基于Stacking集成学习的车货匹配模型研究与实证分析
2022-08-20梁紫堃
梁紫堃
(华南理工大学电子商务系,广州 510006)
0 引言
我国公路货运市场准入门槛低,经营企业普遍存在规模小、分布散乱等问题,导致车、货物信息混乱,严重约束物流业发展。据交通部发布数据,2020年6月至7月全国高速公路货车空载率平均达24%。信息混乱导致车主无法在海量货物信息当中获取有用的货物信息,导致货车空载率提高,社会物流成本上升。随着大数据时代的来临,我国出现了很多车货匹配物流平台,如:运满满、货拉拉等。在大数据技术的支持下,车货匹配物流平台为车主、货主双方提供了一个渠道进行信息交流,进行车货匹配,解决货运市场车、货信息难以获取的问题,实现有效的资源整合。以货拉拉官网公布的数据为例,其月活机会员达66万,月活用户员达840万。因此,对于拥有大量车主和货主的平台来说,如何进行更有效的车货匹配,对车货匹配物流平台具有现实意义。
在此背景下,如何把海量的车、货精准对应起来,成为车货匹配平台需要解决的问题。现有的研究主要分为两类:一类基于语言描述,一类基于车辆位置。首先,基于语言描述的车货匹配主要是根据车主和货主对车、货信息的语言描述进行双边匹配,力求双方满意度最大化。朱江洪等从车货双方语言评价的角度出发,提出基于加权不确定性语言平均算子对车货双方的语言评价转化为评价矩阵,并结合双边匹配理论对车货匹配问题求解。李慧基于模糊综合评价法,建立车货双方的信誉评价体系,并提出车货双方的两层筛选匹配模型。盛莹等基于买卖双方满意度提出了基于改进的模糊信息处理的交易匹配度计算方法。其次,基于车辆位置的车货匹配则是结合车辆位置考虑车辆匹配,匹配目标以路线费用最小为主。牟向伟等考虑车与货之间的距离,提出了有约束惩罚的适应度衰减方法的量子进化算法进行车货匹配。陆慧娟等从多用户角度出发,提出车辆混合禁忌搜索算法对车货匹配问题进行求解。Hu等基于运力和服务优先,提出多目标实时调度模型以最小化成本的车货匹配模型。
上述工作的重点主要集中在根据当次车和货的信息进行匹配,但按照日常生活经验,在相同的外部环境之下,同一个司机对货物的每次选择都存在一定联系。然而就当次车和货物信息进行匹配,则难以考虑司机和货主的历史习惯。此外,在实际应用中,每个司机通常只对平台推送的小部分货物进行反馈。车货匹配模型需要根据不平衡数据预测司机偏好,从而为司机匹配符合其偏好的货物信息。
基于以上背景,本文使用运满满发布的数据集,进行RUS重抽样处理,通过Stacking算法将Logistic Regression、朴素贝叶斯以及Light-GBM模型等集成得到RLBL-Stacking模型,从而得到更优的检测结果。
1 车货匹配模型
1.1 随机欠抽样
随 机 欠 抽 样(Random Under Sampling,RUS)通过随机删除多数类样本以及保留少数类样本的方式,产生原始数据集的子集,达到均匀训练数据集中正负样本分布的效果。考虑到在实际应用中,车货匹配平台会给司机推送大量货物信息,但司机仅会对小部分货物信息感兴趣,而对于车货匹配来说预测这小部分的分类精度更加重要,因此本文先将训练集进行随机欠抽样处理,再进行训练。
1.2 St ac ki ng集成学习
Stacking算法主要是将多个不同的学习器选择性地线性组合在一起,从而综合多个学习器的预测结果,使模型更准确。一般的Stacking算法主要训练步骤为:首先用多个学习器对数据集进行训练;接着将训练得到的预测结果作为下一个学习器的输入,再次进行训练;最后得到预测结果。为避免过拟合的情况出现,本文将数据集与第一级学习器的预测结果共同作为第二级学习器的输入,最终得到的RLBLStacking模型如图1所示。
如图1所示,RLBL-Stacking模型首先将不平衡的原始数据作随机欠抽样处理,将逻辑斯蒂回归和朴素贝叶斯这两个基础模型作为第一级学习器,而LightGBM作为第二级学习器,把欠抽样处理过的数据和第一级学习器预测结果共同作为第二级学习器的输入,使得模型具有更高的预测精度。

图1 RLBL-Stacking算法示意图
1.3 逻辑斯蒂回归
逻辑斯蒂回归(Logistic Regression)是机器学习中常见的分类方法,不仅适用于二分类,也适用于多分类。判断事件发生与否表示为y,其取值为0表示事件不发生;取值为1则表示事件发生,为该事件y发生的概率,见式(1):

其中,=(,,…,θ)表示参数向量,是自变量,即司机、货主以及货物的特征向量,另外是特征向量的个数。
1.4 朴素贝叶斯
朴素贝叶斯(Naive Bayes)是一种以贝叶斯定理为基础的概率分类算法。算法假定存在x={,,…,a}为一个待分类项,其中a表示第个特征属性且满足条件独立分布,存在类别集合={,,…,y}。根据贝叶斯公式,待分类项为类别y的概率,如式(2)所示:

要对待分类项进行分类等同于求待分类项为类别y的最大概率,即求式(3)最大化。另外,式(2)中的分母对于所有类别来说都是常数,因此只要将分子最大化即可。又因为朴素贝叶斯假设各特征属性都是条件独立的,所以有式(3):

1.5 Li ght GBM模型
LightGBM(Light Gradient Boosting Matching)是对GBDT的改进算法,具有快速、低内耗、高准确性的优点,在工业界得到广泛应用。LightGBM主要采用单边梯度算法和直方图算法,实现最快速度和最小内存开支的要求下寻找最佳分裂点的目标,其核心是采用Leaf-wise算法作为树的增长策略,从当前叶子节点中找到增益值最大的一个叶子节点进行分裂,同时直方图算法大大改进了GBDT算法在构建决策树上的寻找最优分割点所带来的计算消耗,以及起到正则化的效果,有效防止过拟合。

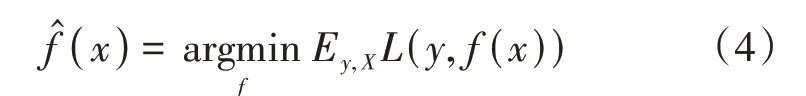
2 实证分析
2.1 数据分析及数据预处理
数据来源于运满满2018年主办的YMMTECH算法大赛提供的车货匹配数据集,共有1751673条,其中数据集由294个字段组成,其中前293个字段按照车货匹配主体分类可分为司机、货主和货物的特征;最后一个字段是司机的行为记录,作为预测目标的字段,该行为记录是指当天司机对货物的反应行为,不同的行为反映了司机对货物信息不同的偏好。运满满把司机的行为定义为司机对货物的评分:0分代表司机仅对平台推送的信息作浏览;1分代表司机对感兴趣货物进行点击,查看货物详细信息;2分代表司机查看货物信息后打电话进行接单。
数据集共有1751673条数据,其中评分为“0”的货物信息占比94.2%,评分为“1”的占比4.9%,评分为“2”的占比0.9%,如表1所示,数据分类不平衡。这是因为在现实中,系统每天都会给司机推荐大量的货物信息,然而司机并不会对推荐的全部货物信息感兴趣,司机一般只会浏览货物信息,并从中选择自己感兴趣的货物信息点击了解详情甚至电话联系。
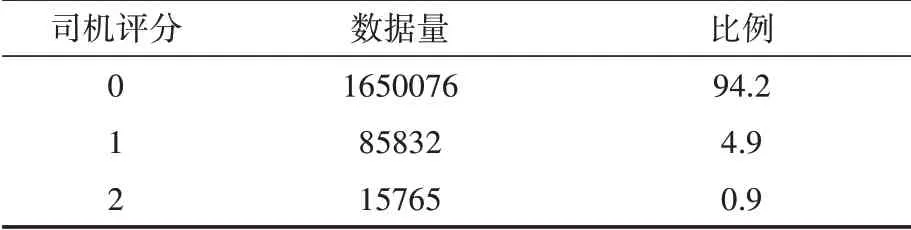
表1 数据集司机评分数量及比例
首先,从表1可见,在总样本数据中司机评分为“0”、“1”和“2”的分类数据不均匀,其比例为94∶5∶1,容易造成结果偏差。因此本文对司机行为三分类转化为二分类进行预测,即把司机评分为“1”和“2”的数据合并为评分为“1”。这是因为评分为“2”司机打电话详细咨询发生在评分为“1”点击查看货物信息的基础上,都是表达对推送的货物信息感兴趣,通过合并评分“1”和“2”,来提高评分预测的准确性。
其次,该数据集共有482556个样本没有对应的货主特征信息,这是因为运满满仅截取了部分货主信息,造成部分样本数据缺失对应的货主特征信息,会对模型结果产生较大的误差,本文将其剔除掉,使得数据集有1269117个样本。至于其他缺失少量特征的样本数据,则采用均值填充方式来处理缺失值。
针对数值型特征,用式(5)对其进行归一化处理,减少因数据的量级不同对模型结果造成的影响,其中代表归一化之后的数据,计算过程如式(5)所示,表示原数据,、分别表示原数据的最小、最大值。

同时为了更好地利用分类特征,需要对其进行重新编码。针对司机、货主性别等分类特征进行独热编码处理。此外根据业务要求,需要对司机常跑路线与货物运输路线、司机车长与货物所需车长、司机车型与货物所需车型等相关联特征数据进行匹配,得到新的特征并添加到训练特征集中,并采用XGBoost筛选得到特征重要性排序,保留重要性前100的特征,作为训练特征集。
此外在上述基础上,本文从数据集随机抽取70%的样本数据用作训练,剩余30%的样本数据用作测试。最终合并后的总样本、测试集、训练集评分为“0”、“1”的货物信息比例如表2所示。
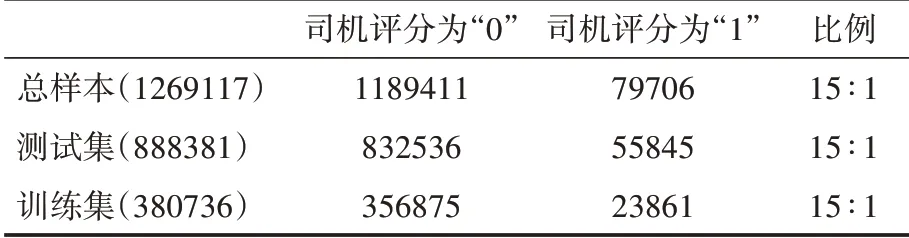
表2 总样本、训练样本、测试样本中司机评分为“0”、“1”的比例
2.2 模型性能评估
本文采用关于预测货物信息评分“1”的查准率(precision)、查全率(recall)以及值进行结果度量。我们用表示正类样本数,即实际评分为“1”的样本数;表示反类样本数,即实际评分为“0”的样本数,则表示正确预测评分为“1”的样本数,表示正确预测评分为“0”的样本数;表示实际评分为“0”,却被预测为“1”的样本数;表示实际评分为“1”,却被预测为“0”的样本数。它们之间的关系为:=+;=+。
查准率代表在预测评分为“1”的样本中实际评分为“1”的概率,具体如式(6)所示:

查全率代表在实际评分为“1”的样本中被预测评分为“1”样本的概率,具体如式(7)所示:

综合性评价指标的计算公式见式(8):

2.3 结果分析
本文采用逻辑斯蒂回归、朴素贝叶斯、随机森林、LightGBM等常见的分类方法与结合重抽样的LBL-Stacking模型作对比。其中逻辑斯蒂回归是常见的非线性模型,朴素贝叶斯是常见的线性模型;GBDT是通过bagging集成决策树的集成学习模型,LightGBM则是GBDT的改进算法,后两类模型都是典型的集成非线性模型。
表3的结果表明,从查全率来看RLBLStacking表现最优;但从查准率角度来看,随机森林模型表现最优,其次是LightGBM,而RLBL-Stacking则表现一般。造成这一情况的可能原因是单一的非线性模型出现过拟合。以随机森林为例,该模型共预测正确81个评分“1”,而将其余的23780个实际评分为“1”的误判为“0”,导致查准率高达100%,而查全率为0.34%。RLBL-Stacking通过牺牲一定的查准率来提升查全率,这是因为RUS通过减少多数类的数量来减少多数类造成的噪声。因为车货匹配的目的是为了提高平台司机总的接单量,因此在车货匹配中需要通过提高模型的查全率,尽可能挖掘司机偏好,为司机推荐更多潜在的订单,有利于提高订单成交量。通过结合了查全率和查重率的综合评价可以看出,相较于其他模型,RLBL-Stacking表现更佳。因此对于不平衡数据的车货匹配,RLBL-Stacking仍具有较好的估计性能。

表3 模型对评分为“1”的预测结果
3 结语
车货匹配算法作为车货匹配平台的主要功能算法支撑,目前正引起越来越多研究者的注意。本文考虑到车货匹配平台需要有效针对不平衡数据,提出结合重抽样RUS,然后整合逻辑斯蒂回归、朴素贝叶斯模型以及LightGBM得到RLBL-Stacking集成模型,并将之和其他单一分类算法进行比较。实验结果表明RLBLStacking集成模型具有一定优势,能够在不平衡数据集中取得较优的预测结果。本文仅对车货匹配数据的部分特征进行处理,并未结合天气以及司机打卡位置等数据进行考虑,因此后续研究需更进一步地考虑车货匹配数据之间的隐藏关联。
