YOLOv4煤矸石检测方法研究
2022-08-24蔡秀凡谢金辰
蔡秀凡,谢金辰
(1.神马实业股份有限公司帘子布公司,河南 平顶山 467000;2.西安科技大学 通信学院,陕西 西安 710600)
矸石是在成煤过程中与煤层伴生的黑灰色岩石,开采出的煤炭中难免会夹杂有矸石成分。矸石含量过高不仅会使煤炭商品价值降低,还会造成煤炭燃效效率低下,严重污染环境;同时,矸石在带式输送机转载过程中容易造成胶带破损,产生安全隐患[1]。矸石具有密度大、发热量小的特性,主要成分包括:二氧化硅、三氧化二铁、氧化钙等氧化物和微量稀有元素[2]。
对于煤矸石检测方法的研究,国外起步稍早于国内,目前比较有代表性的方法有:射线法、光谱探测法以及图像识别等[3]。孔力[4]等提出中、低双能γ射线透射法煤矸石在线识别与分选系统。光谱探测法的原理是由于煤和矸石的光谱差异大,并以此区分二者;申利飞[5]等人提出了基于加权方差的煤矸石X射线图像分形维数最优估计方法,仿真结果表明,采用该方法进行煤矸石X射线图像分形维数估计的精度较高,提高了煤矸石X射线图像的识别和检测能力。宋亮[6]等提出联合分析可见-近红外和热红外光谱通过两次分类实现煤与矸石区分。Hobson D[7]等人研究发现在煤矸石图像中,两者的灰度和纹理特征存在差异,从而可达到识别的效果。Tripathy D[8]等人提出将灰度共生矩阵运用于提取煤矸石图像特征,将提取到的5种纹理特征与颜色相结合,最后通过神经网络进行识别和分类。丁泽海等人[9]通过计算煤矸石图像的灰度直方图,从中提取灰度均值和标准差指标,研究发现,煤炭的灰度均值明显小于矸石的灰度均值,因此可以作为煤矸分选的依据。吴景涛[10]等利用灰度共生矩阵提取煤矸石图像的角二阶矩、相关性、对比度和熵4种纹理特征,并以此作为支持向量机的识别依据进行分类。余杰[11]提出将煤岩图像进行多尺度分解并结合灰度共生矩阵的方式进行特征抽取,最后通过SVM和改进的BP神经网络进行分类。惠洪超[12]在前人对于特征提取的基础上采用基于权值剪枝的神经网络压缩策略,并运用稀疏矩阵进行存储和运算,提高了识别网络的速度。煤矿实地调研结果表明,射线法所需设备系统昂贵,并且射线对人体有害;光谱探测法的系统复杂、步骤繁多;传统的图像识别法需要人工设计提取特征,识别的准确率依赖设计者的算法和经验[13]。
自2012年以来以卷积神经网络为代表的深度学习算法在图像识别领域展示出强大的潜力,现在已在各个行业得到了广泛应用[14],计算机视觉领域的技术也不断发展成熟,大量针对图像处理方向的学者将特征提取工作向卷积神经网络模型转型,抽象特征数据通过卷积神经网络也能够自主获取[15],单鹏飞等人[16]提出改进的Faster R-CNN模型、郜亚松[17]提出的将Mobile Net v3与YOLOv3相结合,以及来文豪[18]等人提出的将多光谱成像与改进的YOLOv4相结合的目标检测模型均能够在煤矸石检测和分类的任务中均有较好的效果。本文通过在手选胶带处搭建视频采集系统,对煤矸传送中图像大量采集后进行基于深度学习的煤矸图像的识别,通过特征卷积提取的方法,及改进算法克服了小块物体无法识别的问题,最终将图像识别系统在手选胶带上进行系统测试。
1 煤矸石数据集采集与标准化
在煤矿手选胶带处实地采集煤矸石图像作为训练集,初筛后剩余煤炭图像800张,矸石图像550张,煤和矸石混合图像500张。
获得数据集后,需要对其进行标准化处理,包括统一尺寸、图像增强、格式统一等。其中,图像增强是为了增强图中的重要信息,减弱或除去某些不需要的信息,首先采用中值滤波器去噪,然后采用Gamma变换提升暗部细节,输出图像的灰度值:
式中,Vin为输入图像的灰度值;A为系数,一般取值为1;γ为Gamma变换值,通过取值不同对图像达到不同的处理结果。
不同的图像采集设备获取的图像格式和尺寸存在差异;当图像尺寸不断变大时,模型学习量增大,但是当图像尺寸过小时,又会丢失掉原图中的一些细节信息,所以需要统一图像的尺寸和格式。将图像裁剪到适合的尺寸送入模型训练,并通过Labeling标注数据集生成VOC格式。经过对比,将图像尺寸固定在512×512能够保留煤矸石图像的细节信息。原始图像与经过上述处理后的图像效果如图1所示。可以看到,处理后的图像效果更好,暗部更为清晰。

图1 煤矸石图像标准化
2 DCGAN数据集扩充
由于深度学习对于数据集数量要求很大,还需要对标准化处理后的煤矸石数据集进行扩充;目前数据增强的方法主要有:翻转、旋转、缩放、平移[19]等;本文在传统数据增强手段的基础上,采用基于深度卷积生成对抗网络(DCGAN)的数据集扩充方法,最终达到煤矸石数据集量大且标准的要求。DCGAN由生成器G、判别器D两部分组成,其核心思想是通过G和D相互竞争,最终达到纳什平衡[20]。DCGAN的训练过程如图2所示。生成器输入随机噪声,经过不断反卷积(fractional-strided convolution)过程,最终生成图像;判别器则相反,输入图像经过不断卷积提取特征进行判别,经过全连接层处理后通过sigmoid函数输出图像的真假概率。
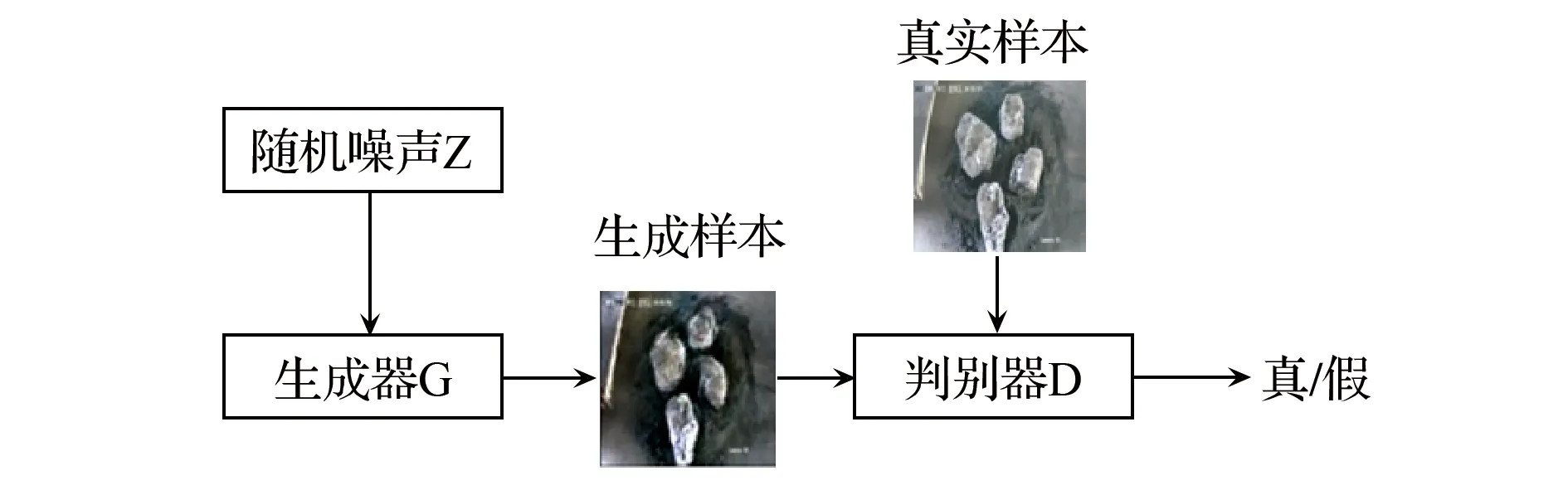
图2 DCGAN训练过程
DCGAN的损失函数采用的是交叉熵损失函数,生成器G与判别器D的优化目标可以表示为:
Ez~pz(z)[lg(1-D(G(z))]
(2)
式中,Ex~pdata(x)为真实数据分布的数学期望;Ez~pz(z)为输入噪声数据分布的数学期望;D(G(z))、D(x)为分别为判别器判别生成数据与真实数据的概率。
由于生成器最终的目的是达到以假乱真的程度,此时D(G(z))应尽可能的大(理想值为1),而D的目标是鉴别能力达到最强,此时D(G(z))应尽可能的小(理想值为0)。由于V(G,D)是连续的,将其写成积分形式:
设生成器G(z)生成的数据是x,定义输入噪声z的生成分布为pg(x),则:x=G(z)⟹z=G-1(x)⟹dz=(G-1)'(x)dx、pg(x)=pz(G-1(x))(G-1)'(x);将其代入(3)式中,同时固定生成器G,对判别器D进行优化,整理后可得到判别器D的最优解函数:
式中,pdata(x)为真实数据的分布;pg(x)为生成数据的分布。
此时D已经取得最优解,即D*(x)=0.5,现对G调整,寻求G的最优解,经过化简和等效代换后,引入JS散度得:
由此可知生成器网络的最小值为-lg4,G和D均达到了最佳状态,证明DCGAN训练方法可行。
DCGAN模型训练过程中的损失函数变化折线如图3所示,经过前5000次迭代,生成器的损失值较低,此时生成器能够仿照真实数据生成相类似的图像;鉴别器的损失值也在不断下降;在5000次迭代后,两个损失值整体趋于平衡但局部是在不断震荡变化,表明生成器的输出数据并不稳定,此时生成器与鉴别器在相互制约、竞争,最终为了达到纳什平衡。

图3 基础 DCGAN 模型训练损失函数变化
图像扩充基于Pytorch框架,所有的实验与训练评估是在计算机配置为系统:win10 64-bit、处理器:Core i5-9300HF 2.40GHz上进行的,实验IDE使用的是Pycharm 2020.3;实验中用到的python库有:Torch 1.2、numpy 1.19.5、opencv 4.5.1.48。最终生成图像如图4所示。经过传统图像扩充以及DCGAN扩充后,数据集共包含5550张煤矸石图像,其中煤炭图像2100张,矸石图像2450张,混合图像1000张。

图4 DCGAN生成图像
3 煤矸石识别平台搭建
在原有的数据集基础上进行扩充标准化后可送入后续的目标检测模型进行训练;本文采用YOLOv4目标检测模型;YOLO系列以其检测速度著名,能够满足本课题实时检测的需求,YOLO网络结构由24个卷积层与2个全连接层构成,YOLOv4是在v3的基础上从数据预处理、骨干网络、特征融合、网络训练方法、激活函数、损失函数等方面做出一系列改进;YOLOv4首先通过骨干特征提取网络提取输入图像的特征,然后将图像划分为s×s的网格,每个单元格负责检测中心落入网格的目标,骨干网络中选取三个检测通道进行特征融合操作,分别对应大、中、小三个尺寸的目标物体。由于YOLO系列对于小目标物体检测存在固有的缺陷,而本课题实验环境中经常会出现小块煤矸石,因此提出分别对骨干网络结构以及特征融合方法进行改进。
基础YOLOv4网络选取骨干网络中3个特征层作为检测通道,分别对应划分13×13、26×26以及52×52的网格,而在检测图像中物体的像素低于小尺寸检测通道的像素时,就会发生漏检的问题。因此,在YOLOv4骨干网络的基础上添加一个检测通道作为检测微小物体的特征层。以输入图像尺寸416×416为例,最终的4个检测通道特征层尺寸为(13,13,1024)(26,26,512)(52,52,256)(104,104,128)。添加一个检测尺度后的实验对比结果如图5所示,其中图5(a)为基础YOLOv4检测结果,图5(b)为添加13×13预测尺度后的检测结果。

图5 改进YOLOv4网络结构
由图5可知,基础YOLOv4目标检测模型存在小目标漏检的问题,经过初次改进,YOLOv4能够检测出尺寸更小的煤矸石,但是检测精度与实际应用场景所需精度相差较大,因此,进一步在主干网络中不同尺度的公共卷积层后加入SE(Squeeze-and-Excitation)注意力机制,SE模块用于增加通道维度上的注意力机制,辅助网络为输入特征图的不同通道分配不同的权重,并有效地融合输入特征图的不同通道信息,使网络学习到不同通道特征的重要程度,进一步增强网络的特征提取能力。SE模块是通用的,可以很便捷的嵌入到现有的网络架构中。SE机制模块的流程如图6所示。

图6 SE模块结构
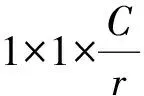
式中,H,W分别表示特征图的高度和宽度;uc表示特征图的第c个通道;zc为Squeeze的特征向量;Excitation操作的公式:
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1×z))
(7)
式中,W1,W2表示区分两次全连接操作;z表示Squeeze操作的输出;δ,σ分别代表ReLU激活函数与Sigmoid激活函数。改进后的YOLOv4网络结构如图7所示。
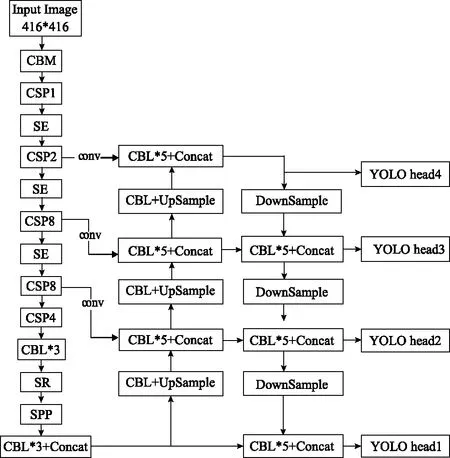
图7 改进YOLOv4网络结构
其次,先验框的大小对于YOLOv4目标检测非常重要,原始先验框是通过对VOC数据集进行聚类得到的。由于原始VOC数据集中的类别数量较多,大小差异较大,聚类得到的初始锚框也存在较大差异。为了提高实验的准确性,采用k-means算法对自制数据集进行聚类,并不断增加聚类中心的数量。经过多次迭代,得到聚类中心。对煤矸石数据集在图像中长宽归一化处理后的分布,结果如图8所示,颜色的深度对应煤矸石的数量,由图8可知,数据集中小块煤矸石所占比重较大,根据此特点,采用K-means聚类算法对初始锚框进行处理,设置4个聚类中心,生成针对本课题煤矸石数据集的初始锚框参数,用以提高目标检测模型的精度与速度。经过K-means聚类算法处理后得到的12组初始锚框参数见表1。
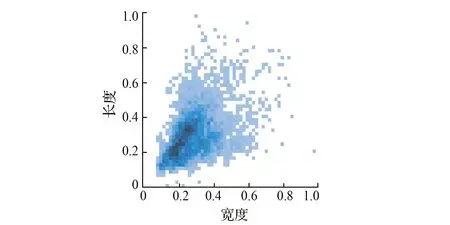
图8 煤矸石长宽归一化分布
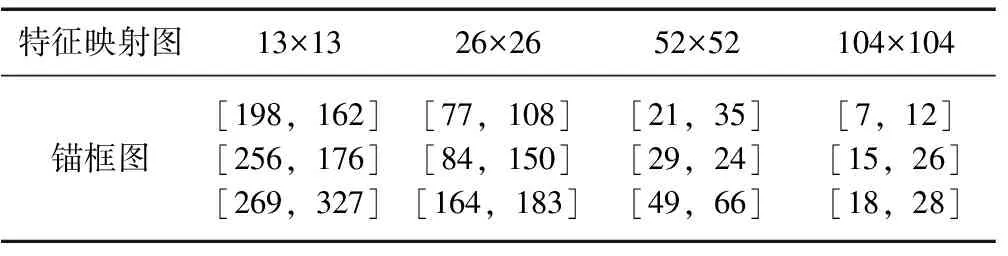
表1 K-means聚类算法处理后初始锚框参数
4 YOLOv4煤矸检测结果
测试环境为煤矿场的手选胶带处,目标检测模型的训练及调试在Win 10操作系统下完成,采用的开发框架为Pytorch。配件配置为:中央处理器(CPU);图形处理器(GPU):NVIDIA GTX1660Ti。数据集共5550张图像,按照9∶1划分为训练集与验证集,同时采用YOLOv4的Mosaic数据增强方法增加数据集的丰富性。模型训练参数参考其他采用YOLOv4算法的参数设定,共设定100个epoch,权重衰减系数为5×10-4,批处理大小为16,lr=1×10-3。
使用基础YOLOv4对训练集数据完成训练后,对本实验煤矸石检测结果的准确率(Precision)、召回率(Recall)进行检验:
准确率=正确检测煤矸石的数量/(正确检测煤矸石的数量+错误检测煤矸石的数量)
召回率=正确检测煤矸石的数量/(正确检测煤矸石的数量+漏检的煤矸石数量)
共检测550张煤矸石图像,其中共包含840块煤矸石,检验结果如下:正确检测煤矸石数量750,错误检测煤矸石数量47,漏检煤矸石数量43,准确率94.1%,召回率94.5%。
通过对基础YOLOv4的实验可以发现,漏检的基本上都是小块的煤矸石,与是采用针对此问题的改进YOLOv4算法进行实验,实验过程中的各项损失曲线如图9所示,横坐标表示迭代epoch次数,纵坐标分别表示锚框回归、置信度、分类概率损失值,其值越接近0,表明训练收敛效果越好。
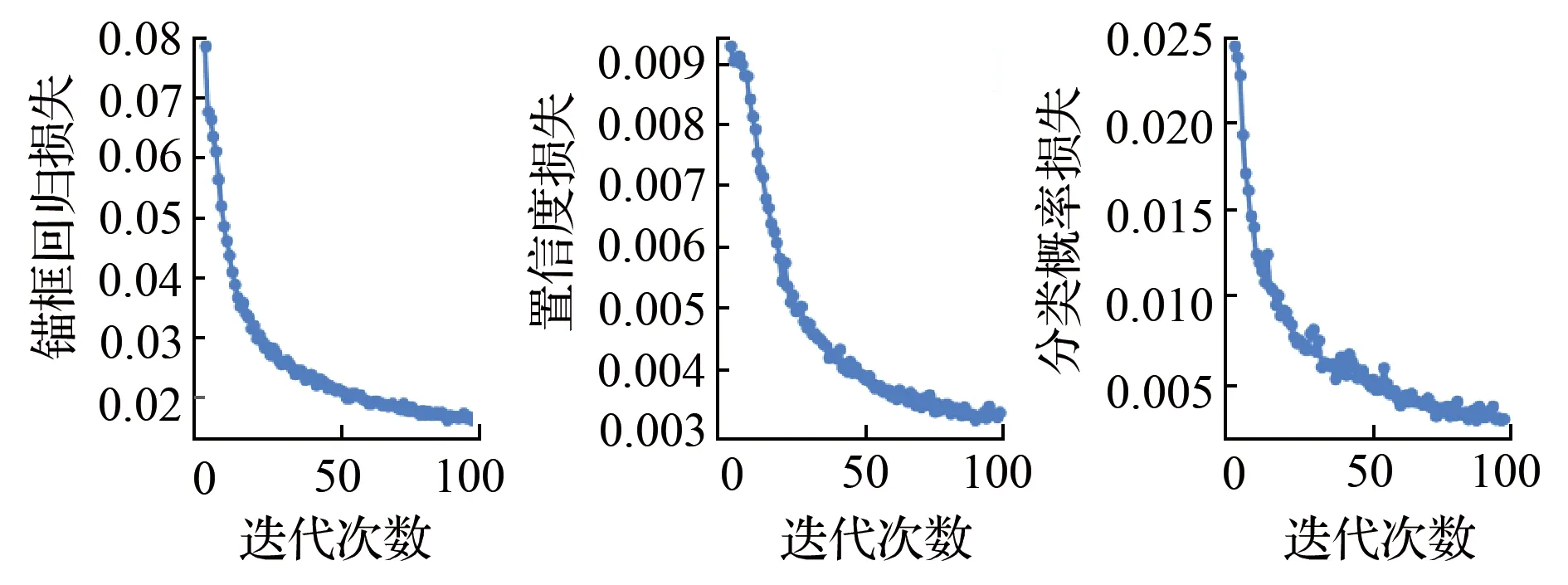
图9 改进YOLOv4的各项损失曲线

图10 改进YOLOv4实验结果对比图
同样使用改进的YOLOv4算法对550张煤矸石图像进行检测,检验结果如下:正确检测煤矸石数量791,错误检测煤矸石数量39,漏检煤矸石数量10,准确率95.3%,召回率98.7%。改进后的目标检测算法克服了基础算法针对小块煤矸石检测漏检的缺陷,在提高小目标检测精度的同时也提高了整体的检测精度。为了更加清晰地展现添加SE注意力机制后的改进效果,实验截取两组结果进行对比,如图10所示,图10(a)为未添加SE注意力模块检测结果,图10(b)为添加SE注意力模块后的检测结果。最终测试结果如图11所示。

图11 改进YOLOv4检测结果
5 结 论
1)针对煤矸石图像数据集样本不足,煤和矸石数量不成比例的问题,提出通过DCGAN模型对数据集进行扩充,提高煤矸石图像识别模型的质量与多样性。
2)针对YOLOv4目标检测模型存在对于小块煤矸石漏检的缺陷,提出在主干网络中添加一个检测通道用于针对小目标检测,以及在主干网络中不同尺度的公共卷积层后加入SE(Squeeze-and-Excitation)注意力机制,同时采用K-means聚类算法生成针对本文煤矸石图像的初始锚框参数,最终通过实验表明,改进的YOLOv4算法能够克服较小煤矸石目标漏检的问题,有效提升了小块矸石的检测精度。
3)通过深层卷积神经网络对煤和矸石进行了特征提取,并能较准确的分类,在光线良好的情况下,排序后的煤矸石检测准确率可以达到95%以上。基于卷积神经网络的图像分类模型,存在对图片质量,标注准确性的严重依赖,需要随着训练集的更新不断更新,否则会大大降低准确率,如何形成有效的通用学习神经网络,使网络能够自主更新,自适应环境变化,是煤矸分类检测下一阶段研究重点。
