一种基于信息传递的稀疏子空间聚类算法框架
2022-08-24荆雪纯崔志华
荆雪纯,赵 鹏,崔志华
(太原科技大学 计算机科学与技术学院,太原 030024)
E-mail:cuizhihua@tyust.edu.cn
1 引 言
聚类作为一种重要的无监督学习算法,被广泛应用于不同领域,例如声学场景[1-3],物联网场景[4, 5],云计算[6]和智能优化算法[7-9].随着数据复杂性的增加,传统的聚类方法已不能满足需求,因此针对高维数据的子空间聚类算法应运而生[10, 11].事实上,高维数据是低维线性子空间的并集.子空间聚类算法的实质是找到低维线性子空间结构,并将同一子空间中的数据点归为一类.如今,子空间聚类算法已在许多领域得到广泛的应用,例如机器学习[12],计算机视觉[13],图像处理[14, 15]和系统识别[16, 17].子空间聚类算法大约包括五类:矩阵分解方法[18, 19],代数方法[20-22],迭代方法[23, 24],统计方法[25]和谱聚类方法[26-28].
基于谱聚类的子空间聚类算法可以根据样本之间的关系获取表示系数矩阵,然后将矩阵传入谱聚类获得聚类结果.但是,对于构建表示系数矩阵,数据规模是一个非常重要的影响因素,算法的时间复杂度随着数据规模的增长呈指数增长.因此,不少研究人员开始研究基于抽样的聚类算法.虽然采样降低了时间成本,但是聚簇质量也不可避免随之降低.
为了解决这个问题,我们提出了一个基于信息传递的稀疏子空间聚类(SSC)算法框架[29].在此框架中,抽取样本的表示系数通过传统方法计算获得,其余数据的系数通过已知信息的传递获得.该框架的最大优点是灵活且通用,一是它抽取样本时可以采用不同的抽样方法,本文采用随机抽样和K-means聚类抽样.二是该方法在提高经典算法SSC效率的同时,还可以应用于其他子空间聚类算法.这种新的子空间聚类方法不仅减少了时间,而且在一定程度上保证了聚类质量.总体而言,这项工作的主要贡献包括以下3个方面:
1)为了提高SSC算法的效率,本文提出了一个基于抽样的子空间聚类算法框架,该框架灵活可扩展.它不仅可以选择不同的采样方法,而且可以扩展到其他子空间聚类算法.
2)本文提出了一种信息传递机制并应用于算法框架中.在计算表示系数矩阵的过程中,首先计算抽取样本表示系数,其余系数通过信息传递的方式得到.在保证聚类精度的前提下,它降低了时间成本.
3)本算法框架在两个数据集上进行试验验证,实验结果表明,与其他算法相比,本算法时间成本低,聚类质量高.
本文的结构如下.相关工作在第二节中介绍.第三节详细介绍了稀疏子空间聚类算法.在第四节中,我们提出了一个基于信息传递的聚类算法框架.其中我们定义了信息传递以及介绍了其如何被应用于框架中.在第五节中,本文方法的有效性被验证.最后第六节总结本文.
2 相关工作
在谱聚类中,需要一个相似度矩阵才可获得聚类结果,而一个相似度矩阵就对应一个邻接图.在图中,一个顶点对应一个数据点,两个数据点之间的关系表示为一条边,边的权重与两个数据点的相似度呈正相关.因此,谱聚类的关键在于构建一个好的邻接图.
构建邻接图的传统方法是利用成对距离.其中任意两个数据点的相似度都是通过欧氏距离来计算的,包括拉普拉斯特征图[30],局部线性嵌入(LLE)[31],K近邻(K-NN)[32]等.但是,成对距离过于关注局部结构而忽略了整体结构,因此受噪声的影响很大.与成对距离不同,表示系数将每个数据点作为其他数据点的线性表示.为了获得更好的聚类结果,学者基于不同的正则化项提出了不同的算法.例如,稀疏子空间聚类(SSC)[29],低秩表示(LRR)[33],低秩稀疏子空间聚类(LRSSC)[34]等.
尽管表示系数与成对距离相比具有更好的有效性,但是面对大规模数据时,需要逐个计算每个数据点和其他数据点之间的关系系数,时间成本将会很高.以n个数据点为例,算法时间复杂度为O(mn3),其中m代表数据维度.因此,ShenJie等人[35]提出对大规模问题进行随机优化.但是由于抽样数目小,该方法的性能较差.与此不同的是,PengXi等人[36]随机选择小部分的数据点并定义为样本内数据,其余数据点被视为样本外数据.他们采用SSC将样本内数据聚类,并将样本外数据分类到最近的进行归类.然后,他们开发了3种算法:可伸缩稀疏子空间聚类(SSSC),可伸缩低秩表示子空间聚类(SLRR)和可伸缩最小二乘回归子空间聚类(SLSR).但是,样本外数据分类时不是基于整个数据的本质特征,因此对噪声更敏感.为了解决这个问题,Libo等人[37]提出了一种新颖的在线LRR子空间学习方法.该方法包括两个阶段:第1阶段是先计算一小部分的数据点的子空间结构,称为静态学习.第2步是计算整个数据集的内部关键组成部分.但是,当数据点不足时,LRR模型可能会失效,那么在静态学习时如果选择数据点太少就无法产生可靠的结果.
为了解决这些问题,我们提出了一个基于信息传递的稀疏子空间聚类算法框架.在此框架中,需要采用两阶段方法来构建表示系数矩阵.首先,我们抽取出一部分数据点利用传统方式计算得到其表示系数.在第2阶段,表示系数矩阵的剩余数值通过信息传递完成,信息传递依赖于第1阶段的已知信息.与PengXi等人[36]的子空间聚类算法相比,该方法抓住了整个数据的特征.另外,信息传递的思想可以扩展到其他子空间聚类算法.
3 稀疏子空间聚类算法
谱聚类需要一个相似度矩阵才可获得聚类结果.因此,基于谱聚类的子空间聚类算法的关键是如何构造表示系数矩阵,表示系数矩阵将直接决定相似度矩阵.
稀疏表示(SR)是构造表示系数矩阵最流行的方法之一.近年来,SR成为某些领域研究的重点.SR的目的是有效表示数据并且通过特定空间中数据的稀疏性来挖掘数据的本质特征.稀疏性是指数据可被视作其他数据的线性组合,要求包括尽可能少的非零系数.因此,SR可以表征数据的子空间特征.
假设给定一个数据集X∈RD×n是K个子空间的并集{S}Ki=1,其中D表示数据的维数,n表示数据的数量.X的每一列代表一个数据点,每个子空间i包含ni个数据点,即∑ki=1ni=n.稀疏子空间聚类的理念是每一个数据点都可以由同一子空间中其他数据点线性表示:
xi=∑j≠izijxj
(1)
其中xi表示第i个数据点.zij表示第i个数据点和第j个数据点之间的表示系数,表示系数反映的是它们的相似度.
对于公式(1)的计算过程,矩阵表示为公式(2):
X=XZ
(2)
其中Z∈Rn×n是表示系数矩阵,当xi和xj不在同一子空间时zij=0,不同于一组基或字典,公式(2)的含义是用自己本身来表示数据,因此也叫做自表示矩阵.如果已知子空间结构并按分类顺序依次排列数据,表示系数矩阵Z在理想状态下将具有块对角结构,如公式(3)所示:
Z=Z10…0
0Z2…0
⋮⋮⋱⋮
00…Zk
(3)
其中Zα(α=1,…,K)是子空间Sα的表示系数矩阵.矩阵的块对角结构揭示了数据的子空间结构.而稀疏子空间聚类的目的正是利用不同的正则化约束项在公式(2)的基础上使表示系数矩阵达到理想的结构,之后通过W=(|Z|+|ZT|)/2将表示系数矩阵转化为相似度矩阵,最终通过谱聚类得到聚类结果.
为了提高聚类精度,通常增加正则化项来改善表示系数矩阵的结构.因此,Elhamifar提出了基于向量稀疏的稀疏子空间聚类算法.该算法利用公式(4)来计算数据点之间的相似度,得到表示系数矩阵:
minz‖Z‖1,s.t.X=XZ,diag(Z)=0
(4)
稀疏子空间聚类算法对于高维数据是一种非常有效的算法.然而,随着数据的数量和维数的增加,构造表示系数矩阵的时间复杂度也急剧增加.因此,本文我们利用信息传递技术,提出了一种基于采样的新型聚类框架来构建表示系数矩阵.
4 基于信息传递的子空间聚类算法框架
4.1 信息传递
一个关系网络中包括不同的顶点以及他们的关系.在一个不完整的关系网络中,如何计算两个顶点之间的未知关系是一个难点.因此,我们提出信息传递理论,信息传递可以通过中介点获得未知的关系.两个顶点的中介点的定义如定义1所示.利用信息传递计算未知关系的方法如定理1所示.
定义1. 假设顶点A与顶点B、C直接相关,并已知A与B和A与C的关系,则A被称为B和C之间的中介点.
定理1. 假设xi和xj的关系是未知的,并且在xi和xj之间存在η个中介点{xk,k=1,2,…,η},则zij可由公式(5)计算得到.
zij=∑ηk=1zikW×zkj
(5)
W=∑ηk=1zik
(6)
其中zij表示xi和xj的关系.同样的,zki和zkj也代表两点之间的关系.W是样本xi与所有中介点之间的关系之和(如公式(6)所示).因此,zik/W表示xi到xj所有路径中选择包含第k个中介点路径的概率.因此,zik/W×zkj表示选择包含第k个中介点路径时xi和xj之间的关系.
4.2 信息传递的应用
在基于抽样的子空间聚类算法中,一些数据点会被率先抽取出来.因此,从n个数据点中选择η个样本点是首要任务.然后可以通过传统方式即公式(7)获得部分系数矩阵Zelite∈Rn×1.需要强调的是,这种传统计算方式的本质是依次计算每个数据点与其他数据点之间的关系作为矩阵的一列.因此,公式(4)与公式(7)等价.
由表1中数据可知,“烟气中溶水性固体气溶胶的排放量”是“烟气中非溶水性固体气溶胶的排放量(PM)”的75倍以上,此表的计算数据可以说明,解决湿法烟气脱硫工艺形成的气溶胶问题远比将燃煤烟气中的含尘排放标准从50mg/Nm3降到10mg/Nm3更为重要,由于气溶胶是“雾霾”的凝结核,因此,湿法烟气脱硫产生的气溶胶对“雾霾”的影响不可低估。但由于污染物监测技术的局限和粉尘监测位置仅在电除尘出口,使对烟囱出口烟气气溶胶的监控出现盲区,随意排放而失去控制。由于燃煤超净排放采用的技术未考虑上述情况,即使采用湿式电除尘器,显然也不能彻底解决该问题[2]。
minzi‖Zi‖1,s.t.xi=XZi,zi(i)=0
(7)
其中Zi∈Rn×1表示Z的第i列,xi是第i个数据点,zi(i)表示Zi的第i个系数.
与矩阵Z不同,Zelite只包含样本点与其他所有数据点之间的关系,因此Zelite不是方阵,它对应的是一个不完整的关系图.但是,谱聚类需要一个完整的关系图,该图与系数矩阵Z相对应.因此需要计算图中未知关系所对应的表示系数.这些缺失的表示系数是剩余数据点之间的关系.此时需采用定理1来解决问题.
根据定理1,还需已知剩余数据点与样本点之间的关系,用Znon-elite∈Rη×(n-η)表示,其每一列为剩余数据点和样本点之间的表示系数.Znon-elite同样可以由公式(7)得到.
为了更加清晰地描述表示系数矩阵的计算过程,我们以图1为例说明.

图1 信息传递图Fig.1 A diagram of information transfer
图1中有五个数据点,包括三个样本点(实心)和两个剩余数据点(空心).首先,Zelite,Znon-elite由传统方式计算,即z25,z35,z45,z12,z13和z14被计算得出.根据定理1,z15=∑4k=2z1k/(z12+z13+z14)×zk5.从矩阵的角度来看,z15是将Zelite的第5行(归一化后)与Znon-elite相乘得到.因此,将归一化的Zelite和Znon-elite相乘则可计算得到缺失的部分系数矩阵Z′.Z′的每一列代表剩余数据点与剩余数据点之间的表示系数.最后,Z矩阵由Zelite和Z′拼接而成.
4.3 整体结构
图2展示了基于信息传递的子空间聚类的基本框架.首先,通过一些采样策略选择出样本点,如图中步骤(a)所示.接下来,在步骤(b)和步骤(c)中,通过公式(7)获得Zelite和Znon-elite.步骤(d)是将归一化的Zelite和Znon-elite相乘得到Z′.最后,(e)将矩阵Zelite和Z′拼接后作为表示系数矩阵Z.Z将被传入谱聚类算法得到最终聚类结构.其中步骤(f)的目的是将矩阵Z对称化.

图2 基于信息传递的子空间聚类框架Fig.2 Framework based on information transfer for subspace clustering
可以看出,新算法与传统的算法的主要区别在于减少了计算量.计算Z矩阵一列的时间复杂度为O(n).因此,传统方法的时间复杂度为O(n2).但是,新算法的时间复杂度仅为O(n×η+η×(n-η)),这是计算Zelite和Zmon-elite的时间复杂度之和.而O(n2)总是高于O(n×η+η×(n-η)),证明过程如公式(8)所示.因此,当面对大规模数据时,所提出的方法更加有效.
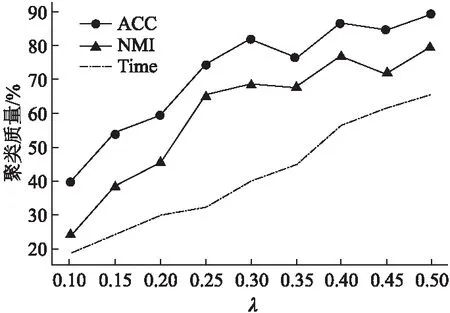
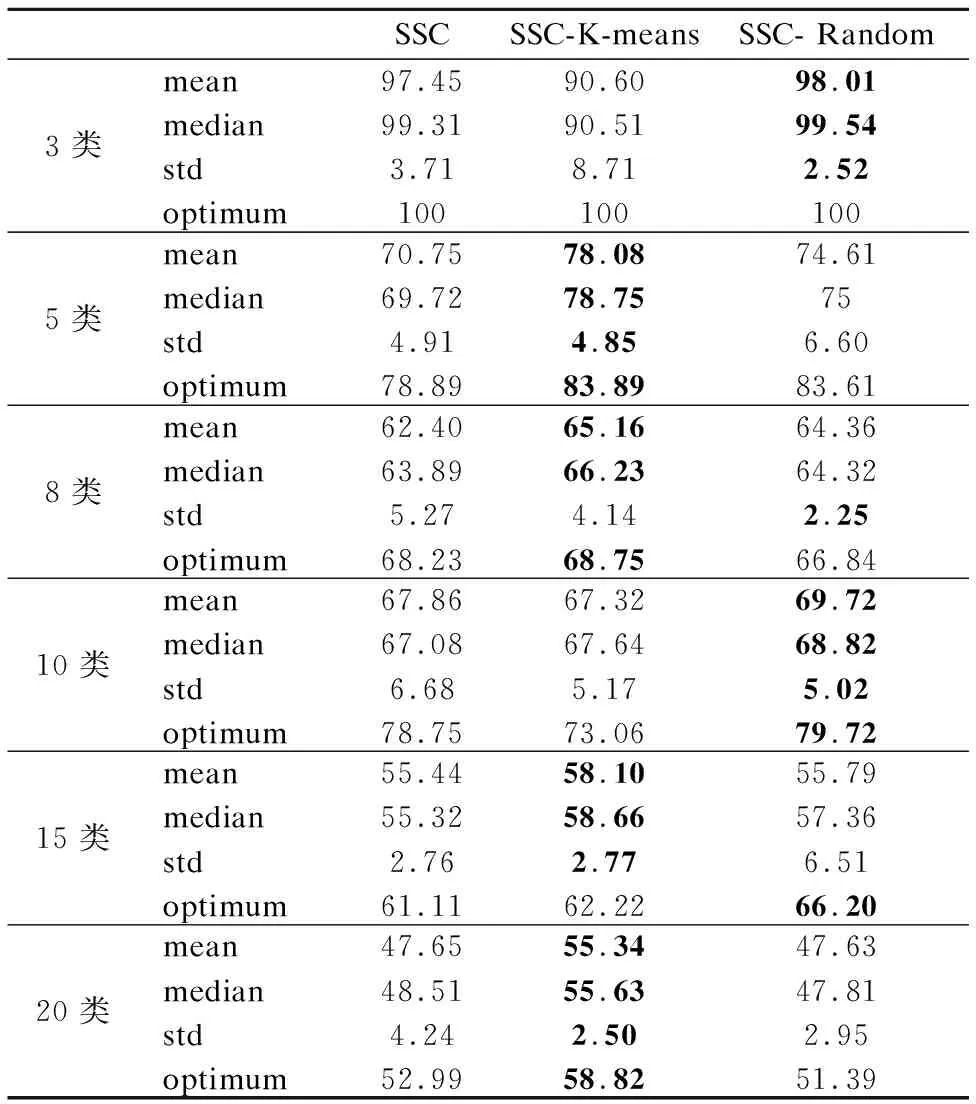
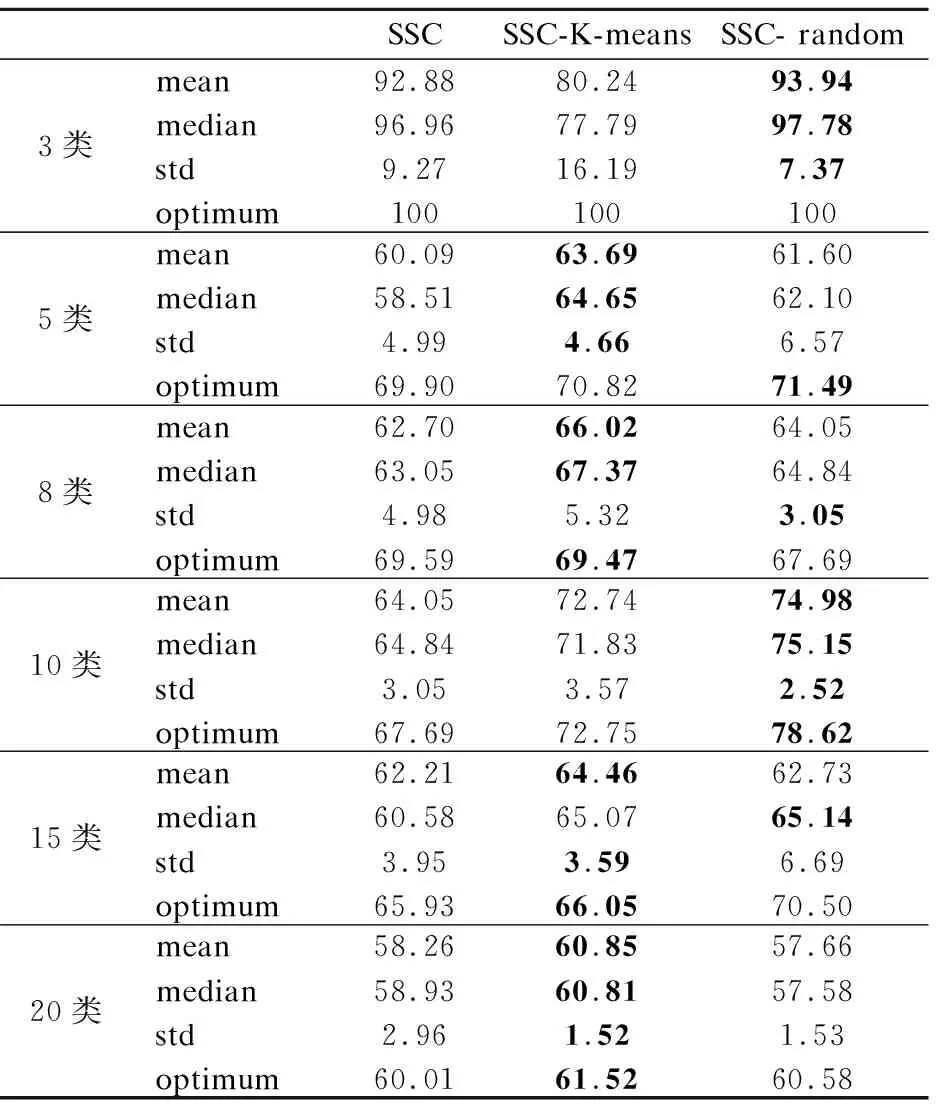
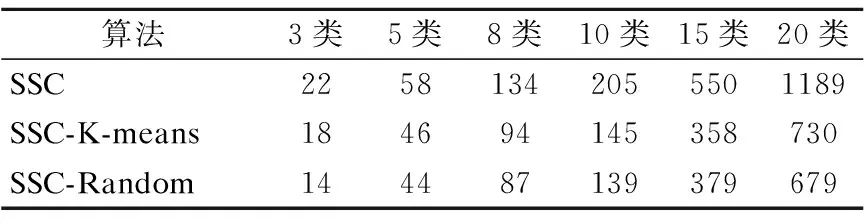
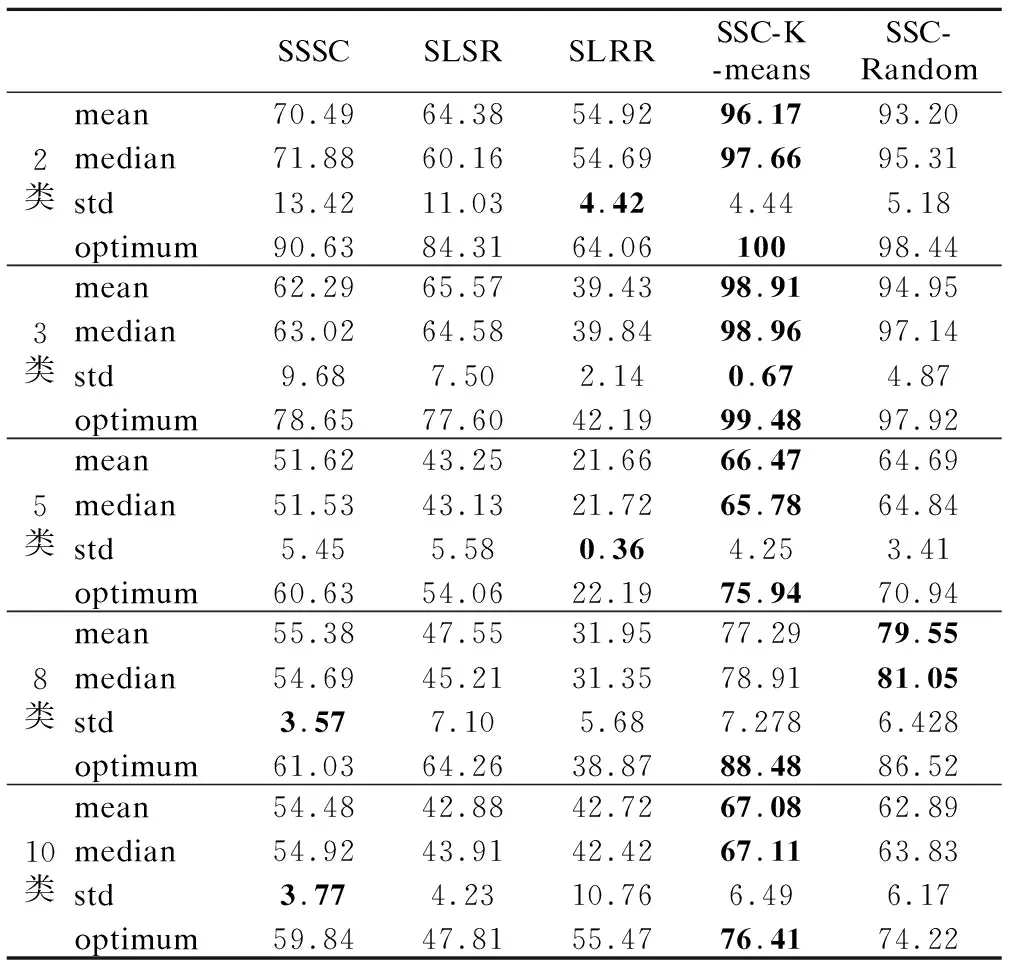
=n2-2nη+η2=(n-η)2>0s.t.y (8) 算法1为所提框架的伪代码.其中K,ε,λ是需要传入的参数.K表示要聚类的类别数.ε表示剪枝的阈值.λ表示样本点所占整个数据的比例,即η=n×λ.首先,数据将被分为两类:样本点和剩余数据点.在此框架中,样本点的采样方式是灵活的,这也是算法框架灵活性的体现.在本文中,我们以K-means抽样和随机抽样为例进行实验.接下来,由公式(7)获得Zelite和Znon-elite.步骤8-10是根据定理1将Znon-elite归一化,而Z是由步骤11-12获得的.为了提高聚类质量,将低于阈值的表示系数置为0,即剪枝操作,如步骤13-15所示.最终的聚类结果在步骤11-13中得到. 算法1.基于信息传递的子空间聚类算法 输入:数据X∈RD×n,K,ε,λ∈[0,1] 1.初始化0矩阵Zelite∈RD×n,Znon-elite∈Rη×(n-η),Z∈Rn×n 2.η=n×λ, 利用抽样策略进行抽样,生成一个长度为η,包含所抽样本的编号的列表 3.Forcol=1:η: 4.X[:,L[col]],作为xi被用于公式(7)计算得到Zelite[:,col] 5.N=[1,2,3,…,n],non=N-L 6. Forcol=1∶n-η: 7.X[:,non[col]]作为xi被用于公式(7)计算得到Znon-elite[:,col] 8.Forrow=1∶η: 9. Forcol=1∶n-η: 10.Znon-elite[row,col]= Znon-elite[row,col]/sum(Znon-elite[row,:]) 11.Z′=Zelite×Znon-elite 12.Zelite和Z′拼接得到Z 13. Forrow=1:n: 14. Forcol=1:n: 15.Z[row,col]=0 ifZ[row,col]<ε 16.W=1/2(Z+ZT),W和K传到谱聚类中得到聚类结果 输出:聚类结果 在实验中,我们使用两个数据集COIL-20,YaleBCrop025来表明算法的有效性.COIL-20包含20个物体72个不同角度的图片,其像素大小统一控制为128×128.因此,COIL-20共有1440张图片.而YaleBCrop025是一个人脸数据集,包括38个人在不同照明条件和不同姿势下的照片,每个人64张照片,整个数据集共有2432张图片.表1展示了数据集的具体说明. 表1 数据集的数值说明Table 1 Numerical statement of the datasets 为了评估效果,采用聚类准确度(ACC)[38],归一化互信息(NMI)[39]和时间(TIME)作为评价指标.聚类质量正是通过ACC和NMI来体现的,他们都是通过比较聚类结果和真实标签得到的结果.它们的范围是从0到1,越接近1,算法性能越好.同时,TIME表示程序的执行时间,执行时间越短,算法越高效. 在本文提出的算法1中,需要预先确定超参数ε和λ. 为了得到更好的聚类效果,我们首先测试了不同的ε和λ对聚类的影响,选择最佳效果对应的参数值用于后续实验. 在确定ε的实验中,随机抽取YaleBCrop025中2类数据为数据集,测试了ε的6个不同值.同时,为了降低λ的影响,将λ设置为1.也就是说,没有采样操作,所有数据均按照传统稀疏子空间聚类进行聚类,这么做的原因是采样与否对表示系数矩阵的剪枝阈值并没有影响.不同的ε得到的ACC和NMI如图3所示.很显然,当ε=10-1时,算法具有最佳性能.因此,在后续实验中均采用ε=10-1. 另一方面,采样率λ对聚类质量和计算时间中都有着重要影响.根据格里文科定理,λ太低将无法达到优秀的聚类质量.因为样本量很小无法确保采样数据与其余数据具有相同的分布.相反,如果λ设置得太高,该算法将会失去采样的意义,退化为传统的子空间聚类算法,效率依旧无法提高.因此,λ∈[0,0.5]是一个合适的区间,该实验测试λ在这个区间范围内的变化.所使用得数据集与测试ε的实验数据相同.实验结果如图4所示.很明显,计算时间和聚类质量随着λ的增大而提高.最终我们确定λ的值为0.4,以平衡时间成本和聚类质量. 图3 参数ε对聚类质量的影响Fig.3 Iimpact of ε on clustering qualities 图4 参数λ对聚类质量的影响Fig.4 Impact of λ on clustering qualities 该算法的第一步就是从整个数据中挑选出样本点.在所提框架中,采样方法不受限制,但不同的采样方法会对聚类质量有不同程度的影响.在这项工作中,我们选择两种抽样方法K-means抽样和随机抽样进行测试.K-means抽样就是将聚类后的聚类中心抽取出来.K-means是一种基础的聚类算法,其主要特征是简单,运算速度快.但是,K-means不适合用于直接图片这种高维数据,但可以将其用作预聚类方式以获得聚类中心,将聚类中心抽取出来作为样本点.因此,K-means可以成为获取样本点的一种采样方法.而随机抽样是随机选择η个数据作为样本点. 我们从COIL-20中随机选择了不同数量的类别,每类均包括72张图片.在这项工作中,由于谱聚类和采样方法具有随机性,每个实验都进行10次重复试验.表2列出了ACC的平均值(mean),中位数(median),标准方差(std)和最优值(optimum).平均值,中位数和最优值从不同的角度反映算法的性能,而标准方差可以反映算法的稳定性.表3为NMI的结果.不同采样方法的计算花费如表4所示. 分析实验结果可以得出以下结论: 1)从结果中可看出所提算法的聚类质量,ACC和NMI,均优于SSC算法.因此,无论采用哪种抽样方式,所提算法均比传统SSC有更好的效果.不可否认,有时由于随机性,SSC-Random比SSC-K-means具有更好的效果.例如,如表2所示,当类别为15时,SSC-K-means的均值,中值,标准差均优于SSC-Random,但SSC-random的最佳值66.20优却于SSC-K-means,这正是由于随机性导致的结果.另外,当类别数较少时,随机抽样的表现也会更好.随着类别数的增加,性能会变差.因此,在对3类进行测试时,随机采样的均值,中值高于K-means采样.原因是随着数据的增加,随机采样不能确保样本数据与总体数据具有相同的分布.相比之下,K-means预聚类抽取聚类中心,更好地保证分布,因此采样也会具有更好的性能.此外,尽管15类时随机抽样比K-means抽样更好,但结果没有太大差异.这也是由于随机性而引发的.总而言之,SSC-K-means总是比SSC-Random聚类效果更好. 表2 不同采样方式在数据集COIL-20上的ACC(%)结果Table 2 ACC (%) of different sampling methods on COIL-20 database 表3 不同采样方式在数据集COIL-20上的NMI (%)结果Table 3 NMI (%) of different sampling methods on COIL-20 database 表4 不同算法在数据集COIL-20上的执行时间Table 4 Computational times(s) of different algorithms on COIL-20 2)如表4所示,所提算法大大减少了运行时间成本.随着数据量的增加,效果更加明显.这表明所提方法更适合处理海量数据,节省时间,效率更高.例如,当类别数为3时,SSC-K-means节省4s,而当类别数为10时,SSC-K-means节省459s.此外,由于随机采样更直接,SSC-Random总是比SSC-K-means花费更少的时间. 表5 不同算法在数据集YaleBCrop025的ACC (%)结果Table 5 ACC (%) of different algorithms on YaleBCrop025 我们在YaleBCrop025数据集中测试了所提算法SSC-K-means和SSC-Random,并与最新的3种抽样子空间聚类方法进行了比较:SLRR,SLSR和SSSC.本实验从38个类别中随机选择不同数量的对象进行实验.每一类包括64张图片.同样,我们将每个实验重复10次以确保结果可靠.在YaleBCrop025测试后不同算法的ACC,NMI和TIME的结果如表5-表6及图5所示. 分析上述实验结果可以得出以下几个结论: 1)表5和表6的实验结果表明,无论类别数是多少,所提出的算法均优于其他算法.其原因是所提出的算法聚类时仍是对整个数据进行聚类.并且,剩余数据点之间的表示系数是通过信息传递来获取的,没有抛弃样本的基本特征.相反,其他算法只是对样本点进行聚类,然后根据样本点的聚类结果将剩余数据归类,这样的方法对噪声更敏感. 表6 不同算法在数据集YaleBCrop025的NMI(%)结果Table 6 NMI (%) of different algorithms on YaleBCrop025 2)从ACC和NMI的标准差可以看出,所提出的算法在大多数情况下具有更好的稳定性.有时,尽管所提出算法的稳定性不如SLRR,但SLLR的聚类质量明显低于SSC-K-means和SSC-random. 图5 不同采样方式在数据集COIL-20上的时间花费Fig.5 Computational times of different sampling methods on COIL-20 database 3)图5的结果表明,与传统的SSC相比,所提出的算法大大减少了运行时间,SSC-K-means和SSC-Random减少了约40%的计算时间.另外,尽管其他算法比所提算法花费的时间短,但是聚类质量大大低于所提算法.毫无疑问,聚类质量比运行时间更重要. 在本文中我们提出了一种基于信息传递的稀疏子空间聚类框架.该框架的关键是采用信息传递来预测数据之间的关系,而不是直接计算,从而节省时间.本文最重要的贡献是,所提出的框架具有通用性:框架内可以采用任何抽样方法来选择样本点,并且该框架可以应用于除SSC之外的其他稀疏子空间聚类算法.在COIL-20数据库上的实验结果表明,与传统的SSC相比,该算法大大减少了计算时间,提高了聚类质量.此外,在YaleBCrop025上的实验证明,所提出的方法比其他方法具有更高的准确性.5 实 验
5.1 数据集和评价指标

5.2 参数的影响

5.3 不同采样方法的对比实验
5.4 YaleBCrop025数据集性能测试


6 结 论
