基于深度学习的变电设备红外热像识别
2022-08-18曹恩宇王旭红
曹恩宇,王旭红
(长沙理工大学电气与信息工程学院,长沙 410114)
0 引言
变电站安全可靠的运行关系重大,在电力设备安全运行中,监测变电设备的温度和诊断分析热故障是尤其重要的[1]。随着科技的不断发展,国内很多变电站通过将红外监测设备安装在电力巡检机器人或者无人机等移动平台上,以这种智能监测的方式来代替人工巡检,虽然可减轻人工巡检的一些负担,但变电站中的变电设备种类多、分布密集,目前国内大部分的变电站识别和诊断红外热像所使用的仍是效率低且复杂的人工方法[2-3]。因此,有必要研究出一种无须人工参与且高效的变电设备红外热像识别技术。在变电设备红外热像识别技术中,为了保证识别的准确性,必须解决的一大难点就是变电站复杂的环境和密集的建筑物[4]。由于极端气候造成的杂波和噪声干扰,以及变电站设备与背景建筑之间的温差较小,所以背景环境和变电站设备无法有效分离,会导致识别精度较低[5]。
红外热像增强算法可以有效改善图像对比度低、噪声污染严重、视觉效果差的问题[6]。大多数现有的基于Retinex 的方法需要手动设置约束和参数。当应用于不同场景时,这些人为设置的约束和参数可能会受到模型容量的限制[7],该技术被广泛应用于图像增强领域。文献[8]提出了一种数据驱动的RetinexNet 图像增强算法,不仅解决了模型容量的限制,而且具有良好的增强效果。经过近几年的不断研究,国内许多研究机构开始着手于将深度学习应用于变电设备的识别中,并取得了一定的进展。基于Faster RCNN 的红外热像缺陷检测方法使用深度学习算法,虽然能够准确地定位和识别红外热像,弥补了传统方法在识别的准确率上的不足,但是没能优化低对比度情况下的红外热像识别精度[9],而且Faster RCNN 等两阶段模型所需要的检测时间较长,实时性无法得到保障[10]。将自适应感知模块和YOLO-v3 网络结合进行绝缘子缺陷定位和识别的方法,对检测的定位速度和识别精度均有所提升[11]。由于没有图像预处理这一环节,因此在复杂的环境背景中该方法的最终识别效果会被噪声等因素影响。
本文研究了一种基于深度学习的变电站设备红外热像增强和识别的方法。首先使用RetinexNet 图像增强方法,解决变电站设备红外热像温度分布过于集中、对比度低、变电站背景复杂等问题,为准确识别变电站设备红外热像创造有利的条件;然后利用YOLOX-Darknet53 算法对变电设备进行识别。该方法能够满足变电站智能监测在准确性、高效性以及实时性上的要求。所设计的变电设备红外热像识别流程如图1所示。

图1 变电设备红外热像识别流程图Fig.1 Flow chart of infrared thermal image recognition for substation equipment
1 基于RetinexNet 的图像增强
1.1 RetinexNet 算法介绍
Retinex 理论是由Land 等学者[12]于1971 年提出的,这是一种模拟人眼感知颜色和亮度能力的理论。Retinex 算法可以从图像中估计出入射光和出射光的强度,减少入射光对反射光的影响,从而增强图像。Retinex 理论将图像视为光照分量I和反射分量R的乘积即:

式中,S为原始图像,I为原始图像的光照分量,R为原始图像的反射分量。RetinexNet 算法是一种基于Retinex 理论和CNN 算法的低照度图像增强算法,该算法集成了图像分解和连续图像增强操作,RetinexNet 算法流程图如图2 所示。
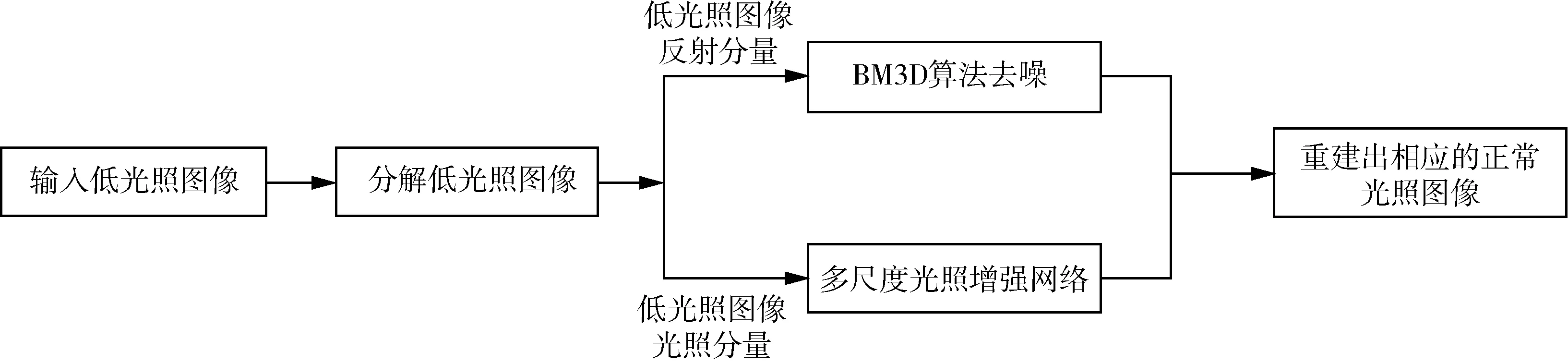
图2 RetinexNet 算法流程图Fig.2 Algorithm flow chart of RetinexNet
1.2 RetinexNet 网络结构
RetinexNet 算法分为三个步骤:分解、增强和重建,该框架如图3 所示。其中,分解步骤是对图像的光照分量I和反射分量R进行分解;增强步骤主要是抑制反射分量R的噪声,同时矫正图像的光照分量I;重建是通过式(1),将处理后的I和R相乘,构建出调整后的正常光照下的图像。
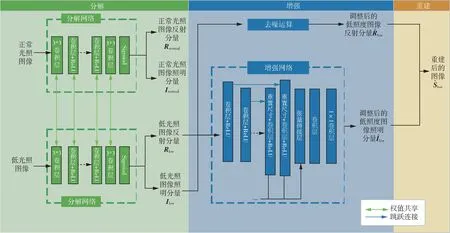
图3 RetinexNet 网络结构图Fig.3 Network structure diagram of RetinexNet
1.2.1 分解
在RetinexNet 网络的分解步骤中,使用多个3×3 卷积层、ReLU(Rectified Linear Unit)激活函数和池运算来提取不同级别的图像特征。为了结合U-Net[13]的思想,首先进行上采样,以确保组合特征图的大小一致,并将前几层的特征图引入更深一层,进行复制和拼接,然后进行特征融合,以获得更完整的细节特征图。最后一个3×3 卷积层从特征空间投影光照分量和反射分量,并通过Sigmoid 函数将光照分量和反射分量约束在[0,1]的范围。
分解模型的损失函数L包括重建损失(Reconstruction Loss)、反射分量一致性损失(Invariable Reflectance Loss)和光照分量平滑损失(Illumination Smoothness Loss),如式(2):

式中,Lrecon为重建损失,Lir、Lis分别为反射分量一致性损失和光照分量平滑损失,λir、λis则分别为反射分量一致性和照度分量平滑度的系数。
重建损失Lrecon函数表达式:
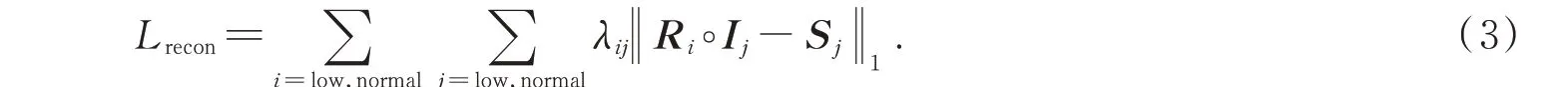
该函数的作用是使分解出来的反射分量R和光照分量I,尽可能多地重建相应的原始图像。
光照分量平滑损失Lis函数表达式:
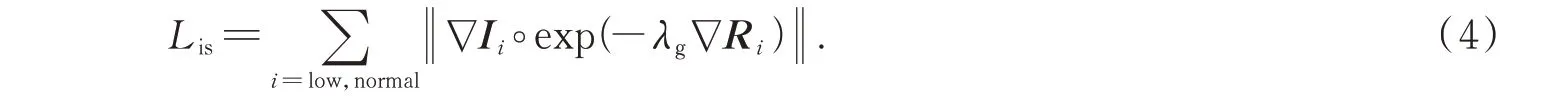
式中,low 和normal 分别代表低光照图像和正常光照图像,λg表示平衡结构感知强度的系数,∇Ii为所分解出的图像光照分量的梯度值,∇Ri为图像反射分量的梯度值。假设一个光照分量I,在纹理细节上比较平滑,并且能够较好地保留整体结构[14],则该函数通过对反射分量R求梯度,来给光照分量I的梯度图分配权重,使得分解出的光照分量是分段平滑的。
反射分量一致性损失Lis函数表达式:

式中,Rlow为低光照图像的反射分量,Rnormal为正常光照图像的反射分量。根据Retinex 分解理论,图像的反射分量R和光照无关,因此图像反射分量的一致性受到该函数的约束。
1.2.2 增强
通过算法的分解网络可得到低光照图像的Ilow和Rlow在RetinexNet 算法的增强步骤中,使用增强网络对Ilow进行调整,使用BM3D(Block-matching and 3D filtering,三维块匹配滤波)算法对Rlow进行去噪增强。。
RetinexNet 网络的增强网络遵循编码器-解码器架构。首先,利用编码器对Ilow进行小尺度逐次下采样,使网络能够学习到大区域的光照分布,下采样块由一个步长为2 的卷积层和一个ReLU 组成。其次,利用解码器对具有大规模光照信息的增强光照图进行重建。在上采样操作中,采用多尺度拼接的方法来保持全局照度和局部照度分布的一致性。上采样块由ReLU 激活的调整大小的卷积层组成。通过单元求和,在下采样块与对应的上采样块之间引入跳跃连接,迫使网络学习残差。编码器-解码器结构含有M对下采样和上采样块,在实验中M取值为5,在保持良好处理速度的同时,提供了良好的增强结果。最后,将所有重建通道进行级联,并将结果通过1×1 卷积层和3×3 卷积层进行推送,重建增强光照图I^low。
一般来说,由于各种条件的限制和随机干扰,采集的图像包含大量的噪声,改变了原始图像中事物的特征,直接对图像进行分析会造成偏差。BM3D 算法是一种基于三维变换滤波的算法,是实现图像和视频降噪的最佳算法之一。BM3D 算法分为两个步骤,第一步是基本估计,第二步是最终估计,在基本估计中得到权重参数,然后通过所得到的权重来过滤噪声。
输入低光照图像的反射分量Rlow,经BM3D 算法的基本估计步骤,对图像进行分块组合,针对输入的低光照图像目标块,以滑动搜索框的方式找到M个相似块,对图像进行DCT 变化后再用欧氏距离衡量相似程度,以从小到大的顺序进行排序,得到一个由M个相似块组成的三维数组;然后将三维数组中每个块相同位置的像素点构成一个数组,将其中小于超参数的值置零,并统计非零成分的数量,对三维矩阵进行逆变换;最后将逆变换后的块放回原位,利用非零成分数量统计叠加数权重,将叠放后的图除以每个点的权重就得到了基础估计的图像。通过基础估计处理后就能很好地消除图像中的噪点,但是需要去除低频系数上的噪声并还原更多的图像细节。在BM3D 算法的最终估计步骤中,首先根据基础估计后的图像与输入的低光照图像通过欧式距离衡量基础图中的块与低光照图像之间的相似度,得到两个三维数组;然后对两个三维数组都进行DCT 变换和一维变换,用维纳滤波根据基础估计图像上的变换系数,对低光照图像形成的三维矩阵进行系数放缩;最后将系数与低光照图像的3D 图块相乘后放回原位,并做加权平均调整,就得到了最终估计图的。
1.2.3 重建
RetinexNet 算法在通过增强模型对分解后的低光照图像的反射分量和光照分量增强后,得到相应的和。在重建步骤中,将其通过式(1)计算,可以恢复出正常光照图像。
2 基于YOLOX-Darknet53 网络的红外热像识别
在目标检测算法中,YOLO 系列占据了重要的地位,目前使用最广泛的是YOLO-v3[16]。最新版本的YOLOX 是由北京旷视科技有限公司于2021 年开发的,与之前的YOLO 系列相比,YOLOX 在识别速度和识别的准确率上更有优势。
2.1 YOLOX-Darknet53 网络结构
YOLOX-Darknet53 网络结构图如图4[17]所示,将YOLOX-Darknet53 网络分为四个部分:输入端、骨干网络(Backbone)、颈部(Neck)和预测层(Prediction)。
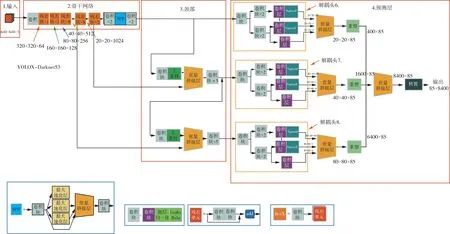
图4 YOLOX-Darknet53 网络结构图[17]Fig.4 Network structure diagram of YOLOX-Darknet53
(1)输入端:YOLOX-Darknet53 主要采用两种数据增强方法,即Mosaic 和Mixup。Mosaic 是YOLO-v3推出的一种非常有效的增强策略,通过随机缩放、随机剪裁和随机排列的拼接可以显著提高小目标的检测效果,而Mixup 是一种基于Mosaic 的附加增强策略。通过这两种数据增强方法,直接将YOLO-v3 baseline提高了2.4 个百分点。
(2)骨干网络(Backbone):YOLOX-Darknet53 的Backbone 骨干网络与YOLO-v3 baseline 的骨干网相同。两者均采用Darknet53 的网络结构,该网络由一系列1×1 和3×3 卷积层组成。由于该网络有53 个卷积层,因此被称为Darknet53。
(3)颈部(Neck):与YOLO-v3 baseline 相比,YOLOX-Darknet53 并没有改善Neck 结构,而是采用同样的FPN 结构进行融合。FPN 能够通过上采样,从上到下传递和融合金字塔的高层特征信息,提高了对小目标的检测能力,在模型的性能方面也有显著的优化效果。
(4)预测层(Prediction):在YOLOX 的预测层,使用了三个解耦头(Decoupled Head)。此外,预测层还包含了标签分配策略SimOTA(Simplified Optimal Transport Assignment)、Anchor-free 检测器、Loss 计算。
2.2 YOLOX 的改进
尽管过去使用的YOLO 系列是一种很好的目标检测模型,但近年来,这一系列模型并未从目标检测领域引入无锚框(anchor-free)检测器、端对端检测器(NMS-free)和更好的Label Assignment 技巧。为了提升目标检测的性能,YOLOX 结合了YOLO 检测器与无锚框检测器,引入了解耦头并使用标签分配策略,有效地提升了目标检测的速度和精度。
2.2.1 无锚框(anchor-free)检测器
以往的YOLO 算法中未使用anchor-free 检测器,多使用anchor-based 检测器,而在YOLOX 中引入了anchor-free 检测器。anchor-based 检测器与anchor-free 检测器相比,有些许不足之处:首先,在Anchorbased 检测器中,由于这些锚框只能应用于对应的区域,因此降低了算法性能;其次,锚框会使得模型的复杂度提高,同时也会增加预测图片的数量。
现在,anchor-free 不仅优化了训练和解码阶段的复杂度,而且其检测速度和精度已经不亚于anchorbased[18]。
在引入了anchor-free 检测器后,YOLOX 变成了一种无锚方式。可以将每个物体的中心点指定为正样本,并提前校准刻度范围,以指定每个对象的FPN 级别。经过这样的修改,参数和检测器GFLOPs 都降低了,因此其检测速度更快,精度更高。
2.2.2 解耦头(Decoupled Head)
目前,许多一阶段网络,如RetinaNet 和FCOS 等,都会应用解耦头。解耦头结构主要考虑目标检测中分类和回归的不同内容,因此采用不同的分支进行操作,以提高检测效果。
通过实验,分析了耦合的检测头对系统性能的不利影响,所以提出了以下方法。
(1)使用一个解耦头代替YOLO 的头部,可使模型的收敛速度更快。
(2)用一个轻量解耦头取代YOLO 检测头,这个解耦头包含一个1×1 卷积层,该卷积层可使信道尺寸减小,在这个卷积层后面是两个并行的分支,每个分支都带有两个3×3 卷积层。2.2.3 标签分配策略SimOTA(Simplified Optimal Transport Assignment)
在标签分配策略中,OTA 所解决的是锚点分配(Anchor Assignment)问题。通常,在分配正样本和负样本时,我们根据锚框和分割图像的交并比IoU(Intersection of Union)进行分配。正、负样本的分界线与遮挡情况,以及目标的形状、大小是紧密相关的,而且如何分配正负样本需要从全局考虑。因此,在线性规划中,锚点分配通常被视为一个传输优化问题。这一策略的核心思想是建立一个代价矩阵。假设一个大小为N×P的代价矩阵中分割图像的数量为N个,锚框的数量为P个。锚框和分割图像的损失值由代价矩阵中的元素来表示。每对GT 和anchor 的成本与损失值相关,损失值越大则成本越高。优化传输是为了以最小的代价来选择锚框和分割图像的匹配度。YOLOX 的开发者发现,在优化传输问题的过程中,使用Sinkhorn-Knopp 算法所花费的训练时间会额外多出25%。因此,可将这个算法过程从整个网络结构中抹去。
3 实验过程与结果
3.1 数据集的构建与训练
为了构建数据集,在训练YOLOX-Darknet53 网络之前,本文选择了8 种变电站中常见的变电设备,分别为隔离开关触点(isolation)、电流互感器(CT)、隔离开关进线(isolation_in)、避雷器(LA)、隔离开关出线(isolation_out)、电压互感器(PT)、断路器(breaker)和接地开关(ground_switch)。
使用红外热像仪采集到的样本数量为3 000 张,其中电流互感器与电压互感器图像各500 张,隔离开关触点、进线、出线的图像各400 张,断路器、避雷器图像各300 张,接地开关图像200 张。样本数据集在经过图像增强后扩展至10 000 张。为保证训练过程中训练样本充足,本文留下数据集中10%的图像作为测试集,其余的图像作为训练集。在硬件方面,训练所使用的计算机搭载了两个2080ti 的GPU,并使用MegEngine框架来训练YOLOX-Darknet53 网络。为了提升模型的学习速度,在训练的过程中加入了Adam[19]优化算法和迁移学习。在训练过程中所检测到的参数,都会在整个训练结束后被系统自动保存。
3.2 背景温度干扰下不同图像增强算例对比
图5 为在背景温度干扰下,分别使用带色彩恢复的多尺度Retinex 算法(MSRCR)、带色彩保护的多尺度Retinex 算法(MSRCP)与本文所使用的RetinexNet 图像增强算法的效果对比图。在不同的天气下,变电设备经常会因为与背景环境温差小,使得红外热像对比度低,无法从背景中分割出变电设备。从图5 中可以看出,本文所使用的增强方法,可以明显提升变电设备与周围建筑以及背景环境的对比度,以减少干扰,更易识别。

图5 背景温度干扰下不同图像增强方法对比Fig.5 Comparison of different image enhancement methods under background temperature interference
为进一步说明本文所使用的增强算法的优越性,实验中分别用峰值信噪比[20](PSNR)、平均结构相似度[21](SSIM)两个图像融合的质量评价方法来与不同的算法做比对,如表1 所示。两个数值分别代表着图像的质量、与原图的差距。其中PSNR 的数值与图像质量相关,PSNR 值越大,则图像质量越好;SSIM 的数值越大,与原图的差别就越小。
如表1 所示,本文所使用的红外热像增强算法的PSNR 值最大,SSIM 值最小,增强的效果最好,对于提升变电设备的红外热像识别精度十分有利。

表1 不同的图像增强算法对比Tab.1 Comparison of different image enhancement algorithms
3.3 YOLOX-Darknet53 网络的识别算例
本文所使用的YOLOX-Darknet53 网络总共进行了68 次迭代训练,耗时150 min,最终损失值如图6 所示,收敛在2.65。
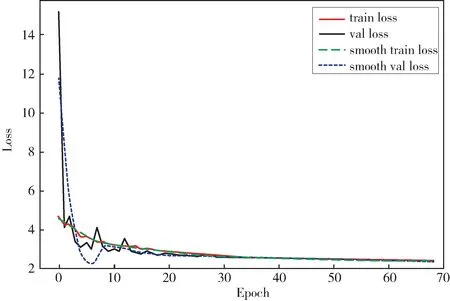
图6 损失收敛过程Fig.6 Loss convergence process
在1 500 幅红外热像上测试本文所使用的检测算法,选取的变电设备红外热像皆为背景温度干扰较大的图像,使用本文提出的图像增强方法前后的识别结果对比如图7 所示,算法识别出的不同的变电设备被标记为不同颜色的矩形框。
由图7 可知,不仅训练过后的变电设备几乎都能被识别出来,而且识别的置信度很高。本文通过表2 所列举的指标对该YOLOX-Darknet53 网络的性能进行评价。
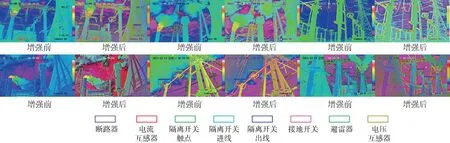
图7 图像增强前后的识别结果对比图Fig.7 Comparison of recognition results before and after image enhancement
由表2 可知,使用本文所提出YOLOX-Darknet53 网络,8 种变电设备的平均精确度为96.51%,F1-score 为96.77%,召回率为97.04%。将YOLOX-Darknet53 网络与YOLO-v3 网络进行比较,YOLOXDarknet53 网络比YOLO-v3 网络的平均检测速度提高了1.19 ms/张,平均F1-score、平均精确率、平均召回率分别提高了2.65%、3.79%和1.45%。该结果说明了将YOLOX-Darknet53 网络的检测算法用于变电设备的红外热像识别比使用传统YOLO-v3 方法的效果更佳。
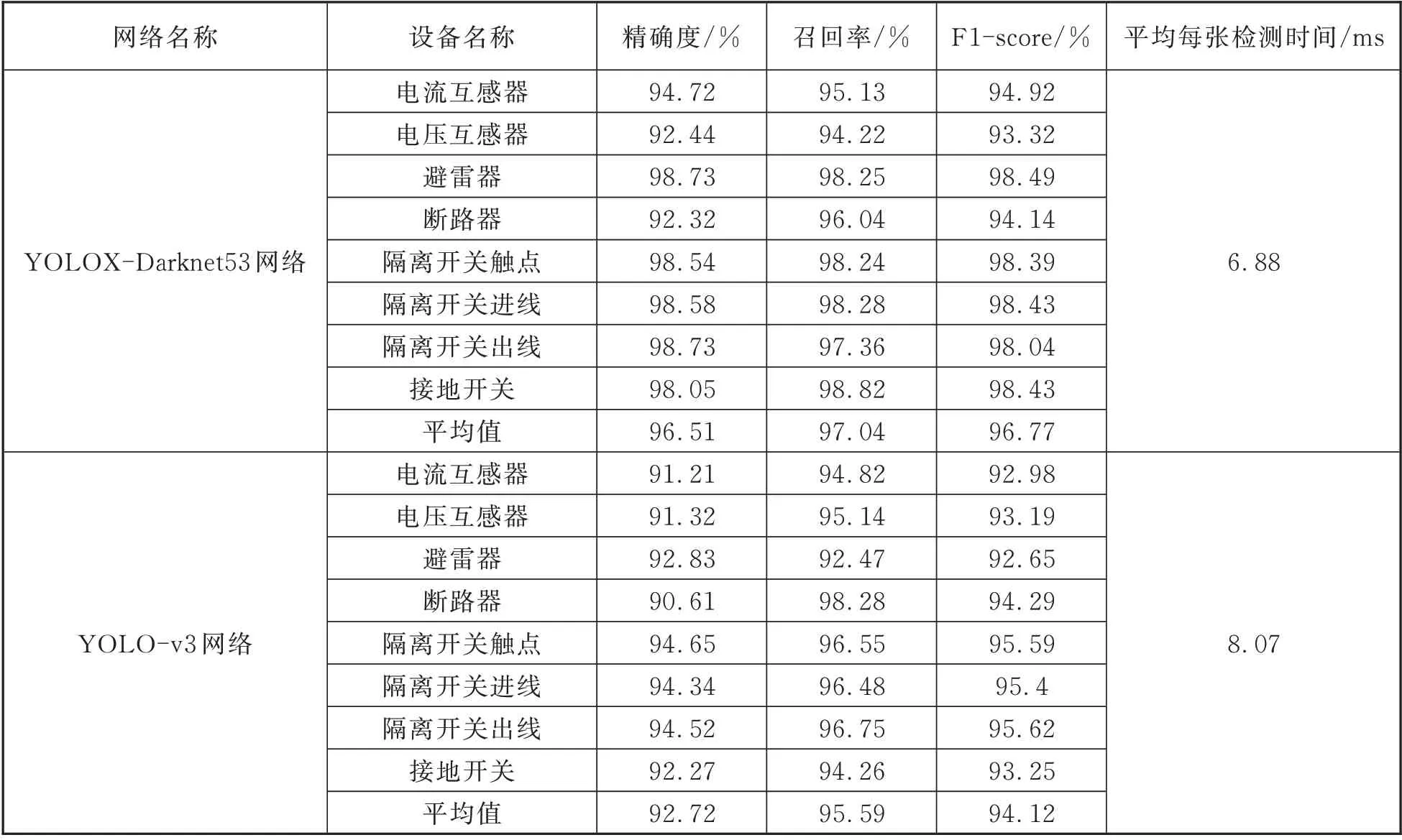
表2 8 种不同设备的识别结果Tab.2 Identification results of 8 different devices
4 结论
使用RetinexNet 红外热像增强算法能够有效克服夜间、温度分布均匀等情况下,被检测设备与背景融为一体难以识别的缺点。在实验中,通过对使用YOLOX-Darknet53 网络与YOLO-v3 网络的算例识别结果进行比较可知,使用本文所提的YOLOX-Darknet53 网络的平均检测速度较YOLO-v3 网络提高了1.19 ms/张,而平均F1-score、平均精确率、平均召回率分别提高了2.65%、3.79%和1.45%。由实验结果可知,本文所提红外热像识别方法具有良好的准确性、实时性,能够满足在变电站复杂场景中的实时监测要求。
