基于权值筛选策略的增量学习方法
2022-08-16莫建文朱彦桥欧阳宁林乐平
莫建文,朱彦桥,欧阳宁,林乐平+
(1.桂林电子科技大学 信息与通信学院 认知无线电与信息处理省部共建教育部重点实验室, 广西 桂林 541004;2.桂林电子科技大学 信息与通信学院,广西 桂林 541004)
0 引 言
人类和动物可以持续地积累和巩固从先前观察到的任务中获取的知识,并不断地学习解决新的问题或任务。但现如今的大多数深度学习系统却缺乏这样的能力,当它们无法一次性访问所有数据的时候,为了适应当前的数据,它们必须通过反向传播来调整先前学习到的参数,这就会导致先前学习到的知识被干扰甚至被完全覆盖,这样的现象被称为灾难性遗忘[1]。
克服灾难性遗忘是深度学习领域中一个长期研究的问题,其本质上是如何令系统在稳定性与可塑性之间寻求平衡,稳定性指的是在学习新知识的同时记忆旧知识的能力,可塑性指的是模型整合新知识的能力。近年来,许多增量学习方法相继涌现,但这并不意味着深度学习模型已经能很好地适应增量式场景,因为现有的多数增量学习方法都过度关注如何提高模型的稳定性,却忽视了模型学习的可持续性。这就使得深度学习模型必须将大量资源耗费在对旧知识的巩固上,但当处于模型容量有限的环境时,这些模型往往会因为无法合理地利用有限的资源而导致其难以适应新任务。
基于这样的观察,提出一种更均衡的增量学习策略,它吸收了稳定性与可塑性间的互补优势,同时最小化它们各自的弱点,实现一个更高效的增量学习模型。
1 相关工作
最近的研究[2]中,缓解灾难性遗忘的方法大致可分为3类:基于样本重现的方法、基于网络结构的方法、基于正则化的方法。
基于样本重现的方法根据一些筛选标准,从旧数据集中抽取一些具有代表性的原始样本,将它们和新任务的样本进行联合训练来达到记忆的目的。例如Rebuffi等提出的增量分类与表示学习(incremental classifier and representation learning,iCaRL)[3],他们根据样本的特征向量从旧样本集中抽取最接近平均特征向量的样本,并使用它们来模拟已训练数据的特征分布。而何丽等[4]则通过快速查找发现密度峰值进行聚类的方法来筛选典型样本。在某些场景中,旧任务的样本并非随时都是可用的,当无法获取旧样本集的时候,一个替代方案是通过一些生成模型合成与原始样本相似度较高的伪样本。例如文献[5,6]利用对抗网络合成高质量的伪样本来代替原始样本。
基于网络结构的方法则采用更直观的方法来克服灾难性遗忘,它们将网络划分为多个独立的部分,每个部分都对应特定的任务,在对当前任务进行训练时,则将其它部分隔离,以防止任何可能的干扰。此类方法又分为两种场景,当对网络结构大小没有限制时,可以通过冻结先前任务学习到的参数集,并为新任务增加新的分支来实现[7,8]。而当处于无法进行扩展的静态模型中时,则可以通过在训练新任务期间将用于旧任务的部分屏蔽来实现,例如Packnet[9]借鉴了模型剪枝的思想,使用二进制掩码隔离旧任务的权值。而HAT[10]则使用基于节点的硬注意力机制来隔离重要节点。
基于正则化的方法通过在损失函数上引入额外的正则项来对权值的调整进行约束。这方面最早的工作为Kirkpatricka等提出的弹性权值固定——EWC(elastic weight consolidation)[11],它通过Fisher信息来评估网络权值对历史任务的重要性,然后根据权值的重要性对权值施加相应的固定力度,使重要性较高的权值进行更小幅度的调整来保存旧样本的特征。之后的很多方法都借鉴了EWC的思想,主要区别在于获取参数信息量的方法。例如,Aljundi等提出的MAS(memory aware synapses)[12]根据模型的输出对权值变化的敏感性,为网络的权值积累重要度。还有一些工作探索过如何通过不确定性判断模型参数的重要性。例如Hur等[13]将不确定性作为参数重要性的衡量标准,并应用于模型裁剪,而Jian等[14]则将不确定性应用到了持续学习领域,他们认为如果权值具有较低的熵值,则说明权值已处于稳态,相反,熵较大的权值具有更大的随机性,通过保留熵值较低的权值而更新那些熵较高的权值,更有利于模型的持续学习。
贝叶斯增量学习是正则化方法在贝叶斯神经网络中的应用模式,在贝叶斯神经网络的框架下,网络权值不再是某个固定的数值,而是由均值和方差定义的概率分布。Ebrahimi等提出在贝叶斯神经网络的框架下,通过权值的不确定性来定义权值重要性并对权值的更新进行相应限制的持续学习框架——UCB(uncertainty-guided continual bayesian neural networks)[15]。
以上方法都在增量学习领域取得了很好的效果,但正如引言所述,它们仍然存在可以改进的空间。例如基于正则化的方法[11,12,14,15]过于注重克服模型的遗忘问题,在训练过程中参数重要性的累积会导致优先训练的任务占用了大部分资源,由于这些参数已经被施加了很强的正则化力度,它们对于新任务来说是难以训练的,随着网络中可训练参数的急剧减少,网络的训练很快便会变得不可持续。通过注意力机制为任务划分参数集的方法[9,10]也同样存在这样的问题,优先训练的任务总是能获得更多资源,随着训练的深入,资源分配不均的问题会愈发凸显。
2 基于贝叶斯推理与权值筛选策略增量学习
针对以上问题,提出一种结合了贝叶斯神经网络和权值筛选策略的增量学习方法。首先它在贝叶斯神经网络的框架下,根据权值的不确定性调整每个权值的学习率,令重要性较高的权值保持较低的学习率,避免它们被过度调整。然后考虑到一昧地限制权值的变化会影响后续任务的学习效果,所以提出一种可选择性进行权值释放的策略,通过有选择地提高部分权值的更新步长,将它们从正则化的束缚中释放,使它们能更好地适应新任务。该方法的参数计算量始终保持恒定,在不进行网络结构扩展的情况下仍然能更学习到一个持续学习能力更强的模型。
2.1 基于变分估计的贝叶斯推理
贝叶斯推理需要一个完整的概率模型,其中包括模型参数的先验分布P(Z) 和数据的似然P(D|Z), 然后通过贝叶斯公式求出模型的后验分布
(1)
但由于式(1)中的分母P(D) 是一个仅与训练数据有关的概率分布,其实际构成比较复杂,所以导致直接求解后验分布在实际场景中很难实现,在实际操作中往往结合变分推理来近似求解模型的真实后验分布。
基于变分推理的贝叶斯优化,首先要假设一个基于参数θ=(μ,σ) 的高斯分布簇Q(Z|θ), 然后通过最小化Q(Z|θ) 与P(Z|D) 间的KL散度令Q(Z|θ) 近似于P(Z|D)

(2)
式(2)中的logP(D)是与变量无关的常数,也称为证据(evidence),右边第二项被称为最小证据因子下界(evidence lower bound,ELBO)。若保持logP(D) 不变,则最小化KL散度的问题也可以转化为针对ELBO的优化问题

(3)
其中, KL[Q(Z|θ)‖P(Z)] 在式(3)中充当了正则项的角色,公式通过最小化Q(Z|θ) 与先验P(Z) 间的KL散度,将模型的对数似然最大化。同时,为了适应一些复杂的后验分布,可以将先验指定为由两个零均值高斯分布组成的混合高斯分布,并通过多次蒙特卡洛采样求出式(3)的近似表达式

(4)
其中,Zn表示第n次采样后得到的权值,由于直接从概率分布中采样权值无法对参数进行梯度估计,所以一般使用重参数技巧来获取用于前向传播的权值
Z=μ+σ·ε
(5)
2.2 基于不确定性的贝叶斯增量学习
结合了变分估计的贝叶斯推理,因为需要通过正则项来近似后验分布,所以为将贝叶斯推理应用于增量学习场景提供了可能性。
Ebrahimi等提出的思想[15],参数的更新步长可以定义为前一任务学习到的标准差σt-1与初始学习率ηinit的乘积,然后在训练当前任务时,根据权值的标准差动态地调整均值更新的步长。与信息熵类似,标准差反映了模型参数的信息量大小,当标准差较大时,意味着权值采样具有更大的不确定性,从贝叶斯优化的角度考虑,这样的权值具有更大的训练价值,此时相应的更新步长Λ会更大,以促使权值做出更多改变来适应新任务,相反,标准差较小的权值,表示其在学习旧任务时已经达到稳态,需要限制它的变化来保存旧任务的信息
(6)

2.3 权值筛选策略
以上操作实现了基本的对权值的弹性约束,但这样的方法无法适应长序列的任务,因为权值的重要性会随着训练次数的增加而不断累积,从而使权值变得越来越难以训练,这对后续任务的学习非常不利。Schwarz等[16]针对这样的问题提出了另一种克服灾难性遗忘的思路,他们认为为了能保持模型的学习能力,对于已经学习过的旧任务,最好能以一种优雅而非灾难性的方式遗忘它们。这种理念也是增量学习的重要组成部分,尤其是在无法对网络进行扩展的环境下,缓慢地遗忘旧任务能为新任务的学习提供更多空间。
根据这样的理念,提出一个选择性释放资源的机制,它的概念如图1所示。

图1 选择性释放机制概念
如图1所示,两个椭圆分别表示训练了前t-1个任务后形成的参数空间和训练第t个任务后的参数空间,传统的训练方式采用随机梯度下降法令参数完全落入任务t的参数空间。而以EWC[12]为代表的正则化方法则通过控制权值的更新方向,令权值落入旧任务与新任务参数空间的交汇处,但随着任务量的增加,越来越多的权值被限制,权值更新方向会逐渐向旧任务的参数空间偏移,即模型越来越倾向于记忆旧任务而非学习新任务。本文的方法采取一个折中策略,它令参数的调整方向逐渐向任务t的参数空间靠拢,即适当地提高模型的学习能力来促进新任务的学习,同时缓慢地遗忘旧任务。
2.3.1 权值筛选
该机制的目的在于令旧任务主动舍弃部分资源来为未来任务腾出足够的学习空间,而自己则缓慢地遗忘先前学习过的知识。所以为了避免任务性能的突然崩溃,在释放前,首先需要确立一个筛选标准来对权值进行筛选。
首先将一层内的所有权值按标准差大小排序
(7)
然后设置一个释放比例r
r=i/I
(8)
然后根据比例将这I个权值中标准差最大的i个视为重要性较低,将它们归入集合GA,另外I-i个标准差较小的权值则视为重要性相对更高,将它们组成集合GB,在训练过程中,将对集合GA内的权值进行释放。
2.3.2 资源释放
对权值进行释放的具体操作,则通过在式(6)增加一个动态因子α来实现
(9)
(10)
如式(9)和式(10)所示,Y中的元素γi定义了每个权值释放的强度。式(6)仅根据权值对历史任务的重要性来对权值的调整进行约束,但加入了Y后,式(10)能根据权值的标准差大小在释放与固定之间进行动态切换,对于GA内的权值,对应位置的γ的取值为1,在优化时仍倾向于令权值的分布保持与先前相同的均值。但当权值的标准差高于该阈值时,对应的γ切换为一个大于1的常数,此时在优化过程中权值的学习率相较于式(6)会有所提高,这就允许权值在优化过程中可以做更大的调整来适应新任务。
权值筛选是基于正则化方法的一个有效补充,但因为以上操作都没有考虑到概率分布的均值,所以在权值的选择策略上仍然可以进行改善。因此,在原基础上将权值的筛选标准进行进一步完善
(11)
如式(11)所示,在原来的基础上,使用均值的绝对值与标准差的比值(信噪比)取代原来单一的标准差作为权值的筛选标准。信噪比是工程领域的常用参数,通过信噪比能更准确地反映权值的重要程度,当权值的信噪比较小时,表示权值的重要性相对较低,模型按比例筛选出信噪比最小的i个权值归入集合GA,然后仍然按照式(9)对它们进行释放,而集合GB内的I-i个权值,则继续维持原状。接下来的实验结果表明,通过信噪比筛选权值再进行释放,能让模型具有更高的鲁棒性。整个算法的流程见表1。
3 实验结果与分析
3.1 数据集介绍
MNSIT:由手写数字组成,共有10个类别,包括60 000个训练样本和10 000个测试样本。在实验中,以随机排列的方式将MNIST中的图像像素进行重新排序[11],形成多个分布不同的数据集(Perturbation-MNIST)来进行

表1 基于权值筛选策略的增量学习方法流程
多任务测试。对于类增量测试,则将MNIST划分为5个独立的子集(Split-MNIST),每个子集包含两个独立的类别,并按顺序输入网络进行类增量测试。
Fashion-MNIST:由10类服装图像组成,相较于MNIST,Fashion-MNIST更贴近真实场景,也更能反映模型的分类性能。在实验中,和MNIST一样,将其划分为5子集(Split-Fashion),并逐一输入网络进行二分类学习。
数据集的示例图如图2所示。

图2 数据集样本示例图
3.2 模型有效性分析
为了验证方法的有效性,将完整的算法和经过简化后的算法在数据集上进行实验对比。实验使用含有两个隐藏层的全连接神经网络,对于Perturbation-MNIST,将每层的神经元数目设为256个,对于Split-MNIST,则将神经元数目设为150个,而对于较难训练的Split-Fashion,则将每层节点增加到250个。实验遵循持续学习的原则,每个阶段仅对当前任务的样本样本进行训练,先前任务的数据样本无法再次访问,图3展示了每次训练结束后所有任务的平均分类精度。

图3 3种设置的分类精度
由图3可知,无论是多任务设置(Perturbation-MNIST)还是类增量设置(Split-MNIST、Split-Fashion),以信噪比为标准的权值筛选策略都能获得最高的分类精度。而只以标准差为标准的释放策略在Perturbation-MNIST和Split-MNIST上可以取得比只有固定操作的方法更好的精度,但在更难训练的Split-Fashion上未能表现出更好的性能。以上结果表明,主动释放资源的理念的确为模型的持续学习带来了积极的影响。
3.3 释放策略对模型稳定性与可塑性的影响
本节将分析释放策略对模型稳定性与可塑性的影响。表2和表3展示了在3.2节的网络配置中,Split-MNIST和Perturbation-MNIST在训练完成后,每个任务的最终分类精度。

表2 Split-MNIST上单个任务的最终分类精度/%

表3 Perturbation-MNIST单个任务的最终分类精度/%
由表2和表3可知,引入释放策略后的方法,其在两个数据集中的第一个任务的分类精度都要略低于仅有固定操作的模型,但后续任务的分类精度都要高于后者,这说明当没有引入权值筛选策略时,模型为了记忆旧任务的知识而限制了权值的调整,因此先前任务都能保持较高的分类精度,但当加入释放机制后,旧任务的资源得到释放,这些被释放的资源促进了后续任务的学习使得后续任务的分类性能得到提高,而且只要释放的比例与释放的强度控制得当,并不会严重损害旧任务的性能。释放机制的引入更充分地发掘了模型的持续学习能力。
3.4 均值变化分析


图4 均值变化趋势分析
如图4所示,当加入权值筛选策略后,均值的变化量在任何一个训练阶段都要高于仅有固定操作的模型。由于范数的大小一定程度上反映了矩阵中的元素大小,所以图4的结果说明了权值筛选策略的引入使得模型对参数的约束力度得到一定程度的减小,模型也就能做更多调整来适应新任务。
3.5 与不同方法的性能对比
将本文提出的权值筛选策略与目前最常用的几种增量学习方法进行比较。
为了更准确地评估模型的分类性能,对网络规模进行了不同设置。同时为了验证提出的方法同样适用于卷积神经网络,对Split-Fashion改用resnet18网络进行测试,其中表4列出了对resnet18的网络规模进行的3种不同设置的具体参数信息。对于Perturbation-MNIST和Split-MNIST,则继续沿用3.2节中的全连接神经网络,但同样对中间两个隐藏层的节点数目进行不同设置。

表4 resnet18的3种网络规模
表5、表6、表7显示了每种方法在完成所有任务训练后的平均分类精度,其中括号内数据表示每种方法的分类精度与本文方法的差距。由实验结果可知,本文提出的方法不仅能在不同规模的网络结构都保持着最高的分类精度,而且随着网络规模的缩小,其它方法与本文方法的差距基本上呈现拉大的趋势,例如使用Perturbation-MNIST测试时,当每层节点数目为256时,UCB的分类精度与本文算法的差距仅为1.05%,但当节点数目减少到150时,这个差距扩大到4.24%。这说明在资源有限的环境下,资源释放理念的引入能更好地保持网络的学习能力,促进有限资源的合理分配。
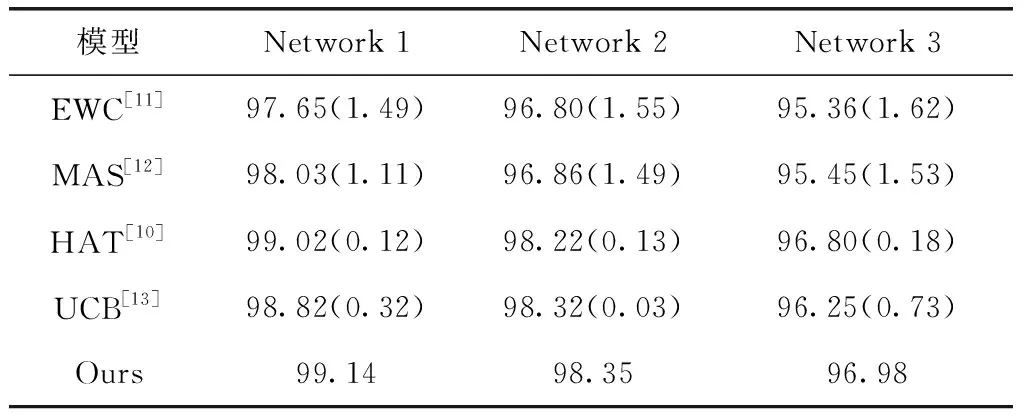
表5 Split-Fashion在不同网络中的分类精度/%
3.6 参数配置分析
本节列出了本文的方法在3.5节中的每个实验上当达到最高分类精度时释放策略的两个主要超参数释放比例r和释放强度γ各自的取值。

表6 Split-MNIST在不同网络中的分类精度/%

表7 Perturbation-MNIST在不同网络中的分类精度/%
通过表8、表9、表10可知,当网络资源相对充足时,可以将r和γ设置得更大,例如每层神经元数目达到256个和使用Network 1训练时,r和γ可以达到50%和2。当网络资源较少时,则需要将两个参数的取值适当减小,例如当每层神经元仅有100个或使用Network 3训练时,在Perturbation-MNIST和Split-Fashion上r和γ需要减小至20%和1.5才能达到最优的分类精度。

表8 Split-Fashion

表9 Split-MNIST

表10 Perurbation-MNIST
4 结束语
针对通过正则化保留重要参数的增量学习方法存在的稳定性与可塑性失衡的问题,提出了一个选择性释放网络资源来促进模型持续学习的策略。该策略首先在贝叶斯神经网络框架下通过权值的不确定性对权值的调整施加相应强度的限制,然后为了提高模型学习的持续性,根据信噪比筛选出部分权值进行适当强度的释放,该方法可以在不增加网络参数量的前提下将模型的学习能力维持在一个较高的水平,同时又不会严重损害旧任务的性能。实验结果表明,无论在多任务场景还是在类增量场景,本文提出的方法在几种对比方法中都保持着最高的分类性能。
