面向渤海生态环境的数据库管理系统设计与实现❋
2022-08-15于晓霞梁生康杨燕群韦志国魏志强王修林
王 瑞, 于晓霞, 叶 敏❋❋, 梁生康, 杨燕群, 韦志国, 聂 婕, 魏志强, 王修林,4,5
(1. 中国海洋大学信息科学与工程学部, 山东 青岛 266100; 2.山东省生态环境规划研究院, 山东 济南 250101; 3.中国海洋大学化学化工学院,山东 青岛 266100; 4. 中国海洋大学海洋化学理论与工程技术教育部重点实验室, 山东 青岛 266100; 5. 深海圈层与地球系统前沿科学中心, 山东 青岛 266100)
渤海是中国近岸海域环境问题最为突出的海区之一。作为我国唯一的半封闭型内海,随着沿海地区产业和人口的高速发展,渤海生态环境形式日趋严峻。近年来,中国高度重视渤海环境保护和治理工作,积累了丰富的陆海生态环境监测、调查、统计和计算数据。主要包括:
(1)丰富的监测和调查数据。在环渤海地区建立了较为完善的环境监测网络和计算模型,构建了基于岸基、水上浮标、卫星遥感等平台的立体观测体系,与常规监测和调查手段相结合,形成了较为完善的连接污染源、流域、海域的监测网络,积累了丰富的陆海环境监测[1]和调查数据[2]。
(2)多样的社会经济数据。渤海海域生态环境质量状况受到环渤海地区人类社会经济活动和自然环境变化协同作用的影响,社会经济统计数据成为深入解析渤海水质演化和人类社会活动响应机制的重要载体。只有充分挖掘人类社会活动和沿海水质时空演化响应关系,才能突破污染物产生、输运、汇集等迁移转化环节监测盲点,制定精准有效的陆源污染物减排措施。随着环渤海地区产业细分、人类社会活动多样性趋向和互联网技术的飞速发展,产生了规模巨大的多样性社会经济统计数据。
(3)多元的地图数据。除监测、调查数据和经济统计数据外,GIS等地理信息数据也构成了近海生态环境大数据,主要包括地形地貌、点源、监测站位、入海排污口坐标,面源、行政区、控制单元、水质响应区域、河流矢量图等地图数据。随着空间控制粒度的精细化、地图绘制技术的多样性发展,形成了丰富的、跨尺度、多模态地理大数据系统,为流域建模、海洋动力过程仿真、时空数据可视化等提供了更加精细和多元的地理信息空间。
(4)海量的计算数据。随着海洋动力模式仿真计算和入海污染物生物地球化学过程建模技术的发展,水质预报模型日益丰富,网格化的仿真计算数据能够从不同时空粒度刻画海域污染物的时空分布状态,随着三维水动力和生物地球化学耦合模型的精细化和多样化发展,计算数据规模激增[3]。
综上,渤海生态环境大数据是加强渤海生态环境保护,改善渤海环境质量,突破渤海入海污染物源解析和水质目标管控等关键瓶颈问题的数据基础。但海量多源异构、跨时空、多尺度、多要素的生态环境数据的有效组织和管理给科学研究和决策分析带来了巨大挑战。因此,本文聚焦渤海生态环境大数据管理的迫切需求,针对渤海生态环境数据的存储、检索、管理等任务,打破传统的数据管理系统范式,提出了一种多层级递进式数据管理模式,通过递进式数据库设计和垂直应用领域业务分级编码方法,构建基于语义和时空线索的多维一体化渤海生态环境数据分级检索系统。为高效管理和利用陆海污染源数据进行科学研究和污染防治等提供技术支撑。
1 研究现状
中国经过长期的海洋观测、监测、卫星遥感、专项调查,形成了丰富的海洋信息数据和管理系统。例如,谢志敏搭建了面向海洋气象的数据汇聚平台[4],针对海洋气象数据标准各异、来源广泛、结构多样等特点,建立了标准统一、存储方便的气象数据平台;李立刚设计了海洋观测数据管理系统[5],通过整合来源于不同观测设备的异构监测数据,实现了数据的一致性管理;赵彩云针对海洋环境数据的实时监测和分析需求,设计了海洋环境在线监测数据管理系统[6];赵雪[7]针对数据分散存储和可信共享问题,提升了数据共享平台的安全性;王天雨设计的面向海洋多元数据的云存储管理系统[8],使用云计算和大数据的技术进一步提升数据存取的可靠性与实时性;陈宇设计的海洋平台分布式综合信息管理系统[9]通过数据分类过程的规范化和统一化约束设计数据编码方法,将孤立分散的数据空间整合为全面系统的数据空间,从而提高了平台使用的寿命和系统运行的质量。
虽然针对海量多源异构的海洋数据管理已形成了有效的数据集成和汇聚手段,但上述研究仅针对海洋监测、调查、统计、地图、计算数据中的单一数据或部分类型开展数据管理,由于数据异构性和时空跨尺度等挑战,难以扩展至兼容多样性数据类型的综合管理平台。其次,数据管理粒度切换困难。现有数据管理系统难以同时应对基于语义的文件数据检索和基于时空线索的数值数据检索。最后,由于缺乏陆海统筹、部门地域协同的陆海统筹污染控制机制,目前尚未形成支撑陆海统筹污染控制垂直应用领域的渤海生态环境大数据管理平台。
针对以上挑战,本文打破传统的数据管理系统范式,通过递进式数据库设计,形成了兼容监测、调查、统计、地图、计算等多种数据类型的原始数据库、原始归集数据库、标准数据库和功用数据库的架构,实现跨尺度、多模态海量异构数据的可兼容综合管理;其次,通过面向垂直应用领域的业务梳理和流程再造,提出了一套通用面向陆海统筹的污染源数据分级编码方法,实现了语义和时空线索多维一体化数据检索模式,并最终实现支撑陆海统筹污染控制的渤海生态环境数据库管理系统。
2 系统设计
2.1 总体设计
系统的总体设计架构如图1所示。采用多层次体系结构,共分为7层,包括基础设施层、数据库、数据层、服务层、运行支持层、业务层和客户端。基础设施层主要包括支撑系统运行的必要硬件系统和软件平台。数据库层包含了本系统所有的基础数据库,为了兼容监测、调查、统计、地图和计算等多类数据类型,本文提出了递进式数据库设计模式,提出原始数据库,原始归集数据库,标准数据库和功用数据库的四级数据管理模式。其后,数据层和服务层主要提供数据缓存、读写、事务、用户管理、配置、监控、日志等通用中间件功能。运行支持层是上层实现对服务层进行调用的中介,业务层主要实现面向应用的功能模块和流程集成开发,客户端主要实现系统的登录和用户交互。标准规范体系,用于解决不同层次间相互调用的兼容问题,使整个系统在统一的标准下运行,有利于系统的维护和扩展。

图1 系统架构图Fig.1 System architecture diagram
2.2 数据库设计
针对海洋监测、调查、统计、地图、计算数据跨尺度、多模态海量异构数据的可兼容综合管理需求,本文提出了多层级递进式数据库设计模式。将数据库划分为四个子数据库,分别为原始数据库、原始归集数据库、准数据库、功用数据库。其中原始数据库采用文件粒度管理模式, 实现对汇聚数据的来源管理。原始归集数据库在原始数据库的基础上,进行数据清洗和质量管控,同时依据元数据规范,将原始数据库文件规约为格式标准的原始归集数据表,形成原始归集数据库。在原始归集数据库的基础上,依据垂直领域业务结构,抽取关键数据,经过可靠性过滤,汇聚形成标准数据库。最后,面向终端应用,基于业务需求进行数据抽取和生成,形成需求驱动的功用数据表,汇聚成为功用数据库。这种递进式的分级数据管理模式和基于业务结构形成的陆海统筹时空语义多维一体化数据管理方法,是本系统的主要创新。
2.2.1 原始数据库设计 原始数据库实现对多源异构数据管理。例如,对于地图数据的shape文件、经济数据的excel表、科学计算的nc文件等原始数据,其主要目标是实现对多来源、多类型、异构文件的综合管理。
根据原始数据库管理需求,设计了一张原始数据库元信息表,记录待解析文件的相关信息,以辅助原始文件入库。其字段结构如表1所示。

表1 原始数据库元信息表Table 1 Original database meta-information table
多来源、多类型、异构文件存在数据结构不一,数据类型多元的问题。因此无法采用单一解析方法,需分文件解析。
当原始文件入库时,首先会对文件进行解析以获取其对应的文件名、文件类型和文件格式等信息,同时生成唯一主键sid并记录于原始数据库元信息表中,这样每个被解析的文件就对应原始数据库元信息表中的一条记录。
随后依据原始数据库元信息表所记录的文件类型信息,采取相应的数据解析操作。例如,对于栅格类型的文件会逐行读取,对文本文件则会逐字节加载,而对图片文件则会将其解析为一串二进制数据。
最后生成一张原始数据库的数据表,存放所解析的数据。其中数据表名称会关联于原始数据库元信息表中的sid字段,这样便实现了数据与元信息相关联,有利于后续对数据的检索与管理。
原始数据库实现了对多源、异构、渤海环境大数据的文件粒度级的综合管理,但是由于原始文件类型多样、规模各异,导致原始数据库数据表规模庞大、要素分散、粒度不一、时空不均,难以有效支撑环境数据的查询和检索。因此,进一步提出原始归集数据库,对原始数据库文件进行统一规约。
2.2.2 原始归集数据库设计 因原始数据库面临两个方面的挑战,一方面原始数据库包含大量小表,缺乏合理关联,导致管理困难。另一方面,表的内部数据结构不尽相同,造成字段缺失,数据冗余,数据置空等挑战。因此,针对以上问题,通过规约原始数据库中的小数据表,形成格式标准、质量可靠原始规约数据表。这是原始归集数据库的构建目标。
原始归集数据库同样设计了一张原始归集数据库元信息表,用以辅助数据规约、转换和质控。原始归集数据库元信息表字段信息如表2所示:

表2 原始归集数据库元信息表Table 2 Meta-information table of the original collection database
借助元信息表开展原始归集数据库的结构设计工作。首先,针对数据类别,在层次化的垂直方向上,将数据划分为四类,“地图数据”、“社会经济数据”、“陆源环境调查监测数据”、“海洋环境监测调查数据”,并将对应的层次结构信息记录于原始归集数据库元信息表中。同时,在层次结构的末端,会挂载一张具有规范结构的原始归集数据库的数据表,从而将数据与类别信息进行关联。最后依据该结构并配合元信息表进行原始数据转化工作。
当数据由原始数据库向原始归集数据库转化时,系统首先根据原始数据库元信息表中的Data_Source字段信息,判断并选择其需要归集到的特定原始归集数据库的数据表,由于原始数据库和原始归集数据库表各自的数据表结构不同,因此需要开展数据质量控制,包括字段信息完整性校验,数据值空缺补全,数据去冗余等。其后,生成主键ssid并将原始数据库中的sid和相关元信息记录于原始归集数据库元信息表;最后,将原始数据库中相对应的表的数据归集进原始归集数据表中。
如图2所示,多张原始数据库的数据表被归并到一张原始归集数据库的表中。这样便解决了数据格式规范不统一和大量小表存在的问题。
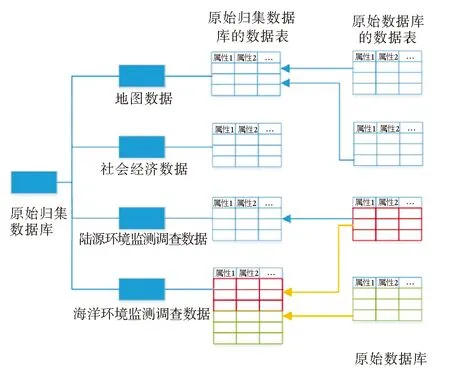
图2 原始归集数据库结构设计Fig.2 Original collection database structure design
原始归集数据库通过定义原始归集数据元信息表和归集数据标准表,实现数据的完整性和规范性的有效提升。但是,由于数据无法与相关业务的语义信息所关联,无法有效支撑面向业务领域的需求。因此,需要面向业务领域,开展数据管理,才能实现数据与业务之间的强耦合。
2.2.3 标准数据库设计 标准数据库需要满足面向业务领域开展基于语义的数据检索需求,既包括基于业务类型的全局数据检索,也包括针对要素、时空等精细粒度的数据管理。因此,在原始归集数据库的基础上,面向垂直应用领域体系架构,通过业务梳理和流程再造,形成包含业务语义的层次化结构,将每条数据实现与相应的业务层次进行关联,形成结构化的标准数据库表;其次,标准数据库的数据需要和原始归集数据库、原始数据库的数据进行关联,实现数据溯源。因此标准数据库的实现需要两个方面的工作,其一,构建标准数据库元信息表,实现标准数据库的结构化管理,将在本节中进行详细说明。其二,形成数据编码,实现数据的可回溯。将在2.3.4节中进行详细介绍。
标准数据库元信息表结构如表3所示。

表3 标准数据库元信息表Table 3 Standard database metadata table
由原始归集数据库向标准数据库进行数据转换的流程如下:首先,根据图3的业务结构图,为每个叶子结点生成标准数据库数据表,用以承载具体数据。本系统所依靠的业务结构是根据陆海统筹污染治理业务需求和逻辑对业务流程进行模块化和重塑后形成的业务体系,详情如图3所示,第一层次包含四大类,包括“陆海界面”,“海域水动力输运过程多源入海”,“多源入海污染排放数量”和“海域生物生态过程”,其后,根据业务流程进行细粒度划分,图3仅对前两层结构进行简单示意。所有的叶子结点都对应标准数据库中的一张数据表,数据表按照层次结构进行关联,数据表元数据信息中的“业务层次结构”字段对该关联进行标识。例如盐度sal要素通过数据业务层次结构字段映射为2-2层次,第一层的2会解析为海域水动力输运过程,第二层的2进一步归属为其下属的水文类别。通过业务层次关联,表征了数据对应的业务层次的语义信息。在数据检索时,依据业务层次信息能快速实现业务领域定位,从而最大程度缩小检索范围,加快数据检索速度。依据业务结构图中叶子结点所对应的标准数据库表,对原始归集数据库表开展数据筛选,加载到标准数据库中,最终完成了标准数据库的构建。
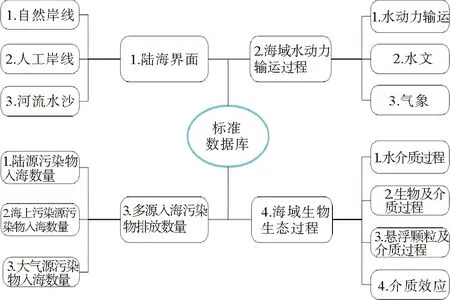
图3 业务结构图Fig.3 Business structure chart
2.2.4 功用数据库设计 功用数据库即特定功能用途的数据库。功用数据库是面向特定领域、特定用户、特定功能的数据库。基于业务化需求进行数据抽取和生成,形成需求驱动的功用数据表,汇聚成为功用数据库。因其数据结构是面向特定业务功能开展定制,本文不做详细的论述。
2.2.5 数据编码表设计 对于渤海生态环境的数据利用,最重要的是时空数据的检索和信息回溯。所谓时空数据检索即依据给出的时间和空间信息,快速搜索出用户所需要的数据。而对于信息回溯则是需要通过给定的数据,由标准数据库开始,由原始归集数据库到原始数据库,最后定位到某个具体的文件并获得数据来源相关的信息。
为了达到数据的全局检索和信息回溯的需求,会在已有的原始数据库元信息表,原始归集数据库元信息表和标准数据库元信息表的基础上,根据各自其部分信息生成一张编码信息表。通过该表,从而实现了用户通过时空条件进行全局检索,同时进行信息回溯的目的。
编码表的具体设计如图4所示。
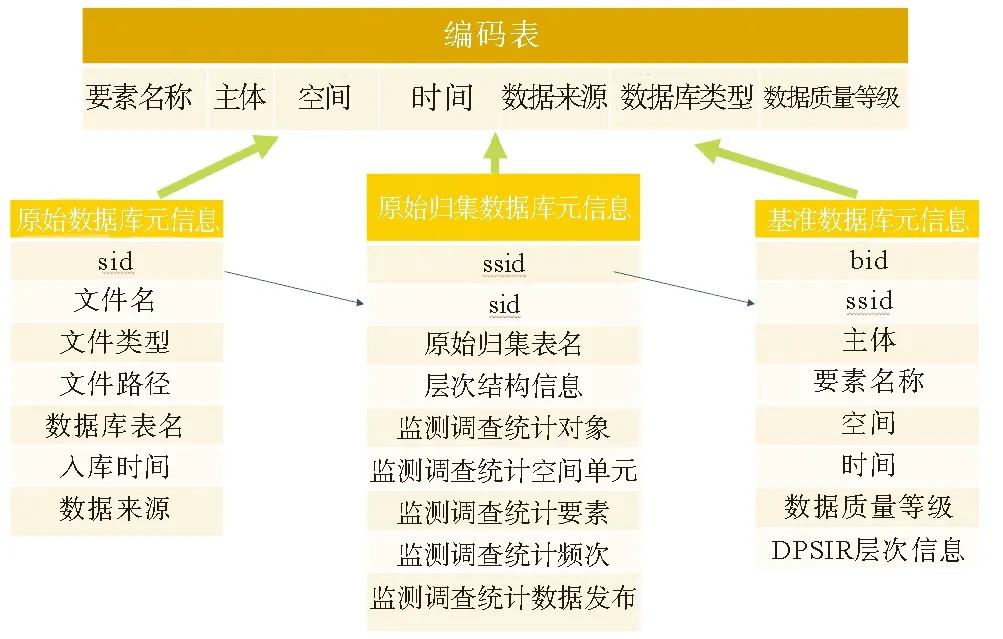
图4 业务结构图Fig.4 Code table structure design
系统通过sid,ssid字段将三张表进行关联,同时筛选出特定的高频使用字段信息生成编码表。如图4所示,红色的字段对应于选中字段。用户对数据进行基于语义或者时空关系检索时,解析所对应的时空信息和语义信息,实现快速定位并查询。同时能由给出的要素名称字段,根据ssid,sid的关联,回溯至原始数据集,获取数据的来源方的相关信息。
3 系统主要功能实现
3.1 技术架构的介绍
本系统采用了B/S架构。同时使用了前后端分离的开发模式。使得整个系统呈现为高内聚、低耦合的特性。
前端应用vue.js框架,遵循MVVM开发的模式,通过数据驱动的方式,将页面的构建和数据的注入进行分离,使得数据和页面彻底实现了解耦。后端采用了Springmvc的技术,通过View、Controller、 Model三大模块的构建以应对前端页面传来的请求和后台数据的处理。Mybatis框架技术实现了对数据库的操作封装。并提供操作数据的接口,以满足系统对数据从源数据、归集数据、标准数据、功用数据的逐步转化需要。
3.2 标准数据模块
该模块划分为五大类别,分别对应原始数据库,原始归集数据库,标准数据库和功用数据库。原始归集数据库和标准数据库分别有对应的层次结构。图5展示了标准数据库的层次结构以及所挂载的数据的样例。通过左侧导航栏可以快速定位业务表及数据。
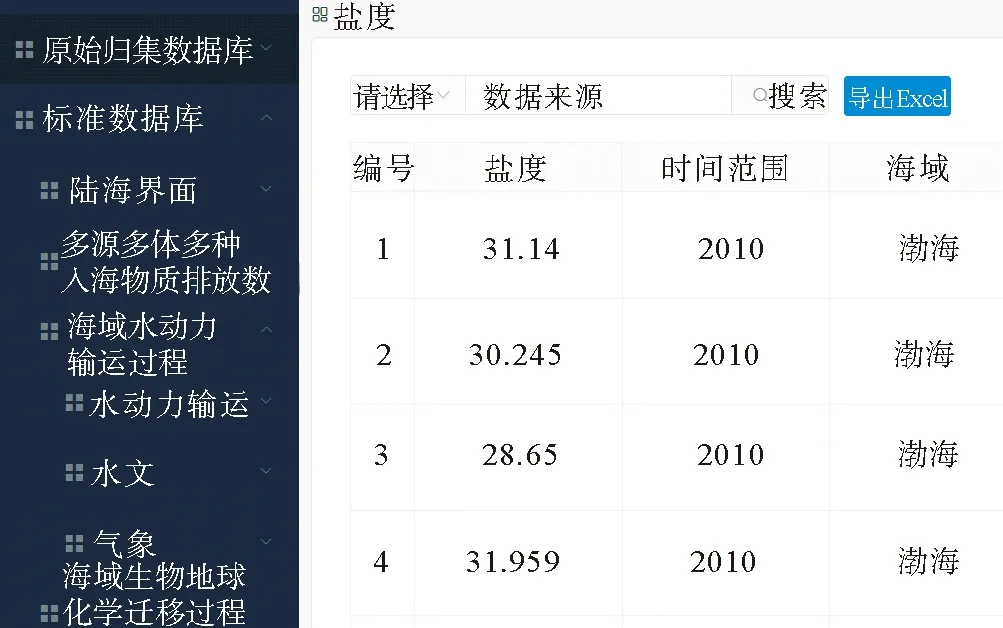
图5 标准数据库界面Fig.5 Standard database interface
3.3 快速检索模块
快速检索模块是利用上述分库、分业务设计架构,依赖编码表所提供的信息,快速定位某一个要素所处的业务表的层级,从而避免了全局遍历数据的情况,大大减少了检索数据的时间,实现快速检索需求。
图6展示了搜索界面,该搜索栏包括三个字段,分别为时间、空间和属性名。系统会根据输入的要素名称所对应的编码信息解码出对应的业务层次,再结合所输入的时空信息,将检索问题限定在特定小范围的进行解决。从而完美解决了大规模时空数据检索的难题。
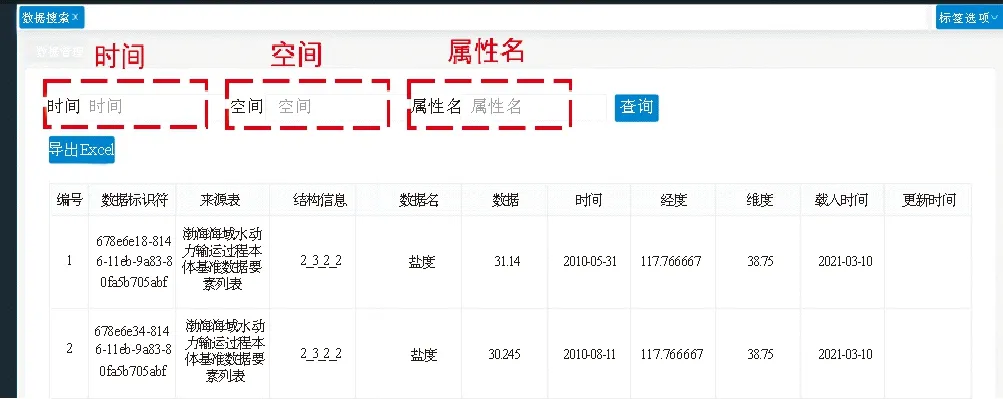
图6 数据检索Fig.6 data retrieval
3.4 统计模块
如图7所示,为使数据能够直观展示,而设计了一套可视化的界面,后台系统通过数据统计分析,将其结果以条形图、折线图和饼状图的方式进行呈现。一方面展示数据的变化趋势,另一方面又展示数据的占比情况。
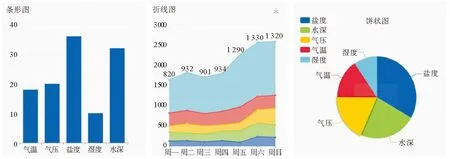
图7 数据可视化Fig.7 Data visualization
4 结语
本文基于渤海海量多源异构、跨时空、多尺度、多要素的生态环境大数据检索与管理的迫切需求。通过递进式数据库设计和通过面向垂直应用领域的业务梳理和流程再造方式方法,实现了一套渤海生态环境数据分级检索系统,解决了多来源、异构数据的管理和快速检索问题。为用户高效利用数据做科学研究和近海污染防治决策分析提供了坚实的数据基础。
