一种面向空间机械臂目标定位的注视点估计方法
2022-08-26曲思霖王从庆展文豪
曲思霖,王从庆,展文豪
(南京航空航天大学 自动化学院,南京 210016;2.中国航天员科研训练中心人因工程重点实验室,北京 100094)
1 引言
航天任务中,航天员利用固定在核心舱或空间机械臂上的摄像机获取舱外信息,通过注视点估计注视操作界面控制舱外设备,对舱外目标进行拾取、操作等。自1901年起,用照相机拍摄图像用于注视点估计成为了主流方法。二维注视点估计方法目前比较成熟且应用最广,通过计算注视点的二维信息,建立注视点与屏幕的对应关系,得出视线在屏幕上的对应位置。二维注视点估计可以分为基于模型的注视估计方法和基于外观的注视估计方法。其中基于模型的注视估计方法包括瞳孔跟踪法、巩膜—虹膜边缘法、瞳孔角膜反射法、普金野象法等;基于外观的注视估计方法直接将人眼图像作为输入,经过图像处理提取表征眼动的特征,推断眼睛在计算机屏幕上的注视位置。瞳孔跟踪法需要引入红外光源,提高瞳孔的辨识度,可克服垂直方向的遮挡,但要求受试者头部相对固定;巩膜-虹膜边缘法通过图像处理提取异色边缘,利用边缘相对位置计算注视点坐标,要求受试者头部相对固定,且只适合测量水平方向眼动;瞳孔角膜反射法也需要引入红外光源获得瞳孔和角膜亮斑,视线方向由瞳孔中心相对于角膜反射的位置确定,允许头部轻微运动,市面上多数头戴式和桌面式眼动仪如Eyelink眼动仪、Tobbi眼动仪、Iview X HED眼动仪都是根据这个原理设计,为用户提供视线跟踪体验;普金野象法需要特征光源与实验设备,且在水平方向测量误差较大。基于外观的注视估计方法将整个眼部图像信息作为输入通过图像处理技术获得瞳孔位置、眼角位置等信息进行注视点定位,实现简单,价格低廉,可以处理低像素图像,允许受试者头部轻微运动,但精准度较低,鲁棒性不足,且需要大量样本进行训练。
目前,国内外已提出了多种基于外观的注视估计方法。Williams等提出一种稀疏半监督高斯过程回归模型将人眼图像映射到屏幕坐标。Marrinez等提出提取多级HOG作为特征,利用支持向量回归和相关向量回归得到眼睛特征与注视坐标之间的映射函数。Tan等提出一种利用线性插值近似外观流形模型的注视点估计方法,平均角度误差为0.38°。Lu等采用优化的方法得到自适应线性回归的最优解,达到通过稀疏的训练样本进行精确的映射的目的,还将问题分解为固定头部姿态下的初始估计和后续对头部转动和眼睛外观变形引起的估计偏差进行补偿,以增加自由头部运动的6个自由度。Liu等等提出了一种两步训练网络Gaze Estimator,以提高移动设备上注视位置的估计精度。毛云丰等采用深度卷积神经网络定位虹膜中心与眼角位置映射计算屏幕上的注视点,并在公开数据库MPIIGaze和Swith上验证该算法,提高了在低分辨率图像上进行注视点估计的准确率。孟春宁提出了一种基于矩形积分方差算子的虹膜定位算法,利用支持向量回归机估计注视方向。
对于空间站机械臂,其中一个重要的任务是完成空间舱外目标的拾取、搬运、定位和释放。利用安装在空间站核心舱或空间机械臂上的相机拍摄空间目标,航天员或地面指挥中心通过显示屏观察空间环境,注视空间目标所在位置,计算空间目标在空间机械臂坐标下的三维坐标。本文设计了虚拟环境下的空间机械臂多模态人机交互仿真平台,利用固定操作显示屏上单目照相机拍摄操作者注视空间目标主视图与左视图时的图像,经过图像预处理、特征提取和多流卷积神经网络训练,得到航天员(操作者)注视点所在矩形框的标签与空间机械臂待捕获目标的空间坐标,然后通过空间机械臂运动学反解计算得到关节角,并控制空间机械臂末端向空间目标运动。
2 基于目标定位的注视点估计
2.1 数据集的建立
通过注视点位置估计人脸图像与屏幕坐标的对应关系,许多国内外的研究团队已经做了大量的工作。2007年德国乌尔姆大学Weidenbacher等公开了一组包括20名受试者,共2220张图片的不同的头姿与视线的组合数据集。2016年麻省理工学院的Antonio Torralba研究小组利用iPhone和平板自带的前置摄像头拍摄人脸图像,并建立数据集GazeCapture,包括1400多人,240多万样本,截取左眼图像、右眼图像、人脸图像与人脸位置,将这些数据输入多流卷积网络,在iPhone上计算欧氏距离误差为1.71 cm,在平板上计算欧氏距离误差为2.53 cm。2017年美国莱斯大学公开了针对平板电脑注视点采集的包括51名受试者,4个不同头部姿势、35个注视点的数据集TabletGaze,提取多级HOG特征,用随机森林回归,得到的欧氏距离误差为3.17 cm。虽然有很多公开的数据集,但多数应用于手机、平板电脑。
本文中仿真平台空间环境显示界面为24寸(53.30 cm×29.90 cm),屏幕显示分辨率为1920×1080,即屏幕的长宽比为16∶9。为保证每个矩形块大小相同,长宽相等,将电脑屏幕平均分为16×9,共144个矩形块,每个矩形块的分辨率为120×120。使用单目摄像机采集9名受试者单一头姿的144个注视点数据集。将单目摄像机放置在屏幕上边正中心的位置,调整摄像头角度,使拍摄画面能完整显示受试者桌面以上身体部分,采集数据集图片时,要求受试者头部正对摄像头,瞳孔转动依次注视144个矩形块正中心部分,利用摄像机拍摄,每人每个矩形块拍摄约10张照片,过程中保持环境光线不变,允许受试者头部轻微晃动。实验采集9名22~25岁受试者的注视图像,其中7名男性,2名女性,数据集共16 395张图片。
使用摄像机拍摄的图片中包含实验室环境、无关人员的背影、侧脸等干扰条件,因此,需要对摄像机拍摄图像进行预处理,截取人脸部分。目前,人脸检测的方法包括Haar级联检测、ACF人脸检测、DPM算法、SURF级联检测等基于图像特征的方法。随着深度学习网络的发展,多种卷积神经网络应用于人脸检测方向,如2015年提出的级联CNN、2018年提出的Faceness-Net等。虽然深度学习算法更精准,但本文数据集中单张图片只包含一个正脸任务较简单,因此选择目前人脸检测速度最快的Haar级联检测器截取人脸部分。
2.2 图像预处理与特征提取
利用OpenCV中的Haar级联检测器检测图片中人脸部分,利用dlib检测器截取左、右眼部分。在Haar级联检测器中包含左眼检测器与右眼检测器,但存在一些问题,如易误采集到眉毛部分且截取人眼图片大小不一。dlib人眼检测较Haar级联检测器更稳定、更精准,且可设置截取图片大小。dlib检测器提取HOG作为特征,采用支持向量机进行脸部特征点识别,标记人脸68个特征点。截取左眼、右眼部分,截取图片像素大小为28 px×69 px,截取的左眼、右眼部分如图1所示。

图1 dlib检测器截取左右眼部分Fig.1 Left and right eyes intercepted with a dlib detector
为了增加数据集样本数,提高定位准确率,通过改变图片大小扩展数据集。综合考虑算法速度与实现效果,本文选择线性插值的方法改变图片大小。将左、右眼截取图像像素值变为36 px×60 px。
最后,在提取图像特征前,需要将RGB图像灰度化。将图片灰度化有利于识别物品边缘,计算梯度值,将图像矩阵变为二维矩阵,加快提取特征。
2.3 图像特征提取
利用图像特征提取方法描述特定区域,使该区域区别于周围其他点,具有高可分度。HOG算法通过计算和统计图像局部区域的梯度方向直方图来构成特征,计算图像每个像素的梯度,捕获轮廓信息,进一步弱化光照的干扰,保持图像几何不变性。获取人眼图像与注视点坐标的关系,需要得到瞳孔与眼角的相对位置。因此,本文选择HOG特征提取方法。左、右眼的梯度直方图如图2所示。
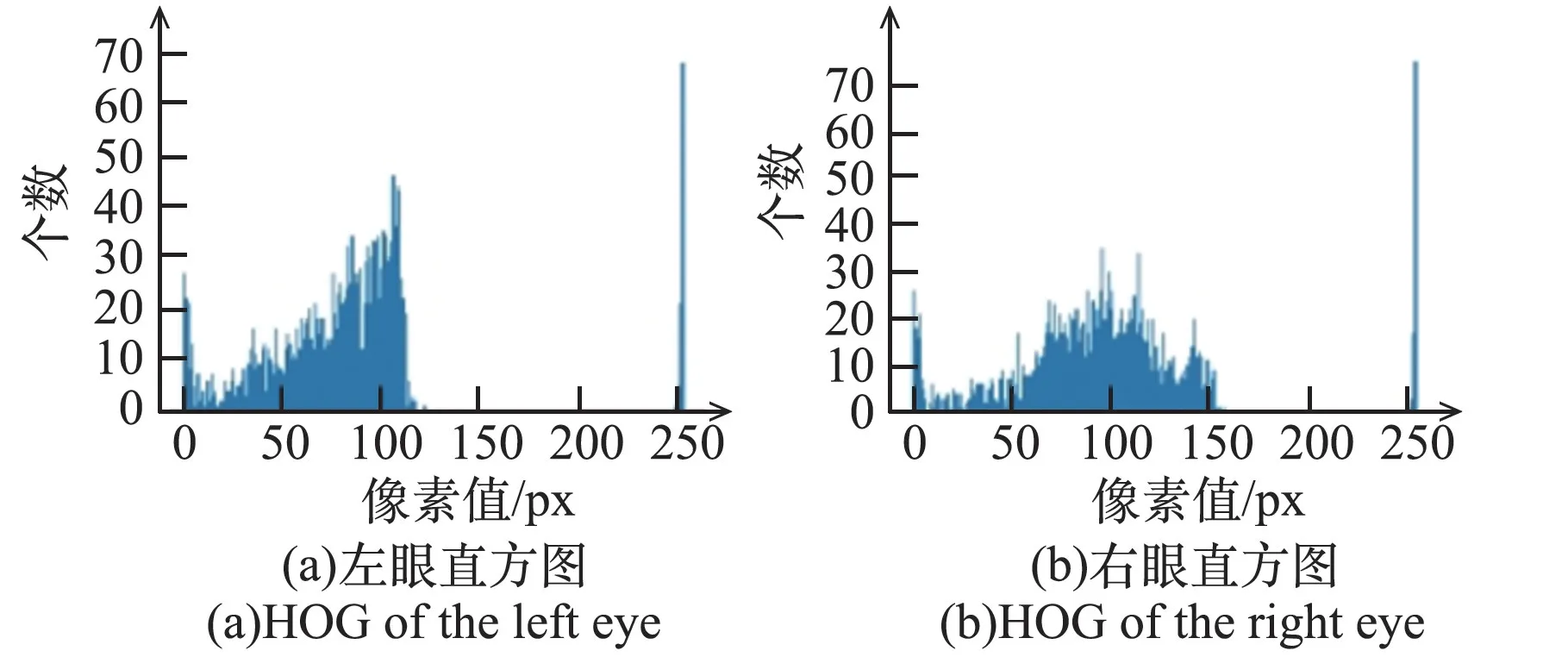
图2 左、右眼梯度直方图Fig.2 HOG of left and right eyes
由图2可知,图像的灰度级集中在低亮度范围,个别的像素点出现在255处,使用直方图均衡化将直方图变成均匀分布,增加像素之间灰度值的动态范围,对在图像中像素个数多的灰度值进行展宽,而对像素个数少的灰度值进行归并,增大图像对比度。左、右眼均衡化直方图如图3所示。

图3 左、右眼均衡化直方图Fig.3 Equalized HOG of left and right eyes
经过直方图均衡化后的左右眼图像如图4所示。由图可知,直方图均衡化后的图像增大了瞳孔与虹膜之间的对比度,有利于分辨瞳孔与眼角的相对位置,提高注视点定位的准确率。

图4 直方图均衡化后的左右眼图像Fig.4 Left and right eyes after HOG equalized
为了进一步消除肤色对实验结果的影响,采用阈值方法处理人眼图像。由双眼直方图可知,大部分像素集中在0~150区间,保持瞳孔像素大小不变的情况下,降低无关因素影响,本文采用截断阈值方法,截断阈值设置为80,图像中大于80的像素值设置为80,小于80的像素值保持不变。经过阈值截断后的左、右眼图像如图5所示。

图5 阈值截断后的左右眼图像Fig.5 Left and right eyes after threshold truncation
2.4 多流卷积神经网络模型设计
本文设计了一种多流卷积网络学习左右眼图像与144个注视点位置之间的映射关系。将预处理及特征提取后的大小为28 px×69 px的左、右眼图像输入如图6的卷积网络中,训练模型参数。将预处理及特征提取后的大小为36 px×60 px的左、右眼图像输入如图7的卷积网络中,训练模型参数。将4组人眼图像(36 px×60 px的左、右眼图像、28 px×69 px的左、右眼图像)分别输入对应网络中,利用全连接层融合,搭建如图7的多流卷积神经网络模型,在数据集上验证注视点位置估计准确率。所有的模型都在一台包含Intel i7核心CPU、16GB RAM的Linux操作系统下的计算机上进行训练,程序开发环境为Tensorflow,使用NVIDIA GEFORCE RTX 3080 GPU加速训练过程。本文设计的所有卷积神经网络训练时迭代次数均为400次,批尺寸为32个,选择交叉熵计算损失值,以及对稀疏数据表现更好的AdaDelta优化算法。

图6 输入为28 px×69 px的卷积神经网络模型Fig.6 CNN model with input of 28 px×69 px

图7 输入为36 px×60 px的卷积神经网络模型Fig.7 CNN model with input of 36 px×60 px
图中C1、C2、C3、C4为卷积层,M1、M2为池化层,F为Flatten层。卷积核大小/通道数为C1:3×3/64,C2:3×3/128,C3:3×3/256,C4:1×3/256,激活函数为ReLU。选择最大池化作为池化层的池化方式,池化核大小/通道数为M1:2×2/64,M2:2×2/128,激活函数为ReLU。输出层有144个神经元,对应144个注视点编号,激活函数为Softmax函数。
B型网络与A型网络比较,将C4卷积层换为C3卷积层,即卷积核大小为3×3,并加入池化层M3,输入M3的矩阵大小为2×8,输出通道数为256,输出矩阵大小为1×4。
调整图6中卷积神经网络(A型网络)和图7中卷积神经网络(B型网络的结构),形成如图8所示的多流卷积神经网络模型(以下简称AB型网络)。将28 px×69 px的左右眼图像输入A型网络,进行训练,在A型网络中Flatten层之前增加一个C4层,输出通道数为256,大小为2×8。将36 px×60 px的左右眼图像输入B型网络,进行训练,B型网络去掉M3层。将4个输出矩阵通道合并,Flatten层将三维矩阵压缩为一维向量,向量长度为2×8×1024=16 284,增加一个全连接层FC,神经元数为256,激活函数为ReLU,输出层输出144个预测注视点编号。
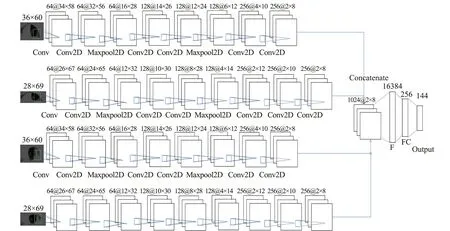
图8 多流卷积神经网络模型Fig.8 Multi-stream CNN model
3 结果与分析
3.1 注视点位置估计准确性分析
为了测试多流卷积神经网络对注视点位置估计的准确性,随机选择80%作为训练集训练模型,并将训练好的模型在测试集上验证。A型网络训练大小为28 px×69 px的左右眼图像、B型网络训练大小为36 px×60 px的左右眼图像、AB型网络训练左眼图像、AB型网络训练右眼图像以及AB型网络训练4个眼部图像的识别准确率如表1所示。

表1 不同输入图像在卷积模型下的识别准确率Table 1 The accuracy of classification with different input images and CNNs
由表1可知,像素大小为28 px×69 px的左、右眼图像在A型网络下的注视点位置估计准确率分为65.117%和64.184%,像素大小为36 px×60 px的左、右眼图像在B型网络下的注视点位置估计准确率分为65.916%和65.709%。将像素大小为28 px×69 px和36 px×60 px的左眼或右眼图像输入AB型网络,注视点位置估计准确率分别达到76.267%和68.222%,较单一输入时有些许提高,而将像素大小为28 px×69 px和36 px×60 px的左眼和右眼图像一同输入AB型网络时,注视点位置估计准确率能达到87.447%,有显著提高。
在数据集上采用其他的特征提取方法与分类方法,比较不同方法在本文数据集上的识别准确率,如表2所示。

表2 不同特征提取及分类方法在数据集上准确率Table 2 The accuracy comparison of different feature extraction and classification methods on the dataset
表2中,mHOG(multi-level Histogram of Gradient)是多尺度梯度直方图,按照Martinez等提出的方法划分图像,计算mHOG。将36 px×60 px的人眼图像分别划分为1×2、3×1、3×2、6×4区块,每个区块建立2×2个细胞单元,每个细胞单元对应9个梯度直方图,利用范数对每个区块归一化获得长度为2520的特征向量。采用主成分分析(Principle Component Analysis,PCA)将特征向量长度降至143,最后用随机森林分类(Random Forest Classifier,RFC)或决策树分类(Decision Tree Classifier,DTC)进行分类。Basilio等改变图像大小至6 px×10 px,计算归一化直方图作为特征,左右眼图像共获得120个特征,并采用支持向量机(Support Vector Machine,SVM)进行识别。提取mHOG时按细胞单元计算梯度直方图以及缩小图像大小的作用与卷积核相似,都是合并区域内像素值,降低特征维度,有利于分类器进行分类。由表2所知,提取多尺度直方图作为特征时,RFC较DTC具有更好的分类效果。提取整张图的直方图作为特征时,SVM分类效果最好。提取多尺度梯度直方图较提取整张图片梯度直方图,识别准确率更高。但提取数据集双眼的多尺度直方图即同一点像素值多次计算,使计算的数据量成倍增加,对于本数据集的图像,计算多尺度梯度直方图的数据量达到44.8 GB,计算机处理速度慢。因此,综合考虑计算速度和识别准确率的条件下,本文提取的多流卷积神经网络具有较大优势。
采用文本方法识别注视点位置,144个注视点从电脑屏幕的左上角至屏幕的右下角依次编号1~144,每列9个注视点,共16列。每个注视点所在的矩形块大小为3.322 cm×3.322 cm,对应的像素范围为120 px×120 px。
输入为36 px×60 px,28 px×69 px左右眼图像,采用多流卷积网络进行分类,144个注视点中有88.89%的注视点识别率在80%以上,验证了该算法在解决注视点估计问题上的有效性。
3.2 虚拟环境下空间机械臂目标定位仿真实验
空间目标定位实现步骤如图9所示。

图9 空间目标定位流程图Fig.9 Process of spatial target positioning
操作者首先注视空间环境主视图正投影中空间目标位置,利用固定在屏幕上方的照相机拍摄受试者照片,采用本文注视点估计算法获得此时空间目标所在矩形块标签1,计算空间机械臂坐标系下空间目标的二维坐标(x,z),如式(1)、(2)所示。其中每个矩形块对应空间机械臂坐标系,轴坐标范围为50,轴坐标范围为60。

式中%表示余数,//表示整除。然后,操作者注视空间环境左视图正投影中空间目标位置,采用上述方法获得此时空间目标矩形块标签2,计算空间机械臂坐标系下空间目标的二维坐标(y,z),如式(3)、(4)所示。每个矩形块边长对应空间机械臂坐标系下的轴坐标范围为50。

通过计算可知,=获得空间目标的三维坐标(x,y,z)。
空间机械臂模型各关节尺寸如图10所示。

图10 空间机械臂尺寸Fig.10 Size of the space manipulator
空间机械臂模型腰部长85 cm,在OpenGL空间坐标系下长34;大臂长470.0 cm,在OpenGL空间坐标系下长187;小臂长532.8 cm,在OpenGL空间坐标系下长212,腰部与大臂的连接处长28 cm,在OpenGL空间坐标系下长11。
空间机械臂3个关节角设置如图11所示。表示腰部平面法向量与垂直方向的夹角,表示大臂轴线与水平方向夹角,表示小臂轴线与大臂轴线的夹角。
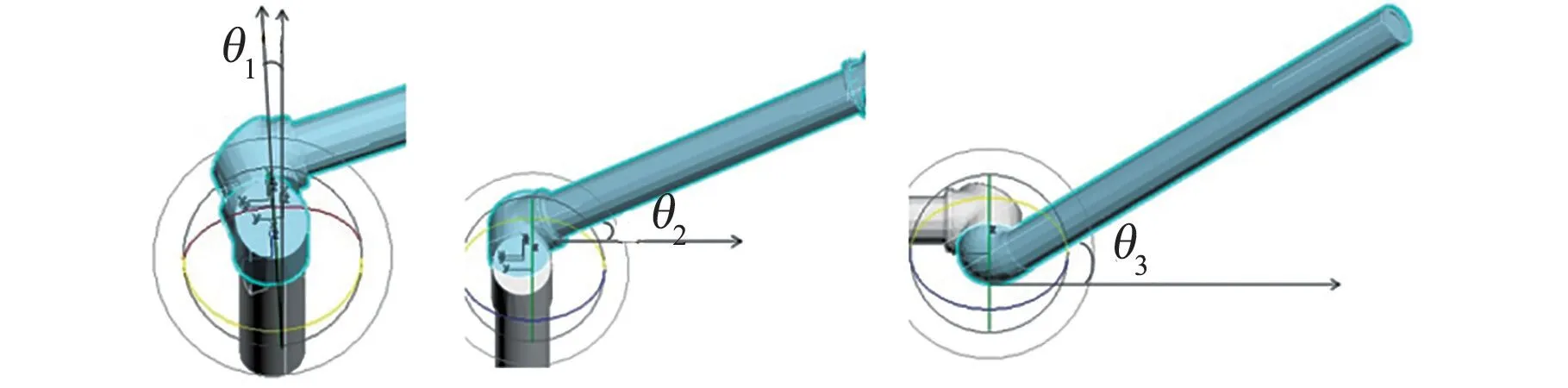
图11 空间机械臂关节角Fig.11 Joint angles of the space manipulator
在空间机械臂坐标系下,水平方向向右为轴正方向,垂直方向向上为轴正方向,垂直于电脑屏幕向内为轴正方向,空间机械臂与航天器连接处为坐标原点,计算空间机械臂模型小臂末端位置三维坐标。该空间机械臂的运动学变换矩阵见式(5)。
通过上述运动学变换矩阵和空间目标的三维坐标(,,)反解求出3个关节角大小见式(6)。
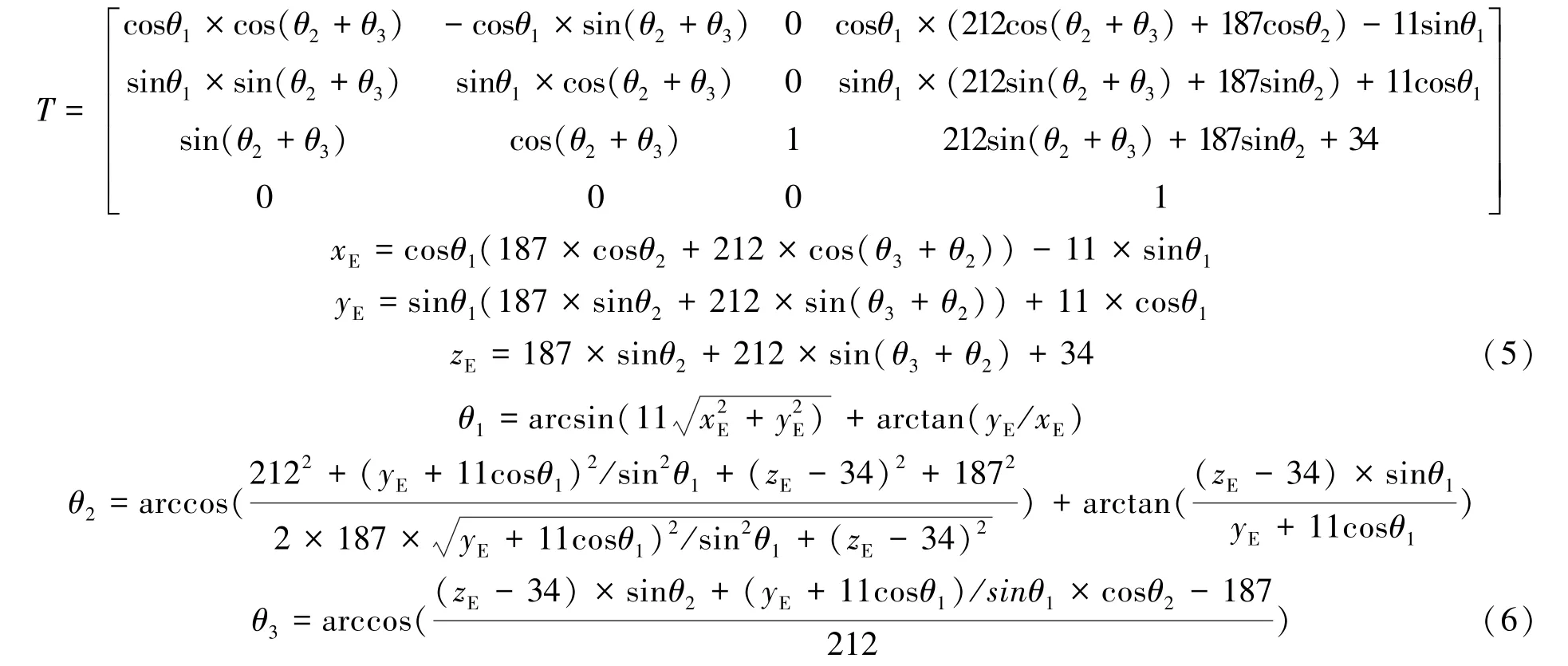
虚拟环境下的空间机械臂人机交互仿真软件系统由客户端、服务器端、网络通讯3部分构成。设计的虚拟环境下空间机械臂人机交互仿真平台客户端如图12所示。
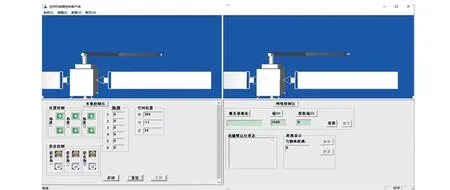
图12 虚拟环境下的空间机械臂人机交互仿真平台客户端Fig.12 The client of human-computer interaction simulation platform for the space manipulator in virtual environment
客户端的交互界面主要包括了本地控制台与网络控制台两个部分,其中左上角部分为本地控制台OpenGL绘制操作者要求的空间机械臂运动姿态,即显示出远端空间机械臂应该达到的运动姿态。网络控制台显示OpenGL绘制的虚拟远端空间环境即服务器端的空间环境与空间机械臂的运动姿态,使操作者了解远地端的空间机械臂的状态。
虚拟环境下空间机械臂人机交互仿真平台服务器如图13所示。

图13 虚拟环境下的空间机械臂人机交互仿真平台服务器Fig.13 The server of human-computer interaction simulation platform for the space manipulator in virtual environment
在网络控制台与服务器连接后,服务器端、网络控制台交互界面中机械臂位置、姿态与本地控制台交互界面中空间机械臂保持一致,在机械臂运行状态消息框中显示系统时间与角度变化,在服务器端计算空间机械臂末端手爪与空间目标之间的距离,传输到客户端并显示。
以图中实验为例,空间机械臂处于初始位置时,空间机械臂末端手爪距空间目标的距离为359.203,经过注视点定位得到空间目标三维坐标并反解调节3个关节角位置后,空间机械臂末端手爪距空间目标的距离为21.9101,大幅度缩小了空间机械臂末端手爪距空间目标的距离。最后鼠标点击按键微调关节角大小。由于空间目标的半径为10,当机械臂末端手爪坐标与目标中心距离小于设置值10时,抓取目标,并在客户端机械臂运行状态消息框中显示“物体已经抓取”。
在人机交互仿真平台服务器界面中,空间机械臂抓取目标如图14所示。
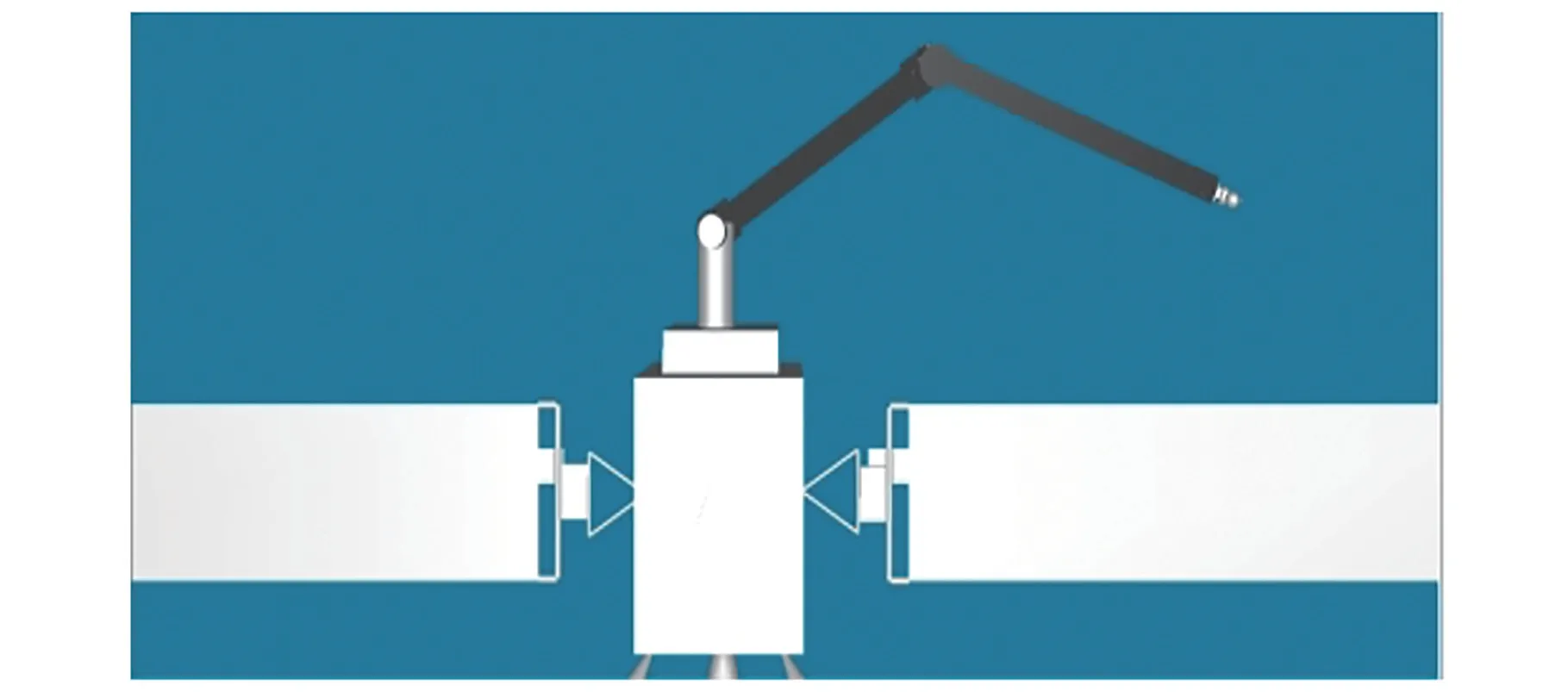
图14 空间机械臂抓取注视的空间目标Fig.14 The space manipulator grabs the gazed space target
造成空间目标定位误差的主要因素有2点:①利用注视点估计方法得到的注视点标签转换为坐标时,计算的是矩形块中心点坐标。若空间目标靠近矩形块顶点处,则计算误差较大,最大误差达46.368。②反解关节角时,省略了3个关节角的小数部分。
4 结论
本文提出了一种基于空间机械臂目标估计的注视点估计方法。
1)建立基于电脑屏幕注视点的人眼图像数据集,补充了电脑屏幕注视点估计数据集的空缺。对数据集中的图像进行预处理、提取图像的均衡化HOG作为特征。
2)设计一种多流卷积神经网络识别144个注视点位置,注视点识别准确率达到87.447%,其中,有88.89%的注视点识别率在80%以上。对本文方法与参考文献中算法在数据集上验证的识别准确率进行比较,实验结果表明了该算法在解决注视点估计问题上识别准确率高、运算速度快的优点。
3)搭建了一个虚拟环境下的空间机械臂人机交互仿真平台,利用本文提出的注视点估计方法,计算虚拟环境下的空间机械臂人机交互仿真平台中空间目标位置,进行了仿真验证。仿真实验表明,本文注视点估计方法能正确定位空间目标位置,反解计算空间机械臂关节角大小,大幅度缩小了空间机械臂末端手爪距空间目标的距离。为完成空间机械臂抓取空间目标提供可行性。
4)针对空间环境中空间目标位置未知的问题,本文采用单目照相机拍摄操作者照片,基于外观注视点估计及视觉转换的方法定位空间目标,避免了眼动仪对航天员增加的负担,具有创新性与实用性。
