日志多维度无监督异常检测算法
2022-08-24邱连涛李晓戈胡飞雄胡立坤张东晨马鲜艳
邱连涛,李晓戈,胡飞雄,胡立坤,张东晨,马鲜艳
1(西安邮电大学 计算机学院,西安 710121)
2(陕西省网络数据分析与智能处理重点实验室,西安 710121)
3(深圳腾讯计算机系统有限公司 智能化运维,广东 深圳 518000)
4(腾讯科技(上海)有限公司,上海 200030)
E-mail:lixg@xupt.edu.cn
1 引 言
在互联网高速发展的时期,服务器的数量也高速增长,运维压力不断增大.很多互联网公司的运维人员面临着一人维护数万台服务器的工作量.在产品开发流程中,开发人员和运维人员往往不是同一部门,因此对于系统输出的重要日志数据,运维人员难以针对日志内容做出有效的检测和分析.随着人工智能的发展和各种海量运维数据的产生,智能运维(Artificial Intelligence for IT Operations,AIOps)[1]这一理念被提出:使用基于机器学习、深度学习等算法,对海量的运维数据自动且高效的学习其内在规则,提出合理决策,辅助专业人员进行运维.
在计算机系统中,及时有效地发现系统事件中的异常行为,对于维护系统稳定运行有着重要作用[2].系统日志作为记录系统运行信息的重要资料,是对系统进行异常检测的主要数据来源.早期独立系统的异常检测,往往依赖开发者凭借自身知识人工检查或编写相关规则抽取日志中的异常信息;现阶段服务器系统已经发展为大型的服务器系统集群,在大量的日志量下依然进行手工检索意义不大并且效率低下.因为现在服务器系统的大规模和并行性,一个复杂的系统由成百上千的开发人员实现,单一的开发人员或异常人员难以理解大部分的日志数据[3];同样大型系统产生新数据量的速度非常快,每小时数据量甚至达到了GB级[4],人工检索的处理速度远远不够.同时某些异常错误在日志中出现时,往往是之前的某些操作造成的,增加了手工分析日志的难度.
因此,如何获得高效准确的日志异常检测方法一直是智能运维方向研究的热点[5].研究中,根据数据是否有标注的区别,异常检测方法可分为基于监督的方法和基于无监督的方法[6].在现实情况中,为了适配大规模的服务器集群和多个业务领域,企业没有足够的时间和人力对每一个数据集都做相应的适配,所以有监督的方法难以适用于工业领域.基于无监督的方法不需要数据标注,通过区分异常实例与其他实例的特征距离,定位相关异常数据.
针对以上情况,本文设计实现了一种基于无监督的日志多维度异常检测算法.该算法可以基于不同日志数据源,自动进行日志解析,模板抽取,并通过统计机器学习的异常检测方法发现系统运行过程中的日志所反映出的异常行为.针对日志异常数据的单点指标异常,日志组异常和行为序列异常采用多种异常分析方法发掘.识别单点指标异常是通过使用统计学方法统计系统日志中变量的概率分布,然后生成正常阈值区分出异常值.日志组异常是通过以时间窗口分割的日志组中各类日志数量关系的异常.行为序列异常则是通过日志的历史数据通过算法生成日志输出的行为模式,并以此来验证系统的行为.本算法针对日志数据的流式输出有增量处理方法,可以在日志输出的过程中不断通过历史数据检测新的异常.
2 相关工作
日志的异常检测工作按流程顺序依次为日志收集、日志解析、特征提取及异常检测.日志通常由大型系统自动生成,每条日志包含了该日志的时间戳和发生具体事件的日志消息信息.收集这些日志作为原始数据集进行后续的日志异常检测工作.由于日志消息是非结构化文本,日志解析的目的是提取一组日志的事件模板,对原始日志进行结构化分析.
目前主流日志解析方法可分为离线方法和在线方法,其中离线方法又分为基于规则的和基于聚类的方法:程世文等[7]提出使用正则表达式的方法识别日志模板,但是对于正则表达式的创建和更新难度随着日志量的增加而增加;首个基于聚类的日志解析算法SLCT由Vaarandi等提出[8],通过对日志中出现频率超过阈值的相同单词集合进行聚类来提取日志模板;Makanju等提出基于分层聚类的IPLoM算法[9],通过对日志的消息长度、令牌位置、映射关系逐层迭代进行聚类,相比SLCT的优势是不需要阈值设置.离线方法的局限性在于其算法均需要脱机解析,无法进行实时的异常检测,且对于新出现的日志类型需要重新训练.为满足现实的工业需求,提出了可以实时解析以便及时进行后续的异常检测的在线方法:Du等提出了基于最长公共子序列的方法在线对日志进行聚类的Spell算法[10,11];He等于2017年提出了基于深度固定树的思路对日志聚类的Drain算法[12];Zhang等于2017年提出了频繁模板树(FT-Tree)模型[3],通过提取日志中频率较高的单词的最长组合来获得日志模板;Meng等于2019年提出了基于同义词和反义词集的模板词嵌入模型Template2Vec[13],将其与FT-Tree结合生成日志模板向量.Studiawan等提出使用基于图数据的结构判断日志间相似性,通过聚类自动化提取日志模板[14,15].
将日志解析为单独的事件后,需要进一步的将日志编码为不同的特征向量以供后续的异常检测算法应用,特征包括日志的顺序特征、变量值特征、窗口特征、共现矩阵等,不同的特征可应用在对应的异常检测算法中.
根据异常种类的不同,日志异常可分为:单点指标异常、日志组异常和行为序列异常.异常检测算法根据是否有带标注的训练数据分为有监督异常检测和无监督异常检测.有监督的异常检测模型准确度往往依赖训练数据的标注数量和准确,常见的监督方法有逻辑回归[16]、决策树[17]和支持向量机(SVM)[18]等.无监督的异常检测方法包括各种聚类方法[8]、关联规则挖掘[19]和主成分分析(Principal Components Analysis,PCA)[20]等,Lin等提出LogCluster方法[8],通过聚类日志来识别在线异常;Xu等首次将PCA方法应用于日志的组异常检测[20];Yu等提出的基于工作流的模型CloudSeer[21]通过发现交叉日志序列的错误确定异常;He等总结了当前异常检测的6种常见方法[6].近年也有学者将深度学习应用于异常检测领域,Du等提出了使用基于长短时记忆网络(LSTM)的深度学习模型DeepLog[22]对系统日志进行建模并进行异常检测;Meng等通过基于LSTM网络的异常检测模型LogAnomaly[13]实现了端到端的日志组与序列异常检测;梅御东等首次将CNN-text与日志信息结合应用于软件系统异常检测[23].
3 模型方法
日志解析的完整流程包括日志预处理、日志解析、特征提取、异常检测,本节中按照模块顺序分别讲解其主要算法和设计思路.图1介绍了本系统的流程架构及运行逻辑:对于原始日志文本,依次进行日志预处理、日志解析,特征抽取,根据抽取的特征分别对3种异常使用不同算法进行检测.
系统生成的原始日志属于非结构化数据,进行日志解析后可以得到日志的模板序号(LogKey)、日志模板、文本日志中的变量(例如:IP地址、路径、日期、时间戳、数值型变量、文本类变量等)及变量位置、日志文本分词后的结果一系列的特征数据,用于作为后面异常检测算法的数据输入,各个算法通过不同特征分析识别异常数据,最后合并算法的异常检测结果统一输出.图2简单概述了日志的预处理流程,左边部分为日志原始信息示例;经过日志解析后,得到中间的日志模板及对应序号;右边部分为日志的不同特征:顺序特征为原始日志对应模板序号的序列;变量特征为每个模板中对应变量值的集合;窗口特征为在划定的时间窗口内每种日志模板出现的频次;共现矩阵为日志模板的两两相隔距离矩阵.

图1 系统整体框架图Fig.1 Diagram of system overall framework

图2 日志预处理流程示意图Fig.2 Diagram of log preprocessing process
3.1 日志解析
日志解析是通过对原始日志中大量的纯文本进行分析,区别系统日志原本的固定句式和其中变量.通过日志解析可以筛选出原始日志中的变量类型和变量内容,用作于后期算法的输入数据,输出的日志模板也可以方便后期的数据研究.由于大量日志文本存在重复的模板,使用日志解析极大地减少了研究数据时的工作量.
本文的日志解析方法基于FT-Tree算法[3]思想改进实现:首先对原始日志数据预处理,包括分词、正则替换日志中固定格式的内容为对应类型标签节点.然后根据预处理后的日志构建初始模板树,对初始树的每层节点进行统计,超过阈值的视为变量并合并为对应变量类型标签节点.具体算法如表1所示.

表1 模板树构建算法Table 1 Template tree construction algorithm
该算法针对不同格式的变量设置有不同的合并阈值,数字型相比单词型拥有更小的阈值,因为它更有可能是一个变量.该算法支持离线处理和在线处理两种方式,在首次启动对某日志源进行处理时,会先根据算法1进行批量处理构建日志模板树.当有了初始的日志模板树时进行增量更新,仅需遍历新增节点及其兄弟节点,将日志分词短语加入日志模板树并在结束后启动合并分支,随后开始进行增量识别,每一条输入日志在分词之后从树的根节点进行匹配,标签节点则依据其格式进行匹配,若没有匹配项则新建节点,分词匹配完毕后,若有新增节点则对其父节点的子树遍历进行合并剪枝,即兄弟节点中超过阈值数量或比例的某一格式节点合并为一个标签节点,叶子节点的唯一标识号NodeID作为该模板的ID.当初始的日志模板树成型时,后期增量处理的大部分日志都是已识别的模板,相比重新批量处理效率显著提高.
系统每经过一时间周期t会将树结构转为JSON格式并导出该系统下的日志模板进行存储,可以保存在数据库中或者是文件系统中,下次启动时会读取所有模板数据并继续增量更新模式,实现快速的热启动.
3.2 单指标异常检测
单指标异常检测是对日志中的变量数值是否正常进行检测,其具体定义如下:
定义1.日志集DM,设某条日志Mi所属模板Lj的变量集合为X={x1,x2,…,xn},若Mi存在变量xk,使得P(xki|Xk)<η,则称Mi存在单指标异常.其中xki为Mi中xk的取值,Xk为Lj中xk的所有取值集合,η为异常概率临界阈值.
单指标异常检测算法基于日志源下统计每个日志模板的每个变量数值,利用3Sigma法分析数值,计算得出变量的概率分布,并基于概率分布通过算法找出数值的高概率分布区间,在区间之外找出其中的异常数值和离群数值.当系统中日志数量越多时,该算法的准确率会越来越高.
算法的输入为模板抽取的日志模板ID和日志分词原文,算法首先建立三维数组用于保存日志中的数值变量,其第一维度是日志模板,长度等于日志模板数量,第二维度是该模板中的数值型变量个数,第三维度则是该数值变量位置所记载的值,针对每一条输入日志,依据模板格式提取其数值变量进行存储,随后对出现频数超过100的变量进行检测,算法会依据统计结果模拟变量的概率分布,对分布概率过小的区域设定为临界阈值,阈值之外的变量所在日志则视为异常.设某指标x的概率分布是正态分布,则有:
F(x)=∫x-∞f(x)dx=12πσ∫x-∞e(x-μ)22σ2dx
(1)
其中μ是正态均值,δ是正态方差.
当使用统计分布去估计概率分布时,μ值取统计结果的平均值,而δ是统计结果的方差,在区间μ±3δ内包含了99.73%的数据.区间以外被视为离群的异常点.
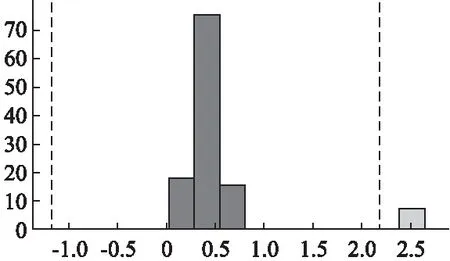
图3 单指标异常检测示例图Fig.3 Single indicator anomaly detection example diagram
如图3所示,数据集中该样例参数经过统计后的参数值的柱状统计图,横坐标为参数的值,纵坐标为参数统计数量,图中虚线内代表算法依据统计分布所取的正常阈值区间,右侧浅色数据区别于深色数据代表算法认定的阈值区间外的异常数据.
在增量处理模型中,加入了半滑动窗口,以避免日志变量的存储量过于庞大.在已有的数据存储超过一定量时,会新建一个数组进行新的存储,同时逐条输入的内容也会存储到以前的数组继续进行异常检测,在达到一定量时,废弃旧的数组启用新的数组.
单指标异常只需要一次遍历统计即可计算变量的概率分布,训练时间复杂度为O(N),其中N为训练日志数量规模.
3.3 组异常检测
组异常检测是对固定时间窗口下的日志数量分布进行检测.其算法将日志以时间窗口T为维度进行切分,统计T中各个日志模板出现的数量,生成日志数量向量.主成分分析(PCA)[20]通过捕获高维数据的最大方差分量,将其投影到低维主成分的新坐标中,经过PCA转换后的低位数据可以保留原始高维数据的主要特征.在异常检测中,使用PCA找出日志模板计数向量维度之间的模式,通过分析向量维度的相关性.如图4所示,大多数数据点都位于一条直线Sn附近,则Sn被视为正常空间,对于远离该维度的数据点,则被认为是异常数据.
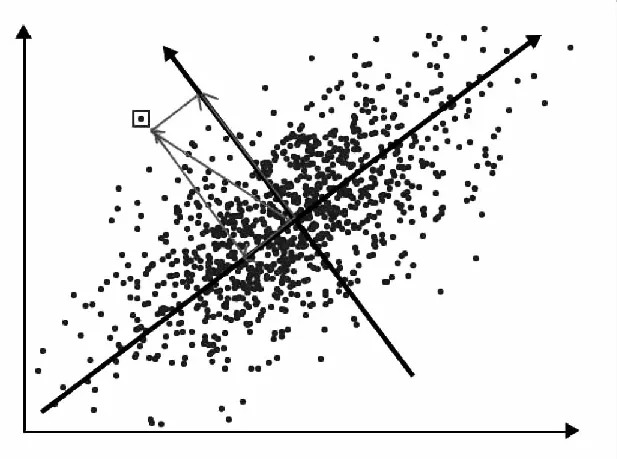
图4 PCA异常检测示例图Fig.4 PCA anomaly detection example diagram
本文使用滑动窗口的方式将日志切分为日志组,每次检测后将窗口向后滑动半个窗口大小,以此充分考虑在窗口边缘被切分的行为串,使其在下一次检测时处于窗口的中心位置.
在通过PCA方法得到数据降维结果后,本文通过计算SPE统计量[24]方法进行异常检测.其中,对于一个新的数据x,其SPE值计算方式为:
SPE=xT(I-PPT)x
(4)
该方法的控制限Qa计算公式为:
Qa=θ1cah02θ2θ1+1+θ2h0(h0-1)θ211h0
(3)
其中,ca为标准正态分布在置信度为a下的阈值,其中θ和h的计算如公式所示.
θr=∑mj=k+1λrj(r=1,2,3)
(4)
h0=1-2θ1θ33θ22
(5)
其中,m为数据原始特征维度;k为主成分分析降维后的特征维度.
当样本的SPE值大于Qa时,则认为该组日志是异常的.
组异常检测因需要奇异值分解进行矩阵运算,故训练时间复杂度为O(N)2,其中N为训练日志数量规模.
3.4 日志序列异常检测
实际的生产输出中,单条日志大多是某个复杂的流程操作的一部分,这些流程有一定的操作流程规律.日志序列异常检测是对日志的上下文顺序进行检测,判断日志是否符合流程的正常顺序,其具体定义如下:
定义2.日志集DM的ID序列P={p1,p2,…,pk},E={e1,e2,…,el}表示所有的流程序列集合,其中ei=pi1pi2…pim为一条任务的ID序列.对于日志Mj,若其对应Pj不属于当前任何流程序列的下一个输入,且不属于E中任何一个流程的开始输入,则认为Mj属于日志序列异常.
使用系统日志的输出顺序为数据集,通过统计方法生成日志的共现矩阵,即日志各个模板输出位置的间隔,构造日志系统的输出行为拓扑图,再根据行为拓扑图判断日志序列是否存在异常.
算法的输入为日志的模板ID序列P={p1,p2,…,pk},通过构造初始共现矩阵,共现矩阵是一个三维数组,前两维是日志模板ID编号序列N={1,2,…,n},第三维是某模板ID到某模板ID的日志所有距离集合Sninj={s1,s2,…,sm}.通过共现矩阵中日志间隔数据识别日志的分支结构.最后通过任务集生成该日志系统的行为拓扑图.随后基于行为拓扑图进行检测,采用有限自动机(Finite Automata,FA)的方式进行匹配,以应对日志系统的交叉任务情况.
首先使用一个初始数组建立共现矩阵,该数组的长度是日志模板ID的个数,即日志模板的数量,初始值为-1.在算法依次输入模板ID的同时,该数组的该ID位置标记为0,其他位置若为正数则该位置数值+1.该数组保存的是每一个模板ID到该输入位置的距离,从未出现过的则标记为-1.这样在每一次输入后,矩阵会更新每一个模板ID到值为0的ID的距离.具体构建共现矩阵的算法如表2所示.

表2 共现矩阵构建算法Table 2 Co-occurrence matrix construction algorithm
生成E的算法如下:首先,算法遍历共现矩阵,给定阈值α,若任意两个日志模板i与j之间概率P(M[i][j]=1)≥α,则认为(i,j)为一个子序列,添加至E中,创建初始序列集.若存在(j,k)且P(M[i][k]=2)≥α,则添加k至(i,j)中,即(i,j,k)为一个子序列,重复遍历E,直到没有新的可以添加的序列,则E更新完毕.依据E生成日志系统的行为拓扑图,作为系统行为的预测.
在异常检测阶段,同样使用有限状态机的思路,以应对日志系统可能出现的序列交叉的情况,即系统因为多线程多进程的原因将可能属于两个流程的日志交叉输出的情况.在检测时,算法的输入同样为日志模板ID,此时算法等待任意序列的开始位,其他的输入认定为异常.假设此时有序列(i,j,k),它的正常输入应为i.若算法在输入i之后,它会开启一个序列任务,同时等待新序列任务的开启,这时的正常输入为i或j.若算法此时再次输入i,这依然被认为是正常的,例如两个线程开启并发执行,此时算法等待两个开启流程的后缀输入j和序列集开始位i,以此类推直到某一序列结束,重新等待开始位,若新的输入不是某一开始位且不是现有的流程后缀,则认为该输入为异常的.
日志序列异常检测只需要按顺序读取一遍日志,通过中间结果生成行为拓扑图,时间复杂度为O(N),其中N为训练日志数量规模.
4 实验与分析
4.1 数据集介绍
本文选取了5个真实日志数据集,分别是BGL数据集[25]、HDFS数据集[26]和3个腾讯服务器的内部数据集来对算法进行评估:BGL数据集是从BlueGene/L超级计算机收集的日志数据集,对日志的分级有详细的标注,BGL数据量达到了474万条,有详细的日志分级,标注了常用的日志分级标签,包括info,kernel,warning,failure,fatal,severe,error;HDFS数据集为Hadoop分布式计算集群中分布式文件系统运行日志,数据量达到1100万条,其中明确标注了出现异常的文件块ID,用以区分正常与异常日志;腾讯服务器数据集为腾讯内部的3个不同的游戏运维日志数据集,其中的异常日志信息由运维专家人工标注作为评价标准.

表3 实验数据集Table 3 Experimental datasets
4.2 实验结果分析
针对日志解析算法,本文使用了腾讯数据集进行测试,与输出日志代码对比得到日志解析的准确率.本文采用的日志解析算法不需要任何标注,经算法有效处理后的日志压缩了大部分的数据量,使得后期的人工标注与日志的人工分析工作量显著减少.如图5所示,腾讯内部的3个测试集中,日志解析的准确率分别是100%,89.36%和100%.其中造成准确率下降的主要原因是日志的分级结构:在某些情况下,程序控制的日志输出会在同一句式下输出不同的结构.产生这一情况的一种可能原因是日志输出了允许为空的数据库表格,例如程序设计某条日志输出用户的个人信息,在信息不全的情况下它会输出姓名、年龄、性别、职业等等当中的某几条,这种可变的结构影响了算法对它原本的输出结构的识别,而错误地认为它们属于不同的句型.
在异常检测算法中,本文使用了所有数据集进行测试,对于公开数据集BGL和HDFS的实验结果进行了分析,结果如表4所示.

图5 腾讯数据集日志解析实验结果Fig.5 Tencent datasets log parsing experimental results
在单指标异常检测中,本文首先分析了算法输出的大部分的单指标统计结果.因为在日常使用环境中,数值型的变量有时并不代表数值,相当一部分是类似于ID编号的形式,因此发现ID形式的变量在统计分布中的体现相当明显,它们更偏向于平均分布的概念,这样在3Sigma方法中假设正态分布的情况下,ID类型所取得的假设阈值会非常大,极大地降低了假阳性的可能性.在BGL数据集上对算法进行了验证,将数据集中标注为warning,failure,fatal,severe,error标签的数据视为异常的数据,最终的精确率是41.5%,而查全率较低,为3.3%,分析结果发现是因为并非所有的错误是由单指标错误引起的,最终的F1值为6.1%.在HDFS数据集中精确率为58.6%,查全率为22.6%,最终的F1值为32.6%.
日志组异常检测部分,在大小100的滑动窗口设置下,BGL数据集的实验精确率为40.3%,查全率为76.3%,最终的F1值为52.8%.在HDFS数据集中,精确率为64.2%,查全率为38.9%,F1值为48.5%.BGL数据集的日志组异常检测查全率相比单指标异常显著提高,说明日志组异常检测可以反映大部分的日志异常.
序列异常检测部分,即有日志输出流程规律标注的日志数据集.在检测阶段,对BGL数据的检测中,最终得到的精确率为57.6%,查全率为99.7%,F1值为73%.在HDFS数据集中精确率为74%,查全率为96.7%,F1值为83.9%.精确率和查全率相比日志组异常检测均有提高,说明了序列异常检测的有效性.
最后,本文将3种异常检测结果取并集输出,即若日志在任一种异常检测部分被标记为异常日志,则认定其为异常日志.合并输出后,算法的查全率在测试数据集中均得到了显著的提升,但由于3种异常检测合并的错误累计,准确率有所下降.适用于对查全率要求较高的工业领域,如信息安全,资金交易等场景.
在对数据的分析得知,单指标异常检测方法不足以覆盖所有可能出现的日志异常情况;而日志组异常检测方法在BGL数据集和腾讯B数据集中精确率比单指标和行为序列的方法有所下降,分析结果认为是因为这两个数据集的日志内容较为复杂,模板抽取的准确率较低造成的.行为异常检测的结果有较高的准确率和查全率,因此序列作为异常检测特征可以反应大部分的服务器异常.通过3种异常检测方法合并输出相比单种异常检测方法得到的异常日志检测结果查全率明显提高,能更为全面地反映日志异常信息.

表4 异常检测实验结果Table 4 Anomaly detection experiment results

表5 IM、DeepLog、本文算法性能对比结果Table 5 Performance comparison results of IM,DeepLog,and the algorithm of this article
为对比评估本文提出的算法性能,分别选取了目前主流的离线检测方法:不变量挖掘[21](IM,invariant mining)和在线检测方法:DeepLog[22]与本文的合并算法进行对比.本文选择了数据量最大的HDFS作为测试数据集进行验证,实验结果如表5所示.可以看出,DeepLog取得了最高的精确率,而本文的合并算法的查全率和F1值均高于其他两者.
5 结 论
本论文使用无监督的方法设计实现了针对日志多维度的异常检测,充分应对了在智能运维环境下的实际工业问题与挑战.本文从数据收集,日志解析,特征提取,异常检测一系列流程的方案以此做了详细的阐述.其中异常检测使用了多个方法从不同角度分析日志可能存在的异常,并考虑实现了批量处理和增量处理的不同方案.实验数据表明,依据日志中数值指标作为特征进行异常检测具有较好的准确率,但无法覆盖所有的异常情况.日志组异常检测和行为异常检测则拥有更好的查全率.针对已有数据集做了相应算法评估与结果分析,并给出了可能造成问题的原因.
