基于多尺寸分解卷积的车道线检测*
2022-08-24李守彪武志斐
李守彪 武志斐
(太原理工大学,太原 030024)
主题词:分解卷积 车道线检测 语义分割 自动驾驶
1 前言
近年来,自动驾驶逐渐成为汽车领域研发的重点,车道线检测作为自动驾驶系统视觉感知的一项基础技术,在车道偏离预警、车道保持辅助、自动变道辅助等高级辅助驾驶功能中起着关键作用。
传统的车道线检测方法通过人工设计的特征来提取车道线信息,这些特征主要包括车道线的颜色特征和边缘特征。然而这类检测只适用于光线充足且结构化程度高的简单驾驶场景,在复杂的驾驶场景下检测困难、鲁棒性差。
基于深度学习的车道线检测方法相较于传统的车道线检测方法获取的车道线信息更丰富,检测精度更高。为了从图像中提取稀疏的车道线信息,Pan 等提出一种空间卷积网络,通过将传统的逐层卷积改为特征图内的逐片卷积来实现层中行和列像素之间的消息传递。Hou 等在模型的特征提取阶段引入自注意力蒸馏(Self Attention Distillation,SAD)模块,通过不同层之间特征图的相互学习来提高车道线特征提取的效果。车道线检测属于密集分类预测,虽然上述算法都取得了一定效果,但受限于模型本身的感知能力,在面对复杂的驾驶场景时,其精度和鲁棒性仍不理想。
针对上述问题,本文提出一种基于多尺寸分解卷积的车道线检测模型,利用多尺寸的分解卷积进行多尺度感知,以提高复杂驾驶场景下的车道线检测精度。
2 基于多尺寸分解卷积的车道线检测模型
2.1 分解卷积原理
分解卷积最早在GoogleNet中被提出,后来在高效残差分解卷积网络(Efficient Residual Factorized ConvNet,ERFNet)中被用来进行高效分割,其原理是将一个大小的标准二维卷积分解成×1 和1×的2个一维卷积。常规残差模块和ERFNet设计的非瓶颈一维(Non-bottleneck-1 Dimension,Non-bt-1D)模块如图1所示,后者是用3×1和1×3的2个一维卷积来代替常规残差模块中3×3 的二维卷积得到的,其中为输入模块特征的通道数量,为模块中各卷积层输出特征的通道数量,每个卷积后采用修正线性单元(Rectified Linear Unit,ReLU)激活函数进行非线性映射。
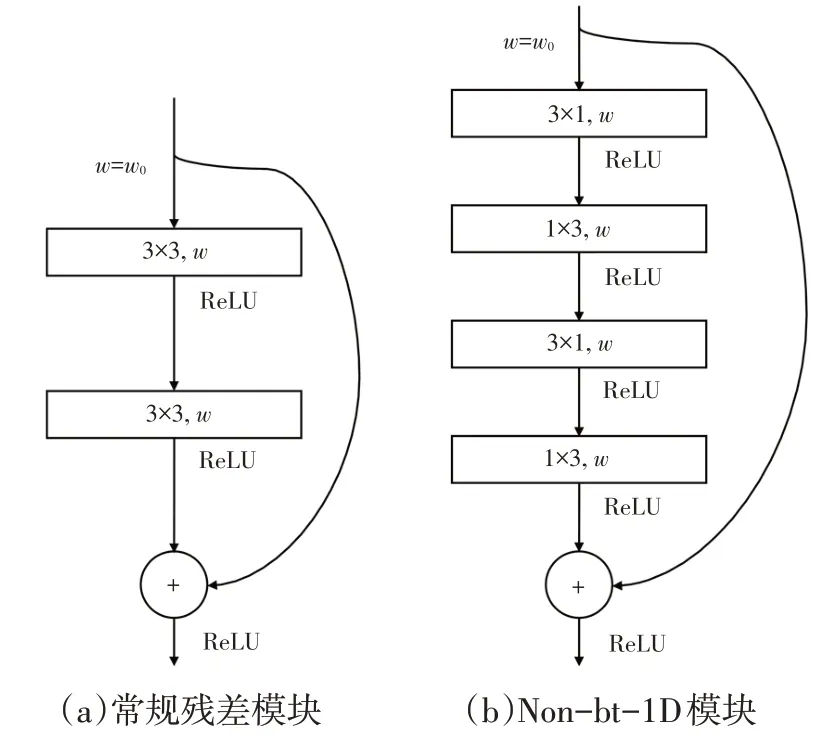
图1 常规残差模块与Non-bt-1D模块
分解卷积具有降低参数量和计算量的特点。不考虑卷积偏置时,×的标准二维卷积参数量为:

式中,、分别为输入、输出特征图的通道数量。
标准二维卷积计算量参考浮点运算数(Floating Point Operations,FLOPs)计算公式:

式中,、分别为输出特征图的高和宽。
卷积的参数量和计算量与卷积核尺寸呈2次方关系。将一个×的二维卷积替换成×1和1×的分解卷积后,其参数量和计算量与卷积核尺寸呈线性关系:

式中,为分解卷积参数量;为分解卷积的计算量。
综合式(1)~式(4)可知,卷积核的尺寸越大,分解卷积替代普通卷积的参数量和计算量降低效果越明显。
2.2 多尺寸分解卷积残差模块
车道线独特的细长特征使得其在图像中的跨度范围大而且容易被遮挡,这就要求检测模型有足够大的感知范围才能更好地提取车道线特征。增大感知范围可以通过增大卷积核尺寸实现,因此本文设计了如图2a所示的多尺寸卷积残差模块,结构上采用残差连接,采用3×3、5×5、9×9 的小、中、大3 个尺寸卷积核来提取不同尺度的车道线特征。但是大卷积核的参数量和计算量大,导致模型推理时间长,不能满足自动驾驶实时性的需求,因此基于分解卷积的原理,对3 个卷积核用相同尺寸的分解卷积进行替换,设计了如图2b 所示的多尺寸分解卷积残差模块,中尺寸和大尺寸卷积核配合扩张卷积进一步扩大感知的范围,大尺寸卷积能更充分地发挥分解卷积降低参数量和计算量的优势。
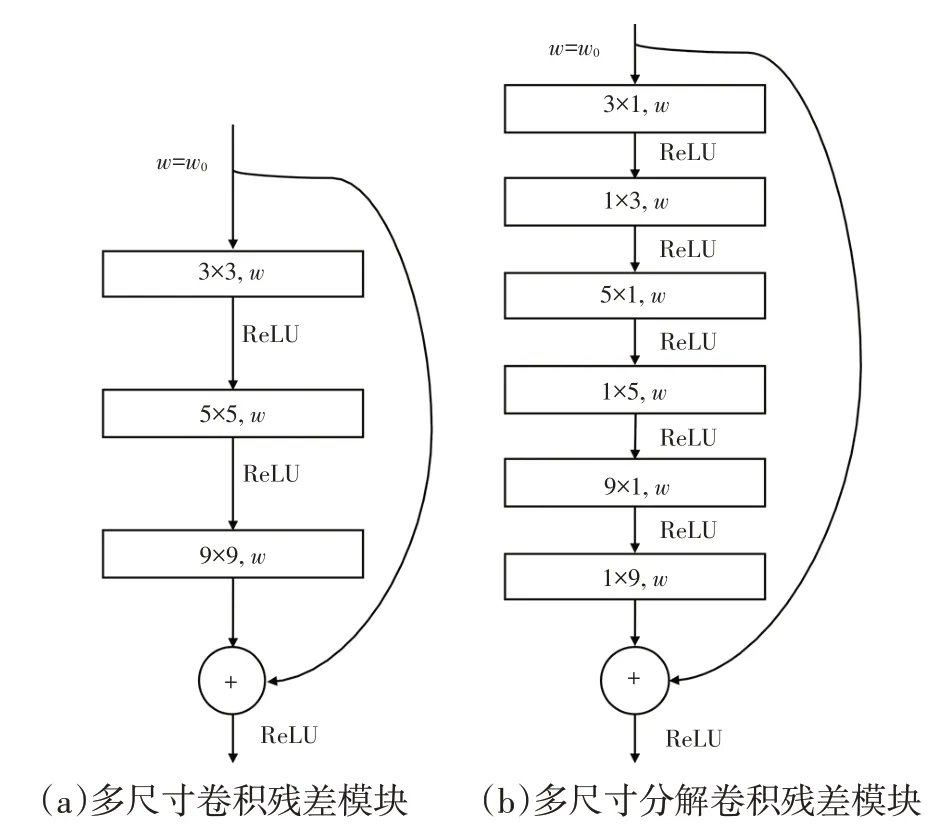
图2 多尺寸卷积残差模块与多尺寸分解卷积残差模块
在固定模块的输入和输出特征宽、高分别为100、36,通道数量为128个时,由式(1)~式(4)计算得到分解卷积替换标准卷积可以使整个模块中卷积的参数量和计算量分别降低70.43%和70.45%。
2.3 车道线检测模型
本文将车道线检测视为语义分割问题,将背景和不同的车道线看作不同的类别,在像素级别上进行分类。如图3 所示,模型整体上采用编码器和解码器结构,同时加入多尺寸分解卷积和车道线预测分支。
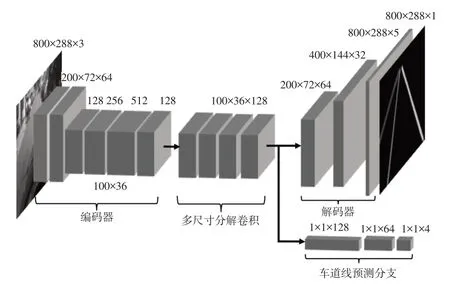
图3 模型整体结构
采用ResNet34 网络作为编码器提取车道线的局部特征。为了避免编码器输出的特征图尺寸过小而导致车道线空间信息损失严重,更改原始ResNet34 网络后两层的输出,将其输出特征图尺寸固定到输入图像尺寸的1/8 大小。输入图像经过改造的ResNet34 网络产生下采样的特征图,通道数量由3个变为512个,然后通过1×1 卷积将通道数压缩到128 个。在提取到图像的局部特征后,利用4个多尺寸分解卷积残差模块进行多尺度的感知。在解码器前加入车道线预测分支,结构如图4a 所示,先通过全局平均池化将二维特征图压缩成一维向量,经过2 个全连接层进一步压缩后利用Sigmoid激活函数输出预测车道线的置信度,预测时,通过设定的置信度阈值来判断车道线是否存在,预测置信度低于阈值时判定车道线不存在,高于阈值时判定车道线存在。解码器负责将特征图上采样到与输入图像相同的尺寸并分类输出,由3个上采样模块组成。上采样模块的结构如图4b所示,将输入的特征图利用1×1卷积进行通道压缩,经过双线性插值将特征图尺寸扩大2倍后送入Non-bt-1D模块。
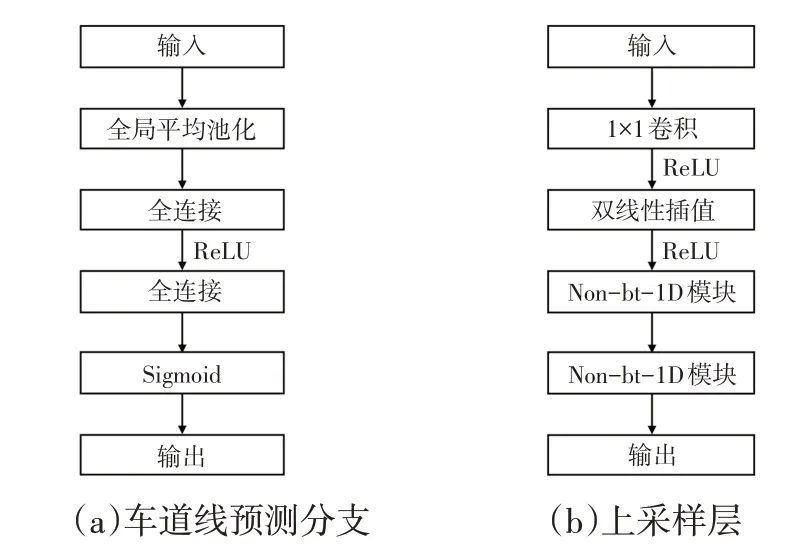
图4 车道线预测分支与上采样层结构
2.4 损失函数
模型有解码器和车道线预测分支2个输出,因此本文通过不同权重将分割损失、交并比(Intersection Over Union,IOU)损失和车道线预测损失3 个不同的损失联系起来,采用的多权重损失函数为:
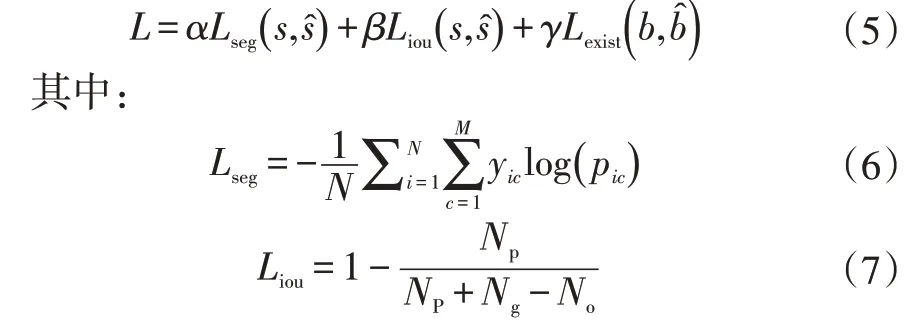

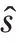
3 试验与结果分析
试验所用处理器为IntelXeonGold 5218 CPU@2.30 GHz,运行内存为64GB,显卡为NVIDIA RTX3090,显存大小为24 GB。
3.1 试验数据集
试验采用的CULane数据集是一个用于车道线检测的大规模数据集,共有133 235张图片,其中训练集含有88 880张图片,验证集含有9 675张图片,测试集含有34 680张图片。数据集有正常场景和8个复杂场景,分别是拥挤、夜晚、无线、阴影、箭头、眩光、弯道和路口,复杂场景图片占数据集图片数量的72.3%,每张图片的分辨率为1 640×590。
3.2 评价指标
将每条车道线视为一条30 像素宽的线,通过计算真实车道线和预测车道线之间的IOU 来判断模型是否预测正确。IOU 大于设定的阈值作为真正例(True Positive,TP),否则作为假正例(False Positive,FP),因漏检而未被检测出的车道线作为假负例(False Negative,FN),本文阈值设为0.5。使用调和均值作为最终的评价指标,路口场景因不含车道线标注,采用FP 数量作为指标,越小,表明模型检测效果越好。精确率、召回率和的计算公式分别为:
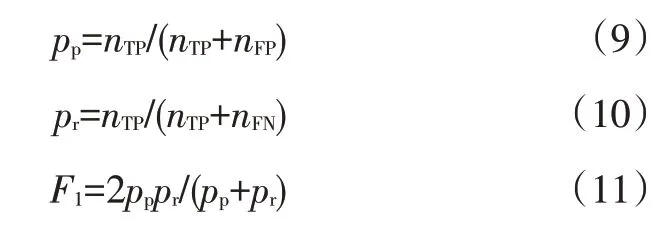
式中,、分别为真正例和假负例数量。
3.3 模型训练
模型采用随机梯度下降(Stochastic Gradient Descent,SGD)作为优化器,初始学习率设为0.04,动量加速参数设为0.9,权重衰减参数设为1×10,采用PolyLR学习率下降策略:

式中,、分别为当前学习率和初始学习率;、分别为当前迭代次数和最大迭代次数;为控制学习率曲线形状的系数,设=0.9。
将图像裁剪掉上部240行像素后,缩放到800×288,在整个训练集上训练20个循环。根据实际训练过程中各损失比例关系,通过参数组合并对比训练结果,确定权重系数、和分别为1.0、0.1和0.1。
模型每次循环训练后在验证集上进行验证,结果如图5 所示,模型在第1 个循环就达到了较高的指标,说明模型泛化能力较强,可以在较短时间内收敛。随着循环次数增加,模型精度逐渐提高并最终趋于稳定状态,在第18个循环,模型的指标达到最大值78.28%。
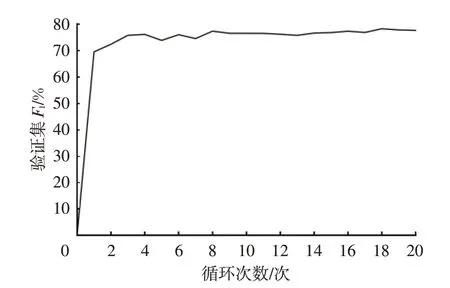
图5 验证集F1曲线
3.4 试验结果及分析
3.4.1 模型有效性
为了验证本文模型的有效性,在CULane 测试集的9 个场景中进行测试并分别与空间卷积神经网络(Spatial Convolutional Neural Network,SCNN)模型和以ResNet34 网络为编码器的SAD 模型进行对比,测试时车道线存在置信度阈值设为0.5,结果如表1所示。
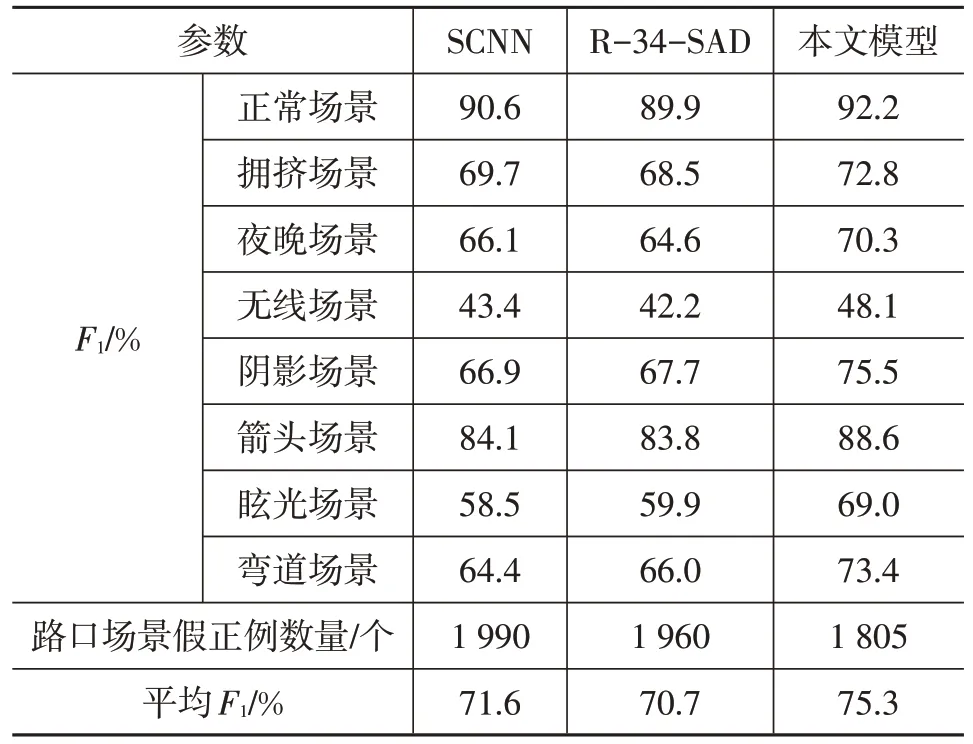
表1 不同模型对比
由表1可以看出:本文模型在所有场景中都取得了更好的测试结果,平均指标达到75.3%,相较于SCNN和SAD 模型分别提高3.7 百分点和4.6 百分点;本文模型在正常场景下的提升相对较小,但在复杂场景特别是阴影、眩光和弯道场景下提升较大,表明本文模型在应对复杂驾驶场景时具有更好的车道线检测能力。同时,在路口场景中也取得了更少的FP 数量,表明本文模型能更好地判断车道线是否存在,鲁棒性更好。
3.4.2 多尺寸分解卷积有效性
为了验证多尺寸分解卷积的有效性,首先可视化多尺寸分解卷积前、后的特征图,如图6所示,可视化特征图中灰度数值越接近1,表示模型的感知能力越强,可以看出,从编码器得到的车道线特征都是局部且零散的,经过多尺寸分解卷积后,车道线特征更加完整,对车道线部分的感知能力更强。

图6 可视化特征图
对比含有和不含多尺寸分解卷积残差模块的模型性能,分别在CULane数据集上进行训练和测试,并测试模型运行时间,结果如表2所示。
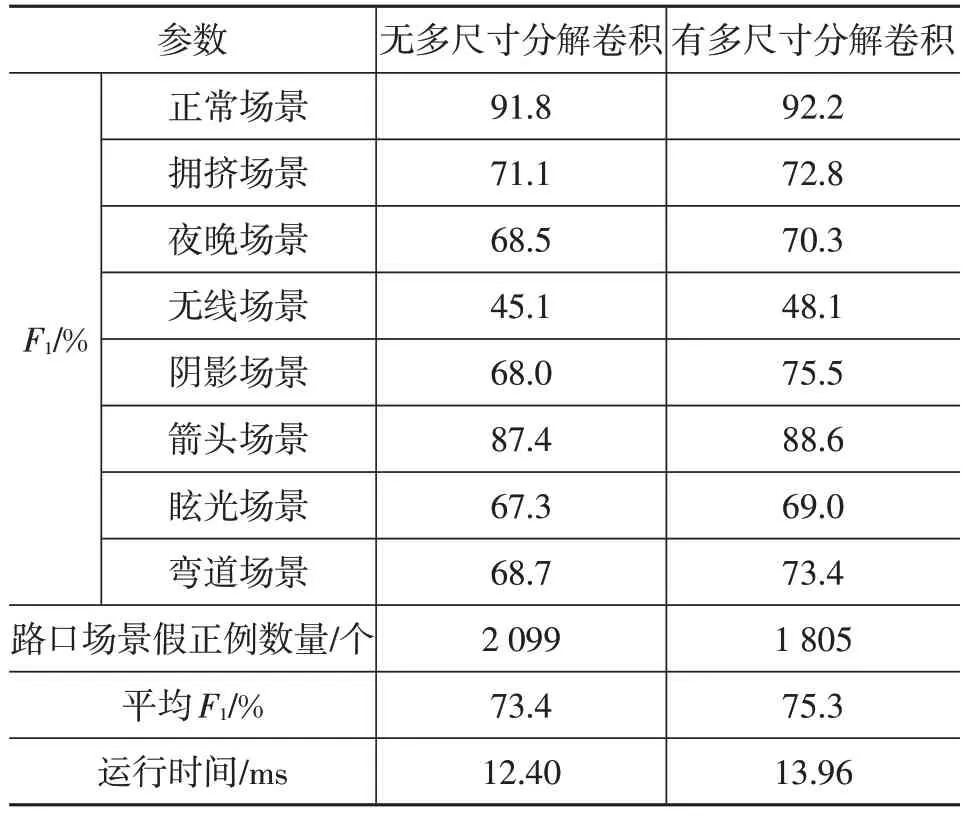
表2 有、无多尺寸分解卷积模型性能对比
由表2可以看出,加入多尺寸分解卷积模块后,模型在所有场景的检测精度均不同程度提高,平均指标提高1.9百分点,在阴影场景下提高最显著,为7.5百分点。在路口场景,加入多尺寸分解卷积后,错误预测的车道线数量减少了294个。对比模型运行时间可以看出,虽然加入多尺寸分解卷积后模型会增加一定的运行时间,但其帧率仍然能达到71.63帧/s,可以满足实时检测的要求。
将2种模型在8个场景下进行预测可视化并与真实标签进行对比,结果如图7所示。在大多数复杂场景下,未加入多尺寸分解卷积的模型在预测时会因模型感知范围不足而出现预测车道线不连续的现象,特别是图像边缘的车道线,而在加入多尺寸分解卷积后,模型预测的车道线会更加连续平滑,更接近真实标签的车道线。在正常场景下,未加入多尺寸分解卷积的模型将原本3条车道线的图像预测成4 条,而加入多尺寸分解卷积的模型预测正确。由上述对比测试结果可以看出,多尺寸分解卷积可以显著提高复杂场景下车道线检测的精度和鲁棒性。

图7 有、无多尺寸分解卷积模型预测对比
在路口场景中,虽然加入多尺寸分解卷积会在一定程度上降低错误检测的车道线数量,但误检数量仍较多,如图8 所示,可以发现模型将路口场景中的道路边沿错误检测成车道线,主要原因在于道路边沿在其他场景中被标记为车道线,而在路口场景中却未标注,存在标签设置不统一的情况,同时路口场景在数据集中占比较少,导致数据不均衡,因此在训练时模型会倾向于将道路边沿判定为车道线,造成路口场景误检较多。

图8 路口场景车道线检测
4 实际道路测试
为测试模型在实际道路上的有效性,如图9 所示,采用装有车载摄像机的智能车在校园内采集实际道路图像,并利用本文模型进行车道线检测。
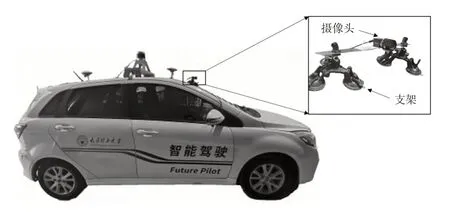
图9 智能车及摄像头安装
在正常道路、阴影道路、眩光道路下的检测结果如图10~图12所示,可以看出本文模型可以有效地进行实际道路的车道线检测,能够应对多种复杂场景,具有良好的实际应用效果。

图10 正常道路车道线检测

图11 阴影道路车道线检测

图12 眩光道路车道线检测
5 结束语
针对复杂场景下车道线检测精度不佳的问题,本文提出一种基于多尺寸分解卷积的车道线检测模型,通过设计的多尺寸分解卷积残差模块提取多尺度的车道线特征,提高了车道线检测的精度。在CULane 数据集上训练和测试的结果表明,本文模型在应对夜晚、眩光、阴影等复杂场景时表现出了优秀的检测性能,对比SCNN、SAD 车道线检测模型,平均指标分别提高3.7百分点、4.6百分点,多尺寸分解卷积可以有效提取车道线特征,使模型的检测效果更好,鲁棒性更高。在实际道路测试中,模型可以准确地检测车道线,具有良好的推广应用效果。
