基于深度学习的气象资料迹线识别
2022-08-23鞠晓慧马楠王妍范宇琛
鞠晓慧 , 马楠, 王妍, 范宇琛
(1. 国家气象信息中心, 北京 100081; 2. 青岛星科瑞升信息科技有限公司, 青岛 266590; 3. 山东大学电气工程学院, 济南 250061)
地面自记纸类气象资料记录了风、降水、温度、湿度以及气压等气象参数随时间的变化,是宝贵的客观表征天气和气候变化的实测基础资料[1]。气象信息对于开发利用风能资源、预防极端天气灾害、城市建设、环境保护以及精细化气象预报等天气课题的研究具有重要意义。
自20世纪60年代,全国2 400多个气象站使用降水、风、气温等各类自记仪器进行小时乃至分钟尺度的气象要素观测,共积累了40多年约2 000多万页的风自记纸[2]。由于存储时间长,许多纸质资料会出现氧化、破损现象,导致许多珍贵气象资料无法使用[3-4]。另外,纸质档案的使用往往不够灵活和方便,已经无法满足当前研究人员系统地了解和应用这些宝贵资源的需求[5]。因此,气象资料数字化处理对气象历史资料的永久存储和高效使用具有至关重要的意义。
图像处理和模式识别技术的发展为降水、风等气象要素自记纸提供了有效的数字化处理手段。全国气象研究学者对气象资料数字化展开了大量的研究。王伯民等[6-7]、Ju等[8]研究了降水自记纸迹线识别技术,研制了降水自记纸彩色扫描数字化处理系统并应用于全国降水自记纸曲线数据提取,建立了中国地面气象站长序列、高质量的分钟和小时降水文件数据集[9]。贺美萍[10]、马宁等[11]对温度自记纸数字化处理展开了研究,实现了气温自记纸曲线数据的提取。岑瑶[12]研究了图像处理技术在气压自记纸数字化方面的应用。全国EL型电接风向风速数字化自动记录与处理工作也已经开展,并取得了较好的效果。李亚丽等[2]应用基于最大类间方差法算法改进的Canny图像边缘检测方法设计开发了EL型电接风自记纸迹线数据提取软件系统。赵晓莉等[1]结合人工整理风向自记纸方法和数字图像处理技术,提出了一种 EL型电接风向风速自记纸数字化风向识别方法应用于EL 型电接风自记纸数字化处理。薛改萍等[13]通过图像扫描技术和风自记纸数字化处理,完成了西藏风自记纸数字化。目前,针对气象资料迹线的提取都是基于传统的迹线跟踪和提取算法,然而,由于存储时间长, 保管条件差, 纸质气象资料已经出现不同程度的纸张变质、迹线变淡 (模糊 )或者墨迹晕染。另外,不同气象观测仪器迹线记录方式也不同。达因型风自记纸记录了24 h内风向风速变化信息,是一种较为复杂的气象迹线,风向风速曲线呈无规律变化,传统的图像分割和迹线提取算法依赖局部或单一的图像特征,无法有效提取复杂背景中的迹线信息。
针对以上问题,现提出一种基于深度学习的气象资料迹线自动识别方法。该方法通过构建高质量的迹线数据集,利用语义分割网络结合多尺度信息,分割复杂背景中的迹线,实现气象资料迹线自动的和高精度的识别。根据《地面气象观测规范》[14],将气象信息转换为标准气象数据,建立历史长序列气象资料数据集。
1 基于深度学习的气象迹线识别
所提出的基于深度学习的气象资料迹线识别算法包括图像预处理、迹线网格定位、迹线分割和迹线量化计算。边缘梯度模板匹配算法被用于准确定位和提取气象资料迹线网格。U-net[15]语义分割网络通过自动提取不同尺度的光谱和空间特征准确分割迹线。最后根据气象标准,量化迹线信息,生成标准气象数据。算法流程如图1所示。
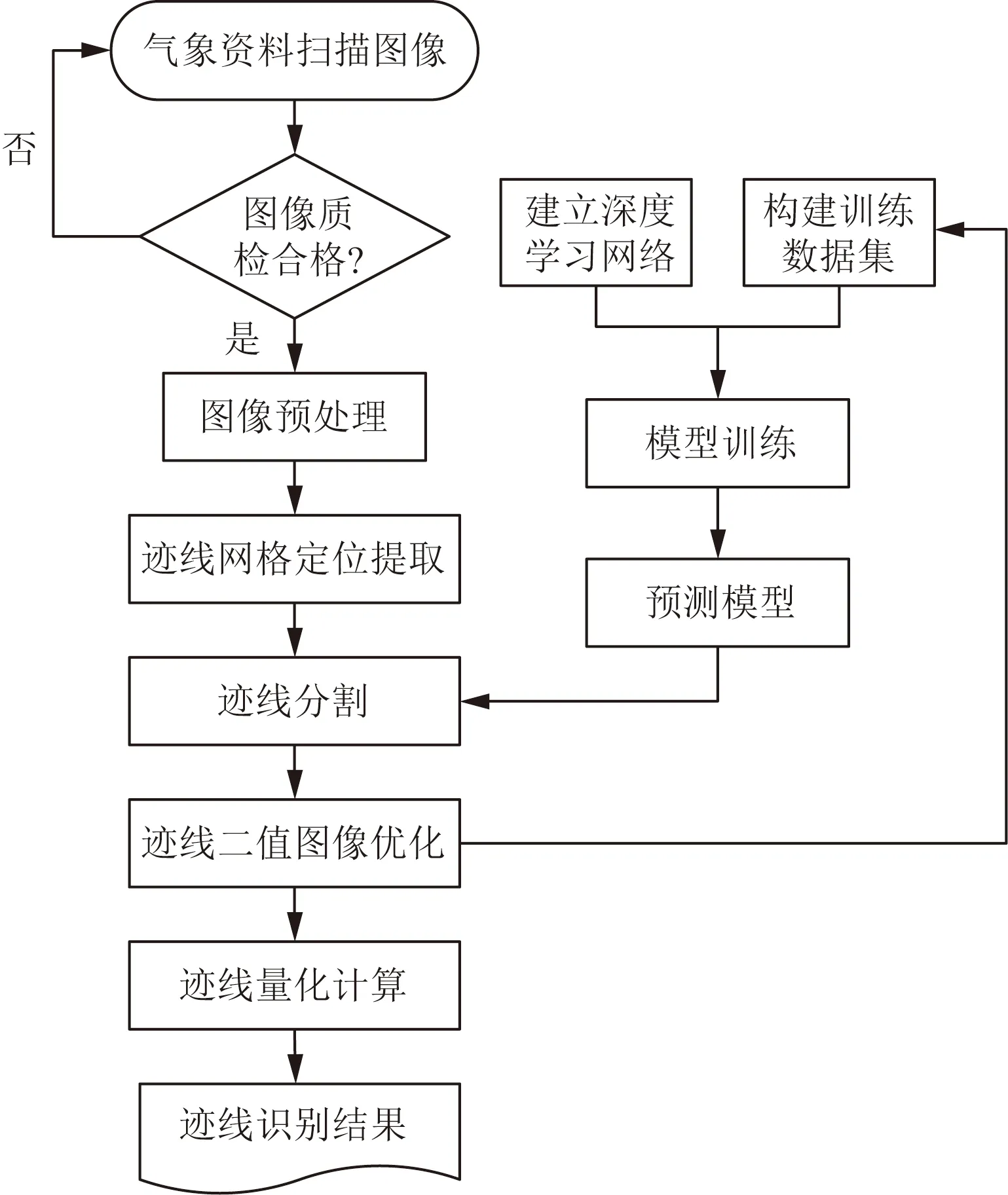
图1 气象资料迹线识别算法流程Fig.1 Algorithm flow of dyne-wind self-recording paper wind direction and wind speed extraction
1.1 图像预处理
由于扫描人员的操作不规范等因素,纸质气象资料在扫描过程中,会出现扫描图像倾斜,倾斜图像会给迹线识别结果带来误差,因此对纸质气象资料数字化处理前首先要进行图像倾斜校正。利用气象资料自记纸的网格竖线特征进行倾斜校正。首先提取网格二值图像,在网格二值结果的基础上,利用霍夫变换定位图像中的竖线。统计网格竖线的倾斜角度均值与垂直方向的角度差作为倾斜角度,利用仿射变换技术实现倾斜图像的角度校正。
1.2 迹线网格定位
气象资料网格线是时刻与迹线的刻度标记线,网格线的精确定位是迹线准确转换为标准数据的重要前提。为保证网格迹线的精准定位,采用基于边缘梯度特征的模板匹配算法[16]提取网格线。该方法结合边缘信息和多级特征进行目标匹配,定位精度可以达到像素级别,且该方法对目标的不均匀亮度变化,目标的部分遮挡,目标存在角度旋转等因素具有良好的鲁棒性,可以满足气象自记纸网格定位与提取的功能与性能要求。
气象自记纸中每一刻度数对应一条刻度线,选取网格边缘的时刻数字作为匹配模板,并记录这些特征字符与网格端点的相对位置坐标。通过对模板图像进行旋转、缩放以及金字塔下采样,生成一系列不同旋转角度和金字塔层数的模板。依据Canny算法的原理[17],首先,提取模板图像边缘点,计算边缘点在的x、y方向的梯度值以及总的梯度值;其次保存边缘点对应的x、y梯度,通过梯度强度归一化处理以消除光照不均的影响;最后,将边缘点坐标转换为相对于重心的相对坐标,将目标图像与模板进行匹配获取网格位置信息。字符匹配过程中,个别匹配度较低的字符结果舍弃,用相邻匹配度较高的字符插值计算代替,根据字符与网格端点的相对位置,计算得到所有网格线的端点,提取出网格。图2中绿色网格为达因型风自记纸网格线提取结果。
1.3 迹线分割
利用彩色方式扫描得到的气象自记纸图像为彩色,在进行迹线跟踪前将迹线分割出来是获取气象迹线信息的重要基础。传统的图像二值化方法大多利用图像的颜色信息,通过设置阈值来获取二值图像。然而,由于气象自记纸的记录方式以及存档时间长,自记纸存在墨迹晕染、人工整理的铅笔痕迹、笔尖滴墨等问题,给传统方法准确地获取二值图像带来了挑战。其中大量相同颜色的墨迹晕染问题是主要难点。近年来,深度学习方法在图像分类、目标检测、图像识别等领域取得了突破性成功并被广泛使用。为了更精准地分割迹线,设计了基于深度学习的气象资料迹线提取方法,利用卷积神经网络强大的特征提取和分析能力,结合多尺度特征,实现迹线的准确分割。该方法不再局限于单一的图像特征,充分挖掘图像的颜色、纹理、形状等光谱与空间几何信息,相对于手工设计特征更全面、更精准。选择U-Net网络作为迹线分割的骨干网络,基于U-net网络的迹线分割主要包括构建训练数据集和深度神经网络训练。
1.3.1 构建训练数据集
U-Net模型可以实现对目标的端对端提取,高质量的训练样本是精确提取目标区域的关键。为保证训练数据集的多样性和丰富性,在选择样本时应考虑到不同的时间和空间分布,选择的数据应涵盖不同的年份、不同的地区。同时气象迹线的种类也应尽可能全面。最后,通过人工标注的方式,获得训练数据对应的像素级标签。图3为达因型风自记纸风向风速迹线训练图像和标签示例。
1.3.2 深度神经网络训练
采用语义分割网络U-net作为骨干网络提取迹线二值图像。如图4所示,整个网络分为左右两部分。左半部分包含5个卷积模块和4个池化层。其中每个卷积模块包含两个卷积层,卷积核的大小为3×3,每个卷积模块的卷积核数分别为32、64、128、256、512。

图2 达因型风自记纸网格线提取Fig.2 Extraction of grid lines from dyne wind self-recording paper

图3 风向风速迹线图像和标签Fig.3 Wind direction and speed curves images and labels

图4 迹线分割网络Fig.4 Curves segmentation network
池化层采用最大池化操作,不断缩小图像分辨率。输入图像的大小为560×560×3,经过卷积层和池化层之后,特征图大小为35×35×512。 右半部分包含4个卷积模块、4个上采样层和一个卷积核为1×1的卷积层。上采样层采用2倍上采样,右半部分逐步修复特征图像的细节和空间维度。该网络还使用了跳跃连接,即每上采样一次,就以拼接的方式将左右两侧中特征图进行特征融合,结合浅层与深层的信息,从而更好地恢复目标的细节[18]。
1.4 迹线量化计算
气象自记纸迹线分割后,需要根据风、温度、降水等相应参数的气象行业标准,将图像中迹线位置信息转化为具有实际意义的气象标准数值。
2 实验结果与分析
2.1 实验数据
选择达因型风自记纸风向风速迹线进行迹线识别实验测试与分析。达因型风自记纸记录了24 h内风向风速变化信息,其图像如图5所示。可以清楚观察出以下特点。
(1)整体上,自记纸分为风向风速两部分,上部为风速部分,下部为风向部分。
(2)风向风速迹线呈现无规律变化趋势。达因型风自记纸中的网格标线为橙色,其中竖线为时间刻度,相邻两条时刻线间的时长为1 h。
(3)网格横线为风速风向刻度,风速相邻刻度间的风速差为1m/s,风向5条水平网格线表示风向方位,由上至下分别为北、西、南、东、北。
(4)风向风速信息为达因型风记录仪笔尖画出的蓝色迹线所在网格中位置表示,其中风速线为一条连续的迹线,风向部分为两条迹线。

图5 达因风自记纸扫描图像Fig.5 Scanned image of dyne-wind self-recording paper
为了保证训练样本的丰富性和多样性,考虑省份、站点、时间等因素,选取了120张达因风自记纸图像作为训练数据,这些图像包含了不同颜色、面积和趋势的风向风速迹线。为了使深度神经网络具有更好的学习特征,减弱其他新的干扰,将原始图像裁剪为风向和风速两部分,分别对风向和风速进行迹线提取。由于整个风向和风速线图像尺寸较大,考虑到硬件设施和计算效率,需要将风向和风速线图像裁切成较小的图像进行训练。然而风向和风速随时间变化,风向和风速图像高度是随机的,这为训练图像大小的确定带来了不确定,因此综合风向风速图像高度,确定训练图像大小为560×560像素,将不同高度的风向风速图像统一重采样到与训练图像相同的高度,同时也保留风向风速迹线的完整特征。120张数据对于神经网络训练是远远不够的,因此将重采样后120张达因型风向风速图像在宽度上交叉裁剪获得3 000多张不同颜色和不同背景下的风向和风速迹线训练图像。
2.2 实验结果
使用Python语言,以TensorFlow为后端的Keras深度学习平台作为训练环境,对达因风自记纸风向风速迹线数据集进行测试。在实验过程,训练数据为75%,验证数据为25%,使用Adam优化器。训练参数学习率为0.000 1,每批训练数据量为8,学习次数为100次。根据验证精度保存最优模型。根据训练精度和损失值,当训练次数达到100次时,学习已经趋于稳定,并获得了很高的训练精度和模型验证精度。
考虑到数据的复杂性和多样性,选择了不同站点和不同年份(1971—1978年),并且具有不同迹线颜色、面积和走势的达因风自记纸数据进行测试和验证,取得了良好的风向风速迹线提取结果。图6和图7分别为风向风速迹线提取结果,其中第一列和第三列为风向风速迹线,第二列和第四列为迹线识别结果。由于墨迹和存档时间的不同,达因风迹线表现为紫色、蓝色、淡紫、深紫等颜色,同时迹线呈现无规律性,具有不同走势和面积。另外,风向风速迹线背景中存在铅笔字符、大片墨迹晕染等干扰,这些因素严重影响迹线的准确提取。根据图6和图7的结果,可以看出,不同颜色、不同趋势风向风速迹线都能被很好地分割出来。根据几何形状信息,大量的墨迹和污点被去除,颜色接近的铅笔字符也会被区分出来,这表明该方法对不同背景下的复杂风向风速迹线提取具有良好的普适性。基于U-net网络的达因型风自记纸风向风速迹线分割与原始迹线具有高度的一致性,为后续风向风速的量化计算提供了高精度结果。
2.3 实验对比分析
为了验证达因型风自记纸风向风速自动提取方法的有效性和可靠性,根据风向风速迹线量化规则,对不同年份的达因风自记纸迹线进行了量化计算和精度验证。选择57 825和57 741气象站点3 200多张达因风自记纸数据,将风向风速整点时刻量化计算结果与人工整理的A6结果对比,获得风向风速计算精度。验证时采用整点10 min风速、风向与小时风数据集、定时风速、风向比较,规则如下:当风速小于3.0 m/s时,误差小于0.4 m/s;当风速为3.0~7.0 m/s时,误差小于0.7 m/s;当风速大于7.0 m/s时,误差小于验证风速的10%。A6数据中的风向表示为16个方位信息,在进行精度验证时,自动识别风向结果与A6风向相差不大于一个风向方位时认为自动提取结果正确。表1和表2分别为57825和57741站点1971—1978年风向风速与A6文件对比精度。结果表明,本文算法的风向风速迹线整体识别精度达95%及以上,与A6参考文件具有较小误差。
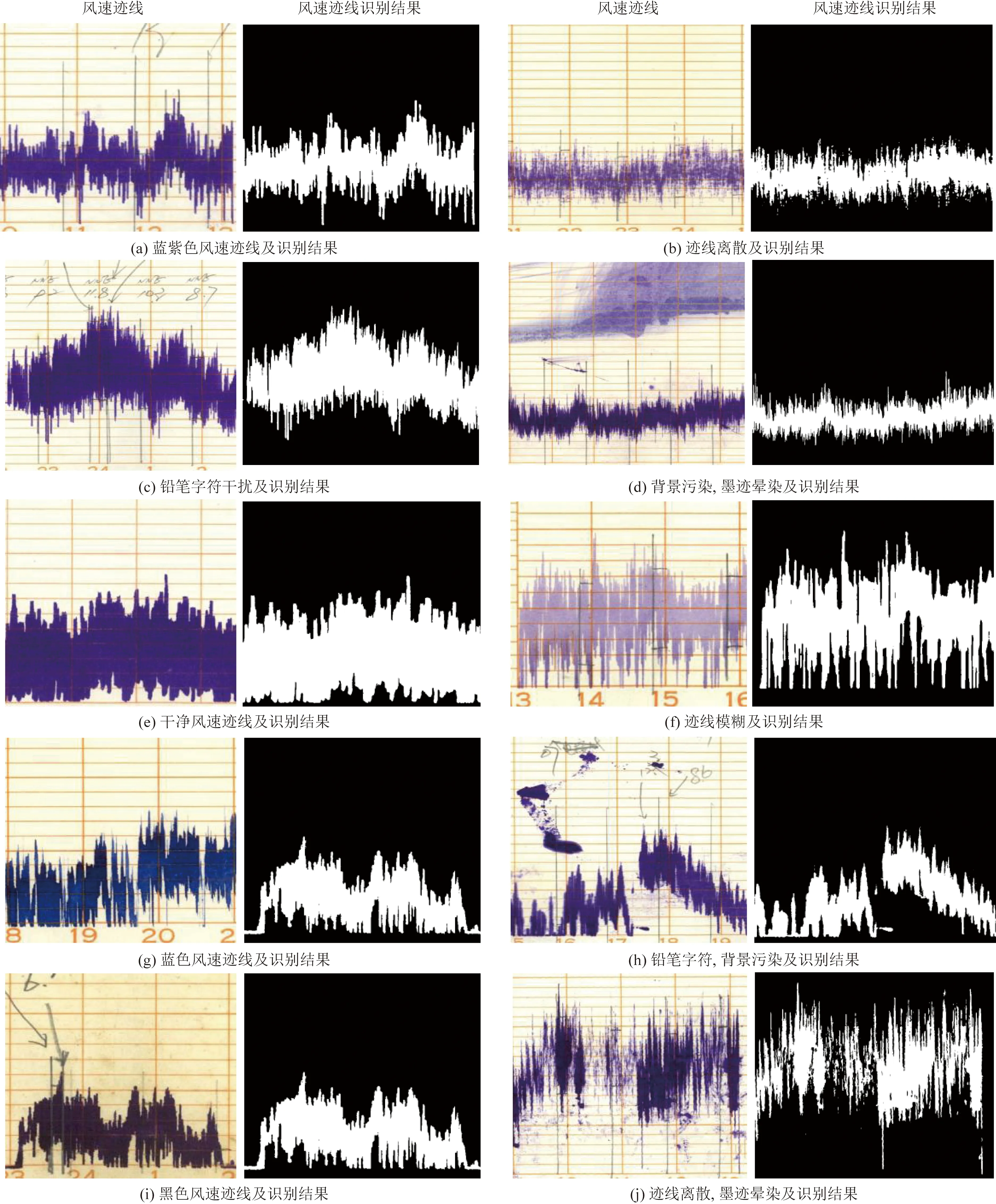
图6 风速迹线提取结果Fig.6 Wind speed extraction results
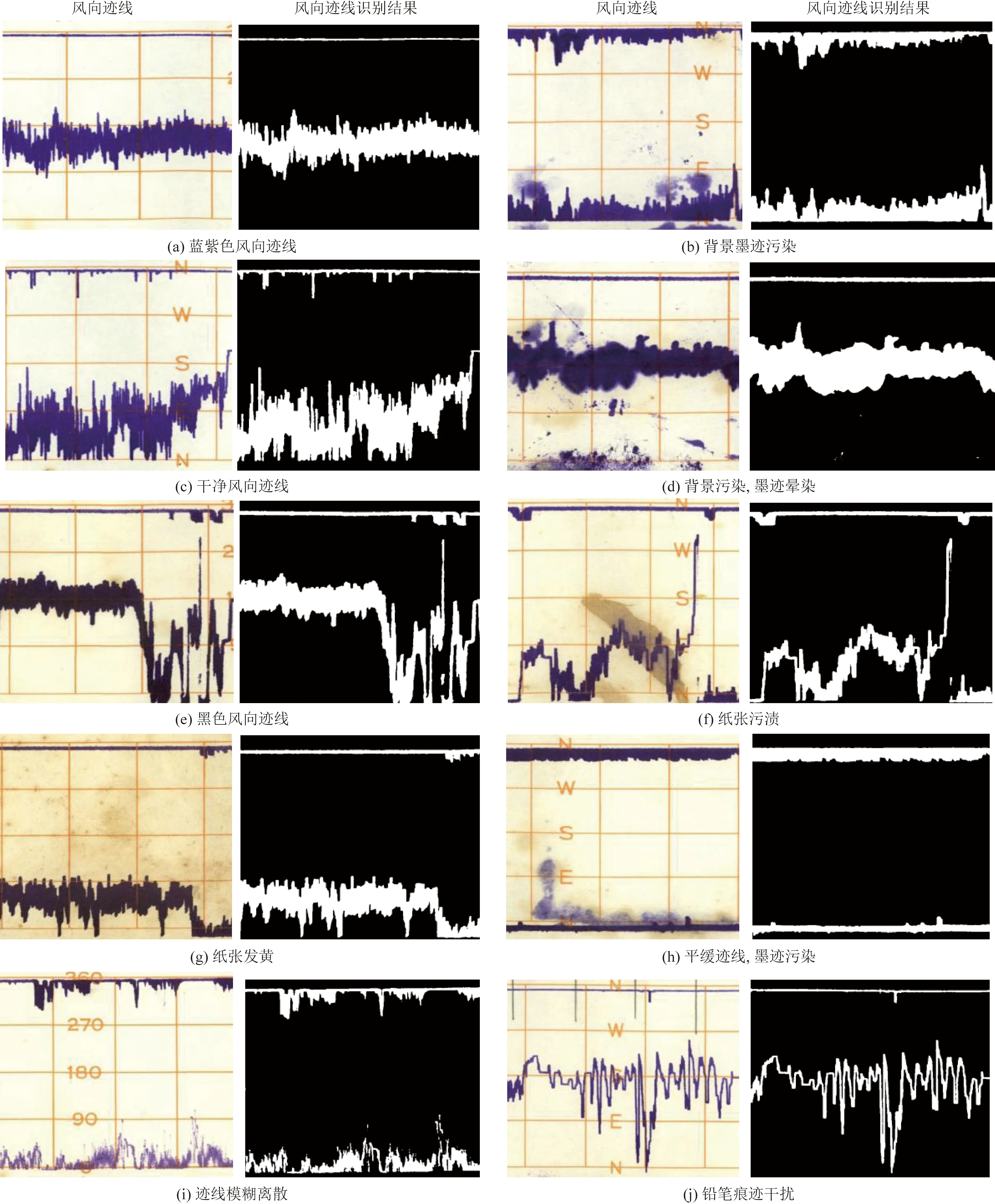
图7 风向迹线提取结果Fig.7 Wind direction extraction results
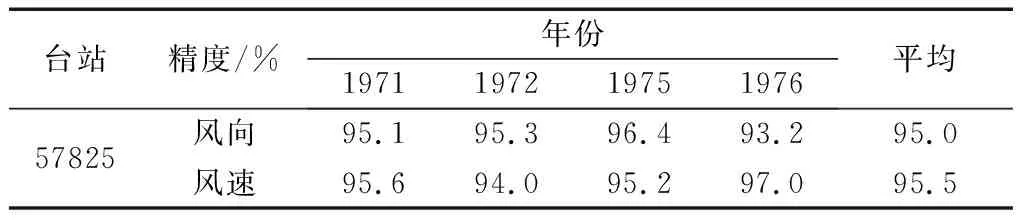
表1 57825站点不同年份风向风速迹线提取精度Table 1 Recognition accuracy of wind direction and speed curves in different years of 57825 station
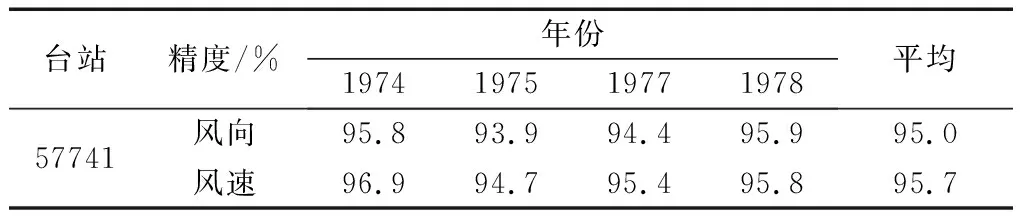
表2 57741站点不同年份风向风速迹线提取精度Table 2 Recognition accuracy of wind direction and speed curves in different years of 57741 station
3 结论
利用数字图像处理技术和深度学习算法实现了气象资料迹线自动识别。基于边缘特征的模板匹配算法实现气象自记纸网格的定位与提取,深度神经网络U-net提取有效特征,除去大片墨迹晕染和铅笔字符干扰信息,高精度分割迹线。根据迹线二值图像和气象行业标准,量化计算迹线,转换为标准气象数据。通过对达因型风自记纸风向风速迹线识别和验证,本文算法风向迹线平均识别正确率达95%,风速迹线平均识别正确率达95.5%,表明所提出的深度学习气象资料迹线自动识别算法高度还原了气象迹线信息。该方法适用于风、降水、温度、气压等迹线数字化提取业务化处理。气象资料迹线自动识别大大减少了气象行业数字化建设工作量和人工成本,为气象服务和研究提供了有力的支撑。
