个体特征属性值之间相似性的判断,可通过相关运算来判断相似性,相关值作为相似程度的判据。相关运算公式如下:
(5)
其中特征属性值a=[a1,a2,a2,…,am],样本特征值x=[x1,x2,x2,…,xm]。相关值越大,相似度越高,当前信号样本判断为该电台个体辐射的置信度就越高,最大值为1。
4 实验及结果
实验选取了三部同型号、同批次生产的手持式超短波通信电台,固定选择60.25 MHz作为发射中心频点进行组网通信,使用同一个超短波接收系统对不同电台辐射信号接收采集。
4.1 分选实验
4.1.1 可行性实验
采集杂散特征样本,将所有样本随机排列。假设未知电台数目的条件下进行分选,采用K-means算法进行聚类,遍历不同K值(大样本情况下,选择合适最大K值,确保评价指数达到收敛即可)。
选择CH值作为评价指数,图4为不同K值聚类后的CH评价指数值,可以看出最优指数对应的K值为3,与实际电台数目相符。随着K值增大,评价指数区域衰减收敛。
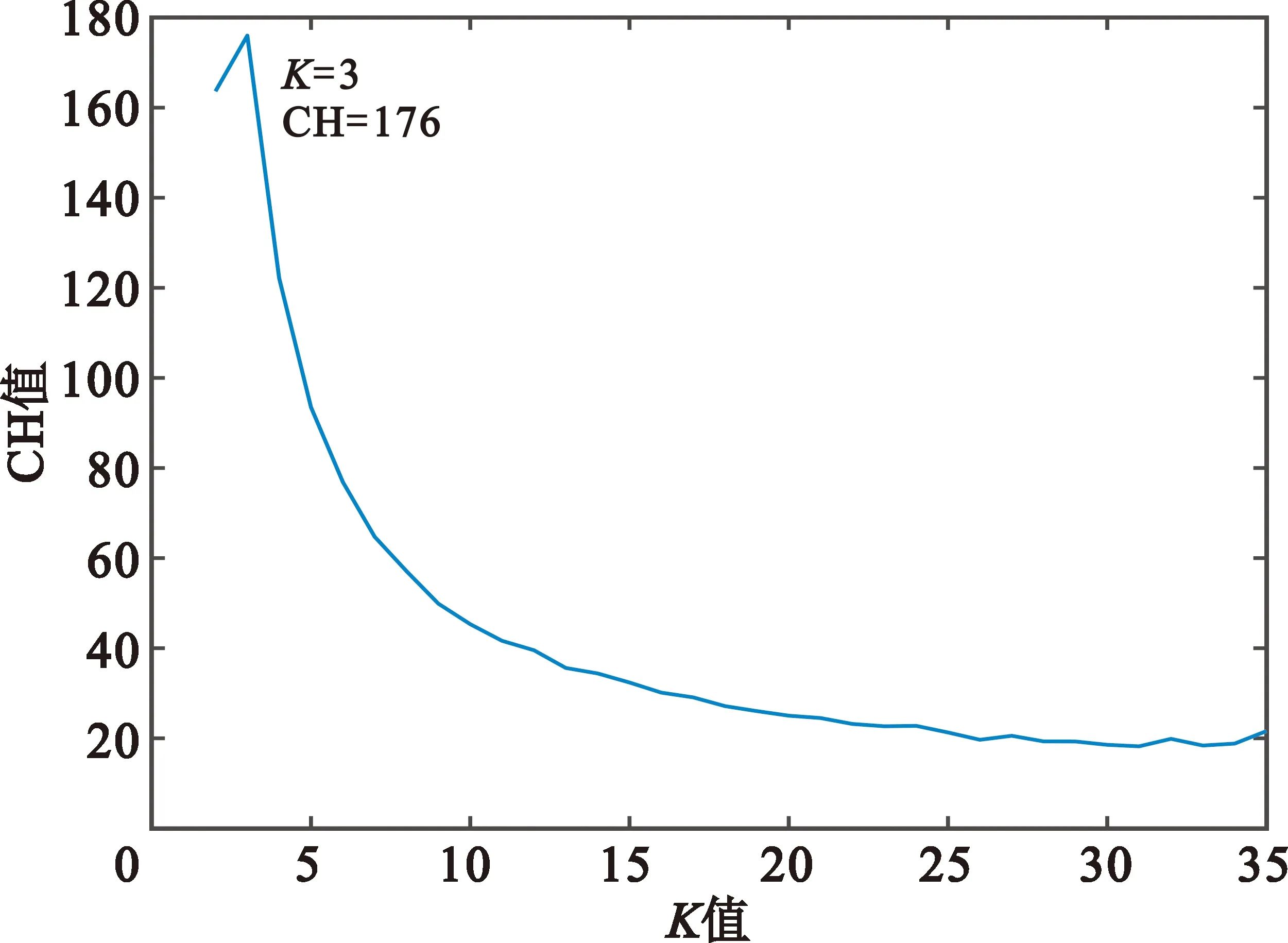
图4 杂散特征CH评价指数
同样随机采集暂态特性样本进行聚类。由于其暂态特征分布具有类内较发散、类间距离较近的特点,选用轮廓系数SC作为评价指数。图5为不同K值聚类对应的SC评价指数值,可以看出最优指数对应的K值为3,与实际电台数目相符。
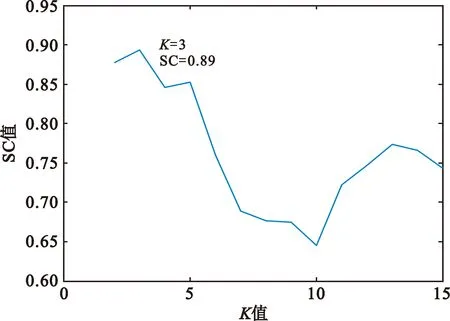
图5 暂态特征SC评价指数
选取75 kHz、120 kHz、172 kHz三个频点的杂散特性观察分选效果,如图6所示,每部电台的样本均能被正确分选。

图6 杂散特征样本分选结果
4.1.2 高效性对比实验
为验证采用K-means聚类算法进行分选的高效性,对比2.1节中提到的Linkage、DBSCAN、GMM三种聚类算法进行分选的运算时间。
在相同样本、相同运算环境下,分选用时的对比结果如图7所示。可以看出,采用其他算法用时较多,且随着样本数的增加,分选用时也随之存在不同程度的增多,而采用K-means聚类算法进行分选始终具有较高效率,特别在大样本的条件下分选效率优势更为明显。
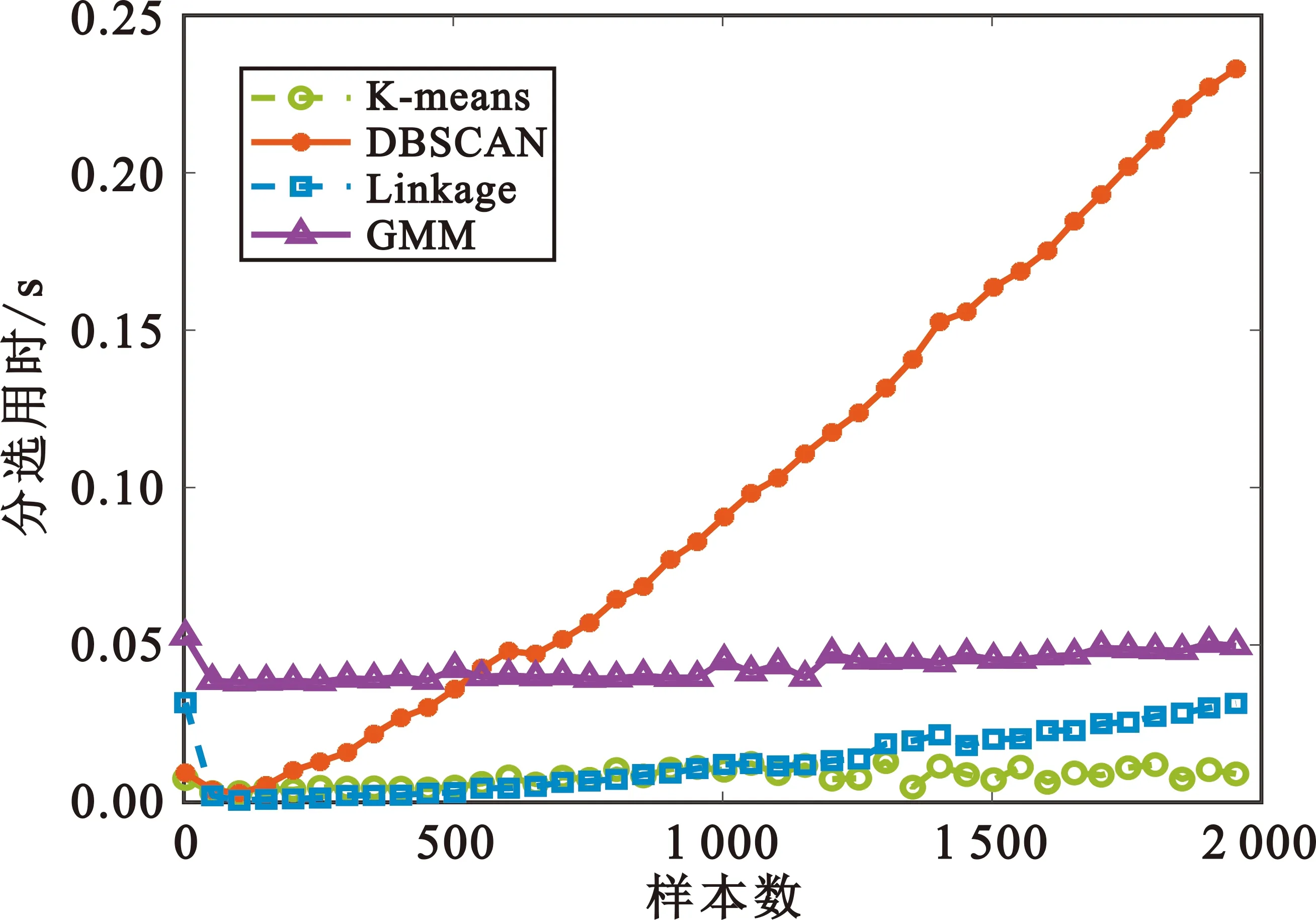
图7 运算时间对比
4.2 特征提取
K-means聚类后每个类的质心可作为对应电台的特征属性值,可以用来作为个体识别的参考特征向量。从图8和图9中可以看出,提取的特征属性值基本位于样本中心。

图8 杂散样本及特征属性值

图9 暂态样本及特征属性值
4.3 个体识别
采集三部电台的新样本,用3.2节方法进行个体识别。表1为不同的电台新样本与提取的特征属性值相关运算的结果。电台样本与其自身特征属性的相关值最高,均达到93%以上,可有效实现信号样本的个体识别。

表1 电台识别相关系数表
5 结束语
本文从电台物理层面出发分析了辐射信号杂散和暂态细微特征的产生机理,并提出了对其进行K-means聚类的电台分选识别技术。通过实验验证,该技术方法可行、高效,易于工程实现。后续工作,一方面针对通信电台研究提取更多其他维度的个体特征属性,以提高分选方法的鲁棒性和适应性;另一方面研究如何将本文所提出的分选识别方法进行改进,以扩展应用到其他类型辐射源。
