基于ALBERT-CAW模型的时政新闻命名实体识别方法
2022-08-17范钰程梁凤梅邬志勇
范钰程,梁凤梅,邬志勇
(太原理工大学信息与计算机学院,山西晋中 030600)
命名实体识别的核心任务就是从文本中识别出人名、地名、机构名等实体的边界和类别,是问答系统、机器翻译、情感分析、知识图谱等NLP 任务的关键[1-2]。
在新闻文本中,词语更新速度快,且存在着大量一词多义的现象[3-4],之前的方法无法在进行特征提取的同时兼顾局部特征信息和上下文含义,对同一个词在不同上下文中的不同含义区分度较差。该文结合预训练语言模型ALBERT(A Lite BERT)和字词融合(Char and Word,CAW)方法,提出一种命名实体识别模型ALBERT-CAW-BiLSTM,充分利用文本的局部特征信息和上下文关联语义,通过对比实验证明了在新闻命名实体识别中的有效性。
1 相关工作
文献[5]提出的Lattice LSTM 模型,对输入文本和潜在词汇进行了编码。文献[6]中采用融合字词BiLSTM(Bi-directional Long Short-Term Memory)的命名实体识别方法,该方法独立处理字模型和词模型。文献[7]把能获取更复杂语义的预训练语言模型BERT 应用于实体识别。文献[8]采用了BERT 的改进版ALBERT,在模型参数少的情况下达到了更好的效果。
文献[9]提出了一种基于新词的新闻命名实体识别方法,该方法借助新词词典提升了新词的识别准确率,但是对词典未覆盖的未登录词基本上没有识别能力。文献[10]采用基于注意力机制的BiLSTM 结合条件随机场(Conditional Random Field,CRF)模型,能获在取局部特征的同时兼顾上下文语义,但该模型使用ngram2vec 训练词向量,对比于ALBERT 并没有充分提取文本信息。
2 ALBERT-CAW-BiLSTM模型
如图1 所示,该文模型主要由四部分组成,包括ALBERT、CAW、BiLSTM 和CRF。
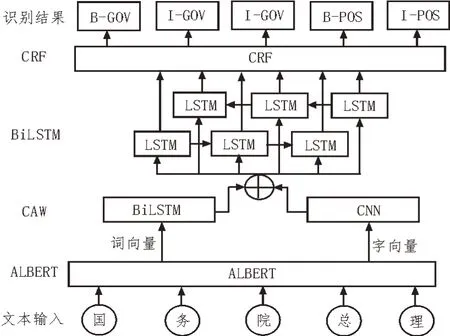
图1 ALBERT-CAW-BiLSTM 模型
1)采用预训练语言模型ALBERT 获取文本的动态词向量;
2)在CAW 层利用多层CNN 提取词语局部特征,使用LSTM 获得词语的前后语义信息,将两者的结果融合成包含丰富信息的动态特征;
3)在BiLSTM 层获取CAW 层已经捕捉实体在序列中的上下文信息,获取M维概率分布;
4)通过CRF 层进行解码,得到实体标注信息,完成对实体边界和类别的识别。
2.1 ALBERT
ALBERT 模型采用双向transformer 提取语言特征,具体结构如图2所示。E1,E2,…,En是输入序列中的字符,在经过多层transformer 训练之后得到输出的文本特征向量T1,T2,…,Tn。模型中每个字符对应的词向量由三个向量组成:字向量(Token Embeddings)、文本向量(Segment Embeddings)和位置向量(Position Embeddings),模型输入为字向量、文本向量和位置向量的和。其中,文本向量代表的是全局的语义信息,且和单字的语义信息相融合;位置向量是人为给定的序列位置向量。

图2 ALBERT模型
Transformer的结构为Encoder-Decoder,ALBERT使用的是Encoder 特征抽取器,其具体结构如图3所示。
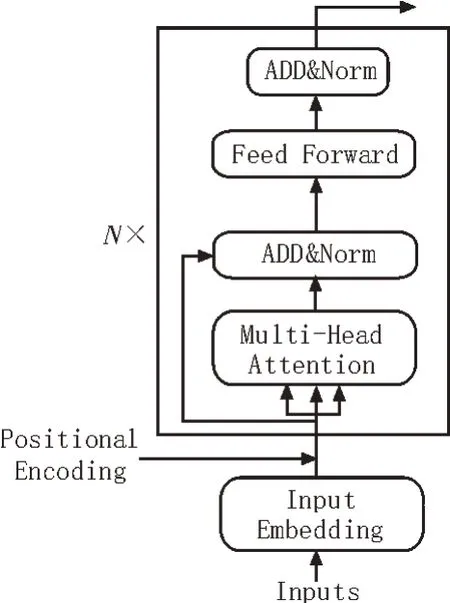
图3 Transformer Encoder结构
与传统神经网络模型相比,ALBERT 能有效提取上下文信息,语义信息丰富,能较好地处理一词多义的问题。
2.2 CAW层
词向量的获取有基于字符和基于词两种方法。基于字符的方法处理的基本单位是字,不需要对输入文本进行分词,减少了未登录词的干扰,但是中文大多不是以单字作为表达语意最小单位,因此其相比基于词存在着语义信息不足等问题。基于词的方法首先需要对输入文本进行分词,分词的效果直接影响最终命名实体识别的效果。两者各有优缺点,因此,该文综合考虑后采用融合字词语义的方式提取文本特征,其结构如图4 所示。
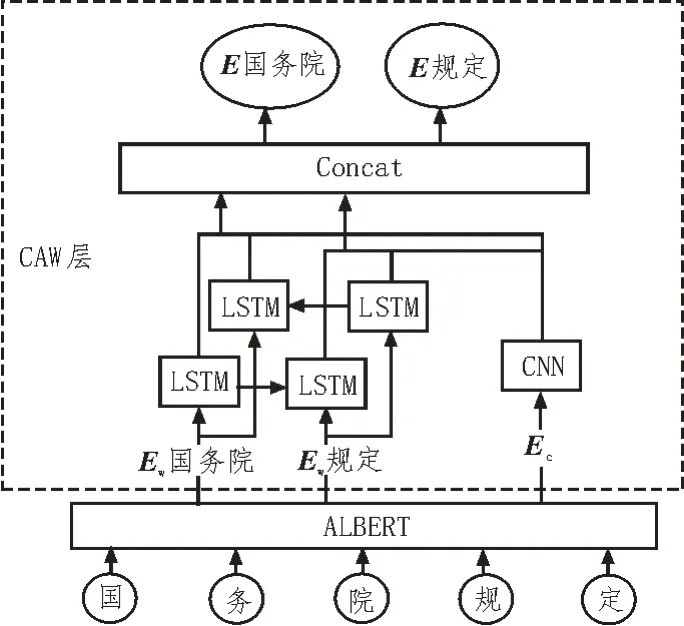
图4 CAW结构
2.2.1 CNN
CNN 的核心是卷积层,主要思想是参数共享和局部连接,特征提取依靠的是对单词的卷积运算。将不同大小的输入特征局部窗口与卷积核进行卷积,将结果通过非线性激活函数f处理得到输出,公式如下:
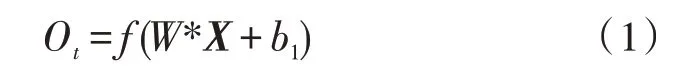
其中,常用的f包括sigmoid、tanh 和ReLU 等,W是卷积核,X是输入词向量,b1是偏置。
在池化层使用最大池化的方法提取最大的特征值,计算公式为:

其中,pj是池中第j个区域内最大的特征值,cj是卷积得到的新特征。
2.2.2 Bi-LSTM
LSTM 是常用的命名实体识别模型,能解决RNN常见的梯度消失和梯度爆炸问题[13]。其结构如图5所示。
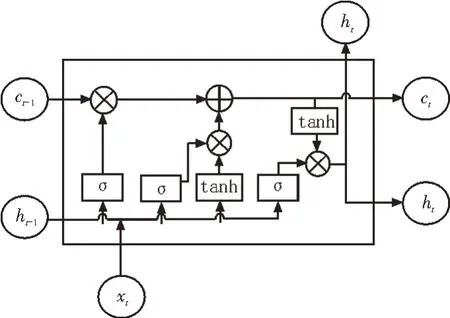
图5 LSTM细胞
其中,xt代表当前t时刻的输入,ht是t时刻隐藏层输出,ct代表t时刻细胞的记忆状态,σ是sigmoid 函数。LSTM 的3 个门控单元为输入门it、遗忘门ft和输出门ot,其更新公式如下:
其中,W为隐藏层权重参数矩阵,b为偏置矩阵。
LSTM 细胞的记忆状态ct和隐藏层ht公式如下:
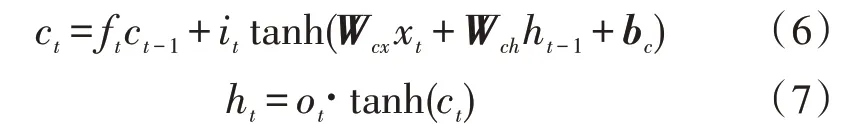
LSTM 能在一定程度上解决梯度消失和梯度爆炸的问题,但是在序列标注任务中,还存在着其他问题,LSTM 只能利用前向信息,无法使用对t+1 时刻的信息,因此提出了双向LSTM(BiLSTM),结构如图6所示。
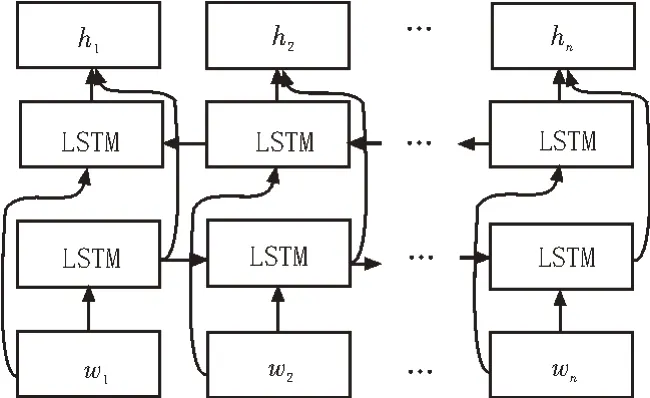
图6 BiLSTM结构
正向输入LSTM 得到输出可以理解成“历史信息”,将序列反向输入LSTM 得到“未来信息”,对两者进行连接合并。需要注意的是,前向LSTM 和后向LSTM 参数并不共享。BiLSTM 模型能很好地提取上下文信息,获得更佳的语义信息[11-13]。
2.2.3 CAW的实现
考虑到使用CNN 虽然能够高效地提取文本局部特征,但是却无法挖掘上下文信息;LSTM 能有效地使用上下文信息,但是因为自身循环递归的设定,网络复杂度较大。因此该文提出字词向量融合的方法,同时输入字向量和词向量,用CNN 和LSTM 分开处理字向量和词向量,尽可能挖掘文本局部信息和上下文语义信息。
用CNN 训练字向量的过程如下:对于字向量,按照分词结果将其输入CNN 来提取信息,根据CNN的窗口大小,不等长的用padding 进行填充,通过卷积操作和最大池化抽取词语所包含的特征,得到新的词级别的特征向量对于词向量,使用BiLSTM提取词向量特征的前后语义,将输入词向量Ew通过BiLSTM 网络训练,即可得到新的初步提取过语义信息的词向量,最后将两者进行Concat 拼接融合,获得拼接后的词向量Ecaw。例如,在处理“国务院总理”时,会根据分词“国务院”“总理”将词语的语义信息拼接到各自的动态特征中。
2.3 CRF
条件随机场(Conditional Random Fields,CRF)是序列标注任务的概率化模型,是根据输入序列预测输出序列标签的判别式模型[14]。CRF 能在给定一组输入的条件下,给出另一组输出变量的条件概率分布模型,可以对分词、词性和实体等特征进行预测。
CRF 的判别公式如下:
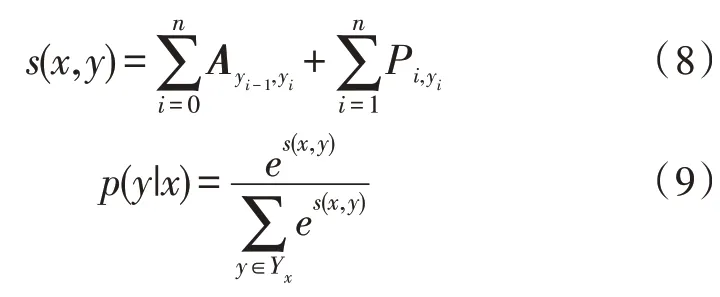
s(x,y)是评估分数,A为转移矩阵,p(y|x)为输入序列到标签序列的对应概率,Yx是所有可能的标签序列,最终使用维特比算法解码获得最可能的标签。
3 实验与分析
3.1 数据标注
该文选择的数据来源是爬取近一年(2020年1月-2021 年1 月)的人民日报图文数据库(http://paper.people.com.cn/)时政新闻数据。人民日报分要闻、评论、理论、文化、国际、经济、体育和国际等多个版块,该实验爬取要闻、文化、经济、体育和国际等版块,标注了其中3 100 篇时政新闻数据作为实验的数据集,按照7∶3 的比例划分训练集和测试集。同时根据爬取的数据自建词典,收录近年的热点名词,提升了分词的准确率。
在制定标注规则时该文考虑新闻的人物、地点、事件等要素,将实体划分为七类。例如,人物要素可以分割成人名和职位两类实体。数据标注均采用BIO 三段标记法,“B”代表每个实体的第一个字,“I”代表实体中除第一个字以外的字,“O”代表无关字。实体分类标注格式如表1 所示。例如,国“B-GOV”、务“I-GOV”、院“I-GOV”、总“B-POS”、理“I-POS”、李“B-PER”、克“I-PER”、强“I-PER”、近“O”、日“O”。
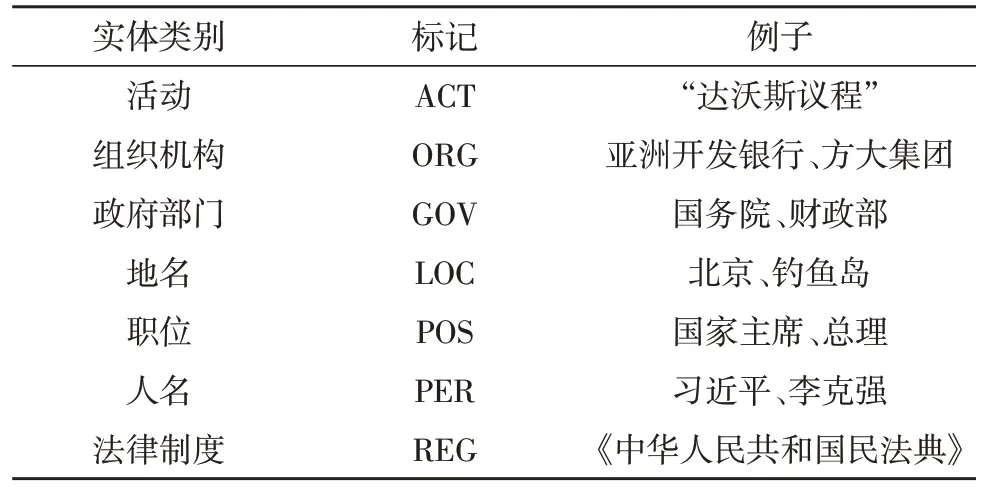
表1 实体分类
3.2 评价指标
该文采用的评价指标为精准率P(Precision)、召回率R(Recall)和F1 值,P表示正确识别的实体占识别出实体的比例,R表示正确识别实体占应识别出实体的比例,F1 是综合P和R的评价指标。具体公式如下:
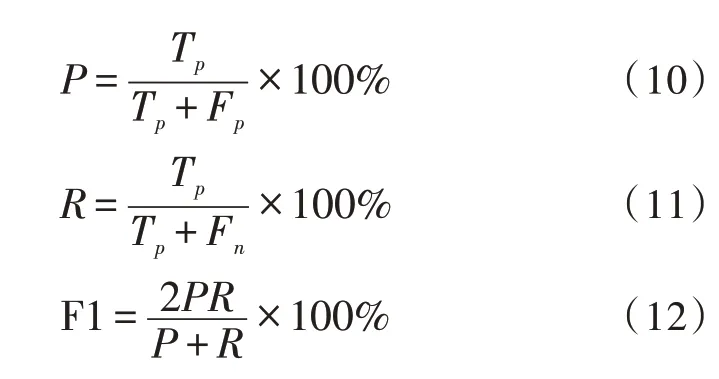
其中,Tp是正确识别的实体个数,Fp是识别出的错误实体个数,Fn是没有识别出的实体个数。
3.3 实验环境和参数设置
实验环境如表2 所示。

表2 实验环境
该文的实验参数中预训练模型采用ALBERTbase,优化器为Adam,学习率初始值设置为2×10-5,迭代次数epoch 设置为40。
3.4 对比试验设置
该文设置了4组对比实验,分别采用Word2Vec和jieba 获取词向量的BiLSTM[11-13]模型,采用Word2Vec和jieba获取词向量的CNN模型,ALBERT-BiLSTM[15]模型和该文字向量与词向量融合的ALBERT-CAWBiLSTM 模型。
3.5 试验结果与分析
表3 是ALBERT-CAW-BiLSTM 模型在时政新闻数据集上的P、R和F1 值。
根据表3 的实验结果可以发现,除了活动识别的F1 值较低,只有76.2%,其他命名实体的F1 值均高于83%,说明该模型在时政新闻数据集标签种类较多的情况下表现良好。法律制度类的实体适用场景特殊,对这些实体中的未登录词的识别效果最好。例如,在“发布新修订的《军队院校教育条例(试行)》”文本中,法律制度实体“《军队院校教育条例(试行)》”能被正确识别。语句“联合国、世界卫生组织等国际组织发出要团结、不要污名化的呼吁”中,模型识别出了“联合国”、“世界卫生组织”为组织机构实体。“在习近平总书记亲自指挥、亲自部署下”识别出“习近平”为人名实体,“总书记”为职位实体。检查数据集中识别效果不佳的活动实体,发现是因为活动名称命名没有规律,容易出现未登录词和歧义词,模型对活动实体的识别能力有所下降。例如在“自然资源调查监测底图年底将完成”语句中,仅仅识别出“调查监测”,正确识别的活动实体应为“自然资源调查监测”。
从表4 中的结果可以看出,该文模型在P、R和F1 值上比BiLSTM 高出9.5%、7.6%、8.5%,比CNN 模型高出13.5%、20.9%、17.7%,这是因为BiLSTM 和CNN 均是使用word2vec 来获取静态词向量,虽然有较强的通用性,但是无法解决一词多义及同义词问题。这一结果证明了该文模型使用预训练语言模型,在学习特征、语义抽取方面性能表现优秀,能充分利用句子中的上下文信息。在特征提取的过程中,CNN 模型使用池化层对文本特征进行降维会导致语义信息损失过多,BiLSTM 只考虑到上下文的语义信息,两者都不能充分使用文本信息。对比ALBERT-BiLSTM 模型,该文模型F1 值提高了2.9%,召回率R提高了3.7%,准确率P提高了1.9%,在自身模型已经识别效果较好的情况下,证明了引入字词融合(CAW)的方法能更充分地利用文本中上下文语义信息和局部特征信息,有效地划分出实体边界,提高命名实体的识别效果。
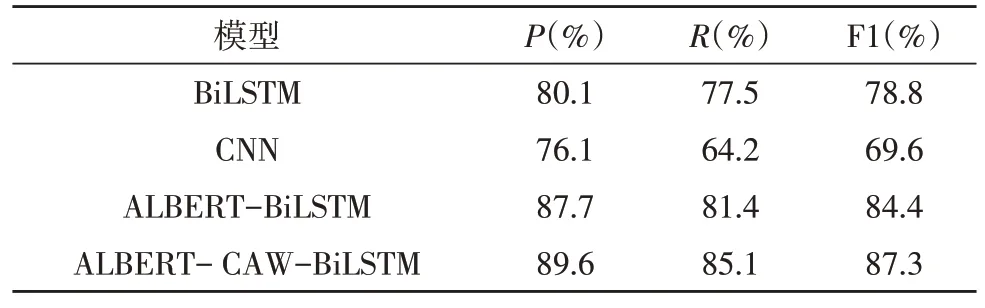
表4 不同模型结果对比
例如文本“会泽县城有新时代文明实践中心”中的组织机构实体“新时代文明实践中心”。CNN 模型标注为“O”完全无法识别出实体信息;BiLSTM 模型能利用上下文语义信息识别出一部分:实“B-ORG”、践“I-ORG”、中“I-ORG”、心“I-ORG”;ALBERTBiLSTM 模型和ALBERT-CAW-BiLSTM 模型均能识别出新“B-ORG”、时“I-ORG”、代“I-ORG”、文“IORG”、明“I-ORG”、实“I-ORG”、践“I-ORG”、中“IORG”、心“I-ORG”,证明充分使用了局部特征和上下文语义。在文本“全国中小学体育教学指导委员会、中国教育发展基金会、耐克体育公益部联合举办”中,ALBERT-BiLSTM 模型虽然将3 个实体都识别出来了,前两个正确识别为组织机构ORG 实体,但是错误地将第三个实体识别成政府部门GOV 实体,而ALBERT-CAW-BiLSTM 模型则成功识别3 个实体。
4 结束语
该文提出了基于ALBERT-CAW 的时政新闻领域实体识别模型,采用预训练语言模型ALBERT 获取文本的字词向量,在字词融合层利用CNN 和LSTM 初步提取的上下文语义和词语语义,将结果融合后,通过BiLSTM 层兼顾上下文语义提取深层特征,最终输入CRF 层进行解码,得到实体标注信息,完成对实体边界和类别的识别。该文设计了4 组对比实验,经过在自建的人民日报时政新闻数据集上进行验证,获得了87.3%的F1 值,与传统模型相比在准确率P、召回率R和F1 值上均有较大程度的提升,证明了该文模型能充分利用上下文信息,较好地解决一词多义问题,提高了识别准确率,模型能有效地完成时政新闻命名实体识别的任务。为进一步提升模型的性能,后续可以从细化和完善各类实体的标记规则、替换为ALBERT-large 的预训练模型、拓展语料规模和减少标注谬误等方面着手进行优化。
