基于3-2D融和模型的毛虾捕捞渔船行为识别
2022-08-23张佳泽张胜茂王书献杨昱皞
张佳泽,张胜茂,王书献,杨昱皞,戴 阳,熊 瑛
1. 上海海洋大学 信息学院,上海 201306
2. 中国水产科学研究院东海水产研究所/农业农村部渔业遥感重点实验室,上海 200090
3. 大连海洋大学 航海与船舶工程学院,辽宁 大连 116023
4. 江苏省海洋水产研究所,江苏 南通 226007
中国毛虾 (Acetes chinensis) 又称虾皮,隶属于樱虾科、毛虾属,为浮游性小型虾类,分布于我国渤海、黄海、东海沿岸及南海北部沿岸,是我国重要的海洋经济渔业资源[1]。我国毛虾捕捞始于20世纪50年代,随着沿海经济的开放,捕捞量持续上升,从1958年起(1.25×106t)持续平稳上涨,1964年骤降至6.54×105t,之后连续20年缓慢增长至1985年的2.09×105t;而后开始迅速增长,至2016 年达到 7.2×105t,此后捕捞量骤降,2018 年降至 4.25×105t[2]。2020年起,为了保护毛虾资源、实现生态循环可持续发展的战略目的,我国开始实行毛虾限额捕捞[3-4]。
深度学习是机器学习领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能,目前应用最广的是卷积神经网络系统(Convolutional neural networks, CNN),其在文字、语音、图片和视频等领域应用广泛,取得了很大的进步,正逐渐深入到海洋等研究领域中[5]。近年来,卷积神经网络在特征学习方面应用众多,各种预训练卷积网络 (ConvNets) 模型被用于提取图像特征。这些图像特征产生于网络最后几个全连接层的激活值,在迁移学习任务中表现良好 。但由于缺少运动建模,基于图像的深度特征并不能直接适用于视频[6-7]。基于深度学习的行为识别技术中最重要的就是行为识别网络,行为识别网络通常以视频流为数据源,综合考察一个时间序列上的图像信息,继而实现一个完整的行为识别[8]。在深度学习应用于该领域前,耿家利[9]使用渔船监控系统(Vessel Monitoring System, VMS) 存储的轨迹数据,利用Fisher判别模型对渔船各种行为对应的轨迹模式进行特征提取,并建立判别模型,依据渔船当前的轨迹数据自动判断渔船的作业行为。Zhang等[10]主要依靠船速、航行时间及渔船轨迹和捕捞努力量等,对捕捞渔船行为进行了识别和分析,并对捕捞产量及资源空间分布进行了统计。
基于深度学习的行为识别方法中,宁耀[11]首次提出了基于卷积长短期记忆神经网络 (Convolutional LSTM Network, ConvLSTM) 的渔船行为识别方法,该方法通过CNN搭建了4次卷积操作和1次池化操作并对LSTM层进行特征时间相关性学习,最终经过2次全连接层和Softmax层得到渔船行为的分类结果。Tran等[12]认为2D卷积神经网络不能很好捕获时序信息,因此,提出了C3D(Convolutional 3D) 卷积神经网络,采用了小卷积核进行特征提取,并得到比2D更好的分类结果。Carreira[13]基于Inception-V1模型,将2D卷积扩展到3D卷积,提出了I3D模型,但该模型参数量巨大,对硬件要求较高。
传统的捕捞渔船行为识别方法主要依靠船速、航行时间和轨迹进行判断,具有一定的局限性,而深度学习在目标检测和识别领域有较为突出的表现及应用前景[14-19]。本文搭建了一种3-2D融合的卷积神经网络模型,利用采集到的捕捞渔船视频数据,经过筛选、标记及压缩、分割等预处理后,通过训练模型实现捕捞渔船视频数据行为特征的提取和分类。
1 材料与方法
1.1 毛虾限额捕捞张网作业
根据《2021年伏休期间特殊经济品种专项捕捞许可和捕捞辅助船配套服务安排的公示》,毛虾限额捕捞点为辽宁、山东、江苏三地海域[20]。限额捕捞时间为2021年6月15日—7月15日,本文毛虾捕捞渔船长36.9 m、吨位160 t、主机功率220 kW,网具为张网 (一口网的囊袋是 3~5 个) (图1)。

图1 毛虾限额捕捞张网示意图Fig. 1 Schematic diagram of net fishing quota for A. chinensis
1.2 捕捞渔船拍摄数据
本研究利用型号为DS-2CD7A47EWD-XZS (D)的海康威视高清摄像头进行4个方向的拍摄,4个摄像头的分辨均为 2 560×1 440 (图2);其中,在前甲板驾驶舱上方安装2个摄像头分别为Camera 01和 Camera 03,后甲板安装 Camera 02,前甲板旗杆上安装 Camera 04,Camera 01 和 Camera 03 分别从左、右2个角度拍摄了作业人员的后方、收放网以及铁锚的状态,Camera 04主要拍摄人员正方向、铁锚、绞机及收放网状态的操作,这3个摄像头从不同角度记录了捕捞作业方式的全过程,而Camera 02作为辅助,主要拍摄后甲板其他船只的停靠和行驶,作为捕捞渔船停靠和行驶的判断依据之一,拍摄时段为6月17日—7月7日。

图2 捕捞渔船安装摄像头示意图Fig. 2 Schematic diagram of camera installation on fishing vessel
1.3 捕捞渔船行为划分
捕捞渔船一般在白天作业,有时等待收网时间较长,偶尔也在晚上作业。为了保证数据的有效性,剔除晚上无作业或晚上停船等行为的视频,本文将毛虾捕捞渔船划分为5种行为 (图3):Behavior 1代表停靠码头,渔船旁有明显的码头和人员,周边有同样靠岸的渔船;Behavior 2代表渔船航行,左右两侧浪花明显,且尚未下张网;Behavior 3代表下网,捕捞渔船左侧有明显浪花说明船在航行,同时前甲板上人员开始下网;Behavior 4代表收网,捕捞渔船停在海中,且前甲板船员开始用绞机和人工进行收网;Behavior 5代表等待,捕捞渔船停在海中静止,且前甲板上没有张网,船员也陆续离开前甲板。其中,下网约30 min,收网约2 h,每天下网3~4次,出海作业共计20 d。

图3 捕捞渔船5种行为图Fig. 3 Five behavior diagrams of fishing vessels
1.4 数据处理
对摄像头下载的数据进行分割、裁剪处理,按捕捞渔船行为划分为时间长短不一的视频数据,作为训练、验证、测试模型的数据集。渔船的5种行为对应4个摄像头视频数量如图4,其中Camera 02位于后甲板,因此摄像头不能拍摄下网和收网的全过程。
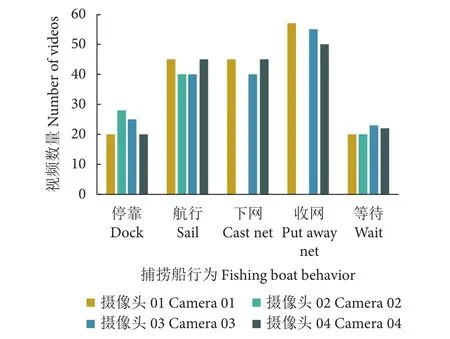
图4 捕捞渔船初始拍摄数据统计图Fig. 4 Statistics chart of initial shooting data of fishing vessel
针对数据不均匀且渔船为了节约用电经常关停摄像头等问题,需要对数据进行人工筛选,剔除模糊不清和断帧的数据,将4个摄像头数据整合进行重新统计。如表1所示,共使用视频数据集:停靠90个、航行110个、下网110个、收网110个、等待80个;样本数据集相对均匀。使用PotPlayer软件进行帧数读取和txt文本对数据进行记录。分别记录视频路径、帧数和捕捞渔船标签并标记出每个数字对应的行为状态 (表2,仅列出部分数据供参考了解标签格式)。由于1个视频中会出现多个状态,因此视频帧数需要衔接,如表2中第2和第3行表示对同1个视频进行行为划分,其中0~11 940 帧代表航行状态,11 940~50 093 帧表示下网状态,分别在文本中记录这两条数据。视频数据标记完成后,将其分割成每100帧为一个批次,并在txt文本中记录该信息,因此可统计到5种行为视频数据的批次图 (图5)。
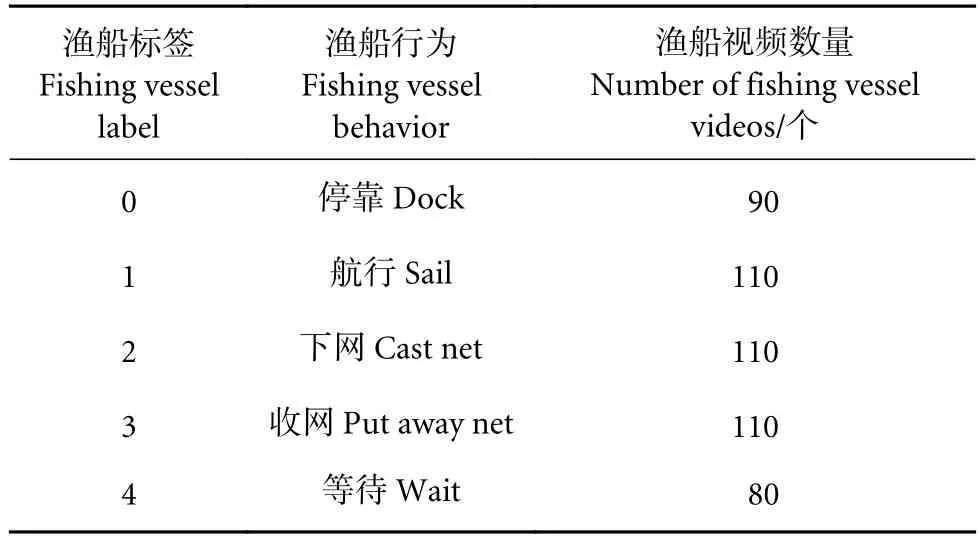
表1 选用视频数据Table 1 Selection of video data

表2 制作数据标签Table 2 Production of data labels

图5 每100帧为一批次读取数据量Fig. 5 Read data every 100 frames as a batch
由于摄像头拍摄的是1 080 p的高清视频数据,会使得需要的网络结构更复杂,还会出现训练时间过长及超参数等问题。因此将视频数据进行二次处理,压缩成大小为256×256像素,在减小网络训练压力的同时提升训练速度。
1.5 基于 3-2D 融合模型的行为提取
本文使用3-2D融和模型来学习时空特征,如图6所示为搭建的网络结构图,模型包含1个3D卷积层、6个2D卷积层、1个1D卷积层以及2个全连接层和分类层 (Softmax)。

图6 3-2D融合模型的卷积神经网络结构图Fig. 6 Convolutional neural network structure diagram of 3-2D fusion model
在第1卷积层,首先进行3D网络卷积,网络输入为2×100×256×256×3的结构,即每批大小(batch_size) 为2,也就是每次输入2个视频,每次处理100帧数据,每帧输入图像大小为256×256,其中图像为RGB 3种颜色的彩色图像故为3通道输入,进一步采用3×3×3的卷积核进行卷积初始输入通道为100输出200,步长为 (1,2,2) 使其降至二维处理,且经过批量归一化 (Batch normalization, BN)[21]处理以及带参数的线性修正单元 (Parametric rectified linear unit, PRelu)[22]作为激活函数。
在第2—第7层,依次进行6次2D卷积使用3×3卷积核、步长为 (2,2),进一步提取到特征,输出2×1 000×2×2,使得图像尺寸降至2×2,之后进行BN层和PRelu激活。
在第8层,经过1次全连接和BN以及PRelu使得尺寸降低至1×1,最后经过1次全连接层和分类层输出各个视频所属的行为状态。其中分类层采用了Softmax函数计算捕捞行为的概率值,其表达式为[23]:
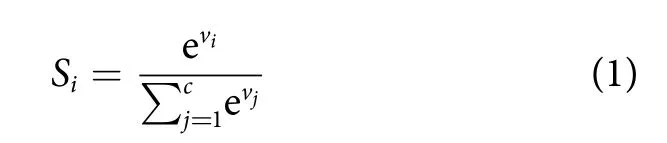
式中:vi为第i个节点的输出值;vj为第j个节点的输出值;c为总的类别个数;假设当前索引为i,则Si为当前类别节点输出指数与所有类别节点输出指数和的比值,即当前捕捞渔船行为的判断概率值。
BN通过将每一层网络的输入进行归一化操作,保证输入分布的均值与方差固定在一定范围内,减少了网络中的内部协变量偏移问题,并在一定程度上缓解了梯度消失,加速了模型收敛。由于BN在总体样本中引入了随机噪声,这不仅使得模型具有正则化效果,也使得网络的参数和激活函数等更具鲁棒性。其主要核心思想表达式为[24]:

式中:xi为原始输入数据;μ为均值;σ2为方差;ε为标准差;︿xi为经过标准化后的数据。
在过去的几年,线性修正单元 (Rectified Linear Unit, ReLU) 常在卷积神经网络中当作激活函数使用,其表达式为:
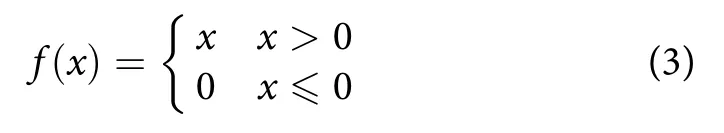
ReLU函数将所有的数据变换为不小于0的数,这样使得计算更加方便,并且由于其计算复杂度低且没有指数等运算的优点,要比其他激活函数计算速度快。但是由于ReLU在x<0时梯度为0,这样就导致负的梯度在经过ReLU函数时被设为0,而且该神经元可能不再会被任何数据激活。如果发生该情况,那么该神经元之后的梯度将永远为0,也就是ReLU神经元已坏死,不再对任何数据有所响应,被称之为“硬饱和问题”,因此针对这种情况,PRelu函数做了很好地优化,其公式表达式为[25]:

式中:ai是一个初始参数,且在给定范围内随机抽取的值,在训练的短时间内即可稳定下来。该函数成功解决了负数问题,使得负梯度被很好地应用于模型训练,解决了梯度的“硬饱和问题”,因此本文选择PRelu作为激活函数。
将渔船采集好的视频数据,输入到已搭建的3-2D融合模型,经过240 h可以得到模型结果。
2 结果
本文在ubuntu系统20.04版本的远程服务器上运行,环境为 Python 3.6、CUDA 10.1,以及 pytroch 1.4.0深度学习平台。其硬件配置为NVIDIA Tesla V100S-PCIE,运行内存为 32 GB。输入视频数据像素大小为256×256,初始学习率设置为0.001,分为5类,使用5个进程同时运行,批处理 (batch) 设置为8,每经过105次迭代将学习率降低0.01%,数据使用8∶2随机选取进行训练和测试,经过1.1×106次迭代得到最终渔船行为模型。
2.1 评价指标
在深度学习模型中,本文主要采用召回率(Prec)、精确率 (Ppre)、损失率 (Ploss)[26]、平衡 F 分数 (PF1)、查准率和查全率 (P-R) 曲线[27]及平均精确度 (PAP) 等指标对模型进行评价。
以下各个指标计算公式主要用到4个数据:NTP、NFP、NTN和NFN。NTP即 True Positive,指将正样本正确预测出来的数量;NFP即False Positive,指将负样本错误预测为正样本的数量;NTN即True Negative,指将负样本正确预测出来的数量;NFN即False Negative,指将正样本预测为负样本的数量[28-31]。
Prec是正确预测出来的正样本数量和所有的正样本数量的比率,其表达式为:

Ppre指正确预测出来的正样本数量占所有预测出来的正样本数量的比率,其表达式为:

Ploss指真实值与预测值之间的差,损失值越小表示结果距离真实值越近,本文主要使用了交叉熵损失函数,其表达式为:

式中:q(x) 为取值;p(x) 为对应概率值。
F1-score是Prec和Ppre的调和值,综合考虑了召回率和精确率对实验数据的影响,防止某一指标主导实验结果,其表达式为:

P-R曲线可以直观地显示出样本的精确率和查全率在总体数据上的关系。
AP是类别的精度的平均值,是模型评价的重要指标之一,其中AP主要是P-R曲线与坐标轴围成面积之和,其表达式如下:
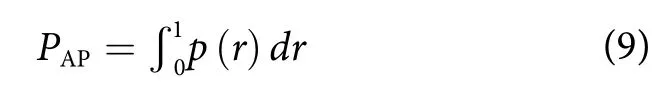
式中:p(r)为函数P-R曲线函数。
2.2 实验结果
模型经过1.1×106次训练的结果如图7-a所示,该图显示了精度与迭代次数的关系,随着迭代次数增加到105次,模型识别视频数据行为类别的精度逐渐稳定在0.99以上;同理,图7-b显示了召回率和迭代次数的关系,同样在约105次时,模型的召回率即识别分类当中正确分类的已经稳定在0.98以上;图7-c显示了损失率与迭代次数的关系,随着迭代次数的增加,模型的损失率也逐渐降低,最终稳定在0.02以下。
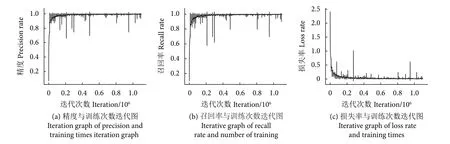
图7 训练模型结果图Fig. 7 Result graph of training model
图8显示了精度与召回率的关系,随着召回率的增加,精度逐渐下降,所以需要找到精度和召回率的一个平衡点,且曲线与坐标轴面积之和等于AP。因此,分别列出了几个主要指标对应训练和测试的结果,测试时间为 35.46 ms·帧−1(表3)。各个指标结果均表明该模型具有很好的泛化能力。

图8 精度与召回率的关系图Fig. 8 Relationship between precision rate and recall rate

表3 模型评价主要指标及结果Table 3 Main indicators and results of model evaluation
为了验证实验结果的有效性,选取一段视频通过预处理进行测试分析,毛虾限额捕捞渔船的5种作业类别和对应判别的类别概率值见图9。

图9 捕捞渔船结果测试图片Fig. 9 Test picture of fishing vessel result test picture
3 讨论
捕捞渔船的行为划分对于限额捕捞研究具有重要意义。本文对2D和3D模型进行研究[32],分析总结出2D卷积神经网络在空间上并不能很好捕获时序信息,在时序较强的数据方面会丢失部分信息,造成模型的精度不高;而3D卷积神经网络分别在空间和时间上进行卷积,可以更好地保留数据的时空特征[33],因此精度够高,但由于参数量过大,使得训练速度较慢,尤其是在摄像头等限定模型大小的设备中,不易被广泛应用。因此本研究设计出两者结合的方式,既可保留数据的有效时序信息,又可加快训练速度,实现精度高和速度快的双重目标。
捕捞渔船行为识别既是水产学研究中的主要课题之一,又是限额捕捞的主要研究方向。传统的捕捞渔船研究方法是指基于船舶自动识别系统 (Automatic Identification System, AIS) 和 VMS 数据对捕捞渔船类别和行为进行识别,AIS和VMS主要记录了渔船的位置、航速、航向以及时间信息且连续自主的发送渔船信息,通过卫星中转获得渔船的实时信息,及时了解渔船的动态信息[34]。国外学者Kroodsma等[35]利用获取的AIS数据经过CNN 算法识别了包括拖网渔船、刺网渔船、延绳钓渔船等6种类型渔船,识别率最高可达95%。由于CNN算法自身的局限性容易引起过拟合现象,故卷积受到了网络限制,本实验与其相比精度提高了0.35%,且节约了大量的数据处理时间。Guan等[36]对南海北部基于AIS数据进行前期的数据处理和贝叶斯优化算法,选择出贡献率较大的多个特征,经过LightGBM模型训练得到最优的分类模型,但是由于模型自身缺陷对噪声点比较敏感或产生较深的决策树,因此易产生过拟合现象。裴凯洋等[37]依据捕捞渔船的作业原理和状态类别进行划分,利用BP神经网络将速度、角度和距离作为输入,输出渔船的行为类别;与之相比本研究采用了更深层次的网络且加入BN等层,大幅提升了网络训练速度且防止了过拟合现象的发生,整体精度提升了5.35%;相较于单独使用BP神经网络,精度提升明显。相比于传统的研究方法,本研究将更直观的视频方式输入到网络中,保留了数据的时序信息,使得捕捞渔船划分多个行为的信息和时间直接关联,并且在数据预处理过程中,可以剔除其他因素影响,如补给造成的停航问题等。但本研究仍存在一些不足,主要体现在研究的深度和广度方面,今后可基于AIS和VMS数据对资源分布、捕捞渔船作业方式、渔场预测、捕捞努力量和捕捞时长计算及其规律作进一步研究[38-40]。本研究更适用于快速确定捕捞渔船的行为类别,提高作业行为划分的准确度和效率。为了评估所提供方法的分类性能,本文研究了国内外不同学者的评估方法,从召回率、精确率、损失率、平衡F分数、查准率、查全率和平均精确度等多个方面进行了测试,所用模型对比已有模型在行为划分识别方面有较好的实验结果,在时空特征表示方面具有可行性和有效性。
捕捞渔船的行为划分,有助于精细化捕捞管理,捕捞行为可辅助管理控制分析。捕捞行为的精确划分,对捕捞管理有一定的促进作用,通过捕捞行为分析,可统计出下网、收网、中间等待等时间,提取渔船的捕捞网次,计算出出航一次的捕捞努力量。从管理层面出发,可根据捕捞渔船的行为规定出海捕鱼的时间、次数以及每次捕捞的时长,对限额捕捞可起到精准化控制的作用。此外,根据捕捞渔船行为划分,可以建立有效的渔业资源监测与评估体系。据此加强船员在捕捞方式和捕捞时长上的培训,并制定相关制度,加强对船员的管理。
本研究在实验推进中仍存在一些问题:1) 实验中一些复杂情况未及时划分,且标签受人为因素影响,不同人划分的行为存在一定差异,因此结果易受主观因素影响。2) 船上不可控因素较多,如船员的行为不受控制和夜间作业灯光等问题。傍晚,船员有时会出现在前甲板上运转机器且在微弱的灯光下作业,虽然持续时间短,但是这些因素易影响分类的准确性,从而影响实验结果。3) 前甲板上Camera 01和Camera 03安装的角度偏高,有时不能准确拍摄到下网的结束时间,因此给人工标记带来了一定困难,使实验结果存在一定误差。4) 限额捕捞同时受到了时空因素的影响,如拍摄数据中包含夜间作业,夜间的视频数据质量较差,对实验结果产生一定影响,同时受到渔获物容器位置的影响,多次从视频中看到渔获物较少甚至看不到渔获物,给渔获物的统计带来一定困难。5) 该模型虽然训练精度较高,也缩短了训练时间,但是由于服务器I/O读写效率低,使得实际训练时间较长,理论上训练时间可以缩短1/4。本研究依据部分船员的捕捞经验,将捕捞渔船的行为划分为5种,但是由于出海情况复杂多变,且没有更加完整健全的分类研究过程,因此分类还不够完善。现阶段仍主要依据船员的捕捞经验和筛选来划分渔船行为,使得模型经过训练获得相对准确的结果。
4 结论
本文以捕捞渔船行为检测为出发点,采用4个摄像头拍摄渔船视频数据,结合2D和3D模型各自的优缺点,构建了3-2D融合的检测模型,提取了视频数据特征进行训练检测,解决了渔船行为分析的问题。通过验证,该模型有较好的实验结果,对我国渔业监控以及毛虾渔船的行为分析有重要意义和关键作用。
在研究过程中发现,设计思路时未考虑到铁锚的数量,因此该部分没有独自进行标签,在未来可以考虑统计铁锚的数量和张网在海里的作业时间等。其次,由于网络参数仍较多及网络训练次数过多的问题使得模型较大,无法业务化应用,未来实际应用时可以考虑更换较小的网络模型进行训练,同时添加多层网络,防止过拟合现象的发生。下一步工作中,将调整摄像头角度、重新安装摄像头,针对收集渔获进行定点拍摄,增加一个Behavior 6,作为渔船处理渔获物的行为,通过近似计算估计渔获物产量,为限额捕捞提供更丰富的数据参考。最后,网络可以通过引入增强模块 (Context enhancement module, CEM) 和空间注意力模块 (Spatial Attention Module, SAM) 使多尺度特征更加聚集,特征区分性也更加明显,从而使得模型更加完善。
