顾及小目标特征的视频人流量智能统计方法
2022-08-25张天奕谢亚坤李闯农李维炼
朱 军 ,张天奕 ,谢亚坤 ,张 杰 ,李闯农 ,赵 犁 ,李维炼
(1.西南交通大学地球科学与环境工程学院,四川 成都 611756;2.四川豪格远景市政建设有限公司,四川 成都610036)
智能视频监控设备作为安防的重要手段而广泛存在于商场、医院、学校、景点等公共场所.人流量统计是智能视频监控的重要研究内容之一,对于智能安防、智慧旅游、灾后救援、交通规划等领域的研究具有重要价值[1-3].
在机器学习技术出现之前,监控视频中的人流量统计多由人工完成,但这不仅需要耗费大量的人力物力,且视频中的大量信息不能得到很好理解.随着计算机视觉和机器学习技术的不断突破,基于浅层学习的人流量统计方法不断涌现[4-6].由于此类方法采用的是人工设计和提取特征,特征冗余度较高,且无法智能地提取有用信息,导致统计精度较低.而构建深层次神经网络则可以通过自动学习的方式有效提取图像深层次特征,进一步解决以上问题.
随着人工智能时代的到来,基于深度学习的人流量统计方法不断被提出[7-8].其与传统方法的最大不同是它能从数据中自动学习得到特征,不需要人工设计和提取特征,且无需进行前景分割.Zhang等[9]通过卷积神经网络(convolutional neural network,CNN)模型生成密度图的方式实现了跨场景计数,相比于手工设计特征的方式具有高效性和鲁棒性.虽然此类方法不需要检测每个行人,可以直接通过回归或对人群密度图积分的方式得到人数,但也正是因为无法获得每个行人的具体信息,使得无法进行后续行人轨迹分析等方面的研究.近年来,由于深度学习在目标检测任务中不断取得突破,基于深度学习检测的人流量统计方法也相继被提出[10-11].曹诚等[12]提出了一种基于卷积神经网络的视频行人分析方法,实现了监控区域中的人流量统计,但当行人之间相互遮挡时会导致漏检.张天琦[13]基于SSD(single shot multibox detector)算法和 KCF (kernel correlation filter)算法对人头目标进行检测和跟踪,进而分析目标轨迹实现了双向计数,其通过检测人头目标有效解决了行人之间的遮挡问题,但由于该方法采取了从行人正上方检测头部的策略,使得算法的应用场景在很大程度上受到了限制.尽管上述方法取得了一定效果,但由于视频中行人姿态、尺度各异,且存在不同程度的遮挡情况,使得现有方法在不同场景下的人流量统计准确度较低.
为解决上述问题,本文拟开展顾及小目标特征的视频人流量智能统计方法研究.通过研究用于小目标检测的Faster R-CNN (Faster region-convolutional neural network)改进算法、探讨基于轨迹预测的目标跟踪技术、设计双向人流量智能统计算法,并构建实验环境开展实验分析,期望实现视频人流量精确智能统计.
1 视频人流量智能统计方法
1.1 总体研究思路
视频人流量智能统计的研究思路如图1所示,主要包括用于小目标检测的Faster R-CNN改进算法、基于轨迹预测的目标跟踪、双向人流量智能统计.
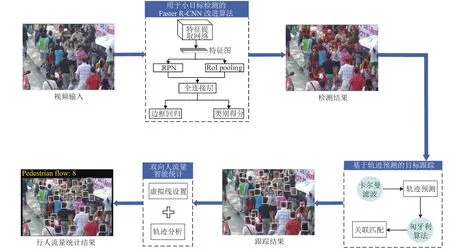
图1 总体框架Fig.1 Overall framework
1.2 用于小目标检测的Faster R-CNN改进算法
Faster R-CNN[14]在通用目标检测领域表现优异,对于常规目标来说,其检测精度高且速度较快.但由于本文所选择的检测对象为人头目标,其在图像上的尺寸较小,而Faster R-CNN对于小目标检测任务精度受限[15].因此,针对人头目标,本文提出一种用于小目标检测的Faster R-CNN改进算法,算法框架如图2所示.
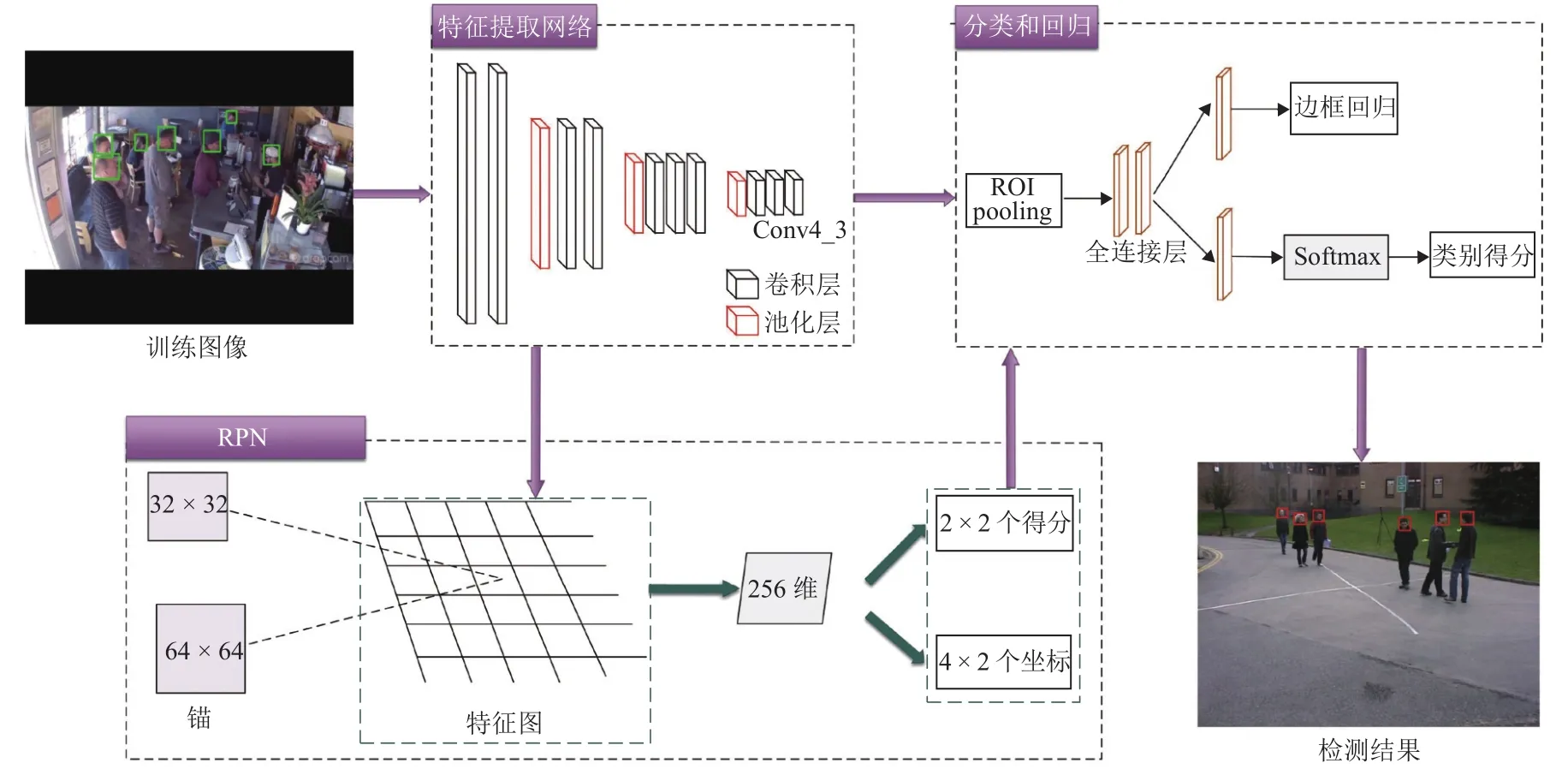
图2 Faster R-CNN改进算法框架Fig.2 Framework of improved Faster R-CNN algorithm
CNN不同深度对应不同层次的特征,深层网络虽然能够较好地表示图像的语义特征,但同时也会忽略图像的纹理、边缘等细节特征,而浅层网络能够很好地表示这些细节特征[16].对于常规目标来说,使用深层特征图能够提取到较为丰富的语义特征,进而提高算法的鲁棒性,但人头目标与常规目标相比,其信息量少且在图像上占比较小,对应区域像素反映的信息量有限,在语义特征较难提取的情况下再使用深层特征图更会使得细节信息缺失.因此,本文将使用VGG16[17]中的Conv4_3层代替Conv5_3层输入区域建议网络(region proposal network, RPN)中生成候选区域(regions of interest, RoI),既能减少网络复杂度,又可弥补小目标在深层特征上细节信息的缺失.
Faster R-CNN中的RPN针对需要进行检测的通用目标设置了3种尺度(128, 256, 512)、3种宽高比(1∶1, 1∶2, 2∶1)共 9 种不同大小的锚(Anchor),但由于人头目标在图像上占比较小,因此这种设置并不适用于小尺度的人头目标.本文在RPN的基础上根据训练数据集中人头目标的宽高比特性,将Anchor的尺度调整为(32, 64),且由于人头目标多为正方形,因此只设定一种宽高比例1∶1,这两种尺度的Anchor既能覆盖数据集中大部分的人头目标,且由于产生的Anchor数量与原来相比大幅减少,导致后续需要进行坐标回归和分类的Anchor数量降低.图3为改进的 Anchor与原 RPN中的 Anchor在Brainwash数据集[18]中的对比图,其中红色方框代表改进后的Anchor,尺寸分别为32 × 32和64 ×64,蓝色方框代表原RPN中1∶1比例的Anchor,尺寸分别为 128 × 128、256 × 256 和 512 × 512.由图3可以看出:原Anchor(蓝色框)由于尺度过大并不适用于人头目标,而改进后的Anchor(红色框)能够对人头目标实现更为准确的覆盖.

图3 多尺度下Anchor尺寸对比Fig.3 Contrast of multi-scale anchor size
1.3 基于轨迹预测的目标跟踪
基于轨迹预测的目标跟踪算法[19]主要包含轨迹预测和数据关联两部分,如图4所示,首先利用卡尔曼滤波预测出每个目标在下一帧的位置,进而通过匈牙利算法将实际检测位置与预测位置进行对比关联.详细阐述如下.
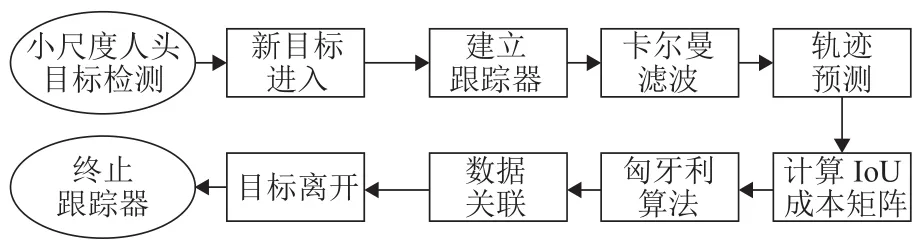
图4 目标跟踪算法流程Fig.4 Flow chart of object tracking algorithm
卡尔曼滤波用于预测目标轨迹状态,其将目标的帧间运动近似为线性运动,并认为目标间、目标与相机间运动独立,那么运动目标的状态可以用式(1)表示.

式中:u、v分别为目标在水平和竖直方向上的中心坐标;s为目标的面积;r为目标的长宽比;m、n分别为目标在水平和竖直方向上的运动速度;o为目标的变化比率.
若检测框关联到目标后,用检测框更新目标状态,同时速度分量利用卡尔曼滤波进行优化求解;若目标没有与检测框相关联,则用线性速度模型对目标位置进行预测.
匈牙利算法用于前后帧数据关联.首先,通过运动模型得到前一帧中每个待跟踪目标的预测框;其次,计算当前帧中每个目标的检测框和所有预测框之间的交并比(intersection over union,IoU)作为成本矩阵;最后,使用匈牙利算法对矩阵进行优化求解.此外,应拒绝检测框与目标预测框重叠小于阈值的分配,本文实验中阈值取值为0.3.
当某个目标的检测框和所有现有目标预测框之间的IoU都小于阈值时则认为进入新的待跟踪目标,此时使用检测框信息初始化新目标的位置信息.若连续T帧没有检测框和目标预测框的IoU匹配,则认为目标消失,本文实验中T取值为1.这种基于轨迹预测的在线跟踪方式能够解决目标前后帧运动过快以至于匹配失败的问题,将下一帧预测的轨迹状态与检测目标进行关联,使得目标跟踪成功的几率大大提高.
1.4 双向人流量智能统计
传统人流量统计方法主要基于单线法实现,但单线法存在无法灵活设定目标区域、无法准确判断行人运动方向等问题,为解决上述问题,本文提出一种双向人流量智能统计方法.相比于传统单线法,通过双虚拟线对需要监视的目标区域进行准确设定,将复杂背景干扰因素排除在目标区域之外,为目标检测和跟踪创造有利条件,提高人流量统计精度,算法流程如图5所示.
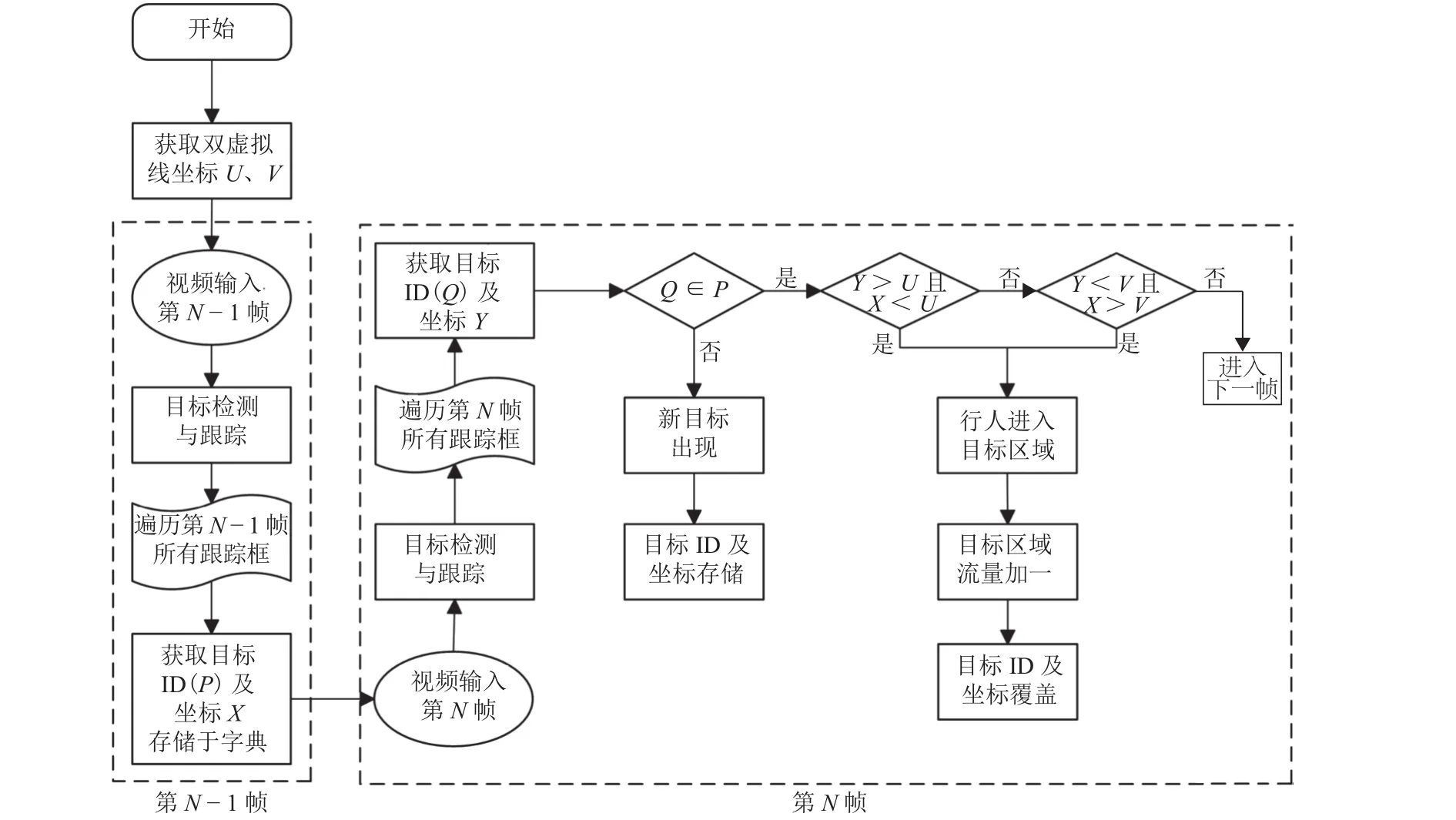
图5 双向人流量智能统计算法流程Fig.5 Flow chart of intelligent statistic algorithm of bidirectional pedestrian flow
首先,预先设定虚拟线并获取其坐标;其次,经过目标检测和跟踪,第N-1帧和第N帧的每个目标都被设定了唯一ID,将第N-1帧的目标以ID为键、坐标为值存储于字典中;再次,遍历第N帧中的所有目标并依次判断其是否在字典内,如不存在,则在字典中增加一条记录,如存在,则判断目标坐标和字典中相同ID的目标坐标与虚拟线坐标之间的大小关系,具体判断过程视实际场景而定;最后,遍历所有视频帧并重复上一步骤,完成目标区域内的人流量统计.
在实际视频场景中利用双虚拟线进行人流量统计的过程如图6所示,在视频中预先设置两条虚拟计数线,其与视频左右边界围成的区域即为要监测的目标区域.如1号目标在第N-1帧中的坐标小于计数线1的坐标,而在第N帧中其坐标大于计数线1的坐标,表明行人此时进入目标区域,目标区域人流量加一.在实际应用中,根据场景的具体情况灵活设置虚拟线的位置即可.本文设计的双向人流量智能统计方法不仅算法复杂度低,可实现快速计数,且通过准确判断行人运动方向实现了人流量高准确率统计.
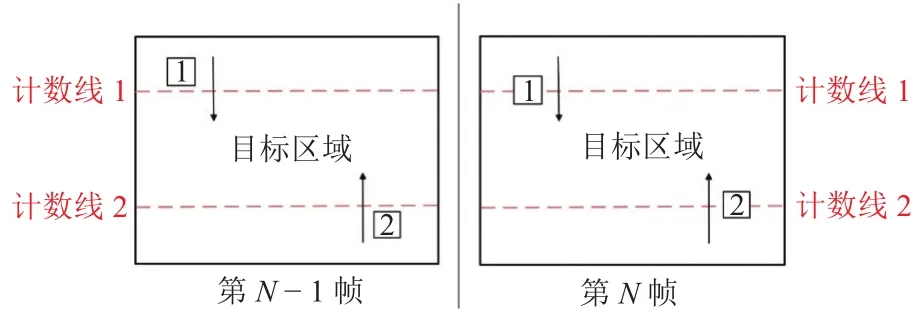
图6 人流量智能统计过程Fig.6 Intelligent statistic process of pedestrian flow
2 实验结果与分析
2.1 实验环境与参数设置
实验所用硬件配置为:操作系统为Windows 10,CPU为 Inter(R) i5-8300H@2.30 GHz, GPU为NVIDIA GTX1060,内存为8 GB.模型训练的平台基于深度学习开发工具TensorFlow,编程语言为Python.训练过程中参数设置为:学习率为0.001,Batch_size为128,最大迭代次数为20 000.
2.2 数据集
实验训练集采用倾斜向下的摄像机拍摄的Brainwash人头数据集,可有效地处理遮挡问题,并且不会受到应用场景的限制,此数据集涵盖了不同光照、不同遮挡程度的场景,以及不同尺度、不同颜色头发的行人头部样本,数据集中用于训练的样本有10 917幅,验证样本和测试样本数量各500幅.
为检验本文方法在不同场景中的鲁棒性,本文选取多种场景下的图像及视频进行测试,并分别设置目标检测实验和人流量统计实验,以测试本文方法的可靠性和先进性.
目标检测实验选用两种数据集进行测试,其一为Brainwash基准数据集中的500幅测试图像,其二为Pets2009基准数据集[20]中S2L1的4种场景下随机选取的509幅图像,如图7所示.

图7 目标检测实验测试集所包含场景Fig.7 Scenes for test set in object detection experiments
人流量统计实验采用了互联网下载的3段密集程度不同的监控视频进行测试,测试视频具体信息如表1所示.

表1 人流量统计实验视频信息Tab.1 Experimental video information of pedestrian flow statistics
2.3 评价标准
本文使用平均准确率(mean average precision,mAP)作为目标检测算法的评价标准,使用召回率(R,式(2))、精确率(P,式(3))和F值(式(4))作为人流量统计算法的评价标准,其中:R衡量算法对于正样本的覆盖能力;P衡量算法判别正样本的准确程度;F值则为权衡R和P的综合指标.

式中:TP指实际为行人且被正确统计的数量,即正检人数;FP指实际为非行人但被错误统计为行人的数量,即误检人数;FN指实际为行人但没有被统计的数量,即漏检人数.
2.4 实验结果分析
2.4.1 目标检测实验分析
由于目标检测的精度直接影响人流量统计结果,实验首先对目标检测算法进行定量精度评定.将本文算法与原始Faster R-CNN算法以及近年来流行的人头目标检测算法在Brainwash基准数据集上进行对比测试,结果如表2所示.文献[18]通过提出一种ReInspect算法解决了密集场景中目标检测的遮挡问题,文献[21]提出了一种卷积层信息融合的方法,通过联合不同尺度的卷积特征信息以提高小目标检测准确率,文献[22]提出了一种基于锚点的完全卷积的FCHD头部检测算法,文献[23]提出了一种基于改进YOLOv3-tiny的轻量人头检测算法MKYOLOv3-tiny,实现了人头目标的快速检测.由对比结果可以看出:本文算法在Brainwash测试集上的平均准确率达到了79.58%,平均准确率不仅高出文献[14]原始算法的7.31%,相比于其余4种模型,整体精度提升了1.58% ~ 37.75%.

表2 不同目标检测算法结果对比Tab.2 Result comparison of different object detection algorithms
为测试本文算法在多种不同场景下的有效性,选用涵盖多种场景的Pets2009数据集进行测试,除原始算法和本文算法外,增加对比算法进行测试,其将Conv3_3层代替Conv5_3层输入RPN中,Anchor尺寸设置与本文算法保持一致,结果如表3所示.由结果可以看出:本文目标检测算法所训练模型的平均准确率达到了74.24%,平均检测每张图像的时间为0.168 s,与原始算法相比,整体精度提升了10.71%,而单张图像检测速度相差仅为0.002 s.另一方面,本文算法检测精度明显高于对比算法,这说明Conv4_3层相较于Conv3_3层针对小目标能够提取到更加有效的特征.总体看来,经过本文方法改进之后的Faster R-CNN通过极少量的时间代价显著提高了小目标检测精度,有效地平衡了检测精度与速度.

表3 模型对比结果Tab.3 Result comparison of models
针对小目标检测问题,一些文献利用多尺度特征融合方式对特征提取网络进行改进,以提高检测精度[24-25].为进一步证明本文改进算法的优越性,采用通道叠加方式对多层特征图进行融合实验,结果如表4所示.由结果可以看出:采用多尺度特征融合方式所训练模型的平均准确率最高可达到69.46%,虽然与原始算法相比有所提升,但比本文算法低出4.78%.这是由于行人头部相比于行人全身所占像素小得多,且数据集中每个行人头部在图像上占比较为平均,因此行人头部的多尺度特性表现不明显.另外,越低层特征图虽然边缘细节信息更为丰富,但同时其包含的无关杂乱信息也就越多,因此Conv4_3相比于多尺度融合而成的特征图能够提取到细节信息更为准确、语义信息更为丰富的特征,从而本文方法相较于多尺度特征融合方法精度更高,充分证明了本文改进方案是行之有效的.

表4 多尺度特征融合方法精度Tab.4 Mean average precision of multi-scale feature fusion methods
2.4.2 人流量统计实验分析
人流量统计测试结果如图8所示.
图8中:红色框为检测结果;白色框为跟踪结果;左上角黄色文字为人流量实时统计结果;两条黄色虚拟计数线所围成的区域即为目标区域.图8(a)、图8(b)为普通场景下的监控视频,从图中可以看出:本文方法能够实现行人的全部检测和跟踪,并能对人流量进行准确统计;图8(c)为密集场景下的监控视频,从图中可以看出:本文方法亦具有较好的效果,此外对于人头密集及存在部分重叠的情况下亦可以实现高精度的检测与跟踪(图8(c)中蓝色框选部分).由此可以证明本文方法具有较好的精度,且具有一定的鲁棒性.

图8 不同场景下视频人流量统计结果Fig.8 Results of video pedestrian flow statistics in different scenes
为定量评价本文视频人流量智能统计方法的性能,通过人工统计出了测试视频中的正检人数、误检人数、漏检人数,并由以上统计量计算出召回率、精确率和F值,结果如表5所示.由结果可以看出:虽然在密集场景中由于误检人数较多导致在精确率标准上低于普通场景,但整体而言,本文方法在3个视频中的召回率、精确率和F值标准上表现较好,皆达到了90.00%以上.

表5 视频人流量统计结果Tab.5 Results of video pedestrian flow statistics %
统计了近年来表现优异的视频人流量统计方法,其算法框架主要有基于SSD-Sort检测跟踪框架[26]以及基于Yolov3-DeepSort检测跟踪框架[27]等.将以上两种人流量统计算法框架与本文方法在相同的数据集下进行对比,结果如表6所示.由对比结果可以看出:相较于上述两个算法,本文方法在召回率标准上提高了1.46% ~ 3.65%,这证明本文方法在普通场景和密集场景下的漏检情况有所降低.本文方法在精确率标准上相较于SSD-Sort算法提高了2.38%,与Yolov3-DeepSort算法基本持平.总体而言,综合指标F值提高了1.14% ~ 3.04%,充分证明了本文方法在视频人流量统计应用上的鲁棒性和先进性.
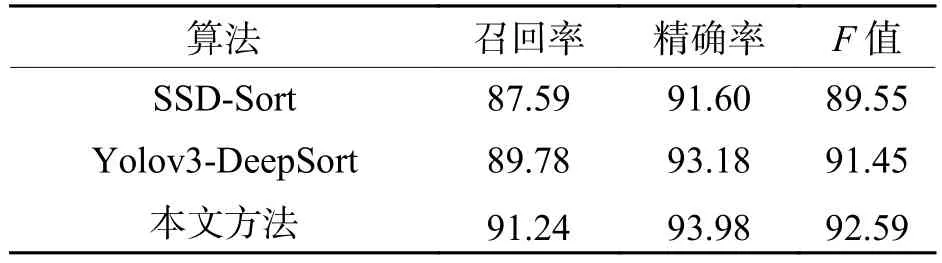
表6 不同算法对比结果Tab.6 Comparison results of different algorithms for pedestrian flow statistics %
3 结 论
1) 提出了用于小目标检测的Faster R-CNN改进算法,检测准确率在Brainwash数据集和Pets2009数据集上分别比原始算法高出7.31%、10.71%,相较于传统多尺度特征融合方法效果更优.
2) 设计了双向人流量智能统计算法,人流量统计指标F值在多种场景下均达到了90.00%以上,相较于以往优秀算法得到了一定提升,实现了多场景下视频人流量的精确智能统计.
