温州市浙南产业集聚区智慧海塘数据中心的设计
2022-08-20周昌臣张守楠
周昌臣,吴 炎,张守楠
(温州市瓯飞经济开发投资有限公司,浙江 温州 325000)
1 引言
数据中心是瓯飞海塘智慧的核心建设内容,是各类应用场景汇聚的基础和数据支撑的基石。基于省市间数据共享交换服务,采用省级数据服务管理模块,以此实现数据服务注册、发布、调用、监控的统一管理。数据服务建设基于瓯飞海塘水利数据仓,建设基础数据共享交换服务,实现与省、市两级水利数据仓的基础数据共享交换,以及与温州市大数据局的数据共享交换。其中省级水利数据仓中的基础数据共享交换服务,直接使用省级服务即可。业务应用的数据服务在业务应用建设过程中建设。
瓯飞海塘智慧数据中心将与温州市大数据局的共享交换。定义数据同步任务,定期将水利数据仓的数据推送至大数据局的数据平台;结合浙水安澜平台业务需求,按照公共数据共享交换规定,向公共数据平台提出数据共享需求,实现水利数据仓与公共数据平台共享交换。
瓯飞海塘智慧数据中心将与省、县水利数据仓进行数据交换。瓯飞海塘水利数据仓通过行业数据归集模块,按既定数据格式和共享需求,推送数据至省级、县级数据仓,同时可向省级申请数据共享授权,将省级、县级数据共享至瓯飞海塘水利数据仓,实现水利数据“一数一源、共享交换”[1]。
2 数据资源体系设计
2.1 数据归集
将多源数据,通过数据流的方式打通汇集渠道,分别归集至设计的基础数据库、物联感知数据库、GIS数据库或业务数据库,为数据中台提供持续的数据来源[2]。
(1)实时数据归集根据统一的数据接口标准,采用数据流的方式归集实施数据,对非标准的数据进行标准转换。
(2)其他数据归集
1)数据整编按照标准数据库结构编。
2)数据校核将整编数据与原始资料进行核对,确保数据准确,提高数据质量。
3)数据入库整编数据导入标准数据库。
4)数据审核对入库的资料数据,通过数据比对分析功能,与原始资料进行校对,完成数据入库。
5)数据更新数据更新采用实时更新和定期更新相结合的方式。
2.2 数据建库
按照水利信息资源标准规范和统一数据要求,结合业务应用和数据资源成果,开展数据库表结构设计,编制水利数据字典,生成标准数据库脚本。主要包括以下6类:
①基础库是用于存储一些变动不太频繁、使用面广的水利工程对象的基本信息,如水利工程、监测站点、功能区等对象的基础属性数据,包括名录、特征值、基本信息等。
②业务库是用于存储一些随时间增长会逐步增加数据量的监测数据和业务数据等,如水雨情、风速、海塘安全等实时监测数据,巡检记录、运行管理台账等管理数据。
③主题库(物联感知数据库)是用于存储通过确定某一个指定主题,获取的跨领域定时作业计算的数据分析成果。
④空间库(GIS数据库)是用于存储各类水利工程对象所处空间位置的数据。
⑤交换库是用于存储与本系统之外的数据源进行交换的数据,如数据仓向外部系统共享的数据、从外部系统归集筛分的数据等。
⑥元数据库是用于存储数据资源目录,及其数据的变更记录等。
2.3 数据初始化与汇聚
对瓯飞海塘已建应用系统的数据资源(包括实时数据、基础数据和业务数据)进行初始化和汇聚,包括数据抽取、数据汇聚、数据清洗、数据编码入库,并将已经汇入省市级数据仓的数据资源同步至区级水利数据仓。
(1)数据抽取
现有自建业务系统数据抽取。从区水利工程标准化运行管理平台等自建业务系统中抽取数据。
主要作用是从数据库中获取需求数据,对不同形式的数据、不同量级的数据、不同效能要求和工作量的业务系统,应采取不一样的接口来抽取数据。抽取效率是抽取数据时需要考虑的重要关键点,但往往只关注效率会影响到系统的性能,故也需要保障抽取数据时不会对系统的性能有影响。两者兼容的解决方式有很多,比如抽取方式、抽取时机、抽取周期等。
1)抽取方式
常用的方式包括:全量抽取、增量抽取。
①全量抽取
全量抽取就是将数据库中的数据原原本本全部复制并转化成可识别的数据。全量抽取相较简单,进行全量抽取的地方一般集中在数据量小,而且数据基本不变的业务系统数据库的抽取。
②增量抽取
增量抽取应用的范围比全量抽取要广。它主要原理是抽取数据库中变化过的数据,而不是全部数据。这样的优势非常明显,不仅减少了抽取数据的工作量,更是提高了业务效率,减轻了系统负担。
在进行增量抽取的过程中,如何获取变化的数据是重点,故需要对业务系统中的所有要抽取的数据特性进行分析和统计,同时获取数据还要满足准确和效率两大要求,既满足实时获取变化数据的同时还需要保证不影响业务系统的正常运行。
比较常用的抽取捕获变化数据的方法有以下4种:
①触发器:在抽取对象的表上设置插入、修改和删除3个种类的触发器,实时获取表的数据变化,并获取变化数据。该方式的优点是数据抽取便捷、性能较高,缺点是设置触发器可能对业务系统的运行会产生部分的影响。
②时间戳:在表中增加时间字段,若有变化则变化该时间字段,通过比较系统时间和时间字段,确定数据是否有变化,从而判断是否需要抽取数据。优点是抽取数据的性能比较好、简单 ,但是在业务系统中加入时间字段对业务系统存在一定的影响。
③全表比对:新建一个与数据库源表相类似临时表,表内仅存储主键和源表数据计算出来的校验码。当需要抽取数据时,比较现有表中数据计算获得的校验码与临时表中的校验码来比较,若有变动,则表示表中的数据有变化,抽取数据后,将新校验码覆盖临时表的校验码。
④日志对比:通过分析数据库本身的记录日志来判断数据是否存在变化。存储日志的文件有可能是txt格式、xml格式等,读取日志文件需要全部获取日志文件,通过日志文件对比,来了解变化的内容,从而判断抽取哪些数据[3]。
2)抽取时机与周期管理
对抽取时机和抽取周期进行管理,基于数据资源存储与管理的现状,按照数据来源与数据更新频率、数据量大小等特点,可以将数据分中心数据类型分为两大类,一类为实时或准实时汇集类数据,具有更新频率快、每次所需传输数据量不大的特点;另一类为基础类数据,具有更新频率低的特点。对于以上不同类型的数据,在抽取时机和抽取周期的选择上要区别对待:
①实时或准实时汇集类信息
主要包括实时水雨情、风速、水质、实时工情等专业数据组成的数据库。可采用增量抽取方式,并将抽取周期设为1次/3~5 min。
②基础类信息
水利工程数据库、水利行政管理信息库、水利行业法规政策数据库等,数据抽取周期可设定为1次/天,抽取时间不应在业务系统高峰时间段,比如在夜间业务系统比较空闲的时候进行数据抽取。
(2)数据汇聚
完成各种途径数据抽取并同步至汇聚库,确保汇聚库与各数据源数据一致性、及时性。其中汇聚库是数据抽取汇聚过程中一个过渡库,也称暂存库,不参与具体业务数据分析,主要为了辅助抽取和汇聚工作。
(3)数据清洗
按照数据清洗、抽取规则,通过数据清洗的工具,并辅以人工判断,完成业务应用系统水利业务数据的清洗、整合。数据清洗是在数据抽取汇聚的基础上,对采集的数据进行清洗、整理、筛选,数据的清洗包括系统自动审核和人工审核两部分。
1)数据的清洗实现方法
自动清洗。从汇聚库中定时或实时提取,使用数据清洗工具,根据定义的数据清洗规则,实现自动数据清洗加载,避免人为操作及增加大数据采集的不准确性。
人工审核。从汇聚库中提取但自动清洗系统无法确定其数据准确性,通过人工审核辨别,实现数据入库。
汇聚数据最终进入主数据之前需要完成数据的清洗,其清洗流程如图1所示。
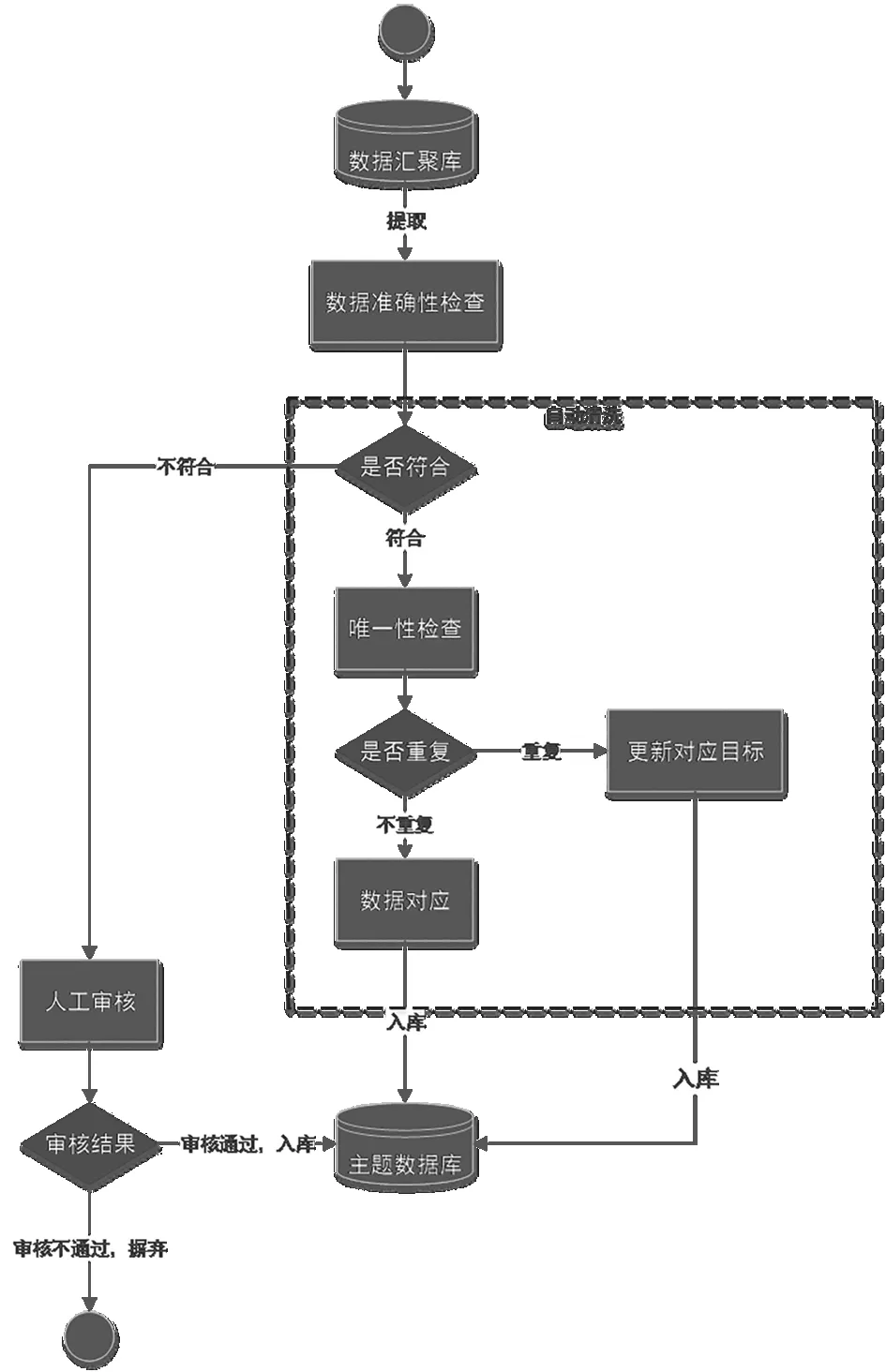
图1 数据清洗处理流程图
2)数据准确性检查
数据准确性的分析计算只针对发现错误后可以修改完善的数据,主要为工程的基础信息数据、管理单位信息、安全责任人信息及其他上报后允许修改的数据;对于上报后无法修改的数据,平台会根据准确性判断规则和控制阈值,通过上报接口进行限制,防止错误数据上报到平台。
(4)数据加载入库
将清洗后的数据根据预先设置好数据源和目标对应表,将数据写入到数据仓指定表,为统计分析和决策分析统计打下数据基础。
数据的加载策略一般有3种类型:直接加载、全部覆盖、更新加载。
1)直接加载
指加载时将数据直接加载到目标的图表中。该方法在清单类型的数据加载中比较常用。在数据分中心中将主要与增量抽取配合使用。
2)全部覆盖
若被抽取数据本身已囊括了该数据的所有情况,则使用该种方式。
3)更新加载
更新加载一般使用在采用连续方式记录对象业务状态数据变化,且需要用新数据和老数据进行比较。
2.4 数据共享交换
利用浙江省水利数据共享交换平台,开展数据资源目录整理及维护、基础数据管理与维护、数据共享交换等工作。
(1)数据资源目录整理及维护
为和省级数据资源目录保持统一规范,满足省市县数据一致的要求,采用省级统建数据资源目录管理模块,在省级资源目录的基础上,根据本地的数据情况增加本地的数据资源,继承省级数据资源目录的数据资源信息,并和省级数据仓保持同步。
(2)基础数据管理
建设水利数据仓库完成之后,水利数据管理的重点就是基础数据的维护和更新,需要规范更新数据流程,明确数据维护部门职责,做到每个数据都有源头可寻。所有的数据维护更新都应遵循职务权限范围,数据的维护更新由数据相对应的责任部门负责。通过将数据管理模块进行统一,依据统一的数据标准和格式来进行数据的收集、维护和更新。数据的有效性和准确性则需要通过有效的数据审核机制来实现。
1)省级通用基础数据管理模块
依托于省级数据仓自带的省级基础数据管理模块,以省级统一的要求对水利数据仓库的基础数据进行维护和管理,确保所有省级要求统一的基础数据均是按照全省的统一要求管理,保障水利数据仓库基础数据的规范性有效。
2)区级自有基础数据管理模块
根据实际需要,建设区级自有基础数据管理模块,实现区级自有基础数据管理,同时将区级自有基础数据管理模块需融入省级通用基础数据管理模块,实现省、市、区三级的数据同步共享。数据管理模块具备数源划分、数据更新维护、审核等功能,具备对区级基础数据的统一规范管理能力。主要功能有:①数源划分。对水利基础数据的具体对象进行数源划分,明确数源责任单位,实现数据的“一数一源”管理。数源划分需具备单个对象划分和批量划分功能,方便管理人员的操作和使用。②数据维护。数据维护模块提供对水利基础数据的查询、新增、编辑和删除等功能。维护后的信息存储在临时库中,经审核人员审核通过后进入正式数据库。数据维护模块只能查看和维护当前数源责任相关的基础数据。③数据查询。数据查询模块提供用户对权限范围内水利基础数据的查询功能。④数据审批。数据审批模块提供对修改后的数据的审核功能,通过审核确保数据的合法性。
(3)数据共享交换服务
1)数据服务管理模块
直接采用省级数据服务管理模块,实现瓯飞海塘数据服务注册、发布、调用、监控的统一管理[5]。
2)数据服务建设
基于瓯飞海塘水利数据仓,建设基础数据共享交换服务,实现与省、市两级水利数据仓的基础数据共享交换,以及与区大数据局的数据共享交换。其中省级水利数据仓中的基础数据共享交换服务,直接使用省级服务即可。业务应用的数据服务在业务应用建设过程中建设。
与区大数据局的共享交换。定义数据同步任务,定期将水利数据仓的数据推送至大数据局的数据平台中;结合水平台业务需求,按照区公共数据共享交换规定,向公共数据平台提出数据共享需求,实现水利数据仓与公共数据平台共享交换[5]。
与省、县(市、区)水利数据仓数据交换。区水利数据仓通过行业数据归集模块,按既定数据格式和共享需求,推送数据至省级、县级数据仓,同时可向省级申请数据共享授权,将省级、县级数据共享至区水利数据仓,实现水利数据“一数一源、共享交换”。
3 实践应用维护
(1)数据库异常应急
考虑到数据库异常在系统运行过程中会有概率出现,我们需要通过建立定时备份数据库的指令,让系统按时自动备份数据库。在出现外在原因或人为原因导致数据库损坏不能运行时,系统会自动检索最新备份数据库并恢复业务平台数据库,确保业务平台运行正常。
(2)数据库容灾和恢复
发生数据丢失会直接影响业务平台的运行和数据的实时性,甚至可能造成一定的社会影响。所以,在尽量短时间内完成数据库数据恢复和备份,保证平台正常运行是非常必要的。所以对水利业务平台数据库的容灾、备份和恢复是我们智慧化运行管理平台系统的重要组成部分。
系统对于数据库容灾能力建设采用的是在根数据库上配置两个容灾的备份数据库和严密的RMAN多级备份策略,分别放在不同的互联网数据中心,同步根数据库的数据,保障平台数据安全,以防因意外导致平台数据错误,同时可缩短恢复数据所需的暂停业务时间。
(3)备份方式
根数据库备份使用归档方式,并且采用严密的RMAN多级备份策略。使用归档方式的作用是当根数据库有意外错误时尽可能地复原根数据库,且能让已提交的所有数据得以保存。采用严密的RMAN多级备份是为了提高效率,减少备份需时,且保证系统的恢复性。所以在备份和恢复的时间上需要一个平衡点。
(4)备份策略
每月备份一次数据库的所有数据和表空间。每周做一次数据库的0级备份。所有数据库的变化都需要同步到CATALOG目录并重新备份。每次备份后均需备份归档日志。
4 结束语
本数据中心的研发基本满足了硬件数据的集成和软件数据的交互应用,达到了应用的效果,在实践运行中,具有可拓性好,性能稳定,起到支撑硬件实时数据的采集和汇聚,软件系统的数据支撑和模型计算,达到科学决策智慧支撑的作用。
