基于双流结构和多知识点映射结构改进的深度知识追踪模型*
2022-08-25周东岱董晓晓顾恒年马宇驰
周东岱 董晓晓 顾恒年 马宇驰
基于双流结构和多知识点映射结构改进的深度知识追踪模型*
周东岱 董晓晓 顾恒年 马宇驰
(东北师范大学 信息科学与技术学院,吉林长春 130117)
目前,知识追踪已成为自适应个性化辅助学习的研究热点,而基于循环神经网络的深度知识追踪(Deep Knowledge Tracing,DKT)模型在知识追踪领域已取得了较好的效果。但是,DKT模型在融合领域特征时仍存在特征消减和知识点关联关系遗忘等问题,其精准性有待提高。为此,文章在梳理DKT模型融合领域特征相关研究现状的基础上,提出了一种基于双流结构和多知识点映射结构改进的深度知识追踪模型,并通过实验验证了此模型的精准性相较于原始DKT模型及其相关的改进模型有明显提升,并指出其在智慧学习环境下学生认知结构刻画和学习服务精准推荐方面具有的广阔应用前景。通过研究,文章旨在提升深度知识追踪的精准性并进一步助力自适应个性化学习的实现。
自适应学习;知识追踪;DKT模型;DKTDM模型
引言
知识追踪是自适应个性化辅助学习的研究热点,旨在评价学生的知识状态,预测学生下一时刻试题的正确回答概率[1]。传统的知识评价模型主要是项目反应理论(Item Response Theory,IRT)和贝叶斯知识追踪(Bayesian Knowledge Tracing,BKT)两种经典模型[2][3],研究发现前者存在参数估计的问题,而后者存在单一知识点建模、知识状态二元表征单一等问题[4][5][6]。Piech等[7]提出基于循环神经网络的深度知识追踪(Deep Knowledge Tracing,DKT)模型,以高维连续向量表示知识状态和时间动态,为解决上述问题提供了思路。
学生的答题结果是多因素影响的产物,可能会受知识点关系、答题次数和答题时间等领域特征的影响。原始DKT模型仅考虑问题标签和答题正误信息,虽然已有模型尝试将领域特征融入DKT模型,但实验结果表明融入后模型的精准性提升并不明显[8][9]。本研究认为,已有研究未关注领域特征在深度学习网络传递中存在的特征消减问题和知识点关联关系遗忘问题,这是导致模型精准性不足的原因。因此,本研究首先梳理深度知识追踪模型融合领域特征的研究进展;然后针对特征消减问题和知识点关联关系遗忘问题,提出基于双流结构和多知识点映射结构改进的深度知识追踪模型(Deep Knowledge Tracing Model with Dual-stream Structure and Multi-knowledge Points Mapping Structure,DKTDM),并验证其精准性;最后,本研究对模型的应用前景进行展望,以期提升深度知识追踪的精准性并进一步助力自适应个性化学习的实现。
一 研究现状
DKT模型是一种基于循环神经网络的深度知识追踪模型,它通过将交互序列={1,2, …,x}[其中,t=(qa)表示学生回答问题q的正误情况,a∈{0,1},0表示错误,1表示正确]输入循环神经网络,来预测下一时刻试题的正确回答概率(a+1|,q+1)。原始DKT模型的输入只有问题标签、答题正误这两种信息,而忽视了领域其他特征对预测结果的作用,其精准性有待提高。为此,研究者尝试引入更多的领域特征来提高模型预测的精准性。例如,Zhang等[10]提出了基于特征工程的深度知识追踪(DKT with Feature Engineering,DKT-FE)模型,采用栈式自编码器将数据集中的3种特征(响应时间、第一行为、尝试次数)降维后输入DKT模型。Yang等[11]结合决策树,提出了基于分类回归树的深度知识追踪(DKT-Classification and Regression Tree,DKT-CART),并采用12种特征构建决策树来预测学生的答题结果,然后与真实答题结果拼接后一起输入原始模型,但这12种特征并未直接参与网络训练,故决策过程会损失特征中隐含的关键领域信息。实验数据表明,上述融合领域特征的改进DKT模型相较于未融合领域特征的原始DKT模型在精准性上提升不明显,如Zhu等[12]、Rum等[13]发现深度学习网络在映射和投影之后不能确保利用了所需要的特征执行任务。基于以上分析,本研究认为已有DKT模型在融入领域特征时领域知识没有被有效传递,即领域特征在从网络底层向高层传递的过程中存在关键信息消减的特征消减问题。
此外,由于循环神经网络自身会遗忘长期依赖关系,当输入序列过长时,循环神经网络就会随之出现遗忘问题,即新的内容输入后会遗忘之前的内容[14]。在知识追踪过程中,一道试题可能关联多个知识点,知识点间存在的关联关系是循环神经网络隐藏层捕捉的关键信息之一。当时间跨度很大时,可能会出现知识点跨度也很大的情况,前期的知识点间的关联关系(长期依赖关系)就会被遗忘,导致出现错误关联和预测结果波动现象,影响预测的精准性[15]。
综上,本研究从缓解特征消减和抑制关联关系遗忘出发,构建了一种新的深度知识追踪模型,重点关注两方面内容:①改进特征融合方法,提出一种双流结构来缓解特征消减;②构建多知识点映射结构,抑制知识追踪过程中知识点关联关系遗忘。
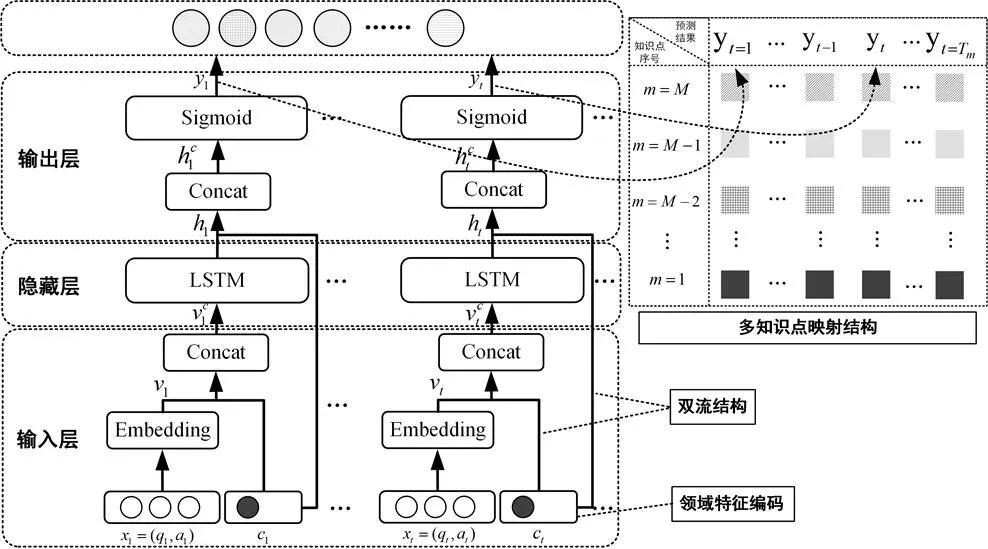
图1 DKTDM模型的整体框架
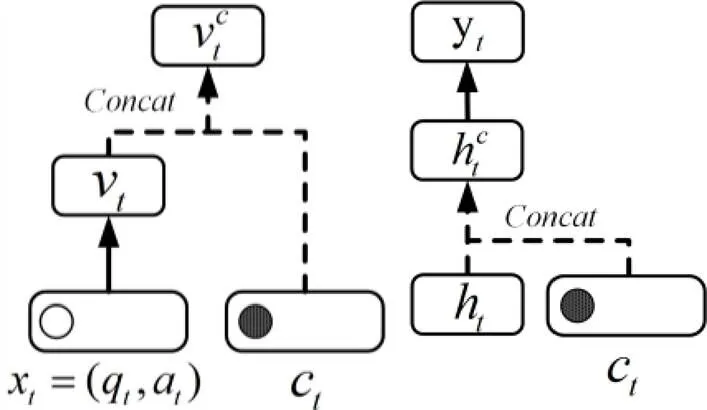
图2 输入层融合过程图3 输出层融合过程
二 DKTDM模型框架的构建
1 DKTDM模型整体框架
根据前文研究现状的分析,为解决特征消减和知识点关联关系遗忘的问题,本研究在原始DKT模型的基础上构建了DKTDM模型,其整体框架如图1所示。DKTDM模型由输入层、隐藏层和输出层组成,其中输入层设计了双流结构(Dual-stream Structure),实现领域特征的两次融入;输出层设计了多知识点映射结构(Multi-knowledge Points Mapping Structure),将输出结果记录下来参与损失计算。
①输入层:共有两部分输入。第一部分是原始DKT的答题交互x,表示作答问题的正误情况,x∈{0, 1},其中表示知识点个数。学生回答问题如果正确,则在前长度编码上的数值索引位上置1,反之则在后长度编码上的数值索引位上置1,接着将x进行嵌入表示,得到维度为的嵌入表示向量v。第二部分是本模型新融入的数据集中的领域特征,对其采用one-hot编码得到维度为的领域特征向量c。将嵌入表示向量v与领域特征向量c拼接,得到融合特征向量vc,其维度为,如公式(1)所示。
vc=(v,c)公式(1)
②隐藏层:本模型采用LSTM作为隐藏层单元,隐藏层维度为。通过内部的门控机制,可以筛选、计算当前时刻的隐藏层输入即融合特征向量vc和上一时刻的隐藏层状态h,得到当前时刻隐藏层输出向量h,如公式(2)所示。其中,是维度为×的当前时刻隐藏层输入权重矩阵,是维度为的上一时刻隐藏层状态权重矩阵,是维度为的偏置向量。
h(vc+Uh+b) 公式(2)
③输出层:将由输入层恒等映射而来的领域特征向量c与h拼接,得到融合向量hc,其维度为然后输入函数得到预测结果y,如公式(3)所示。其中,()=1/(1+e),W是维度为×的输出层权重矩阵,b是维度为的偏置向量,和均为超参数
y=Sigmoid(Whc+b公式(3)
2 DKTDM模型构建的关键细节
为克服已有DKT模型存在的特征消解和知识点关联关系遗忘问题,本研究在输入层设计了双流结构,以通过领域特征的高层传播和强化来抑制特征消减问题;同时,在输出层设计了多知识点映射结构,以通过补充损失计算正则项的方式来缓解知识点关联关系遗忘问题。
(1)双流结构抑制特征消减问题
已有DKT模型融合领域特征的通常做法是将特征编码后直接在输入层融入,然而领域特征向网络高层传播时存在关键信息消减的问题。针对该问题,本研究将领域特征向量c分别在输入层、输出层融合,其融合过程分别如图2、图3所示。领域特征向量c一方面在输入层融入;另一方面经过恒等映射后,在输出层与h拼接,得到融合向量hc,如公式(4)所示。
hc=(h,c)公式(4)
领域特征在输入层融合的数据流(图2中的虚线)与输出层再次融合的数据流(图3中的虚线)共同构成双流结构。基于残差网络原理,双流结构能够有效缓解特征在网络结构中由低层向高层传递时因网络梯度和退化导致的特征信息丢失问题[16]。
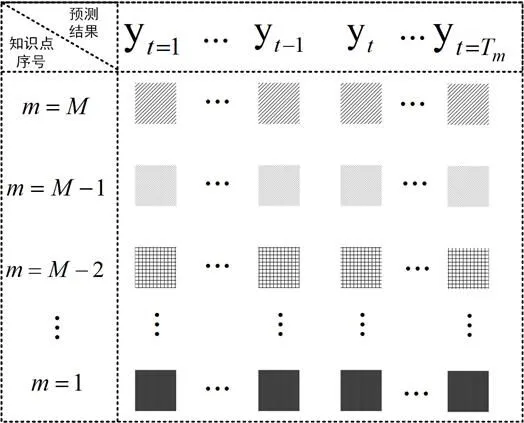
图4 多知识点映射结构
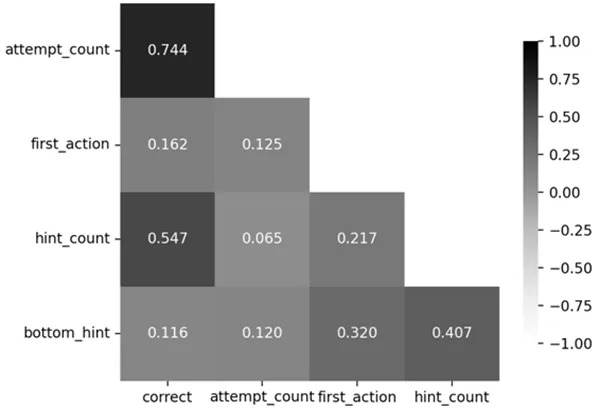
图5 特征关联分析图
(2)多知识点映射结构缓解知识点关联关系遗忘问题
本研究对知识点关联关系遗忘问题的处理分两步进行:①主动捕捉和保存知识点关联关系;②将该关系以变化量的形式再次加入训练。针对这两个步骤的内容,本研究设计了多知识点映射结构,如图4所示。其中,行表示在不同时刻下第m个知识点节点的预测结果,列表示在t时刻下不同知识点节点的预测结果,通过这种映射结构保存了不同时刻下不同知识点的预测结果,间接实现了知识点关联关系的捕捉和保存,从而缓解了知识点关联关系遗忘的问题。
为了将保存的知识点关联关系以变化量的形式再次加入训练,本研究按照公式(5)、公式(6)、公式(7),计算了变化趋势量k、绝对变化量k和平方变化量k。其中,T表示学生答题交互次数,M表示知识点数量。将上述三个变化量加入损失函数,连同原DKT损失函数共同计算损失,修正输出结果。加入变化量的DKTDM损失函数如公式(8)所示。其中,μμ和μ分别是与三个修正量对应的超参数。
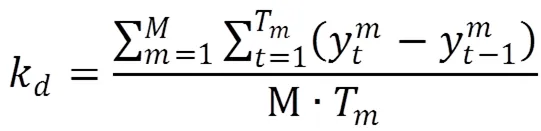
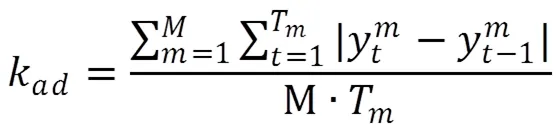
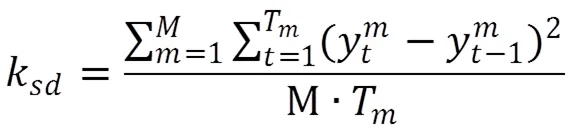
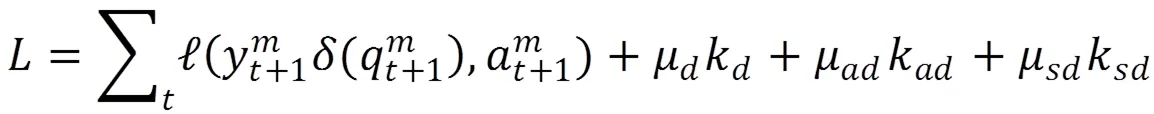
三 实验验证
为检验DKTDM模型的精准性与有效性,本研究从两个方面开展了相关实验:①对比实验,将DKTDM模型与主流的DKT模型在不同公开数据集上的精准性表现进行对比;②验证实验,通过消融实验验证DKTDM模型双流结构与多知识点映射结构改进的有效性。
1 数据集
目前,知识追踪领域的主流模型主要采用如表1所示的三个公开数据集进行精准性评估和比较,因此本研究也基于这三个数据集来验证DKTDM模型的精准性。

表1 数据集统计表
1ASSISTment2009:https://sites.google.com/site/assistmentsdata/home/assistment-2009-2010-data/skill-builder-data-2009-2010.
2ASSISTment2015:https://sites.google.com/site/assistmentsdata/home/2015-assistment-skill-builder-data.
3Statics2011:https://pslcdatashop.web.cmu.edu/ DatasetInfo?datasetId=507.
本研究以ASSITment数据集中的尝试次数(学生尝试回答一道题的次数)特征为例开展DKTDM模型特征融合实验,以验证其改进优势。本研究发现,从统计数据分析角度来说,尝试次数和答题结果存在较大关联,特征关联分析图如图5所示,可以看出:尝试次数attempt_count与答题结果correct的关联度为0.744,相较于其他特征(如提示次数hint_count)与correct的关联度最高;从认知规律角度来说,多次尝试后答题正确率理论上也会明显高于初次尝试的结果。
2 参数设置
本实验采用了数据集中提供的训练、验证和测试数据,具体步骤为:在训练集上训练模型→根据验证集结果调整模型参数→在测试集上评估模型的精准性。优化器采用Adam optimizer,学习率Learning rate设置为0.002。实验结果评估使用ROC曲线下的面积(Receiver Operation Characteristic,AUC)和准确度(Accuracy,ACC)两种深度知识追踪精准性的主要衡量指标。
3 对比实验
本实验探索了三种不同批处理大小(Batch Size,记为b)下的精准性,包括训练、测试AUC值和测试ACC值的比较。图6列出了DKTDM模型在ASSISTment2009上的精准性评估结果,可以看出:当批处理大小为8时,DKTDM模型在数据集上的表现最佳。经过多组实验,测试AUC平均值达到0.827,测试ACC平均值达到0.758。
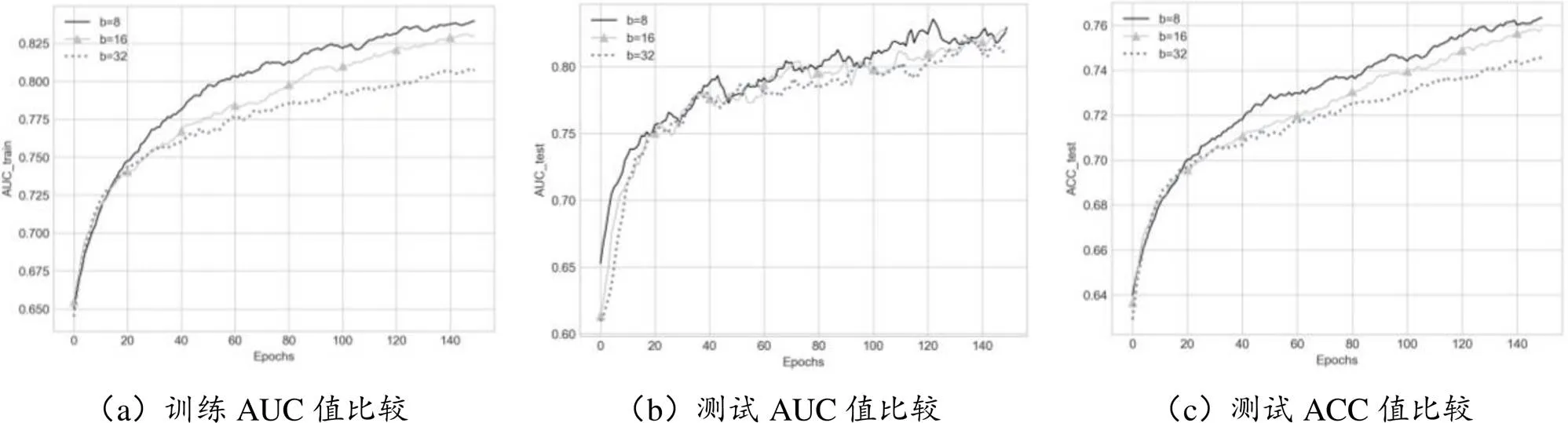
图6 不同批处理大小下的精准性评估结果
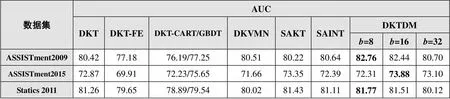
表2 主流模型AUC对比表

表3 主流模型ACC对比表
本研究对DKTDM模型与几种先进的深度知识追踪领域模型在三个公开数据集下的测试AUC、ACC值进行比较,结果如表2、表3所示(每个数据集的最佳结果都加粗表示)。其中,DKT是深度知识追踪领域的开篇之作;DKT-FE采用栈式自编码器,将数据集中的3种特征(响应时间、第一行为、尝试次数)降维后输入DKT模型;DKT-CART/GBDT采用决策树模型处理多种特征得到预测结果后与真实结果拼接,之后输入模型中进行预测;DKVMN是一种基于记忆增强网络和键值矩阵的深度知识追踪模型[17];SAKT采用自注意力机制,重新分配学生答题序列上的权重[18];SAINT是一种基于Transformer的深度知识追踪模型,采用深度自注意力机制捕捉问题和答题结果间的复杂关系[19]。上述主流模型,都是在深度知识追踪领域和融合领域特征方面具有代表性的模型。
通过对比,本研究发现:相较于DKT、DKT-FE、DKT-CART/GBDT和DKVMN,DKTDM模型的精准性提升明显,说明双流结构能够更好地融合领域特征,多知识点映射结构能够缓解知识点关联关系遗忘,共同提高了预测的精准度;相较于新近的SAKT、SAINT,DKTDM模型在精准性的表现依然具有优势。
4 验证实验
本研究对DKTDM模型进行了消融实验,以验证DKTDM模型在解决原始DKT模型特征消减和知识点关联关系遗忘问题方面的有效性。消融实验对DKTDM模型、带有双流结构的DKT模型(DKT-DUAL)、带有多知识点映射结构的DKT模型(DKT-Mul.K)和原始DKT模型的表现进行了对比。通过图7(a)中AUC值的比较可以看出,相较于DKT,DKT-DUAL模型能够充分利用、拟合领域特征,DKT-Mul.K模型能够很好地发掘、拟合答题序列中隐含的复杂知识点关系并抑制遗忘,两个模型的精准性均得到了提升;而与DKT-DUAL、DKT-Mul.K相比,DKTDM模型的精准性更高。通过图7(b)中Loss值的比较可以看出,与DKT-DUAL、DKT-Mul.K、DKT相比,DKTDM模型随着回合数增加在损失收敛上的表现最好。
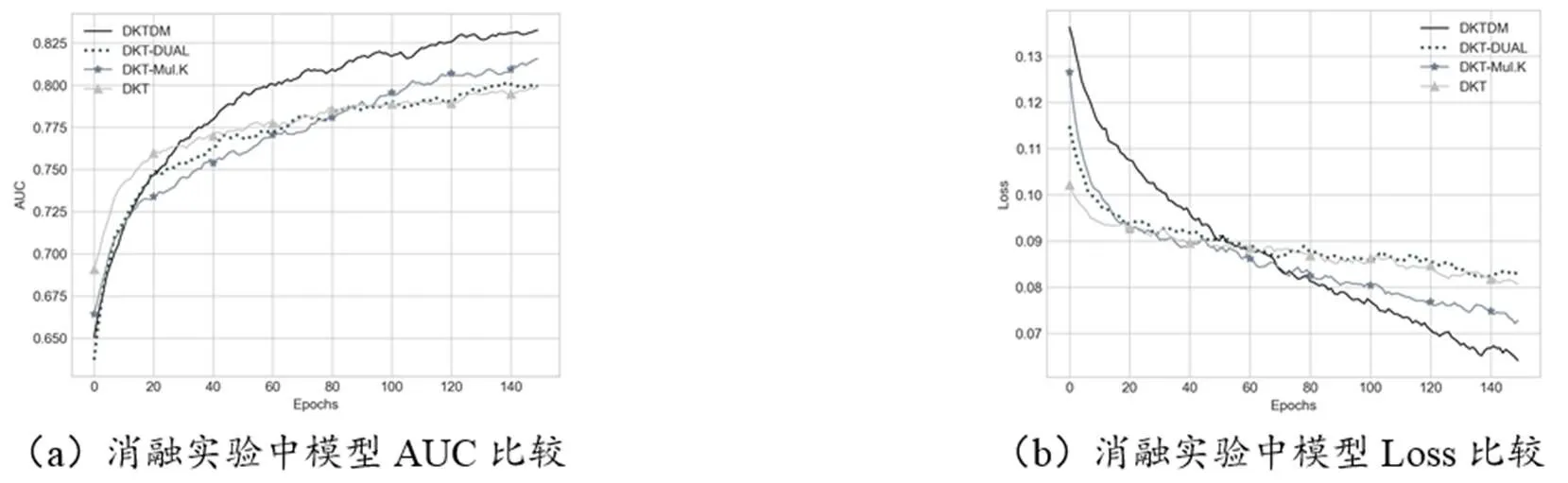
图7 DKTDM、DKT-DUAL、DKT-Mul.K和DKT的表现对比
四 结语
深度知识追踪模型通过追踪学生的知识状态来预测学生的认知水平,是评估学生认知水平的有效手段。针对现有DKT模型存在的特征消减问题和知识点关联关系遗忘问题,本研究提出了DKTDM模型,并聚焦于解决两个问题:①构建了一种将领域特征分别在输入层和输出层融合的双流结构,解决了已有DKT模型融入领域特征时存在的特征消减问题;②在DKT输出层构建了一种多知识点映射结构,通过补充损失计算正则项的方式来缓解知识点间关联关系遗忘问题。实验结果表明,本研究针对上述两个问题的改进是有效的,且提出的DKTDM模型的精准性明显优于原始DKT模型及其相关的改进模型。
随着新一代人工智能技术与教育教学深度融合,未来精准的深度知识追踪对于加快推进教育教学数字转型和智能升级具有重要的作用,主要体现为:①认知结构刻画方面,结合深度知识追踪模型与学科知识图谱,能够精准刻画学生的知识状态、知识结构等特征,实现学生认知结构的可视化表征,进而支撑挖掘学生的认知发展模式,为后续学习服务的精准推荐奠定基础。②学习服务精准推荐方面,在学生认知结构刻画和发展模式挖掘的基础上,结合学科知识图谱,对学生学习过程中存在的问题进行溯源,进而为其制定适切的干预策略。在此基础上,根据干预策略为学生推荐个性化的学习路径或学习资源并检验其效果,构建“问题诊断—溯源归因—干预推荐”的闭合回路,为学生达成个性化学习目标提供精准服务。
[1]卢宇,王德亮,章志,等.智能导学系统中的知识追踪建模综述[J].现代教育技术,2021,(11):87-95.
[2]Wyse A E. R.J.DE AYALA(2009)The theory and practice of item response theory[J]. Psychometrika, 2010,(4):778-779.
[3]Baker D R S J, Corbett A T, Aleven V. More accurate student modeling through contextual estimation of slip and guess probabilities in Bayesian knowledge tracing[A]. Proceedings of the 9th International Conference on Intelligent Tutoring Systems[C]. Berlin: Spinger, 2008:406-415.
[4]Xiong X, Zhao S, Van Inwegen E G, et al. Going deeper with deep knowledge tracing[OL].
[5]Chen L, Min C. A comparisons of BKT, RNN and LSTM for learning gain prediction[A]. Artificial Intelligence in Education[C]. Cham: Springer, 2017:536-539.
[6]戴静,顾小清,江波.殊途同归:认知诊断与知识追踪——两种主流学习者知识状态建模方法的比较[J].现代教育技术,2022,(4):88-98.
[7]Piech C, Bassen J, Huang J, et al. Deep knowledge tracing[A]. Proceedings of the 28th International Conference on Neural Information Processing Systems[C]. Cambridge: MIT Press, 2015:505-513.
[8]Wang Z, Feng X, Tang J, et al. Deep knowledge tracing with side information[A]. Artificial Intelligence in Education[C]. Cham: Springer, 2019:303-308.
[9]Yeung C K, Yeung D Y. Incorporating features learned by an enhanced deep knowledge tracing model for STEM/Non-STEM job prediction[J].International Journal of Artificial Intelligence in Education, 2019,(3):317-341.
[10]Zhang L, Xiong X L, Zhao S Y, et al. Incorporating rich features into deep knowledge tracing[A].Proceedings of theFourth ACM Conference on Learning @ Scale[C]. New York: Association for Computing Machinery, 2017:169-172.
[11]Yang H, Cheung L P. Implicit heterogeneous features embedding in deep knowledge tracing[J]. Cognitive Computation, 2018,(1):3-14.
[12]Zhu X, Li T, De Melo G D. Exploring semantic properties of sentence embeddings[A]. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics[C]. Stroudsburg: Association for Computational Linguistics, 2018:632-637.
[13]Rum D E, Hin G E, Will R J. Learning representations by back-propagating errors[J]. Nature, 1986,323:533-536.
[14]Kemker R, McClure M, Abitino A, et al. Measuring catastrophic forgetting in neural networks[A]. Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence[C].California: AAAI Press, 2018:3390-3398.
[15]Yeung C K, Yeung D Y. Addressing two problems in deep knowledge tracing via prediction-consistent regularization[A].Proceedings of the Fifth Annual ACM Conference on Learning at Scale[C]. New York: Association for Computing Machinery, 2018:1-10.
[16]He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[A]. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)[C].New York: IEEE Computer Society, 2016:770-778.
[17]Zhang J, Shi X, King I, et al. Dynamic key-value memory networks for knowledge tracing[A].Proceedings of the26th International Conference on World Wide Web[C].Republic and Canton of Geneva: International World Wide Web Conferences Steering Committee, 2017:765-774.
[18]Pandey S, Karypis G. A self-attentive model for knowledge Tracing[OL].
[19]Choi Y, Lee Y, Cho J, et al. Towards an appropriate query, key, and value computation for knowledge tracing[A]. Proceedings of the Seventh ACM Conference on Learning @ Scale[C].New York: Association for Computing Machinery, 2020:341-344.
Deep Knowledge Tracing Model Improved with Dual-stream Structure and Multi-knowledge Points Mapping Structure
ZHOU Dong-dai DONG Xiao-xiao GU Heng-nian MA Yu-chi
At present, knowledge tracing has become the research hotspot of adaptive personalized assisted learning, and the deep knowledge tracing (DKT) model based on the recurrent neural network has achieved good results in the field of knowledge tracing. However, the DKT model still has problems such as feature elimination and forgetting knowledge point association relationships when fusing domain features, and its accuracy needs to be improved. Therefore, on the basis of combing the research status related to fusing domain features of the DKT model, this paper proposed a deep knowledge tracing model with dual-stream structure and multi-knowledge points mapping structure (DKTDM), and through experiments verified that its accuracy was significantly improved compared to the original DKT model and its related improved models. In addition, it was pointed out that its application in characterizing students’ cognitive structure and accurate recommendation of learning services in smart learning environments would be promising.Through the study, this paper aimed to improve the accuracy of deep knowledge tracing, and contribute more to the realization of adaptive learning.
adaptive learning; knowledge tracing; DKT model; DKTDM model

G40-057
A
1009—8097(2022)08—0111—08
10.3969/j.issn.1009-8097.2022.08.013
本文为国家自然科学基金面上项目“基于深度学习的自适应学习系统关键技术研究”(项目编号:61977015)、吉林省自然科学基金项目“基于深度学习的学习者知识水平精准评估技术研究”(项目编号:20200201298JC)、国家自然科学基金青年项目“融合知识结构与试题属性的概率知识追踪关键技术研究”(项目编号:62107008)、吉林省科技发展计划项目“智能化网络学习空间构建关键技术研究”(项目编号:20200602053ZP)的阶段性研究成果。
周东岱,教授,博士,研究方向为教育信息科学与技术的理论、方法与关键技术,邮箱为ddzhou@nenu.edu.cn。
2021年11月20日
编辑:小时
