基于关系探索和KTBoost的暂态稳定裕度评估
2022-08-24王强,刘炼,陈浩
王 强,刘 炼,陈 浩
(三峡大学电气与新能源学院,宜昌 443002)
随着现代电网的广域互联和大规模新能源的接入,电力系统运行面临的风险也在不断增加,快速、准确的暂态稳定评估已成为保证系统安全稳定运行的重要手段[1]。传统用于分析电力系统暂态稳定的方法有时域仿真法[2]和直接法[3]。其中:时域仿真法计算速度较慢,难以适应在线应用的需求;直接法虽然计算速度快,但对于复杂系统,其能量函数构造困难,模型的适应性较差。
近年来,广域测量系统的不断发展促进了同步相量测量单元PMU(phasor measurement unit)在电网中的广泛应用。PMU能够快速采集电力系统中各种关键设备的运行状态信息,为在线暂态稳定预测创造了条件[4-5]。并且,PMU采集的海量数据为人工智能方法在电力系统中的应用提供了数据支撑,掀起了机器学习在暂态稳定评估领域的研究热潮[6-8]。
基于机器学习的暂态稳定评估方法不需要建立复杂的数学模型,主要通过在离线阶段训练大量的样本建立特征数据与暂态稳定指标之间的映射关系,然后将训练好的模型应用于在线暂态稳定预测。常用于分析电力系统暂态稳定的机器学习方法有神经网络[9-10]、支持向量机SVM(support vector machine)[11-12]、决策树DT(decision tree)[13-14]和深度学习[15-17]等。虽然上述方法已经取得了较多的成果,但仍存在着不足之处。其中:DT和SVM由于模型结构简单,对数据的挖掘能力有限,其评估精度仍存在提升的空间;神经网络和深度学习模型属于“黑箱模型”,模型的结构较为复杂,导致模型离线更新的成本较高,很难应用于实际。
此外,机器学习方法在应用过程中,通常还会面临以下问题:一方面,随着电网规模的不断扩大,电力系统运行数据的维度也在不断增加,如何筛选初始样本中的关键运行特征是暂态稳定评估中的一个难题;另一方面,基于机器学习的暂态稳定评估方法通常只是评估系统的稳定与否,并未给出系统的稳定裕度信息,容易造成低暂态稳定裕度情况下由于预防控制措施采取不及时而导致电力系统出现暂态失稳。
基于上述分析,本文提出了一种基于关系探索和核-树联合提升KTBoost(combined kernel and tree boosting)的暂态稳定裕度评估方法。首先,通过分析特征与目标变量之间的相关性以及特征之间的冗余性和协同性,筛选出初始特征集中的关键特征子集。然后,使用关键特征数据及其对应的暂态稳定裕度指标训练KTBoost模型,构建KTBoost驱动的暂态稳定裕度评估模型。最后,在新英格兰10机39节点系统和1648节点系统进行仿真实验,验证了该方法的准确性和有效性。
1 基于机器学习的暂态稳定评估问题
1.1 暂态稳定裕度
暂态稳定裕度TSM(transient stability margin)用于反映电力系统的暂态稳定水平,本文通过引入电力系统故障的极限清除时间CCT(critical clear⁃ing time)来构建每个运行点的暂态稳定裕度指标。CCT是指电力系统故障后可以恢复稳定运行所允许的最大故障切除时间,CCT越长,表明系统维持稳定运行的能力越强。文献[18]将CCT作为电力系统的暂态稳定裕度指标,提出了一种基于Elastic Net的暂态稳定裕度评估方法;文献[19]使用不同故障位置的CCT与故障清除时间的差值来表征电力系统的稳定水平,并采用随机森林RF(random for⁃est)实现暂态稳定裕度的回归预测。基于上述研究,本文将暂态稳定裕度指标构建为

式中:TCCT为故障的极限清除时间;TACT为故障的实际清除时间。当TSM>0时,表明系统处于稳定运行,反之则表明系统失稳。TSM越大,则系统的稳定性越强。本文采用二分法计算故障的CCT,将能够保持系统稳定运行的最长清除时间作为该故障位置的CCT。在CCT的求解过程中,以任意两台发电机的最大功角差是否超过360°作为系统稳定的判断依据。
1.2 关键特征子集的筛选
1.2.1 初始输入特征

1.2.2 关键特征的选择
由于初始特征中包含了许多冗余重复的信息,若将其作为机器学习模型的输入,将会极大程度地增加模型的计算负担,因此需要进行特征降维。最大信息系数MIC(maximal information coefficient)是一种基于互信息的关系探索方法,常用于挖掘变量之间的隐含关系[20]。MIC的基本思想是将两个变量的关系离散到一个二维空间并通过散点图进行表示。给定一个数据集D={(X,Y)}={(x1,y1),(x2,y2),∙∙∙,(xn,yn)},其中n为样本的数量。首先,将xi和yi构成的散点图进行x行y列网格化,再根据两个变量在网格中的近似概率密度分布,分别计算这两个变量的互信息。其中,网格的划分方式有很多种,求取不同网格划分下互信息的最大值作为最终的MIC。MIC的计算公式为
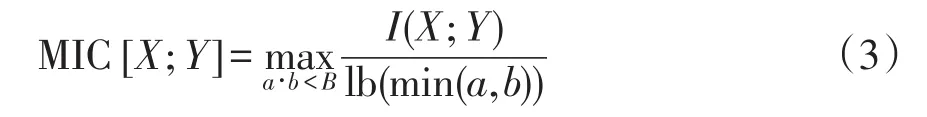
式中:a、b为在x轴和y轴方向上划分格子的个数;I(X;Y)为变量X、Y之间的互信息;B为网格划分的阈值,通常设置为n0.6。MIC∈[0,1],MIC越大,表明变量之间的相关性越强。
虽然MIC能够筛选出与目标变量具有强相关性的关键特征,但在考虑相关性的同时,还应考虑特征之间的冗余性和协同性。为此,本文提出了一种基于施密特正交化GSO(Gram-Schmidt orthonor⁃malization)[21]和信息增益 IG(information gain)[22]的GSO-MIC-IG特征选择框架。
首先,通过GSO分析变量之间的冗余度。假设F为包含N个特征的初始特征集,需要选择的特征子集为S={f1,f2,…,fm},其中,第i次选择的特征为fi,fi∈F-S,目标变量为Y。将fi关于特征子集S的正交化变量,定义为

式中:‖v‖为正交化向量v的模;GSO(fi,S)为表征变量fi独立于已选特征子集S之外的信息。通过计算GSO(fi,S)与目标变量Y之间的MIC[GSO(fi,S),Y]来衡量待选变量fi与子集S的相关度。MIC[GSO(fi,S),Y]越大,表明fi所包含独立于已选子集S的信息越多,对子集S越重要。通过分析特征fi独立于子集S之外的信息间接考虑了特征之间的冗余度,避免了无关冗余信息的干扰。
在分析特征之间冗余性的同时,还需对特征之间的协同作用进行分析。对于特征fi、fS以及目标变量Y,将这三者的协同增益定义为
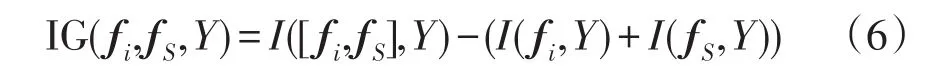
式中:I([fi,fS],Y)为特征fi和fS协同作用时与Y的互信息,I(fi,Y)和I(fS,Y)分别为fi和fS单独作用时与Y的互信息。当IG(fi,fS,Y)≥0时,表明特征fi和fS之间存在协同作用;反之,则表明fi和fS对于目标变量Y存在冗余。将特征fi和子集S对于Y的协同度VI(variable interaction)定义[23]为
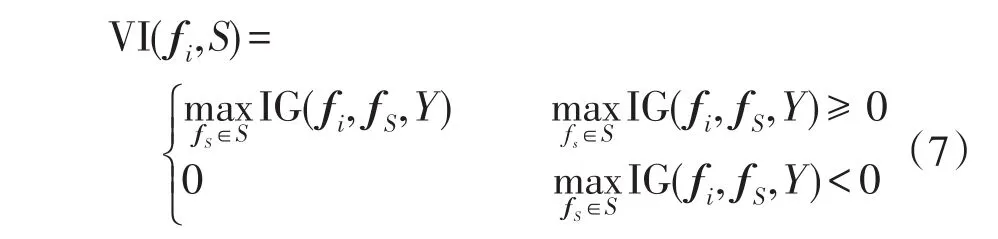
结合上述冗余性和协同性分析过程,文中所提特征选择框架的整体流程如下所示。


1.3 KTBoost模型
KTBoost[24]是一种结合核提升和树提升的新型Boosting算法,其基本思想是通过回归树和再生核希尔伯特空间RKHS(reproducing kernel Hilbert space)函数相结合,从而获得学习能力更强的强学习器。KTBoost在每一次增强迭代中,首先通过牛顿法或梯度下降法来学习回归树和RKHS函数,然后选择使经验风险最低的基学习器加入到集成模型中。KTBoost算法的工作原理如下。


2 KTBoost驱动的暂态稳定裕度评估模型
基于关系探索和KTBoost的暂态稳定裕度评估流程如图1所示,包括离线训练和在线应用2个阶段。
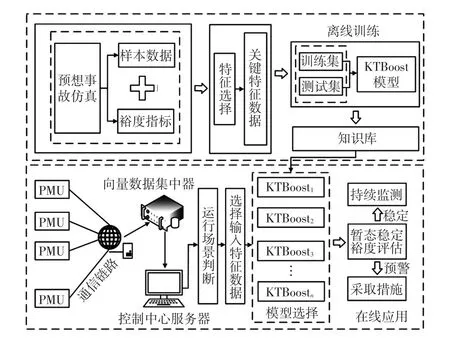
图1 暂态稳定裕度评估流程Fig.1 Process of assessment on transient stability margin
2.1 离线训练
(1)初始数据库。准备一个可靠且丰富的初始数据库是构建准确映射关系的前提。文中借助电力系统仿真软件PSS/E[25]进行电力系统预想事故的时域仿真,得到包含多个样本的初始数据库,并通过第1.1节所提方法计算每个样本对应的暂态稳定裕度指标。
(2)特征选择。为了降低模型的计算复杂度,文中通过第1.2小节提出的方法对初始数据进行降维,筛选出具有强相关性、低冗余性和高协同度的关键特征子集。
(3)模型训练及测试。将特征选择后的数据划分为训练集和测试集对KTBoost模型进行训练及测试,构建能够准确反映输入特征数据与暂态稳定裕度指标之间映射关系的暂态稳定裕度评估模型。
(4)知识库的建立。由于检修和调整运行方式等原因,电力系统的运行场景会经常发生改变,而初始训练样本中不可能涵盖电力系统所有的运行场景,导致离线训练好的模型在应用阶段的适用性大为降低。为了保证评估模型在应用阶段的有效性,需要进行暂态稳定评估模型的更新。
通常,电力系统的调度会根据“日前-日内-小时内”的负荷预测结果来安排电力系统下一阶段的运行方式和启停计划,表明电力系统的运行方式和拓扑结构是可以提前预测的。对于这种情况,可以通过在离线阶段生成多个未来的运行场景和相应的预想事故集,构建针对不同运行场景的暂态稳定裕度评估模型,并将所有的模型集成到一个知识库中,以备后续出现紧急事故时的快速调用。对于在应用阶段出现的计划外的停运或故障情况,则需及时仿真生成新的样本进行模型的更新,并将更新后的模型添加到知识库中。
随着知识库的不断丰富,更多潜在的电力系统运行场景将被覆盖,未考虑的运行场景将会越来越少,模型的适应性及在线应用的可靠性将不断提高。
2.2 在线应用
在应用阶段,首先对电力系统的运行场景进行判断,然后选择PMU采集的关键特征数据输入离线训练好的暂态稳定裕度评估模型,实时评估系统的稳定情况。当电力系统的暂态稳定裕度较高时,说明系统的稳定水平较强,则保持对系统的持续监测。当系统处于失稳或暂态稳定裕度较低时,应及时采取预防控制措施,使电力系统恢复到较为稳定的运行状况。
2.3 模型性能评价指标
文中采用决定系数(R2)和均方根误差RMSE(root mean square error)两个统计指标来衡量模型的预测性能。R2和RMSE的计算公式分别为
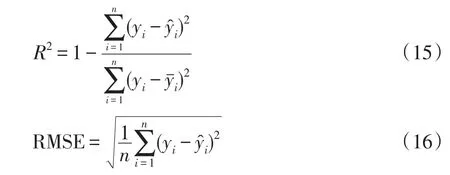
式中:n为样本数量;yi为xi对应的暂态稳定裕度指标;为预测值;为yi的平均值。一般来说,R2越接近于1,RMSE越小,表明模型的拟合效果越好。
3 算例分析
3.1 新英格兰10机39节点系统
为验证所提方法的有效性,本文通过PSS/E软件对如图2所示的新英格兰10机39节点系统进行仿真。所有测试均是在一台配置Intel Core i5-4200H 2.80 GHz CPU和8 GB RAM的电脑上进行。
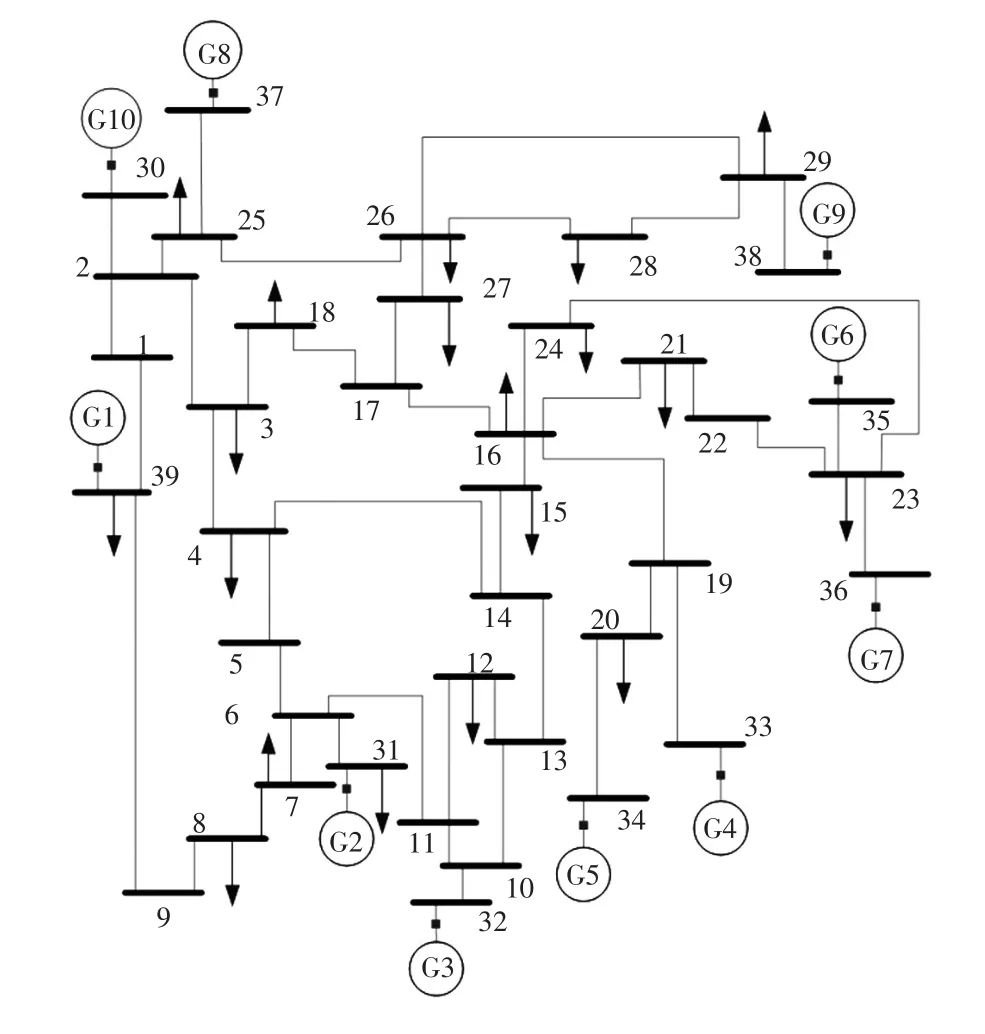
图2 新英格兰10机39节点系统Fig.2 New England 10-machine 39-bus system
3.1.1 数据生成及参数设置
在仿真过程中,以5%为步长,模拟总负荷在[75%,125%]之间增长变化,并根据负荷水平相应调整发电机出力。通过在线路上设置三相短路故障来模拟电力系统的预想事故情况,将故障的持续时间设置在0.1~0.4 s之间变化,通过切除线路来清除故障。基于不同的初始运行方式进行电力系统的时域仿真,采集不同初始运行方式下的电网运行数据,最终一共生成了4 590个样本。通过五折交叉验证法随机选取初始样本的80%作为训练集,剩余20%作为测试集。
KTBoost模型参数的设置在一定程度上影响了模型的评估性能,通过网格搜索法优化模型的参数,最终得到KTBoost的最优参数组合:基回归器数量为200,叶子最大深度为4,学习率为0.05,核函数设置为径向基核函数。
3.1.2 特征选择的影响
KTBoost在不同特征维度下测试的精度及训练时间如图3所示。结果表明,随着特征维度的增加,模型的评估精度逐步上升,最后趋于稳定。考虑到基于机器学习的暂态稳定评估模型需要经常进行更新迭代,为了避免计算资源的浪费,最终选择初始特征的30维作为关键特征子集。
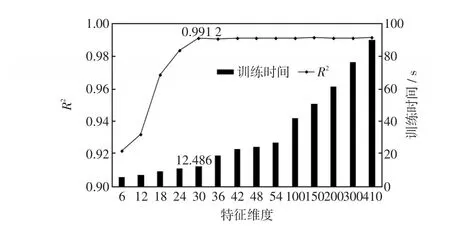
图3 不同特征维度下的性能测试Fig.3 Performance tests under different feature dimensions
为了体现本文所提特征选择方法的优越性,将其与MIC、最大相关最小冗余MRMR(maximum rel⁃evance minimum redundancy)和联合互信息JMI(joint mutual information)3种特征选择方法进行对比测试。基于不同的方法分别选择初始特征的30维作为关键特征子集,测试结果如表1所示。结果表明,由于MIC只是挖掘特征与目标变量之间的相关性,并未考虑其他因素的影响,因此模型评估的精度偏低;JMI考虑了多个特征以及目标变量之间的相关性,能够获得比MIC更高的评估准确性;MRMR在特征选择过程中,并未考虑特征之间的协同作用,其评估精度低于本文所提的GSOMIC-IG特征选择框架。总体来看,基于GSO-MICIG筛选的特征子集,KTBoost模型能够获得最优的评估结果。
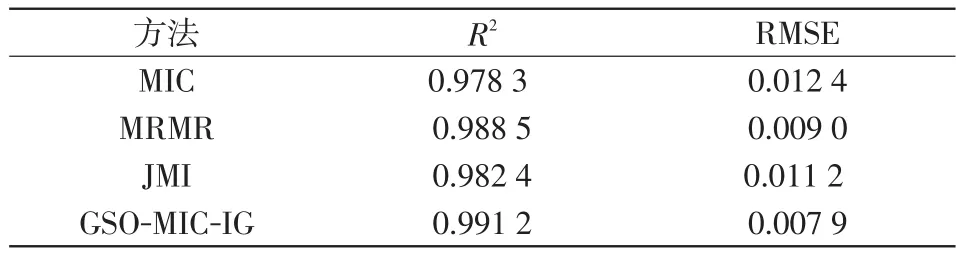
表1 不同特征选择方法的对比Tab.1 Comparison among different feature selectionmethods
3.1.3 预测精度与时间复杂度
随着同步相量测量技术的不断发展,PMU对电网运行数据的采集频率已经高达50次/s[5]。即对每个时间步的电力系统暂态稳定裕度的评估,评估模型对PMU数据的处理时间必须少于0.02 s。其中,KTBoost模型的性能测试结果如表2所示,其拟合效果随迭代次数变化的曲线如图4所示。结果表明,模型对每个样本的评估时间远小于0.02 s,并且随着迭代次数的增加,KTBoost模型的拟合效果越好。总体来看,KTBoost模型能在短时间内实现高精度的暂态稳定裕度评估,能够满足在线应用的需求。

表2 预测精度和时间复杂度Tab.2 Prediction accuracy and time complexity
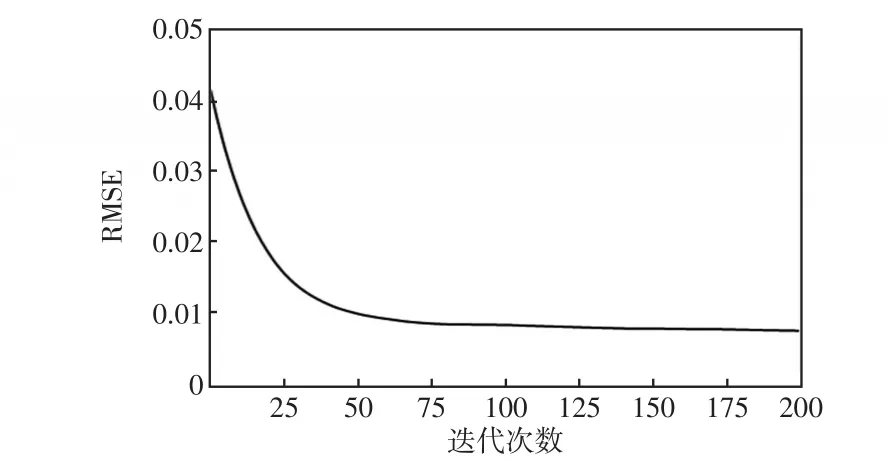
图4 不同迭代次数下的RMSEFig.4 RMSE under different numbers of iterations
3.1.4 不同机器学习模型的性能对比
为了体现本文所提KTBoost模型的优越性,将其与不同的机器学习模型进行对比测试。主要包括人工神经网络ANN(artificial neural network)、DT、RF、梯度提升决策树 GBDT(gradient boosting decision tree)、SVM和卷积神经网络CNN(convolu⁃tional neural network)。其中,CNN基于深度学习库TensorFlow搭建,其他机器学习模型均基于机器学习库Scikit-learn搭建。在测试过程中,所有模型均使用相同的输入特征。不同机器学习模型的性能测试结果如表3所示。
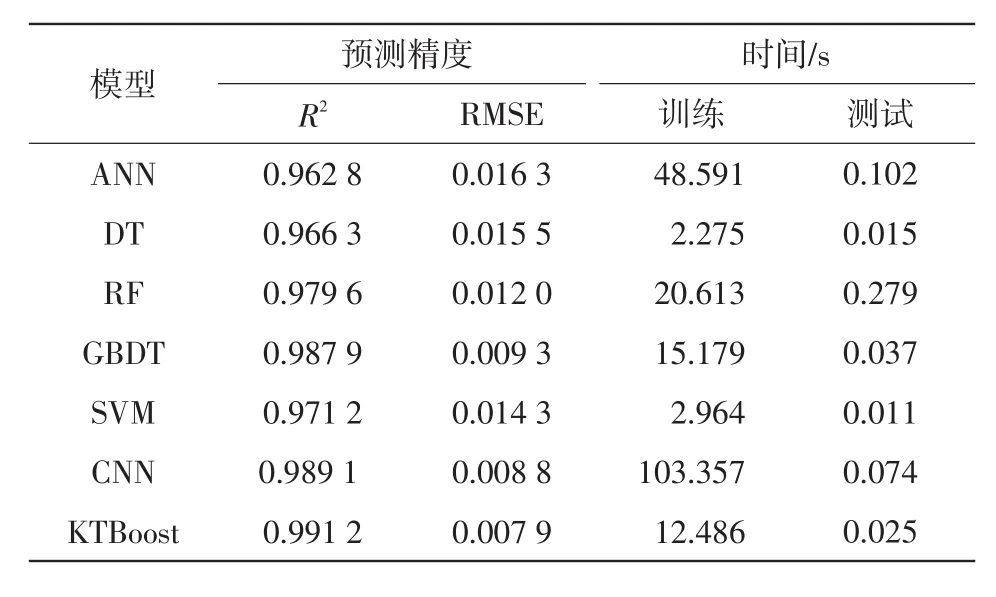
表3 不同模型的性能测试Tab.3 Performance tests of different models
结果表明,ANN、DT和SVM相对与其他方法,总体评估精度处于一个较低的水平。与基于树提升的GBDT和简单树集成的RF相比,KTBoost通过回归树与RKHS回归函数相结合,能够获得一个更高的评估精度。CNN虽然能够获得一个较高的评估准确性,但CNN在训练时需要调整大量的网络参数,导致模型的计算量较大,模型离线训练的成本较高。总体来看,KTBoost在保证精度的同时不会消耗大量的训练时间,更加适用于电力系统的在线暂态稳定裕度预测。
3.1.5 不同训练集规模的影响
当电力系统出现紧急事故时,已经训练好的离线模型可能无法给出满意的评估结果,因此需要进行模型的更新。为了快速建立暂态稳定裕度评估模型,如何确定训练数据的规模使模型能够达到满足要求的评估精度也是一个非常关键的问题。为此,文中分别测试了不同训练集规模对模型评估精度的影响,结果如图5所示。由图5可知,随着训练集规模的逐步递增,KTBoost模型的评估精度也随之增加,表明了需要充足的训练样来保证评估的高准确性。此外,对于电网运行人员而言,可以根据暂态稳定评估所需的精度要求来选择合适的训练样本规模,快速建立适用于某个运行场景的暂态稳定裕度评估模型。

图5 不同训练集规模下的测试Fig.5 Tests under different sizes of training set
3.1.6 模型的鲁棒性测试
PMU在数据采集与传输的过程中,可能会出现以下两类数据异常情况:①由于PMU测量误差导致部分输入数据存在噪声;②由于PMU故障导致部分输入特征缺失。本文针对上述两种情况分别进行了研究。
为了测试噪声对KTBoost模型评估性能的影响,文中在原始数据中考虑了4种不同信噪比SNR(signal to noise ratio)的高斯白噪声。在不同噪声条件下,各种机器学习模型评估的R2如图6所示。结果表明,ANN和DT由于结构简单,模型的评估精度总体偏低。SVM在低噪声条件下能够维持评估的R2在0.97左右,但当噪声增加到20 dB时,模型评估的R2骤减至0.96以下,表明SVM对噪声的鲁棒性较差。RF、GBDT和KTBoost都为集成模型,对噪声具有一定的鲁棒性,因此都能够维持一个较为稳定的评估精度。CNN借助其深层结构,对数据的挖掘能力较强,虽然CNN对噪声的鲁棒性较强,但其评估精度仍要低于文中所提的KTBoost模型。总体来看,与其他机器学习模型相比,KTBoost在不同噪声条件下能够保持一个较高的评估精度,具有更高的实用价值。
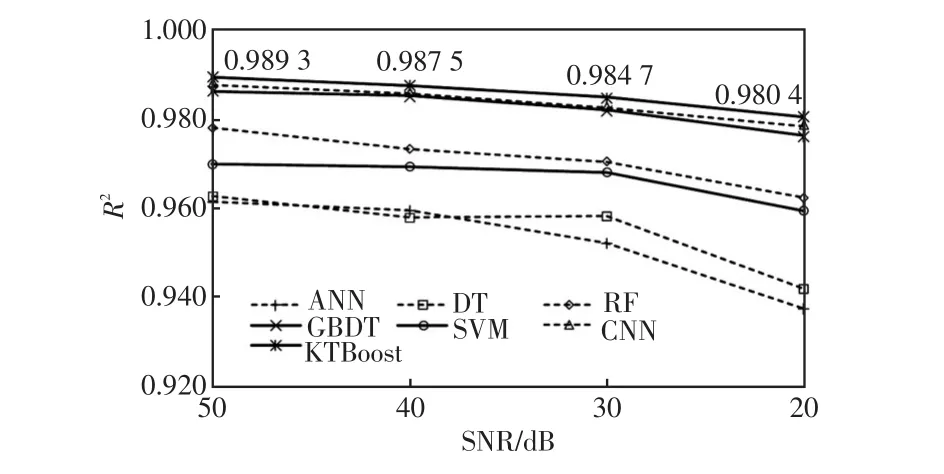
图6 不同模型的抗噪能力测试Fig.6 Anti-noise capability tests of different models
为了测试输入数据存在部分特征缺失情况下KTBoost模型的评估性能,本文在测试集中考虑了4种不同比例的特征缺失情况。在不同条件下,模型评估的精度如表4所示。结果表明,随着特征缺失比例的增加,对KTBoost模型的负面影响也越来越大,虽然模型的评估精度出现一定程度地下降,但仍能够维持相对稳定的预测结果。
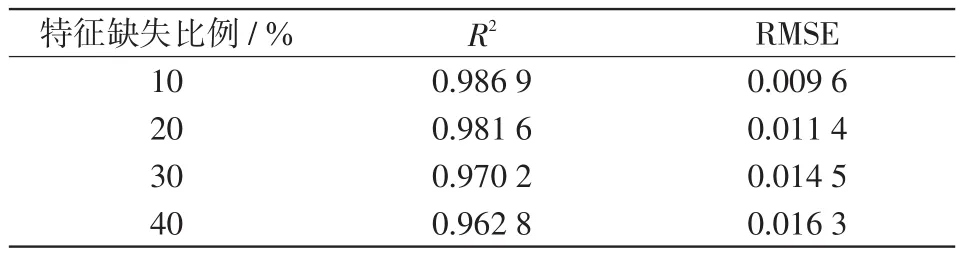
表4 数据缺失的影响Tab.4 Impact of missing data
3.1.7 模型的泛化能力测试
由于电力系统是一个时变的系统,在考虑模型评估精度的同时,泛化能力也是衡量模型性能的重要指标。本文测试了以下5种场景模型的泛化能力:
场景1:负荷水平仍保持在[75%,125%],系统拓扑结构不变,改变发电机出力;
场景2:负荷水平为100%,输电线路16-17和27-28退出运行;
场景3:负荷水平为70%,输电线路23-36、母线36和7号发电机退出运行;
场景4:负荷水平为100%,在母线8处新增1台发电机、1条母线和1条输电线路;
场景5:负荷水平为130%,在母线8和母线16处新增2台发电机、2条母线和2条输电线路。
针对每种运行场景仿真生成450个新样本,通过将新样本输入KTBoost模型测试其评估性能,测试结果如表5所示。结果表明,在场景1和场景2中,由于系统的负荷水平和拓扑结构变化较小,KT⁃Boost模型仍能够维持评估的R2在0.98以上;在场景3至场景5中,随着变化的加剧,虽然KTBoost模型的评估精度出现明显的下降,但仍能够给出可接受的评估结果,显示出KTBoost模型针对未知的电力系统运行场景具有一定的泛化能力。

表5 不同场景下的预测精度Tab.5 Prediction accuracy under different scenarios
3.2 1648节点系统
为了进一步验证本文所提方法的有效性,将PSS/E软件自带的一个1648节点系统作为测试系统。该系统包含1 648条母线、313台发电机、182个分流器和2 294条输电线路。采用第3.1.1节所提方法进行仿真,共生成了9 240个样本。KTBoost模型的参数使用第3.1.1节所设置的参数。
3.2.1 模型的评估性能检验
1648节点系统的每个仿真样本包含37 439个初始运行特征,为了降低KTBoost模型的计算负担,文中利用第1.2节所提的GSO-MIC-IG特征选择框架选取初始特征的1%作为关键特征子集。基于筛选的关键特征子集,不同机器学习模型的性能测试结果如表6和表7所示。结果表明,在无噪声条件下,KTBoost模型能够获得比其他模型更高的预测精度。当SNR为20 dB时,除了KTBoost模型外,其他模型的预测精度均出现显著下降,体现了KT⁃Boost优异的预测性能。
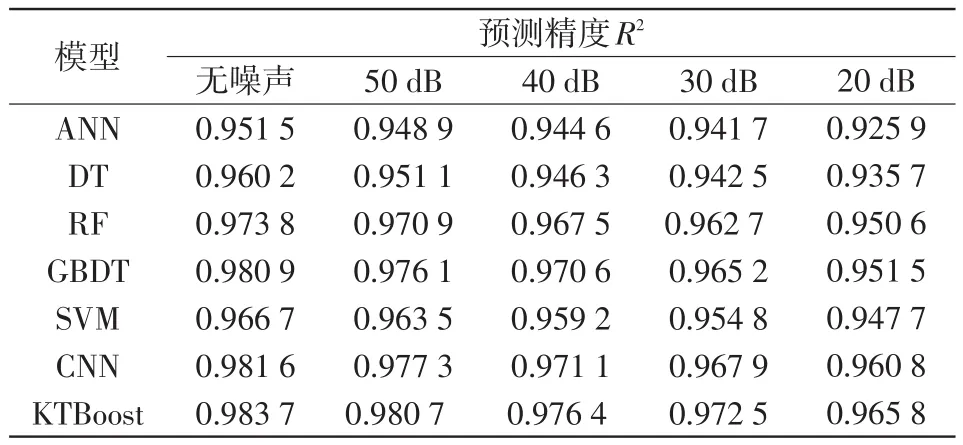
表6 不同模型预测的R2Tab.6 R2predicted by different models
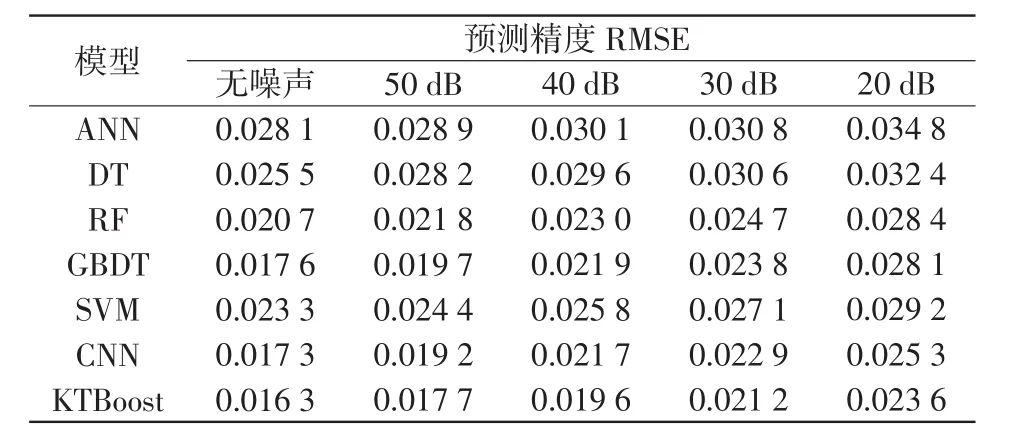
表7 不同模型预测的RMSETab.7 RMSE predicted by different models
3.2.2 模型的泛化能力测试
为了测试KTBoost模型在大系统中的泛化能力,文中保持负荷水平在[75%,125%],主要考虑如表8所示的5种电力系统拓扑结构变换场景,针对每种场景仿真生成450个新样本,不同场景的测试结果如表9所示。结果表明,在1648节点系统中,电力系统运行拓扑结构的改变不会导致KTBoost模型的评估精度出现大幅度下降,体现了文中所提方法在大系统中的有效性。

表8 电力系统的拓扑结构Tab.8 Topology of power system

表9 不同场景下的预测精度Tab.9 Prediction accuracy under different scenarios
4 结论
本文提出了一种基于关系探索和KTBoost的电力系统暂态稳定裕度评估方法。在新英格兰10机39节点系统和一个1648节点系统进行了仿真研究,实验结果表明:
(1)所提GSO-MIC-IG特征选择框架能够有效挖掘特征与目标变量之间的相关性以及特征之间的冗余性和协同性,能够有效降低样本数据的维度。与MIC、JMI和MRMR等方法相比,本文所提特征选择方法能够筛选出更为关键的特征子集。
(2)与DT、SVM、ANN、RF、GBDT和CNN等模型相比,KTBoost模型能够在较短的时间给出更为精确的评估结果,具有更高的实用价值。
(3)针对未知的电力系统运行场景以及输入数据存在噪声和数据缺失的问题,本文所提KTBoost模型仍能够给出相对稳定的评估结果,具有较强的鲁棒性和泛化能力。
