基于ISSA-SVM的煤矿变压器故障诊断方法*
2022-08-26田锦绣李燕杰
郑 鑫,石 纯,田锦绣,齐 冀,李燕杰
(1.山西潞安环保能源开发股份有限公司,山西长治 046200;2.辽宁工程技术大学,辽宁阜新 125105;3.山西潞安矿业集团慈林山煤业有限公司李村煤矿,山西长治 046200)
0 引言
矿用变压器作为煤矿供电系统中的重要组成部分,变压器的绝缘老化现象也变得越来越严重,若发生故障将给企业带来难以预料的经济损失,甚至是员工生命的危险,使整个煤矿开采单位的施工和工人的人身安全受到变压器的工作状态的影响。因此需要实时监测变压器的运行状态,及时发现故障问题。如今传统的变压器故障诊断方法缺点也很明显,其检测时间长且容易出错,需要大量的人力和财力。在当前的故障诊断中,采用了许多智能化的诊断技术。
目前,油浸式电力变压器在输配电系统中被普遍使用,而且DGA技术成为了变压器故障诊断的一种主要方法[1]。在故障诊断方面,随着人工智能和数据挖掘等技术的发展,利用DGA技术与人工智能算法结合的诊断方法提高了变压器故障诊断准确率[2],如神经网络[3]、支持向量机[4](Support Vector Machine,SVM)、极限学习机[5](Extreme Learning Machine,ELM)等。Zhou Yichen等[6]基于油的溶解气体分析技术,通过改进的灰狼优化器优化概率神经网络(Probabilistic Neural Network,PNN)模式层的平滑因子,提高PNN的分类精度和鲁棒性;夏玉剑等[7]通过集合经验模式分解提取变压器不同运行状态下振动信号特征矢量,并结合主成分分析投影到直观的二维图像中,利用K近邻(K-nearest neighbor,KNN)实现故障分类和自动故障识别。结果表明,该方法可以对测试样本进行快速的自动模式识别。Fan Qingchuan等[8]通过无编码比法提取油中9维特征向量,利用改进的WOA优化SVM进行变压器故障诊断。结果表明,所建立的模型具有诊断精度高、稳定性强的特点;闫鹏程等[9]以实验采集的油样作为依据,提出MSC-KPCA-ELM模型并结合激光诱导荧光光谱技术对电力变压器是否发生故障进行快速诊断,结果表明,所提方法能够保障电力设备的运行安全。
针对现有研究存在的局限,本文提出一种基于混沌种群初始化和柯西高斯变异策略改进麻雀算法(ISSA)优化支持向量机的煤矿供电变压器故障诊断方法。最后与传统麻雀搜索算法(Sparrow Search Algorithm,SSA)、PSO算法优化的SVM诊断模型的诊断精度对比分析,验证本文方法的可行性。
1 故障特征提取
变压器故障发生时,绝缘油中溶解气体H2、CH4、C2H2、C2H4、C2H6、CO2、CO、O2、N2含 量 将 发 生 变化。在传统的电力变压器故障诊断当中,研究学者经常会忽略原始数据的高纬度对变压器故障诊断精度产生的影响。所以本文利用核主成分分析(KPCA)对故障样本数据进行特征提取。使气体之间避之保持独立,减小计算量。如表1所示,累计方差贡献率达到90%以上,因此确定经过KPCA降维[10]后的输入变量个数为5个。
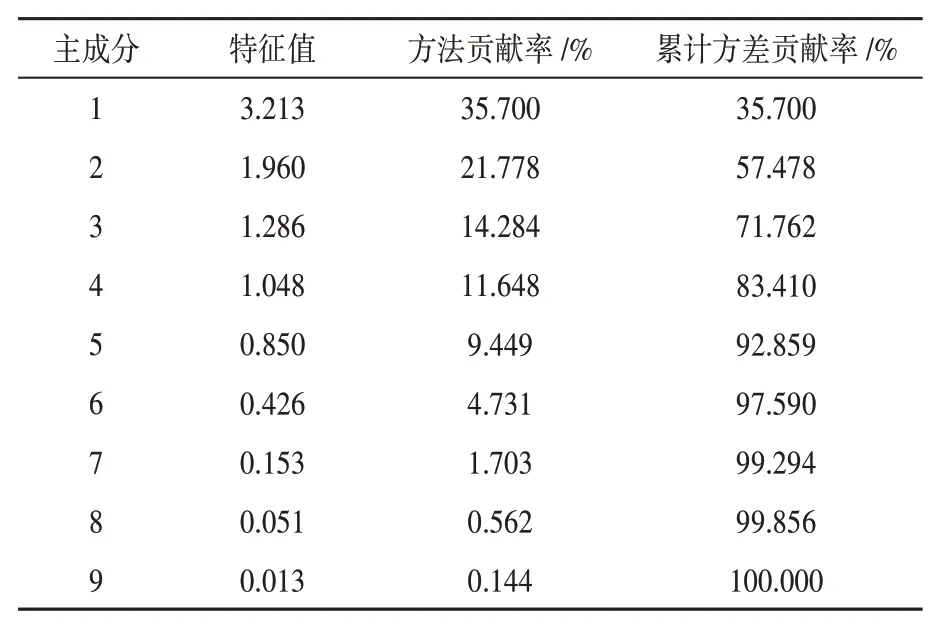
表1 特征值及累计方差贡献率
2 ISSA-SVM模型
2.1 ISSA算法
SSA[11-13]数学模型的建立是按照麻雀觅食行为,灵感来自于麻雀的习性。在种群中有两种角色,分别是发现者和加入者,发现者和加入者的比例和总数量不变。种群个体的最优位置通过觅食和预警反捕食行为来随时更新。
麻雀集合如下所示:

麻雀的适应度值如下所示:

发现者的位置更新公式为:

式中:α为一个随机数;t为迭代次数;itermax为最大迭代次数;S T为安全值,ST∈[0.5,1];R2为预警值,R2∈[0,1];L为元素均为1的1×d的矩阵;Q为服从正态分布的随机数。
当R2<S T时,麻雀种群附近没有危险。当R2≥ST时,麻雀种群中的预警者发现了危险,使其他个体更新到安全区域。
加入者的位置更新公式为:
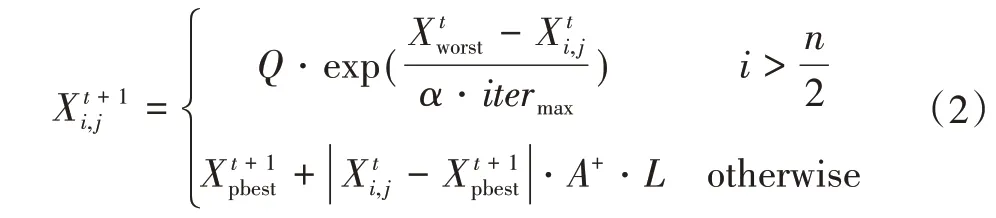
当i>时,表示第i只麻雀个体需要更新到其他地方进行觅食,其他情况则表示第i只麻雀在的位置周围觅食。
预警者更新公式如下:
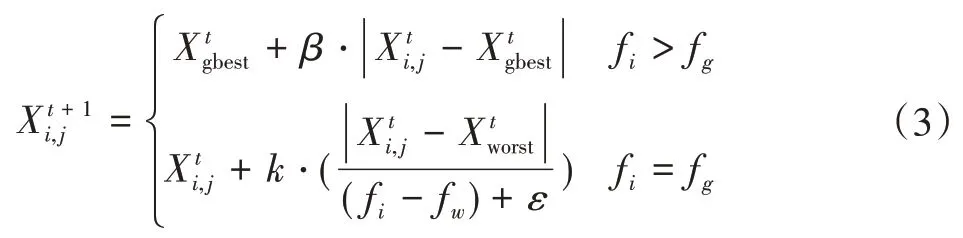
2.1.1 ISSA基本理论
传统的麻雀算法[14]虽然有着不错的寻优能力,但还有一定的缺陷,而且有一个缺陷不易忽视,那就是容易陷入局部最优,并且初始种群分布不均。因此提出以下的方法来对麻雀算法进行改进。
(1)Logistic映射
混沌[15]是一种由确定性系统自发地引起不稳定的现象,它在非线性系统中比较常见。由于混沌的遍历性,使得它可以在一段时间内不反复地经历各种状态,并充分利用了混沌变量。
在此基础上,在SSA算法中引入Logistic如下:

式中:μ∈(0,4];k为迭代次数;x∈(0,1)。
Logistic映射在分叉参数3.57<μ<4时x的值向0和1发散并逐渐出现混沌现象,本文取μ=4。
通过下式实现种群初始化:

式中:Xlb、Xub为上下限;X为映射后的个体。
(2)柯西高斯变异策略
传统的SSA算法迭代的后半程,有着容易陷入局部极值的问题。柯西在扰动能力方面比较强,有着比较好的全局寻优能力,而高斯有着比较强的局部寻优能力,因此引入柯西高斯变异[16]来对麻雀算法进行优化,挑选适应度较优的麻雀进行变异进而更新位置,公式如下:
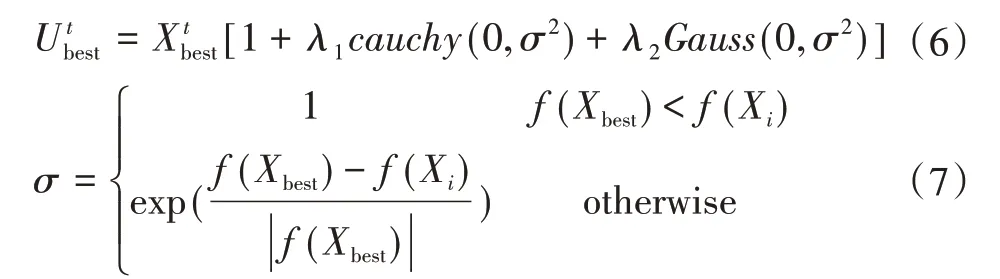
2.1.2 ISSA性能测试
为了验证ISSA的性能,选取两种基准测试函数来测试,对比传统的SSA和PSO进行仿真对比实验。测试函数如图1~2所示。
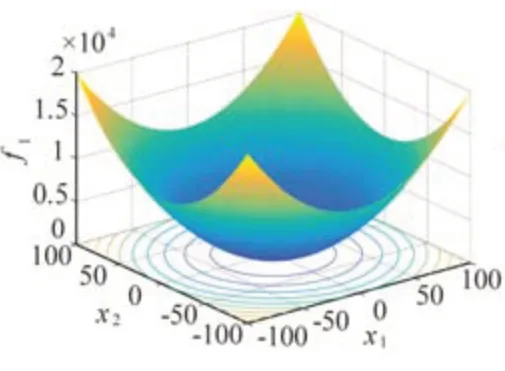
图1 测试函数f1
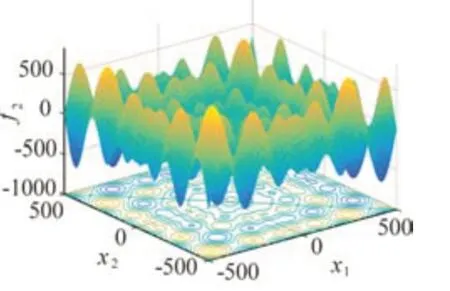
图2 测试函数f2
测试函数1:
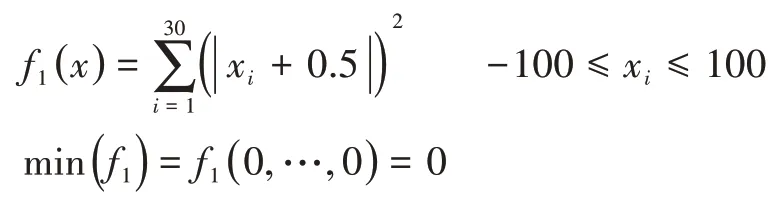
测试函数2:
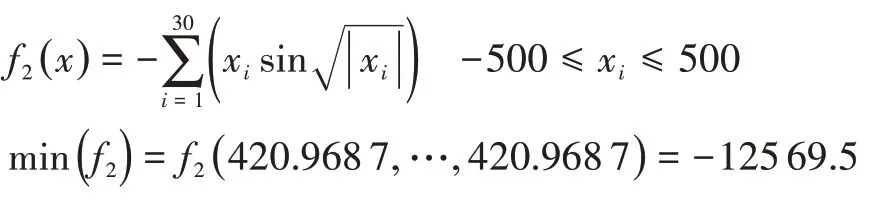
分别对f1(x)和f2(x)两个测试函数进行独立实验,得到图3和图4所示的仿真结果。由图可知,f1(x)和f2(x)两种测试函数对算法的寻优过程的性能测试时,SSA和PSO表现不如ISSA,相较于另外两种算法有很大提升。

图3 ISSA、SSA和PSO对f1(x)函数的优化过程
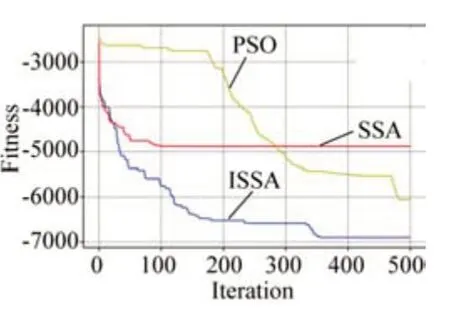
图4 ISSA、SSA和PSO对f2(x)函数的优化过程
通过上述比较试验可以看出:加入混沌映射和柯西高斯变异策略的麻雀搜索算法的寻优能力和收敛速度有着明显提升,和其他算法相比,改进后的麻雀算法具有较强的适应能力。
2.2 多分类支持向量机
标准的SVM[17]分类本质上是找到一个最优分类超平面。其表达式为:

式中:φ(x)为映射函数表达式;w为超平面的法向量;b为偏置量。
超明面问题转变成约束条件,其目标函数为:
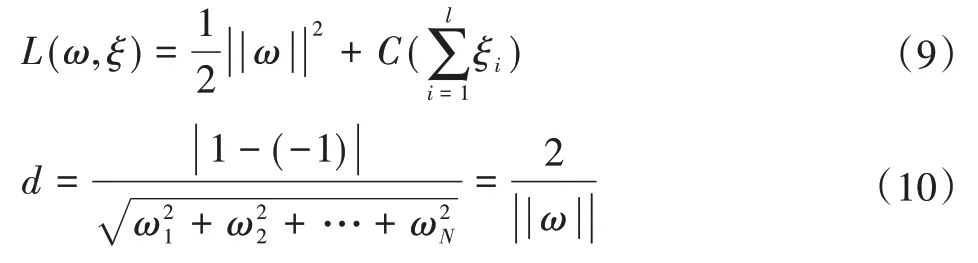
想要正确分类,d最好能够是最大值,即 ||ω||为最小值。
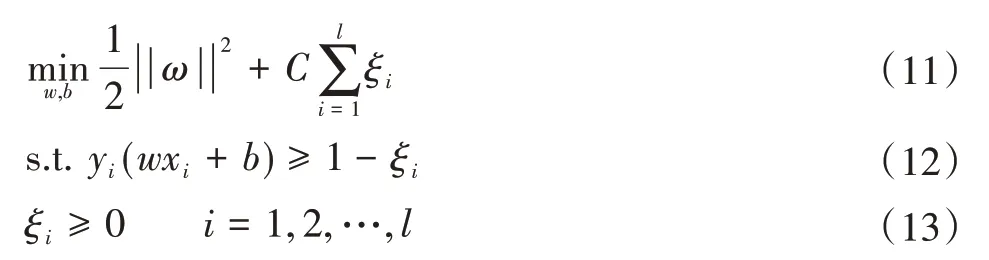
最优超平面函数为:
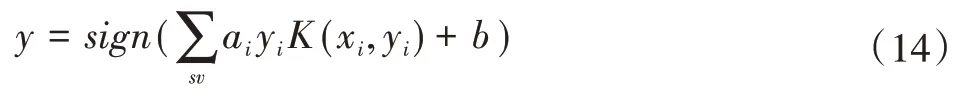
式中:sv为支持向量。
核函数表达式为:
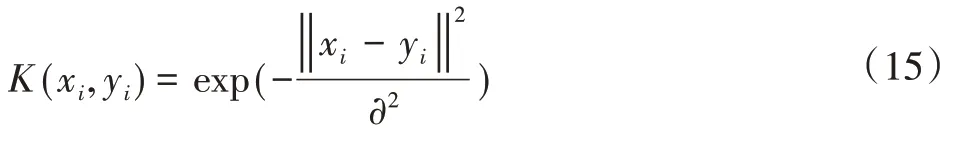
由上式可知,SVM的分类性能与(C,∂)有关,C和∂需要确定。因此想要提高精度需要最优的(C,∂)。
2.3 基于ISSA优化的SVM
ISSA优化SVM的故障诊断流程如下所述。
(1)将变压器故障数据利用KPCA方法降维,把降维后的数据按比例分为训练集与测试集。
(2)设置麻雀种群规模N,搜索空间维度D,最大迭代次数i termax,采用式(5)对麻雀种群初始化。
(3)初始化SVM相关参数。
(4)计算当前麻雀的适应度值,找出最优值和最劣值。
(5)根据公式(1)更新发现者位置。
(6)根据公式(2)更新加入者位置。
(7)根据公式(3)更新预警者位置。
(8)计算适应度值,保留最优个体位置。根据式(6)、(7)计算变异后的位置并更新。
(9)判断否达到最大迭代次数,如没有达到,则返回步骤4,若达到则用输出的参数建立ISSA-SVM的故障诊断模型。
综上所述,通过混沌映射和柯西高斯变异改进的麻雀算法对SVM参数寻优,能够得到最优参数,代入模型,使诊断的正确率得到提高。
3 煤矿供电变压器故障诊断
用KPCA将318组故障数据降维,得到5维特征变量,随机选择300组故障数据,其中200组用来进行训练,100组用来测试。变压器故障类型编号为1~5,如表2所示。
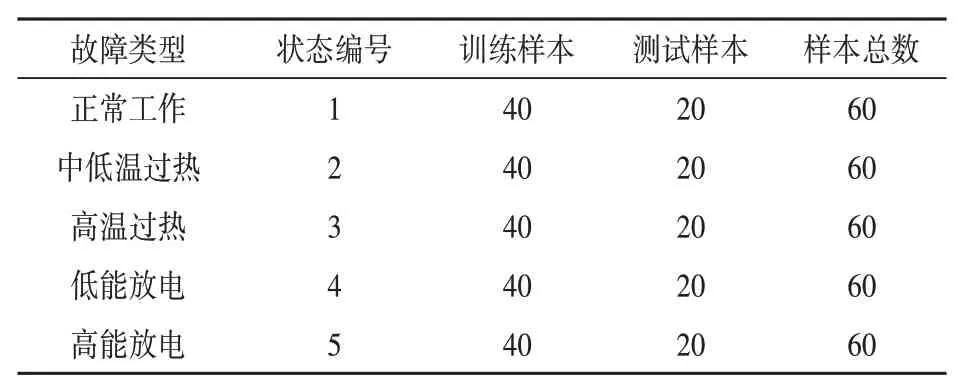
表2 样本数据分布
利用ISSA训练SVM并对变压器故障样本进行分类正确率测试,并用SSA、PSO算法优化的SVM相对比,仿真结果如表3所示。

表3 不同诊断方法对不同故障诊断的正确率
如图5所示,以PSO优化的SVM的变压器故障诊断模型中,中低温过热故障错误有6个,高温过热故障错误有5个,低能放电故障错误有6个,高能放电故障错误有5个,综合正确率为79.73%。

图5 PSO-SVM故障诊断分类结果
如图6所示,以SSA优化的SVM的变压器故障诊断模型中,中低温过热故障错误有5个,高温过热故障错误有5个,低能放电故障错误有5个,高能放电故障错误有4个,综合正确率为85.22%。
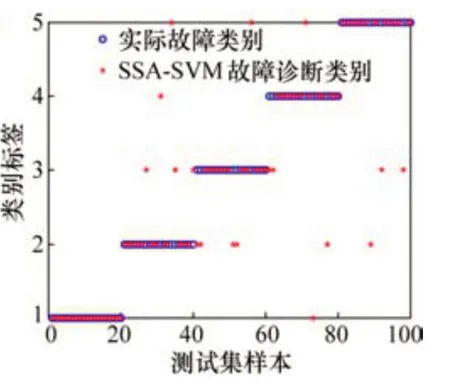
图6 SSA-SVM故障诊断分类结果
如图7所示,以ISSA优化的SVM的变压器故障诊断模型中,中低温过热故障错误有2个,高温过热故障错误有2个,低能放电故障错误有2个,高能放电故障错误有2个,综合正确率为93.80%。
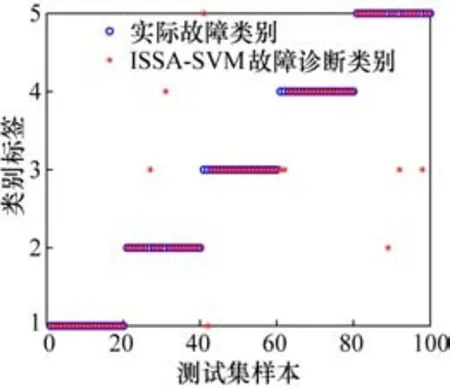
图7 ISSA-SVM故障诊断分类结果
综上所述,以ISSA-SVM的变压器故障模型进行变压器故障诊断,结果表明,ISSA-SVM模型诊断效果较好,精度最高,达到93.80%。综上可知,经过Logistic混沌映射初始化,能够使种群初始位置分布均匀;结合柯西高斯变异的SSA优化SVM所建立的故障诊断模型的性能最优,具有更高的可靠性。
4 结束语
针对变压器高维复杂的原始故障数据,采用KPCA降维进行特征提取,能够有效降低特征向量的维数,便于SVM模型识别数据特征,提高识别精度。通过Logistic混沌映射初始化、柯西高斯变异策略改进的麻雀搜索算法,进一步丰富了种群复杂性,改善了在寻优过程中很容易进入局部最优估计的问题。使用ISSA方法优化SVM的相关参数,可以有效地改善SVM的变压器故障诊断模型的准确度和泛化能力,从而提升了诊断准确度和提高了收敛性速度。较SSA-SVM和PSO-SVN诊断方法分别提升了8.58%和14.07%。采用此方法建立的诊断模型具有普适性,为解决此类问题提供了新的思路。
