Fusion-Based Deep Learning Model for Hyperspectral Images Classification
2022-08-24KritiMohdAnulHaqUrvashiGargMohdAbdulRahimKhanandRajinikanth
Kriti, Mohd Anul Haq, Urvashi Garg, Mohd Abdul Rahim Khan,*and V.Rajinikanth
1Department of Computer Science and Engineering, Chandigarh University, Mohali, 140413, India
2Department of Computer Science, College of Computer Science and Information Science, Majmaah University,AL-Majmaah, 11952, Saudi Arabia
3Department of Electronics and Instrumentation Engineering, St.Joseph’s College of Engineering,Chennai, 600119, Tamil Nadu, India
Abstract: A crucial task in hyperspectral image (HSI) taxonomy is exploring effective methodologies to effusively practice the 3-D and spectral data delivered by the statistics cube.For classification of images, 3-D data is adjudged in the phases of pre-cataloging, an assortment of a sample, classifiers, post-cataloging, and accurateness estimation.Lastly, a viewpoint on imminent examination directions for proceeding 3-D and spectral approaches is untaken.In topical years, sparse representation is acknowledged as a dominant classification tool to effectually labels deviating difficulties and extensively exploited in several imagery dispensation errands.Encouraged by those efficacious solicitations, sparse representation (SR) has likewise been presented to categorize HSI’s and validated virtuous enactment.This research paper offers an overview of the literature on the classification of HSI technology and its applications.This assessment is centered on a methodical review of SR and support vector machine (SVM) grounded HSI taxonomy works and equates numerous approaches for this matter.We form an outline that splits the equivalent mechanisms into spectral aspects of systems, and spectral-spatial feature networks to methodically analyze the contemporary accomplishments in HSI taxonomy.Furthermore, cogitating the datum that accessible training illustrations in the remote distinguishing arena are generally appropriate restricted besides training neural networks(NNs) to necessitate an enormous integer of illustrations, we comprise certain approaches to increase taxonomy enactment, which can deliver certain strategies for imminent learnings on this issue.Lastly, numerous illustrative neural learning-centered taxonomy approaches are piloted on physical HSI’s in our experimentations.
Keywords: Hyperspectral images; feature reduction (FR); support vector machine (SVM); semi supervised learning (SSL); markov random fields(MRFs); composite kernels (CK); semi-supervised neural network (SSNN)
1 Introduction
Classification of HSI has developed as a hot area in the arena of remote sensing.With the progressive expansion of spectral imageries methods, a taxonomy of HSI’s has enticed excessive consideration in numerous solicitations for instance terrestrial analysis and resource tracking in the arena of remote recognizing.HSI procures a 3-D dataset baptized hypercube, having twofold 3-D magnitudes and one spectral element [1].Over the preceding era, the unification of 3-D data has drained cumulative consideration in HSI statistics exploration.Particularly, the characteristic of 3-D autocorrelation amid pixels has presented excessive impending for refining appreciative of remotely recognized metaphors.Generally, the compound physiognomies of HSI statistics create the precise taxonomy of such statistics perplexing for contemporary machine erudition approaches.Furthermore,HSI frequently handles an intrinsically nonlinear association concerning the apprehended spectral data and the equivalent resources.This article provides an inclusive analysis of the contemporary procedures in integrating spatial evidence in imagery taxonomy [2].HSI statistics comprises customary imageries using the identical topographical prospect.These imageries link to diverse spectral ensembles of electromagnetic emission.Stabilizing a band, the HSI statistics shrinks to solitary imagery comprising the prospect edifice data of diverse constituents.Fixing an imagery synchronize helps in obtaining a spectral arc trajectory, which is baptized a pixel.HSI sensors permit for the acquirement of hundreds of adjoining ensembles for the identical expanse on the appearance of the Earth and deliver abundant valuable data that upsurges the precise refinement of spectrally related resources of concern.HSI has been comprehensively and progressively exploited in taxonomy, unmixing, synthesis, object recognition, terrestrial somatic and biochemical constraint approximation, and profligate calculating[3].Among numerous dispensation errands, cataloging has enticed amply of consideration in the last eras.This category of processing purposes at allocating every pixel with a unique thematic session for an entity in a section.Diverse resources have dissimilar concentrations or considerations at a firm spectral ensemble.Therefore, it can recognize and categorize the constituents centered on their spectral curvatures.The objective of the examination is threefold: an outline for that novel to the arena, a summary for those employed in the arena, and an orientation for those probing for literature on an explicit solicitation.Contemporary classifiers, for instance, the Bayesian classifier, the k-nearest neighbor (k-NN) classifier, and NNs practice the spectral signs in the HSI taxonomy.HSI sensors register the Earth’s apparent reflectance in a huge integer of constricted adjoining spectral ensembles.The HSI imageries consequently deliver comprehensive data about pulverized prospects[4].Explicitly, we principally condense the key complications of HSI taxonomy which are incapable of effectually conquering the traditional approaches and likewise present the benefits of the proposed technique to regulate these complications.Then, the great integer of spectral ensembles surges the analysis impending of HSI, it enforces certain dispensation complications.One of these complications baptized the Hughes aspect, is the requirement for additional training illustrations in the perspective of supervised taxonomy [5].The objective of the assessment compiled in the article is threefold: an overview for those new to the arena, an outline for those employed in the arena, and an orientation for those probing for works on an explicit solicitation.
2 Related Work
2.1 FR Methods
FR methods, which comprises attribute selection and characteristic abstraction, are the furthermost customary resolutions for alleviating the consequences of an enormous ensemble integer of HSI.Feature assortment approaches attempt to elite the minutest subsection of prevailing attributes comprehending satisfactory data to distinguish among diverse modules [6].For this cause,detachability extents are utilized in several assortment arrangements.Divergence and Bhattacharyya distance [7] are the two recognized removability extents.Amongst assortment systems, consecutive forward assortment and uninterrupted forward variable assortment are the furthermost customary approaches.Metaheuristic exploration systems, such as genetic algorithms, can similarly be exploited for this objective.Contrasting feature assortment, feature abstraction approaches presents altogether participation topographies to an alteration of that plots, the novel statistics to an inferior dimensional subplanetary [8].
2.2 Outline of SVM
Understanding scenes from remotely distinguished imageries is a perplexing mission in machine erudition.One crucial motive encountered is the miscellany of statistics composed from ocular sensors say, HSI.These exposed innovative expanses of solicitation nevertheless pose novel methodological difficulties in the scrutiny of data.The additional vital difficulty is the comparative insufficiency of labeled statistics for training and assessment [9].There are additional approaches proficient in handling the higher aspect of attribute planetary, where amongst them SVM is the supreme approach applied for HSI taxonomy.SVM has publicized extraordinary capability concerning taxonomy when training illustrations are limited.SVMs have regularly been exploited for the taxonomy of HSI data for their capability to regulate higher dimensional statistics using a restricted integer of training illustrations [10].The aim is to outline an optimal lined extricating hyperplane in a manifold dimensional attribute expanse that discriminates the training illustrations of two modules.The finest hyperplane vacates the supreme boundary from both modules [11].The hyperplane is attained exhausting a refinement delinquent that is resolved through physical risk deprecation [12].In this manner, contrary to statistical methods, SVMs reduce taxonomy fault on concealed data deprived of any previous norms prepared on the likelihood dissemination of the statistics [13].The SVM attempts to exploit the restrictions among the hyperplane and the contiguous training illustrations.To edify the classifier, merely illustrations that are nearby to the class periphery are necessary to localize the hyperplane trajectory.This is why the edifying illustrations closest to the hyperplane are baptized support vectors.More prominently, as merely the adjoining training illustrations are prominent in engaging the hyperplane in the attribute planetary, the SVM can categorize the contribution data proficiently even if merely an inadequate quantity of training illustrations is accessible [14].
2.3 Requisite to Modify SVM
The traditional approaches generally encounter difficulty due to measured noise, disruption,nonlinear spectral retorts [15], and the Hughes phenomenon instigated by the higher-dimensional insignificant illustrations.Henceforth making HSI classification a tremendously perplexing problem.SVM and additional kernel-centered approaches overcome these restrictions to a certain level for their virtuous capabilities of controlling higher-dimensional trivial illustration-sized nondirective and noisy information.Although SVM in turn is rapidly turning into a deficient approach in exploiting the rich HSI information.Since SVM consider each labeled pixel of HSI as an illustration point and practice it autonomously therein ignoring the associations that exist among the 3-D adjoining pixels.For an HSI, 3-D adjoining pixels have analogous spectral physiognomies and generally be in the identical session.The significance among adjacent pixels is explored to upsurge the consistency and accurateness of the SVM taxonomy [16].Actually, for an assumed pixel, we can abstract the adjacent dimension, outline, and edifice dispersal data.For the pixels that belong to diverse constituents, the analogous 3-D geometrical edifice data is dissimilar.These 3-D statistics are utilized in improving the pixels taxonomy that is inflexible to distinguish via spectral aspects alone.Consequently, achieving an excellent performance of HSI classification would require syndicating the spectral and 3-D data [17].Though the kernel process (SVM) is known for likeness metric and arrangement, the dispensation aspects are distinct pixels or illustration points.Consequently, these 3-D and spectral classifiers can be viewed as the illustration point-centered approaches, in which an illustration trajectory cannot copiously apprehend the 3-D native neighborhood inconsistency of the spectral sign.Since an HSI comprises numerous consistent areas, the pixels in a homogeneous province usually fit the equivalent class.It can categorize these native standardized provinces directly instead of cataloging the aspect trajectories mined from the areas.Fig.1 indicates the updating done in the current SVM classifier to increase its classification efficiency.
2.4 Subspace-centered Classifier
The base of subspace-centered taxonomy is that furthermost of the higher dimensional expanses are vacant and statistics are concerted in the truncated dimensional sub-planetary of the novel interplanetary.Along with this representation, a sub-planetary is allotted to each objective session, which is demarcated exhausting its training illustrations.This sub-planetary is then practical for taxonomy tenacity.Despite the auspicious consequences of this classifier on higher-dimensional aspect arrangement, their solicitations on HSI are less reflected by researchers [18].The sub-planetary notion is also explored in certain additional studies [19].
2.5 A Framework of Ensemble Methods
HSI classification is typically more challenging than other distant distinguishing imagery owing to the Hughes effect.For adequate labeled training illustrations, the transformation among diverse classifiers is insignificant for they altogether congregate at or adjacent to the Bayes fault degree.Nevertheless, this is impractical hypothetically, particularly to classify remote sensing data with expensive and time-consuming acquisition of ground truth.In recent years owing to the struggle and prices of attaining pulverized actuality for HSI, taxonomy via scarce labeled illustrations, has fascinated the attention of distant distinguishing investigators [19].This delinquent of scarce training illustrations is depreciated by the higher dimensionality of spectral groups in HSI.Tab.1 lists the various classifiers used in domain of HSI, the contribution of each classifier and the various issues for eeach classifier.Additional means to overcome the constraint of labeled illustrations embrace exploring the spectral and 3-D data of HSI by feature abstraction and aspect assortment methods or influencing its insufficient nature by sparse illustration ways.Ensemble approaches are magnificently functional for HSI taxonomy.Paralleled to additional classifiers, aspect decrease is typically avoidable for cooperative approaches since they deal impartially fine with higher-dimensional statistics.Paralleled to additional classifiers, aspect decrease is typically avoidable for cooperative approaches since they deal impartially fine with higher-dimensional statistics.

Table 1: HSI classifiers, their contributions, and the various issues
2.6 SR Classifier
SR has emerged as an operative mode in numerous HSI dispensation tasks e.g., target detection besides spectral unmixing.Particularly, SR can characterize higher-dimensional indications as a lined configuration of scarce non-zero measurements centered on a pre-demarcated vocabulary, which is advantageous in yielding contemporary enactmentwhile smearing SR to HSI arrangement.The earlier work explored HSI decay centered on morphological module scrutiny and SR, leading to precise spectral and 3-D arrangement consequences.In SR-centered diverse erudition, authors explored SR to form a sparse grid, and they assumed sparse grid implanting procedure to abstract spectral aspect.Likewise, the effort in fused native lined implanting and Laplacian Eigenmap with SR in fused optimization complications for HSI taxonomy.In SR-centered feature assortment, authors anticipated a discriminative sparse manifold modal erudition system to incorporate spectral and 3-D aspects centered on the concatenating policy.Usually, in SR-centered arrangement methods,an assumed pixel is sparsely characterized by an insufficient molecule from a specified vocabulary,and the acquired SR’s achieve the session-label data.Consequently, the vocabulary shapes a conduit among the perceived sign and its sparse cipher, which has noble discriminative supremacy for SR to produce virtuous enactment [8].Nevertheless, the vocabulary in maximum solicitations is pre demarcated, afore erudite from a training customary.An insignificant policy to shape the vocabulary is by exhausting arbitrary sampling.Consecutively, eradicating an anticipated vocabulary from the training customary has attained acceptance recently as it can auxiliary advance the efficacy of SR.Certain dictionary erudition approaches have been industrialized concerning the abating restoration fault, for instance, K-SVD which is comprehensive from K-means and is extensively explored for natural imagery dispensation, and the major method (MM) which approves a substitute utility to modernize vocabulary in each stage.An additional significant concern in SR [12] centered HSI exploration is the prerequisite for creating SR’s show substantial discriminative supremacy, which is predominantly vital for its effective practice in the arrangement phase.Though, maximum accessible SR approaches in HSI arrangement are centered on the imperative of signal-to-restoration fault, where the label of an indefinite pixel is allocated consistent with the label of the allied subdictionary that yields the least restoration inaccuracy.
This policy may persist absence of oversimplification ever since it is reliant on the error events and simply influenced by noise.Extrication dictionary erudition from arrangement may outcome in a suboptimum vocabulary for arrangement, so it is usually chosen to insert vocabulary and the classifier erudition in SR.The postulation behind SRC is that illustrations from the equivalent session lie in a lower-dimensional sub-planetary regardless of their higher dimensional contribution aspects.A binding assessment illustration is adequately characterized by the training illustrations from the course it is appropriate to, which is certainly sparse under the all-inclusive vocabulary involving training illustrations from all courses [4].Fig.2 depicts the SR Classifier with various updated approaches applied to modify the original archetypal of SR classifier.A concise standard prototypes that are regularly exploited to classify HSIs are presented with an emphasis on SR-centered classification practices for HSIs and a wide-ranging and inclusive outline of the present approaches in an integrated structure.

Figure 2: SR classifier with various updated approaches
2.7 Semi Supervised Classification
Though supervised aspect erudition has attained unlimited revolution in the HSI arrangement arena, there is still an imperative requirement to acquire HSI aspects in an SS manner.The chief tenacity of SS aspect erudition is to abstract valuable aspects from a restricted volume of unlabeled information.Recently, additional investigation mechanisms [4], emphasize crafting a vigorous and operative SS aspect erudition structure established on deep erudition to categorize HSIs.Also, the arrangement enactment is enhanced via reassigning the trained system and adequate regulation on the labeled statistics customary.Tab.2 provides a summary of HSI classification approach, the assumption for each method along with their advantages and disadvantages.

Table 2: HSI classification summary

Table 2: Continued
2.8 Neural Networks
The practice of Neural Networks (NNs) in multifarious taxonomy circumstances is a sign of their prosperous solicitation in the arena of configuration acknowledgment.Predominantly in the 1990s, NN methodologies fascinated numerous researchers in the expanse of the organization of HSI.The gain of suchmethods above probabilistic techniques results primarily from the datum that NNs do not requisite previous information about the algebraic dispersal of the modules.Their desirability amplified as the obtainability of practicable training procedures for nonlinearly distinguishable statistics, though their usage has been conventionally pretentious by their algorithmic and training intricacy along with the number of constraints that must be altered.Numerous NN-centered arrangement methods exist that cogitate both supervised and unsupervised nonparametric methods.The feedforward NN (FN)-centered classifiers remain the greatest assumed ones.FNs have extensively used subsequently the outline of the distinguished back propagation procedure (BP), a first-edict inclination technique for constraint optimization.The BP grants two key difficulties, i.e., slow conjunction and the probability of deteriorating in native minima, particularly when the constraints of the system are not accurately adequately altered.To assuage the drawbacks of the unusual BP process, numerous second-edict optimization-centered approaches, which are quicker and require scarcer contribution constraints, have been anticipated in the works [13].The extreme learning mechanism (ELM) erudition procedure has been anticipated to train solitary hidden-level FNs (SLFN).Then, the notion has been protracted to manifold hidden-stratum complexes, radiated base function (RBF) systems, and kernel erudition.
The chief representative of the ELM is that the hidden stratum (aspect plotting) is erratically stable and requisite not to be iteratively regulated.ELM-centered linkages are extraordinarily effectual concerning accurateness and computational intricacy and have been efficaciously functional as nondirect classifiers for HSI statistics, delivering outcomes analogous with contemporary organizations.Tab.3 emphasis on the various issues in the classification of HSI and the respective solutions in terms of Classifier.

Table 3: HSI classification issues brief and their solutions in terms of classifier
3 Proposed Approach
3.1 Reduction of Dimensionality
The very initial step is to contemplate a 2-D imagery f:φ→z, with φ defined as the distinct province of imagery (φ⊆Z2) and z⊆Z as the customary of probable scalar assessments related to the components of φ.The proposed methodology is established on the concept of dimensionality reduction(DR)of the imagery assessments from z to,n>1,using a standard alterationfunctional to a contribution imagery( i.e.,., g =) and then on the solicitation of the attribute profile (AP) to every(i = 1,.....,) of the distorted imagery.This is formalized as

3.2 SVM Transformation
For a categorized training data customary usingillustrations= {|= 1, 2, ...,n˙ },xi∈, and Y = {yi||i= 1, 2, ...,n˙}, wherexiis a pixel vector withmeasurement, yiis the label of the class, andis the integer of hyperspectral ensembles.The modules in the novel aspect planetary are regularly attached.Now, the kernel process plots these modules to an advanced dimensional aspect planetary using non-lined plotting utility Φ.The plotted advanced dimensional aspect space is symbolized as Q,that is

The mapping of features delivers additional flexibility in structure to further efficiently use statistics, equated via SVM [17].In a map, a flexible united feature is produced by a lined or nonlined amalgamation of a sequence of base SVM and is upgraded in an erudition model to accomplish an enhanced ability to learn.SVM may explore the complete customary of aspects or a subcategory of aspects.The updated SVM is as follows:

whereMis the number of candidate map features for grouping,ηmis the load of the m th base feature.Altogether the weighting constants are non-adverse and summation to solitary confirm that the united features accomplish the progressive semidefinite circumstance and preserve regularization as SVM.The mapping delinquent is considered to enhance both the relating loads ηmand the resolutions to the novel erudition delinquent, explicitly, the elucidations of αiand αjfor SVM in (3).
3.3 SR Transformation
This section concisely presents the SR procedure for HSI classification with the rationalized functionality.Therefore, an indefinite trial illustration x∈RB,where B is the number of spectral groups,given as a sparsely lined grouping for all of the training pixels as

where A = [α1,α2, ..,αN]∈RB×Nis an organized dictionary with columns {αi}(i= 1,....., N)are N training illustrations from every classes, and α∈RNis an indefinite sparse trajectory.The index customary on which α has nonzero accesses is the provision of α.The amount of nonzero entries in α is termed as the scarcity phase k of α and symbolized via k= ||α0||.For the dictionary A, the sparse measurement route α is acquired by deciphering

where K0 is a predetermined superior bound on the sparsity stage.The delinquent in (5) is NP-hard and is practically resolved by greedy procedures.The class mark ofis resolute by the nominal residual amongbesides its estimate from every class subdictionary:

where Ωm⊂{1, 2, ...,˙n} is the key customary allied with the training illustrations that belong to themth class.
3.4 SSNNs Transformation
For n-dimensional data points {x1,x2,...,xN}, SSNNs determines [19] to discover a revolution matrix A = [a1,.,...., ad]that plots the N points to {y1,y2,...,yN} in a lower-dimensional subspace Rd, where yi= AZxiand {y1,y2,...,yN} conserves the native neighborhood arrangement (i.e.,adjacent association) as {x1, x2,..., xN}.The objective utility of SSNNs is in this manner:

where W is a symmetric˙n×˙n matrix and Wijdenotes the load of the edge linking apexes xiand xj.The parallel array W is generally calculated established on the heat kernel utility

where σ is the heat kernel constraint.The objective utility (7) is simplified as
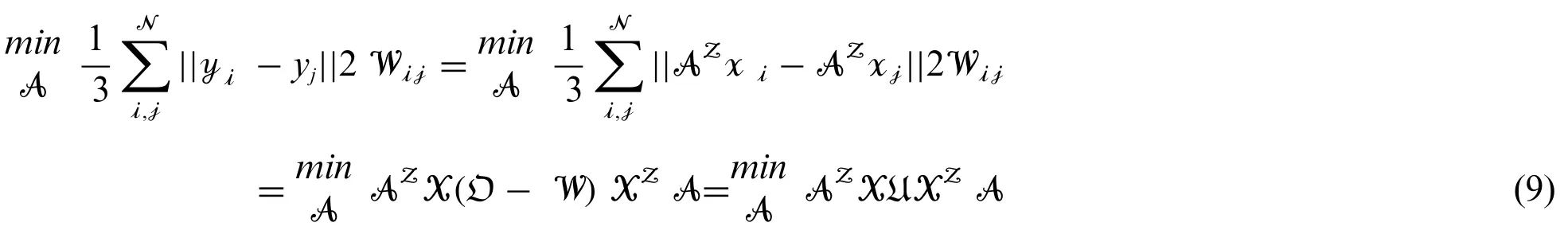
where X = {x1,x2,...,xN}, O is a diagonal matrix using Oii=ΣjWij, U = O - W is the Laplacian matrix.
4 Results: Experimentation on HSI Data Sets
The data set of Indian Pines comprises 143×143 pixels with 218 spectral groups.Nearby 16 classes are present in the data customary.For each class the amount of illustrations arrays from 18 to 2453.The University of Pavia data customary comprises 608×338 pixels with 113 spectral ensembles.For each data set, there are nine modules, and the number of illustrations arrays is from 947 to 18 649.For evaluation, we deliver the outcomes of SVM [10], SR [12], SSL [4], NNs [13] and FDLM.The URL of the dataset used is http://www.ehu.eus/ccwintco/index.php/Hyperspectral_Remote_Sensing_Scenes.Forboththedatasets,weerraticallyselect150testillustrationswithvaryinglabelsfortraining.Fig.3 depicts the Indian Pines data customary with its three-band false-color intricate, the ground reference data and the University of Pavia data set with its three-band false-color complex and the ground reference information.The Fig.4 depicts the Indian Pines data customary with its three-band false-color complex and the Ground reference data, the University of Pavia data customary with its three-band false-color complex and the ground reference data.

Figure 3: Indian Pines data set: (a) Three-band false-color complex.(b) Ground reference data.University of Pavia data customary: (c) Three-band false-color complex.(d) Ground reference data
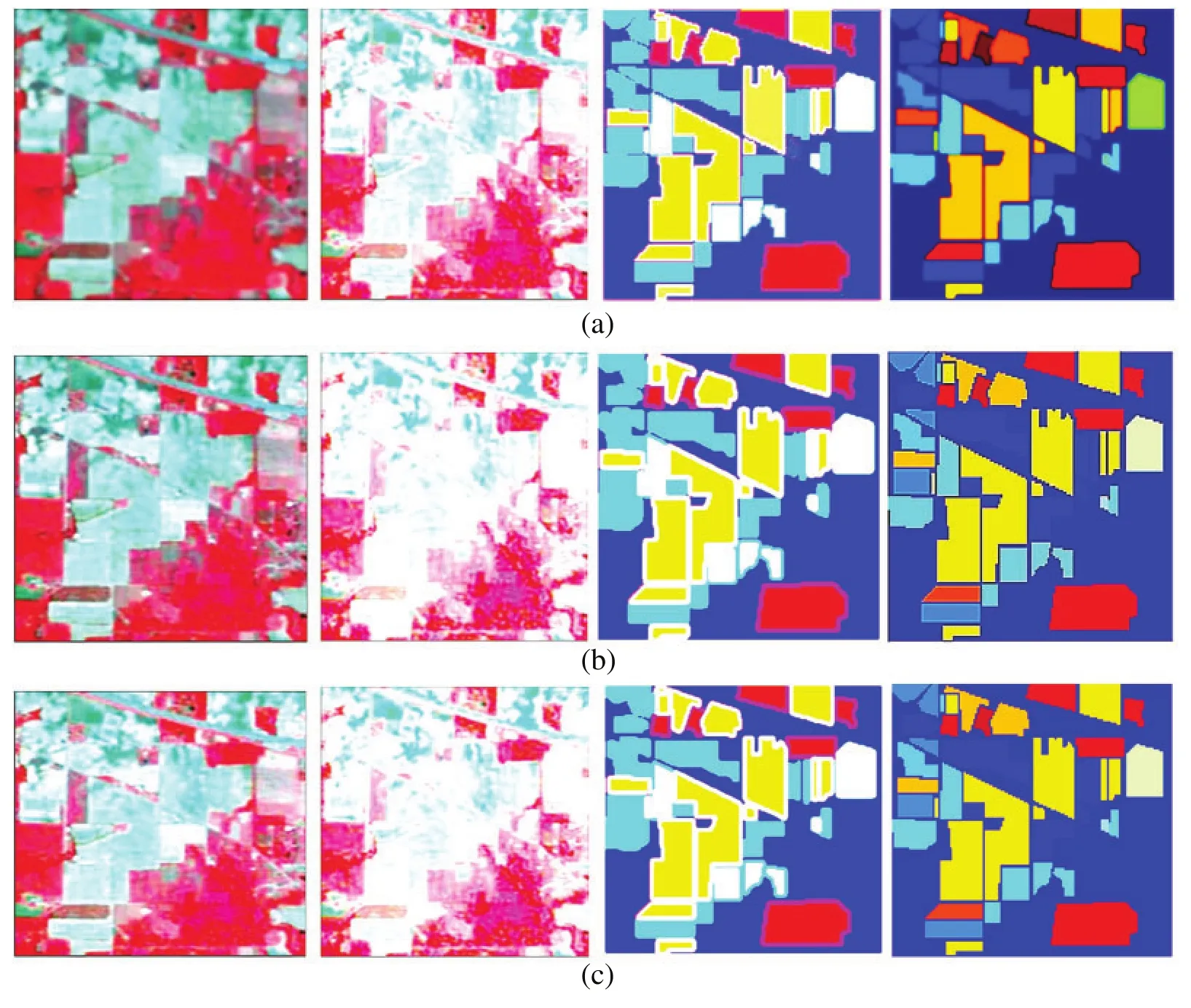
Figure 4: (Continued)

Figure 4: Indian Pines data set: (a) Three-band false-color complex.(b) Ground reference data.University of Pavia data set: (c) Three-band false-color complex.(d) Ground reference data
The University of Pavia data customary, which detects an urban expanse adjoining the University of Pavia, Italy, was composed by the ROSIS-03 sensor in Northern Italy in 2001.
This site is of dimension 608×338×113 with a 3-D resolution of 1.3m per pixel and spectral analysis extending from 0.43 to 0.86 μm.This imagery comprises 9 modules of concern and has 103 spectral ensembles after eliminating 12 appropriate noisy groups.Tabs.4 and 5 respectively demonstrates statistics on the quantity of training and test illustrations for the diverse modules of concern.150 illustrations per class are erratically elected as the training illustrations and the rest of the illustrations as the test illustrations.
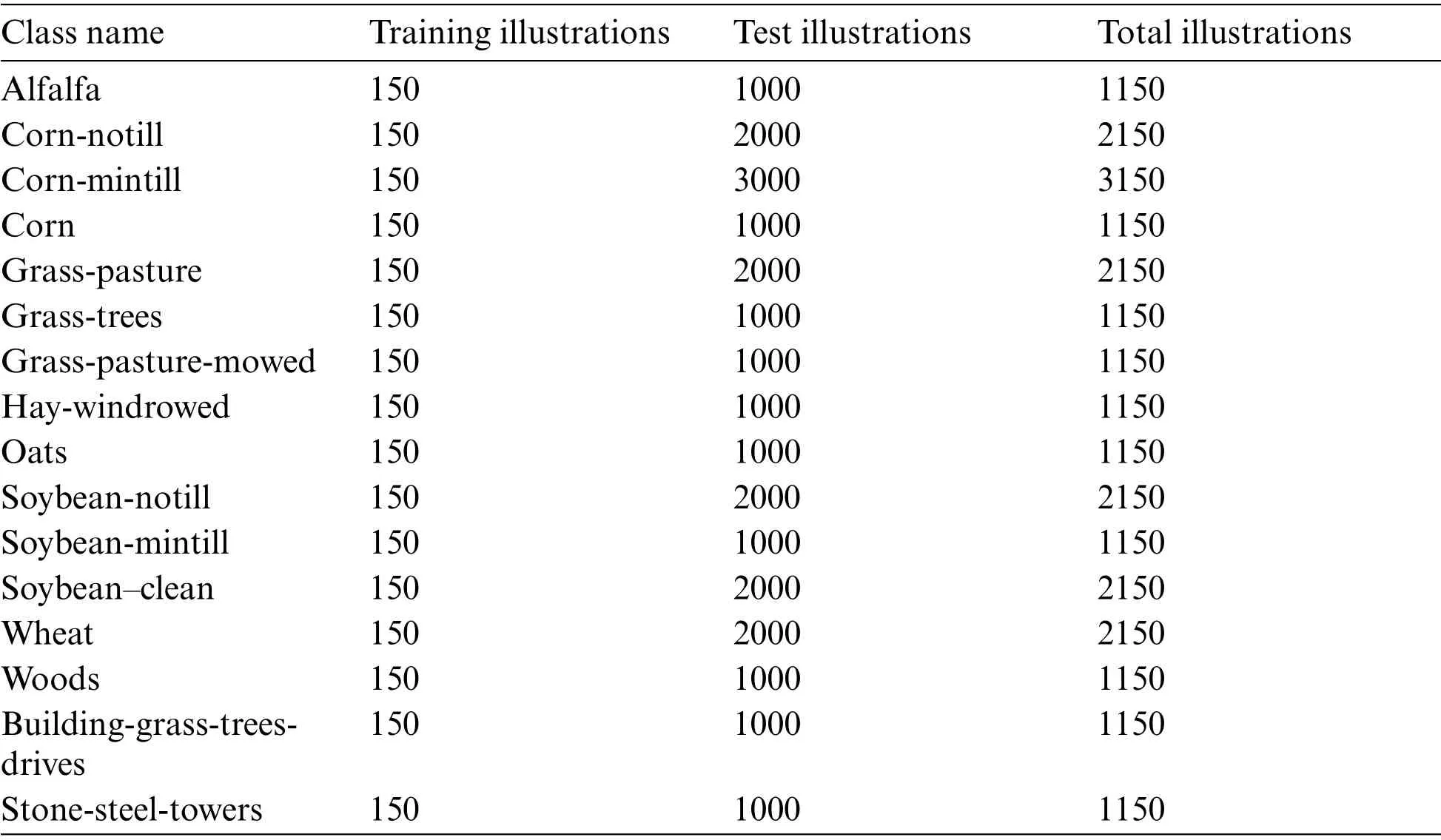
Table 4: Number of training and test illustrations used for the AVIRIS Indian Pines data customary
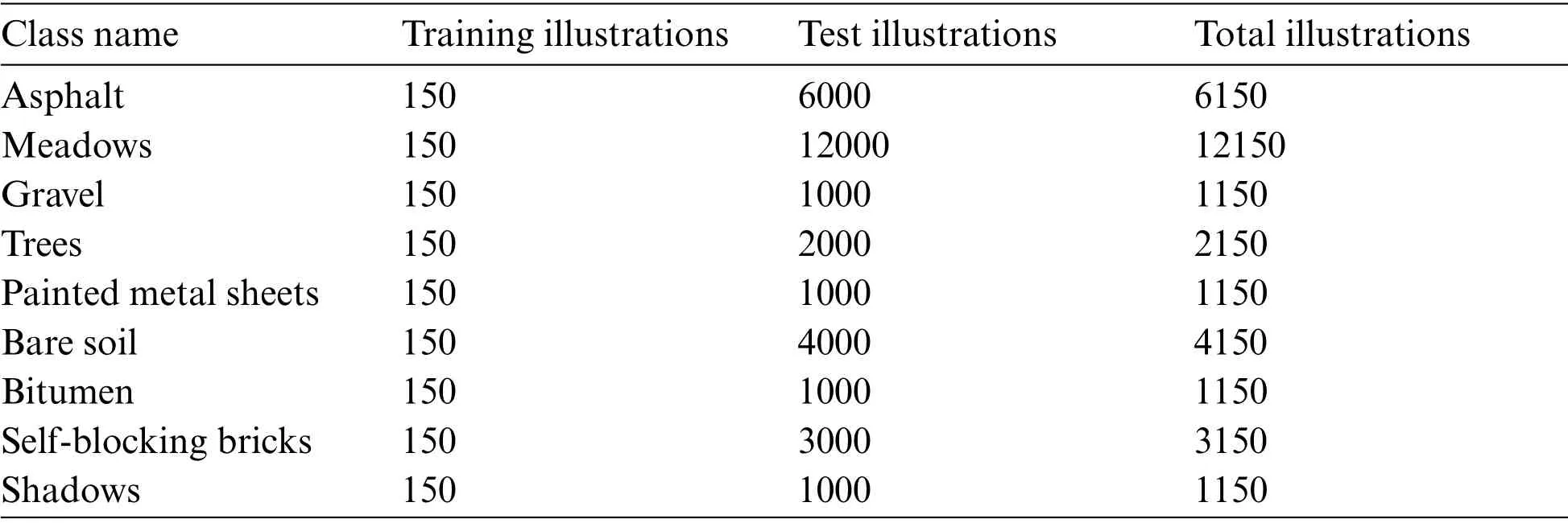
Table 5: Number of training and test illustrations explored for the Pavia data set
Fig.5 illustrates the Classification results achieved by various methods for the Pavia data set that includes well-known approaches like SVM, SR, SSL, NN and the proposed approach i.e., FDLM.To equate the efficacy of diverse approaches, we practice the average taxonomy accurateness (AA) of all modules, the overall taxonomy accurateness (OA), and the kappa coefficient (κ).For every technique,we run five loops and the outcomes are specified as mean with typical deviations.

Figure 5: (Continued)

Figure 5: Classification results accomplished by assorted methods for the Pavia data set (a) SVM (b)SR (c) SS (d) NN (e) FDLM
Tab.6 offers quantitative outcomes of numerous approaches on the imagery, where three metrics, i.e.,OA, AA, andKappa coefficient, are espoused to estimate the taxonomy enactment.The compared methods comprise standard methods such as SVMs, SSL, neural networks, and sparse illustrationcentered classifiers that are extensively exploited in the HSI examination however never analytically using a quantitative and comparative approach scrutinized.
From the above experimental results, the proposed method demonstrates great benefits over other traditional approaches concerning visual taxonomy maps and computable outcomes.For instance,considering that in the evaluation of numerous classifiers, including SVM, SR, SS, NN, the proposed approach executes the finest on three hyperspectral datasets, which is exploited to authenticate the efficacy of deep aspects equated with hand-crafted aspects.FDLM provides an enhanced enactment than what was acquired by the other four traditional-centered approaches on the AVIRIS Indian Pines and Pavia imageries.The classification accuracies are defined in Tab.6 for the various approaches like SVM, SR etc.and the proposed approach i.e., FDLM.The Tab.6 clearly illustrates the advancement of the proposed method over the existing techniques.wherePBERis the quadrature amplitude modulation(QAM) BER.

Table 6: Classification accuracies (in percentages) obtained by SVM [10], SR [12], SSL [4], NN [13]and FDLM on the Pavia imagery
The foremost inference that is attained from the present learning is that no classifier reliably delivers the unsurpassed enactment between the reflected metrics (predominantly, from the perspective of classification accurateness).As an alternative, diverse elucidations be contingent on the complication of the exploration situation (perhaps, the accessibility of training illustrations, dispensation necessities, alteration parameters, and rapidity of the procedure) and the considered solicitation province.United, the insights delivered in this article may enable the assortment of an unambiguous classifier by a client reliant on researcher expectations and exploitation objectives.Nonparametric classifiers for instance SVMs and RF have chiefly verified to deal fine with the higher dimensionality of the silhouettes.Recently, SVM with complex kernels and SR taxonomy are anticipated, leading to precise and vigorous outcomes even in circumstances of an abridged integer of training illustrations.Classification with SVMs requires a convex blend of kernels and a period-consuming enhancement practice.One disadvantage of the SVM is regulating the key constraints.Besides, the selection of the variable constraint C, which drafts the transaction among exploiting the margin and abating the training error, is extremely imperative.On the other hand, SR needs adequate redundant information and features necessities to be alienated into distinctive interpretation leading to a time wastage.SSL has an extraordinary cost of computational and the feature assortment is classifier reliant.Their practice is conventionally influenced by their training and algorithmic intricacy.NNs has slow convergence and the likelihood of sinking in local minima, particularly when the constraints of the setup are not accurately fine-tuned.On the contrary, FDLM are relatively flexible, and handles diverse circumstances, such as huge characteristics, very restricted training illustrations, and trivial or huge data sets.Besides, they are easy and rapid to assess.The benefit of FDLM over contemporary techniques is that FDLM is independent of the familiarity about the statistical scattering of the classes and feasible to training practices for nonlinearly distinguishable data.
5 Conclusion and Future Directions
In this paper, we have delivered an assessment and acute evaluation of diverse hyperspectral taxonomy methods from a diverse perspective, with specific prominence on the outline, promptness,and accuracy of several algorithms.The acute assessment accompanied in this effort hints to stimulating indications about the rational choice of an appropriate classifier centered on the solicitation at hand.Explicitly, these SR frameworks exploited in the HSI taxonomy are alienated into spectralaspect systems, 3-D feature grids, and spectral and 3-D feature networks, where every class mines the equivalent aspect.With this structure, we can effortlessly see that NNs make complete usage of diverse aspect categories for taxonomy.We have likewise equated and analyzed the enactments of numerous HSI taxonomy approaches, comprising three traditional approaches.The classification precisions acquired by diverse methods validate that the anticipated method outperforms the contemporary procedures and achieves the best classification performance.In addition, because accessible training illustrations in distant recognizing are generally very restricted and training NNs necessitates a huge number of illustrations, we likewise incorporated certain policies to advance classification enactment.We have correspondingly conducted trials to authenticate and equate the efficacy of these approaches.
The outcomes show that FDLM attains the utmost enhancement among all methods.Nevertheless, the anticipated methods are explicit to certain aspects (i.e., expanse and standard deviation) and might be irrelevant to others, consequently opening the necessity for emergent additional standard assortment approaches for the filter constraints.Though edifying, FDLMs are characteristically customary of extremely dimensional and redundant aspects.So, these aspects must be appropriately controlled to a mark complete exploration of the edifying content of the profiles.So, the assortment of the classifier is an additional crucial characteristic to cogitate.To decrease the redundancy of the APs,chiefly when considered in their protracted design, it has been anticipated to practice dimensionality decrease methods.In conclusion, although the FDLM has verified to be operative in the scrutiny of distant distinguishing imageries predominantly for classification, many areas of study remain as a future scope [22-26].
Funding Statement:Mohd Abdul Rahim Khan would like to thank Deanship of Scientific Research at Majmaah University for supporting this work under Project No.R-2021-298.
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
杂志排行

Computers Materials&Continua的其它文章
- Constructing Collective Signature Schemes Using Problem of Finding Roots Modulo
- Modeling and Simulation of Two Axes Gimbal Using Fuzzy Control
- Artificial Monitoring of Eccentric Synchronous Reluctance Motors Using Neural Networks
- An Optimal Scheme for WSN Based on Compressed Sensing
- Triple-Band Metamaterial Inspired Antenna for Future Terahertz (THz)Applications
- Adaptive Multi-Cost Routing Protocol to Enhance Lifetime for Wireless Body Area Network